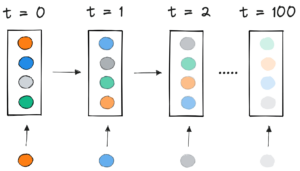
Giới thiệu BERT đóng gói để tăng gấp đôi tốc độ đào tạo trong xử lý ngôn ngữ tự nhiên
Kiểm tra thuật toán đóng gói BERT mới này để đào tạo hiệu quả hơn.
By Tiến sĩ Mario Michael Krell, Trưởng nhóm Học máy chính tại Graphcore & Matej Kosec, Chuyên gia ứng dụng AI tại Graphcore

Hình ảnh của tác giả.
Bằng cách sử dụng thuật toán đóng gói mới, chúng tôi đã tăng tốc Xử lý ngôn ngữ tự nhiên hơn 2 lần trong khi đào tạo BERT-Large. Kỹ thuật đóng gói mới của chúng tôi loại bỏ phần đệm, cho phép tính toán hiệu quả hơn đáng kể.
Chúng tôi nghi ngờ điều này cũng có thể được áp dụng cho các mô hình gấp khúc gen và protein và các mô hình khác có phân bố độ dài lệch để tạo ra tác động rộng hơn nhiều trong các ngành và ứng dụng khác nhau.
Chúng tôi đã giới thiệu thuật toán đóng gói biểu đồ bình phương tối thiểu không tiêu cực hiệu quả cao của Graphcore (hoặc NNLSHP) cũng như thuật toán BERT của chúng tôi được áp dụng cho các chuỗi được đóng gói trong một bài báo mới [1].
Lãng phí tính toán trong NLP do đệm trình tự
Chúng tôi đã bắt đầu nghiên cứu các cách mới để tối ưu hóa đào tạo BERT trong khi làm việc với đệ trình điểm chuẩn cho MLPerf ™. Mục tiêu là phát triển các tính năng tối ưu hữu ích có thể dễ dàng áp dụng trong các ứng dụng trong thế giới thực. BERT là một sự lựa chọn tự nhiên như là một trong những mô hình cần tập trung cho những tối ưu hóa này, vì nó được sử dụng rộng rãi trong ngành công nghiệp và bởi nhiều khách hàng của chúng tôi.
Chúng tôi thực sự ngạc nhiên khi biết rằng trong ứng dụng đào tạo BERT-Large của chính chúng tôi bằng cách sử dụng tập dữ liệu Wikipedia, 50% mã thông báo trong tập dữ liệu là đệm - dẫn đến việc tính toán lãng phí rất nhiều.
Các trình tự đệm để sắp xếp tất cả chúng có độ dài bằng nhau là một cách tiếp cận phổ biến được sử dụng với GPU, nhưng chúng tôi nghĩ rằng nên thử một cách tiếp cận khác.
Các chuỗi có sự thay đổi lớn về độ dài vì hai lý do:
- Dữ liệu cơ bản của Wikipedia cho thấy sự thay đổi lớn về độ dài tài liệu
- Bản thân việc xử lý trước BERT làm giảm ngẫu nhiên kích thước của các tài liệu được trích xuất được kết hợp để tạo ra một chuỗi huấn luyện
Việc lấp đầy độ dài đến độ dài tối đa là 512 dẫn đến 50% tất cả các mã thông báo là mã thông báo đệm. Việc thay thế 50% khoảng đệm bằng dữ liệu thực có thể dẫn đến việc xử lý thêm 50% dữ liệu với cùng một nỗ lực tính toán và do đó tăng tốc gấp 2 lần trong điều kiện tối ưu.

Hình 1: Các phân phối tập dữ liệu Wikipedia. Hình ảnh của tác giả.
Điều này có dành riêng cho Wikipedia không? Không.
Vậy thì nó có dành riêng cho ngôn ngữ không? Không.
Trên thực tế, sự phân bố độ dài lệch được tìm thấy ở khắp mọi nơi: trong ngôn ngữ, hệ gen và sự gấp khúc của protein. Hình 2 và 3 cho thấy các phân phối cho tập dữ liệu SQuAD 1.1 và tập dữ liệu GLUE.

Hình 2: Biểu đồ độ dài trình tự tập dữ liệu trước BERT của SQuAD 1.1 cho độ dài trình tự tối đa là 384. Hình ảnh của tác giả.

