Giới thiệu
Transformers và Mô hình ngôn ngữ lớn đã gây bão trên toàn thế giới sau khi chúng được giới thiệu trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP). Kể từ khi thành lập, lĩnh vực này đã nhanh chóng phát triển với những đổi mới và nghiên cứu giúp các LLM này hoạt động hiệu quả hơn. Chúng bao gồm LoRA (Thích ứng cấp thấp), Chú ý nhanh, Lượng tử hóa và phương pháp Hợp nhất gần đây của các LLM đáng chú ý. Trong hướng dẫn này, chúng ta sẽ xem xét một cách tiếp cận mới để hợp nhất LLM (Mặt trời 10.7B) được giới thiệu bởi Upstage AI.

Mục tiêu học tập
- Hiểu kiến trúc độc đáo của Solar 10.7B và khả năng “mở rộng quy mô theo chiều sâu” đầy sáng tạo của nó
- Khám phá quy trình đào tạo trước của mô hình và dữ liệu đa dạng mà nó sử dụng
- Phân tích các điểm chuẩn hiệu suất ấn tượng của Solar 10.7B trên các tác vụ NLP khác nhau
- So sánh và đối chiếu Solar 10.7B với các LLM đáng chú ý khác, như Mixtral MoE
- Tìm hiểu cách truy cập và làm việc với Solar 10.7B cho các dự án của bạn
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
MẶT TRỜI 10.7B là gì?
Upstange AI đã giới thiệu mô hình Thông số 10.7 tỷ mới, SOLAR 10.7B. Mô hình này là kết quả của việc hợp nhất hai Mô hình tham số 7 tỷ, cụ thể là hai mô hình Llama 2 7 tỷ, đã được đào tạo trước để tạo ra SOLAR 10.7B. Khía cạnh độc đáo của sự hợp nhất này là việc áp dụng một phương pháp tiếp cận mới gọi là Tăng tỷ lệ độ sâu (DUS), tương phản với phương pháp Mixtral nơi sử dụng hỗn hợp các chuyên gia.
Model 10.7B mới hoạt động tốt hơn Mistral 7B, Qwen 14B. Một phiên bản Instruct có tên SOLAR 10.7B Instruct đã được phát hành và khi phát hành, nó đã đứng đầu bảng xếp hạng, vượt qua cả Qwen 72B và Mô hình ngôn ngữ lớn Mixtral 8x7B. Mặc dù là mô hình 10.7 tỷ Tham số, SOLAR có thể hoạt động tốt hơn các LLM có kích thước gấp nhiều lần kích thước của nó
Tăng tỷ lệ tăng chiều sâu là gì?
Hãy hiểu mọi chuyện bắt đầu như thế nào và sự hình thành của SOLAR 10.7B. Tất cả bắt đầu với một Mô hình cơ sở duy nhất. Upstage đã chọn Llama 2 chứa 32 Lớp biến áp cho Mô hình cơ sở của nó do có nhiều Người đóng góp nguồn mở hơn. Sau đó, một bản sao của Mô hình cơ sở này đã được tạo

Sau đó chúng tôi nhận được hai Mô hình cơ sở. Về trọng lượng, Upstage đã lấy trọng lượng đã được huấn luyện trước từ Mistral 7B vì nó hoạt động tốt nhất vào thời điểm đó. Bây giờ, chúng ta bắt đầu mở rộng quy mô theo chiều sâu. Mỗi Mô hình cơ sở chứa 32 Lớp. Từ 32 Lớp này, chúng tôi loại bỏ m Lớp, tức là m Lớp cuối cùng khỏi Mô hình gốc và m lớp đầu tiên khỏi phiên bản sao chép của nó. Điều này thêm tối đa 24 Lớp trong mỗi lớp. Sau đó, chúng tôi hợp nhất hai mô hình này:
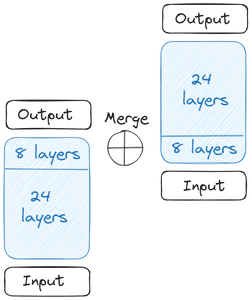
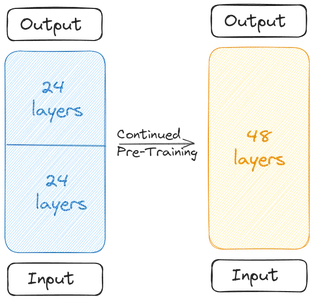
Hai Mô hình cơ sở được nối với nhau để tạo thành mô hình tỷ lệ. Mô hình tỷ lệ hiện có 48 Lớp. Mô hình được chia tỷ lệ hoạt động kém do việc hợp nhất. Do đó, mô hình thu nhỏ trải qua quá trình huấn luyện trước. Việc mở rộng quy mô theo chiều sâu này, sau đó là quá trình Đào tạo trước tiếp tục cùng nhau tạo nên Quy mô tăng chiều sâu (DUS).
