I nutidens digitale tidsalder er data kernen i enhver organisations succes. Et af de mest brugte formater til udveksling af data er XML. At analysere XML-filer er afgørende af flere årsager. For det første bruges XML-filer i mange brancher, herunder finans, sundhedspleje og regering. Analyse af XML-filer kan hjælpe organisationer med at få indsigt i deres data, så de kan træffe bedre beslutninger og forbedre deres drift. Analyse af XML-filer kan også hjælpe med dataintegration, fordi mange applikationer og systemer bruger XML som et standarddataformat. Ved at analysere XML-filer kan organisationer nemt integrere data fra forskellige kilder og sikre konsistens på tværs af deres systemer. Men XML-filer indeholder semi-strukturerede, stærkt indlejrede data, hvilket gør det vanskeligt at få adgang til og analysere information, især hvis filen er stor og har komplekst, meget indlejret skema.
XML-filer er velegnede til applikationer, men de er muligvis ikke optimale til analysemotorer. For at forbedre forespørgselsydeevnen og muliggøre nem adgang i downstream-analysemotorer som f.eks Amazonas Athena, er det afgørende at forbehandle XML-filer til et søjleformat som Parquet. Denne transformation giver mulighed for forbedret effektivitet og brugervenlighed i analytiske arbejdsgange. I dette indlæg viser vi, hvordan man behandler XML-data ved hjælp af AWS Lim og Athena.
Løsningsoversigt
Vi udforsker to forskellige teknikker, der kan strømline din XML-filbehandlingsworkflow:
- Teknik 1: Brug en AWS Glue crawler og AWS Glue visuelle editor – Du kan bruge AWS Glue-brugergrænsefladen sammen med en crawler til at definere tabelstrukturen for dine XML-filer. Denne tilgang giver en brugervenlig grænseflade og er særligt velegnet til personer, der foretrækker en grafisk tilgang til håndtering af deres data.
- Teknik 2: Brug AWS Glue DynamicFrames med udledte og faste skemaer – Crawleren har en begrænsning, når det kommer til at behandle en enkelt række i XML-filer større end 1 MB. For at overvinde denne begrænsning bruger vi en AWS Glue notesbog til at konstruere AWS Glue
DynamicFrames, ved at bruge både udledte og faste skemaer. Denne metode sikrer effektiv håndtering af XML-filer med rækker, der er større end 1 MB.
I begge tilgange er vores ultimative mål at konvertere XML-filer til Apache Parquet-format, hvilket gør dem let tilgængelige for forespørgsler ved hjælp af Athena. Med disse teknikker kan du forbedre behandlingshastigheden og tilgængeligheden af dine XML-data, så du nemt kan udlede værdifuld indsigt.
Forudsætninger
Inden du starter denne øvelse, skal du udfylde følgende forudsætninger (disse gælder for begge teknikker):
- Download XML-filerne teknik1.xml , teknik2.xml.
- Upload filerne til en Amazon Simple Storage Service (Amazon S3) spand. Du kan uploade dem til den samme S3-bucket i forskellige mapper eller til forskellige S3-buckets.
- Opret en AWS identitets- og adgangsstyring (IAM)-rolle for dit ETL-job eller notesbog som instrueret i Konfigurer IAM-tilladelser for AWS Glue Studio.
- Tilføj en inline politik til din rolle med allerede: PassRole handling:
- Tilføj en tilladelsespolitik til rollen med adgang til din S3-bøtte.
Nu hvor vi er færdige med forudsætningerne, lad os gå videre til at implementere den første teknik.
Teknik 1: Brug en AWS Glue-crawler og den visuelle editor
Følgende diagram illustrerer den enkle arkitektur, som du kan bruge til at implementere løsningen.
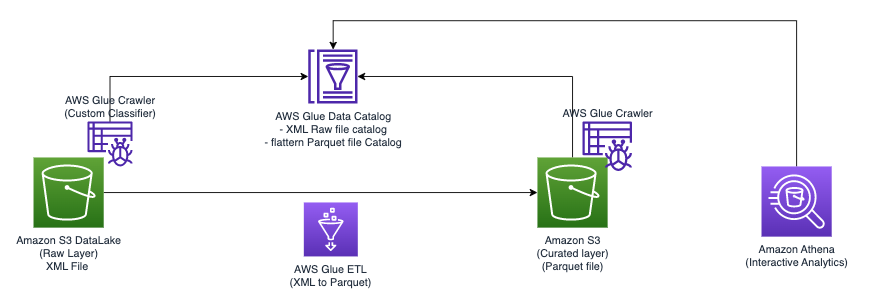
For at analysere XML-filer, der er gemt i Amazon S3 ved hjælp af AWS Glue og Athena, gennemfører vi følgende trin på højt niveau:
- Opret en AWS Glue-crawler for at udtrække XML-metadata og opret en tabel i AWS Glue Data Catalog.
- Bearbejd og transformer XML-data til et format (som Parket), der passer til Athena, ved hjælp af et AWS-limudtræk, transformer og indlæs (ETL) job.
- Konfigurer og kør et AWS Glue-job via AWS Glue-konsollen eller AWS kommandolinjegrænseflade (AWS CLI).
- Brug de behandlede data (i Parket-format) med Athena-tabeller, hvilket muliggør SQL-forespørgsler.
- Brug den brugervenlige grænseflade i Athena til at analysere XML-dataene med SQL-forespørgsler på dine data gemt i Amazon S3.
Denne arkitektur er en skalerbar, omkostningseffektiv løsning til at analysere XML-data på Amazon S3 ved hjælp af AWS Glue og Athena. Du kan analysere store datasæt uden kompleks infrastrukturstyring.
Vi bruger AWS Glue-crawleren til at udtrække XML-filmetadata. Du kan vælge standard AWS Glue-klassificering til almindelig XML-klassificering. Det registrerer automatisk XML-datastruktur og -skema, hvilket er nyttigt til almindelige formater.
Vi bruger også en brugerdefineret XML-klassifikator i denne løsning. Det er designet til specifikke XML-skemaer eller -formater, hvilket tillader præcis metadataudtræk. Dette er ideelt til ikke-standard XML-formater, eller når du har brug for detaljeret kontrol over klassificering. En tilpasset klassifikator sikrer, at kun nødvendige metadata udtrækkes, hvilket forenkler downstream-behandling og analyseopgaver. Denne tilgang optimerer brugen af dine XML-filer.
Følgende skærmbillede viser et eksempel på en XML-fil med tags.
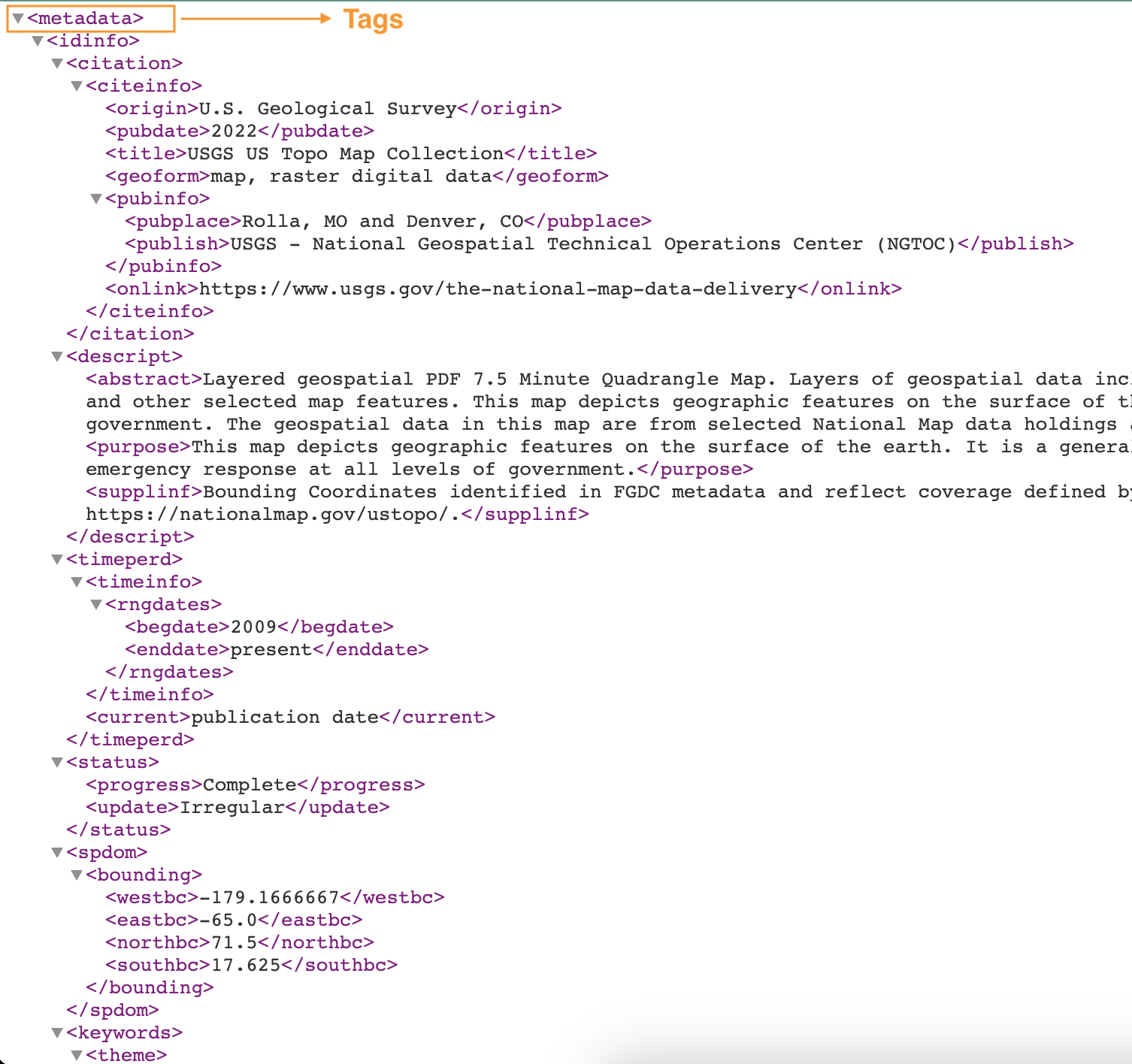
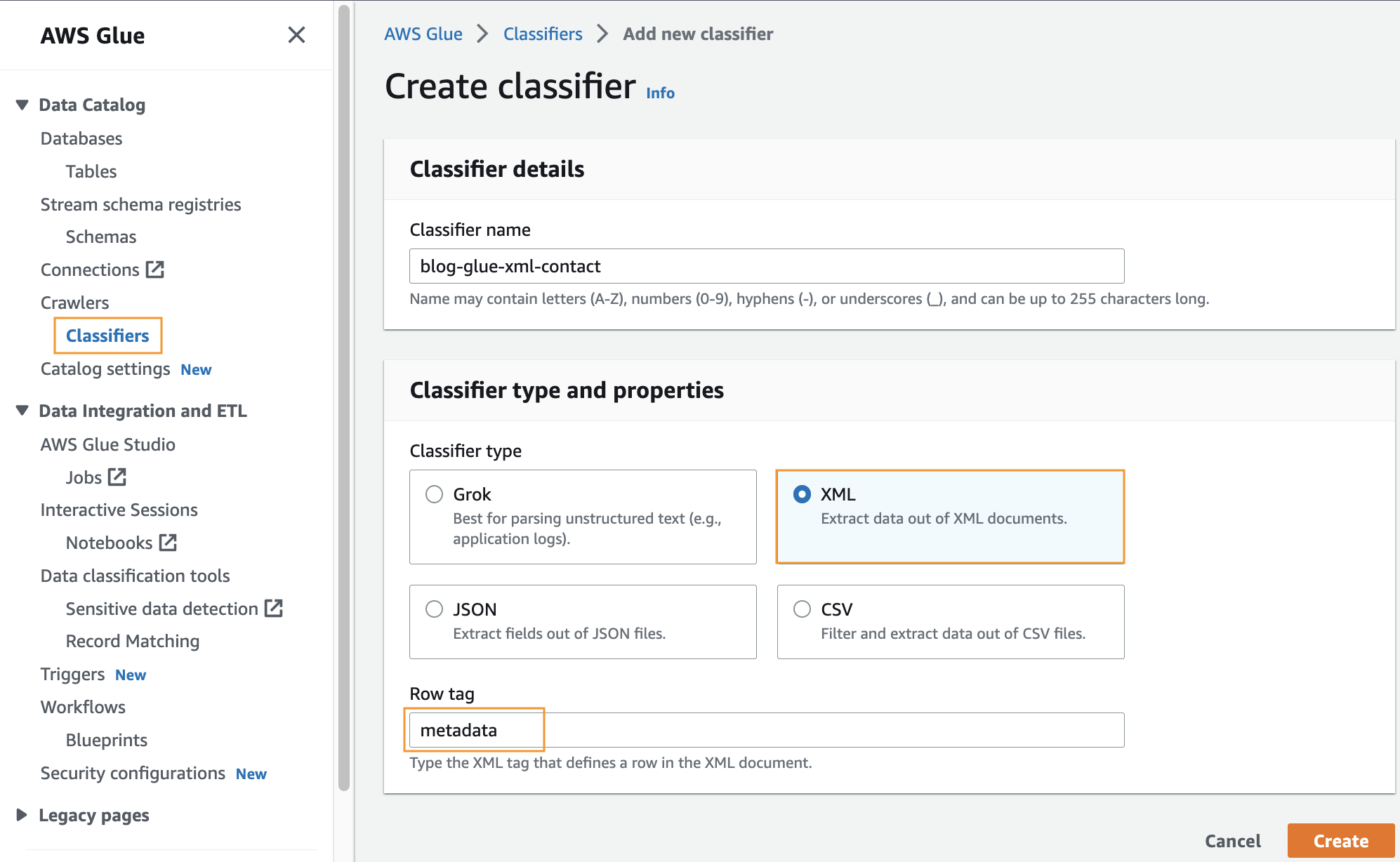
Opret en brugerdefineret klassificering
I dette trin opretter du en brugerdefineret AWS Glue-klassificering for at udtrække metadata fra en XML-fil. Udfør følgende trin:
- På AWS Glue-konsollen, under Crawlere i navigationsruden skal du vælge Klassificører.
- Vælg Tilføj klassificering.
- Type XML som klassificeringstype.
- Indtast et navn til klassificeringen, som f.eks
blog-glue-xml-contact. - Til Rækkemærke, skal du indtaste navnet på det rodtag, der indeholder metadataene (f.eks.
metadata). - Vælg Opret.
Opret en AWS Glue Crawler til at crawle xml-fil
I dette afsnit opretter vi en Glue Crawler til at udtrække metadataene fra XML-filen ved hjælp af kundeklassificeringen oprettet i det foregående trin.
Opret en database
- Gå til AWS Lim konsol, vælg Databaser i navigationsruden.
- Klik på Tilføj database.
- Angiv et navn som f.eks
blog_glue_xml - Vælg Opret Database
Opret en webcrawler
Udfør følgende trin for at oprette din første webcrawler:
- På AWS Glue-konsollen skal du vælge Crawlere i navigationsruden.
- Vælg Opret crawler.
