Amazon OpenSearch Service er en administreret tjeneste, der gør det nemt at sikre, implementere og betjene OpenSearch og ældre Elasticsearch-klynger i stor skala i AWS Cloud. Amazon OpenSearch Service sørger for alle ressourcer til din klynge, lancerer den og registrerer og erstatter automatisk fejlbehæftede noder, hvilket reducerer omkostningerne ved selvadministrerede infrastrukturer. Tjenesten gør det nemt for dig at udføre interaktiv loganalyse, applikationsovervågning i realtid, webstedssøgninger og mere ved at tilbyde de nyeste versioner af OpenSearch, understøttelse af 19 versioner af Elasticsearch (1.5 til 7.10 versioner) og visualiseringsfunktioner drevet af OpenSearch Dashboards og Kibana (1.5 til 7.10 versioner).
I den seneste servicesoftwareudgivelse har vi opdateret shard-allokeringslogikken til at være load-aware, så når shards omfordeles i tilfælde af knudefejl, forhindrer tjenesten overlevende knudepunkter i at blive overbelastet af shards, der tidligere har været vært på den mislykkede knude. Dette er især vigtigt for Multi-AZ-domæner for at give ensartet og forudsigelig klyngeydelse.
Hvis du gerne vil have mere baggrund om shard allokeringslogik generelt, så se venligst Afmystificerende Elasticsearch-shard-allokering.
Udfordringen
Et Amazon OpenSearch Service-domæne siges at være "afbalanceret", når antallet af noder er ligeligt fordelt på tværs af konfigurerede tilgængelighedszoner, og det samlede antal shards er fordelt ligeligt på tværs af alle tilgængelige knudepunkter uden koncentration af shards af et indeks på nogen. node. OpenSearch har også en egenskab kaldet "Zone Awareness", der, når den er aktiveret, sikrer, at den primære shard og dens tilsvarende replika er allokeret i forskellige tilgængelighedszoner. Hvis du har mere end én kopi af data, giver det bedre fejltolerance og tilgængelighed at have flere tilgængelighedszoner. I tilfælde af, at domænet skaleres ud eller skaleres i eller under svigt af node(r), omfordelter OpenSearch automatisk skårene mellem tilgængelige noder, mens de overholder allokeringsreglerne baseret på zonebevidsthed.
Mens shard-balanceringsprocessen sikrer, at shards er jævnt fordelt på tværs af tilgængelighedszoner, vil shards i nogle tilfælde, hvis der er en uventet fejl i en enkelt zone, blive omallokeret til de overlevende noder. Dette kan resultere i, at de overlevende noder bliver overvældet, hvilket påvirker klyngestabiliteten.
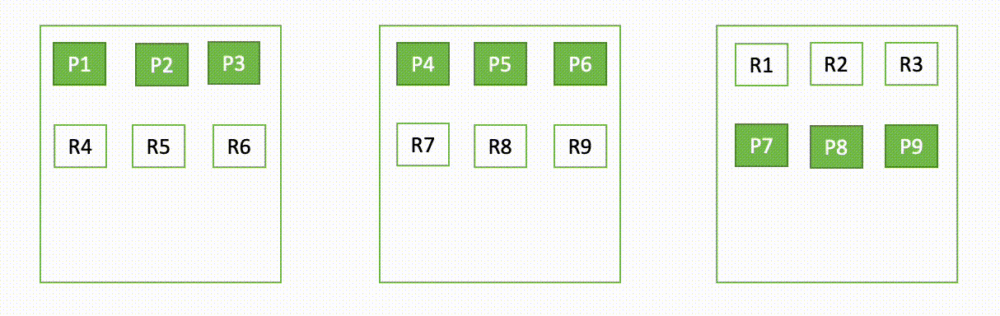
Hvis f.eks. én knude i en klynge med tre knudepunkter går ned, omdistribuerer OpenSearch de ikke-tildelte shards, som vist i det følgende diagram. Her repræsenterer "P" en primær shard-kopi, mens "R" repræsenterer en replika shard-kopi.

Denne adfærd af domænet kan forklares i to dele - under fejl og under genopretning.
Under fiasko
Et domæne, der er implementeret på tværs af flere tilgængelighedszoner, kan støde på flere typer fejl i løbet af dets livscyklus.
Komplet zonefejl
En klynge kan miste en enkelt tilgængelighedszone på grund af en række forskellige årsager og også alle noderne i den zone. I dag forsøger tjenesten at placere de tabte noder i de resterende sunde tilgængelighedszoner. Tjenesten forsøger også at genskabe de tabte shards i de resterende noder, mens den stadig følger tildelingsreglerne. Dette kan resultere i nogle utilsigtede konsekvenser.
- Når skårene fra den berørte zone omfordeles til sunde zoner, udløser de skårgendannelser, der kan øge forsinkelserne, da det bruger yderligere CPU-cyklusser og netværksbåndbredde.
- For en n-AZ, n-kopi-opsætning, (n>1), tildeles de overlevende n-1-tilgængelighedszoner den n-te shard-kopi, hvilket kan være uønsket, da det kan forårsage skævheder i shard-fordelingen, hvilket også kan resultere i ubalanceret trafik på tværs af knudepunkter. Disse noder kan blive overbelastet, hvilket fører til yderligere fejl.
Delvis zonefejl
I tilfælde af en delvis zonefejl, eller når domænet kun mister nogle af noderne i en tilgængelighedszone, forsøger Amazon OpenSearch Service at erstatte de mislykkede noder så hurtigt som muligt. Men i tilfælde af at det tager for lang tid at erstatte noderne, forsøger OpenSearch at allokere de ikke-tildelte shards af denne zone til de overlevende noder i tilgængelighedszonen. Hvis tjenesten ikke kan erstatte noderne i den berørte tilgængelighedszone, kan den allokere dem i den anden konfigurerede tilgængelighedszone, hvilket yderligere kan skævvride fordelingen af shards både på tværs og inden for zonen. Dette har igen utilsigtede konsekvenser.
- Hvis noderne på domænet ikke har nok lagerplads til at rumme de ekstra shards, kan domænet skriveblokeres, hvilket påvirker indekseringsoperationen.
- På grund af den skæve fordeling af shards kan domænet også opleve skæv trafik på tværs af noderne, hvilket yderligere kan øge latenserne eller timeouts for læse- og skriveoperationer.
Recovery
I dag, for at opretholde domænets ønskede nodeantal, lancerer Amazon OpenSearch Service dataknudepunkter i de resterende sunde tilgængelighedszoner, svarende til scenarierne beskrevet i fejlafsnittet ovenfor. For at sikre korrekt nodefordeling på tværs af alle tilgængelighedszoner efter en sådan hændelse, var manuel indgriben nødvendig af AWS.
Hvad ændrer sig
For at forbedre den overordnede fejlhåndtering og minimere virkningen af fejl på domænets sundhed og ydeevne, udfører Amazon OpenSearch Service følgende ændringer:
- Tvunget zonebevidsthed: OpenSearch har en allerede eksisterende shard-balanceringskonfiguration kaldet forceret bevidsthed, der bruges til at indstille de tilgængelighedszoner, som shards skal allokeres til. For eksempel, hvis du har en bevidsthedsattribut kaldet zone og konfigurerer noder i
zone1,zone2, kan du bruge tvungen opmærksomhed til at forhindre OpenSearch i at tildele replikaer, hvis kun én zone er tilgængelig:
Med denne eksempelkonfiguration, hvis du starter to noder med node.attr.zone indstillet til zone1 og opretter et indeks med fem shards og en replika, opretter OpenSearch indekset og tildeler de fem primære shards, men ingen replikaer. Replikaer tildeles kun én gang noder med node.attr.zone indstillet til zone2 er tilgængelige.
Amazon OpenSearch Service vil bruge den tvungne bevidsthedskonfiguration på Multi-AZ-domæner for at sikre, at shards kun tildeles i henhold til reglerne for zonebevidsthed. Dette ville forhindre den pludselige stigning i belastningen på knudepunkterne i de sunde tilgængelighedszoner.
- Load-Aware Shard Allocation: Amazon OpenSearch Service vil tage hensyn til faktorer som den tilvejebragte kapacitet, faktiske kapacitet og samlede shard-kopier for at beregne, om en knude er overbelastet med flere shards baseret på forventede gennemsnitlige shards pr. node. Det ville forhindre shard-tildeling, når en hvilken som helst knude har tildelt et shard-antal, der går ud over denne grænse.
Bemærk at enhver utildelt primære kopiering ville stadig være tilladt på den overbelastede node for at forhindre klyngen i et forestående datatab.
Tilsvarende, for at løse problemet med manuel gendannelse (som beskrevet i afsnittet Gendannelse ovenfor), foretager Amazon OpenSearch Service også ændringer i sin interne skaleringskomponent. Med de nyere ændringer på plads vil Amazon OpenSearch Service ikke starte noder i de resterende tilgængelighedszoner, selv når den gennemgår det tidligere beskrevne fejlscenarie.
Visualisering af den nuværende og nye adfærd
For eksempel er et Amazon OpenSearch Service-domæne konfigureret med 3-AZ, 6 dataknuder, 12 primære shards og 24 replika shards. Domænet er klargjort på tværs af AZ-1, AZ-2 og AZ-3 med to noder i hver af zonerne.
Nuværende shard allokering:
Samlet antal skår: 12 primære + 24 replika = 36 skår
Antal tilgængelighedszoner: 3
Antal skår pr. zone (zonebevidsthed er sand): 36/3 = 12
Antal noder pr. tilgængelighedszone: 2
Antal skår pr. node: 12/2 = 6
Følgende diagram giver en visuel repræsentation af domæneopsætningen. Cirklerne angiver antallet af skår, der er allokeret til noden. Amazon OpenSearch Service vil tildele seks shards pr. node.

Under en delvis zonefejl, hvor en knude i AZ-3 fejler, tildeles den fejlbehæftede knude til den resterende zone, og skårene i zonen omfordeles baseret på de tilgængelige knudepunkter. Efter ændringerne beskrevet ovenfor, vil klyngen ikke oprette en ny node eller omfordele shards efter fejl i noden.

I diagrammet ovenfor, med tabet af en node i AZ-3, ville Amazon OpenSearch Service forsøge at starte erstatningskapaciteten i samme zone. På grund af nogle afbrydelser kan zonen dog være svækket og vil ikke kunne starte udskiftningen. I et sådant tilfælde forsøger tjenesten at lancere underskudskapacitet i en anden sund zone, hvilket kan føre til zoneubalance på tværs af tilgængelighedszoner. Skår på den påvirkede zone bliver stoppet på den overlevende knude i samme zone. Men med den nye adfærd ville tjenesten forsøge at forsøge at lancere kapacitet i samme zone, men ville undgå at lancere underskudskapacitet i andre zoner for at undgå ubalance. Shard-allokatoren vil også sikre, at de overlevende noder ikke bliver overbelastet.

Tilsvarende, i tilfælde af at alle noder i AZ-3 går tabt, eller AZ-3 bliver svækket, henter Amazon OpenSearch Service de tabte noder i den resterende tilgængelighedszone og omfordeler også skårene på noderne. Efter de nye ændringer vil Amazon OpenSearch Service dog hverken allokere noder til den resterende zone, eller den vil forsøge at genallokere tabte shards til den resterende zone. Amazon OpenSearch Service vil vente på, at gendannelsen sker, og på at domænet vender tilbage til den oprindelige konfiguration efter gendannelse.
Hvis dit domæne ikke er klargjort med tilstrækkelig kapacitet til at modstå tabet af en tilgængelighedszone, kan du opleve et fald i gennemstrømningen for dit domæne. Det anbefales derfor på det kraftigste at følge den bedste praksis, mens du dimensionerer dit domæne, hvilket betyder, at du har tilstrækkelige ressourcer til rådighed til at modstå tabet af en enkelt tilgængelighedszone-fejl.

I øjeblikket, når domænet genoprettes, kræver tjenesten manuel indgriben for at balancere kapaciteten på tværs af tilgængelighedszoner, hvilket også involverer skårbevægelser. Men med den nye adfærd er der ikke behov for indgreb under genopretningsprocessen, fordi kapaciteten vender tilbage i den påvirkede zone, og skårene også automatisk allokeres til de genvundne noder. Dette sikrer, at der ikke er nogen konkurrerende prioriteringer på de resterende ressourcer.
Hvad du kan forvente
Når du har opdateret dit Amazon OpenSearch Service-domæne til den seneste servicesoftwareudgivelse, de domæner, der har været konfigureret med bedste praksis vil have mere forudsigelig ydeevne, selv efter at have mistet en eller mange dataknuder i en tilgængelighedszone. Der vil være reducerede tilfælde af shard overallokering i en node. Det er en god praksis at sørge for tilstrækkelig kapacitet til at kunne tolerere en enkelt zonefejl
Du kan til tider se et domæne blive gult under sådanne uventede fejl, da vi ikke vil tildele replika-shards til overbelastede noder. Det betyder dog ikke, at der vil være datatab i et velkonfigureret domæne. Vi vil stadig sørge for, at alle primærvalg bliver tildelt under udfaldene. Der er en automatiseret gendannelse på plads, som vil sørge for at balancere noderne i domænet og sikre, at replikaerne tildeles, når fejlen genoprettes.
Opdater servicesoftwaren på dit Amazon OpenSearch Service-domæne for at få disse nye ændringer anvendt på dit domæne. Flere detaljer om servicesoftwareopdateringsprocessen findes i Amazon OpenSearch Service dokumentation.
Konklusion
I dette indlæg så vi, hvordan Amazon OpenSearch Service for nylig forbedrede logikken til at distribuere noder og shards på tværs af tilgængelighedszoner under zoneafbrydelser.
Denne ændring vil hjælpe tjenesten med at sikre mere ensartet og forudsigelig ydeevne under knude- eller zonefejl. Domæner vil ikke se nogen øgede latenser eller skriveblokeringer under behandling af skrivninger og læsninger, som til tider dukkede op tidligere på grund af overallokering af shards på noder.
Om forfatterne
 Bukhtawar Khan er en senior softwareingeniør, der arbejder på Amazon OpenSearch Service. Han er interesseret i distribuerede og autonome systemer. Han er en aktiv bidragyder til OpenSearch.
Bukhtawar Khan er en senior softwareingeniør, der arbejder på Amazon OpenSearch Service. Han er interesseret i distribuerede og autonome systemer. Han er en aktiv bidragyder til OpenSearch.
 Anshu Agarwal er en senior softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Hun brænder for at løse problemer relateret til at bygge skalerbare og yderst pålidelige systemer.
Anshu Agarwal er en senior softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Hun brænder for at løse problemer relateret til at bygge skalerbare og yderst pålidelige systemer.
 Shourya Dutta Biswas er en softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Han brænder for at bygge meget modstandsdygtige distribuerede systemer.
Shourya Dutta Biswas er en softwareingeniør, der arbejder på AWS OpenSearch hos Amazon Web Services. Han brænder for at bygge meget modstandsdygtige distribuerede systemer.
 Rishab Nahata er en softwareingeniør, der arbejder på OpenSearch hos Amazon Web Services. Han er fascineret af at løse problemer i distribuerede systemer. Han er aktiv bidragyder til OpenSearch.
Rishab Nahata er en softwareingeniør, der arbejder på OpenSearch hos Amazon Web Services. Han er fascineret af at løse problemer i distribuerede systemer. Han er aktiv bidragyder til OpenSearch.
 Ranjith Ramachandra er en Engineering Manager, der arbejder på Amazon OpenSearch Service hos Amazon Web Services.
Ranjith Ramachandra er en Engineering Manager, der arbejder på Amazon OpenSearch Service hos Amazon Web Services.
 Jon Handler er en Senior Principal Solutions Architect med speciale i AWS-søgeteknologier – Amazon CloudSearch og Amazon OpenSearch Service. Baseret i Palo Alto hjælper han en bred vifte af kunder med at få deres søge- og loganalysearbejdsbelastninger implementeret rigtigt og velfungerende.
Jon Handler er en Senior Principal Solutions Architect med speciale i AWS-søgeteknologier – Amazon CloudSearch og Amazon OpenSearch Service. Baseret i Palo Alto hjælper han en bred vifte af kunder med at få deres søge- og loganalysearbejdsbelastninger implementeret rigtigt og velfungerende.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- I stand
- Om
- over
- imødekomme
- Ifølge
- tværs
- aktiv
- Yderligere
- adresse
- Efter
- Alle
- allokeret
- allokerer
- allokering
- Amazon
- Amazon Web Services
- analytics
- ,
- En anden
- Anvendelse
- anvendt
- tildelt
- attributter
- Automatiseret
- automatisk
- autonom
- tilgængelighed
- til rådighed
- gennemsnit
- bevidsthed
- AWS
- baggrund
- Balance
- båndbredde
- baseret
- fordi
- bliver
- BEDSTE
- bedste praksis
- Bedre
- mellem
- Beyond
- Blocks
- Bringer
- bred
- Bygning
- kaldet
- Kan få
- kan ikke
- kapaciteter
- Kapacitet
- hvilken
- tilfælde
- tilfælde
- Årsag
- lave om
- Ændringer
- kredse
- Cloud
- Cluster
- konkurrerende
- komponent
- koncentration
- Konfiguration
- Konsekvenser
- overvejelse
- konsekvent
- bidragsyder
- Tilsvarende
- skabe
- skaber
- Nuværende
- Kunder
- cykler
- data
- datatab
- UNDERSKUD
- indsætte
- indsat
- beskrevet
- detaljer
- forskellige
- distribuere
- distribueret
- distribuerede systemer
- fordeling
- domæne
- Domæner
- Dont
- ned
- Drop
- i løbet af
- hver
- tidligere
- ingeniør
- Engineering
- nok
- sikre
- sikrer
- sikring
- lige
- især
- Ether (ETH)
- Endog
- begivenhed
- eksempel
- forventet
- erfaring
- forklarede
- faktorer
- FAIL
- mislykkedes
- mislykkes
- Manglende
- følger
- efter
- Tving
- fra
- fungerer
- yderligere
- Generelt
- få
- få
- gif
- Goes
- godt
- Håndtering
- ske
- have
- Helse
- sund
- hjælpe
- hjælper
- link.
- stærkt
- hostede
- Hvordan
- Men
- HTML
- HTTPS
- ubalance
- KIMOs Succeshistorier
- påvirket
- vigtigt
- Forbedre
- forbedret
- in
- I andre
- hændelse
- Forøg
- øget
- indeks
- Infrastruktur
- infrastruktur
- instans
- interaktiv
- interesseret
- interne
- indgriben
- spørgsmål
- IT
- seneste
- lancere
- lanceringer
- lancering
- føre
- førende
- Legacy
- GRÆNSE
- belastning
- Lang
- taber
- taber
- miste
- off
- vedligeholde
- lave
- maerker
- Making
- lykkedes
- leder
- manuel
- mange
- midler
- måske
- minimering
- overvågning
- mere
- bevægelser
- flere
- Behov
- Ingen
- netværk
- Ny
- node
- Node distribution
- noder
- nummer
- tilbyde
- ONE
- betjene
- drift
- Produktion
- ordrer
- original
- Andet
- nedbrud
- udfald
- samlet
- overvældet
- Palo Alto
- dele
- lidenskabelige
- udføre
- ydeevne
- udfører
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- mulig
- Indlæg
- strøm
- praksis
- praksis
- Forudsigelig
- forhindre
- tidligere
- primære
- Main
- problemer
- behandle
- forarbejdning
- passende
- ejendom
- give
- giver
- bestemmelse
- hurtigt
- rækkevidde
- Læs
- realtid
- årsager
- for nylig
- anbefales
- Genopretter
- opsving
- Reduceret
- reducere
- relaterede
- frigive
- pålidelig
- resterende
- erstatte
- svar
- repræsentation
- repræsenterer
- Kræver
- elastisk
- Ressourcer
- resultere
- afkast
- afkast
- regler
- Said
- samme
- skalerbar
- Scale
- skalering
- scenarier
- Søg
- Sektion
- sikker
- tjeneste
- Tjenester
- sæt
- setup
- vist
- lignende
- siden
- enkelt
- SIX
- skævt
- So
- Software
- Software Engineer
- Løsninger
- Løsning
- nogle
- Space
- speciale
- Stabilitet
- starte
- Stadig
- opbevaring
- kraftigt
- sådan
- pludselige
- tilstrækkeligt
- support
- overflade
- Systemer
- Tag
- tager
- Teknologier
- deres
- derfor
- Gennem
- kapacitet
- gange
- til
- i dag
- tolerance
- også
- I alt
- Trafik
- udløse
- sand
- Drejning
- typer
- Uventet
- Opdatering
- opdateret
- brug
- Værdier
- række
- visualisering
- vente
- web
- webservices
- Hjemmeside
- som
- mens
- vilje
- inden for
- uden
- arbejder
- ville
- skriver
- Din
- zephyrnet
- zoner