Cải thiện cách người dùng khám phá nội dung mới là rất quan trọng để tăng mức độ tương tác và sự hài lòng của người dùng trên nền tảng truyền thông. Chỉ tìm kiếm từ khóa đã có những thách thức trong việc nắm bắt ngữ nghĩa và mục đích của người dùng, dẫn đến kết quả thiếu ngữ cảnh phù hợp; ví dụ: tìm buổi tối hẹn hò hoặc phim có chủ đề Giáng sinh. Điều này có thể làm giảm tỷ lệ giữ chân nếu người dùng không thể tìm thấy nội dung họ muốn một cách đáng tin cậy. Tuy nhiên, với mô hình ngôn ngữ lớn (LLM), sẽ có cơ hội giải quyết những thách thức về ngữ nghĩa và ý định của người dùng này. Bằng cách phối hợp nhúng nắm bắt ngữ nghĩa bằng một kỹ thuật gọi là Truy xuất thế hệ tăng cường (RAG), bạn có thể tạo các câu trả lời phù hợp hơn dựa trên ngữ cảnh được truy xuất từ nguồn dữ liệu của riêng bạn.
Trong bài đăng này, chúng tôi chỉ cho bạn cách tạo chatbot phim một cách an toàn bằng cách triển khai RAG bằng dữ liệu của riêng bạn bằng cách sử dụng Cơ sở kiến thức cho nền tảng Amazon. Chúng tôi sử dụng tập dữ liệu IMDb và Box Office Mojo để mô phỏng danh mục dành cho khách hàng truyền thông và giải trí, đồng thời giới thiệu cách bạn có thể xây dựng giải pháp RAG của riêng mình chỉ trong vài bước.
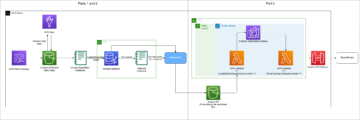
Tổng quan về giải pháp
Sản phẩm IMDb và Box Office Mojo Phim/TV/OTT gói dữ liệu có thể cấp phép cung cấp nhiều loại siêu dữ liệu giải trí, bao gồm hơn 1.6 tỷ xếp hạng của người dùng; tín dụng cho hơn 13 triệu diễn viên và thành viên phi hành đoàn; 10 triệu tựa phim, truyền hình và giải trí; và dữ liệu báo cáo phòng vé toàn cầu từ hơn 60 quốc gia. Nhiều khách hàng phương tiện và giải trí AWS cấp phép cho dữ liệu IMDb thông qua Trao đổi dữ liệu AWS để cải thiện khả năng khám phá nội dung và tăng mức độ tương tác cũng như giữ chân khách hàng.
Giới thiệu Cơ sở tri thức của Amazon Bedrock
Để trang bị cho LLM thông tin độc quyền cập nhật, các tổ chức sử dụng RAG, một kỹ thuật liên quan đến việc tìm nạp dữ liệu từ các nguồn dữ liệu của công ty và làm phong phú thêm lời nhắc bằng dữ liệu đó để đưa ra phản hồi chính xác và phù hợp hơn. Cơ sở kiến thức dành cho Amazon Bedrock hỗ trợ khả năng RAG được quản lý hoàn toàn, cho phép bạn tùy chỉnh phản hồi LLM bằng dữ liệu công ty có liên quan và theo ngữ cảnh. Cơ sở Kiến thức tự động hóa quy trình làm việc RAG từ đầu đến cuối, bao gồm nhập, truy xuất, tăng cường lời nhắc và trích dẫn, giúp bạn không cần phải viết mã tùy chỉnh để tích hợp nguồn dữ liệu và quản lý truy vấn. Cơ sở Kiến thức dành cho Amazon Bedrock cũng cho phép hội thoại nhiều lượt để LLM có thể trả lời các truy vấn phức tạp của người dùng bằng câu trả lời chính xác.
Chúng tôi sử dụng các dịch vụ sau như một phần của giải pháp này:
Chúng tôi đi qua các bước cấp cao sau:
- Xử lý trước dữ liệu IMDb để tạo tài liệu từ mọi bản ghi phim và tải dữ liệu lên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) xô.
- Tạo nền tảng kiến thức.
- Đồng bộ hóa cơ sở kiến thức của bạn với nguồn dữ liệu của bạn.
- Sử dụng cơ sở kiến thức để trả lời các truy vấn ngữ nghĩa về danh mục phim.
Điều kiện tiên quyết
Dữ liệu IMDb được sử dụng trong bài đăng này yêu cầu giấy phép nội dung thương mại và đăng ký trả phí cho gói cấp phép IMDb và Box Office Mojo Movies/TV/OTT trên AWS Data Exchange. Để hỏi về giấy phép và truy cập dữ liệu mẫu, hãy truy cập nhà phát triển.imdb.com. Để truy cập tập dữ liệu, hãy tham khảo Đề xuất và tìm kiếm hiệu quả bằng sơ đồ tri thức IMDb – Phần 1 và làm theo Truy cập dữ liệu IMDb phần.
Xử lý trước dữ liệu IMDb
Trước khi tạo cơ sở kiến thức, chúng ta cần xử lý trước tập dữ liệu IMDb thành các tệp văn bản và tải chúng lên vùng lưu trữ S3. Trong bài đăng này, chúng tôi mô phỏng danh mục khách hàng bằng cách sử dụng bộ dữ liệu IMDb. Chúng tôi lấy 10,000 bộ phim nổi tiếng từ tập dữ liệu IMDb cho danh mục và xây dựng tập dữ liệu.
Sử dụng những thứ sau máy tính xách tay để tạo tập dữ liệu với thông tin bổ sung như tên diễn viên, đạo diễn và nhà sản xuất. Chúng tôi sử dụng đoạn mã sau để tạo một tệp duy nhất cho một bộ phim với tất cả thông tin được lưu trữ trong tệp dưới dạng văn bản phi cấu trúc mà LLM có thể hiểu được:
Sau khi có dữ liệu ở định dạng .txt, bạn có thể tải dữ liệu lên Amazon S3 bằng lệnh sau:
Tạo cơ sở kiến thức IMDb
Hoàn thành các bước sau để tạo cơ sở kiến thức của bạn:
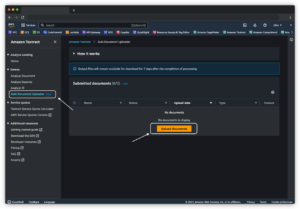
- Trên bảng điều khiển Amazon Bedrock, chọn Kiến thức cơ bản trong khung điều hướng.
- Chọn Tạo nền tảng kiến thức.
- Trong Tên cơ sở kiến thức, đi vào
imdb. - Trong Mô tả cơ sở kiến thức, hãy nhập mô tả tùy chọn, chẳng hạn như Cơ sở kiến thức để nhập và lưu trữ dữ liệu imdb.
- Trong Quyền IAM, lựa chọn Tạo và sử dụng vai trò dịch vụ mới, sau đó nhập tên cho vai trò dịch vụ mới của bạn.
- Chọn Sau.
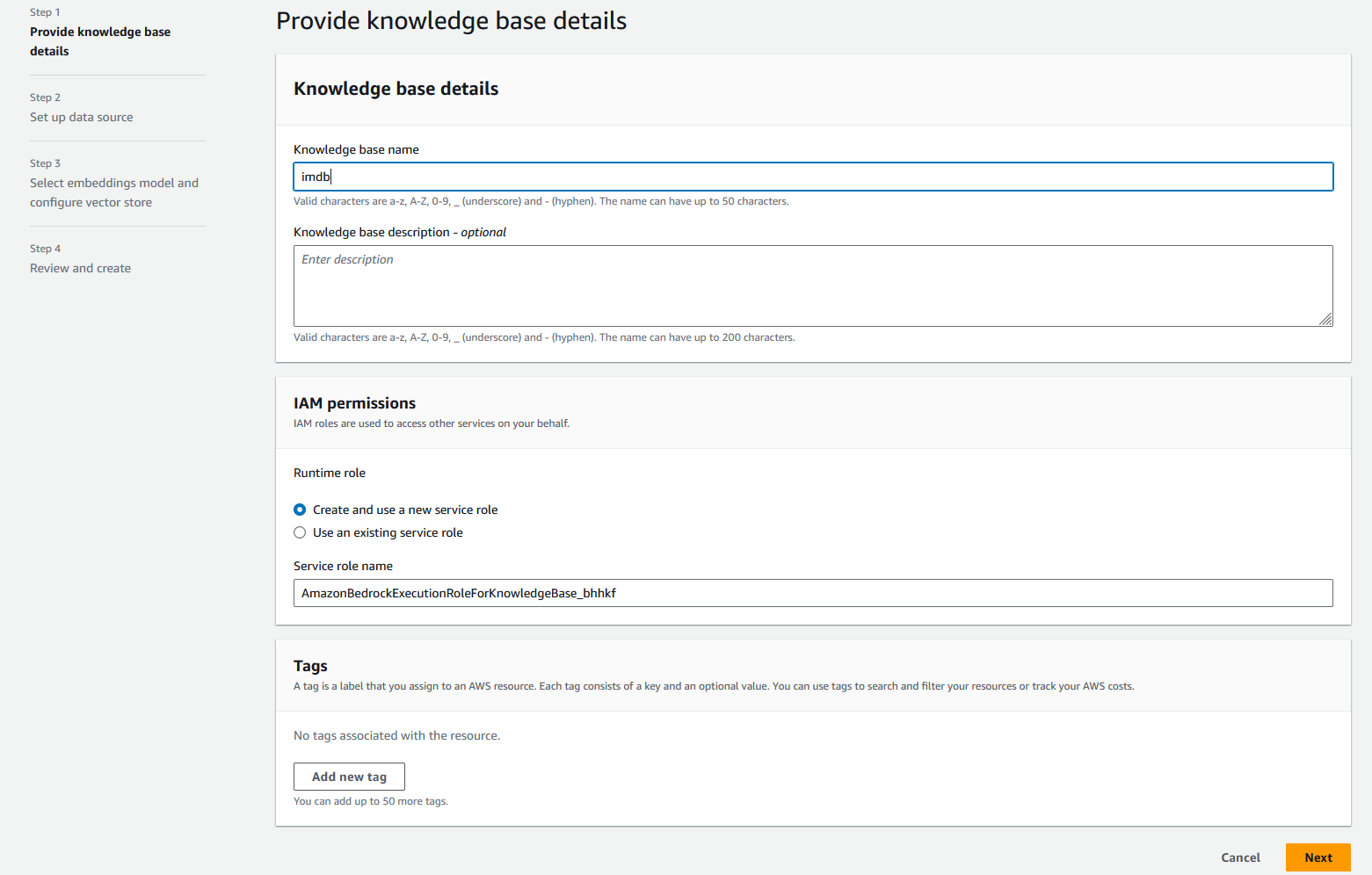
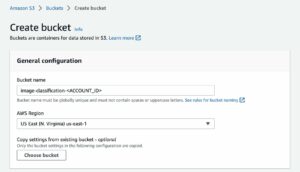
- Trong Tên nguồn dữ liệu, đi vào
imdb-s3. - Trong URI S3, hãy nhập URI S3 mà bạn đã tải dữ liệu lên.
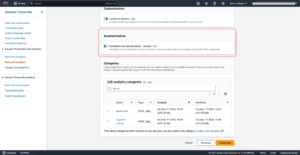
- Trong tạp chí Cài đặt nâng cao - tùy chọn phần, cho Chiến lược chia nhỏ, chọn Không phân chia.
- Chọn Sau.
Cơ sở kiến thức cho phép bạn chia tài liệu thành các phân đoạn nhỏ hơn để giúp bạn xử lý các tài liệu lớn một cách đơn giản. Trong trường hợp của chúng tôi, chúng tôi đã chia dữ liệu thành một tài liệu có kích thước nhỏ hơn (mỗi tài liệu một phim).
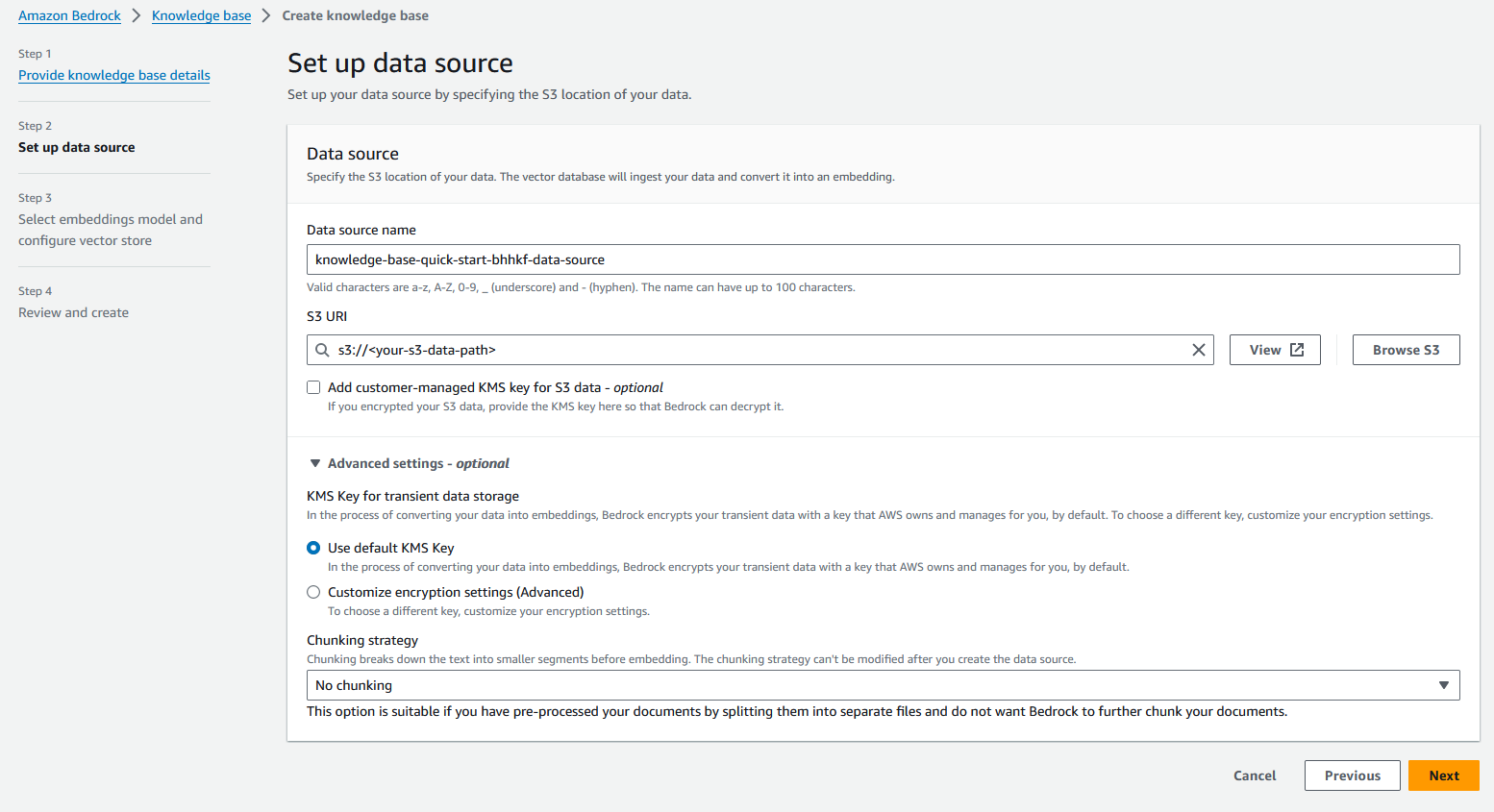
- Trong tạp chí Cơ sở dữ liệu vectơ phần, chọn Tạo nhanh một cửa hàng vector mới.
Amazon Bedrock sẽ tự động tạo bộ sưu tập tìm kiếm vectơ OpenSearch Serverless được quản lý hoàn toàn và định cấu hình cài đặt để nhúng nguồn dữ liệu của bạn bằng cách sử dụng mô hình nhúng Titan Embedding G1 – Văn bản đã chọn.
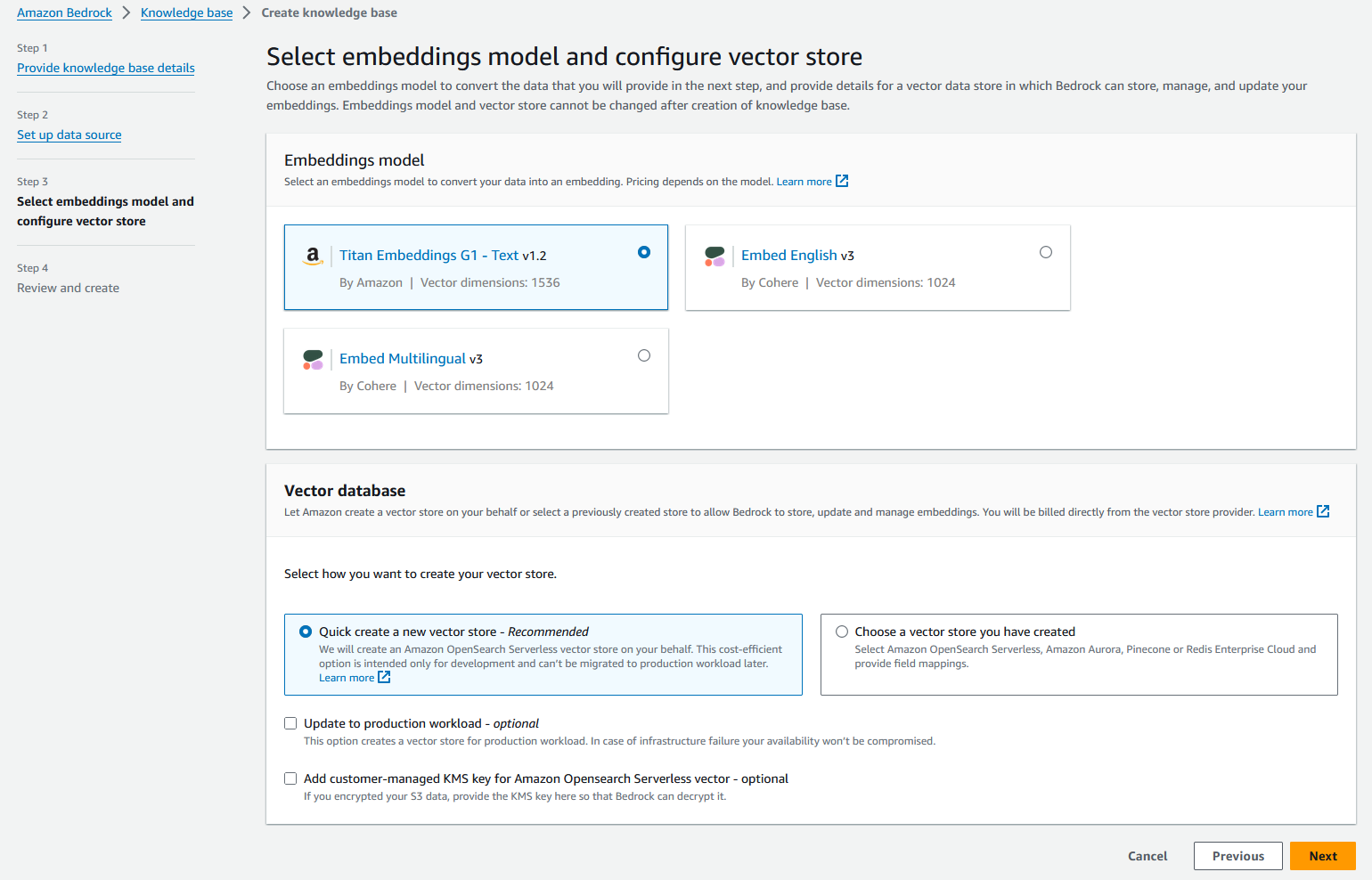
- Chọn Sau.
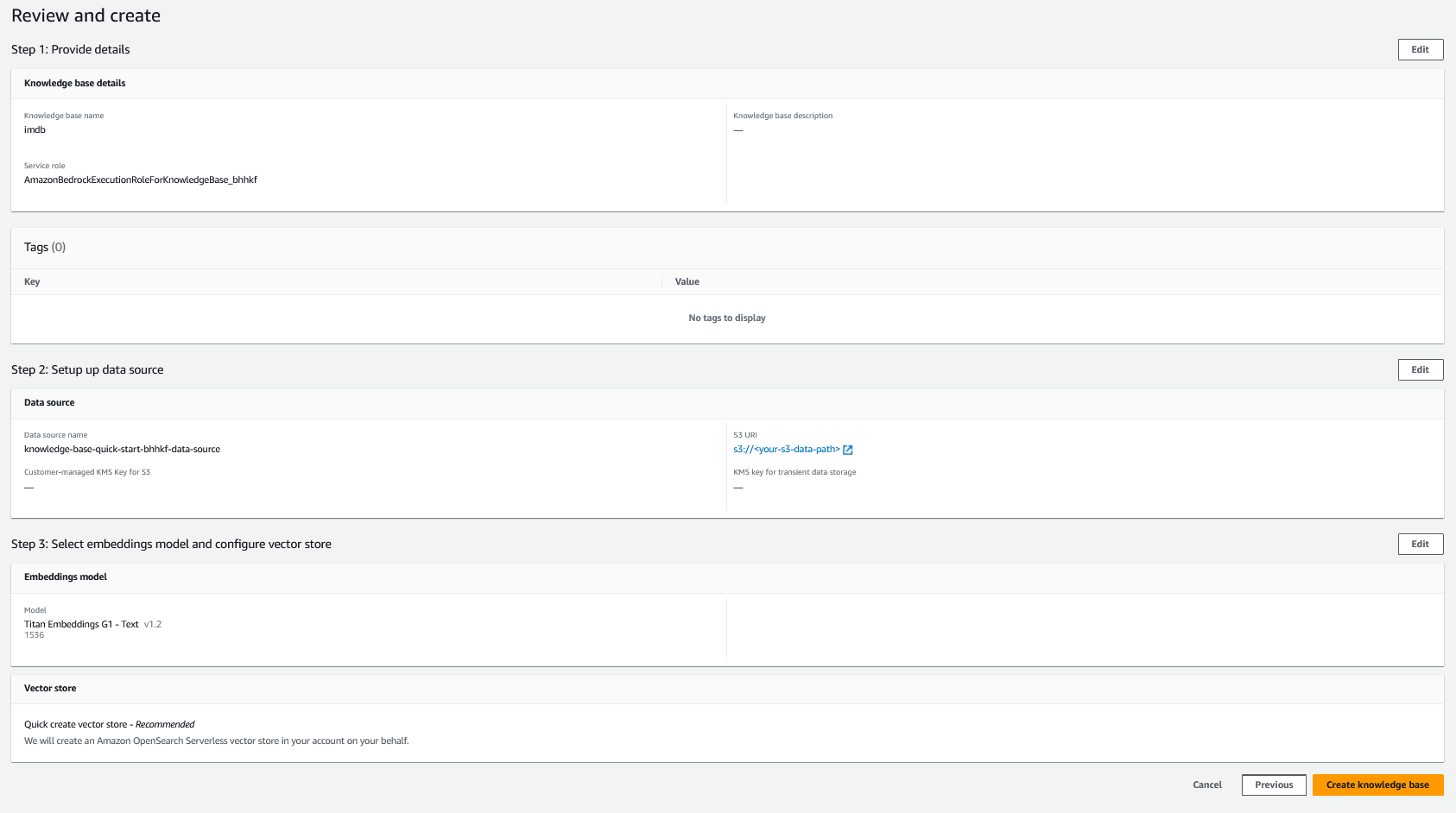
- Xem lại cài đặt của bạn và chọn Tạo nền tảng kiến thức.
Đồng bộ hóa dữ liệu của bạn với cơ sở kiến thức
Bây giờ bạn đã tạo cơ sở kiến thức của mình, bạn có thể đồng bộ hóa cơ sở kiến thức với dữ liệu của mình.
- Trên bảng điều khiển Amazon Bedrock, hãy điều hướng đến cơ sở kiến thức của bạn.
- Trong tạp chí Nguồn dữ liệu phần, chọn Đồng bộ.

Sau khi nguồn dữ liệu được đồng bộ hóa, bạn đã sẵn sàng truy vấn dữ liệu.
Cải thiện tìm kiếm bằng kết quả ngữ nghĩa
Hoàn thành các bước sau để kiểm tra giải pháp và cải thiện tìm kiếm của bạn bằng kết quả ngữ nghĩa:
- Trên bảng điều khiển Amazon Bedrock, hãy điều hướng đến cơ sở kiến thức của bạn.
- Chọn cơ sở kiến thức của bạn và chọn Kiểm tra cơ sở kiến thức.
- Chọn Chọn mô hình, và lựa chọn Nhân chủng học Claude v2.1.
- Chọn Đăng Nhập.
Bây giờ bạn đã sẵn sàng để truy vấn dữ liệu.
Chúng ta có thể hỏi một số câu hỏi ngữ nghĩa, chẳng hạn như “Giới thiệu cho tôi một số bộ phim có chủ đề Giáng sinh”.
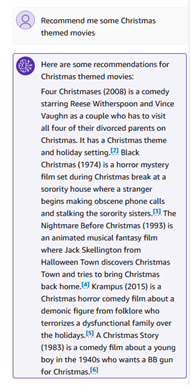
Các phản hồi cơ sở kiến thức chứa các trích dẫn mà bạn có thể khám phá để biết tính chính xác và tính xác thực của phản hồi.
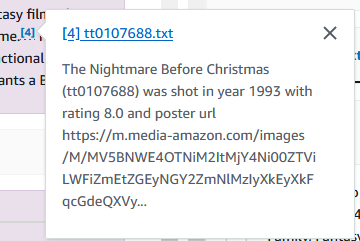
Bạn cũng có thể tìm hiểu sâu bất kỳ thông tin nào bạn cần từ những bộ phim này. Trong ví dụ sau, chúng tôi hỏi “ai đã chỉ đạo cơn ác mộng trước Giáng sinh?”

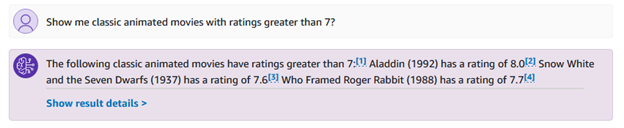
Bạn cũng có thể hỏi những câu hỏi cụ thể hơn liên quan đến thể loại và xếp hạng, chẳng hạn như “cho tôi xem những bộ phim hoạt hình cổ điển có xếp hạng lớn hơn 7?”
Nâng cao nền tảng kiến thức của bạn với các đại lý
Đại lý cho Amazon Bedrock giúp bạn tự động hóa các tác vụ phức tạp. Nhân viên có thể chia truy vấn của người dùng thành các tác vụ nhỏ hơn và gọi các API tùy chỉnh hoặc cơ sở kiến thức để bổ sung thông tin cho các hành động đang chạy. Với Đại lý cho Amazon Bedrock, các nhà phát triển có thể tích hợp các đại lý thông minh vào ứng dụng của họ, đẩy nhanh quá trình phân phối các ứng dụng hỗ trợ AI và tiết kiệm hàng tuần thời gian phát triển. Với các đại lý, bạn có thể nâng cao nền tảng kiến thức của mình bằng cách thêm nhiều chức năng hơn như đề xuất từ Cá nhân hóa Amazon để đưa ra các đề xuất dành riêng cho người dùng hoặc thực hiện các hành động như lọc phim dựa trên nhu cầu của người dùng.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách xây dựng một chatbot phim đàm thoại bằng Amazon Bedrock trong một vài bước để trả lời trải nghiệm hội thoại và tìm kiếm ngữ nghĩa dựa trên dữ liệu của riêng bạn cũng như tập dữ liệu được cấp phép của IMDb và Box Office Mojo Movies/TV/OTT. Trong bài đăng tiếp theo, chúng ta sẽ thực hiện quy trình bổ sung thêm chức năng cho giải pháp của bạn bằng cách sử dụng Đại lý cho Amazon Bedrock. Để bắt đầu với cơ sở kiến thức trên Amazon Bedrock, hãy tham khảo Cơ sở kiến thức về Amazon Bedrock.
Về các tác giả
 Gaurav phát hành là Nhà khoa học dữ liệu cấp cao tại Trung tâm đổi mới AI sáng tạo, nơi ông làm việc với các khách hàng AWS thuộc các ngành dọc khác nhau để đẩy nhanh việc họ sử dụng các dịch vụ AI và Đám mây AWS sáng tạo nhằm giải quyết các thách thức kinh doanh của họ.
Gaurav phát hành là Nhà khoa học dữ liệu cấp cao tại Trung tâm đổi mới AI sáng tạo, nơi ông làm việc với các khách hàng AWS thuộc các ngành dọc khác nhau để đẩy nhanh việc họ sử dụng các dịch vụ AI và Đám mây AWS sáng tạo nhằm giải quyết các thách thức kinh doanh của họ.
 Divya Bhargavi là Trưởng nhóm khoa học ứng dụng cấp cao tại Trung tâm đổi mới AI sáng tạo, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng các phương pháp AI sáng tạo. Cô làm việc về hiểu và truy xuất hình ảnh/video, biểu đồ tri thức tăng cường các mô hình ngôn ngữ lớn và các trường hợp sử dụng quảng cáo được cá nhân hóa.
Divya Bhargavi là Trưởng nhóm khoa học ứng dụng cấp cao tại Trung tâm đổi mới AI sáng tạo, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng các phương pháp AI sáng tạo. Cô làm việc về hiểu và truy xuất hình ảnh/video, biểu đồ tri thức tăng cường các mô hình ngôn ngữ lớn và các trường hợp sử dụng quảng cáo được cá nhân hóa.
 Suren Gunturu là Nhà khoa học dữ liệu làm việc tại Trung tâm đổi mới AI sáng tạo, nơi anh làm việc với nhiều khách hàng AWS khác nhau để giải quyết các vấn đề kinh doanh có giá trị cao. Anh ấy chuyên xây dựng quy trình ML bằng Mô hình ngôn ngữ lớn, chủ yếu thông qua Amazon Bedrock và các dịch vụ Đám mây AWS khác.
Suren Gunturu là Nhà khoa học dữ liệu làm việc tại Trung tâm đổi mới AI sáng tạo, nơi anh làm việc với nhiều khách hàng AWS khác nhau để giải quyết các vấn đề kinh doanh có giá trị cao. Anh ấy chuyên xây dựng quy trình ML bằng Mô hình ngôn ngữ lớn, chủ yếu thông qua Amazon Bedrock và các dịch vụ Đám mây AWS khác.
 Vidya Sagar Ravipati là Giám đốc khoa học tại Trung tâm đổi mới AI sáng tạo, nơi ông tận dụng kinh nghiệm sâu rộng của mình về các hệ thống phân tán quy mô lớn và niềm đam mê học máy để giúp khách hàng AWS ở các ngành dọc khác nhau tăng tốc việc áp dụng AI và đám mây.
Vidya Sagar Ravipati là Giám đốc khoa học tại Trung tâm đổi mới AI sáng tạo, nơi ông tận dụng kinh nghiệm sâu rộng của mình về các hệ thống phân tán quy mô lớn và niềm đam mê học máy để giúp khách hàng AWS ở các ngành dọc khác nhau tăng tốc việc áp dụng AI và đám mây.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- : có
- :là
- :Ở đâu
- $ 10 triệu
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- Giới thiệu
- đẩy nhanh tiến độ
- tăng tốc
- truy cập
- chính xác
- ngang qua
- hành động
- diễn viên
- thêm
- thêm vào
- Nhận con nuôi
- Quảng cáo
- đại lý
- AI
- Hỗ trợ AI
- Tất cả
- cho phép
- cô đơn
- Đã
- Ngoài ra
- đàn bà gan dạ
- Amazon Web Services
- an
- và
- trả lời
- câu trả lời
- bất kì
- API
- các ứng dụng
- áp dụng
- ứng dụng
- LÀ
- AS
- xin
- At
- tăng
- tăng cường
- tự động hóa
- tự động
- AWS
- cơ sở
- dựa
- BE
- trước
- Tỷ
- Hộp
- phòng vé
- Nghỉ giải lao
- xây dựng
- Xây dựng
- kinh doanh
- by
- cuộc gọi
- gọi là
- CAN
- khả năng
- nắm bắt
- Chụp
- trường hợp
- trường hợp
- Danh mục hàng
- Trung tâm
- thách thức
- chatbot
- Chọn
- lựa chọn
- Giáng Sinh
- cổ điển
- đám mây
- áp dụng đám mây
- dịch vụ điện toán đám mây
- mã
- bộ sưu tập
- kết hợp
- thương gia
- công ty
- phức tạp
- An ủi
- chứa
- nội dung
- bối cảnh
- theo ngữ cảnh
- đàm thoại
- cuộc hội thoại
- sửa chữa
- nước
- Couple
- tạo
- tạo ra
- tín
- đội
- quan trọng
- khách hàng
- khách hàng
- Cam kết của khách hàng
- khách hàng
- tùy chỉnh
- dữ liệu
- Trao đổi dữ liệu
- nhà khoa học dữ liệu
- Ngày
- cung cấp
- giao hàng
- Mô tả
- chi tiết
- phát triển
- Phát triển
- khác nhau
- đạo diễn
- Giám đốc
- Giám đốc
- khám phá
- phát hiện
- phân phối
- hệ thống phân phối
- tài liệu
- tài liệu
- xuống
- lái xe
- loại bỏ
- nhúng
- cho phép
- Cuối cùng đến cuối
- Tham gia
- làm giàu
- đăng ký hạng mục thi
- Giải trí
- Ether (ETH)
- Mỗi
- ví dụ
- Sàn giao dịch
- kinh nghiệm
- Kinh nghiệm
- khám phá
- vài
- Tập tin
- Các tập tin
- lọc
- Tìm kiếm
- tìm kiếm
- theo
- tiếp theo
- Trong
- định dạng
- từ
- đầy đủ
- chức năng
- g1
- tạo ra
- thế hệ
- thế hệ
- Trí tuệ nhân tạo
- thể loại
- được
- Toàn cầu
- Go
- đồ thị
- lớn hơn
- Có
- he
- giúp đỡ
- cấp độ cao
- của mình
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- if
- thực hiện
- nâng cao
- in
- Bao gồm
- Tăng lên
- ngành công nghiệp
- Thông tin
- thông tin
- sự đổi mới
- hỏi thăm
- tích hợp
- Thông minh
- ý định
- trong
- liên quan đến
- IT
- jpg
- chỉ
- kiến thức
- Thiếu sót
- Ngôn ngữ
- lớn
- quy mô lớn
- dẫn
- hàng đầu
- học tập
- đòn bẩy
- Giấy phép
- Cấp phép
- Cấp phép
- