Organisationer på tværs af alle brancher har komplekse databehandlingskrav til deres analytiske use cases på tværs af forskellige analysesystemer, som f.eks datasøer på AWS, datavarehuse (Amazon rødforskydning), Søg (Amazon OpenSearch Service), NoSQL (Amazon DynamoDB), maskinelæring (Amazon SageMaker), og mere. Analytics-professionelle har til opgave at udlede værdi fra data, der er lagret i disse distribuerede systemer, for at skabe bedre, sikre og omkostningsoptimerede oplevelser for deres kunder. For eksempel søger digitale medievirksomheder at kombinere og behandle datasæt i interne og eksterne databaser for at opbygge ensartede visninger af deres kundeprofiler, anspore ideer til innovative funktioner og øge platformengagementet.
I disse scenarier kan kunder, der leder efter en serverløs dataintegration, bruge AWS Lim som en kernekomponent til behandling og katalogisering af data. AWS Glue er godt integreret med AWS-tjenester og partnerprodukter og giver mulighed for udtræk, transformation og load (ETL) med lav kode/no-kode for at muliggøre analyse, maskinlæring (ML) eller applikationsudviklingsarbejdsgange. AWS Glue ETL-job kan være en komponent i en mere kompleks pipeline. Orkestrering af kørsel og styring af afhængigheder mellem disse komponenter er en nøglefunktion i en datastrategi. Amazon administrerede arbejdsgange til Apache Airflows (Amazon MWAA) orkestrerer datapipelines ved hjælp af distribuerede teknologier, herunder lokale ressourcer, AWS-tjenester og tredjepartskomponenter.
I dette indlæg viser vi, hvordan man forenkler overvågningen af et AWS Glue-job orkestreret af Airflow ved hjælp af de nyeste funktioner i Amazon MWAA.
Oversigt over løsning
Dette indlæg diskuterer følgende:
- Sådan opgraderes et Amazon MWAA-miljø til version 2.4.3.
- Sådan orkestreres et AWS Lim-job fra en Airflow Retning Acyclic Graph (DAG).
