Giới thiệu
Sự hợp nhất của trí tuệ nhân tạo (AI) và nghệ thuật mở ra những con đường mới trong nghệ thuật kỹ thuật số sáng tạo, nổi bật là thông qua các mô hình khuếch tán. Những mô hình này nổi bật trong thế hệ nghệ thuật AI sáng tạo, mang đến một cách tiếp cận khác biệt so với các mạng thần kinh thông thường. Bài viết này đưa bạn vào một cuộc hành trình khám phá vào chiều sâu của các mô hình khuếch tán, làm sáng tỏ cơ chế độc đáo của chúng trong việc tạo ra các tác phẩm nghệ thuật giàu hình ảnh và giàu tính sáng tạo. Hiểu các sắc thái của các mô hình khuếch tán và hiểu rõ hơn về vai trò của chúng trong việc xác định lại cách thể hiện nghệ thuật thông qua lăng kính của công nghệ AI tiên tiến.

Mục tiêu học tập
- Hiểu các khái niệm cơ bản về mô hình khuếch tán trong AI.
- Khám phá sự khác biệt giữa các mô hình khuếch tán và mạng lưới thần kinh truyền thống trong thế hệ nghệ thuật.
- Phân tích quá trình sáng tạo nghệ thuật bằng cách sử dụng các mô hình khuếch tán.
- Đánh giá ý nghĩa sáng tạo và thẩm mỹ của AI trong nghệ thuật kỹ thuật số.
- Thảo luận về những cân nhắc về mặt đạo đức trong tác phẩm nghệ thuật do AI tạo ra.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Hiểu mô hình khuếch tán

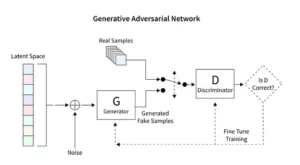
Các mô hình khuếch tán cách mạng hóa AI tổng hợp, trình bày một phương pháp tạo hình ảnh độc đáo khác biệt với các kỹ thuật thông thường như Mạng đối thủ sáng tạo (GAN). Bắt đầu với tiếng ồn ngẫu nhiên, các mô hình này dần dần tinh chỉnh nó, giống như một nghệ sĩ đang tinh chỉnh một bức tranh, tạo ra những hình ảnh phức tạp và mạch lạc.
Quá trình sàng lọc gia tăng này phản ánh bản chất có phương pháp của sự khuếch tán. Ở đây, mỗi lần lặp lại sẽ thay đổi tiếng ồn một cách tinh tế, đưa nó đến gần hơn với tầm nhìn nghệ thuật cuối cùng. Sản phẩm đầu ra không chỉ đơn thuần là sản phẩm của sự ngẫu nhiên mà còn là một tác phẩm nghệ thuật được tiến hóa, khác biệt trong quá trình tiến triển và hoàn thiện.
Mã hóa cho các mô hình khuếch tán đòi hỏi sự hiểu biết sâu sắc về mạng lưới thần kinh và các khung học máy như TensorFlow hoặc PyTorch. Mã kết quả rất phức tạp, đòi hỏi phải đào tạo chuyên sâu về các bộ dữ liệu mở rộng để đạt được các hiệu ứng sắc thái như trong nghệ thuật do AI tạo ra.
Ứng dụng khuếch tán ổn định trong nghệ thuật
Sự ra đời của các công cụ tạo nghệ thuật AI như mô hình khuếch tán ổn định đòi hỏi phải mã hóa phức tạp trong các nền tảng như TensorFlow hoặc PyTorch. Những mô hình này nổi bật nhờ khả năng biến tính ngẫu nhiên thành cấu trúc một cách có phương pháp, giống như một nghệ sĩ biến bản phác thảo sơ bộ thành một kiệt tác sống động.
Các mô hình phổ biến ổn định định hình lại khung cảnh nghệ thuật AI bằng cách tạo ra các hình ảnh có trật tự từ sự ngẫu nhiên, tránh tính năng động cạnh tranh đặc trưng của GAN. Họ xuất sắc trong việc diễn giải các gợi ý mang tính khái niệm thành nghệ thuật thị giác, thúc đẩy vũ điệu tổng hợp giữa khả năng AI và sự khéo léo của con người. Bằng cách khai thác PyTorch, chúng tôi quan sát cách các mô hình này liên tục tinh chỉnh sự hỗn loạn thành rõ ràng, phản ánh hành trình của người nghệ sĩ từ một ý tưởng non trẻ đến một sáng tạo bóng bẩy.
