SmugMug vận hành hai nền tảng ảnh trực tuyến rất lớn, SmugMug và Flickr, cho phép hơn 100 triệu khách hàng lưu trữ, tìm kiếm, chia sẻ và bán hàng chục tỷ bức ảnh một cách an toàn. Việc khách hàng tải lên và tìm kiếm các bức ảnh trong nhiều thập kỷ đã giúp biến tìm kiếm thành cơ sở hạ tầng quan trọng, tăng trưởng ổn định kể từ khi SmugMug được sử dụng lần đầu tiên Tìm kiếm trên nền tảng đám mây của Amazon trong 2012, tiếp theo là Dịch vụ Tìm kiếm Mở của Amazon kể từ năm 2018, sau khi đạt tới hàng tỷ tài liệu và dung lượng lưu trữ tìm kiếm hàng terabyte.
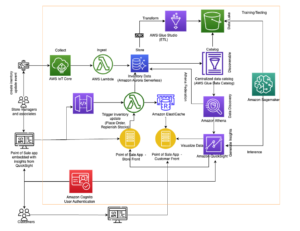
Tại đây, Lee Shepherd, Kỹ sư nhân viên của SmugMug, chia sẻ kiến trúc tìm kiếm của SmugMug được sử dụng để xuất bản, chèn lấp và phản ánh lưu lượng truy cập trực tiếp tới nhiều cụm. SmugMug sử dụng các quy trình này để đo điểm chuẩn, xác thực và di chuyển sang các cấu hình mới, bao gồm các phiên bản r6gd.2xlarge dựa trên Graviton từ i3.2xlarge, cùng với thử nghiệm Amazon OpenSearch Serverless. Chúng tôi bao gồm ba quy trình được sử dụng để xuất bản, chèn lấp và truy vấn mà không đưa ra các mẫu lưu lượng truy cập phi thực tế tăng đột biến và không có bất kỳ tác động nào đến các dịch vụ sản xuất.
Có hai phần kiến trúc chính quan trọng đối với quá trình này:
- Một nguồn sự thật lâu dài cho dữ liệu chỉ mục. Đó là cách thực hành tốt nhất và một phần trong chiến lược dự phòng của chúng tôi để có một cửa hàng bền vững ngoài chỉ mục OpenSearch và Máy phát điện Amazon cung cấp khả năng mở rộng và tích hợp với AWS Lambda điều đó đơn giản hóa rất nhiều quá trình. Chúng tôi sử dụng DynamoDB cho các dịch vụ không phải tìm kiếm khác nên điều này là phù hợp một cách tự nhiên.
- Hàm Lambda để xuất bản dữ liệu từ nguồn sự thật vào OpenSearch. sử dụng bí danh hàm giúp chạy nhiều cấu hình của cùng một hàm Lambda cùng lúc và là chìa khóa để giữ cho dữ liệu được đồng bộ hóa.
