Các tổ chức trong tất cả các ngành có các yêu cầu xử lý dữ liệu phức tạp cho các trường hợp sử dụng phân tích của họ trên các hệ thống phân tích khác nhau, chẳng hạn như kho dữ liệu trên AWS, Kho dữ liệu (Amazon RedShift), tìm kiếm (Dịch vụ Tìm kiếm Mở của Amazon), NoQuery (Máy phát điện Amazon), học máy (Amazon SageMaker), và hơn thế nữa. Các chuyên gia phân tích được giao nhiệm vụ lấy giá trị từ dữ liệu được lưu trữ trong các hệ thống phân tán này để tạo trải nghiệm tốt hơn, an toàn và tối ưu hóa chi phí cho khách hàng của họ. Ví dụ: các công ty truyền thông kỹ thuật số tìm cách kết hợp và xử lý bộ dữ liệu trong cơ sở dữ liệu bên trong và bên ngoài để xây dựng chế độ xem thống nhất về hồ sơ khách hàng của họ, thúc đẩy ý tưởng cho các tính năng đổi mới và tăng mức độ tương tác với nền tảng.
Trong những trường hợp này, khách hàng đang tìm kiếm dịch vụ tích hợp dữ liệu phi máy chủ sẽ sử dụng Keo AWS như một thành phần cốt lõi để xử lý và biên mục dữ liệu. AWS Glue được tích hợp tốt với các dịch vụ AWS và sản phẩm của đối tác, đồng thời cung cấp các tùy chọn trích xuất, chuyển đổi và tải (ETL) mã thấp/không mã để kích hoạt quy trình phân tích, máy học (ML) hoặc phát triển ứng dụng. Công việc AWS Glue ETL có thể là một thành phần trong quy trình phức tạp hơn. Phối hợp hoạt động và quản lý các quan hệ phụ thuộc giữa các thành phần này là khả năng chính trong chiến lược dữ liệu. Amazon Managed Workflows cho Apache Airflows (Amazon MWAA) điều phối các đường ống dẫn dữ liệu bằng cách sử dụng các công nghệ phân tán bao gồm tài nguyên tại chỗ, dịch vụ AWS và các thành phần của bên thứ ba.
Trong bài đăng này, chúng tôi trình bày cách đơn giản hóa việc theo dõi tác vụ AWS Glue do Airflow dàn xếp bằng cách sử dụng các tính năng mới nhất của Amazon MWAA.
Tổng quan về giải pháp
Bài đăng này thảo luận về những điều sau đây:
- Cách nâng cấp môi trường Amazon MWAA lên phiên bản 2.4.3.
- Cách sắp xếp công việc AWS Glue từ Airflow Đồ thị Acyclic có hướng (DAG).
- Các cải tiến về khả năng quan sát của gói nhà cung cấp Airflow Amazon trong Amazon MWAA. Giờ đây, bạn có thể hợp nhất nhật ký chạy của các tác vụ AWS Glue trên bảng điều khiển Airflow để đơn giản hóa quy trình xử lý sự cố dữ liệu. Bảng điều khiển Amazon MWAA trở thành một tham chiếu duy nhất để theo dõi và phân tích các lần chạy công việc AWS Glue. Trước đây, các nhóm hỗ trợ cần truy cập vào Bảng điều khiển quản lý AWS và thực hiện các bước thủ công cho khả năng hiển thị này. Tính năng này có sẵn theo mặc định từ Amazon MWAA phiên bản 2.4.3.
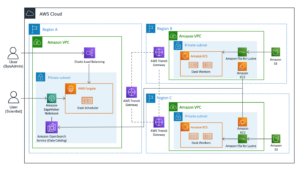
Sơ đồ sau minh họa kiến trúc giải pháp của chúng tôi.
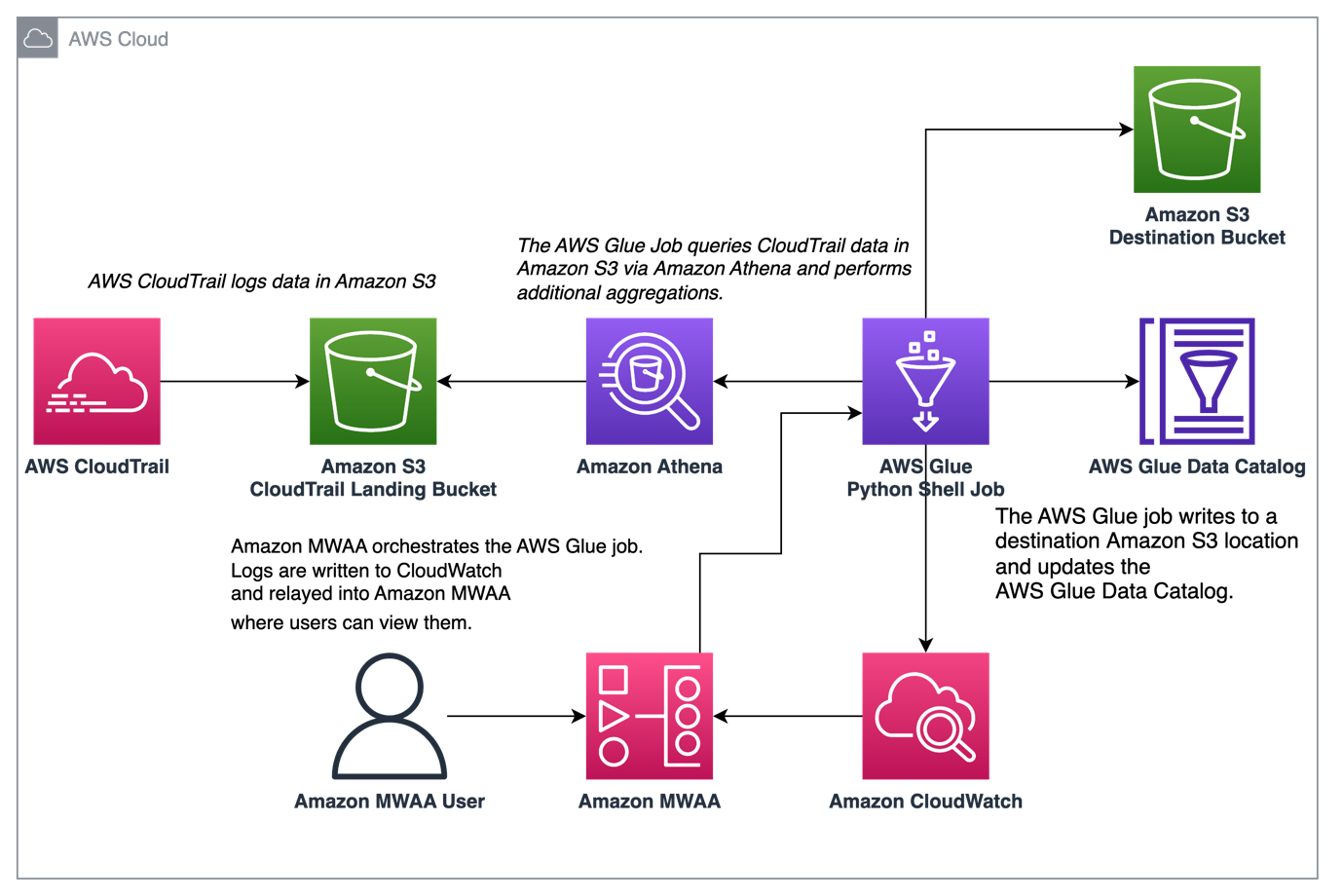
Điều kiện tiên quyết
Bạn cần các điều kiện tiên quyết sau:
Thiết lập môi trường Amazon MWAA
Để biết hướng dẫn về cách tạo môi trường của bạn, hãy tham khảo Tạo môi trường Amazon MWAA. Đối với những người dùng hiện tại, chúng tôi khuyên bạn nên nâng cấp lên phiên bản 2.4.3 để tận dụng các cải tiến về khả năng quan sát được nêu trong bài đăng này.
Các bước nâng cấp Amazon MWAA lên phiên bản 2.4.3 khác nhau tùy thuộc vào việc phiên bản hiện tại là 1.10.12 hay 2.2.2. Chúng tôi thảo luận về cả hai lựa chọn trong bài viết này.
Điều kiện tiên quyết để thiết lập môi trường Amazon MWAA
Bạn phải đáp ứng các điều kiện tiên quyết sau:
Nâng cấp từ phiên bản 1.10.12 lên 2.4.3
Nếu bạn đang sử dụng phiên bản Amazon MWAA 1.10.12, tham khảo Di chuyển sang môi trường Amazon MWAA mới để nâng cấp lên 2.4.3.
Nâng cấp từ phiên bản 2.0.2 hoặc 2.2.2 lên 2.4.3
Nếu bạn đang sử dụng môi trường Amazon MWAA phiên bản 2.2.2 trở xuống, hãy hoàn thành các bước sau:
- Tạo ra một tests.txt cho bất kỳ phụ thuộc tùy chỉnh nào với các phiên bản cụ thể cần thiết cho DAG của bạn.
- Tải tệp lên Amazon S3 ở vị trí thích hợp nơi môi trường Amazon MWAA trỏ đến tệp tests.txt để cài đặt phần phụ thuộc.
- Thực hiện theo các bước trong Di chuyển sang môi trường Amazon MWAA mới và chọn phiên bản 2.4.3.
Cập nhật DAG của bạn
Những khách hàng đã nâng cấp từ môi trường Amazon MWAA cũ hơn có thể cần cập nhật các DAG hiện có. Trong Airflow phiên bản 2.4.3, môi trường Airflow sẽ sử dụng gói nhà cung cấp Amazon phiên bản 6.0.0 theo mặc định. Gói này có thể bao gồm một số thay đổi có khả năng phá vỡ, chẳng hạn như thay đổi tên nhà điều hành. Ví dụ, các AWSGlueJobToán tử đã không được dùng nữa và được thay thế bằng KeoCông ViệcĐiều Hành. Để duy trì khả năng tương thích, hãy cập nhật DAG luồng không khí của bạn bằng cách thay thế bất kỳ nhà khai thác nào không được dùng nữa hoặc không được hỗ trợ từ các phiên bản trước bằng các nhà khai thác mới. Hoàn thành các bước sau:
- Hướng đến Nhà điều hành Amazon AWS.
- Chọn phiên bản thích hợp được cài đặt trong phiên bản Amazon MWAA của bạn (6.0.0. theo mặc định) để tìm danh sách các nhà khai thác Luồng không khí được hỗ trợ.
- Thực hiện các thay đổi cần thiết trong mã DAG hiện có và tải các tệp đã sửa đổi lên vị trí DAG trong Amazon S3.
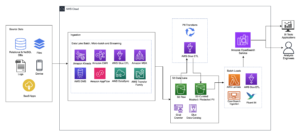
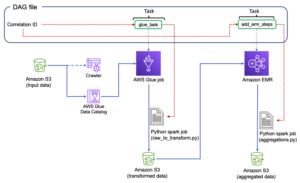
Điều phối công việc AWS Glue từ Airflow
Phần này trình bày chi tiết về cách sắp xếp tác vụ AWS Glue trong DAG luồng khí. Luồng không khí giúp giảm bớt sự phát triển của các đường ống dữ liệu có sự phụ thuộc giữa các hệ thống không đồng nhất, chẳng hạn như các quy trình tại chỗ, các phần phụ thuộc bên ngoài, các dịch vụ AWS khác, v.v.
Phối hợp tập hợp nhật ký CloudTrail với AWS Glue và Amazon MWAA
Trong ví dụ này, chúng ta xem xét một trường hợp sử dụng Amazon MWAA để sắp xếp một công việc AWS Glue Python Shell để duy trì các chỉ số tổng hợp dựa trên nhật ký CloudTrail.
CloudTrail cho phép hiển thị các lệnh gọi API AWS đang được thực hiện trong tài khoản AWS của bạn. Một trường hợp sử dụng phổ biến với dữ liệu này là thu thập số liệu sử dụng đối với các hiệu trưởng hoạt động trên tài nguyên tài khoản của bạn cho các nhu cầu kiểm toán và quy định.
Khi các sự kiện CloudTrail được ghi lại, chúng được phân phối dưới dạng tệp JSON trong Amazon S3, không lý tưởng cho các truy vấn phân tích. Chúng tôi muốn tổng hợp dữ liệu này và duy trì dữ liệu đó dưới dạng tệp Parquet để cho phép đạt được hiệu suất truy vấn tối ưu. Ở bước đầu tiên, chúng ta có thể sử dụng Athena để thực hiện truy vấn dữ liệu ban đầu trước khi thực hiện các tổng hợp bổ sung trong công việc AWS Glue của mình. Để biết thêm thông tin về cách tạo bảng AWS Glue Data Catalog, tham khảo Tạo bảng cho nhật ký CloudTrail trong Athena bằng phép chiếu phân vùng dữ liệu. Sau khi khám phá dữ liệu qua Athena và quyết định số liệu nào chúng tôi muốn giữ lại trong các bảng tổng hợp, chúng tôi có thể tạo một công việc AWS Glue.
Tạo bảng CloudTrail trong Athena
Trước tiên, chúng ta cần tạo một bảng trong Danh mục dữ liệu cho phép truy vấn dữ liệu CloudTrail qua Athena. Truy vấn mẫu sau đây tạo một bảng có hai phân vùng trên Vùng và ngày (được gọi là snapshot_date). Đảm bảo thay thế trình giữ chỗ cho bộ chứa CloudTrail, ID tài khoản AWS và tên bảng CloudTrail của bạn:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Chạy truy vấn trước đó trên bảng điều khiển Athena và ghi lại tên bảng cũng như cơ sở dữ liệu AWS Glue Data Catalog nơi nó được tạo. Chúng tôi sử dụng các giá trị này sau trong mã DAG luồng không khí.
Mã công việc AWS Glue mẫu
Đoạn mã sau đây là một mẫu Công việc AWS Glue Python Shell điều đó làm như sau:
- Lấy đối số (mà chúng tôi chuyển từ Amazon MWAA DAG) về dữ liệu của ngày nào cần xử lý
- Sử dụng SDK AWS dành cho gấu trúc chạy truy vấn Athena để thực hiện lọc ban đầu dữ liệu JSON của CloudTrail bên ngoài AWS Glue
- Sử dụng Pandas để thực hiện tổng hợp đơn giản trên dữ liệu đã lọc
- Xuất dữ liệu tổng hợp sang AWS Glue Data Catalog trong một bảng
- Sử dụng ghi nhật ký trong quá trình xử lý, sẽ hiển thị trong Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Sau đây là một số ưu điểm chính trong công việc AWS Glue này:
- Chúng tôi sử dụng truy vấn Athena để đảm bảo quá trình lọc ban đầu được thực hiện bên ngoài công việc AWS Glue của chúng tôi. Do đó, một tác vụ Python Shell với khả năng tính toán tối thiểu vẫn đủ để tổng hợp tập dữ liệu CloudTrail lớn.
- chúng tôi đảm bảo tùy chọn bộ thư viện phân tích được bật khi tạo công việc AWS Glue để sử dụng thư viện AWS SDK cho Pandas.
Tạo một công việc AWS Glue
Hoàn thành các bước sau để tạo tác vụ AWS Glue của bạn:
- Sao chép tập lệnh trong phần trước và lưu tập lệnh vào tệp cục bộ. Đối với bài đăng này, tệp được gọi là
script.py. - Trên bảng điều khiển AWS Glue, hãy chọn công việc ETL trong khung điều hướng.
- Tạo một công việc mới và chọn Trình chỉnh sửa tập lệnh Python Shell.
- Chọn Tải lên và chỉnh sửa tập lệnh hiện có và tải lên tệp bạn đã lưu cục bộ.
- Chọn Tạo.

- trên Chi tiết công việc tab, hãy nhập tên cho tác vụ AWS Glue của bạn.
- Trong Vai trò IAM, chọn một vai trò hiện có hoặc tạo một vai trò mới có các quyền cần thiết cho Amazon S3, AWS Glue và Athena. Vai trò cần truy vấn bảng CloudTrail mà bạn đã tạo trước đó và ghi vào một vị trí đầu ra.
Bạn có thể sử dụng mã chính sách mẫu sau đây. Thay thế trình giữ chỗ bằng bộ chứa nhật ký CloudTrail, tên bảng đầu ra, cơ sở dữ liệu AWS Glue đầu ra, bộ chứa S3 đầu ra, tên bảng CloudTrail, cơ sở dữ liệu AWS Glue chứa bảng CloudTrail và ID tài khoản AWS của bạn.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Trong Phiên bản Python, chọn Python 3.9.
- Chọn Tải các thư viện phân tích phổ biến.
- Trong Đơn vị xử lý dữ liệu, chọn 1 DPU.
- Để các tùy chọn khác như mặc định hoặc điều chỉnh nếu cần.

- Chọn Lưu để lưu cấu hình công việc của bạn.
Định cấu hình Amazon MWAA DAG để sắp xếp công việc AWS Glue
Đoạn mã sau dành cho một DAG có thể điều phối công việc AWS Glue mà chúng tôi đã tạo. Chúng tôi tận dụng các tính năng chính sau trong DAG này:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Tăng khả năng quan sát các công việc AWS Glue trong Amazon MWAA
Công việc AWS Glue ghi nhật ký vào amazoncloudwatch. Với những cải tiến gần đây về khả năng quan sát đối với gói nhà cung cấp Amazon của Airflow, các nhật ký này hiện được tích hợp với nhật ký tác vụ của Airflow. Việc hợp nhất này cung cấp cho người dùng Airflow khả năng hiển thị từ đầu đến cuối trực tiếp trong giao diện người dùng Airflow, loại bỏ nhu cầu tìm kiếm trong CloudWatch hoặc bảng điều khiển AWS Glue.
Để sử dụng tính năng này, hãy đảm bảo vai trò IAM được gắn với môi trường Amazon MWAA có các quyền sau để truy xuất và ghi nhật ký cần thiết:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Nếu verbose=true, thì nhật ký chạy công việc AWS Glue sẽ hiển thị trong nhật ký tác vụ Luồng khí. Mặc định này sai. Để biết thêm thông tin, hãy tham khảo Thông số.
Khi được bật, các DAG đọc từ luồng nhật ký CloudWatch của công việc AWS Glue và chuyển tiếp chúng tới các nhật ký bước công việc DAG AWS Glue của Airflow. Điều này cung cấp thông tin chuyên sâu chi tiết về quá trình chạy của tác vụ AWS Glue trong thời gian thực thông qua nhật ký DAG. Lưu ý rằng các công việc AWS Glue tạo ra một nhóm nhật ký CloudWatch đầu ra và lỗi dựa trên STDOUT và STDERR của công việc tương ứng. Tất cả nhật ký trong nhóm nhật ký đầu ra và nhật ký ngoại lệ hoặc lỗi từ nhóm nhật ký lỗi đều được chuyển tiếp vào Amazon MWAA.
Giờ đây, quản trị viên AWS có thể giới hạn quyền truy cập của nhóm hỗ trợ chỉ với Airflow, giúp Amazon MWAA trở thành tấm kính duy nhất trong việc điều phối công việc và quản lý tình trạng công việc. Trước đây, người dùng cần kiểm tra trạng thái chạy công việc AWS Glue trong các bước DAG của Airflow và truy xuất mã định danh chạy công việc. Sau đó, họ cần truy cập bảng điều khiển AWS Glue để tìm lịch sử chạy công việc, tìm kiếm công việc quan tâm bằng mã định danh và cuối cùng điều hướng đến nhật ký CloudWatch của công việc để khắc phục sự cố.
Tạo DAG
Để tạo DAG, hãy hoàn thành các bước sau:
- Lưu mã DAG trước đó vào tệp .py cục bộ, thay thế các trình giữ chỗ được chỉ định.
Các giá trị cho ID tài khoản AWS của bạn, tên công việc AWS Glue, cơ sở dữ liệu AWS Glue với bảng CloudTrail và tên bảng CloudTrail đã được biết đến. Bạn có thể điều chỉnh bộ chứa S3 đầu ra, cơ sở dữ liệu AWS Glue đầu ra và tên bảng đầu ra nếu cần, nhưng hãy đảm bảo rằng vai trò IAM của công việc AWS Glue mà bạn đã sử dụng trước đó được định cấu hình tương ứng.
- Trên bảng điều khiển Amazon MWAA, điều hướng đến môi trường của bạn để xem nơi mã DAG được lưu trữ.
Thư mục DAGs là tiền tố trong bộ chứa S3 nơi đặt tệp DAG của bạn.
- Tải lên tệp đã chỉnh sửa của bạn ở đó.

- Mở bảng điều khiển Amazon MWAA để xác nhận rằng DAG xuất hiện trong bảng.

Chạy DAG
Để chạy DAG, hãy hoàn thành các bước sau:
- Chọn từ các tùy chọn sau:
- Kích hoạt DAG – Điều này khiến dữ liệu của ngày hôm qua được sử dụng làm dữ liệu để xử lý
- Kích hoạt DAG với cấu hình – Với tùy chọn này, bạn có thể chuyển vào một ngày khác, có khả năng là để chèn lấp, được truy xuất bằng cách sử dụng
dag_run.conftrong mã DAG, sau đó được chuyển vào công việc AWS Glue dưới dạng tham số

Ảnh chụp màn hình sau đây hiển thị các tùy chọn cấu hình bổ sung nếu bạn chọn Kích hoạt DAG với cấu hình.

- Theo dõi DAG khi nó chạy.
- Khi DAG hoàn tất, hãy mở chi tiết của lần chạy.
Trên ngăn bên phải, bạn có thể xem nhật ký hoặc chọn Chi tiết phiên bản tác vụ để có cái nhìn đầy đủ.

- Xem nhật ký kết quả công việc AWS Glue trong Amazon MWAA mà không cần sử dụng bảng điều khiển AWS Glue nhờ có
GlueJobOperatorcờ tiết.

Công việc AWS Glue sẽ ghi kết quả vào bảng đầu ra mà bạn đã chỉ định.