Thử nghiệm nghệ thuật do AI tạo ra
Cuộc trình diễn này đi sâu vào thế giới hấp dẫn của nghệ thuật do AI tạo ra bằng cách sử dụng mạng lưới thần kinh tích chập được gọi là Chuyển đổiMô hình khuếch tán. Mô hình này được đào tạo về các hình ảnh nghệ thuật đa dạng, bao gồm các bản vẽ, tranh vẽ, tác phẩm điêu khắc và bản khắc, có nguồn gốc từ tập dữ liệu Kaggle này. Mục tiêu của chúng tôi là khám phá khả năng của mô hình trong việc nắm bắt và tái tạo tính thẩm mỹ phức tạp của những tác phẩm nghệ thuật này.
Kiến trúc mô hình và đào tạo
Thiết kế kiến trúc
Về cốt lõi, ConvDiffusionModel là một tuyệt tác của kỹ thuật thần kinh, có kiến trúc bộ mã hóa-giải mã tinh vi phù hợp với nhu cầu sáng tạo nghệ thuật. Cấu trúc của mô hình là một mạng lưới thần kinh phức tạp, tích hợp các cơ chế mã hóa-giải mã tinh tế được thiết kế đặc biệt cho việc tạo ra tác phẩm nghệ thuật. Với các lớp tích chập bổ sung và bỏ qua các kết nối mô phỏng trực giác nghệ thuật, mô hình có thể mổ xẻ và tập hợp lại nghệ thuật với sự hiểu biết sâu sắc về bố cục và phong cách.
- Mã hoá: Bộ mã hóa là con mắt phân tích của mô hình, xem xét kỹ lưỡng từng chi tiết nhỏ của hình ảnh đầu vào. Khi hình ảnh đi qua các lớp chập của bộ mã hóa, chúng sẽ dần dần bị nén vào một không gian tiềm ẩn—một bản trình bày nhỏ gọn, được mã hóa của tác phẩm nghệ thuật gốc. Bộ mã hóa của chúng tôi không chỉ xem xét kỹ lưỡng hình ảnh đầu vào mà giờ đây còn thực hiện điều đó với chiều sâu nhận thức được nâng cao nhờ các lớp bổ sung và kỹ thuật chuẩn hóa hàng loạt. Việc kiểm tra mở rộng này cho phép thể hiện phong phú hơn, cô đọng hơn trong không gian tiềm ẩn, phản ánh sự chiêm nghiệm sâu sắc của nghệ sĩ về một chủ đề.
- Bộ giải mã: Ngược lại, bộ giải mã đóng vai trò là bàn tay sáng tạo của người mẫu, lấy các bản phác thảo trừu tượng từ bộ mã hóa và thổi sức sống vào chúng. Nó tái tạo lại tác phẩm nghệ thuật từ không gian tiềm ẩn, từng lớp, từng chi tiết cho đến khi xuất hiện một hình ảnh hoàn chỉnh. Bộ giải mã của chúng tôi được hưởng lợi từ việc bỏ qua các kết nối và có thể tái tạo lại tác phẩm nghệ thuật với độ chính xác cao hơn. Nó xem lại bản chất trừu tượng của đầu vào và dần dần tô điểm nó, đạt được sự thể hiện trung thực hơn với tài liệu nguồn. Các lớp nâng cao hoạt động đồng bộ để đảm bảo rằng hình ảnh cuối cùng là một tác phẩm sống động, phức tạp phản ánh tính nghệ thuật của đầu vào.
Quy trình đào tạo
Việc đào tạo ConvDiffusionModel là một hành trình xuyên qua bối cảnh nghệ thuật trải dài 150 kỷ nguyên. Mỗi kỷ nguyên thể hiện một lượt hoàn chỉnh xuyên qua toàn bộ tập dữ liệu, với mô hình cố gắng tinh chỉnh sự hiểu biết của nó và cải thiện độ trung thực của hình ảnh được tạo ra.
