Xưởng sản xuất Amazon SageMaker cung cấp giải pháp được quản lý hoàn toàn cho các nhà khoa học dữ liệu để xây dựng, đào tạo và triển khai các mô hình học máy (ML) một cách tương tác. Công việc trên sổ ghi chép Amazon SageMaker cho phép các nhà khoa học dữ liệu chạy sổ ghi chép của họ theo yêu cầu hoặc theo lịch chỉ với vài cú nhấp chuột trong SageMaker Studio. Với lần ra mắt này, bạn có thể lập trình chạy sổ ghi chép dưới dạng công việc bằng cách sử dụng API do Đường ống Amazon SageMaker, tính năng điều phối quy trình làm việc ML của Amazon SageMaker. Hơn nữa, bạn có thể tạo quy trình làm việc ML gồm nhiều bước với nhiều sổ ghi chép phụ thuộc bằng cách sử dụng các API này.
SageMaker Pipelines là một công cụ điều phối quy trình làm việc gốc để xây dựng các quy trình ML tận dụng khả năng tích hợp trực tiếp của SageMaker. Mỗi đường dẫn SageMaker bao gồm bước, tương ứng với các tác vụ riêng lẻ như xử lý, đào tạo hoặc xử lý dữ liệu bằng cách sử dụng Amazon EMR. Các công việc sổ ghi chép SageMaker hiện có sẵn dưới dạng loại bước tích hợp trong quy trình SageMaker. Bạn có thể sử dụng bước công việc sổ ghi chép này để dễ dàng chạy sổ ghi chép dưới dạng công việc chỉ với một vài dòng mã bằng cách sử dụng SDK Python SageMaker của Amazon. Ngoài ra, bạn có thể ghép nhiều sổ ghi chép phụ thuộc lại với nhau để tạo một quy trình công việc ở dạng Đồ thị tuần hoàn có hướng (DAG). Sau đó, bạn có thể chạy các công việc sổ ghi chép hoặc DAG này, đồng thời quản lý và trực quan hóa chúng bằng SageMaker Studio.
Các nhà khoa học dữ liệu hiện đang sử dụng SageMaker Studio để phát triển sổ ghi chép Jupyter của họ một cách tương tác, sau đó sử dụng các tác vụ sổ ghi chép SageMaker để chạy các sổ ghi chép này như các công việc đã lên lịch. Những công việc này có thể được chạy ngay lập tức hoặc theo lịch trình định kỳ mà không cần nhân viên dữ liệu phải cấu trúc lại mã dưới dạng mô-đun Python. Một số trường hợp sử dụng phổ biến để thực hiện việc này bao gồm:
- Chạy máy tính xách tay dài ở chế độ nền
- Thường xuyên chạy suy luận mô hình để tạo báo cáo
- Mở rộng quy mô từ việc chuẩn bị các tập dữ liệu mẫu nhỏ sang làm việc với dữ liệu lớn ở quy mô petabyte
- Đào tạo lại và triển khai các mô hình trên một số nhịp
- Lập kế hoạch công việc để theo dõi chất lượng mô hình hoặc trôi dạt dữ liệu
- Khám phá không gian tham số cho các mô hình tốt hơn
Mặc dù chức năng này giúp nhân viên dữ liệu dễ dàng tự động hóa các sổ ghi chép độc lập, nhưng quy trình công việc ML thường bao gồm một số sổ ghi chép, mỗi sổ ghi chép thực hiện một nhiệm vụ cụ thể với các phần phụ thuộc phức tạp. Ví dụ: một sổ ghi chép theo dõi độ lệch dữ liệu của mô hình phải có bước trước cho phép trích xuất, chuyển đổi và tải (ETL) cũng như xử lý dữ liệu mới cũng như bước làm mới và đào tạo mô hình sau trong trường hợp nhận thấy độ lệch đáng kể . Hơn nữa, các nhà khoa học dữ liệu có thể muốn kích hoạt toàn bộ quy trình làm việc này theo lịch định kỳ để cập nhật mô hình dựa trên dữ liệu mới. Để giúp bạn dễ dàng tự động hóa sổ ghi chép của mình và tạo các quy trình công việc phức tạp như vậy, các công việc sổ ghi chép SageMaker hiện có sẵn dưới dạng một bước trong SageMaker Pipelines. Trong bài đăng này, chúng tôi chỉ ra cách bạn có thể giải quyết các trường hợp sử dụng sau bằng một vài dòng mã:
- Lập trình chạy một sổ ghi chép độc lập ngay lập tức hoặc theo lịch trình định kỳ
- Tạo quy trình công việc gồm nhiều bước của sổ ghi chép dưới dạng DAG cho mục đích tích hợp liên tục và phân phối liên tục (CI/CD) có thể được quản lý thông qua giao diện người dùng SageMaker Studio
Tổng quan về giải pháp
Sơ đồ sau minh họa kiến trúc giải pháp của chúng tôi. Bạn có thể sử dụng SageMaker Python SDK để chạy một tác vụ sổ tay hoặc một quy trình công việc. Tính năng này tạo ra một công việc đào tạo SageMaker để chạy sổ ghi chép.
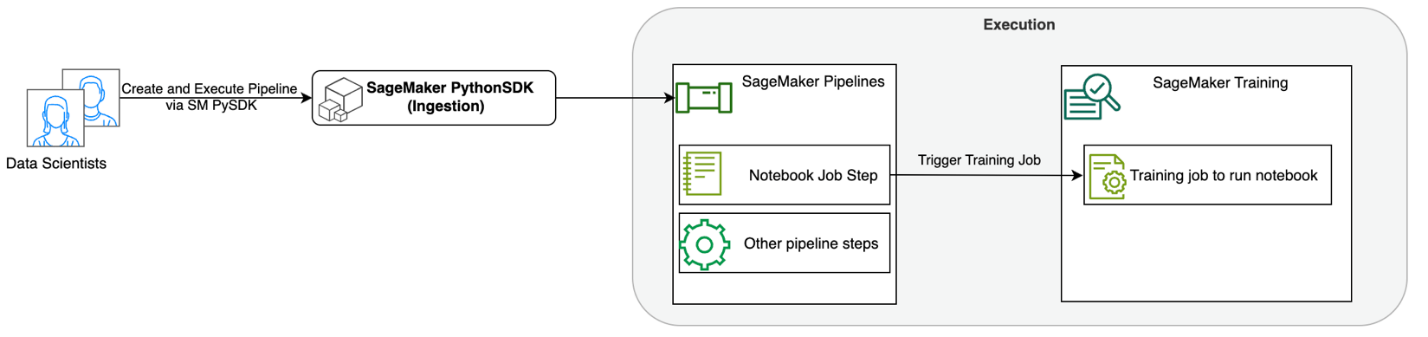
Trong các phần sau, chúng tôi sẽ giới thiệu một trường hợp sử dụng ML mẫu và giới thiệu các bước để tạo quy trình làm việc của sổ ghi chép, chuyển tham số giữa các bước sổ ghi chép khác nhau, lên lịch cho quy trình làm việc của bạn và giám sát quy trình đó qua SageMaker Studio.
Đối với vấn đề ML của chúng tôi trong ví dụ này, chúng tôi đang xây dựng một mô hình phân tích cảm tính, đây là một loại nhiệm vụ phân loại văn bản. Các ứng dụng phổ biến nhất của phân tích tình cảm bao gồm giám sát phương tiện truyền thông xã hội, quản lý hỗ trợ khách hàng và phân tích phản hồi của khách hàng. Tập dữ liệu được sử dụng trong ví dụ này là tập dữ liệu Stanford Sentiment Treebank (SST2), bao gồm các bài đánh giá phim cùng với một số nguyên (0 hoặc 1) biểu thị cảm tính tích cực hoặc tiêu cực của bài đánh giá.
Sau đây là một ví dụ về một data.csv tệp tương ứng với tập dữ liệu SST2 và hiển thị các giá trị trong hai cột đầu tiên của nó. Lưu ý rằng tệp không được có bất kỳ tiêu đề nào.
| Cột 1 | Cột 2 |
| 0 | ẩn các chất tiết mới từ các đơn vị cha mẹ |
| 0 | không có trí tuệ, chỉ có những trò đùa cợt nhả |
| 1 | yêu thích các nhân vật của nó và truyền đạt một điều gì đó khá đẹp về bản chất con người |
| 0 | vẫn hoàn toàn hài lòng để giữ nguyên trong suốt |
| 0 | về những lời sáo rỗng về sự trả thù tồi tệ nhất của những kẻ mọt sách mà các nhà làm phim có thể tìm ra |
| 0 | quá bi thảm để xứng đáng với sự đối xử hời hợt như vậy |
| 1 | chứng minh rằng đạo diễn của những bộ phim bom tấn hollywood như trò chơi yêu nước vẫn có thể tạo ra một bộ phim nhỏ, cá nhân với một bức tường đầy cảm xúc. |
Trong ví dụ ML này, chúng ta phải thực hiện một số nhiệm vụ:
- Thực hiện kỹ thuật tính năng để chuẩn bị tập dữ liệu này theo định dạng mà mô hình của chúng tôi có thể hiểu được.
- Kỹ thuật hậu tính năng, chạy một bước đào tạo sử dụng Transformers.
- Thiết lập suy luận hàng loạt bằng mô hình được tinh chỉnh để giúp dự đoán cảm tính đối với các đánh giá mới được đưa ra.
- Thiết lập bước giám sát dữ liệu để chúng tôi có thể thường xuyên theo dõi dữ liệu mới của mình xem có bất kỳ sự sai lệch nào về chất lượng có thể yêu cầu chúng tôi đào tạo lại trọng số mô hình hay không.
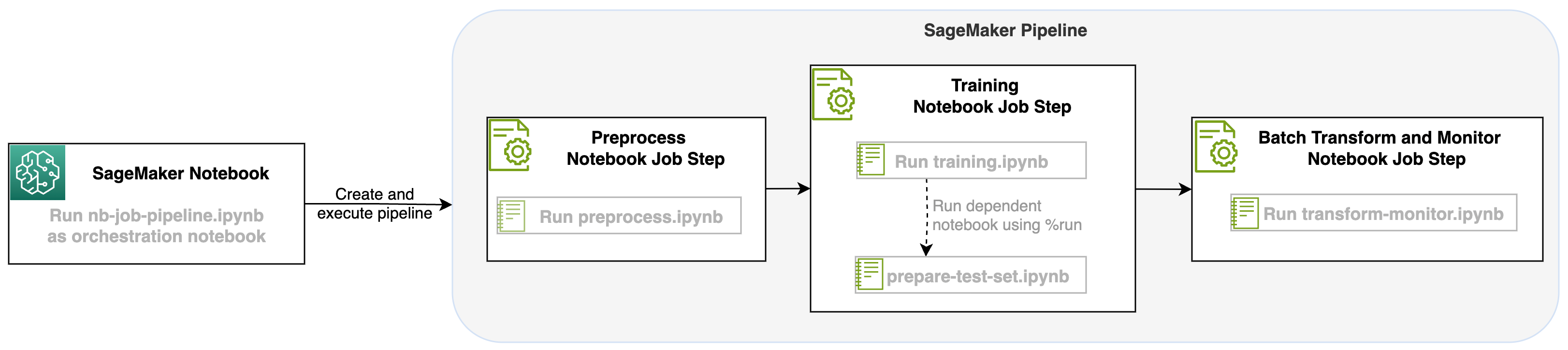
Với việc ra mắt tác vụ sổ ghi chép như một bước trong quy trình của SageMaker, chúng tôi có thể điều phối quy trình làm việc này, bao gồm ba bước riêng biệt. Mỗi bước của quy trình làm việc được phát triển trong một sổ ghi chép khác nhau, sau đó sổ ghi chép này được chuyển đổi thành các bước công việc sổ ghi chép độc lập và được kết nối dưới dạng quy trình:
- Sơ chế – Tải xuống tập dữ liệu SST2 công khai từ Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và tạo tệp CSV cho sổ ghi chép ở Bước 2 để chạy. Tập dữ liệu SST2 là tập dữ liệu phân loại văn bản có hai nhãn (0 và 1) và một cột văn bản để phân loại.
- Hội thảo – Lấy file CSV đã định hình và chạy tinh chỉnh bằng BERT để phân loại văn bản bằng thư viện Transformers. Chúng tôi sử dụng sổ ghi chép chuẩn bị dữ liệu thử nghiệm như một phần của bước này, đây là bước phụ thuộc cho bước tinh chỉnh và suy luận hàng loạt. Khi quá trình tinh chỉnh hoàn tất, sổ ghi chép này sẽ được chạy bằng cách sử dụng ma thuật chạy và chuẩn bị tập dữ liệu thử nghiệm để suy luận mẫu với mô hình được tinh chỉnh.
- Chuyển đổi và giám sát – Thực hiện suy luận hàng loạt và thiết lập chất lượng dữ liệu bằng tính năng giám sát mô hình để có đề xuất tập dữ liệu cơ sở.
Chạy sổ ghi chép
Mã mẫu cho giải pháp này có sẵn trên GitHub.
Tạo bước công việc trong sổ ghi chép SageMaker cũng tương tự như việc tạo các bước khác trong Quy trình SageMaker. Trong ví dụ về sổ ghi chép này, chúng tôi sử dụng SageMaker Python SDK để điều phối quy trình làm việc. Để tạo một bước sổ ghi chép trong SageMaker Pipelines, bạn có thể xác định các tham số sau:
- Sổ ghi chép đầu vào – Tên sổ ghi chép mà bước sổ ghi chép này sẽ sắp xếp. Tại đây bạn có thể chuyển đường dẫn cục bộ tới sổ ghi chép đầu vào. Theo tùy chọn, nếu sổ ghi chép này có các sổ ghi chép khác đang chạy, bạn có thể chuyển những sổ ghi chép này vào
AdditionalDependenciestham số cho bước công việc sổ ghi chép. - URI hình ảnh – Hình ảnh Docker đằng sau bước công việc của sổ ghi chép. Đây có thể là hình ảnh được xác định trước mà SageMaker đã cung cấp hoặc hình ảnh tùy chỉnh mà bạn đã xác định và đẩy tới Đăng ký container đàn hồi Amazon (Amazon ECR). Hãy tham khảo phần cân nhắc ở cuối bài này để biết các hình ảnh được hỗ trợ.
- Tên hạt nhân – Tên kernel bạn đang sử dụng trên SageMaker Studio. Thông số kernel này được đăng ký trong hình ảnh mà bạn đã cung cấp.
- Loại phiên bản (tùy chọn) - Đám mây điện toán đàn hồi Amazon (Amazon EC2) loại phiên bản đằng sau tác vụ sổ ghi chép mà bạn đã xác định và sẽ chạy.
- Thông số (tùy chọn) – Các tham số bạn có thể chuyển vào sẽ có thể truy cập được vào sổ ghi chép của bạn. Chúng có thể được xác định theo cặp khóa-giá trị. Ngoài ra, các tham số này có thể được sửa đổi giữa các lần chạy công việc sổ ghi chép hoặc các lần chạy quy trình khác nhau.
Ví dụ của chúng tôi có tổng cộng năm sổ ghi chép:
- nb-job-pipeline.ipynb – Đây là sổ ghi chép chính của chúng tôi, nơi chúng tôi xác định quy trình và quy trình làm việc của mình.
- tiền xử lý.ipynb – Sổ ghi chép này là bước đầu tiên trong quy trình làm việc của chúng tôi và chứa mã sẽ lấy tập dữ liệu AWS công khai và tạo tệp CSV từ đó.
- đào tạo.ipynb – Sổ tay này là bước thứ hai trong quy trình làm việc của chúng tôi và chứa mã để lấy CSV từ bước trước và tiến hành đào tạo cũng như tinh chỉnh cục bộ. Bước này cũng có sự phụ thuộc từ
prepare-test-set.ipynbsổ ghi chép để lấy tập dữ liệu thử nghiệm để suy luận mẫu bằng mô hình được tinh chỉnh. - chuẩn bị-test-set.ipynb – Sổ ghi chép này tạo một tập dữ liệu thử nghiệm mà sổ ghi chép đào tạo của chúng tôi sẽ sử dụng trong bước quy trình thứ hai và sử dụng để suy luận mẫu với mô hình được tinh chỉnh.
- biến đổi-monitor.ipynb – Sổ ghi chép này là bước thứ ba trong quy trình làm việc của chúng tôi và sử dụng mô hình BERT cơ sở và chạy công việc chuyển đổi hàng loạt SageMaker, đồng thời thiết lập chất lượng dữ liệu bằng giám sát mô hình.
Tiếp theo, chúng ta đi qua sổ ghi chép chính nb-job-pipeline.ipynb, kết hợp tất cả các sổ ghi chép phụ vào một đường dẫn và chạy quy trình làm việc từ đầu đến cuối. Lưu ý rằng mặc dù ví dụ sau chỉ chạy sổ ghi chép một lần nhưng bạn cũng có thể lên lịch quy trình để chạy sổ ghi chép nhiều lần. tham khảo Tài liệu SageMaker để có hướng dẫn chi tiết.
Đối với bước công việc sổ ghi chép đầu tiên, chúng tôi chuyển vào một tham số có nhóm S3 mặc định. Chúng tôi có thể sử dụng nhóm này để kết xuất bất kỳ thành phần lạ nào mà chúng tôi muốn có sẵn cho các bước quy trình khác của mình. Đối với sổ ghi chép đầu tiên (preprocess.ipynb), chúng tôi lấy tập dữ liệu huấn luyện SST2 công khai của AWS xuống và tạo một tệp CSV đào tạo từ đó để đẩy vào bộ chứa S3 này. Xem đoạn mã sau:
Sau đó chúng ta có thể chuyển đổi sổ ghi chép này thành một NotebookJobStep với đoạn mã sau trong sổ ghi chép chính của chúng tôi:
Bây giờ chúng ta đã có tệp CSV mẫu, chúng ta có thể bắt đầu đào tạo mô hình của mình trong sổ tay đào tạo. Sổ tay đào tạo của chúng tôi có cùng tham số với nhóm S3 và kéo tập dữ liệu đào tạo từ vị trí đó xuống. Sau đó, chúng tôi thực hiện tinh chỉnh bằng cách sử dụng đối tượng Transformers trainer với đoạn mã sau:
Sau khi tinh chỉnh, chúng tôi muốn chạy một số suy luận hàng loạt để xem mô hình đang hoạt động như thế nào. Việc này được thực hiện bằng cách sử dụng một sổ ghi chép riêng (prepare-test-set.ipynb) trong cùng một đường dẫn cục bộ tạo tập dữ liệu thử nghiệm để thực hiện suy luận bằng cách sử dụng mô hình đã đào tạo của chúng tôi. Chúng ta có thể chạy sổ ghi chép bổ sung trong sổ ghi chép đào tạo của mình bằng ô ma thuật sau:
Chúng tôi xác định phần phụ thuộc sổ ghi chép bổ sung này trong AdditionalDependencies tham số trong bước công việc sổ ghi chép thứ hai của chúng tôi:
Chúng ta cũng phải xác định rằng bước công việc sổ ghi chép đào tạo (Bước 2) phụ thuộc vào bước công việc sổ ghi chép tiền xử lý (Bước 1) bằng cách sử dụng add_depends_on Lệnh gọi API như sau:
Bước cuối cùng của chúng tôi sẽ đưa mô hình BERT chạy Chuyển đổi hàng loạt SageMaker, đồng thời thiết lập Thu thập dữ liệu và chất lượng thông qua Trình giám sát mô hình SageMaker. Lưu ý rằng điều này khác với việc sử dụng tính năng tích hợp sẵn Chuyển đổi or Chụp các bước thông qua Pipelines. Sổ ghi chép của chúng tôi cho bước này sẽ thực thi các API tương tự nhưng sẽ được theo dõi dưới dạng Bước công việc sổ ghi chép. Bước này phụ thuộc vào Bước công việc đào tạo mà chúng tôi đã xác định trước đó, vì vậy, chúng tôi cũng nắm bắt bước đó bằng cờ phụ thuộc.
Sau khi xác định được các bước khác nhau trong quy trình làm việc, chúng ta có thể tạo và chạy quy trình từ đầu đến cuối:
Giám sát việc chạy đường ống
Bạn có thể theo dõi và giám sát bước chạy của sổ ghi chép thông qua SageMaker Pipelines DAG, như trong ảnh chụp màn hình sau.
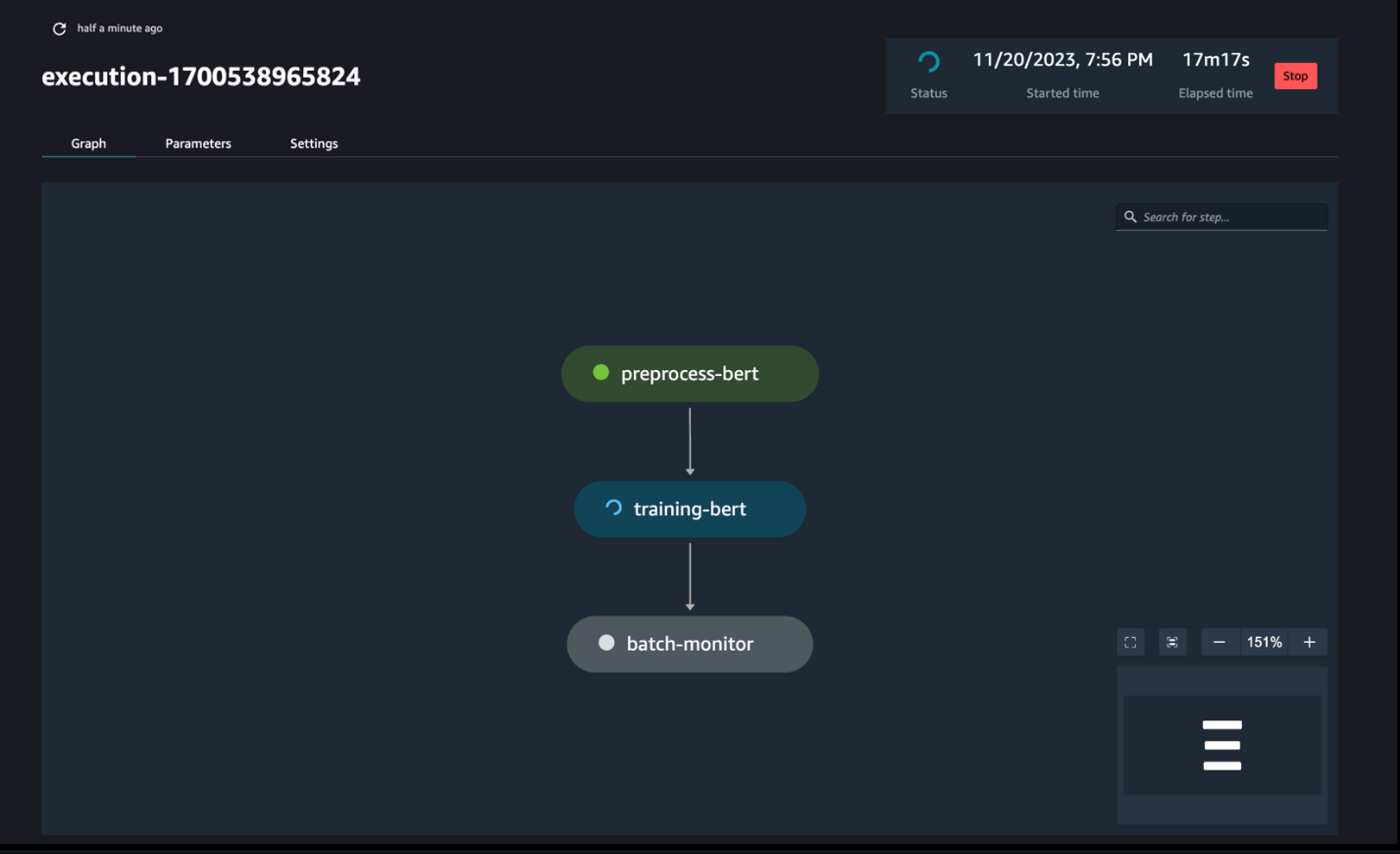
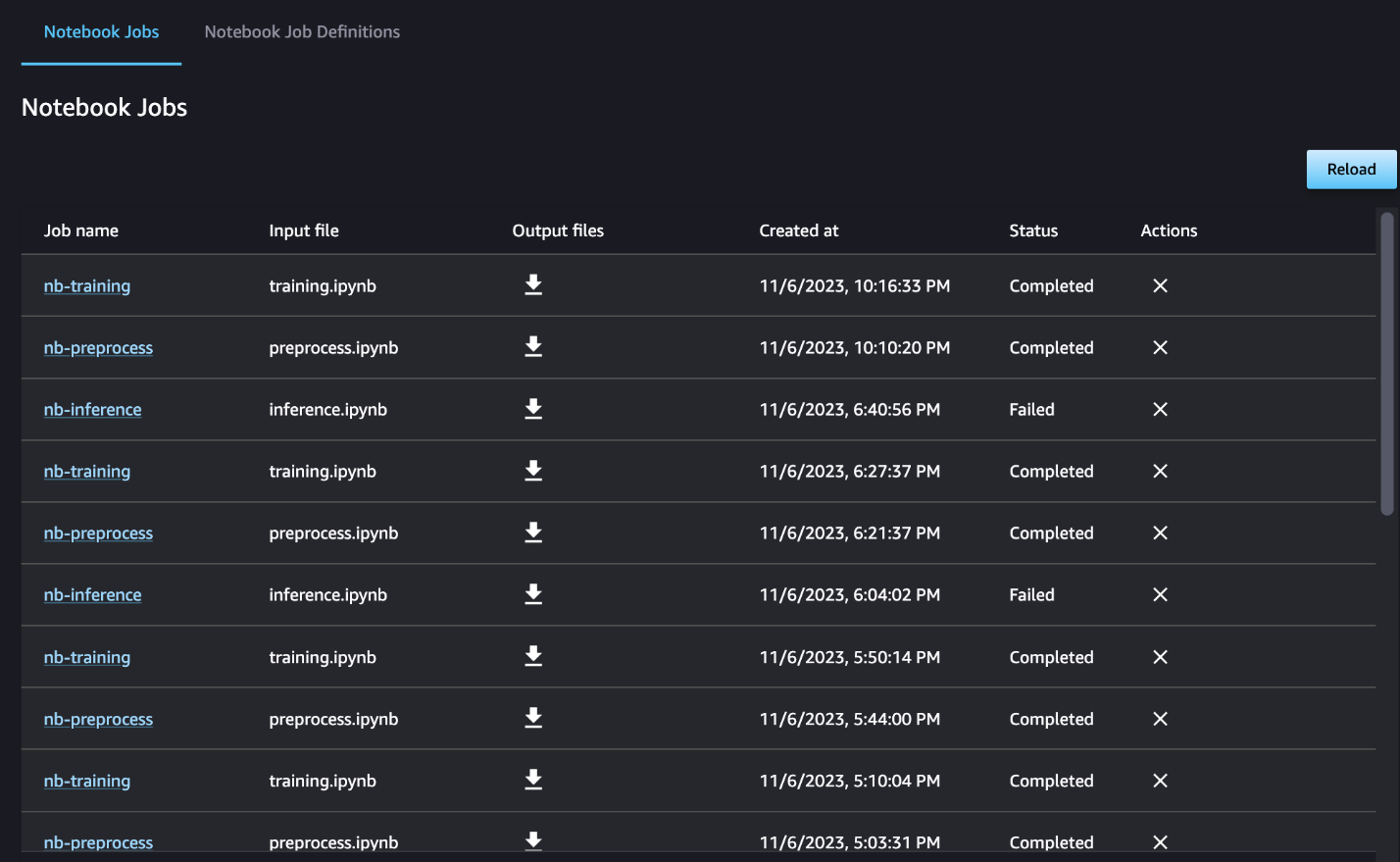
Bạn cũng có thể tùy ý giám sát quá trình chạy của sổ ghi chép riêng lẻ trên bảng thông tin công việc của sổ ghi chép và chuyển đổi các tệp đầu ra đã được tạo thông qua giao diện người dùng SageMaker Studio. Khi sử dụng chức năng này bên ngoài SageMaker Studio, bạn có thể xác định những người dùng có thể theo dõi trạng thái chạy trên bảng điều khiển công việc sổ ghi chép bằng cách sử dụng thẻ. Để biết thêm chi tiết về các thẻ cần đưa vào, hãy xem Xem công việc sổ ghi chép của bạn và tải xuống kết quả đầu ra trong bảng điều khiển UI Studio.