- Airflow Amazon-udbyderpakkens forbedringer af observerbarhed i Amazon MWAA. Du kan nu konsolidere kørelogfiler af AWS Glue-job på Airflow-konsollen for at forenkle fejlfinding af datapipelines. Amazon MWAA-konsollen bliver en enkelt reference til at overvåge og analysere AWS Glue job kører. Tidligere havde supportteams brug for at få adgang til AWS Management Console og tag manuelle trin for denne synlighed. Denne funktion er tilgængelig som standard fra Amazon MWAA version 2.4.3.
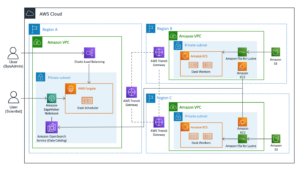
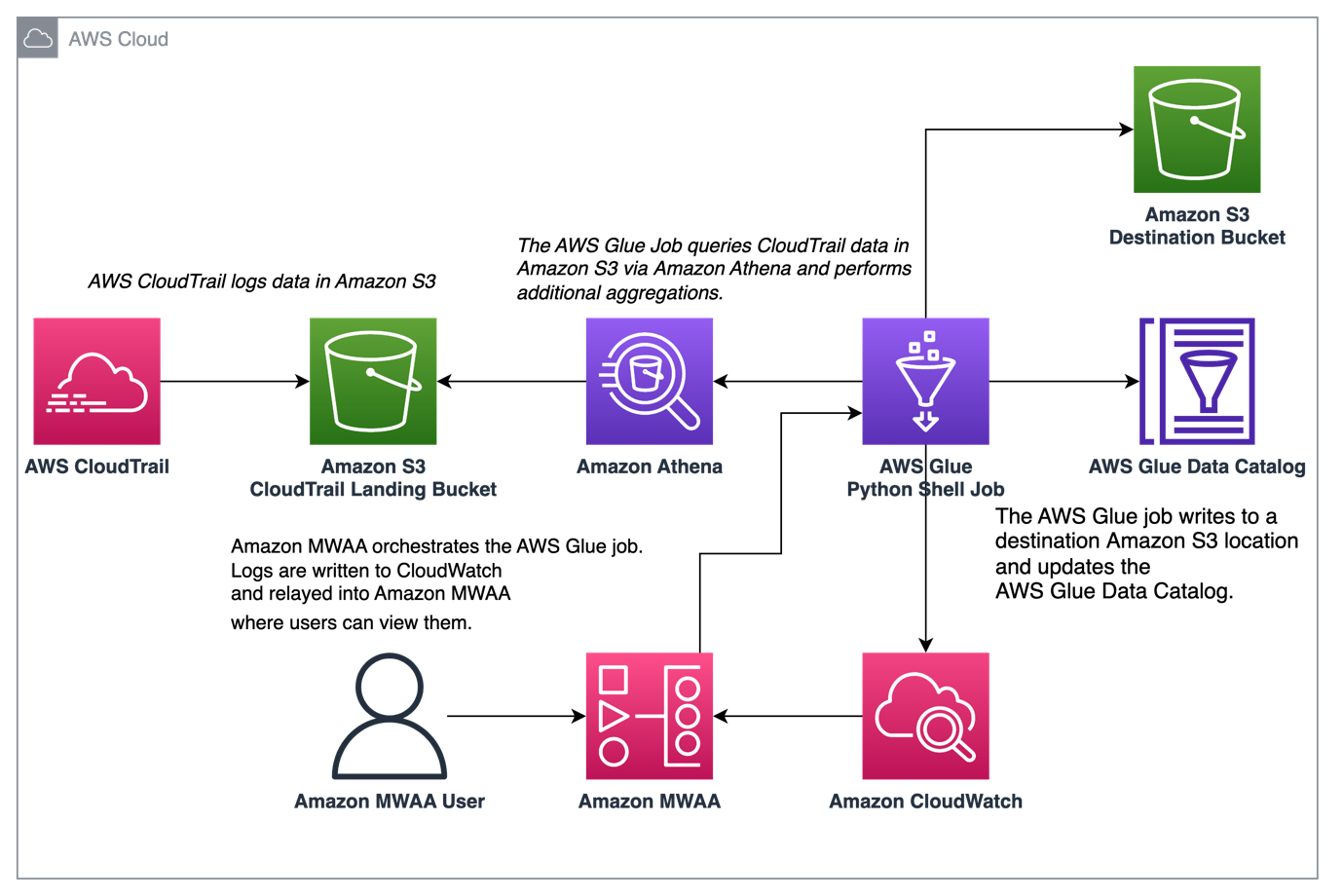
Følgende diagram illustrerer vores løsningsarkitektur.
Forudsætninger
Du har brug for følgende forudsætninger:
Konfigurer Amazon MWAA-miljøet
For instruktioner om oprettelse af dit miljø, se Opret et Amazon MWAA-miljø. For eksisterende brugere anbefaler vi at opgradere til version 2.4.3 for at drage fordel af observerbarhedsforbedringerne i dette indlæg.
Trinnene til at opgradere Amazon MWAA til version 2.4.3 varierer afhængigt af, om den aktuelle version er 1.10.12 eller 2.2.2. Vi diskuterer begge muligheder i dette indlæg.
Forudsætninger for opsætning af et Amazon MWAA-miljø
Du skal opfylde følgende forudsætninger:
Opgrader fra version 1.10.12 til 2.4.3
Hvis du bruger Amazon MWAA-version 1.10.12, henvise til Migrerer til et nyt Amazon MWAA-miljø at opgradere til 2.4.3.
Opgrader fra version 2.0.2 eller 2.2.2 til 2.4.3
Hvis du bruger Amazon MWAA-miljø version 2.2.2 eller lavere, skal du udføre følgende trin:
- Opret en requirements.txt for eventuelle tilpassede afhængigheder med specifikke versioner, der kræves til dine DAG'er.
- Upload filen til Amazon S3 på det passende sted, hvor Amazon MWAA-miljøet peger på requirements.txt til installation af afhængigheder.
- Følg trinnene i Migrerer til et nyt Amazon MWAA-miljø og vælg version 2.4.3.
