Amazon EMR er en big data-tjeneste, der tilbydes af AWS til at køre Apache Spark og andre open source-applikationer på AWS for at bygge skalerbare datapipelines på en omkostningseffektiv måde. Overvågning af logfilerne, der genereres fra de job, der er implementeret på EMR-klynger, er afgørende for at hjælpe med at opdage kritiske problemer i realtid og hurtigt identificere grundlæggende årsager.
At skubbe disse logs ind amazoncloudwatch giver dig mulighed for at centralisere og drive handlingsorienteret intelligens fra dine logfiler for at løse driftsproblemer uden at skulle klargøre servere eller administrere software. Du kan med det samme begynde at skrive forespørgsler med aggregeringer, filtre og regulære udtryk. Derudover kan du visualisere tidsseriedata, bore ned i individuelle loghændelser og eksportere forespørgselsresultater til CloudWatch-dashboards.
At indtage logfiler, der er fastholdt på Amazon Elastic Compute Cloud (Amazon EC2) forekomster af en EMR-klynge i CloudWatch, kan du bruge CloudWatch agent. Dette giver en enkel måde at skubbe logfiler fra en EC2-instans til CloudWatch.
CloudWatch-agenten er en softwarepakke, der autonomt og kontinuerligt kører på dine servere. Du kan installere og konfigurere CloudWatch-agenten til at indsamle system- og applikationslogfiler fra EC2-instanser, lokale værter og containeriserede applikationer. CloudWatch behandler og gemmer logfilerne indsamlet af CloudWatch-agenten, hvilket yderligere hjælper med ydeevnen og sundhedsovervågningen af din infrastruktur og applikationer.
I dette indlæg opretter vi en EMR-klynge og centraliserer EMR-trinloggene for jobs i CloudWatch. Dette vil gøre det nemmere for dig at administrere din EMR-klynge, fejlfinde problemer og overvåge ydeevnen. Denne løsning er især nyttig, hvis du vil bruge CloudWatch til at indsamle og visualisere realtidslogfiler, metrics og hændelsesdata, hvilket strømliner din infrastruktur og applikationsvedligeholdelse.
Oversigt over løsning
Løsningen præsenteret i dette indlæg er baseret på en specifik konfiguration, hvor EMR-trinnets samtidighedsniveau er sat til 1. Det betyder, at der kun køres et trin ad gangen på klyngen. Det er vigtigt at bemærke, at hvis samtidighedsniveauet for EMR-trin er indstillet til en værdi større end 1, fungerer løsningen muligvis ikke som forventet. Vi anbefaler stærkt at verificere din EMR trin samtidighed konfiguration før implementering af løsningen præsenteret i dette indlæg.
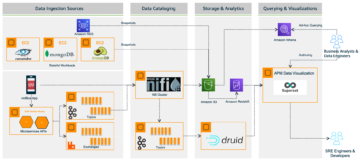
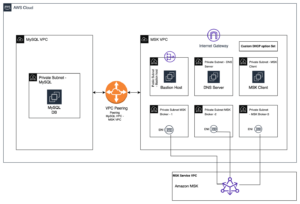
Følgende diagram illustrerer løsningsarkitekturen.
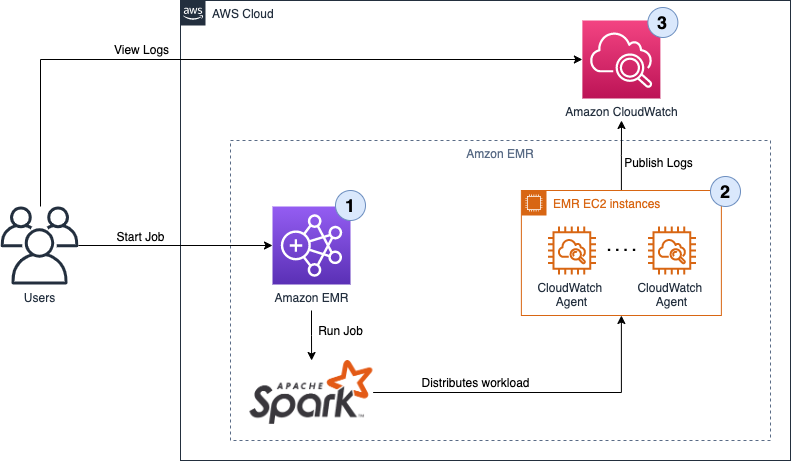
Arbejdsgangen omfatter følgende trin:
- Brugere starter et Apache Spark EMR-job og skaber et trin på EMR-klyngen. Ved hjælp af Apache Spark fordeles arbejdsbyrden på tværs af de forskellige noder i EMR-klyngen.