- Chức năng mất lai: Trọng tâm của quá trình đào tạo là hàm mất mát sai số bình phương trung bình (MSE). Hàm này định lượng sự khác biệt giữa kiệt tác gốc và tác phẩm tái tạo của mô hình, cung cấp số liệu rõ ràng để giảm thiểu. Chúng tôi sẽ giới thiệu thành phần tổn thất cảm nhận có nguồn gốc từ mạng VGG được đào tạo trước để bổ sung cho chỉ số lỗi bình phương trung bình (MSE). Chiến lược mất mát kép này thúc đẩy mô hình tôn vinh tính toàn vẹn về mặt nghệ thuật của bản gốc đồng thời hoàn thiện việc tái tạo kỹ thuật các chi tiết của chúng.
- Trình tối ưu hóa: Với tốc độ học tập được điều chỉnh linh hoạt bởi bộ lập lịch, trình tối ưu hóa Adam sẽ hướng dẫn quá trình học tập của mô hình với độ chính xác cao hơn. Cách tiếp cận thích ứng này đảm bảo rằng sự tiến bộ của mô hình trong việc học cách nhân rộng và đổi mới nghệ thuật vừa ổn định vừa mạnh mẽ.
- Lặp lại và sàng lọc: Việc lặp đi lặp lại quá trình đào tạo là một cuộc khiêu vũ giữa việc bảo tồn bản chất nghệ thuật và theo đuổi việc nhân rộng kỹ thuật. Với mỗi chu kỳ, mô hình tiến gần hơn đến sự tổng hợp giữa độ trung thực và tính sáng tạo.
- Trực quan hóa tiến trình: Hình ảnh được lưu định kỳ trong quá trình đào tạo để trực quan hóa tiến trình của mô hình. Những ảnh chụp nhanh này cung cấp một cái nhìn vào đường cong học tập của mô hình, cho thấy nghệ thuật được tạo ra của nó phát triển như thế nào, trở nên rõ ràng hơn, chi tiết hơn và mạch lạc về mặt nghệ thuật hơn theo từng thời đại.



Điều trên được thể hiện qua đoạn mã sau:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Trực quan hóa tác phẩm nghệ thuật được tạo
Thể hiện nghệ thuật do AI tạo ra
Với ConvDiffusionModel hiện đã được đào tạo đầy đủ, trọng tâm sẽ chuyển từ trừu tượng sang cụ thể—từ tiềm năng đến hiện thực hóa nghệ thuật do AI tạo ra. Đoạn mã tiếp theo hiện thực hóa các khả năng nghệ thuật đã học của mô hình, chuyển đổi dữ liệu đầu vào thành một khung biểu đạt kỹ thuật số.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()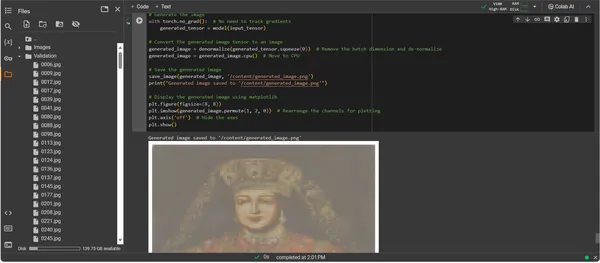

Hướng dẫn tạo mã tác phẩm nghệ thuật
- Sự hồi sinh của người mẫu: Bước đầu tiên trong quá trình tạo tác phẩm nghệ thuật là khôi phục ConvDiffusionModel đã được đào tạo của chúng tôi. Các trọng số đã học của mô hình được tải và đưa vào chế độ đánh giá, thiết lập giai đoạn tạo mà không cần thay đổi thêm các tham số của mô hình.
- Chuyển đổi hình ảnh: Để đảm bảo tính nhất quán với chế độ huấn luyện, hình ảnh đầu vào được xử lý thông qua cùng một chuỗi biến đổi. Điều này bao gồm việc thay đổi kích thước để phù hợp với kích thước đầu vào của mô hình, chuyển đổi tensor để tương thích với PyTorch và chuẩn hóa dựa trên hồ sơ thống kê của dữ liệu huấn luyện.
- Tiện ích không chuẩn hóa: Chức năng tùy chỉnh đảo ngược các hiệu ứng tiền xử lý, điều chỉnh lại thang đo theo dải màu của ảnh gốc. Bước này rất cần thiết để hiển thị đầu ra được tạo thành một bản trình bày chính xác về mặt trực quan.
- Chuẩn bị đầu vào: Một hình ảnh được tải và chịu các biến đổi nói trên. Điều quan trọng cần lưu ý là hình ảnh này đóng vai trò là nguồn cảm hứng để AI lấy cảm hứng — lời thì thầm thầm lặng sẽ khơi dậy trí tưởng tượng tổng hợp của người mẫu.