Đào tạo MẶT TRỜI 10.7B
Mô hình chia tỷ lệ cần được huấn luyện trước do hiệu suất giảm do hợp nhất. Các nhà sản xuất cho biết hiệu suất đã tăng lên nhanh chóng khi được đào tạo trước. Việc đào tạo trước/tinh chỉnh bao gồm hai giai đoạn
Giai đoạn đầu tiên là Hướng dẫn Tinh chỉnh. Trong loại Tinh chỉnh này, mô hình đã trải qua quá trình đào tạo về bộ dữ liệu để phù hợp với hướng dẫn. Quá trình tinh chỉnh bao gồm làm việc với các bộ dữ liệu Nguồn mở phổ biến như Alpaca-GPT4 và OpenOrca. Bài viết lưu ý rằng chỉ một tập hợp con của tập dữ liệu được sử dụng để tinh chỉnh mô hình đã hợp nhất. Cùng với dữ liệu Nguồn mở, Upstage thậm chí còn đào tạo nó bằng một số dữ liệu Toán học nguồn đóng.
Trong giai đoạn thứ hai, Điều chỉnh căn chỉnh được thực hiện. Trong Điều chỉnh căn chỉnh, chúng tôi thực hiện mô hình tinh chỉnh ở giai đoạn một và tinh chỉnh thêm để phù hợp hơn với con người hoặc các AI mạnh mẽ như GPT4. Điều này được thực hiện thông qua kỹ thuật tương tự DPOTrainer (Tối ưu hóa ưu tiên trực tiếp) và RLHF (Học tăng cường với phản hồi của con người).
Trong Tối ưu hóa tùy chọn trực tiếp, chúng tôi có tập dữ liệu chứa ba cột, Lời nhắc, cột câu trả lời ưa thích và cột câu trả lời bị từ chối. Sau đó, điều này được sử dụng để huấn luyện mô hình chia tỷ lệ nhằm tạo ra các câu trả lời mà chúng ta cần nó tạo ra. Các bộ dữ liệu tương tự đã được huấn luyện để tinh chỉnh lệnh cũng được sử dụng ở đây.
Kết quả đánh giá và điểm chuẩn
Bảng xếp hạng OpenLLM ôm mặt sử dụng một số điểm chuẩn để đánh giá khả năng của Mô hình ngôn ngữ lớn (LLM). Mỗi điểm chuẩn đánh giá các khía cạnh khác nhau về hiệu suất của LLM:
- ARC (Thử thách suy luận AI2): Điểm chuẩn này kiểm tra khả năng của LLM trong việc trả lời các câu hỏi khoa học cấp tiểu học, cung cấp những hiểu biết sâu sắc về sự hiểu biết và lý luận của mô hình về các khái niệm khoa học.
- MMLU (Hiểu ngôn ngữ đa tác vụ lớn): MMLU là một chuẩn mực đa dạng bao gồm 57 nhiệm vụ khác nhau, bao gồm các câu hỏi liên quan đến toán học cơ bản, lịch sử, luật, khoa học máy tính và các vấn đề khác. Nó đánh giá khả năng xử lý và hiểu thông tin của LLM trên nhiều lĩnh vực.
- Xin chào! Nhằm mục đích kiểm tra khả năng suy luận thông thường của LLM, HellaSwag thách thức các mô hình áp dụng logic hàng ngày vào nhiều tình huống khác nhau, đánh giá khả năng đưa ra phán đoán trực quan tương tự như quá trình suy nghĩ của con người.
- Winogrande: Điểm chuẩn này tương tự như HellaSwag, tập trung vào lý luận thông thường nhưng có sắc thái khác so với HellaSwag. Nó đòi hỏi LLM phải thể hiện mức độ hiểu biết phức tạp và lý luận logic.
- QA trung thực: TruthfulQA đánh giá tính chính xác và độ tin cậy của thông tin do LLM cung cấp. Nó bao gồm các câu hỏi từ các lĩnh vực khác nhau bao gồm khoa học, luật pháp, chính trị, v.v., kiểm tra khả năng của mô hình trong việc tạo ra các câu trả lời trung thực và thực tế.
- GSM8K: Được thiết kế đặc biệt để kiểm tra khả năng Toán học, GSM8K bao gồm các bài toán gồm nhiều bước cần suy luận logic và tư duy tính toán, thách thức các LLM đánh giá kỹ năng giải quyết vấn đề của họ trong toán học.
Mô hình SOLAR 10.7B cơ bản hoạt động tốt hơn các mô hình như mô hình Mistral 7B Instruct v0.2 và mô hình Qwen 14B. Phiên bản Hướng dẫn của SOLAR 10.7B thậm chí có thể đánh bại các Mô hình Ngôn ngữ Lớn như Mistral 8x7B, Qwen 72B, Falcon 180B và các Mô hình Ngôn ngữ Lớn khổng lồ khác. Nó đi trước tất cả các mô hình trong ARC và điểm chuẩn TruthfulQA
Bắt đầu với MẶT TRỜI 10.7B
Mô hình SOLAR 10.7B có sẵn trong HuggingFace Hub để hoạt động với thư viện máy biến áp. Ngay cả các mô hình lượng tử hóa của SOLAR 10.7B cũng có sẵn để hoạt động. Trong phần này, chúng ta sẽ tải xuống phiên bản lượng tử hóa và thử nhập mô hình với các tác vụ khác nhau và xem kết quả được tạo ra
Để thử nghiệm với phiên bản lượng tử hóa của SOLAR 10.7B, chúng tôi sẽ làm việc với thư viện llama_cpp_python của Python cho phép chúng tôi chạy các Mô hình ngôn ngữ lớn được lượng tử hóa. Đối với bản demo này, chúng tôi sẽ làm việc với phiên bản Google Colab miễn phí.
Tải xuống gói
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- Sản phẩm CMAKE_ARGS=”-DLLAMA_CUBLAS=bật” và FORCE_CMAKE=1, sẽ cho phép llama_cpp_python để hoạt động với GPU Nvidia có sẵn trong phiên bản colab miễn phí
- Sau đó chúng ta cài đặt llama_cpp_python gói thông qua pip3
- Chúng tôi thậm chí còn tải xuống ôm mặt-trung tâm, mà chúng tôi sẽ tải xuống mô hình SOLAR 10.7B được lượng tử hóa
Để làm việc với mô hình SOLAR 10.7B, trước tiên chúng ta cần tải xuống phiên bản lượng tử hóa của nó. Để tải xuống, chúng tôi sẽ chạy đoạn mã sau:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
Làm việc với Hugging Face Hub
Ở đây, chúng tôi làm việc với ôm_face_hub để tải xuống mô hình lượng tử hóa. Đối với điều này, chúng tôi nhập khẩu hf_hub_download có các tham số sau
- tên_người mẫu: Đây là loại mô hình mà chúng tôi muốn tải xuống. Ở đây chúng tôi muốn tải xuống mô hình GGUF hướng dẫn SOLAR 10.7B
- tệp_mô hình: Ở đây chúng tôi cho biết phiên bản lượng tử hóa nào chúng tôi muốn tải xuống. Tại đây chúng tôi sẽ tải xuống phiên bản lượng tử hóa 2bit của Hướng dẫn SOLAR 10.7B
- Sau đó chúng tôi chuyển các tham số này cho hf_hub_download, lấy các tham số này và tải xuống mô hình đã chỉ định. Sau khi tải xuống, nó trả về đường dẫn tải mô hình xuống
- Đường dẫn trả về này đang được lưu trong model_path biến
Bây giờ, chúng ta có thể tải mô hình này thông qua llama_cpp_python thư viện. Mã để tải mô hình sẽ giống như mã bên dưới
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
Nhập lớp Llama
Chúng tôi nhập lớp Llama từ llama_cpp, có các tham số sau
- model_path: Biến này lấy đường dẫn nơi mô hình của chúng tôi được lưu trữ. Chúng tôi đã có đường dẫn từ bước trước mà chúng tôi sẽ cung cấp ở đây
- n_ctx: Ở đây, chúng tôi đưa ra độ dài ngữ cảnh cho mô hình. Hiện tại, chúng tôi đang cung cấp 512 mã thông báo cho độ dài ngữ cảnh
- n_thread: Ở đây chúng tôi đề cập đến số lượng luồng được lớp Llama sử dụng. Hiện tại, chúng tôi vượt qua nó 8, vì chúng tôi có CPU 4 lõi, trong đó mỗi lõi có thể chạy đồng thời 2 luồng
- n_gpu_layers: Chúng tôi cung cấp số tiền này nếu chúng tôi có GPU đang chạy, điều này chúng tôi làm vì chúng tôi đang làm việc với colab miễn phí. Về vấn đề này, chúng tôi vượt qua 110, cho biết rằng chúng tôi muốn giảm tải toàn bộ mô hình vào GPU và không muốn một phần của nó chạy trong RAM hệ thống
- Cuối cùng, chúng ta tạo một đối tượng từ lớp Llama này và gán nó cho biến llm
Việc chạy mã này sẽ tải mô hình lượng tử hóa SOLAR 10.7B lên GPU và đặt độ dài ngữ cảnh phù hợp. Bây giờ là lúc thực hiện một số suy luận về mô hình này. Đối với điều này, chúng tôi làm việc với mã dưới đây
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
Suy ra mô hình
Để suy ra mô hình, chúng tôi chuyển các tham số sau cho LLM:
- Mẫu nhắc nhở/trò chuyện: Đây là mẫu cần thiết để trò chuyện với người mẫu. Mẫu được đề cập ở trên (### Người dùng:n{user_prompt}?nn### Trợ lý:) là mẫu phù hợp với mô hình SOLAR 10.7B. Trong mẫu, câu sau người sử dang là Lời nhắc của Người dùng và việc tạo sẽ được tạo sau Trợ lý
- max_tokens: Đây là số lượng mã thông báo tối đa mà Mô hình ngôn ngữ lớn có thể xuất ra khi đưa ra Lời nhắc. Hiện tại, chúng tôi đang giới hạn ở mức 512 mã thông báo
- dừng lại: Đây là mã thông báo dừng. Mã thông báo dừng cho Mô hình ngôn ngữ lớn biết rằng nó cần ngừng tạo thêm mã thông báo. Đối với SOLAR 10.7B, mã thông báo dừng là
Việc chạy này sẽ lưu trữ kết quả trong đầu ra Biến đổi. Kết quả được tạo ra tương tự như lệnh gọi API OpenAI. Do đó, chúng ta có thể truy cập thế hệ thông qua câu lệnh in đã cho, tương tự như cách chúng ta truy cập thế hệ từ các phản hồi OpenAI. Đầu ra được tạo ra có thể được nhìn thấy dưới đây

Câu được tạo ra có vẻ đủ tốt và không xuất hiện những lỗi ngữ pháp nghiêm trọng. Chúng ta hãy thử phần ý thức chung của mô hình bằng cách đưa ra Lời nhắc sau
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Ở đây chúng ta thấy hai ví dụ liên quan đến lẽ thường và đáng ngạc nhiên là SOLAR 10.7B xử lý nó rất tốt. Mô hình Ngôn ngữ Lớn có thể đưa ra câu trả lời đúng với một số nội dung hữu ích. Hãy thử kiểm tra khả năng toán học và suy luận của mô hình thông qua các gợi ý sau
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Từ Lời nhắc ví dụ đã cho, SOLAR 10.7B đã tạo ra phản hồi tốt. Nó có thể trả lời chính xác các lý luận toán học và logic đã cho và thậm chí cả những câu hỏi liên quan đến lẽ thường. Nhìn chung, chúng ta có thể kết luận rằng Mô hình ngôn ngữ lớn SOLAR 10.7B đang tạo ra phản hồi tốt
MẶT TRỜI 10.7B so với MoE hỗn hợp
Mixtral 8x7B MoE được tạo ra bởi Mistral AI với kiến trúc Hỗn hợp các Chuyên gia. Tóm lại, Nhóm chuyên gia này, Mistral sử dụng 8 Mô hình tham số 7 tỷ. Mỗi mô hình này có một số mạng chuyển tiếp được thay thế bằng các lớp khác gọi là chuyên gia. Do đó Mixtral 8x7B được coi là có 8 chuyên gia. Và tất cả những người mà mô hình đưa vào Dấu nhắc đầu vào, sẽ có một cơ chế chọn chỉ chọn 2 trong số các chuyên gia này trong số 8 chuyên gia. Sau đó, 2 chuyên gia sẽ nhận Dấu nhắc đầu vào này và tạo mã thông báo đầu ra cuối cùng. Vì vậy, chúng ta có thể thấy rằng có một chút phức tạp liên quan đến kiểu hợp nhất này, trong đó chúng ta phải thay thế các lớp chuyển tiếp nguồn cấp dữ liệu bằng các lớp khác và giới thiệu một cơ chế chọn lọc giữa các chuyên gia này
Trong khi Mô hình SOLAR 10.7B từ Upstage tận dụng phương pháp Tăng tỷ lệ độ sâu. Trong Tăng tỷ lệ chiều sâu, chúng tôi chỉ loại bỏ một số lớp bắt đầu khỏi Mô hình cơ sở và cùng số lượng lớp cuối cùng khỏi phiên bản sao chép của nó. Sau đó, chúng ta chỉ cần hợp nhất các mô hình bằng cách xếp chồng mô hình này lên mô hình kia. Và chỉ với một vài giai đoạn tinh chỉnh, mô hình được hợp nhất có thể cho thấy hiệu suất tăng trưởng nhanh chóng. Ở đây chúng ta không thay thế các lớp hiện có bằng một số lớp khác. Ngoài ra ở đây chúng tôi không có cơ chế kiểm soát. Nhìn chung, Tăng tỷ lệ độ sâu là một cách đơn giản và hiệu quả để hợp nhất các mô hình không phức tạp.
Cũng so sánh hiệu suất, Tăng tỷ lệ độ sâu, mặc dù chỉ bằng cách kết hợp hai Mô hình 7 tỷ, SOLAR 10.7B có thể vượt trội hơn rõ ràng so với Mixtral 8x7B, một mô hình lớn hơn nhiều khi so sánh. Điều này chứng tỏ tính hiệu quả của phương pháp hợp nhất đơn giản so với phương pháp phức tạp như Mixtral of Experts
Hạn chế và Cân nhắc
- Khám phá siêu tham số: Một hạn chế quan trọng là việc khám phá không đầy đủ các siêu tham số trong phương pháp DUS. Do hạn chế về phần cứng, 8 lớp đã bị xóa khỏi cả hai đầu của Mô hình cơ sở mà không xác minh xem con số này có tối ưu để đạt được hiệu suất tốt nhất hay không. Công việc trong tương lai nhằm mục đích tiến hành các thí nghiệm nghiêm ngặt hơn và thực hiện phân tích để giải quyết vấn đề này.
- Yêu cầu tính toán: Mô hình cần một lượng lớn tài nguyên tính toán để đào tạo và suy luận. Điều này có thể hạn chế việc sử dụng nó, chủ yếu dành cho những người có khả năng tính toán hạn chế.
- Xu hướng trong dữ liệu đào tạo: Giống như tất cả các mô hình học máy, nó dễ bị sai lệch trong dữ liệu đào tạo, có khả năng dẫn đến kết quả sai lệch trong một số trường hợp nhất định.
- Tác động môi trường: Ngay cả mức tiêu thụ năng lượng cần thiết cho việc đào tạo và vận hành mô hình cũng đặt ra những lo ngại về môi trường, làm nổi bật tầm quan trọng của việc phát triển AI bền vững.
- Ý nghĩa rộng hơn của mô hình: Mặc dù mô hình cho thấy hiệu suất được cải thiện theo các hướng dẫn sau nhưng nó vẫn yêu cầu tinh chỉnh theo từng nhiệm vụ cụ thể để có hiệu suất tối ưu trong các ứng dụng chuyên biệt. Quá trình tinh chỉnh này tốn nhiều tài nguyên và có thể không phải lúc nào cũng hiệu quả.
Kết luận
Trong hướng dẫn này, chúng tôi đã xem xét mô hình Thông số SOLAR 10.7 tỷ được phát hành gần đây bởi Upstage AI. AI ở giai đoạn cao hơn đã thực hiện một cách tiếp cận mới để hợp nhất và mở rộng quy mô các mô hình. Bài viết đã sử dụng một phương pháp mới gọi là Tăng tỷ lệ độ sâu để hợp nhất hai mô hình Thông số Llama-2 7 tỷ bằng cách loại bỏ một số lớp biến áp khởi đầu và cuối cùng. Sau đó, nó đã tinh chỉnh mô hình trên các bộ dữ liệu Nguồn mở và thử nghiệm nó trên Bảng xếp hạng OpenLLM, đạt được điểm H6 cao nhất và đứng đầu bảng xếp hạng.
Chìa khóa chính
- SOLAR 10.7B giới thiệu Depth Up-Scaling, một phương pháp hợp nhất độc đáo, thách thức các phương pháp truyền thống và thể hiện những tiến bộ trong kiến trúc mô hình
- Mặc dù có 10.7 tỷ thông số, SOLAR 10.7B vẫn vượt trội so với các mẫu lớn hơn, vượt qua Mistral 7B, Qwen 14B và thậm chí đứng đầu bảng xếp hạng với các phiên bản như SOLAR 10.7B Instruct
- Quy trình tinh chỉnh hai giai đoạn bao gồm Hướng dẫn và Điều chỉnh căn chỉnh đảm bảo khả năng thích ứng của mô hình với các nhiệm vụ khác nhau, giúp mô hình thực hiện rất tốt các hướng dẫn và điều chỉnh theo sở thích của con người
- SOLAR 10.7B vượt trội trên nhiều tiêu chuẩn khác nhau, do đó thể hiện năng lực của nó trong các nhiệm vụ từ Toán cơ bản và hiểu ngôn ngữ đến lý luận thông thường và đánh giá tính trung thực
- Có sẵn trên HuggingFace Hub, SOLAR 10.7B cung cấp cho các nhà phát triển và nhà nghiên cứu một công cụ hiệu quả và sẵn có cho các ứng dụng xử lý ngôn ngữ
- Bạn có thể tinh chỉnh mô hình bằng các phương pháp thông thường được sử dụng để tinh chỉnh các mô hình ngôn ngữ lớn. Ví dụ: bạn có thể sử dụng Trình huấn luyện tinh chỉnh được giám sát (SFTrainer) từ Ôm mặt để tinh chỉnh Mô hình SOLAR 10.7B.
Những câu hỏi thường gặp
A. SOLAR 10.7B là mô hình 10.7 tỷ tham số của Upstage AI, sử dụng kỹ thuật hợp nhất độc đáo có tên là Depth Up-Scaling. Nó tạo nên sự khác biệt bằng cách vượt trội so với các LLM lớn hơn và thể hiện những tiến bộ trong các mô hình hợp nhất.
A. Chia tỷ lệ theo chiều sâu bao gồm hai mô hình cơ sở. Quá trình này bao gồm việc hợp nhất trực tiếp hai mô hình cơ sở này bằng cách xếp chúng lên nhau. Trước khi quá trình hợp nhất diễn ra, các lớp ban đầu của một mô hình và các lớp cuối cùng của mô hình kia sẽ bị xóa.
A. SOLAR 10.7B trải qua quá trình đào tạo trước hai giai đoạn. Tinh chỉnh hướng dẫn bao gồm việc đào tạo mô hình trên các tập dữ liệu nhấn mạnh vào việc tuân theo hướng dẫn. Điều chỉnh căn chỉnh sẽ tinh chỉnh sự liên kết của mô hình với các tùy chọn của con người bằng cách sử dụng kỹ thuật được gọi là Tối ưu hóa tùy chọn trực tiếp (DPO).
A. SOLAR 10.7B vượt trội trên nhiều điểm chuẩn khác nhau, bao gồm ARC (Thử thách lý luận AI2), MMLU (Hiểu ngôn ngữ đa tác vụ quy mô lớn), HellaSwag, Winogrande, TruthfulQA và GSM8K. Nó đạt được điểm số cao, thể hiện tính linh hoạt trong việc xử lý các nhiệm vụ ngôn ngữ khác nhau.
A. SOLAR 10.7B vượt qua các mẫu như Mistral 7B và Qwen 14B, cho thấy hiệu suất vượt trội mặc dù có ít thông số hơn. Phiên bản hướng dẫn thậm chí còn cạnh tranh và vượt trội hơn các mẫu rất lớn, bao gồm Mistral 8x7B và Qwen 72B, trên nhiều tiêu chuẩn khác nhau.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 10
- 110
- 12
- 15%
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- khả năng
- có khả năng
- Có khả năng
- truy cập
- chính xác
- Đạt được
- đạt được
- ngang qua
- địa chỉ
- Thêm
- tiến bộ
- Sau
- trước
- AI
- AIX NUMX
- nhằm vào
- Mục tiêu
- sắp xếp
- căn chỉnh
- sắp xếp
- liên kết
- Tất cả
- cho phép
- dọc theo
- Ngoài ra
- luôn luôn
- số lượng
- an
- phân tích
- phân tích
- Phân tích Vidhya
- và
- Một
- trả lời
- câu trả lời
- api
- Các Ứng Dụng
- các ứng dụng
- Đăng Nhập
- phương pháp tiếp cận
- thích hợp
- Arc
- kiến trúc
- LÀ
- khu vực
- bài viết
- AS
- khía cạnh
- các khía cạnh
- đánh giá
- Đánh giá
- Trợ lý
- At
- sự chú ý
- có sẵn
- cơ sở
- cơ bản
- BE
- đánh bại
- bởi vì
- được
- trước
- bắt đầu
- được
- phía dưới
- điểm chuẩn
- Điểm chuẩn
- BEST
- giữa
- thành kiến
- Tỷ
- Một chút
- cuộc thi viết blog
- cả hai
- rộng hơn
- nhưng
- by
- cuộc gọi
- gọi là
- CAN
- khả năng
- nhất định
- thách thức
- thách thức
- thách thức
- trò chuyện trên mạng
- lựa chọn
- lựa chọn
- tốt nghiệp lớp XNUMX
- Rõ ràng
- đóng cửa
- mã
- Cột
- Cột
- kết hợp
- Đến
- Chung
- Common Sense
- so sánh
- so
- so sánh
- sự so sánh
- cạnh tranh
- phức tạp
- phức tạp
- phức tạp
- tính toán
- máy tính
- Khoa học Máy tính
- khái niệm
- Mối quan tâm
- kết luận
- Tiến hành
- xem xét
- tiêu thụ
- chứa
- nội dung
- bối cảnh
- tiếp tục
- Ngược lại
- đóng góp
- Trung tâm
- đúng
- có thể
- bìa
- CPU
- tạo
- tạo ra
- quan trọng
- dữ liệu
- bộ dữ liệu
- giảm
- cung cấp
- nhu cầu
- Demo
- chứng minh
- thể hiện
- chiều sâu
- thiết kế
- Mặc dù
- phát triển
- Phát triển
- khác nhau
- trực tiếp
- trực tiếp
- kỷ luật
- tùy ý
- phân biệt
- khác nhau
- do
- làm
- thực hiện
- tải về
- Tải xuống
- hai
- mỗi
- ăn
- Hiệu quả
- hiệu quả
- hiệu quả
- Trứng
- nhấn mạnh
- việc làm
- sử dụng
- kết thúc
- năng lượng
- Tiêu thụ năng lượng
- đủ
- đảm bảo
- Toàn bộ
- môi trường
- mối quan tâm về môi trường
- kỷ nguyên
- Ether (ETH)
- đánh giá
- đánh giá
- Ngay cả
- hàng ngày
- mọi người
- phát triển
- ví dụ
- ví dụ
- hiện tại
- thí nghiệm
- các chuyên gia
- thăm dò
- Đối mặt
- Thực tế
- chim ưng
- xa
- nhanh hơn
- thông tin phản hồi
- vài
- ít hơn
- lĩnh vực
- cuối cùng
- Tên
- Đèn flash
- tập trung
- sau
- tiếp theo
- Trong
- hình thức
- hình thành
- Miễn phí
- từ
- xa hơn
- tương lai
- tạo ra
- tạo ra
- tạo ra
- thế hệ
- được
- nhận được
- Cho
- được
- Cho
- tốt
- có
- GPU
- Tăng trưởng
- hướng dẫn
- Xử lý
- Xử lý
- phần cứng
- Có
- có
- vì thế
- tại đây
- Cao
- cao nhất
- làm nổi bật
- lịch sử
- Độ đáng tin của
- Hướng dẫn
- HTTPS
- Hub
- lớn
- ÔmKhuôn Mặt
- Nhân loại
- Con người
- if
- Va chạm
- hàm ý
- nhập khẩu
- tầm quan trọng
- ấn tượng
- cải thiện
- in
- khởi đầu
- bao gồm
- bao gồm
- Bao gồm
- thông tin
- ban đầu
- đổi mới
- sáng tạo
- đầu vào
- những hiểu biết
- cài đặt, dựng lên
- ví dụ
- hướng dẫn
- trong
- giới thiệu
- giới thiệu
- Giới thiệu
- trực quan
- liên quan
- tham gia
- liên quan đến
- liên quan đến
- IT
- ITS
- chính nó
- nhà vệ sinh
- bản án
- chỉ
- kumar
- Ngôn ngữ
- lớn
- lớn hơn
- Luật
- nằm xuống
- lớp
- leaderboards
- hàng đầu
- học tập
- Chiều dài
- cho phép
- Cấp
- đòn bẩy
- Thư viện
- đời
- Lượt thích
- LIMIT
- giới hạn
- hạn chế
- Hạn chế
- Loài đà mã ở nam mỹ
- tải
- tải
- logic
- hợp lý
- Xem
- máy
- học máy
- phần lớn
- chính
- làm cho
- Các nhà sản xuất
- LÀM CHO
- Làm
- nhiều
- lớn
- toán học
- toán học
- toán học
- max-width
- tối đa
- số tiền tối đa
- Có thể..
- cơ chế
- Phương tiện truyền thông
- đề cập đến
- đi
- sáp nhập
- phương pháp
- phương pháp
- sai lầm
- hỗn hợp
- kiểu mẫu
- mô hình
- chi tiết
- hiệu quả hơn
- nhiều
- tên
- cần thiết
- Cần
- cần thiết
- nhu cầu
- mạng
- Mới
- tiếp theo
- nlp
- Nổi bật
- lưu ý
- tại
- che
- con số
- Nvidia
- vật
- of
- on
- ONE
- có thể
- mở
- mã nguồn mở
- OpenAI
- hoạt động
- tối ưu
- tối ưu hóa
- or
- nguyên
- Nền tảng khác
- Khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- kết quả
- Vượt trội hơn
- vượt trội
- vượt trội
- Vượt trội hơn
- đầu ra
- kết thúc
- tổng thể
- sở hữu
- Giấy
- tham số
- thông số
- một phần
- vượt qua
- con đường
- thực hiện
- hiệu suất
- biểu diễn
- thực hiện
- biểu diễn
- thực hiện
- Nơi
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chính trị
- Phổ biến
- đặt ra
- có khả năng
- mạnh mẽ
- ưu đãi
- ưa thích
- trình bày
- trước
- In
- giải quyết vấn đề
- vấn đề
- quá trình
- Quy trình
- nhắc nhở
- chứng minh
- cung cấp
- cung cấp
- cung cấp
- công bố
- Python
- Câu hỏi
- Mau
- khác nhau,
- nhanh
- sẵn sàng
- gần đây
- gần đây
- đều đặn
- học tăng cường
- Phế phẩm..
- liên quan
- phát hành
- phát hành
- độ tin cậy
- tẩy
- Đã loại bỏ
- loại bỏ
- thay thế
- thay thế
- đòi hỏi
- nghiên cứu
- nhà nghiên cứu
- nguồn lực chuyên sâu
- Thông tin
- phản ứng
- phản ứng
- kết quả
- Kết quả
- Trả về
- ngay
- nghiêm ngặt
- Phục Sinh
- chạy
- chạy
- chạy
- Nói
- tương tự
- lưu
- Quy mô
- mở rộng quy mô
- kịch bản
- Khoa học
- khoa học
- Điểm số
- điểm
- Thứ hai
- Phần
- xem
- nhìn thấy
- dường như
- đã xem
- ý nghĩa
- kết án
- Loạt Sách
- định
- một số
- nên
- hiển thị
- giới th
- hiển thị
- thể hiện
- Chương trình
- tương tự
- Đơn giản
- kể từ khi
- duy nhất
- kỹ năng
- điện thoại thông minh
- So
- hệ mặt trời
- một số
- tinh vi
- nguồn
- chuyên nghành
- đặc biệt
- quy định
- xếp chồng
- Traineeship
- đứng
- Bắt đầu
- bắt đầu
- Bắt đầu
- bắt đầu
- Tuyên bố
- Bước
- Vẫn còn
- Dừng
- hàng
- lưu trữ
- bão
- như vậy
- cao
- vượt qua
- vượt qua
- apt
- bền vững
- SVG
- hệ thống
- Hãy
- Lấy
- mất
- nhiệm vụ
- kỹ thuật
- nói
- nói
- mẫu
- thử nghiệm
- thử nghiệm
- Kiểm tra
- kiểm tra
- văn bản
- hơn
- việc này
- Sản phẩm
- thế giới
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- Suy nghĩ
- điều này
- những
- Tuy nhiên?
- nghĩ
- số ba
- Thông qua
- Như vậy
- thời gian
- thời gian
- đến
- bên nhau
- mã thông báo
- Tokens
- công cụ
- hàng đầu
- đứng đầu
- truyền thống
- Train
- đào tạo
- Hội thảo
- biến áp
- máy biến áp
- thử
- hai
- kiểu
- trải qua
- hiểu
- sự hiểu biết
- trải qua
- độc đáo
- trên
- us
- Sử dụng
- sử dụng
- đã sử dụng
- hữu ích
- người sử dang
- sử dụng
- sử dụng
- sử dụng
- tận dụng
- Bằng cách sử dụng
- biến
- nhiều
- khác nhau
- xác minh
- tính linh hoạt
- phiên bản
- rất
- vs
- muốn
- là
- Đường..
- we
- webp
- TỐT
- là
- Điều gì
- Là gì
- khi nào
- cái nào
- trong khi
- rộng hơn
- sẽ
- với
- không có
- Công việc
- đang làm việc
- công trinh
- thế giới
- bạn
- trên màn hình
- zephyrnet