- I hver node (EC2-instans) af klyngen overvåger en CloudWatch-agent forskellige log-mapper, fanger nye poster i logfilerne og skubber dem til CloudWatch.
- Brugere kan se trinlogfilerne, der får adgang til de forskellige loggrupper fra CloudWatch-konsollen. Trinloggene skrevet af Amazon EMR er som følger:
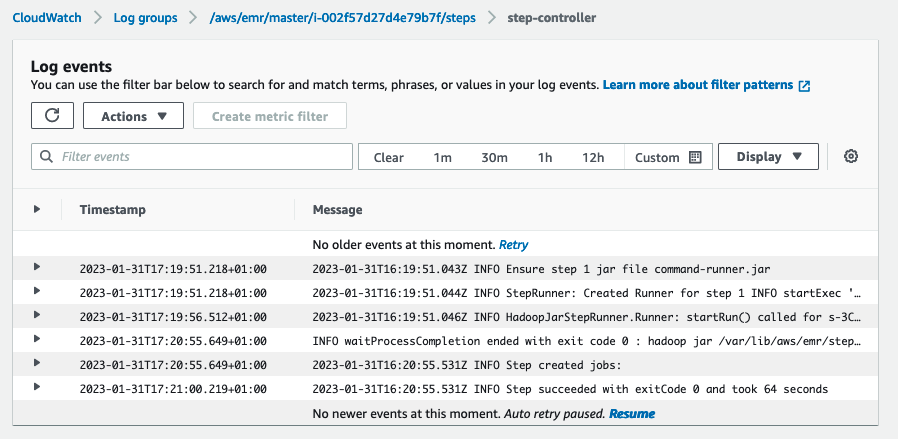
- controller — Oplysninger om behandlingen af trinnet. Hvis dit trin mislykkes under indlæsning, kan du finde stak-sporet i denne log.
- stderr — Standardfejlkanalen for Spark, mens den behandler trinnet.
- stdout — Standardudgangskanalen for Spark, mens den behandler trinnet.
Vi leverer en AWS CloudFormation skabelon i dette indlæg som en generel vejledning. Skabelonen viser, hvordan man konfigurerer en CloudWatch-agent på Amazon EMR til at skubbe Spark-logfiler til CloudWatch. Du kan gennemgå og tilpasse det efter behov for at inkludere dine Amazon EMR-sikkerhedskonfigurationer. Som en bedste praksis anbefaler vi at inkludere dine Amazon EMR-sikkerhedskonfigurationer i skabelonen til kryptere data under transport.
Du skal også være opmærksom på, at nogle af de ressourcer, der implementeres af denne stak, medfører omkostninger, når de forbliver i brug.
I de næste afsnit gennemgår vi følgende trin:
- Opret og upload bootstrap-scriptet til en Amazon Simple Storage Service (Amazon S3) spand.
- Brug CloudFormation-skabelonen til at oprette følgende ressourcer:
- Overvåg Spark-logfilerne på CloudWatch-konsollen.
Forudsætninger
Dette indlæg forudsætter, at du har følgende:
Opret og upload bootstrap-scriptet til en S3-bøtte
For mere information, se Uploader objekter , Installation og kørsel af CloudWatch-agenten på dine servere.
For at oprette og uploade bootstrap-scriptet skal du udføre følgende trin:
- Opret en lokal fil med navnet
bootstrap_cloudwatch_agent.shmed følgende indhold: - På Amazon S3-konsollen skal du vælge din S3-spand.
- På Objekter fanebladet, vælg Upload.
- Vælg Tilføj filer, og vælg derefter bootstrap-scriptet.
- Vælg Upload, vælg derefter filnavnet:
bootstrap_cloudwatch_agent.sh. - Vælg Kopiér S3 URI. Vi bruger denne værdi i et senere trin.
Levering af ressourcer med CloudFormation-skabelonen
Vælg Start Stack for at starte en CloudFormation-stak i din konto og implementere skabelonen:
![]()
Denne skabelon opretter en IAM-rolle, IAM-instansprofil, Systems Manager-parameter og EMR-klynge. Klyngen starter Eksempel på applikation til Spark PI-estimering. Du vil blive faktureret for de brugte AWS-ressourcer, hvis du opretter en stak fra denne skabelon.
CloudFormation-guiden vil bede dig om at ændre eller angive disse parametre:
- InstanceType - Den type instans for alle instansgrupper. Standard er m4.xlarge.
- InstanceCountCore – Antallet af instanser i kerneinstansgruppen. Standard er 2.
- EMRReaseLabel - Den Amazon EMR release label du vil bruge. Standarden er emr-6.9.0.
- BootstrapScriptPath – S3-stien til dit CloudWatch-agentinstallations-bootstrap-script, som du kopierede tidligere.
- Subnet – EC2-undernettet, hvor klyngen starter. Du skal angive denne parameter.
- EC2KeyPairName – Et valgfrit EC2-nøglepar til tilslutning til klynge noder, som et alternativ til Session Manager.
Overvåg logstrømmene
Når CloudFormation-stakken er implementeret, skal du vælge på CloudWatch-konsollen Log grupper i navigationsruden. Filtrer derefter loggrupperne efter præfikset /aws/emr/master.
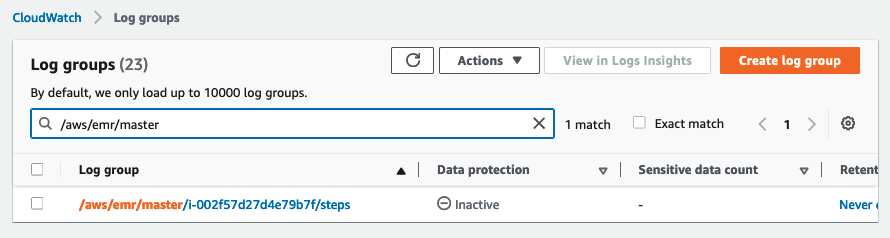
ID'et i loggruppen svarer til EC2-instans-ID'et for den primære EMR-knude. Hvis du har flere EMR-klynger, kan du bruge dette ID til at identificere en bestemt EMR-klynge baseret på det primære node-id.
I log-gruppen finder du de tre forskellige log-strømme.
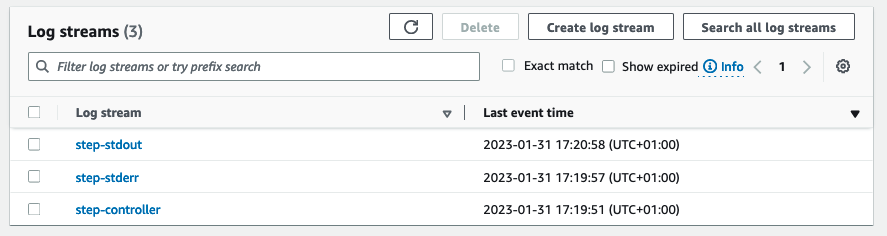
Logstrømmene indeholder følgende oplysninger:
- step-stdout – Standardudgangskanalen for Spark, mens den behandler trinnet.
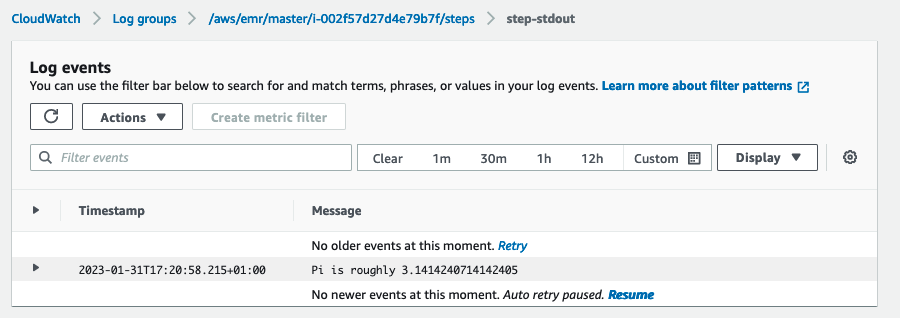
- trin-stderr – Standardfejlkanalen for Spark, mens den behandler trinnet.
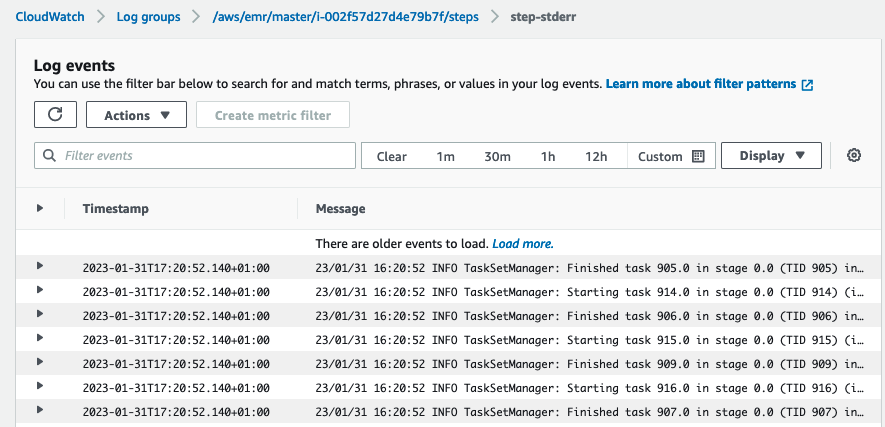
- trin-controller – Oplysninger om behandlingen af trinnet. Hvis dit trin mislykkes under indlæsning, kan du finde stak-sporet i denne log.
Ryd op
For at undgå fremtidige debiteringer på din konto skal du slette de ressourcer, du oprettede i denne gennemgang. EMR-klyngen vil pålægges gebyrer, så længe klyngen er aktiv, så stop den, når du er færdig.
- På CloudFormation-konsollen skal du i navigationsruden vælge Stakke.
- Vælg den stak du har startet (
EMR-CloudWatch-Demo), vælg derefter Slette. - Tøm S3-spanden du har skabt.
- Slet S3-bøtten du har skabt.
Konklusion
Nu hvor du har gennemført trinene i denne gennemgang, har du CloudWatch-agenten kørende på dine klyngeværter og konfigureret til at sende EMR-trinlogfiler til CloudWatch. Med denne funktion kan du effektivt overvåge sundheden og ydeevnen af dine Spark-job, der kører på Amazon EMR, opdage kritiske problemer i realtid og hurtigt identificere grundlæggende årsager.
Du kan pakke og implementere denne løsning gennem en CloudFormation-skabelon som denne eksempelskabelon, der opretter IAM-instansprofilrollen, Systems Manager-parameteren og EMR-klyngen.
For at tage dette videre kan du overveje at bruge disse logfiler i CloudWatch-alarmer til advarsler på en log gruppe-metrisk filter. Du kan samle dem med andre alarmer i en sammensat alarm eller konfigurer alarmhandlinger såsom afsendelse Amazon Simple Notification Service (Amazon SNS) notifikationer for at udløse hændelsesdrevne processer som f.eks AWS Lambda funktioner.
Om forfatteren
 Ennio Pastore er Senior Data Architect på AWS Data Lab-teamet. Han er entusiast for alt relateret til nye teknologier, der har en positiv indvirkning på virksomheder og generel levebrød. Ennio har over 10 års erfaring med dataanalyse. Han hjælper virksomheder med at definere og implementere dataplatforme på tværs af brancher, såsom telekommunikation, bank, spil, detailhandel og forsikring.
Ennio Pastore er Senior Data Architect på AWS Data Lab-teamet. Han er entusiast for alt relateret til nye teknologier, der har en positiv indvirkning på virksomheder og generel levebrød. Ennio har over 10 års erfaring med dataanalyse. Han hjælper virksomheder med at definere og implementere dataplatforme på tværs af brancher, såsom telekommunikation, bank, spil, detailhandel og forsikring.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/push-amazon-emr-step-logs-from-amazon-ec2-instances-to-amazon-cloudwatch-logs/
- :er
- 1
- 10
- 100
- 9
- a
- Om
- Adgang
- Konto
- tværs
- aktioner
- aktiv
- Desuden
- adresse
- Agent
- alarm
- indberetninger
- Alle
- alternativ
- Amazon
- Amazon EC2
- Amazon EMR
- analytics
- ,
- Apache
- Apache Spark
- Anvendelse
- applikationer
- arkitektur
- ER
- AS
- At
- autonomt
- AWS
- Bank
- baseret
- BE
- før
- begynde
- BEDSTE
- Big
- Big data
- Bootstrap
- bygge
- virksomheder
- by
- CAN
- Optagelse
- årsager
- Kanal
- afgifter
- Vælg
- Cluster
- indsamler
- Virksomheder
- fuldføre
- Afsluttet
- Compute
- Konfiguration
- Tilslutning
- Overvej
- Konsol
- indhold
- kontinuerligt
- Core
- svarer
- omkostningseffektiv
- Omkostninger
- kunne
- skabe
- oprettet
- skaber
- Oprettelse af
- kritisk
- tilpasse
- data
- Dataanalyse
- Standard
- demonstrerer
- indsætte
- indsat
- udruller
- forskellige
- mapper
- distribueret
- ned
- køre
- hver
- tidligere
- lettere
- ekko
- effektivt
- muliggør
- entusiast
- fejl
- væsentlig
- Ether (ETH)
- begivenhed
- begivenheder
- at alt
- eksempel
- forventet
- erfaring
- eksport
- udtryk
- mislykkes
- Feature
- File (Felt)
- Filer
- filtrere
- Filtre
- Finde
- efter
- følger
- Til
- fra
- funktioner
- yderligere
- fremtiden
- spil
- Generelt
- genereret
- Go
- større
- gruppe
- Gruppens
- vejlede
- Have
- Helse
- hjælpe
- hjælpsom
- hjælper
- stærkt
- værter
- Hvordan
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- identificere
- identificere
- KIMOs Succeshistorier
- gennemføre
- gennemføre
- vigtigt
- in
- omfatter
- omfatter
- Herunder
- individuel
- industrier
- oplysninger
- Infrastruktur
- installere
- installation
- instans
- forsikring
- Intelligens
- spørgsmål
- IT
- Job
- Karriere
- jpg
- json
- lab
- lancere
- lanceret
- lanceringer
- Niveau
- ligesom
- lastning
- lokale
- Lang
- vedligeholdelse
- lave
- administrere
- leder
- måde
- midler
- Metrics
- ændre
- Overvåg
- overvågning
- mere
- flere
- navn
- Som hedder
- Navigation
- behov
- behøve
- Ny
- Nye teknologier
- næste
- node
- noder
- underretning
- meddelelser
- nummer
- of
- tilbydes
- on
- ONE
- open source
- operationelle
- Andet
- output
- pakke
- brød
- parameter
- parametre
- særlig
- især
- sti
- ydeevne
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- positiv
- Indlæg
- praksis
- forelagt
- primære
- Processer
- forarbejdning
- Profil
- give
- giver
- bestemmelse
- Skub ud
- Pushing
- hurtigt
- ægte
- realtid
- anbefaler
- fast
- relaterede
- frigive
- forblive
- Ressourcer
- Resultater
- detail
- gennemgå
- roller
- rod
- Kør
- kører
- skalerbar
- sektioner
- sikkerhed
- afsendelse
- senior
- Series
- tjeneste
- Session
- sæt
- bør
- Simpelt
- So
- Software
- løsninger
- nogle
- Spark
- specifikke
- stable
- standard
- starte
- Starter
- starter
- Trin
- Steps
- Stands
- opbevaring
- forhandler
- strømlining
- vandløb
- subnet
- Succesfuld
- sådan
- sudo
- systemet
- Systemer
- Tag
- hold
- Teknologier
- telekommunikation
- skabelon
- at
- Them
- Disse
- tre
- Gennem
- tid
- Tidsserier
- til
- spore
- udløse
- brug
- værdi
- verificere
- Specifikation
- går igennem
- ure
- Vej..
- som
- mens
- vilje
- med
- uden
- Arbejde
- workflow
- skrivning
- skriftlig
- yaml
- år
- Din
- zephyrnet