I nutidens datadrevne verden er evnen til ubesværet at flytte og analysere data på tværs af forskellige platforme afgørende. Amazon App Flow, en fuldt administreret dataintegrationstjeneste, har været på forkant med at strømline dataoverførsel mellem AWS-tjenester, software as a service-applikationer (SaaS) og nu Google BigQuery. I dette blogindlæg udforsker du det nye Google BigQuery-connector i Amazon AppFlow og opdag, hvordan det forenkler processen med at overføre data fra Googles datavarehus til Amazon Simple Storage Service (Amazon S3), hvilket giver betydelige fordele for dataprofessionelle og organisationer, herunder demokratisering af multi-cloud-dataadgang.
Oversigt over Amazon AppFlow
Amazon App Flow er en fuldt administreret integrationstjeneste, som du kan bruge til sikker overførsel af data mellem SaaS-applikationer såsom Google BigQuery, Salesforce, SAP, Hubspot og ServiceNow, og AWS-tjenester såsom Amazon S3 og Amazon rødforskydning, med blot et par klik. Med Amazon AppFlow kan du køre datastrømme i næsten enhver skala med den frekvens, du vælger – på en tidsplan, som svar på en forretningsbegivenhed eller på efterspørgsel. Du kan konfigurere datatransformationsfunktioner såsom filtrering og validering for at generere fyldige, brugsklare data som en del af selve flowet uden yderligere trin. Amazon AppFlow krypterer automatisk data i bevægelse og giver dig mulighed for at begrænse data i at flyde over det offentlige internet for SaaS-applikationer, der er integreret med AWS PrivateLink, hvilket reducerer eksponeringen for sikkerhedstrusler.
Introduktion til Google BigQuery-connectoren
Den nye Google BigQuery-connector i Amazon afslører AppFlow muligheder for organisationer, der søger at bruge den analytiske kapacitet i Googles datavarehus og ubesværet at integrere, analysere, gemme eller viderebehandle data fra BigQuery og omdanne dem til handlingsvenlig indsigt.
arkitektur
Lad os gennemgå arkitekturen til at overføre data fra Google BigQuery til Amazon S3 ved hjælp af Amazon AppFlow.

- Vælg en datakilde: In Amazon App Flow, skal du vælge Google BigQuery som din datakilde. Angiv de tabeller eller datasæt, du vil udtrække data fra.
- Feltkortlægning og transformation: Konfigurer dataoverførslen ved hjælp af Amazon AppFlows intuitive visuelle grænseflade. Du kan kortlægge datafelter og anvende transformationer efter behov for at tilpasse dataene til dine krav.
- Overførselsfrekvens: Bestem, hvor ofte du vil overføre data – f.eks. dagligt, ugentligt eller månedligt – hvilket understøtter fleksibilitet og automatisering.
- Destination: Angiv en S3-bøtte som destination for dine data. Amazon AppFlow vil effektivt flytte dataene, hvilket gør dem tilgængelige i dit Amazon S3-lager.
- Forbrug: Anvendelse Amazonas Athena at analysere dataene i Amazon S3.
Forudsætninger
Datasættet brugt i denne løsning er genereret af Synthea, en syntetisk patientpopulationssimulator og opensource-projekt under Apache-licens 2.0. Indlæs disse data i Google BigQuery, eller brug dit eksisterende datasæt.
Forbind Amazon AppFlow til din Google BigQuery-konto
Til dette indlæg bruger du en Google-konto, OAuth-klient med passende tilladelser og Google BigQuery-data. For at aktivere Google BigQuery-adgang fra Amazon AppFlow skal du konfigurere en ny OAuth-klient på forhånd. For instruktioner, se Google BigQuery-stik til Amazon AppFlow.
Konfigurer Amazon S3
Hvert objekt i Amazon S3 er gemt i en spand. Før du kan gemme data i Amazon S3, skal du lav en S3-spand at gemme resultaterne.