Xuất bản
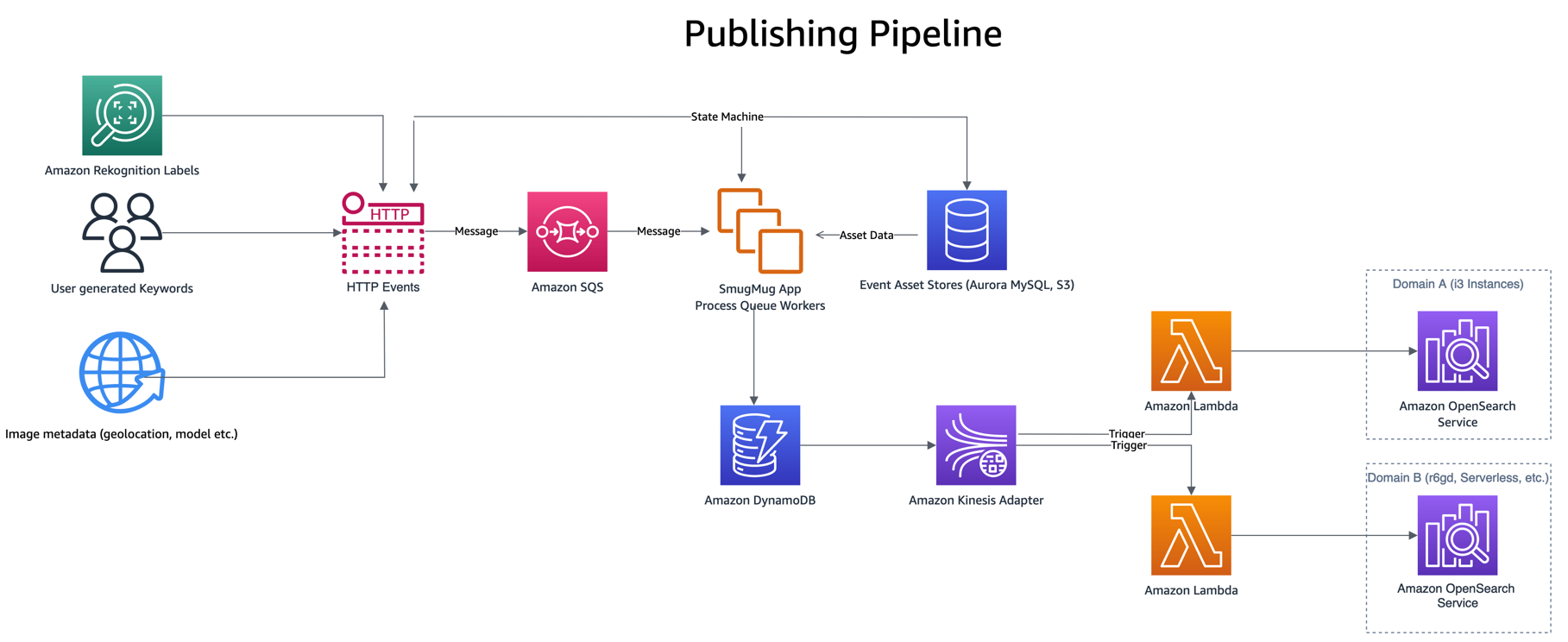
Quy trình xuất bản được điều khiển từ các sự kiện như người dùng nhập từ khóa hoặc chú thích, nội dung tải lên mới hoặc phát hiện nhãn thông qua Nhận thức lại Amazon. Những sự kiện này được xử lý, kết hợp dữ liệu từ một số kho tài sản khác như Phiên bản tương thích với Amazon Aurora MySQL và Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), trước khi ghi một mục vào DynamoDB.
Việc ghi vào DynamoDB sẽ gọi hàm xuất bản Lambda, thông qua DynamoDB truyền trực tuyến bộ điều hợp Kinesis, thao tác này lấy một loạt mục được cập nhật từ DynamoDB và lập chỉ mục chúng vào OpenSearch. Có những lợi ích khác khi sử dụng Bộ điều hợp Kinesis DynamoDB Streams chẳng hạn như giảm số lượng Lambda đồng thời cần thiết.