- Tổng hợp tác phẩm nghệ thuật: Trong một vũ điệu tinh tế của quá trình lan truyền về phía trước, mô hình diễn giải tensor đầu vào, cho phép các lớp của nó cộng tác để tạo ra một tầm nhìn nghệ thuật mới. Thực hiện quá trình này mà không cần theo dõi độ dốc, vì hiện tại chúng ta đang ở trong lĩnh vực ứng dụng chứ không phải lĩnh vực đào tạo.
- Chuyển đổi hình ảnh: Đầu ra tensor của mô hình, hiện đang chứa tác phẩm nghệ thuật được sinh ra bằng kỹ thuật số, không được chuẩn hóa, chuyển tác phẩm của mô hình trở lại không gian màu sắc và ánh sáng quen thuộc mà mắt chúng ta có thể đánh giá được.
- Tiết lộ tác phẩm nghệ thuật: Tensor đã biến đổi được đặt trên một khung vẽ kỹ thuật số, đạt đến đỉnh điểm là một tệp hình ảnh đã lưu. Tệp này là cửa sổ nhìn vào tâm hồn sáng tạo của AI, một tiếng vang tĩnh của quá trình năng động đã mang lại sự sống cho nó.
- Truy xuất tác phẩm nghệ thuật: Tập lệnh kết thúc bằng cách lưu hình ảnh đã tạo vào một đường dẫn được chỉ định và thông báo hoàn thành. Hình ảnh được lưu lại, sự tổng hợp của các nguyên tắc nghệ thuật đã học và khả năng sáng tạo mới nổi, đã sẵn sàng để trưng bày và chiêm ngưỡng.
Phân tích đầu ra
Đầu ra của ConvDiffusionModel trình bày một hình vẽ rõ ràng liên quan đến nghệ thuật lịch sử. Được khoác lên mình bộ trang phục cầu kỳ, hình ảnh được kết xuất bằng AI phản ánh sự hùng vĩ của những bức chân dung cổ điển nhưng vẫn mang nét hiện đại, khác biệt. Trang phục của đối tượng có nhiều họa tiết, kết hợp các mẫu đã học của người mẫu với cách diễn giải mới lạ. Các đặc điểm khuôn mặt thanh tú và sự tương tác tinh tế giữa ánh sáng và bóng tối thể hiện sự hiểu biết sâu sắc của AI về các kỹ thuật nghệ thuật truyền thống. Tác phẩm nghệ thuật này là minh chứng cho quá trình đào tạo tinh vi của người mẫu, phản ánh sự tổng hợp tinh tế của nghệ thuật lịch sử thông qua lăng kính học máy tiên tiến. Về bản chất, nó là sự tôn kính kỹ thuật số đối với quá khứ, được tạo ra bằng các thuật toán của hiện tại.
Những thách thức và cân nhắc về đạo đức
Việc triển khai các mô hình phổ biến cho thế hệ nghệ thuật mang đến một số thách thức và cân nhắc về mặt đạo đức mà bạn nên cân nhắc:
- Xuất xứ dữ liệu: Các tập dữ liệu đào tạo phải được quản lý một cách có trách nhiệm. Việc xác minh rằng dữ liệu được sử dụng để huấn luyện các mô hình phổ biến không chứa các tác phẩm có bản quyền hoặc được bảo vệ mà không có sự cho phép thích hợp là điều cần thiết.
- Xu hướng và đại diện: Các mô hình AI có thể duy trì sự thiên vị trong dữ liệu đào tạo của họ. Việc đảm bảo các bộ dữ liệu đa dạng và toàn diện là điều quan trọng để tránh củng cố các khuôn mẫu trong nghệ thuật do AI tạo ra.
- Kiểm soát đầu ra: Vì các mô hình phổ biến có thể tạo ra nhiều loại đầu ra nên việc thiết lập các ranh giới để ngăn chặn việc tạo ra nội dung không phù hợp hoặc gây khó chịu là cần thiết.
- Khuôn khổ pháp lý: Việc thiếu khung pháp lý mạnh mẽ để giải quyết các sắc thái của AI trong quá trình sáng tạo là một thách thức. Pháp luật cần phải phát triển để bảo vệ quyền lợi của tất cả các bên liên quan.