- Truy vấn bảng này qua Athena để xác nhận nó đã thành công.
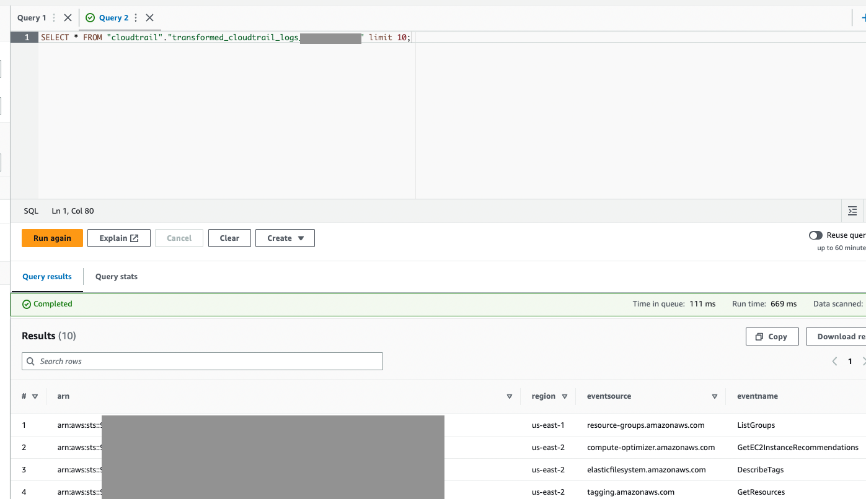
Tổng kết
Amazon MWAA hiện cung cấp một nơi duy nhất để theo dõi trạng thái tác vụ AWS Glue và cho phép bạn sử dụng bảng điều khiển Airflow dưới dạng một ô kính duy nhất để điều phối tác vụ và quản lý sức khỏe. Trong bài đăng này, chúng tôi đã hướng dẫn các bước để sắp xếp các tác vụ AWS Glue thông qua Airflow bằng cách sử dụng GlueJobOperator. Với các điểm cải tiến mới về khả năng quan sát, bạn có thể khắc phục sự cố liên tục các tác vụ AWS Glue trong một trải nghiệm thống nhất. Chúng tôi cũng trình bày cách nâng cấp môi trường Amazon MWAA của bạn lên phiên bản tương thích, cập nhật các phần phụ thuộc và thay đổi chính sách vai trò IAM cho phù hợp.
Để biết thêm thông tin về các bước khắc phục sự cố phổ biến, hãy tham khảo Khắc phục sự cố: Tạo và cập nhật môi trường Amazon MWAA. Để biết chi tiết chuyên sâu về việc di chuyển sang môi trường Amazon MWAA, hãy tham khảo Nâng cấp từ 1.10 lên 2. Để tìm hiểu về các thay đổi mã nguồn mở để tăng khả năng quan sát các tác vụ AWS Glue trong gói nhà cung cấp Airflow Amazon, hãy tham khảo chuyển tiếp nhật ký từ công việc AWS Glue.
Cuối cùng, chúng tôi khuyên bạn nên truy cập Blog dữ liệu lớn của AWS cho các tài liệu khác về phân tích, ML và quản trị dữ liệu trên AWS.
Về các tác giả
 Rushabh Lokhhande là Kỹ sư dữ liệu & ML với Thực hành phân tích dịch vụ chuyên nghiệp AWS. Anh ấy giúp khách hàng triển khai các giải pháp dữ liệu lớn, học máy và phân tích. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đọc sách, chạy bộ và chơi gôn.
Rushabh Lokhhande là Kỹ sư dữ liệu & ML với Thực hành phân tích dịch vụ chuyên nghiệp AWS. Anh ấy giúp khách hàng triển khai các giải pháp dữ liệu lớn, học máy và phân tích. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đọc sách, chạy bộ và chơi gôn.
 Ryan Gomes là Kỹ sư dữ liệu & ML với Thực hành phân tích dịch vụ chuyên nghiệp AWS. Anh ấy đam mê giúp khách hàng đạt được kết quả tốt hơn thông qua các giải pháp phân tích và học máy trên đám mây. Ngoài công việc, anh ấy thích tập thể dục, nấu ăn và dành thời gian chất lượng cho bạn bè và gia đình.
Ryan Gomes là Kỹ sư dữ liệu & ML với Thực hành phân tích dịch vụ chuyên nghiệp AWS. Anh ấy đam mê giúp khách hàng đạt được kết quả tốt hơn thông qua các giải pháp phân tích và học máy trên đám mây. Ngoài công việc, anh ấy thích tập thể dục, nấu ăn và dành thời gian chất lượng cho bạn bè và gia đình.
 Vishwa Gupta là Kiến trúc sư dữ liệu cấp cao với Thực tiễn phân tích dịch vụ chuyên nghiệp AWS. Anh ấy giúp khách hàng triển khai các giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đi du lịch và thử những món ăn mới.
Vishwa Gupta là Kiến trúc sư dữ liệu cấp cao với Thực tiễn phân tích dịch vụ chuyên nghiệp AWS. Anh ấy giúp khách hàng triển khai các giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đi du lịch và thử những món ăn mới.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 1
- 10
- 100
- 12
- 8
- a
- Giới thiệu
- truy cập
- cho phù hợp
- Tài khoản
- Đạt được
- ngang qua
- Hoạt động
- xoay vòng
- thêm vào
- Lợi thế
- lợi thế
- Sau
- tập hợp
- Tất cả
- cho phép
- cho phép
- Đã
- Ngoài ra
- đàn bà gan dạ
- Amazon Web Services
- an
- Phân tích
- phân tích
- phân tích
- và
- bất kì
- Apache
- api
- Các Ứng Dụng
- Phát triển ứng dụng
- thích hợp
- kiến trúc
- LÀ
- đối số
- đối số
- AS
- At
- thuộc tính
- kiểm toán
- có sẵn
- AWS
- Keo AWS
- Dịch vụ chuyên nghiệp của AWS
- dựa
- BE
- trở thành
- được
- trước
- được
- Hơn
- giữa
- lớn
- Dữ Liệu Lớn.
- cả hai
- Phá vỡ
- xây dựng
- nhưng
- by
- gọi là
- Cuộc gọi
- CAN
- trường hợp
- trường hợp
- Danh mục hàng
- nguyên nhân
- thay đổi
- Những thay đổi
- kiểm tra
- Chọn
- đám mây
- mã
- COM
- kết hợp
- bình luận
- Chung
- Các công ty
- khả năng tương thích
- tương thích
- hoàn thành
- phức tạp
- thành phần
- các thành phần
- Tính
- Cấu hình
- Xác nhận
- An ủi
- Củng cố
- hợp nhất
- nấu ăn
- Trung tâm
- bìa
- tạo
- tạo ra
- tạo ra
- Tạo
- Current
- khách hàng
- khách hàng
- khách hàng
- DAG
- dữ liệu
- tích hợp dữ liệu
- xử lý dữ liệu
- chiến lược dữ liệu
- Kho dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- bộ dữ liệu
- Ngày
- Ngày
- ngày giờ
- Ngày
- quyết định
- Mặc định
- giao
- chứng minh
- Tùy
- phản đối
- chi tiết
- chi tiết
- Phát triển
- khác nhau
- khác nhau
- kỹ thuật số
- Truyền thông kỹ thuật số
- trực tiếp
- thảo luận
- phân phối
- hệ thống phân phối
- do
- làm
- làm
- thực hiện
- suốt trong
- e
- Sớm hơn
- Ease
- hiệu lực
- loại bỏ
- khác
- cho phép
- kích hoạt
- cho phép
- Cuối cùng đến cuối
- Tham gia
- ky sư
- cải tiến
- đảm bảo
- đăng ký hạng mục thi
- Môi trường
- lôi
- Ether (ETH)
- sự kiện
- ví dụ
- Trừ
- ngoại lệ
- tồn tại
- hiện tại
- tồn tại
- kinh nghiệm
- Kinh nghiệm
- Khám phá
- biểu hiện
- ngoài
- trích xuất
- thất bại
- sai
- gia đình
- Đặc tính
- đặc sắc
- Tính năng
- Tập tin
- Các tập tin
- lọc
- Cuối cùng
- Tìm kiếm
- phòng tập thể dục
- tiếp theo
- thực phẩm
- Trong
- định dạng
- bạn bè
- từ
- Full
- thu thập
- tạo ra
- ly
- Go
- golf
- quản trị
- Nhóm
- Hadoop
- Có
- he
- cho sức khoẻ
- giúp đỡ
- giúp
- lịch sử
- Tổ ong
- Độ đáng tin của
- Hướng dẫn
- HTML
- http
- HTTPS
- IAM
- ID
- lý tưởng
- ý tưởng
- định danh
- if
- minh họa
- thực hiện
- nhập khẩu
- in
- sâu
- bao gồm
- Bao gồm
- Tăng lên
- tăng
- chỉ ra
- các ngành công nghiệp
- Thông tin
- thông tin
- ban đầu
- sáng tạo
- những hiểu biết
- Cài đặt
- ví dụ
- hướng dẫn
- tích hợp
- hội nhập
- quan tâm
- nội bộ
- trong
- IT
- Việc làm
- việc làm
- jpg
- json
- Key
- nổi tiếng
- lớn
- một lát sau
- mới nhất
- LEARN
- học tập
- Thư viện
- LIMIT
- Danh sách
- tải
- địa phương
- tại địa phương
- địa điểm thư viện nào
- đăng nhập
- đăng nhập
- khai thác gỗ
- tìm kiếm
- máy
- học máy
- thực hiện
- duy trì
- làm cho
- Làm
- quản lý
- quản lý
- quản lý
- nhãn hiệu
- vật liệu
- Có thể..
- Phương tiện truyền thông
- Gặp gỡ
- tin nhắn
- Metrics
- di cư
- tối thiểu
- ML
- sửa đổi
- mô-đun
- Màn Hình
- giám sát
- chi tiết
- phải
- tên
- tên
- Điều hướng
- THÔNG TIN
- cần thiết
- Cần
- cần thiết
- nhu cầu
- Mới
- không
- tại
- of
- cung cấp
- on
- ONE
- những
- có thể
- mở
- mã nguồn mở
- mã nguồn mở
- nhà điều hành
- khai thác
- tối ưu
- Tùy chọn
- Các lựa chọn
- or
- dàn xếp
- dàn nhạc
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- kết quả
- đầu ra
- bên ngoài
- gói
- gấu trúc
- cửa sổ
- thông số
- đối tác
- vượt qua
- thông qua
- đam mê
- hiệu suất
- quyền
- vẫn tồn tại
- đường ống dẫn
- Nơi
- nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- điểm
- điều luật
- Bài đăng
- có khả năng
- thực hành
- điều kiện tiên quyết
- trước
- trước đây
- quá trình
- Quy trình
- xử lý
- Sản phẩm
- chuyên nghiệp
- chuyên gia
- Profiles
- Chiếu
- nhà cung cấp dịch vụ
- nhà cung cấp
- cung cấp
- Python
- chất lượng
- truy vấn
- nâng cao
- phạm vi
- Đọc
- Reading
- thực
- thời gian thực
- gần đây
- giới thiệu
- khu
- nhà quản lý
- Đặt lại
- thay thế
- thay thế
- cần phải
- Yêu cầu
- tài nguyên
- Thông tin
- tương ứng
- phản ứng
- Kết quả
- giữ lại
- ngay
- Vai trò
- HÀNG
- chạy
- chạy
- s
- Lưu
- kịch bản
- sdk
- liền mạch
- Tìm kiếm
- Phần
- an toàn
- xem
- Tìm kiếm
- cao cấp
- Không có máy chủ
- DỊCH VỤ
- thiết lập
- thiết lập
- Shell
- nên
- hiển thị
- Chương trình
- Đơn giản
- đơn giản hóa
- kể từ khi
- duy nhất
- Ảnh chụp
- giải pháp
- Giải pháp
- một số
- riêng
- quy định
- Chi
- Tuyên bố
- Trạng thái
- Bước
- Các bước
- Vẫn còn
- là gắn
- lưu trữ
- Chiến lược
- dòng
- Chuỗi
- thành công
- như vậy
- đủ
- hỗ trợ
- Hỗ trợ
- hệ thống
- bàn
- Hãy
- dùng
- Nhiệm vụ
- đội
- Công nghệ
- mẫu
- cảm ơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- của bên thứ ba
- điều này
- Thông qua
- thời gian
- đến
- theo dõi
- Chuyển đổi
- Đi du lịch
- đúng
- thử
- Thứ Ba
- Quay
- hai
- kiểu
- ui
- thống nhât
- đơn vị
- Cập nhật
- Cập nhật
- cập nhật
- nâng cấp
- nâng cấp
- Đang tải lên
- Sử dụng
- sử dụng
- ca sử dụng
- đã sử dụng
- Người sử dụng
- sử dụng
- giá trị
- Các giá trị
- phiên bản
- thông qua
- Xem
- Lượt xem
- khả năng hiển thị
- có thể nhìn thấy
- đi bộ
- muốn
- là
- we
- web
- các dịch vụ web
- TỐT
- Điều gì
- khi nào
- liệu
- cái nào
- CHÚNG TÔI LÀ
- sẽ
- với
- ở trong
- không có
- Công việc
- Luồng công việc
- sẽ
- viết
- viết
- bạn
- trên màn hình
- zephyrnet