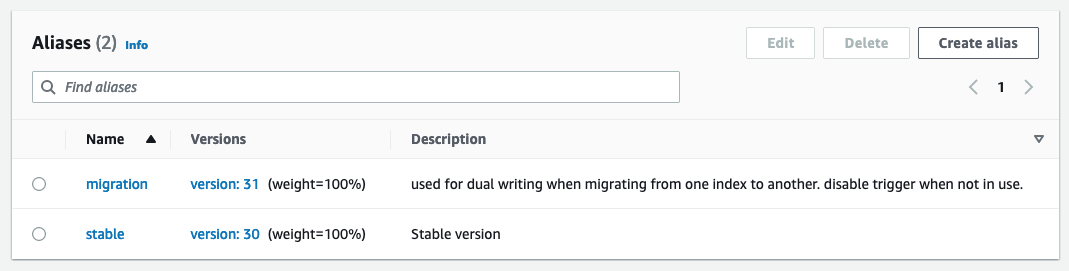
Hàm Lambda xuất bản sử dụng các biến môi trường để xác định miền và chỉ mục OpenSearch cần xuất bản. Bí danh sản xuất được định cấu hình để ghi vào miền OpenSearch sản xuất, ngoài bảng DynamoDB hoặc Kinesis Stream
Khi kiểm tra cấu hình mới hoặc di chuyển, bí danh di chuyển được định cấu hình để ghi vào miền OpenSearch mới nhưng sử dụng cùng một trình kích hoạt như bí danh sản xuất. Điều này cho phép lập chỉ mục kép dữ liệu cho cả hai miền Dịch vụ OpenSearch cùng một lúc.
Sau đây là ví dụ về lược đồ bảng DynamoDB:
Giá trị 'LastUpdated' được sử dụng làm phiên bản tài liệu khi lập chỉ mục, cho phép OpenSearch từ chối mọi cập nhật không theo thứ tự.
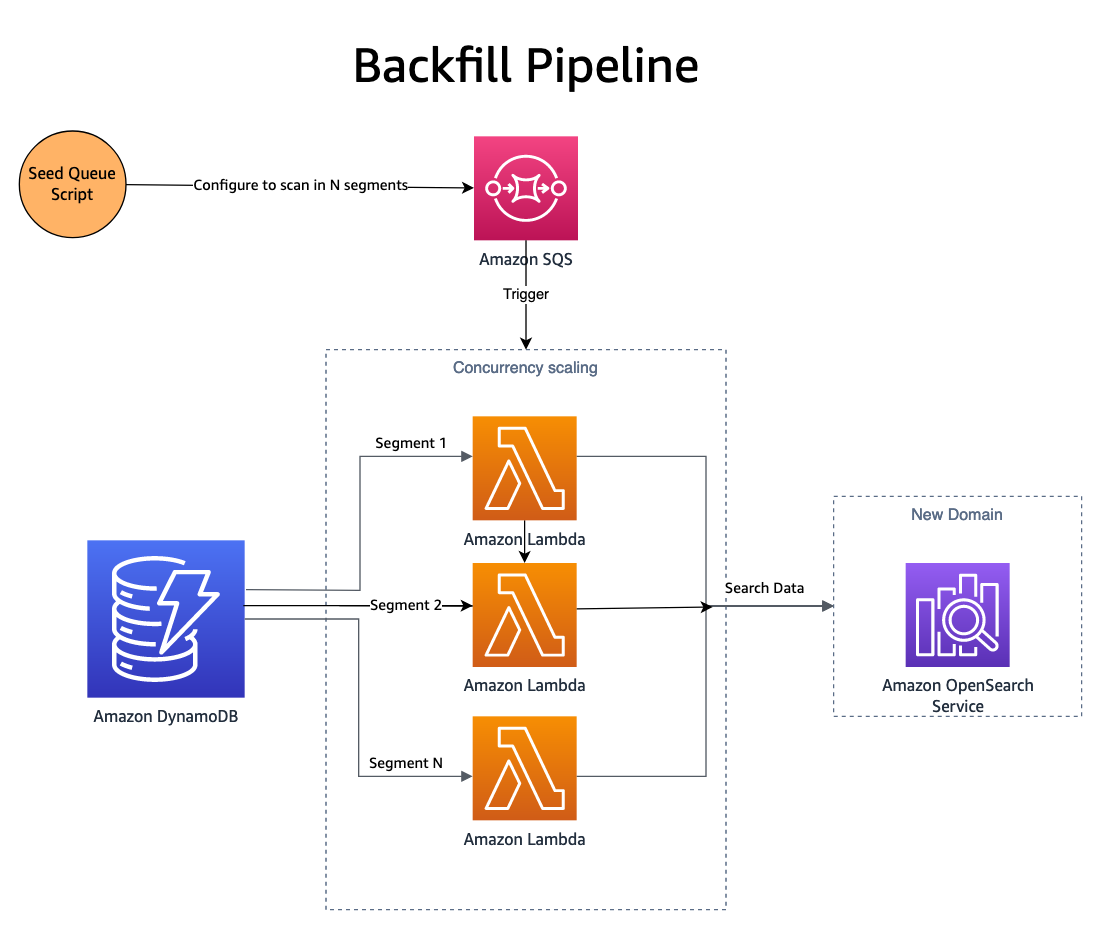
Lấp đất
Bây giờ các thay đổi đang được xuất bản cho cả hai tên miền, tên miền (chỉ mục) mới cần được lấp đầy bằng dữ liệu lịch sử. Để chèn lấp một chỉ mục mới được tạo, sự kết hợp của Dịch vụ xếp hàng đơn giản của Amazon (Amazon SQS) và DynamoDB được sử dụng. Một tập lệnh đưa vào hàng đợi SQS với các thông báo chứa hướng dẫn quét song song một phân đoạn của bảng DynamoDB.