Opdater dine DAG'er
Kunder, der har opgraderet fra et ældre Amazon MWAA-miljø, skal muligvis foretage opdateringer til eksisterende DAG'er. I Airflow version 2.4.3 vil Airflow-miljøet bruge Amazon-udbyderpakken version 6.0.0 som standard. Denne pakke kan indeholde nogle potentielt brydende ændringer, såsom ændringer af operatørnavne. For eksempel AWSGlueJobOperator er blevet forældet og erstattet med GlueJobOperator. For at bevare kompatibiliteten skal du opdatere dine Airflow DAG'er ved at erstatte eventuelle forældede eller ikke-understøttede operatører fra tidligere versioner med de nye. Udfør følgende trin:
- Naviger til Amazon AWS-operatører.
- Vælg den relevante version installeret i din Amazon MWAA-instans (6.0.0. som standard) for at finde en liste over understøttede Airflow-operatører.
- Foretag de nødvendige ændringer i den eksisterende DAG-kode og upload de ændrede filer til DAG-placeringen i Amazon S3.
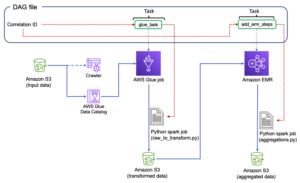
Organiser AWS-lim-jobbet fra Airflow
Dette afsnit dækker detaljerne om orkestrering af et AWS-limjob i Airflow DAG'er. Airflow letter udviklingen af datapipelines med afhængigheder mellem heterogene systemer såsom on-premises processer, eksterne afhængigheder, andre AWS-tjenester og mere.
Orkestrere CloudTrail-logaggregering med AWS Glue og Amazon MWAA
I dette eksempel gennemgår vi et use case med at bruge Amazon MWAA til at orkestrere et AWS Glue Python Shell-job, der vedvarer aggregerede metrics baseret på CloudTrail-logfiler.
CloudTrail muliggør synlighed i AWS API-kald, der foretages på din AWS-konto. Et almindeligt tilfælde med disse data ville være at indsamle brugsmetrics for principaler, der handler på din kontos ressourcer til revision og regulatoriske behov.
Da CloudTrail-hændelser bliver logget, leveres de som JSON-filer i Amazon S3, som ikke er ideelle til analytiske forespørgsler. Vi ønsker at aggregere disse data og bevare dem som parketfiler for at tillade optimal forespørgselsydeevne. Som et indledende trin kan vi bruge Athena til at foretage den indledende forespørgsel af dataene, før vi foretager yderligere aggregeringer i vores AWS Glue-job. For mere information om oprettelse af en AWS Glue Data Catalog tabel, se Oprettelse af tabellen til CloudTrail-logfiler i Athena ved hjælp af partitionsprojektion data. Efter at vi har udforsket dataene via Athena og besluttet, hvilke metrics vi vil beholde i aggregerede tabeller, kan vi oprette et AWS Glue-job.
Opret en CloudTrail-tabel i Athena
Først skal vi oprette en tabel i vores datakatalog, der gør det muligt at forespørge CloudTrail-data via Athena. Følgende eksempelforespørgsel opretter en tabel med to partitioner på regionen og datoen (kaldet snapshot_date). Sørg for at erstatte pladsholderne for din CloudTrail-bøtte, AWS-konto-id og CloudTrail-tabelnavnet:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Kør den foregående forespørgsel på Athena-konsollen, og noter tabelnavnet og AWS Glue Data Catalog-databasen, hvor det blev oprettet. Vi bruger disse værdier senere i Airflow DAG-koden.
Eksempel på AWS Lim jobkode
Følgende kode er et eksempel AWS Lim Python Shell job der gør følgende:
- Tager argumenter (som vi videregiver fra vores Amazon MWAA DAG) om, hvilken dags data der skal behandles
- Bruger AWS SDK til pandaer at køre en Athena-forespørgsel for at udføre den indledende filtrering af CloudTrail JSON-data uden for AWS Glue
- Bruger Pandas til at lave simple sammenlægninger på de filtrerede data
- Udsender de aggregerede data til AWS Glue Data Catalog i en tabel
- Bruger logning under behandlingen, som vil være synlig i Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Følgende er nogle af de vigtigste fordele ved dette AWS-limopgave:
- Vi bruger en Athena-forespørgsel for at sikre, at den indledende filtrering udføres uden for vores AWS-lim-job. Som sådan er et Python Shell-job med minimal beregning stadig tilstrækkeligt til at samle et stort CloudTrail-datasæt.
- Vi sikrer indstilling for analytics-bibliotekssæt er slået til, når vi opretter vores AWS Glue-job for at bruge AWS SDK for Pandas-biblioteket.
Opret et AWS-limjob
Udfør følgende trin for at oprette dit AWS-limjob:
- Kopier scriptet i det foregående afsnit, og gem det i en lokal fil. Til dette indlæg kaldes filen
script.py. - På AWS Glue-konsollen skal du vælge ETL job i navigationsruden.
- Opret et nyt job og vælg Python Shell script editor.
- Type Upload og rediger et eksisterende script og upload den fil, du har gemt lokalt.
- Vælg Opret.

- På Joboplysninger fanen, skal du indtaste et navn til dit AWS-limjob.
- Til IAM rolle, vælg en eksisterende rolle eller opret en ny rolle, der har de nødvendige tilladelser til Amazon S3, AWS Glue og Athena. Rollen skal forespørge i CloudTrail-tabellen, du oprettede tidligere, og skrive til en outputplacering.
Du kan bruge følgende eksempelpolitikkode. Udskift pladsholderne med din CloudTrail-logs-bucket, outputtabelnavn, output AWS Glue-database, output S3-bucket, CloudTrail-tabelnavn, AWS Glue-database, der indeholder CloudTrail-tabellen, og dit AWS-konto-id.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Til Python version, vælg Python 3.9.
- Type Indlæs almindelige analysebiblioteker.
- Til Databehandlingsenheder, vælg 1 DPU.
- Lad de andre indstillinger være standard eller juster efter behov.

- Vælg Gem for at gemme din jobkonfiguration.
Konfigurer en Amazon MWAA DAG til at orkestrere AWS Glue-jobbet
Følgende kode er til en DAG, der kan orkestrere AWS Glue-job, som vi har oprettet. Vi udnytter følgende nøglefunktioner i denne DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Øg observerbarheden af AWS Glue-job i Amazon MWAA
AWS Glue-jobbene skriver logs til amazoncloudwatch. Med de seneste forbedringer af observerbarhed til Airflows Amazon-udbyderpakke er disse logfiler nu integreret med Airflow-opgavelogfiler. Denne konsolidering giver Airflow-brugere ende-til-ende-synlighed direkte i Airflow-brugergrænsefladen, hvilket eliminerer behovet for at søge i CloudWatch eller AWS Glue-konsollen.
For at bruge denne funktion skal du sikre dig, at IAM-rollen knyttet til Amazon MWAA-miljøet har følgende tilladelser til at hente og skrive de nødvendige logfiler:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Hvis verbose=true, vises AWS Glue-jobkørselslogfilerne i Airflow-opgaveloggene. Standarden er falsk. For mere information, se parametre.
Når det er aktiveret, læser DAG'erne fra AWS Glue-jobbets CloudWatch-logstrøm og videresender dem til Airflow DAG AWS Glue-jobtrinloggene. Dette giver detaljeret indblik i et AWS Glue jobs kørsel i realtid via DAG-logfilerne. Bemærk, at AWS Glue-job genererer en output- og fejl-CloudWatch-loggruppe baseret på henholdsvis jobbets STDOUT og STDERR. Alle logfiler i outputloggruppen og undtagelses- eller fejllogfiler fra fejlloggruppen videresendes til Amazon MWAA.
AWS-administratorer kan nu begrænse et supportteams adgang til kun Airflow, hvilket gør Amazon MWAA til den eneste glasrude på joborkestrering og jobsundhedsstyring. Tidligere skulle brugere kontrollere AWS Glue-jobkørselsstatus i Airflow DAG-trinene og hente jobkørsels-id'et. De skulle derefter have adgang til AWS Glue-konsollen for at finde jobkørselshistorikken, søge efter jobbet af interesse ved hjælp af identifikatoren og til sidst navigere til jobbets CloudWatch-logfiler for at fejlfinde.
Opret DAG
Udfør følgende trin for at oprette DAG:
- Gem den foregående DAG-kode i en lokal .py-fil, og erstatter de angivne pladsholdere.