- På Indstil crawleregenskaber side, skal du angive et navn til den nye webcrawler (f.eks
blog-glue-parquet), vælg derefter Næste. - På Vælg datakilder og klassifikatorer side, vælg Not Yet under Datakildekonfiguration.
- Vælg Tilføj et datalager.
- Til S3 sti, gennemse til
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Sørg for at vælge XML-mappen i stedet for filen i mappen.
- Lad resten af mulighederne være standard, og vælg Tilføj en S3-datakilde.
- Udvid Brugerdefinerede klassifikatorer – valgfrit, vælg blog-lim-xml-contact, og vælg derefter Næste og behold resten af mulighederne som standard.
- Vælg din IAM-rolle eller vælg Opret ny IAM-rolle, tilføj suffikset
glue-xml-contact(for eksempel,AWSGlueServiceNotebookRoleBlog), og vælg Næste. - På Indstil output og planlægning side, under Konfiguration af output, vælg
blog_glue_xmlforum Måldatabase. - Indtast
console_som præfiks tilføjet til tabeller (valgfrit) og under Crawler tidsplan, behold frekvensen indstillet til On demand. - Vælg Næste.
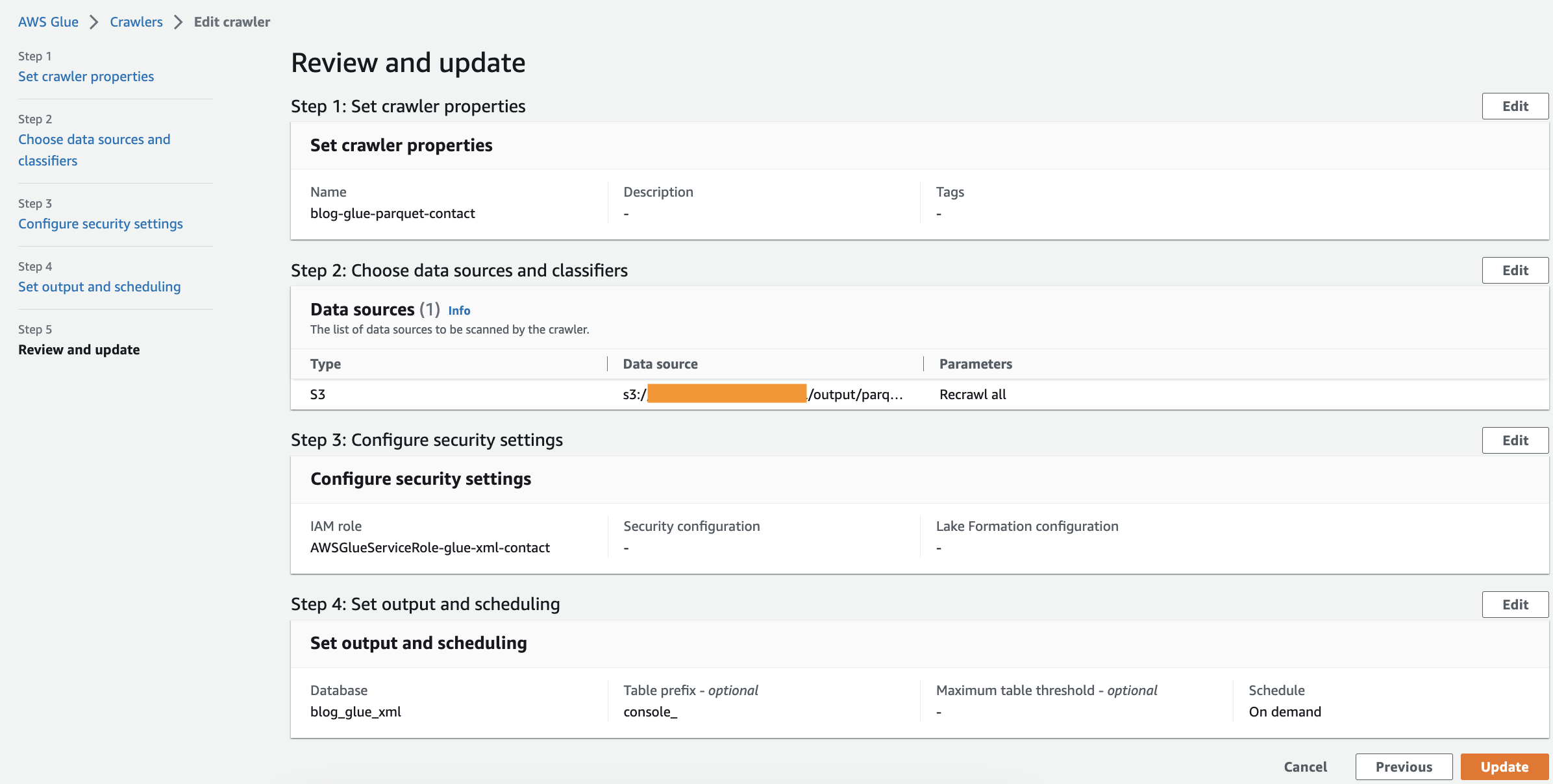
- Gennemgå alle parametre og vælg Opret crawler.
Kør webcrawleren
Når du har oprettet webcrawleren, skal du udføre følgende trin for at køre den:
- På AWS Glue-konsollen skal du vælge Crawlere i navigationsruden.
- Åbn den webcrawler, du har oprettet, og vælg Kør.
Webcrawleren vil tage 1-2 minutter at fuldføre.
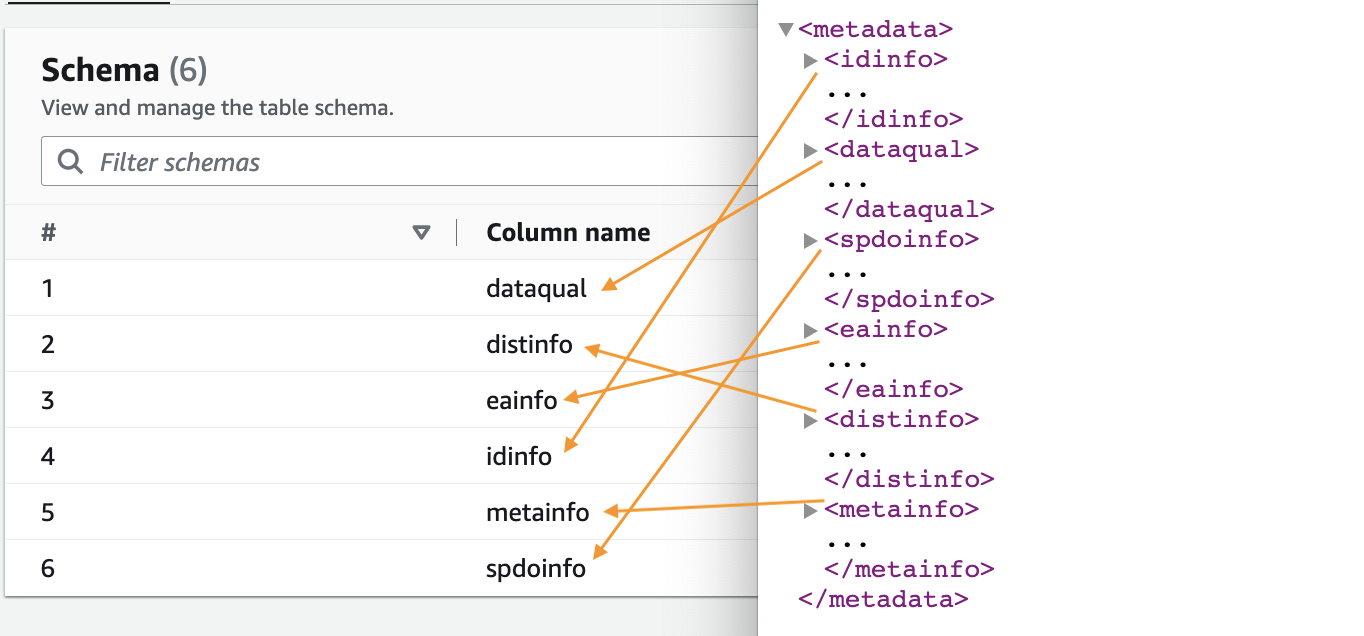
- Når webcrawleren er færdig, skal du vælge Databaser i navigationsruden.
- Vælg den database, du har oprettet, og vælg tabelnavnet for at se skemaet udtrukket af crawleren.
Opret et AWS Glue-job for at konvertere XML til Parket-format
I dette trin opretter du et AWS Glue Studio-job for at konvertere XML-filen til en Parket-fil. Udfør følgende trin:
- På AWS Glue-konsollen skal du vælge Karriere i navigationsruden.
- Under Skab job, Vælg Visuel med et tomt lærred.
- Vælg Opret.
- Omdøb jobbet til
blog_glue_xml_job.
Nu har du en tom AWS Glue Studio visuel jobeditor. Øverst i editoren er fanerne for forskellige visninger.
- Vælg den Script fanen for at se en tom skal af AWS Glue ETL-scriptet.
Efterhånden som vi tilføjer nye trin i den visuelle editor, opdateres scriptet automatisk.
- Vælg den Joboplysninger fanen for at se alle jobkonfigurationer.
- Til IAM rolle, vælg
AWSGlueServiceNotebookRoleBlog. - Til Lim version, vælg Lim 4.0 – Support Spark 3.3, Scala 2, Python 3.
- sæt Ønsket antal arbejdere til 2.
- sæt Antal genforsøg til 0.
- Vælg den Visuel fanen for at gå tilbage til den visuelle editor.
- På Kilde rullemenu, vælg AWS Glue Data Katalog.
- På Datakildeegenskaber – Datakatalog fanen, skal du angive følgende oplysninger:
- Til Database, vælg
blog_glue_xml. - Til Bordlampe, skal du vælge den tabel, der starter med navnet console_, som webcrawleren oprettede (f.eks.
console_geologicalsurvey).
- Til Database, vælg
- På Nodeegenskaber fanen, skal du angive følgende oplysninger:
- Skift Navn til
geologicalsurveydatasæt. - Vælg Handling og transformationen Skift skema (anvend kortlægning).
- Vælg Nodeegenskaber og ændre navnet på transformationen fra Change Schema (Apply Mapping) til
ApplyMapping. - På mål menu, vælg S3.
- Skift Navn til
- På Datakildeegenskaber – S3 fanen, skal du angive følgende oplysninger:
- Til dannet, Vælg parket.
- Til Komprimeringstype, Vælg ukomprimeret.
- Til S3 kildetype, Vælg S3 placering.
- Til S3 URL, gå ind
s3://${BUCKET_NAME}/output/parquet/. - Vælg Node egenskaber og ændre navnet til
Output.
- Vælg Gem for at redde jobbet.
- Vælg Kør at køre jobbet.
Følgende skærmbillede viser jobbet i den visuelle editor.
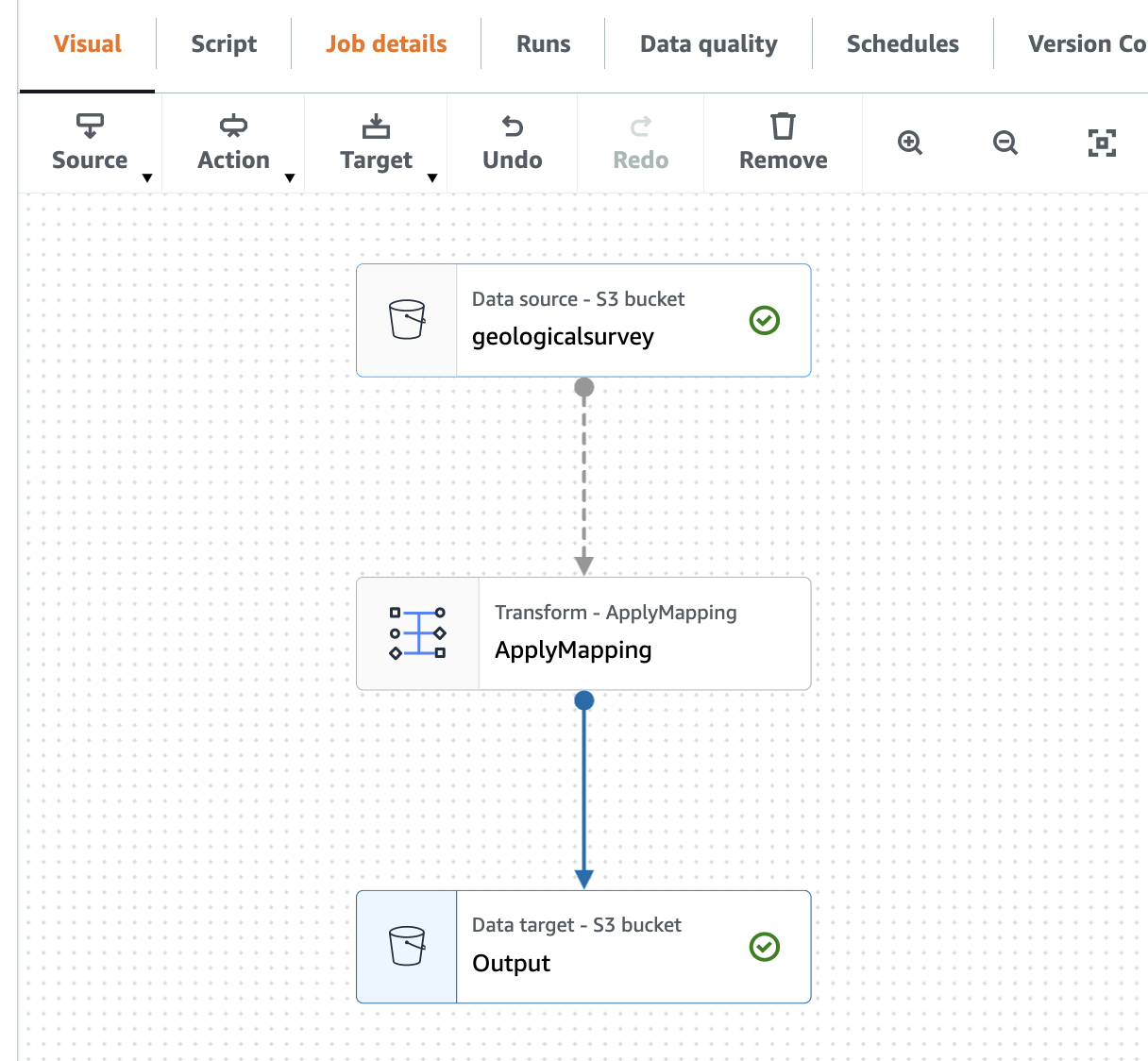
Opret en AWS Gue Crawler for at crawle Parket-filen
I dette trin opretter du en AWS Glue-crawler til at udtrække metadata fra den parketfil, du oprettede ved hjælp af et AWS Glue Studio-job. Denne gang bruger du standardklassifikatoren. Udfør følgende trin:
- På AWS Glue-konsollen skal du vælge Crawlere i navigationsruden.
- Vælg Opret crawler.
- På Indstil crawleregenskaber side, angiv et navn til den nye crawler, såsom blog-lim-parket-kontakt, og vælg derefter Næste.
- På Vælg datakilder og klassifikatorer side, vælg Not Yet forum Datakildekonfiguration.
- Vælg Tilføj et datalager.
- Til S3 sti, gennemse til
s3://${BUCKET_NAME}/output/parquet/.
Sørg for at vælge parquet mappe i stedet for filen inde i mappen.
- Vælg din IAM-rolle oprettet under forudsætningssektionen, eller vælg Opret ny IAM-rolle (for eksempel,
AWSGlueServiceNotebookRoleBlog), og vælg Næste. - På Indstil output og planlægning side, under Konfiguration af output, vælg
blog_glue_xmlforum Database. - Indtast
parquet_som præfiks tilføjet til tabeller (valgfrit) og under Crawler tidsplan, behold frekvensen indstillet til On demand. - Vælg Næste.
- Gennemgå alle parametre og vælg Opret crawler.
Nu kan du køre crawleren, som tager 1-2 minutter at fuldføre.

Du kan forhåndsvise det nyoprettede skema for Parket-filen i AWS Glue Data Catalog, som ligner skemaet for XML-filen.
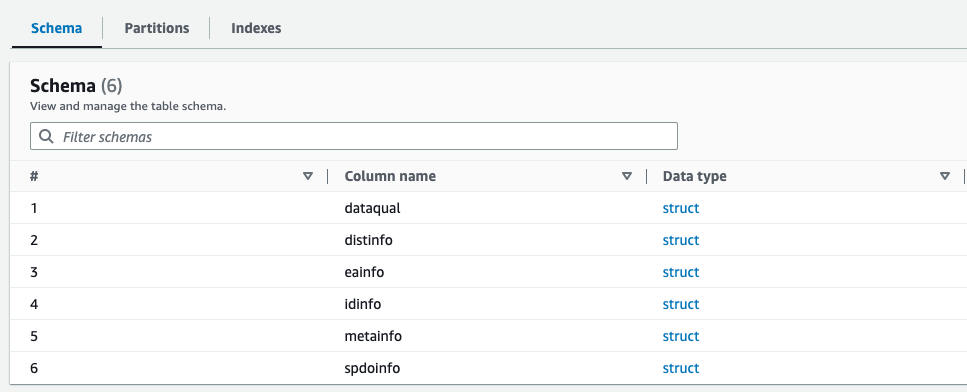
Vi har nu data, der er egnet til brug med Athena. I næste afsnit udfører vi dataforespørgsler ved hjælp af Athena.
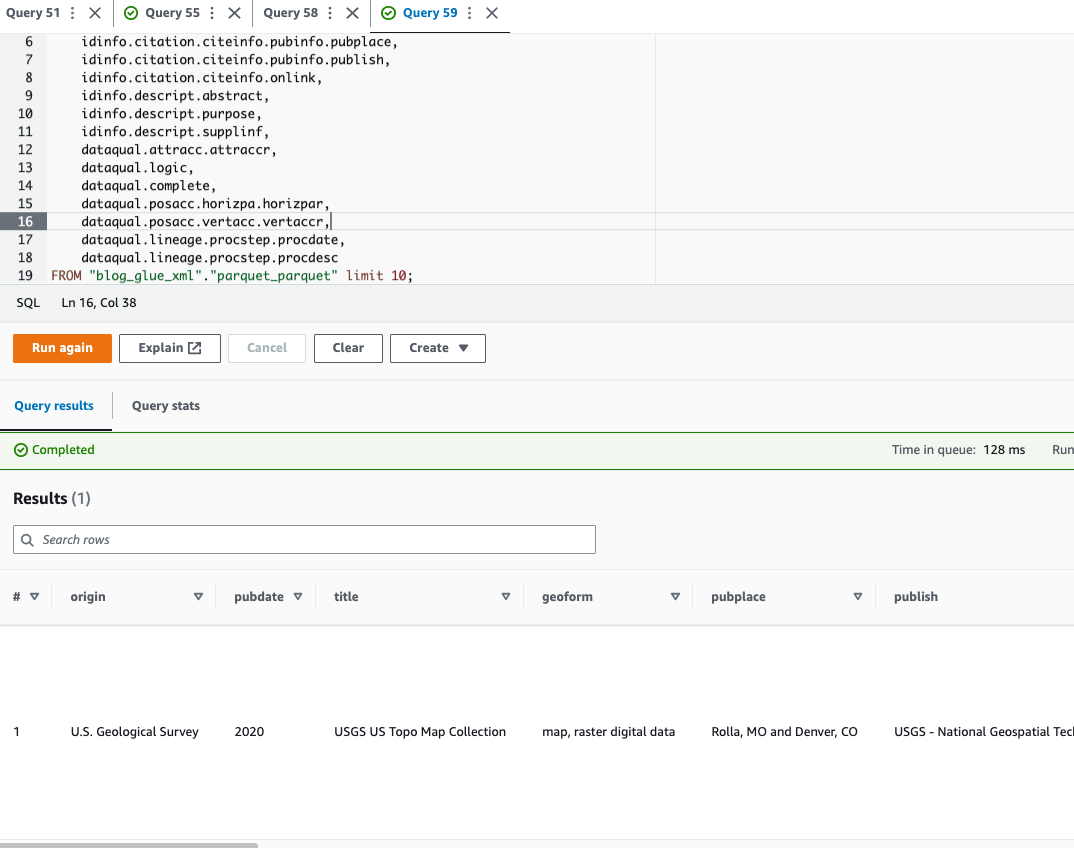
Forespørg på Parket-filen ved hjælp af Athena
Athena understøtter ikke forespørgsler om XML filformat, hvorfor du konverterede XML-filen til Parquet for mere effektiv dataforespørgsel og brug punktnotation at forespørge på komplekse typer og indlejrede strukturer.
Følgende eksempelkode bruger punktnotation til at forespørge indlejrede data:
Nu hvor vi har gennemført teknik 1, lad os gå videre med at lære om teknik 2.
Teknik 2: Brug AWS Glue DynamicFrames med udledte og faste skemaer
I det foregående afsnit dækkede vi processen med at håndtere en lille XML-fil ved hjælp af en AWS Glue-crawler til at generere en tabel, et AWS Glue-job til at konvertere filen til Parket-format og Athena for at få adgang til Parket-dataene. Imidlertid støder crawleren på begrænsninger, når det kommer til at behandle XML-filer, der overskrider 1 MB i størrelse. I dette afsnit dykker vi ned i emnet batchbehandling af større XML-filer, hvilket nødvendiggør yderligere parsing for at udtrække individuelle hændelser og udføre analyser ved hjælp af Athena.
Vores tilgang involverer at læse XML-filerne gennem AWS Glue DynamicFrames, der anvender både udledte og faste skemaer. Derefter udtrækker vi de enkelte arrangementer i Parket format ved hjælp af relationalisere transformation, hvilket gør det muligt for os at forespørge og analysere dem problemfrit ved hjælp af Athena.
For at implementere denne løsning skal du gennemføre følgende trin på højt niveau:
- Opret en AWS Glue-notesbog for at læse og analysere XML-filen.
- Brug
DynamicFramesmedInferSchemafor at læse XML-filen. - Brug relationaliseringsfunktionen til at fjerne alle arrays.
- Konverter dataene til parketformat.
- Spørg parketdataene ved hjælp af Athena.
- Gentag de foregående trin, men denne gang videregive et skema til
DynamicFramesi stedet for at brugeInferSchema.
XML-filen for befolkningsdata for elektriske køretøjer har en response tag på dets rodniveau. Dette tag indeholder en række af row tags, som er indlejret i det. Rækkemærket er et array, der indeholder et sæt af andre rækkemærker, som giver information om et køretøj, herunder dets mærke, model og andre relevante detaljer. Følgende skærmbillede viser et eksempel.

Opret en AWS Glue Notebook
For at oprette en AWS Glue notesbog skal du udføre følgende trin:
- Åbne AWS Glue Studio konsol, vælg Karriere i navigationsruden.
- Type Jupyter Notebook Og vælg Opret.
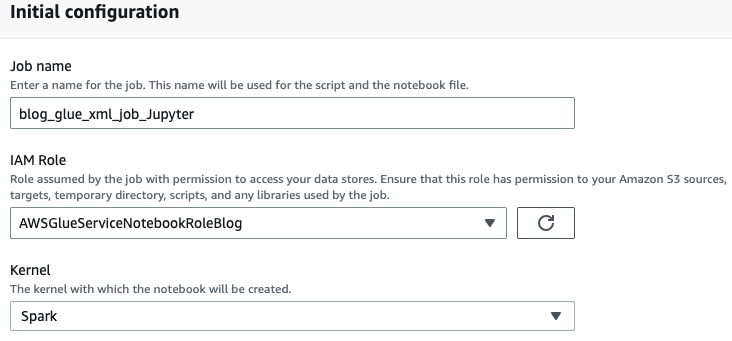
- Indtast et navn til dit AWS Lim-job, som f.eks
blog_glue_xml_job_Jupyter. - Vælg den rolle, du har oprettet i forudsætningerne (
AWSGlueServiceNotebookRoleBlog).
AWS Glue-notebooken leveres med et allerede eksisterende eksempel, der viser, hvordan man forespørger i en database og skriver outputtet til Amazon S3.
- Juster timeoutet (i minutter) som vist på det følgende skærmbillede, og kør cellen for at oprette den interaktive AWS Glue-session.
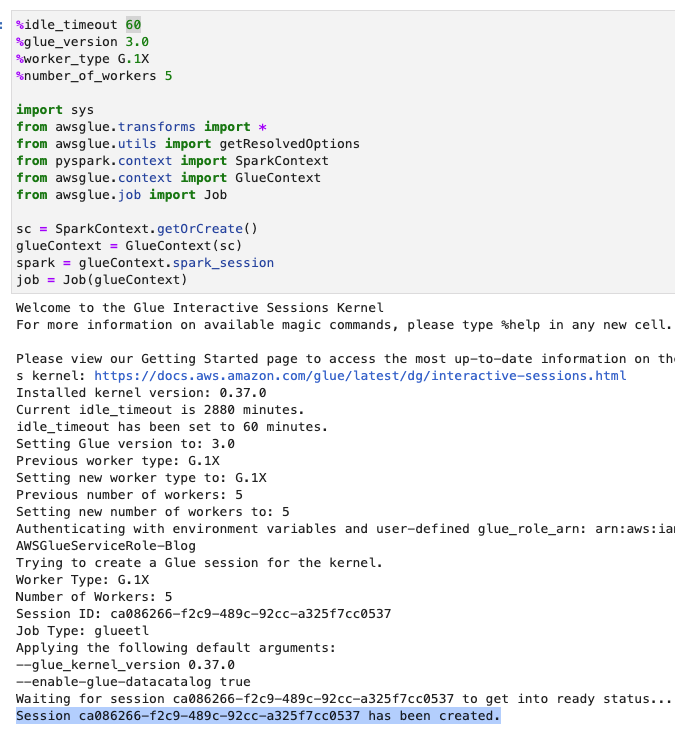
Opret grundlæggende variabler
Når du har oprettet den interaktive session, skal du i slutningen af notesbogen oprette en ny celle med følgende variabler (angiv dit eget bøttenavn):
Læs XML-filen, der udleder skemaet
Hvis du ikke sender et skema til DynamicFrame, vil det udlede skemaet for filerne. For at læse dataene ved hjælp af en dynamisk ramme kan du bruge følgende kommando:
Udskriv DynamicFrame-skemaet
Udskriv skemaet med følgende kode:
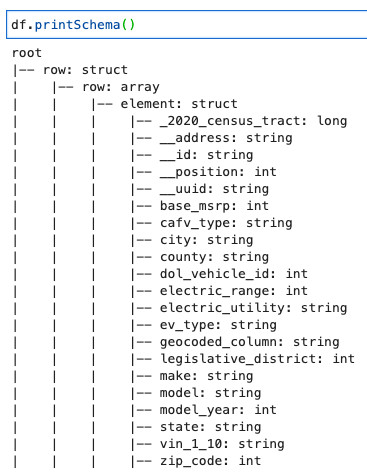
Skemaet viser en indlejret struktur med en row array, der indeholder flere elementer. For at fjerne denne struktur i linjer kan du bruge AWS-limen relationalisere transformation:
Vi er kun interesserede i informationen indeholdt i rækkearrayet, og vi kan se skemaet ved at bruge følgende kommando:
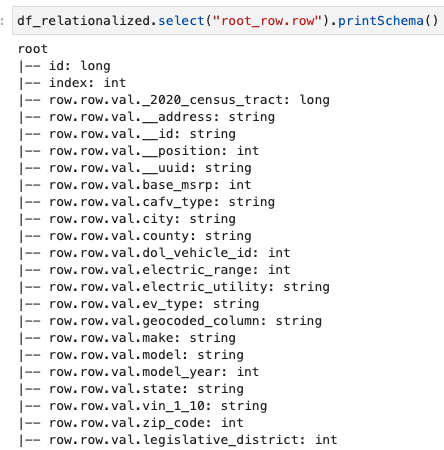
Kolonnenavnene indeholder row.row, som svarer til matrixstrukturen og matrixkolonnen i datasættet. Vi omdøber ikke kolonnerne i dette indlæg; for instruktioner til at gøre det, se Automatiser dynamisk kortlægning og omdøbning af kolonnenavne i datafiler ved hjælp af AWS Glue: Part 1. Derefter kan du konvertere dataene til Parket-format og oprette AWS Glue-tabellen ved hjælp af følgende kommando:
AWS Lim DynamicFrame indeholder funktioner, som du kan bruge i dit ETL-script til at oprette og opdatere et skema i datakataloget. Vi bruger updateBehavior parameter for at oprette tabellen direkte i datakataloget. Med denne tilgang behøver vi ikke at køre en AWS Glue-crawler, efter at AWS Glue-jobbet er fuldført.

Læs XML-filen ved at indstille et skema
En alternativ måde at læse filen på er ved at foruddefinere et skema. For at gøre dette skal du udføre følgende trin:
- Importer AWS Glue-datatyperne:
- Opret et skema til XML-filen:
- Send skemaet, når du læser XML-filen:
- Fjern datasættet som før:
- Konverter datasættet til Parket og opret AWS Glue-tabellen:
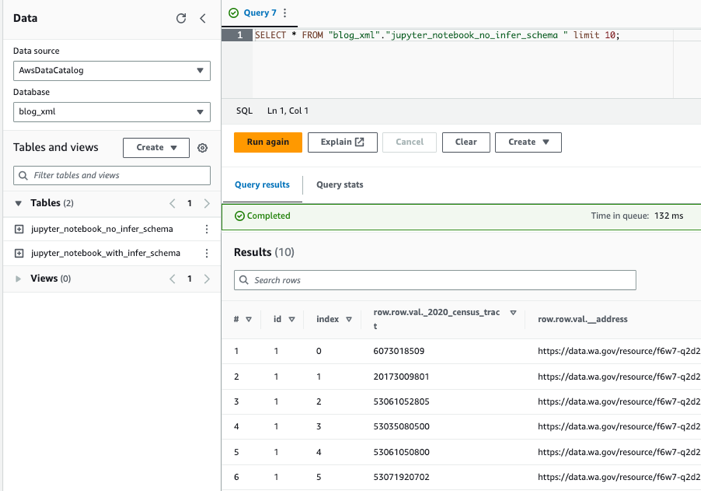
Forespørg tabellerne ved hjælp af Athena
Nu hvor vi har oprettet begge tabeller, kan vi forespørge tabellerne ved hjælp af Athena. For eksempel kan vi bruge følgende forespørgsel:
Clean Up
I dette indlæg oprettede vi en IAM-rolle, en AWS Glue Jupyter-notesbog og to tabeller i AWS Glue Data Catalog. Vi uploadede også nogle filer til en S3-bøtte. For at rydde op i disse objekter skal du udføre følgende trin:
- På IAM-konsollen skal du slette den rolle, du har oprettet.