Hàng đợi SQS khởi chạy hàm Lambda để đọc hướng dẫn thông báo, tìm nạp một loạt mục từ phân đoạn tương ứng của bảng DynamoDB và ghi chúng vào chỉ mục OpenSearch. Tin nhắn mới được ghi vào hàng đợi SQS để theo dõi tiến trình qua phân đoạn. Sau khi phân đoạn hoàn tất, không có tin nhắn nào được ghi vào hàng đợi SQS nữa và quá trình sẽ tự dừng lại.
Tính đồng thời được xác định theo số lượng phân đoạn, với các biện pháp kiểm soát bổ sung được cung cấp bởi khả năng chia tỷ lệ đồng thời của Lambda. SmugMug có thể lập chỉ mục hơn 1 tỷ tài liệu mỗi giờ trên cấu hình OpenSearch của chúng trong khi không gây ảnh hưởng gì đến miền sản xuất.
Tập lệnh dựa trên NodeJS AWS-SDK được sử dụng để tạo hàng đợi SQS. Đây là một đoạn tùy chọn của tập lệnh cấu hình SQS:
Cùng với định dạng của thông báo SQS thu được:
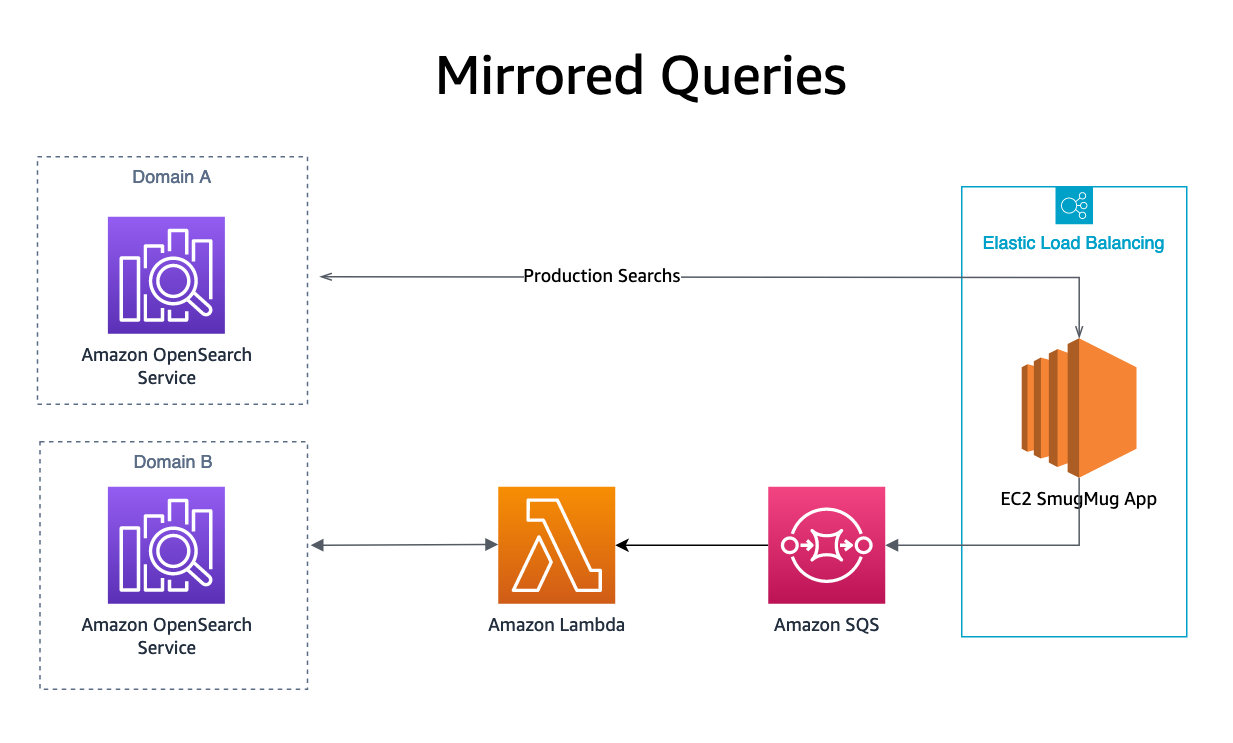
Phản chiếu