Værdierne for dit AWS-konto-id, AWS Glue-jobnavn, AWS Glue-database med CloudTrail-tabel og CloudTrail-tabelnavn burde allerede være kendt. Du kan justere output S3-bucket, output AWS Glue-database og outputtabelnavn efter behov, men sørg for, at AWS Glue-jobbets IAM-rolle, som du brugte tidligere, er konfigureret i overensstemmelse hermed.
- På Amazon MWAA-konsollen skal du navigere til dit miljø for at se, hvor DAG-koden er gemt.
DAGs-mappen er præfikset i S3-bøtten, hvor din DAG-fil skal placeres.
- Upload din redigerede fil der.

- Åbn Amazon MWAA-konsollen for at bekræfte, at DAG vises i tabellen.

Kør DAG
Udfør følgende trin for at køre DAG:
- Vælg mellem følgende muligheder:
- Udløs DAG – Dette medfører, at gårsdagens data bruges som data, der skal behandles
- Trigger DAG m/ config – Med denne mulighed kan du indtaste en anden dato, potentielt for udfyldninger, som hentes vha
dag_run.confi DAG-koden og derefter overført til AWS Glue-jobbet som en parameter

Følgende skærmbillede viser de yderligere konfigurationsmuligheder, hvis du vælger det Trigger DAG m/ config.

- Overvåg DAG'en, mens den kører.
- Når DAG er fuldført, skal du åbne kørselsoplysningerne.
I højre rude kan du se logfilerne eller vælge Opgaveforekomstdetaljer for en fuld visning.

- Se AWS Glue-joboutputlogfilerne i Amazon MWAA uden at bruge AWS Glue-konsollen takket være
GlueJobOperatorudførligt flag.

AWS Glue-jobbet vil have skrevet resultater til den outputtabel, du har angivet.
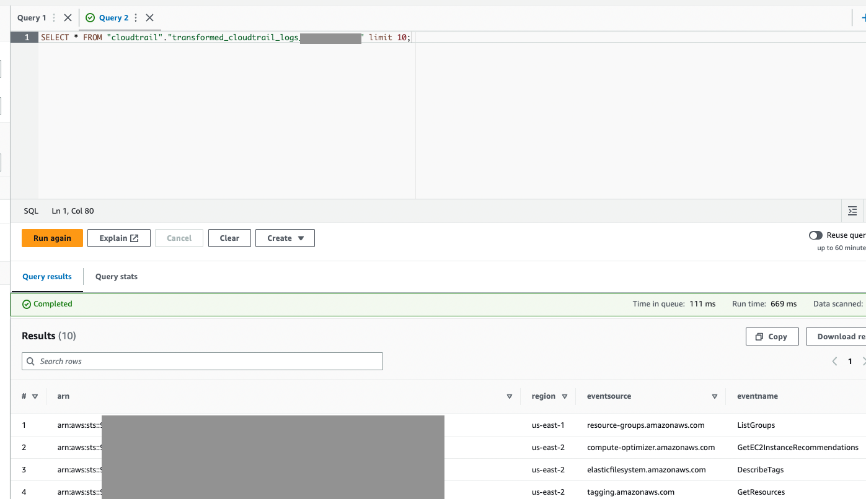
- Forespørg denne tabel via Athena for at bekræfte, at det lykkedes.
Resumé
Amazon MWAA giver nu et enkelt sted at spore AWS Glue-jobstatus og giver dig mulighed for at bruge Airflow-konsollen som den enkelte rude til joborkestrering og sundhedsstyring. I dette indlæg gik vi gennem trinene til at orkestrere AWS Glue-job via Airflow ved hjælp af GlueJobOperator. Med de nye forbedringer af observerbarhed kan du problemfrit fejlfinde AWS Glue-job i en samlet oplevelse. Vi demonstrerede også, hvordan du opgraderer dit Amazon MWAA-miljø til en kompatibel version, opdaterer afhængigheder og ændrer IAM-rollepolitikken i overensstemmelse hermed.
For mere information om almindelige fejlfindingstrin henvises til Fejlfinding: Oprettelse og opdatering af et Amazon MWAA-miljø. For dybdegående detaljer om migrering til et Amazon MWAA-miljø, se Opgradering fra 1.10 til 2. For at lære om ændringerne i open source-kode for øget observerbarhed af AWS Glue-job i Airflow Amazon-udbyderpakken, se relælogfiler fra AWS Lim-job.
Endelig anbefaler vi at besøge AWS Big Data Blog for andet materiale om analytics, ML og datagovernance på AWS.
Om forfatterne
 Rushabh Lokhande er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han hjælper kunder med at implementere big data, machine learning og analyseløsninger. Uden for arbejdet nyder han at bruge tid med familien, læse, løbe og golf.
Rushabh Lokhande er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han hjælper kunder med at implementere big data, machine learning og analyseløsninger. Uden for arbejdet nyder han at bruge tid med familien, læse, løbe og golf.
 Ryan Gomes er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han brænder for at hjælpe kunder med at opnå bedre resultater gennem analyser og maskinlæringsløsninger i skyen. Uden for arbejdet nyder han fitness, madlavning og at tilbringe kvalitetstid med venner og familie.
Ryan Gomes er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han brænder for at hjælpe kunder med at opnå bedre resultater gennem analyser og maskinlæringsløsninger i skyen. Uden for arbejdet nyder han fitness, madlavning og at tilbringe kvalitetstid med venner og familie.
 Vishwa Gupta er Senior Data Architect med AWS Professional Services Analytics Practice. Han hjælper kunder med at implementere big data og analyseløsninger. Uden for arbejdet nyder han at tilbringe tid med familien, rejse og prøve ny mad.
Vishwa Gupta er Senior Data Architect med AWS Professional Services Analytics Practice. Han hjælper kunder med at implementere big data og analyseløsninger. Uden for arbejdet nyder han at tilbringe tid med familien, rejse og prøve ny mad.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 12
- 8
- a
- Om
- adgang
- derfor
- Konto
- opnå
- tværs
- Handling
- acykliske
- Yderligere
- Fordel
- fordele
- Efter
- aggregering
- Alle
- tillade
- tillader
- allerede
- også
- Amazon
- Amazon Web Services
- an
- Analytisk
- analytics
- analysere
- ,
- enhver
- Apache
- api
- Anvendelse
- Application Development
- passende
- arkitektur
- ER
- argument
- argumenter
- AS
- At
- attributter
- revision
- til rådighed
- AWS
- AWS Lim
- AWS Professional Services
- baseret
- BE
- bliver
- været
- før
- være
- Bedre
- mellem
- Big
- Big data
- både
- Breaking
- bygge
- men
- by
- kaldet
- Opkald
- CAN
- tilfælde
- tilfælde
- katalog
- årsager
- lave om
- Ændringer
- kontrollere
- Vælg
- Cloud
- kode
- KOM
- kombinerer
- KOMMENTAR
- Fælles
- Virksomheder
- kompatibilitet
- kompatibel
- fuldføre
- komplekse
- komponent
- komponenter
- Compute
- Konfiguration
- Bekræfte
- Konsol
- konsolidere
- konsolidering
- madlavning
- Core
- dækker
- skabe
- oprettet
- skaber
- Oprettelse af
- Nuværende
- skik
- kunde
- Kunder
- DAG
- data
- dataintegration
- databehandling
- datastrategi
- datavarehuse
- Database
- databaser
- datasæt
- Dato
- Datoer
- dato tid
- Dage
- besluttede
- Standard
- leveret
- demonstreret
- Afhængigt
- forældet
- detaljeret
- detaljer
- Udvikling
- afvige
- forskellige
- digital
- Digitalt medie
- direkte
- diskutere
- distribueret
- distribuerede systemer
- do
- gør
- gør
- færdig
- i løbet af
- e
- tidligere
- Letter
- effekt
- eliminere
- andet
- muliggøre
- aktiveret
- muliggør
- ende til ende
- engagement
- ingeniør
- forbedringer
- sikre
- Indtast
- Miljø
- fejl
- Ether (ETH)
- begivenheder
- eksempel
- Undtagen
- undtagelse
- eksisterer
- eksisterende
- eksisterer
- erfaring
- Oplevelser
- udforsket
- udtryk
- ekstern
- ekstrakt
- mislykkedes
- falsk
- familie
- Feature
- featured
- Funktionalitet
- File (Felt)
- Filer
- filtrering
- Endelig
- Finde
- fitness
- efter
- mad
- Til
- format
- venner
- fra
- fuld
- samle
- generere
- glas
- Go
- golf
- regeringsførelse
- gruppe
- Hadoop
- Have
- he
- Helse
- hjælpe
- hjælper
- historie
- Hive
- Hvordan
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- ideer
- identifikator
- if
- illustrerer
- gennemføre
- importere
- in
- dybdegående
- omfatter
- Herunder
- Forøg
- øget
- angivet
- industrier
- info
- oplysninger
- initial
- innovativ
- indsigt
- installation
- instans
- anvisninger
- integreret
- integration
- interesse
- interne
- ind
- IT
- Job
- Karriere
- jpg
- json
- Nøgle
- kendt
- stor
- senere
- seneste
- LÆR
- læring
- Bibliotek
- GRÆNSE
- Liste
- belastning
- lokale
- lokalt
- placering
- log
- logget
- logning
- leder
- maskine
- machine learning
- lavet
- vedligeholde
- lave
- Making
- lykkedes
- ledelse
- styring
- manuel
- materiale
- Kan..
- Medier
- Mød
- besked
- Metrics
- migrere
- mindste
- ML
- modificeret
- modul
- Overvåg
- overvågning
- mere
- skal
- navn
- navne
- Naviger
- Navigation
- nødvendig
- Behov
- behov
- behov
- Ny
- intet
- nu
- of
- tilbyde
- on
- ONE
- dem
- kun
- åbent
- open source
- open source-kode
- operatør
- Operatører
- optimal
- Option
- Indstillinger
- or
- orkestreret
- orkestrering
- Andet
- vores
- udfald
- output
- uden for
- pakke
- pandaer
- brød
- parametre
- partner
- passerer
- Bestået
- lidenskabelige
- ydeevne
- Tilladelser
- vedvarer
- pipeline
- Place
- perron
- plato
- Platon Data Intelligence
- PlatoData
- punkter
- politik
- Indlæg
- potentielt
- praksis
- forudsætninger
- tidligere
- tidligere
- behandle
- Processer
- forarbejdning
- Produkter
- professionel
- professionelle partnere
- Profiler
- Fremskrivning
- udbyder
- udbydere
- giver
- Python
- kvalitet
- forespørgsler
- rejse
- rækkevidde
- Læs
- Læsning
- ægte
- realtid
- nylige
- anbefaler
- region
- lovgivningsmæssige
- Relæ
- erstatte
- udskiftes
- påkrævet
- Krav
- ressource
- Ressourcer
- henholdsvis
- svar
- Resultater
- tilbageholde
- højre
- roller
- RÆKKE
- Kør
- kører
- s
- Gem
- scenarier
- SDK
- problemfrit
- Søg
- Sektion
- sikker
- se
- Søg
- senior
- Serverless
- Tjenester
- indstilling
- setup
- Shell
- bør
- Vis
- Shows
- Simpelt
- forenkle
- siden
- enkelt
- Snapshot
- løsninger
- Løsninger
- nogle
- specifikke
- specificeret
- udgifterne
- Statement
- Status
- Trin
- Steps
- Stadig
- opbevaring
- opbevaret
- Strategi
- strøm
- String
- vellykket
- sådan
- tilstrækkeligt
- support
- Understøttet
- Systemer
- bord
- Tag
- tager
- Opgaver
- hold
- Teknologier
- skabelon
- tak
- at
- deres
- Them
- derefter
- Der.
- Disse
- de
- tredjepart
- denne
- Gennem
- tid
- til
- spor
- Transform
- Traveling
- sand
- prøv
- Tirsdag
- Drejede
- to
- typen
- ui
- forenet
- enhed
- Opdatering
- opdateringer
- opdatering
- opgradering
- opgraderet
- Uploading
- Brug
- brug
- brug tilfælde
- anvendte
- brugere
- ved brug af
- værdi
- Værdier
- udgave
- via
- Specifikation
- visninger
- synlighed
- synlig
- gik
- ønsker
- var
- we
- web
- webservices
- GODT
- Hvad
- hvornår
- hvorvidt
- som
- WHO
- vilje
- med
- inden for
- uden
- Arbejde
- arbejdsgange
- ville
- skriver
- skriftlig
- dig
- Din
- zephyrnet