Kết luận
Sự nổi lên của các mô hình khuếch tán trong AI và nghệ thuật đánh dấu một kỷ nguyên biến đổi, kết hợp độ chính xác tính toán với khám phá thẩm mỹ. Hành trình của họ trong thế giới nghệ thuật nêu bật tiềm năng đổi mới đáng kể nhưng cũng đi kèm với những phức tạp. Cân bằng giữa tính độc đáo, tầm ảnh hưởng, tính sáng tạo có đạo đức và sự tôn trọng đối với các tác phẩm hiện có là điều không thể thiếu trong quá trình nghệ thuật.
Chìa khóa chính
- Các mô hình truyền bá đang đi đầu trong sự thay đổi mang tính biến đổi trong sáng tạo nghệ thuật. Họ cung cấp các công cụ kỹ thuật số mới giúp mở rộng phạm vi thể hiện nghệ thuật vượt ra ngoài ranh giới truyền thống.
- Trong nghệ thuật được nâng cao bởi AI, việc ưu tiên thu thập dữ liệu đào tạo một cách có đạo đức và tôn trọng tài sản trí tuệ của người sáng tạo là điều bắt buộc để duy trì tính toàn vẹn trong nghệ thuật kỹ thuật số.
- Sự hội tụ giữa tầm nhìn nghệ thuật và đổi mới công nghệ mở ra cánh cửa cho mối quan hệ cộng sinh giữa nghệ sĩ và nhà phát triển AI. Thúc đẩy một môi trường hợp tác có thể tạo ra nghệ thuật đột phá.
- Việc đảm bảo rằng tác phẩm nghệ thuật do AI tạo ra thể hiện nhiều quan điểm đa dạng là điều quan trọng. Kết hợp nhiều loại dữ liệu phản ánh sự phong phú của các nền văn hóa và quan điểm khác nhau, từ đó thúc đẩy tính toàn diện.
- Mối quan tâm ngày càng tăng đối với nghệ thuật do AI tạo ra đòi hỏi phải thiết lập các khuôn khổ pháp lý mạnh mẽ. Các khuôn khổ này sẽ làm rõ các vấn đề về bản quyền, ghi nhận những đóng góp và quản lý việc sử dụng thương mại các tác phẩm nghệ thuật do AI tạo ra.
Buổi bình minh của quá trình phát triển nghệ thuật này mở ra một con đường tràn đầy tiềm năng sáng tạo nhưng vẫn đòi hỏi sự giám hộ có tâm. Nhiệm vụ của chúng ta là xây dựng một bối cảnh nơi sự kết hợp giữa AI và nghệ thuật phát triển mạnh mẽ, được hướng dẫn bởi các hoạt động có trách nhiệm và nhạy cảm về văn hóa.
Những câu hỏi thường gặp
A. Mô hình khuếch tán là thuật toán ML tổng quát tạo ra hình ảnh bằng cách bắt đầu bằng một mẫu nhiễu ngẫu nhiên và dần dần định hình nó thành một bức tranh mạch lạc. Quá trình này giống như một nghệ sĩ bắt đầu với một khung vẽ trống và từ từ thêm các lớp chi tiết.
A. GAN, mô hình khuếch tán không yêu cầu mạng riêng để đánh giá đầu ra. Chúng hoạt động bằng cách lặp đi lặp lại việc thêm và loại bỏ nhiễu, thường mang lại hình ảnh chi tiết và nhiều sắc thái hơn.
Đáp: Có, các mô hình khuếch tán có thể tạo ra các tác phẩm nghệ thuật nguyên bản bằng cách học từ tập dữ liệu hình ảnh. Tuy nhiên, tính nguyên bản bị ảnh hưởng bởi tính đa dạng và phạm vi của dữ liệu huấn luyện. Hiện đang có một cuộc tranh luận về đạo đức của việc sử dụng các tác phẩm nghệ thuật hiện có để huấn luyện những người mẫu này.
A. Các mối quan tâm về đạo đức bao gồm việc tránh vi phạm bản quyền nghệ thuật do AI tạo ra. Tôn trọng tính độc đáo của các nghệ sĩ con người, ngăn chặn sự tồn tại thành kiến và đảm bảo tính minh bạch trong quá trình sáng tạo của AI.