Opret en ny S3-bøtte til Amazon AppFlow-resultater
For at oprette en S3-spand skal du udføre følgende trin:
- På AWS Management-konsollen til Amazon S3, vælg Opret spand.
- Indtast en globalt unik navn til din spand; for eksempel,
appflow-bq-sample. - Vælg Opret spand.
Opret en ny S3-spand til Amazon Athena-resultater
For at oprette en S3-spand skal du udføre følgende trin:
- På AWS Management-konsollen til Amazon S3, vælg Opret spand.
- Indtast en globalt unik navn til din spand; for eksempel,
athena-results. - Vælg Opret spand.
Brugerrolle (IAM-rolle) for AWS Glue Data Catalog
For at katalogisere de data, du overfører med dit flow, skal du have den relevante brugerrolle i AWS Identity and Access Management (IAM). Du giver denne rolle til Amazon AppFlow for at give de tilladelser, den skal bruge for at oprette en AWS Glue Data Katalog, tabeller, databaser og partitioner.
For et eksempel på en IAM-politik, der har de nødvendige tilladelser, se Identitetsbaserede politikeksempler for Amazon AppFlow.
Gennemgang af designet
Lad os nu gennemgå en praktisk use case for at se, hvordan Amazon AppFlow Google BigQuery til Amazon S3-stikket fungerer. Til brugssagen skal du bruge Amazon AppFlow til at arkivere historiske data fra Google BigQuery til Amazon S3 til langtidslagring og analyse.
Konfigurer Amazon AppFlow
Opret et nyt Amazon AppFlow-flow for at overføre data fra Google Analytics til Amazon S3.
- På Amazon AppFlow-konsol, vælg Skab flow.
- Indtast et navn til dit flow; for eksempel,
my-bq-flow. - Tilføj nødvendigt Tags; for eksempel for Nøgle indtaste
envog for Værdi indtastedev.

- Vælg Næste.
- Til Kildens navn, vælg Google BigQuery.
- Vælg Opret ny forbindelse.
- Indtast din OAuth kunde-id , Klienthemmelighed, navngiv derefter din forbindelse; for eksempel,
bq-connection.

- I pop op-vinduet skal du vælge at tillade amazon.com adgang til Google BigQuery API.

- Til Vælg Google BigQuery-objekt, vælg Bordlampe.
- Til Vælg Google BigQuery-underobjekt, vælg BigQueryProjectName.
- Til Vælg Google BigQuery-underobjekt, vælg Databasenavn.
- Til Vælg Google BigQuery-underobjekt, vælg tabelnavn.
- Til Destinationsnavn, vælg Amazon S3.
- Til Spand detaljer, skal du vælge den Amazon S3-bøtte, du har oprettet til lagring af Amazon AppFlow-resultater i forudsætningerne.
- Indtast
rawsom en præfiks.