Cuối cùng, của chúng tôi truy vấn tìm kiếm được nhân đôi kết quả chạy bằng cách gửi truy vấn OpenSearch đến hàng đợi SQS, ngoài miền sản xuất của chúng tôi. Hàng đợi SQS khởi chạy hàm Lambda phát lại truy vấn tới miền bản sao. Kết quả tìm kiếm từ những yêu cầu này không được gửi đến bất kỳ người dùng nào nhưng cho phép sao chép tải sản xuất trên dịch vụ OpenSearch đang được thử nghiệm mà không ảnh hưởng đến hệ thống sản xuất hoặc khách hàng.
Kết luận
Khi đánh giá một miền hoặc cấu hình OpenSearch mới, số liệu chính mà chúng tôi quan tâm là hiệu suất độ trễ truy vấn, cụ thể là độ trễ thực hiện (độ trễ mỗi lần) và quan trọng nhất là độ trễ tìm kiếm. Khi chuyển sang Graviton R6gd, chúng tôi nhận thấy độ trễ P40-P50 thấp hơn khoảng 99%, cùng với mức tăng sử dụng CPU tương tự so với i3 (bỏ qua chi phí thấp hơn của Graviton). Một lợi ích đáng hoan nghênh khác là áp lực bộ nhớ JVM dễ dự đoán và giám sát hơn với những thay đổi về thu thập rác từ việc bổ sung G1GC trên R6gd và các phiên bản mới khác.