A. Tương lai của nghệ thuật do AI tạo ra có vẻ đầy hứa hẹn, với các mô hình phổ biến cung cấp các công cụ mới cho nghệ sĩ và người sáng tạo. Chúng ta có thể mong đợi được chiêm ngưỡng những tác phẩm nghệ thuật tinh xảo và phức tạp hơn khi công nghệ tiến bộ. Tuy nhiên, cộng đồng sáng tạo phải điều hướng các cân nhắc về mặt đạo đức và hướng tới các hướng dẫn rõ ràng và các phương pháp thực hành tốt nhất.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :là
- :không phải
- :Ở đâu
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- có khả năng
- Giới thiệu
- ở trên
- TÓM TẮT
- chính xác
- Đạt được
- đạt được
- Adam
- thích nghi
- thêm
- thêm vào
- địa chỉ
- Điều chỉnh
- tiên tiến
- tiến bộ
- sự xuất hiện
- đối thủ
- AI
- nghệ thuật ai
- dòng chảy
- thuật toán
- Tất cả
- Cho phép
- cho phép
- an
- Phân tích
- phân tích
- Phân tích Vidhya
- và
- Thông báo
- Các Ứng Dụng
- đánh giá cao
- phương pháp tiếp cận
- kiến trúc
- LÀ
- Nghệ thuật
- bài viết
- nghệ sĩ
- nghệ thuật
- một cách nghệ thuật
- nghệ thuật
- Nghệ sĩ
- tác phẩm nghệ thuật
- tác phẩm nghệ thuật
- AS
- At
- tăng cường
- ủy quyền
- có sẵn
- đại lộ
- tránh
- tránh
- VÒI
- trở lại
- Bad
- cân bằng
- dựa
- BE
- trở thành
- Lợi ích
- BEST
- thực hành tốt nhất
- giữa
- Ngoài
- thiên vị
- thành kiến
- trống
- trộn
- cuộc thi viết blog
- sinh
- cả hai
- ranh giới
- thở
- rưng rưng
- Mang lại
- rộng
- Mang lại
- sự phát triển
- nhưng
- by
- tính toán
- gọi là
- CAN
- vải
- khả năng
- khả năng
- nắm bắt
- thách thức
- thách thức
- kênh
- Chaos
- đặc trưng
- kiểm tra
- kiểm tra
- cái kẹp
- rõ ràng
- tốt nghiệp lớp XNUMX
- trong sáng
- rõ ràng hơn
- gần gũi hơn
- mã
- Lập trình
- mạch lạc
- hợp tác
- hợp tác
- màu sắc
- đến
- thương gia
- cộng đồng
- nhỏ gọn
- khả năng tương thích
- cạnh tranh
- hoàn thành
- hoàn thành
- phức tạp
- phức tạp
- thành phần
- thành phần
- tính toán
- Tính
- khái niệm
- khái niệm
- Mối quan tâm
- buổi hòa nhạc
- kết luận
- Kết nối
- Hãy xem xét
- sự cân nhắc
- chứa
- nội dung
- Ngược lại
- đóng góp
- thông thường
- Hội tụ
- Chuyển đổi
- chuyển đổi
- mạng lưới thần kinh tích chập
- quyền tác giả
- vi phạm bản quyền
- Trung tâm
- hư hỏng
- CPU
- chế tạo
- tạo
- Tạo
- tạo
- Sáng tạo
- Sáng tạo
- sáng tạo
- người sáng tạo
- quan trọng
- đỉnh điểm
- Cày cấy
- về mặt văn hóa
- lưu trữ
- đường cong
- khách hàng
- chu kỳ
- nhảy
- dữ liệu
- bộ dữ liệu
- tranh luận
- sâu
- xác định
- nhu cầu
- chứng minh
- chiều sâu
- Độ sâu
- Nguồn gốc
- được chỉ định
- chi tiết
- chi tiết
- chi tiết
- phát triển
- thiết bị
- khác nhau
- sự khác biệt
- khác nhau
- Lôi thôi
- kỹ thuật số
- Nghệ thuật kỹ thuật số
- kỹ thuật số
- kích thước
- kích thước
- tùy ý
- Giao diện
- hiển thị
- khác biệt
- phân biệt
- khác nhau
- SỰ ĐA DẠNG
- do
- làm
- cửa ra vào
- vẽ tranh
- Bản vẽ
- suốt trong
- năng động
- năng động
- động lực
- e
- mỗi
- bỏ lỡ
- tiếng vang
- hiệu ứng
- Kỹ lưỡng
- khác
- nổi lên
- mã hóa
- bao gồm
- bao trùm
- Kỹ Sư
- nâng cao
- đảm bảo
- đảm bảo
- đảm bảo
- Toàn bộ
- Môi trường
- kỷ nguyên
- kỷ nguyên
- Kỷ nguyên
- lôi
- bản chất
- thiết yếu
- thành lập
- Ether (ETH)
- đạo đức
- đạo đức
- đánh giá
- Mỗi
- sự tiến hóa
- phát triển
- phát triển
- tiến hóa
- kiểm tra
- Excel
- Trừ
- hiện tại
- Mở rộng
- mở rộng
- mong đợi
- thăm dò
- khám phá
- biểu hiện
- gia tăng
- mở rộng
- mắt
- Mắt
- mặt
- trung thành
- sai
- quen
- hấp dẫn
- Tính năng
- Với
- lòng trung thành
- Hình
- Tập tin
- Các tập tin
- cuối cùng
- hoàn thành
- Tên
- Tập trung
- tiếp theo
- Trong
- đi đầu
- Forward
- Foster
- bồi dưỡng
- Khung
- khung
- từ
- đầy đủ
- chức năng
- chức năng
- cơ bản
- xa hơn
- nhiệt hạch
- tương lai
- Thu được
- GAN
- thu thập
- cho
- tạo ra
- tạo ra
- tạo ra
- thế hệ
- thế hệ
- mạng lưới nghịch cảnh
- Trí tuệ nhân tạo
- máy phát điện
- Cho
- mục tiêu
- GPU
- gradients
- dần dần
- sự cao quý
- sự hiểu biết
- lớn hơn
- đột phá
- hướng dẫn
- hướng dẫn
- Hướng dẫn
- tay
- Khai thác
- Trái Tim
- tại đây
- Ẩn giấu
- nổi bật
- lịch sử
- tổ chức
- tỏ lòng tôn kính
- danh dự
- Độ đáng tin của
- Tuy nhiên
- HTTPS
- Nhân loại
- i
- ý tưởng
- if
- bắt lửa
- hình ảnh
- hình ảnh
- trí tưởng tượng
- bắt buộc
- thực hiện
- hàm ý
- nhập khẩu
- quan trọng
- nâng cao
- in
- bao gồm
- Bao gồm
- Bao gồm
- kết hợp
- tăng
- gia tăng
- Đương nhiệm
- ảnh hưởng
- bị ảnh hưởng
- sự vi phạm
- ngây thơ
- đổi mới
- sự đổi mới
- đầu vào
- đầu vào
- cái nhìn sâu sắc
- thiếu
- Tích hợp
- tính toàn vẹn
- trí tuệ
- sở hữu trí tuệ
- quan tâm
- giải thích
- trong
- phức tạp
- giới thiệu
- trực giác
- tham gia
- các vấn đề
- IT
- sự lặp lại
- sự lặp lại
- ITS
- cuộc hành trình
- jpg
- thẩm phán
- Thiếu sót
- cảnh quan
- lớp
- lớp
- học
- học tập
- Hợp pháp
- khuôn khổ pháp lý
- Pháp luật
- ống kính
- nằm
- Cuộc sống
- ánh sáng
- Lượt thích
- tải
- NHÌN
- sự mất
- thiệt hại
- máy
- học máy
- duy trì
- tuyệt vời
- kiệt tác
- Trận đấu
- vật liệu
- matplotlib
- nghĩa là
- cơ chế
- cơ chế
- Phương tiện truyền thông
- chỉ đơn thuần là
- sáp nhập
- phương pháp
- có phương pháp
- số liệu
- giảm thiểu
- phút
- phản ánh
- ML
- Thuật toán ML
- Chế độ
- kiểu mẫu
- mô hình
- hiện đại
- mô-đun
- chi tiết
- di chuyển
- nhiều
- MUSE
- phải
- tên
- non trẻ
- Thiên nhiên
- Điều hướng
- cần thiết
- nhu cầu
- mạng
- mạng
- Thần kinh
- Kỹ thuật thần kinh
- mạng lưới thần kinh
- mạng thần kinh
- Mới
- Tiếng ồn
- ghi
- tiểu thuyết
- tại
- che
- tuân theo
- quan sát
- of
- off
- phản cảm
- cung cấp
- cung cấp
- Cung cấp
- thường
- on
- đang diễn ra
- có thể
- mở ra
- Tối ưu hóa
- or
- nguyên
- độc đáo
- Bản gốc
- OS
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- đầu ra
- kết quả đầu ra
- kết thúc
- sở hữu
- bức tranh
- bức tranh
- tham số
- thông số
- một phần
- các bên tham gia
- vượt qua
- qua
- con đường
- Họa tiết
- mô hình
- nhận thức
- hoàn thiện
- thực hiện
- quan điểm
- hình ảnh
- mảnh
- miếng
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chân dung
- tiềm năng
- thực hành
- Độ chính xác
- sơ bộ
- trình bày
- quà
- bảo quản
- ngăn chặn
- ngăn chặn
- nguyên tắc
- in ấn
- ưu tiên
- quá trình
- xử lý
- sản xuất
- Sản phẩm
- Hồ sơ
- thâm thúy
- Tiến độ
- tiến triển
- dần dần
- hứa hẹn
- Thúc đẩy
- nhắc nhở
- tuyên truyền
- đúng
- tài sản
- bảo vệ
- bảo vệ
- nguồn gốc
- cung cấp
- công bố
- theo đuổi
- ngọn đuốc
- định lượng
- ngẫu nhiên
- ngẫu nhiên
- phạm vi
- Tỷ lệ
- sẵn sàng
- vương quốc
- công nhận
- Xác định lại
- lọc
- tinh chế
- phản ánh
- phản ánh
- chế độ
- đều đặn
- mối quan hệ
- loại bỏ
- vẽ
- nhân rộng
- đại diện
- đại diện cho
- sinh sản
- yêu cầu
- đòi hỏi
- giống như
- định hình lại
- tôn trọng
- tôn trọng
- chịu trách nhiệm
- có trách nhiệm
- kết quả
- trở lại
- sự mặc khải
- Hồi sinh
- cách mạng hóa
- RGB
- Giàu
- quyền
- Tăng lên
- mạnh mẽ
- Vai trò
- tương tự
- lưu
- tiết kiệm
- bối cảnh
- Khoa học
- phạm vi
- kịch bản
- xem
- TỰ
- nhạy cảm
- riêng biệt
- Trình tự
- phục vụ
- định
- thiết lập
- thiết lập
- một số
- Bóng tối
- định hình
- thay đổi
- Thay đổi
- nên
- giới thiệu
- giới th
- thể hiện
- có ý nghĩa
- kể từ khi
- chậm rãi
- đoạn
- So
- tinh vi
- Linh hồn
- nguồn
- nguồn gốc
- Không gian
- Vôn
- đặc biệt
- quang phổ
- Bình phương
- ổn định
- Traineeship
- đứng
- Bắt đầu
- thống kê
- vững chắc
- Bước
- Chiến lược
- phấn đấu
- cấu trúc
- Stunning
- phong cách
- Tiêu đề
- tiếp theo
- như vậy
- Cộng sinh
- hiệp lực
- tổng hợp
- sợi tổng hợp
- phù hợp
- mất
- dùng
- Mục tiêu
- Kỹ thuật
- kỹ thuật
- công nghệ
- Công nghệ
- Công nghệ
- tensorflow
- di chúc
- việc này
- Sản phẩm
- Tương lai
- Nguồn
- cung cấp their dịch
- Them
- Đó
- Kia là
- họ
- điều này
- phát triển mạnh
- Thông qua
- Như vậy
- đến
- công cụ
- ngọn đuốc
- ngọn đuốc
- chạm
- đối với
- Theo dõi
- truyền thống
- Train
- đào tạo
- Hội thảo
- Chuyển đổi
- Chuyển đổi
- biến đổi
- biến đổi
- chuyển đổi
- biến đổi
- biến đổi
- Minh bạch
- đúng
- thử
- hiểu
- sự hiểu biết
- độc đáo
- cho đến khi
- Công bố
- cập nhật
- trên
- us
- sử dụng
- đã sử dụng
- sử dụng
- tiện ích
- hợp lệ
- xác minh
- thông qua
- xem
- quan điểm
- tầm nhìn
- trực quan
- nghệ thuật thị giác
- hình dung
- hình dung
- trực quan
- quan trọng
- là
- we
- webp
- Điều gì
- Là gì
- cái nào
- trong khi
- Thì thầm
- CHÚNG TÔI LÀ
- rộng
- Phạm vi rộng
- sẽ
- cửa sổ
- với
- ở trong
- không có
- Công việc
- công trinh
- thế giới
- X
- Vâng
- nhưng
- bạn
- zephyrnet
- không