- På AWS Glue Studio-konsollen skal du slette den tilpassede klassificering, crawler, ETL-job og Jupyter-notebook.
- Naviger til AWS Glue Data Catalog og slet de tabeller, du har oprettet.
- På Amazon S3-konsollen skal du navigere til den bøtte, du har oprettet, og slette de navngivne mapper
temp,infer_schemaogno_infer_schema.
Nøgleforsøg
I AWS Glue er der en funktion kaldet InferSchema i AWS Lim DynamicFrames. Den finder automatisk ud af strukturen af en dataramme baseret på de data, den indeholder. I modsætning hertil betyder at definere et skema eksplicit at angive, hvordan datarammens struktur skal være, før dataene indlæses.
XML, som er et tekstbaseret format, begrænser ikke datatyperne i dets kolonner. Dette kan forårsage problemer med InferSchema-funktionen. For eksempel, i den første kørsel resulterer en fil med kolonne A med værdien 2 i en Parket-fil med kolonne A som et heltal. I anden kørsel har en ny fil kolonne A med værdien C, hvilket fører til en Parketfil med kolonne A som en streng. Nu er der to filer på S3, hver med en kolonne A med forskellige datatyper, hvilket kan skabe problemer nedstrøms.
Det samme sker med komplekse datatyper som indlejrede strukturer eller arrays. For eksempel, hvis en fil har én tag-indgang kaldet transaction, det udledes som en struktur. Men hvis en anden fil har det samme tag, udledes det som et array
På trods af disse datatypeproblemer, InferSchema er nyttigt, når du ikke kender skemaet, eller det er upraktisk at definere et manuelt. Det er dog ikke ideelt til store eller konstant skiftende datasæt. At definere et skema er mere præcist, især med komplekse datatyper, men har sine egne problemer, som at kræve manuel indsats og være ufleksibel over for dataændringer.
InferSchema har begrænsninger, såsom ukorrekt datatypeslutning og problemer med håndtering af null-værdier. At definere et skema har også begrænsninger, såsom manuel indsats og potentielle fejl.
Valget mellem at udlede og definere et skema afhænger af projektets behov. InferSchema er fantastisk til hurtig udforskning af små datasæt, hvorimod at definere et skema er bedre for større, komplekse datasæt, der kræver nøjagtighed og konsistens. Overvej afvejninger og begrænsninger for hver metode for at vælge, hvad der passer bedst til dit projekt.
Konklusion
I dette indlæg undersøgte vi to teknikker til at administrere XML-data ved hjælp af AWS Glue, hver skræddersyet til at imødekomme specifikke behov og udfordringer, du kan støde på.
Teknik 1 tilbyder en brugervenlig vej til dem, der foretrækker en grafisk grænseflade. Du kan bruge en AWS Glue-crawler og den visuelle editor til ubesværet at definere tabelstrukturen for dine XML-filer. Denne tilgang forenkler datahåndteringsprocessen og er især tiltalende for dem, der leder efter en ligetil måde at håndtere deres data på.
Vi erkender dog, at crawleren har sine begrænsninger, specielt når det drejer sig om XML-filer med rækker større end 1 MB. Det er her teknik 2 kommer til undsætning. Ved at udnytte AWS Glue DynamicFrames med både udledte og faste skemaer og ved at bruge en AWS Glue-notesbog kan du effektivt håndtere XML-filer af enhver størrelse. Denne metode giver en robust løsning, der sikrer problemfri behandling selv for XML-filer med rækker, der overstiger 1 MB-begrænsningen.
Når du navigerer i datahåndteringens verden, giver disse teknikker i dit værktøjssæt dig mulighed for at træffe informerede beslutninger baseret på de specifikke krav til dit projekt. Uanset om du foretrækker enkelheden ved teknik 1 eller skalerbarheden af teknik 2, giver AWS Glue den fleksibilitet, du har brug for til at håndtere XML-data effektivt.
Om forfatterne
 Navnit Shuklafungerer som AWS Specialist Solution Architect med fokus på Analytics. Han besidder en stærk entusiasme for at hjælpe kunder med at opdage værdifuld indsigt fra deres data. Gennem sin ekspertise konstruerer han innovative løsninger, der sætter virksomheder i stand til at nå frem til informerede, datadrevne valg. Navnit Shukla er især den dygtige forfatter til bogen med titlen "Data-strid om AWS.
Navnit Shuklafungerer som AWS Specialist Solution Architect med fokus på Analytics. Han besidder en stærk entusiasme for at hjælpe kunder med at opdage værdifuld indsigt fra deres data. Gennem sin ekspertise konstruerer han innovative løsninger, der sætter virksomheder i stand til at nå frem til informerede, datadrevne valg. Navnit Shukla er især den dygtige forfatter til bogen med titlen "Data-strid om AWS.
 Patrick Muller arbejder som Senior Data Lab Architect hos AWS. Hans hovedansvar er at hjælpe kunder med at omsætte deres ideer til et produktionsklart dataprodukt. I sin fritid nyder Patrick at spille fodbold, se film og rejse.
Patrick Muller arbejder som Senior Data Lab Architect hos AWS. Hans hovedansvar er at hjælpe kunder med at omsætte deres ideer til et produktionsklart dataprodukt. I sin fritid nyder Patrick at spille fodbold, se film og rejse.
 Amogh Gaikwad er Senior Solutions Developer hos Amazon Web Services. Han hjælper globale kunder med at bygge og implementere AI/ML-løsninger på AWS. Hans arbejde er hovedsageligt fokuseret på computersyn og naturlig sprogbehandling og at hjælpe kunder med at optimere deres AI/ML-arbejdsbelastninger til bæredygtighed. Amogh har modtaget sin kandidatgrad i datalogi med speciale i maskinlæring.
Amogh Gaikwad er Senior Solutions Developer hos Amazon Web Services. Han hjælper globale kunder med at bygge og implementere AI/ML-løsninger på AWS. Hans arbejde er hovedsageligt fokuseret på computersyn og naturlig sprogbehandling og at hjælpe kunder med at optimere deres AI/ML-arbejdsbelastninger til bæredygtighed. Amogh har modtaget sin kandidatgrad i datalogi med speciale i maskinlæring.
 Sheela Sonone er Senior Resident Architect hos AWS. Hun hjælper AWS-kunder med at træffe informerede valg og afvejninger om at accelerere deres data, analyser og AI/ML-arbejdsbelastninger og implementeringer. I sin fritid nyder hun at bruge tid sammen med sin familie - normalt på tennisbaner.