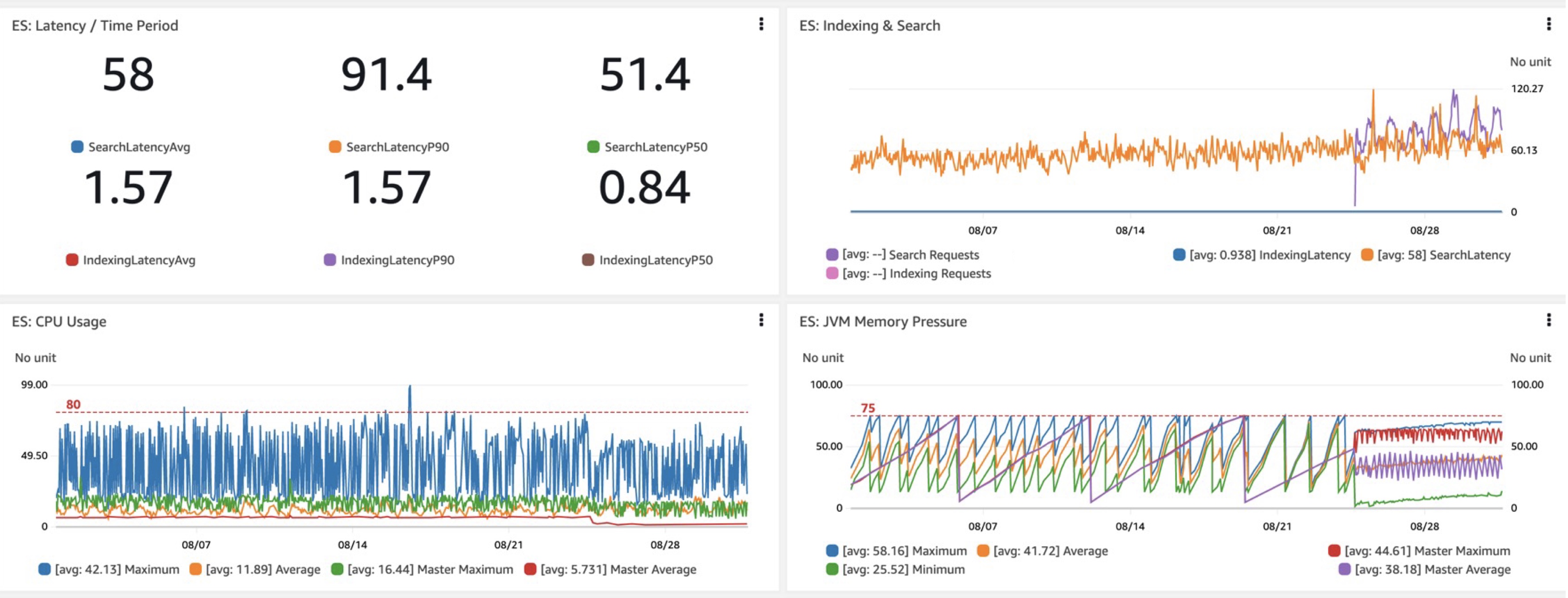
Bằng cách sử dụng quy trình này, chúng tôi cũng đang thử nghiệm OpenSearch Serverless và tìm ra những trường hợp sử dụng tốt nhất. Chúng tôi rất vui mừng về dịch vụ đó và hoàn toàn có ý định sớm xây dựng một kiến trúc hoàn toàn không có máy chủ. Hãy theo dõi để biết kết quả.
Về các tác giả
Lee Shepherd là Kỹ sư phần mềm của nhân viên SmugMug
Aydn Bekirov là Giám đốc tài khoản kỹ thuật chính của Amazon Web Services
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :là
- :không phải
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- Có khả năng
- Giới thiệu
- Tài khoản
- thêm
- Ngoài ra
- thêm vào
- Sau
- cho phép
- Cho phép
- dọc theo
- Ngoài ra
- đàn bà gan dạ
- Amazon Web Services
- an
- và
- Một
- bất kì
- kiến trúc
- kiến trúc
- LÀ
- AS
- tài sản
- At
- Rạng đông
- AWS
- sao lưu
- dựa
- BE
- trước
- được
- điểm chuẩn
- hưởng lợi
- Lợi ích
- BEST
- Ngoài
- Tỷ
- tỷ
- cả hai
- nhưng
- by
- chú thích
- Những thay đổi
- bộ sưu tập
- kết hợp
- kết hợp
- so
- tương thích
- Hoàn thành
- đồng thời
- Cấu hình
- cấu hình
- chứa
- điều khiển
- Tương ứng
- Chi phí
- che
- CPU
- tạo ra
- quan trọng
- Cơ sở hạ tầng quan trọng
- khách hàng
- dữ liệu
- thập kỷ
- Phát hiện
- Xác định
- xác định
- tài liệu
- tài liệu
- miền
- lĩnh vực
- điều khiển
- mỗi
- cho phép
- cho phép
- Điểm cuối
- ky sư
- vào
- hoàn toàn
- Môi trường
- Ether (ETH)
- đánh giá
- sự kiện
- ví dụ
- kích thích
- vài
- Lĩnh vực
- tìm kiếm
- Tên
- phù hợp với
- sau
- Trong
- định dạng
- từ
- đầy đủ
- chức năng
- thu nhập
- Phát triển
- Có
- cao
- đã giúp
- giúp
- lịch sử
- giờ
- HTML
- http
- HTTPS
- i
- i3
- ID
- Va chạm
- quan trọng
- in
- Bao gồm
- chỉ số
- chỉ số
- Cơ sở hạ tầng
- trường hợp
- hướng dẫn
- hội nhập
- ý định
- quan tâm
- trong
- giới thiệu
- viện dẫn
- mặt hàng
- sự lặp lại
- ITS
- chính nó