Hình 3: Biểu đồ độ dài chuỗi tập dữ liệu GLUE cho độ dài chuỗi tối đa là 128. Hình ảnh của tác giả.
Làm thế nào chúng ta có thể xử lý các độ dài khác nhau trong khi tránh lãng phí tính toán?
Các cách tiếp cận hiện tại yêu cầu các hạt nhân tính toán khác nhau với các độ dài khác nhau hoặc để kỹ sư loại bỏ phần đệm theo chương trình và sau đó thêm lại nó nhiều lần cho mỗi khối chú ý và tính toán tổn thất. Việc tiết kiệm máy tính bằng cách làm cho mã phức tạp hơn không hấp dẫn, vì vậy chúng tôi đã tìm kiếm thứ gì đó tốt hơn. Chúng ta không thể chỉ đặt nhiều chuỗi lại với nhau trong một gói có độ dài tối đa và xử lý tất cả cùng nhau? Hóa ra, chúng ta có thể!
Cách tiếp cận này yêu cầu ba thành phần chính:
- Một thuật toán hiệu quả để quyết định những mẫu nào nên ghép lại với nhau để có ít phần đệm còn lại nhất có thể
- Điều chỉnh mô hình BERT để xử lý các gói thay vì các chuỗi
- Và điều chỉnh các siêu tham số
Đóng gói sản phẩm
Lúc đầu, có vẻ như bạn sẽ không thể đóng gói một tập dữ liệu lớn như Wikipedia một cách hiệu quả. Sự cố này thường được gọi là đóng gói thùng rác. Ngay cả khi đóng gói được giới hạn trong ba trình tự hoặc ít hơn, vấn đề dẫn đến vẫn là NP-đầy đủ, thiếu một giải pháp thuật toán hiệu quả. Các thuật toán đóng gói heuristics hiện tại không có triển vọng vì chúng có độ phức tạp ít nhất là O(n nhật ký(n)), ở đâu n là số chuỗi (~ 16M đối với Wikipedia). Chúng tôi quan tâm đến các phương pháp tiếp cận có thể mở rộng quy mô tốt đến hàng triệu chuỗi.
Hai thủ thuật đã giúp chúng tôi giảm thiểu sự phức tạp một cách đáng kể:
- Giới hạn số chuỗi trong một gói ở mức ba (đối với phương pháp giải pháp đầu tiên của chúng tôi)
- Chỉ hoạt động trên biểu đồ độ dài trình tự với một ngăn cho mỗi độ dài xảy ra
Độ dài trình tự tối đa của chúng tôi là 512. Vì vậy, việc chuyển sang biểu đồ đã làm giảm kích thước và độ phức tạp từ 16 triệu trình tự xuống còn 512 lần đếm độ dài. Việc cho phép tối đa ba chuỗi trong một gói làm giảm số lượng kết hợp độ dài cho phép xuống 22K. Điều này đã bao gồm thủ thuật yêu cầu các trình tự được sắp xếp theo độ dài trong gói. Vậy tại sao không thử 4 chuỗi? Điều này làm tăng số lượng kết hợp từ 22K lên 940K, quá nhiều so với cách tiếp cận mô hình đầu tiên của chúng tôi. Ngoài ra, độ sâu 3 đã đạt được hiệu quả đóng gói cao đáng kể.
Ban đầu, chúng tôi nghĩ rằng việc sử dụng nhiều hơn ba chuỗi trong một gói sẽ làm tăng chi phí tính toán và tác động đến hành vi hội tụ trong quá trình đào tạo. Tuy nhiên, để hỗ trợ các ứng dụng như suy luận, đòi hỏi đóng gói theo thời gian thực, nhanh hơn, chúng tôi đã phát triển thuật toán Đóng gói biểu đồ bình phương tối thiểu không âm (NNLSHP) hiệu quả cao.
Đóng gói biểu đồ bình phương tối thiểu không âm (NNLSHP)
Việc đóng gói thùng thường được xây dựng như một bài toán tối ưu hóa toán học. Tuy nhiên, với 16 triệu chuỗi (hoặc nhiều hơn) thì điều này không thực tế. Chỉ riêng các biến sự cố sẽ vượt quá bộ nhớ của hầu hết các máy. Chương trình toán học cho cách tiếp cận dựa trên biểu đồ khá gọn gàng. Để đơn giản, chúng tôi quyết định phương pháp tiếp cận bình phương nhỏ nhất (Ax = b) với vectơ biểu đồ b. Chúng tôi đã mở rộng nó bằng cách yêu cầu vectơ chiến lược x không âm và thêm trọng lượng để cho phép đệm nhỏ.
Phần khó khăn là ma trận chiến lược. Mỗi cột có tổng tối đa là ba và mã hóa chuỗi nào được đóng gói lại với nhau để khớp chính xác với tổng chiều dài mong muốn; 512 trong trường hợp của chúng tôi. Các hàng mã hóa từng kết hợp tiềm năng để đạt được độ dài bằng tổng độ dài. Vectơ chiến lược x là những gì chúng tôi đang tìm kiếm, mô tả tần suất chúng tôi chọn bất kỳ kết hợp nào trong số 20k kết hợp. Điều thú vị là cuối cùng chỉ có khoảng 600 tổ hợp được chọn. Để có được một giải pháp chính xác, chiến lược được tính vào x sẽ phải là số nguyên dương, nhưng chúng tôi nhận ra rằng một giải pháp làm tròn gần đúng với chỉ không âm x là đủ. Đối với một giải pháp gần đúng, một bộ giải đơn giản có thể được sử dụng để nhận được kết quả trong vòng 30 giây.

Hình 4: Ví dụ về ma trận chiến lược cho độ dài chuỗi 8 và độ sâu đóng gói 3. Các hàng tượng trưng cho các chuỗi có độ dài 1–8 được đóng gói với nhau và các cột tượng trưng cho tất cả các kết hợp độ dài có thể trong một gói không có thứ tự cụ thể. Hình ảnh của tác giả.
Cuối cùng, chúng tôi phải sửa một số mẫu không được chỉ định chiến lược nhưng những mẫu đó ở mức tối thiểu. Chúng tôi cũng đã phát triển một trình giải biến thể thực thi rằng mỗi trình tự được đóng gói, có khả năng có phần đệm và có trọng số phụ thuộc vào phần đệm. Nó mất nhiều thời gian hơn, và giải pháp không tốt hơn.
Đóng gói biểu đồ ngắn nhất-gói đầu tiên
NNLSHP đã cung cấp phương pháp đóng gói phù hợp cho chúng tôi. Tuy nhiên, chúng tôi đã tự hỏi liệu về mặt lý thuyết, liệu chúng tôi có thể có được một cách tiếp cận có khả năng trực tuyến nhanh hơn và loại bỏ giới hạn của việc chỉ đặt 3 chuỗi lại với nhau hay không.
Do đó, chúng tôi đã lấy một số cảm hứng từ các thuật toán đóng gói hiện có nhưng vẫn tập trung vào biểu đồ.
Có bốn thành phần cho thuật toán đầu tiên của chúng tôi, Đóng gói biểu đồ ngắn nhất-gói-đầu tiên (SPFHP):
- Hoạt động trên số lượng của biểu đồ từ chuỗi dài nhất đến ngắn nhất
- Nếu độ dài trình tự hiện tại không vừa với bất kỳ gói nào, hãy bắt đầu một nhóm gói mới
- Nếu có nhiều khớp, hãy lấy gói trong đó tổng độ dài chuỗi là ngắn nhất và sửa đổi số lượng tương ứng
- Kiểm tra lại xem có phù hợp với các số đếm còn lại không
Phương pháp này dễ thực hiện nhất và chỉ mất 0.02 giây.
Một biến thể là lấy tổng chiều dài chuỗi lớn nhất thay vì tổng số lượng ngắn nhất và số tách để có được sự phù hợp hoàn hảo hơn. Nhìn chung, điều này không làm thay đổi hiệu quả nhiều nhưng làm tăng độ phức tạp của mã lên rất nhiều.
Cách đóng gói biểu đồ gói đầu tiên ngắn nhất hoạt động. Hoạt hình của tác giả.
Wikipedia, SQuAD 1.1, kết quả đóng gói GLUE
Bảng 1, 2 và 3 cho thấy kết quả đóng gói của hai thuật toán được đề xuất của chúng tôi. Độ sâu đóng gói mô tả số lượng trình tự được đóng gói tối đa. Độ sâu đóng gói 1 là quá trình thực hiện BERT đường cơ sở. Chiều sâu đóng gói tối đa xảy ra, không đặt giới hạn được biểu thị bằng một chữ “max” bổ sung. Các số lượng gói mô tả độ dài của tập dữ liệu mới được đóng gói. Hiệu quả là phần trăm mã thông báo thực trong tập dữ liệu được đóng gói. Các yếu tố đóng gói mô tả tốc độ tiềm năng kết quả so với độ sâu đóng gói 1.
Chúng tôi có bốn quan sát chính:
- Phân phối càng lệch thì lợi ích của việc đóng gói càng cao.
- Tất cả các bộ dữ liệu được hưởng lợi từ việc đóng gói. Một số thậm chí nhiều hơn hệ số 2.
- SPFHP trở nên hiệu quả hơn khi độ sâu đóng gói không bị giới hạn.
- Đối với số lượng tối đa 3 trình tự được đóng gói, NNLSHP càng phức tạp thì hiệu quả càng cao (99.75 so với 89.44).

Bảng 1: Kết quả hoạt động chính của các thuật toán đóng gói được đề xuất (SPFHP và NNLSHP) trên Wikipedia. Hình ảnh của tác giả.

Bảng 2: Kết quả hoạt động của các thuật toán đóng gói được đề xuất cho đào tạo trước SQUaD 1.1 BERT. Hình ảnh của tác giả.

Bảng 3: Kết quả hoạt động của các thuật toán đóng gói được đề xuất cho tập dữ liệu GLUE. Chỉ đường cơ sở và kết quả đóng gói SPFHP mà không giới hạn độ sâu đóng gói được hiển thị. Hình ảnh của tác giả.
Điều chỉnh xử lý BERT
Một điều thú vị về kiến trúc BERT là hầu hết quá trình xử lý diễn ra ở cấp độ mã thông báo, có nghĩa là nó không can thiệp vào việc đóng gói của chúng tôi. Chỉ có bốn thành phần cần điều chỉnh: mặt nạ chú ý, tổn thất MLM, mất NSP và độ chính xác.
Chìa khóa cho tất cả bốn cách tiếp cận để xử lý số lượng trình tự khác nhau là vector hóa và sử dụng số lượng trình tự tối đa có thể được nối với nhau. Đối với sự chú ý, chúng tôi đã có một mặt nạ để giải quyết phần đệm. Việc mở rộng điều này thành nhiều chuỗi rất đơn giản như có thể thấy trong mã giả TensorFlow sau đây. Khái niệm này là chúng tôi đảm bảo rằng sự chú ý được giới hạn trong các chuỗi riêng biệt và không thể mở rộng ra ngoài phạm vi đó.
Mẫu mã mặt nạ chú ý.

Hình 5: Ví dụ về mặt nạ không-một
Đối với tính toán tổn thất, về nguyên tắc, chúng tôi giải nén các chuỗi và tính toán các tổn thất riêng biệt, cuối cùng thu được giá trị trung bình của tổn thất qua các chuỗi (thay vì gói).
Đối với mất mát MLM, mã có dạng như sau:
Mẫu mã tính toán tổn thất.
Đối với việc mất NSP và độ chính xác, nguyên tắc là như nhau. Trong các ví dụ công khai của chúng tôi, bạn có thể tìm thấy mã tương ứng với nội bộ của chúng tôi Khung PopART.
Ước tính tổng chi phí và tốc độ trên Wikipedia
Với việc sửa đổi BERT của chúng tôi, chúng tôi có hai câu hỏi:
- Nó mang theo bao nhiêu chi phí?
- Chi phí phụ thuộc vào số lượng tối đa các trình tự được ghép lại với nhau trong một gói là bao nhiêu?
Vì việc chuẩn bị dữ liệu trong BERT có thể phức tạp, chúng tôi đã sử dụng một phím tắt và biên dịch mã cho nhiều độ sâu đóng gói khác nhau và so sánh các chu kỳ tương ứng (được đo). Kết quả được hiển thị trong Bảng 4. Với trên không, chúng tôi biểu thị phần trăm giảm thông lượng do các thay đổi đối với mô hình để cho phép đóng gói (chẳng hạn như sơ đồ che để chú ý và tính toán tổn thất đã thay đổi). Các tăng tốc độ nhận ra là sự kết hợp của tốc độ tăng do đóng gói ( yếu tố đóng gói) và giảm thông lượng do trên không.

Bảng 4: So sánh tốc độ ước tính của các thuật toán đóng gói được đề xuất (SPFHP và NNLSHP) trên Wikipedia. Hình ảnh của tác giả.
Nhờ kỹ thuật vectơ hóa, chi phí nhỏ đáng kinh ngạc và không có bất lợi khi đóng gói nhiều chuỗi lại với nhau.
Điều chỉnh siêu tham số
Với việc đóng gói, chúng tôi đang tăng gấp đôi kích thước lô hiệu quả (trung bình). Điều này có nghĩa là chúng ta cần điều chỉnh các siêu tham số đào tạo. Một mẹo đơn giản là giảm số lượng tích lũy gradient đi một nửa để giữ nguyên kích thước lô trung bình hiệu quả như trước khi đào tạo. Bằng cách sử dụng cài đặt điểm chuẩn với các điểm kiểm tra được đào tạo trước, chúng ta có thể thấy rằng độ chính xác của các đường cong hoàn toàn khớp.

Hình 6: So sánh các đường cong học tập cho quá trình đóng gói và giải nén với giảm kích thước lô cho cách tiếp cận đóng gói. Hình ảnh của tác giả.
Độ chính xác phù hợp: sự mất mát trong đào tạo MLM có thể hơi khác lúc đầu nhưng nhanh chóng bắt kịp. Sự khác biệt ban đầu này có thể đến từ những điều chỉnh nhỏ của các lớp chú ý có thể thiên về các chuỗi ngắn trong bài huấn luyện trước.
Để tránh bị chậm lại, đôi khi có thể giữ nguyên kích thước lô ban đầu và điều chỉnh siêu tham số để tăng kích thước lô hiệu quả (tăng gấp đôi). Các siêu tham số chính cần xem xét là các tham số beta và tỷ lệ học tập. Một cách tiếp cận phổ biến là tăng gấp đôi kích thước lô, điều này làm giảm hiệu suất trong trường hợp của chúng tôi. Nhìn vào số liệu thống kê của trình tối ưu hóa LAMB, chúng tôi có thể chứng minh rằng việc tăng thông số beta lên sức mạnh của hệ số đóng gói tương ứng với việc đào tạo nhiều lô liên tục để giữ cho động lượng và vận tốc có thể so sánh được.

Hình 7: So sánh các đường cong học tập cho quá trình đóng gói và giải nén với heuristic đã áp dụng. Hình ảnh của tác giả.
Các thí nghiệm của chúng tôi cho thấy rằng lấy beta theo lũy thừa của hai là một phương pháp phỏng đoán tốt. Trong trường hợp này, các đường cong dự kiến sẽ không khớp vì việc tăng kích thước lô thường làm giảm tốc độ hội tụ theo nghĩa của mẫu / kỷ nguyên cho đến khi đạt được độ chính xác mục tiêu.
Bây giờ, câu hỏi đặt ra là nếu trong kịch bản thực tế, chúng ta có thực sự đạt được tốc độ như mong đợi hay không?

Hình 8: So sánh các đường cong học tập cho quá trình đóng gói và giải nén trong thiết lập tối ưu hóa. Hình ảnh của tác giả.
Có, chúng tôi làm! Chúng tôi đã tăng thêm tốc độ vì chúng tôi đã nén quá trình truyền dữ liệu.
Kết luận
Đóng gói các câu lại với nhau có thể tiết kiệm công sức tính toán và môi trường. Kỹ thuật này có thể được thực hiện trong bất kỳ khuôn khổ nào bao gồm PyTorch và TensorFlow. Chúng tôi đã đạt được tốc độ tăng gấp 2 lần rõ ràng và trong quá trình này, chúng tôi đã mở rộng quy mô hiện đại trong các thuật toán đóng gói.
Các ứng dụng khác mà chúng tôi tò mò là hệ gen và nếp gấp protein, nơi có thể quan sát thấy sự phân bố dữ liệu tương tự. Máy biến áp thị giác cũng có thể là một lĩnh vực thú vị để áp dụng các hình ảnh đóng gói có kích thước khác nhau. Bạn nghĩ ứng dụng nào sẽ hoạt động tốt? Chúng tôi rất mong nhận được hồi âm từ bạn!
Cảm ơn bạn
Cảm ơn các đồng nghiệp của chúng tôi trong nhóm Kỹ thuật ứng dụng của Graphcore, Sheng Fu và Mrinal Iyer, vì những đóng góp của họ cho công việc này và cảm ơn Douglas Orr từ nhóm Nghiên cứu của Graphcore vì những phản hồi quý giá của anh ấy.
dự án
[1] M. Kosec, S. Fu, MM Krell, Đóng gói: Hướng tới Tăng tốc gấp 2 lần NLP BERT (2021), arXiv
Tiến sĩ Mario Michael Krell là Trưởng nhóm Học máy Chính tại Graphcore. Mario đã nghiên cứu và phát triển các thuật toán học máy trong hơn 12 năm, tạo ra phần mềm cho các ngành công nghiệp đa dạng như robot, ô tô, viễn thông và chăm sóc sức khỏe. Tại Graphcore, anh ấy đã đóng góp vào sự ấn tượng của chúng tôi Đệ trình MLPerf và có niềm đam mê tăng tốc các mô hình phi tiêu chuẩn mới như tính toán Bayes gần đúng để phân tích dữ liệu thống kê COVID-19.
Matej Kosec là Chuyên gia ứng dụng AI tại Graphcore ở Palo Alto. Trước đây anh ấy đã từng là Nhà khoa học AI về lái xe tự hành tại NIO ở San Jose và có Bằng Thạc sĩ về hàng không và du hành vũ trụ của Đại học Stanford.
Nguyên. Đăng lại với sự cho phép.
Liên quan:
- "
- &
- 2021
- 7
- thêm vào
- thuật hàng không
- AI
- thuật toán
- thuật toán
- Tất cả
- Cho phép
- phân tích
- hình ảnh động
- Các Ứng Dụng
- các ứng dụng
- kiến trúc
- KHU VỰC
- xung quanh
- Nghệ thuật
- tự động
- ô tô
- tự trị
- Baseline
- điểm chuẩn
- beta
- thay đổi
- mã
- Cột
- Chung
- Tính
- đóng góp
- Covid-19
- Tạo
- Current
- khách hàng
- dữ liệu
- phân tích dữ liệu
- khoa học dữ liệu
- học kĩ càng
- phát triển
- ĐÃ LÀM
- kích thước
- Giám đốc
- tài liệu
- lái xe
- Hiệu quả
- hiệu quả
- ky sư
- Kỹ Sư
- Môi trường
- Tên
- phù hợp với
- Sửa chữa
- Tập trung
- Khung
- genomics
- tốt
- GPU
- chăm sóc sức khỏe
- Cao
- Độ đáng tin của
- HTTPS
- hình ảnh
- Va chạm
- Bao gồm
- Tăng lên
- các ngành công nghiệp
- ngành công nghiệp
- Cảm hứng
- Phỏng vấn
- điều tra
- IT
- Việc làm
- Key
- kiến thức
- Ngôn ngữ
- lớn
- dẫn
- LEARN
- học tập
- Cấp
- Hạn chế
- yêu
- học máy
- Làm
- mặt nạ
- Trận đấu
- triệu
- ML
- kiểu mẫu
- Momentum
- Ngôn ngữ tự nhiên
- Xử lý ngôn ngữ tự nhiên
- Khéo léo
- Thần kinh
- nlp
- số
- Trực tuyến
- mở
- mã nguồn mở
- Nền tảng khác
- Giấy
- hiệu suất
- quyền lực
- Hiệu trưởng
- chương trình
- Protein
- công khai
- Python
- ngọn đuốc
- Giá
- thời gian thực
- lý do
- giảm
- hồi quy
- nghiên cứu
- Kết quả
- robotics
- San
- San Jose
- tiết kiệm
- Quy mô
- Khoa học
- các nhà khoa học
- Tìm kiếm
- chọn
- ý nghĩa
- định
- thiết lập
- ngắn
- Đơn giản
- Kích thước máy
- nhỏ
- So
- Phần mềm
- tốc độ
- chia
- stanford
- Đại học Stanford
- Bắt đầu
- Tiểu bang
- số liệu thống kê
- Những câu chuyện
- Chiến lược
- hỗ trợ
- Mục tiêu
- viễn thông
- tensorflow
- mã thông báo
- Tokens
- hàng đầu
- Hội thảo
- trường đại học
- us
- Thành phố Velo
- tầm nhìn
- Wikipedia
- ở trong
- Công việc
- công trinh
- giá trị
- X
- năm