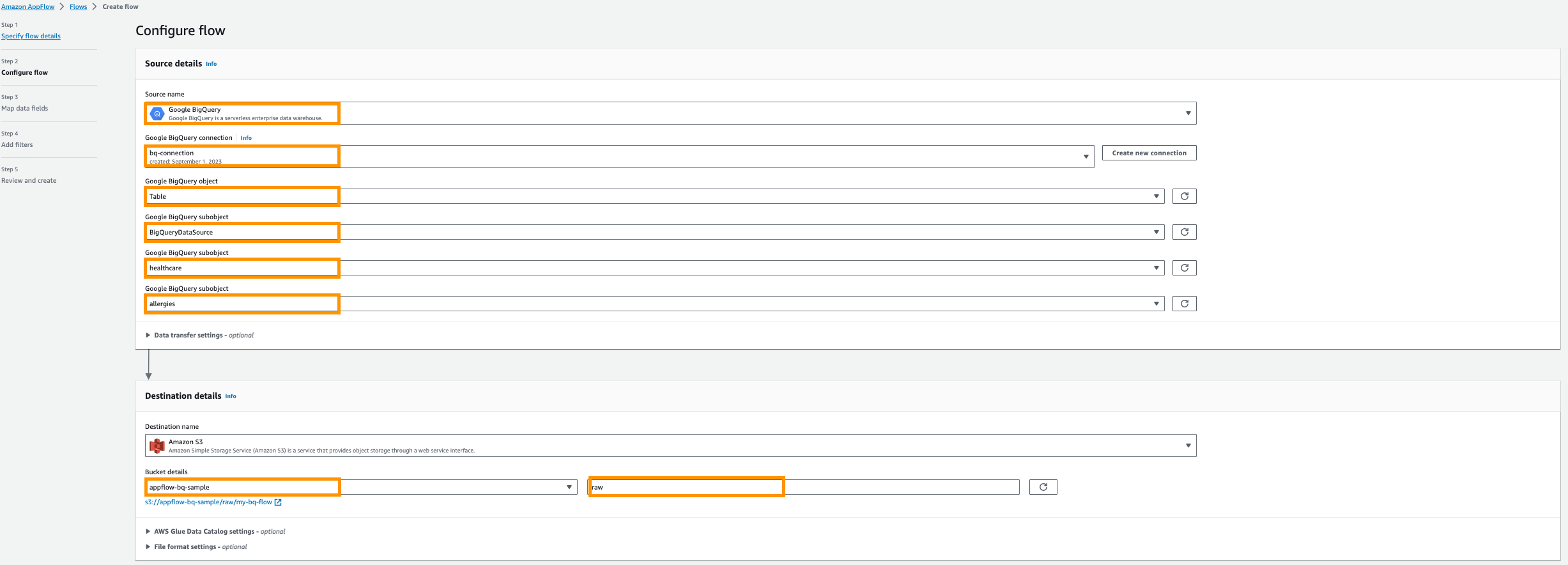
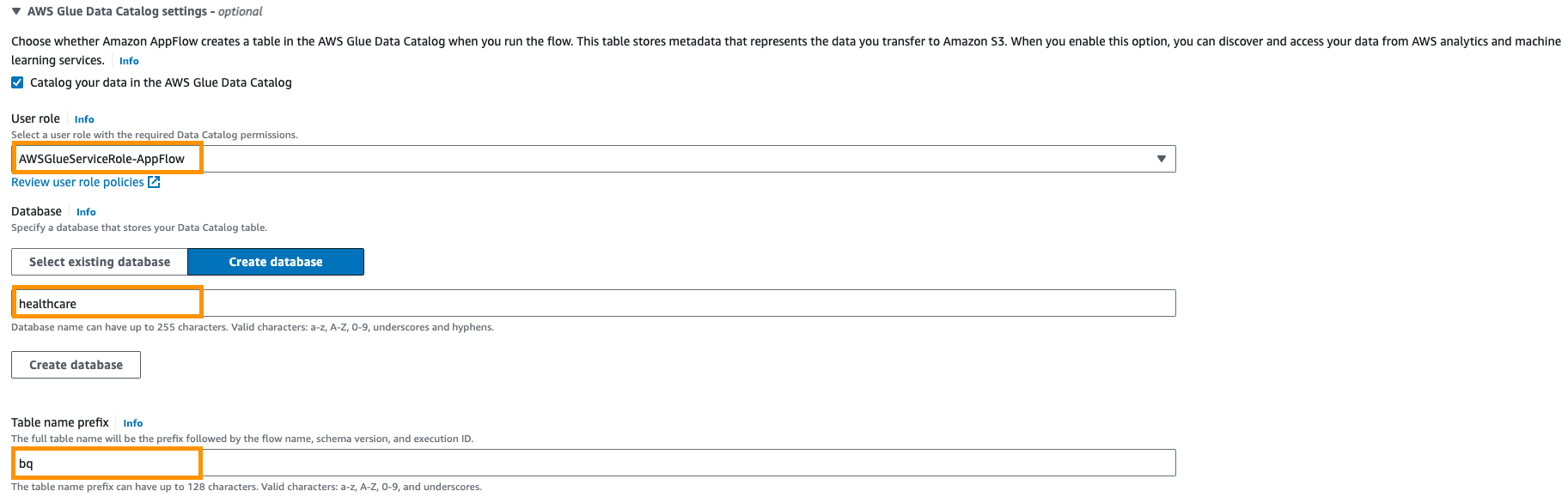
- Dernæst, giv AWS Glue Data Katalog indstillinger for at oprette en tabel til yderligere analyse.