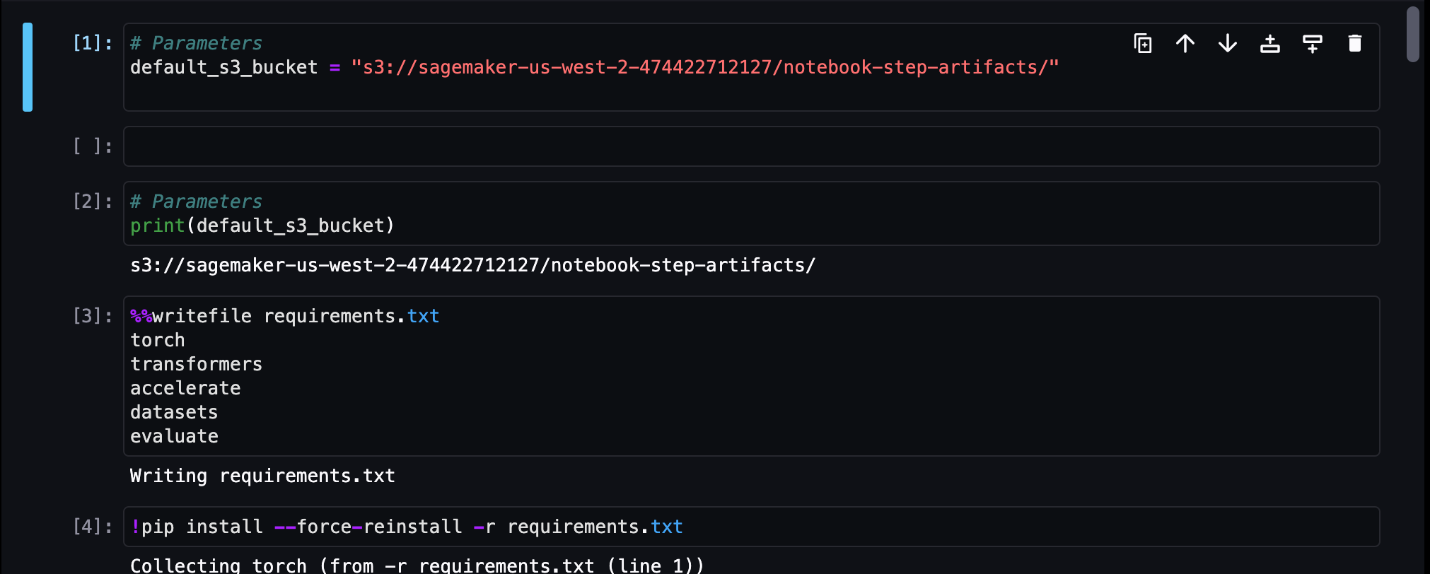
Trong ví dụ này, chúng tôi xuất kết quả công việc của sổ ghi chép vào một thư mục có tên outputs trong đường dẫn cục bộ của bạn bằng mã chạy đường dẫn của bạn. Như được hiển thị trong ảnh chụp màn hình sau, tại đây bạn có thể thấy đầu ra của sổ ghi chép đầu vào của mình cũng như bất kỳ tham số nào bạn đã xác định cho bước đó.
Làm sạch
Nếu bạn làm theo ví dụ của chúng tôi, hãy đảm bảo xóa quy trình đã tạo, công việc sổ ghi chép và dữ liệu s3 được sổ ghi chép mẫu tải xuống.
Những cân nhắc
Sau đây là một số cân nhắc quan trọng đối với tính năng này:
- Hạn chế SDK – Chỉ có thể tạo bước công việc sổ ghi chép thông qua SageMaker Python SDK.
- Hạn chế về hình ảnh –Bước công việc sổ ghi chép hỗ trợ các hình ảnh sau:
Kết luận
Với lần ra mắt này, nhân viên dữ liệu giờ đây có thể chạy sổ ghi chép của mình theo chương trình với một vài dòng mã bằng cách sử dụng SDK Python của SageMaker. Ngoài ra, bạn có thể tạo quy trình công việc gồm nhiều bước phức tạp bằng sổ ghi chép của mình, giảm đáng kể thời gian cần thiết để chuyển từ sổ ghi chép sang quy trình CI/CD. Sau khi tạo quy trình, bạn có thể sử dụng SageMaker Studio để xem và chạy DAG cho quy trình của mình cũng như quản lý và so sánh các lần chạy. Cho dù bạn đang lên lịch cho các quy trình công việc ML toàn diện hay một phần của quy trình đó, chúng tôi vẫn khuyến khích bạn thử quy trình làm việc dựa trên sổ tay.
Giới thiệu về tác giả
 Anchit Gupta là Giám đốc sản phẩm cấp cao của Amazon SageMaker Studio. Cô tập trung vào việc hỗ trợ các quy trình kỹ thuật dữ liệu và khoa học dữ liệu tương tác từ bên trong SageMaker Studio IDE. Trong thời gian rảnh rỗi, cô thích nấu ăn, chơi board/bài và đọc sách.
Anchit Gupta là Giám đốc sản phẩm cấp cao của Amazon SageMaker Studio. Cô tập trung vào việc hỗ trợ các quy trình kỹ thuật dữ liệu và khoa học dữ liệu tương tác từ bên trong SageMaker Studio IDE. Trong thời gian rảnh rỗi, cô thích nấu ăn, chơi board/bài và đọc sách.
 Ram Vegiraju là một Kiến trúc sư ML với nhóm Dịch vụ SageMaker. Anh ấy tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa các giải pháp AI / ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và viết lách.
Ram Vegiraju là một Kiến trúc sư ML với nhóm Dịch vụ SageMaker. Anh ấy tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa các giải pháp AI / ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và viết lách.
 Edward mặt trời là một SDE cấp cao làm việc cho SageMaker Studio tại Amazon Web Services. Anh ấy tập trung vào việc xây dựng giải pháp ML tương tác và đơn giản hóa trải nghiệm của khách hàng để tích hợp SageMaker Studio với các công nghệ phổ biến trong kỹ thuật dữ liệu và hệ sinh thái ML. Khi rảnh rỗi, Edward rất thích cắm trại, đi bộ đường dài và câu cá, đồng thời tận hưởng thời gian dành cho gia đình.
Edward mặt trời là một SDE cấp cao làm việc cho SageMaker Studio tại Amazon Web Services. Anh ấy tập trung vào việc xây dựng giải pháp ML tương tác và đơn giản hóa trải nghiệm của khách hàng để tích hợp SageMaker Studio với các công nghệ phổ biến trong kỹ thuật dữ liệu và hệ sinh thái ML. Khi rảnh rỗi, Edward rất thích cắm trại, đi bộ đường dài và câu cá, đồng thời tận hưởng thời gian dành cho gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- : có
- :là
- :Ở đâu
- $ LÊN
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Giới thiệu
- có thể truy cập
- xoay vòng
- thêm vào
- Ngoài ra
- Lợi thế
- Sau
- AI / ML
- Tất cả
- cho phép
- dọc theo
- Đã
- Ngoài ra
- Mặc dù
- đàn bà gan dạ
- Amazon EC2
- Amazon SageMaker
- Xưởng sản xuất Amazon SageMaker
- Amazon Web Services
- an
- phân tích
- phân tích
- và
- bất kì
- api
- API
- các ứng dụng
- kiến trúc
- LÀ
- AS
- At
- tự động hóa
- có sẵn
- AWS
- cơ sở
- dựa
- Baseline
- BE
- đẹp
- được
- sau
- được
- Hơn
- giữa
- lớn
- xây dựng
- Xây dựng
- được xây dựng trong
- nhưng
- by
- cuộc gọi
- gọi là
- cắm trại
- CAN
- nắm bắt
- trường hợp
- trường hợp
- pin
- nhân vật
- phân loại
- mã
- Cột
- Cột
- kết hợp
- Đến
- Chung
- so sánh
- hoàn thành
- phức tạp
- sáng tác
- Bao gồm
- Tính
- Tiến hành
- kết nối
- sự cân nhắc
- bao gồm
- Container
- chứa
- liên tục
- chuyển đổi
- chuyển đổi
- nấu ăn
- Tương ứng
- có thể
- tạo
- tạo ra
- tạo ra
- Tạo
- Hiện nay
- khách hàng
- khách hàng
- kinh nghiệm khach hang
- Hỗ trợ khách hàng
- khách hàng
- DAG
- bảng điều khiển
- dữ liệu
- giám sát dữ liệu
- Chuẩn bị dữ liệu
- xử lý dữ liệu
- chất lượng dữ liệu
- khoa học dữ liệu
- bộ dữ liệu
- Mặc định
- định nghĩa
- xác định
- giao hàng
- Nhu cầu
- phụ thuộc
- Phụ thuộc
- phụ thuộc
- phụ thuộc