- jpg
- Giữ
- giữ
- Key
- từ khóa
- nhãn
- lớn
- Độ trễ
- ra mắt
- Lee
- Lượt thích
- sống
- tải
- Rất nhiều
- thấp hơn
- Chủ yếu
- Bộ nhớ
- tin nhắn
- tin nhắn
- Metrics
- di chuyển
- di cư
- di cư
- triệu
- triệu khách hàng
- gương
- chi tiết
- hầu hết
- di chuyển
- nhiều
- MySQL
- tên
- cụ thể là
- Tự nhiên
- nhu cầu
- Mới
- mới
- tiếp theo
- Không
- con số
- of
- off
- on
- Trực tuyến
- hoạt động
- Các lựa chọn
- Hoạt động
- or
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- Song song
- một phần
- mô hình
- mỗi
- phần trăm
- hiệu suất
- hình chụp
- Hình ảnh
- miếng
- đường ống dẫn
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Dự đoán
- áp lực
- trước
- Hiệu trưởng
- quá trình
- xử lý
- Sản lượng
- Tiến độ
- cung cấp
- cung cấp
- xuất bản
- công bố
- Xuất bản
- đạt
- giảm
- trả lời
- yêu cầu
- cần phải
- kết quả
- Kết quả
- chạy
- một cách an toàn
- tương tự
- thấy
- khả năng mở rộng
- mở rộng quy mô
- kịch bản
- Tìm kiếm
- tìm kiếm
- hạt giống
- phân khúc
- phân đoạn
- bán
- gửi
- gởi
- Không có máy chủ
- dịch vụ
- DỊCH VỤ
- Chia sẻ
- cổ phiếu
- tương tự
- Đơn giản
- đồng thời
- kể từ khi
- duy nhất
- đoạn
- So
- Phần mềm
- nguồn
- Nhân sự
- ở lại
- ổn định
- Dừng
- là gắn
- hàng
- cửa hàng
- Chiến lược
- dòng
- như vậy
- hệ thống
- bàn
- mất
- Kỹ thuật
- hàng chục
- thử nghiệm
- Kiểm tra
- hơn
- việc này
- Sản phẩm
- Nguồn
- cung cấp their dịch
- Them
- Đó
- Kia là
- điều này
- số ba
- Thông qua
- thời gian
- đến
- mất
- theo dõi
- giao thông
- kích hoạt
- Sự thật
- XOAY
- hai
- Dưới
- cập nhật
- Cập nhật
- Đang tải lên
- URL
- Sử dụng
- sử dụng
- trường hợp sử dụng
- đã sử dụng
- người sử dang
- sử dụng
- sử dụng
- HIỆU LỰC
- giá trị
- phiên bản
- rất
- là
- we
- web
- các dịch vụ web
- chào mừng
- Điều gì
- khi nào
- trong khi
- với
- không có
- viết
- viết
- viết
- zephyrnet
- không