- Vælg Brugerrolle (IAM-rolle) oprettet i forudsætningerne.
- Opret ny database for eksempel,
healthcare. - Giv en tabelpræfiks indstilling f.eks.
bq.
- Type Kør efter behov.
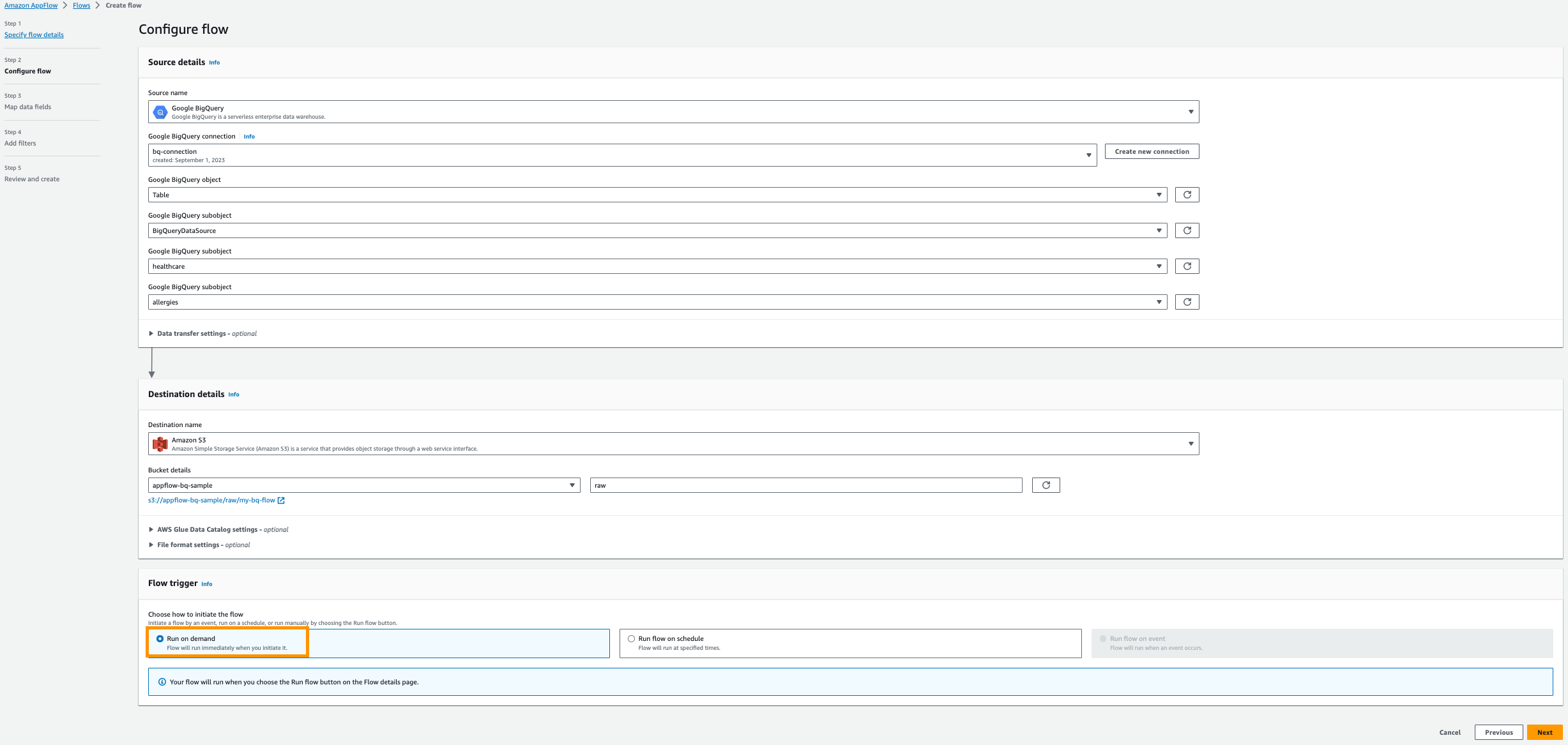
- Vælg Næste.
- Type Kortlæg felter manuelt.
- Vælg følgende seks felter for Kildefeltnavn fra tabellen Allergi:
- Starten
- Patient
- Kode
- Beskrivelse
- Type
- Boligtype
- Vælg Kort felter direkte.

- Vælg Næste.
- In Tilføj filtre sektion, skal du vælge Næste.
- Vælg Skab flow.
Kør flowet
Når du har oprettet dit nye flow, kan du køre det efter behov.
- På Amazon AppFlow-konsol, vælg
my-bq-flow. - Vælg Kør flow.

Til denne gennemgang skal du vælge kør jobbet on-demand for at lette forståelsen. I praksis kan du vælge et planlagt job og med jævne mellemrum kun udtrække nyligt tilføjede data.
Forespørgsel gennem Amazon Athena
Når du vælger de valgfrie AWS Glue Data Catalog-indstillinger, opretter Data Catalog kataloget for dataene, så Amazon Athena kan udføre forespørgsler.
Hvis du bliver bedt om at konfigurere en forespørgselsresultatplacering, skal du navigere til Indstillinger fanebladet og vælg Administrer. Under Administrer indstillinger, vælg Athena-resultatspanden oprettet i forudsætninger og vælg Gem.
- På Amazon Athena konsol, vælg Datakilden som
AWSDataCatalog. - Vælg derefter Database as
healthcare. - Nu kan du vælge den tabel, der er oprettet af AWS Glue-crawleren, og få vist den.

- Du kan også køre en tilpasset forespørgsel for at finde top 10 allergier som vist i følgende forespørgsel.
Bemærk: I nedenstående forespørgsel skal du erstatte tabelnavnet, i dette tilfælde bq_appflow_mybqflow_1693588670_latest, med navnet på tabellen genereret i din AWS-konto.
- Vælg Kør forespørgsel.

Dette resultat viser top 10 allergier efter antal tilfælde.
Ryd op
For at undgå at pådrage sig gebyrer skal du rydde op i ressourcerne på din AWS-konto ved at udføre følgende trin:
- Vælg på Amazon AppFlow-konsollen strømme i navigationsruden.
- Vælg flowet på listen over flows
my-bq-flow, og slet den. - Indtast slet for at slette flowet.
- Vælg Tilslutninger i navigationsruden.
- Vælg Google BigQuery fra listen over stik skal du vælge
bq-connector, og slet den. - Indtast slet for at slette forbindelsen.
- På IAM-konsollen skal du vælge roller på navigationssiden, vælg derefter den rolle, du oprettede for AWS Glue-crawler, og slet den.
- På Amazon Athena-konsollen:
- Slet de tabeller, der er oprettet under databasen
healthcareved hjælp af AWS Glue crawler. - Slip databasen
healthcare
- Slet de tabeller, der er oprettet under databasen
- På Amazon S3-konsollen, søg efter den Amazon AppFlow-resultatbøtte, du har oprettet, og vælg Tom for at slette objekterne, og slet derefter bøtten.
- På Amazon S3-konsollen, søg efter den Amazon Athena-resultatbøtte, du har oprettet, og vælg Tom for at slette objekterne, og slet derefter bøtten.