Sheela Sonone er Senior Resident Architect hos AWS. Hun hjælper AWS-kunder med at træffe informerede valg og afvejninger om at accelerere deres data, analyser og AI/ML-arbejdsbelastninger og implementeringer. I sin fritid nyder hun at bruge tid sammen med sin familie - normalt på tennisbaner.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Om
- ABSTRACT
- accelererende
- adgang
- tilgængelighed
- gennemført
- nøjagtighed
- tværs
- Handling
- tilføje
- tilføjet
- Yderligere
- adresse
- Efter
- alder
- AI / ML
- Alle
- tillade
- tillade
- tillader
- også
- alternativ
- Amazon
- Amazonas Athena
- Amazon Web Services
- an
- analyse
- analytics
- analysere
- analysere
- ,
- En anden
- enhver
- Apache
- tiltrækkende
- applikationer
- Indløs
- tilgang
- tilgange
- arkitektur
- ER
- Array
- AS
- hjælpe
- bistår
- At
- forfatter
- automatisk
- til rådighed
- AWS
- AWS Lim
- tilbage
- baseret
- grundlæggende
- BE
- fordi
- før
- begynde
- være
- BEDSTE
- Bedre
- mellem
- blank
- bog
- både
- bygge
- virksomheder
- men
- by
- kaldet
- CAN
- katalog
- Årsag
- celle
- udfordringer
- lave om
- Ændringer
- skiftende
- valg
- Vælg
- By
- klassificering
- kunder
- kode
- Kolonne
- Kolonner
- KOM
- kommer
- Fælles
- almindeligt
- fuldføre
- Afsluttet
- komplekse
- computer
- Datalogi
- Computer Vision
- betingelse
- Adfærd
- sammenholdt
- Overvej
- Konsol
- konstant
- begrænsninger
- konstruere
- indeholder
- indeholdt
- indeholder
- kontrast
- kontrol
- konvertere
- konverteret
- omkostningseffektiv
- omkostningseffektiv løsning
- amt
- Domstole
- dækket
- crawler
- skabe
- oprettet
- Oprettelse af
- afgørende
- skik
- kunde
- Kunder
- data
- dataintegration
- datastyring
- datastyret
- Database
- datasæt
- beskæftiger
- afgørelser
- Standard
- definere
- definere
- dykke
- demonstrerer
- afhænger
- indsætte
- konstrueret
- detaljeret
- detaljer
- Udvikler
- forskellige
- svært
- digital
- digitale tidsalder
- direkte
- opdage
- distinkt
- do
- Er ikke
- færdig
- Dont
- DOT
- i løbet af
- dynamisk
- hver
- lette
- nemt
- let
- editor
- effekt
- effektivt
- effektivitet
- effektiv
- effektivt
- indsats
- ubesværet
- Elektrisk
- elbil
- elementer
- anvendelse
- bemyndige
- bemyndiger
- tom
- muliggøre
- muliggør
- møde
- ende
- Motorer
- forbedre
- sikre
- sikrer
- Indtast
- entusiasme
- indrejse
- fejl
- især
- Ether (ETH)
- Endog
- begivenheder
- Hver
- eksempel
- overstige
- udveksling
- ekspertise
- udforskning
- udforske
- udforsket
- ekstrakt
- udvinding
- familie
- Feature
- Funktionalitet
- tal
- File (Felt)
- Filer
- finansiere
- Fornavn
- fast
- Fleksibilitet
- Fokus
- fokuserede
- efter
- Til
- format
- FRAME
- Gratis
- Frekvens
- fra
- funktion
- Gevinst
- generelle formål
- generere
- Global
- Go
- mål
- Regering
- stor
- håndtere
- Håndtering
- sker
- udnyttelse
- Have
- have
- he
- sundhedspleje
- Hjerte
- hjælpe
- hjælpe
- hjælper
- hende
- højt niveau
- stærkt
- hans
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- IAM
- ideal
- ideer
- Identity
- if
- illustrerer
- gennemføre
- implementeringer
- gennemføre
- importere
- Forbedre
- forbedret
- in
- Herunder
- individuel
- enkeltpersoner
- industrier
- oplysninger
- informeret
- Infrastruktur
- innovativ
- indvendig
- indsigt
- i stedet
- anvisninger
- integrere
- integration
- interaktiv
- interesseret
- grænseflade
- ind
- involverer
- spørgsmål
- IT
- ITS
- Job
- Karriere
- jpg
- json
- Jupyter Notebook
- Holde
- Kend
- lab
- Sprog
- stor
- større
- førende
- LÆR
- læring
- Niveau
- ligesom
- GRÆNSE
- begrænsning
- begrænsninger
- Line (linje)
- linjer
- belastning
- lastning
- logik
- leder
- maskine
- machine learning
- Main
- hovedsageligt
- lave
- Making
- ledelse
- styring
- manuel
- manuelt
- mange
- kortlægning
- herres
- Kan..
- midler
- Menu
- Metadata
- metode
- minutter
- model
- mere
- mere effektiv
- mest
- bevæge sig
- Film
- flere
- navn
- Som hedder
- navne
- Natural
- Naturligt sprog
- Natural Language Processing
- Naviger
- Navigation
- nødvendig
- Behov
- behov
- Ny
- nyligt
- næste
- især
- notesbog
- nu
- nummer
- objekter
- of
- Tilbud
- on
- ONE
- kun
- Produktion
- optimal
- Optimer
- Optimerer
- Indstillinger
- or
- ordrer
- organisationer
- Oprindelse
- Andet
- vores
- ud
- output
- i løbet af
- Overvind
- egen
- side
- brød
- parameter
- parametre
- del
- især
- passerer
- sti
- patrick
- udføre
- ydeevne
- Tilladelser
- pick
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- politik
- befolkning
- have
- Indlæg
- potentiale
- brug
- foretrække
- forudsætninger
- Eksempel
- tidligere
- problemer
- behandle
- bearbejdet
- forarbejdning
- Produkt
- projekt
- projekter
- egenskaber
- give
- giver
- offentliggøre
- formål
- Python
- forespørgsler
- Hurtig
- hellere
- Læs
- let
- Læsning
- årsager
- modtaget
- genkende
- henvise
- relevant
- Krav
- redde
- ressource
- svar
- ansvar
- REST
- begrænse
- begrænsning
- Resultater
- robust
- roller
- rod
- RÆKKE
- Kør
- samme
- Gem
- Scala
- Skalerbarhed
- skalerbar
- Videnskab
- script
- sømløs
- problemfrit
- Anden
- Sektion
- se
- senior
- Tjenester
- Session
- sæt
- indstilling
- flere
- hun
- Shell
- bør
- Vis
- vist
- Shows
- lignende
- Simpelt
- enkelhed
- forenkle
- enkelt
- Størrelse
- lille
- So
- Fodbold
- løsninger
- Løsninger
- nogle
- Kilde
- Kilder
- Spark
- specialist
- speciale
- specifikke
- specifikt
- hastighed
- udgifterne
- SQL
- standard
- starter
- Tilstand
- Statement
- angivelse
- Trin
- Steps
- opbevaring
- opbevaret
- ligetil
- strømline
- String
- stærk
- struktur
- strukturer
- Studio
- succes
- sådan
- egnede
- support
- sikker
- Bæredygtighed
- Systemer
- bord
- TAG
- skræddersyet
- Tag
- tager
- opgaver
- teknikker
- tennis
- end
- at
- oplysninger
- verdenen
- deres
- Them
- derefter
- Der.
- Disse
- de
- denne
- dem
- Gennem
- tid
- Titel
- titlen
- til
- nutidens
- toolkit
- top
- emne
- Transform
- Transformation
- Traveling
- Drejning
- tutorial
- to
- typen
- typer
- ultimativ
- under
- Opdatering
- opdateret
- uploadet
- us
- usability
- brug
- anvendte
- Bruger
- Brugergrænseflade
- brugervenlig
- bruger
- ved brug af
- sædvanligvis
- Ved hjælp af
- Værdifuld
- værdi
- Værdier
- køretøj
- udgave
- via
- Specifikation
- visninger
- vision
- ser
- Vej..
- we
- web
- webservices
- Hvad
- hvornår
- ud fra følgende betragtninger
- hvorvidt
- som
- WHO
- hvorfor
- vilje
- med
- inden for
- uden
- Arbejde
- workflow
- arbejdsgange
- virker
- world
- skriver
- XML
- dig
- Din
- zephyrnet