- triển khai
- triển khai
- chi tiết
- chi tiết
- phát triển
- phát triển
- khác nhau
- trực tiếp
- đạo diễn
- Giám đốc
- khác biệt
- phu bến tàu
- làm
- thực hiện
- xuống
- tải về
- đổ
- mỗi
- dễ dàng
- hệ sinh thái
- Edward
- cho phép
- cho phép
- khuyến khích
- cuối
- Cuối cùng đến cuối
- Kỹ Sư
- Toàn bộ
- kỷ nguyên
- Ether (ETH)
- ví dụ
- thi hành
- thực hiện
- kinh nghiệm
- thêm
- trích xuất
- gia đình
- fan hâm mộ
- xa
- Đặc tính
- thông tin phản hồi
- vài
- Tập tin
- Các tập tin
- Phim ảnh
- nhà làm phim
- Tên
- Đánh bắt cá
- năm
- tập trung
- tập trung
- sau
- tiếp theo
- sau
- Trong
- hình thức
- định dạng
- từ
- đầy đủ
- chức năng
- Hơn nữa
- Trò chơi
- tạo ra
- đồ thị
- Có
- he
- giúp đỡ
- giúp đỡ
- cô
- tại đây
- đi bộ đường dài
- của mình
- Hollywood
- Độ đáng tin của
- HTML
- http
- HTTPS
- Nhân loại
- if
- minh họa
- hình ảnh
- hình ảnh
- ngay
- nhập khẩu
- quan trọng
- in
- bao gồm
- độc lập
- chỉ
- hệ thống riêng biệt,
- đầu vào
- ví dụ
- hướng dẫn
- tích hợp
- hội nhập
- tương tác
- trong
- IT
- ITS
- Việc làm
- việc làm
- jpg
- chỉ
- nhãn
- Nhãn
- Họ
- phóng
- học tập
- thư viện
- Dòng
- dòng
- tải
- địa phương
- địa điểm thư viện nào
- dài
- yêu
- máy
- học máy
- ma thuật
- Chủ yếu
- LÀM CHO
- quản lý
- quản lý
- quản lý
- giám đốc
- Phương tiện truyền thông
- Merit
- Might
- ML
- kiểu mẫu
- mô hình
- sửa đổi
- Modules
- Màn Hình
- giám sát
- màn hình
- chi tiết
- hầu hết
- di chuyển
- phim
- nhiều
- phải
- tên
- tự nhiên
- Cần
- cần thiết
- tiêu cực
- Mới
- Không
- ghi
- máy tính xách tay
- máy tính xách tay
- tại
- vật
- of
- thường
- on
- ONE
- có thể
- Tối ưu hóa
- or
- dàn nhạc
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- đầu ra
- kết quả đầu ra
- bên ngoài
- cặp
- tham số
- thông số
- một phần
- vượt qua
- Đi qua
- con đường
- thực hiện
- biểu diễn
- riêng
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chơi
- Phổ biến
- tích cực
- Bài đăng
- dự đoán
- chuẩn bị
- Chuẩn bị
- Chuẩn bị
- chuẩn bị
- trước
- trước đây
- Vấn đề
- xử lý
- Sản phẩm
- giám đốc sản xuất
- cho
- cung cấp
- cung cấp
- công khai
- Kéo
- mục đích
- Đẩy
- đẩy
- Python
- chất lượng
- nhanh hơn
- R
- hơn
- Đọc
- Reading
- định kỳ
- giảm
- Cấu trúc lại
- xem
- đăng ký
- thường xuyên
- vẫn
- NHIỀU LẦN
- yêu cầu
- kết quả
- xem xét
- Đánh giá
- chạy
- chạy
- chạy
- nhà làm hiền triết
- Đường ống SageMaker
- tương tự
- hài lòng
- lịch trình
- lên kế hoạch
- công việc theo lịch trình
- lập kế hoạch
- Khoa học
- các nhà khoa học
- sdk
- Thứ hai
- Phần
- phần
- xem
- đã xem
- cao cấp
- tình cảm
- riêng biệt
- dịch vụ
- DỊCH VỤ
- Phiên
- định
- thiết lập
- một số
- hình
- chị ấy
- nên
- hiển thị
- giới thiệu
- thể hiện
- Chương trình
- có ý nghĩa
- đáng kể
- tương tự
- Đơn giản
- đơn giản hóa
- duy nhất
- nhỏ
- nhỏ hơn
- đoạn
- So
- Mạng xã hội
- truyền thông xã hội
- giải pháp
- Giải pháp
- động SOLVE
- một số
- một cái gì đó
- Không gian
- riêng
- Chi
- độc lập
- stanford
- Bắt đầu
- Trạng thái
- Bước
- Các bước
- Vẫn còn
- là gắn
- đơn giản
- phòng thu
- như vậy
- mặt trời
- hỗ trợ
- Hỗ trợ
- Hỗ trợ
- chắc chắn
- Hãy
- mất
- Nhiệm vụ
- nhiệm vụ
- nhóm
- Công nghệ
- thử nghiệm
- văn bản
- Phân loại văn bản
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Kia là
- Thứ ba
- điều này
- những
- số ba
- Thông qua
- thời gian
- đến
- bên nhau
- quá
- công cụ
- Tổng số:
- theo dõi
- Train
- đào tạo
- Hội thảo
- Chuyển đổi
- máy biến áp
- Đi du lịch
- kích hoạt
- XOAY
- hai
- kiểu
- ui
- hiểu
- Cập nhật
- us
- sử dụng
- ca sử dụng
- đã sử dụng
- Người sử dụng
- sử dụng
- sử dụng
- Bằng cách sử dụng
- Các giá trị
- khác nhau
- thông qua
- Xem
- hình dung
- đi bộ
- muốn
- we
- web
- các dịch vụ web
- khi nào
- liệu
- cái nào
- trong khi
- CHÚNG TÔI LÀ
- sẽ
- với
- ở trong
- không có
- công nhân
- quy trình làm việc
- Luồng công việc
- đang làm việc
- tệ nhất
- viết
- bạn
- trên màn hình
- zephyrnet