- Ryd op i ressourcer på din Google-konto ved at slette det projekt, der indeholder Google BigQuery-ressourcerne. Følg dokumentationen til rydde op i Googles ressourcer.
Konklusion
Google BigQuery-stikket i Amazon AppFlow strømliner processen med at overføre data fra Googles datavarehus til Amazon S3. Denne integration forenkler analyse og maskinlæring, arkivering og langtidslagring, hvilket giver betydelige fordele for dataprofessionelle og organisationer, der søger at udnytte de analytiske muligheder på begge platforme.
Med Amazon AppFlow elimineres kompleksiteten af dataintegration, så du kan fokusere på at udlede handlingsorienteret indsigt fra dine data. Uanset om du arkiverer historiske data, udfører komplekse analyser eller forbereder data til maskinlæring, forenkler denne forbindelse processen og gør den tilgængelig for en bredere vifte af dataprofessionelle.
Hvis du er interesseret i at se, hvordan dataoverførslen fra Google BigQuery til Amazon S3 ved hjælp af Amazon AppFlow, så tag et kig på trin-for-trin video tutorial. I denne tutorial gennemgår vi hele processen, fra opsætning af forbindelsen til at køre dataoverførselsflowet. For mere information om Amazon AppFlow, besøg Amazon App Flow.
Om forfatterne
![]() Kartikay Khator er en løsningsarkitekt på Global Life Science hos Amazon Web Services. Han brænder for at hjælpe kunder på deres cloud-rejse med fokus på AWS-analysetjenester. Han er en ivrig løber og nyder at vandre.
Kartikay Khator er en løsningsarkitekt på Global Life Science hos Amazon Web Services. Han brænder for at hjælpe kunder på deres cloud-rejse med fokus på AWS-analysetjenester. Han er en ivrig løber og nyder at vandre.
 Kamen Sharlandjiev er Sr. Big Data og ETL Solutions Architect og Amazon AppFlow-ekspert. Han har en mission om at gøre livet lettere for kunder, der står over for komplekse dataintegrationsudfordringer. Hans hemmelige våben? Fuldt administrerede, lavkode AWS-tjenester, der kan få arbejdet gjort med minimal indsats og ingen kodning.
Kamen Sharlandjiev er Sr. Big Data og ETL Solutions Architect og Amazon AppFlow-ekspert. Han har en mission om at gøre livet lettere for kunder, der står over for komplekse dataintegrationsudfordringer. Hans hemmelige våben? Fuldt administrerede, lavkode AWS-tjenester, der kan få arbejdet gjort med minimal indsats og ingen kodning.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/
- :har
- :er
- $OP
- 10
- 100
- 14
- 16
- 17
- 22
- 321
- 8
- 9
- a
- evne
- Om
- adgang
- adgangsstyring
- tilgængelig
- Konto
- tværs
- tilføje
- tilføjet
- Yderligere
- fremme
- tilpasse
- Allergi
- tillade
- tillade
- tillader
- også
- Amazon
- Amazonas Athena
- Amazon Web Services
- Amazon.com
- an
- analyse
- Analytisk
- analytics
- analysere
- ,
- enhver
- api
- applikationer
- Indløs
- passende
- arkitektur
- Arkiv
- ER
- AS
- At
- automatisk
- Automation
- undgå
- AWS
- AWS Lim
- AWS Management Console
- været
- før
- jf. nedenstående
- fordele
- mellem
- Big
- Big data
- bigquery
- Blog
- både
- bredere
- virksomhed
- by
- CAN
- Kan få
- kapaciteter
- kapacitet
- tilfælde
- tilfælde
- katalog
- Boligtype
- udfordringer
- afgifter
- Vælg
- kunde
- Cloud
- Kodning
- KOM
- fuldføre
- færdiggøre
- komplekse
- kompleksiteter
- tilslutning
- Konsol
- indeholder
- crawler
- skabe
- oprettet
- skaber
- Oprettelse af
- skik
- Kunder
- dagligt
- data
- dataadgang
- dataintegration
- datalager
- datastyret
- Database
- databaser
- datasæt
- beslutte
- Efterspørgsel
- demokratisering
- beskrivelse
- destination
- opdage
- forskelligartede
- dokumentation
- færdig
- lette
- lettere
- effektivt
- indsats
- ubesværet
- elimineret
- muliggøre
- muliggør
- Hele
- væsentlig
- Ether (ETH)
- begivenhed
- eksempel
- eksempler
- eksisterende
- ekspert
- udforske
- Eksponering
- ekstrakt
- vender
- få
- felt
- Fields
- filtrering
- Finde
- Fleksibilitet
- flow
- Flowing
- strømme
- Fokus
- følger
- efter
- Til
- forkant
- Frekvens
- hyppigt
- fra
- fuldt ud
- yderligere
- generere
- genereret
- få
- Global
- Globalt
- Google Analytics
- Googles
- indrømme
- gruppe
- seletøj
- Have
- he
- sundhedspleje
- hjælpe
- hiking
- hans
- historisk
- Hvordan
- HTML
- http
- HTTPS
- HubSpot
- IAM
- Identity
- identitets- og adgangsstyring
- in
- Herunder
- oplysninger
- indsigt
- anvisninger
- integrere
- integreret
- integration
- interesseret
- grænseflade
- Internet
- ind
- intuitiv
- IT
- selv
- Job
- rejse
- lige
- læring
- Licens
- Livet
- Life Science
- GRÆNSE
- Liste
- belastning
- placering
- langsigtet
- Se
- maskine
- machine learning
- lave
- Making
- lykkedes
- ledelse
- kort
- kortlægning
- mindste
- Mission
- mere
- bevægelse
- bevæge sig
- skal
- navn
- Naviger
- Navigation
- næsten
- nødvendig
- behov
- behov
- Ny
- nyligt
- ingen
- nu
- nummer
- oauth
- objekt
- objekter
- of
- on
- On-Demand
- kun
- opensource
- or
- ordrer
- organisationer
- i løbet af
- side
- brød
- del
- lidenskabelige
- patient
- udføre
- udfører
- Tilladelser
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- politik
- pop-up
- befolkning
- muligheder
- Indlæg
- Praktisk
- praksis
- forberede
- forudsætninger
- Eksempel
- behandle
- professionelle partnere
- projekt
- give
- leverer
- offentlige
- forespørgsler
- rækkevidde
- reducere
- erstatte
- påkrævet
- Krav
- Ressourcer
- svar
- begrænse
- resultere
- Resultater
- gennemgå
- Rich
- roller
- Kør
- runner
- kører
- SaaS
- salgsstyrke
- sap
- Scale
- planlægge
- planlagt
- Videnskab
- Søg
- Secret
- Sektion
- sikkert
- sikkerhed
- Sikkerhedsrisici
- se
- søger
- tjeneste
- ServiceNow
- Tjenester
- sæt
- indstilling
- indstillinger
- vist
- Shows
- signifikant
- Simpelt
- forenkle
- simulator
- SIX
- Software
- software som en tjeneste
- løsninger
- Løsninger
- Kilde
- Steps
- opbevaring
- butik
- opbevaret
- strømlining
- sådan
- syntetisk
- bord
- Tag
- at
- deres
- derefter
- denne
- trusler
- Gennem
- til
- nutidens
- top
- Top 10
- overførsel
- Overførsel
- Transformation
- transformationer
- omdanne
- tutorial
- typen
- under
- forståelse
- enestående
- Løfter sløret
- brug
- brug tilfælde
- anvendte
- Bruger
- ved brug af
- validering
- værdi
- Besøg
- gå
- går igennem
- ønsker
- Warehouse
- we
- web
- webservices
- ugentlig
- hvorvidt
- WHO
- vilje
- vindue
- med
- uden
- virker
- world
- dig
- Din
- youtube
- zephyrnet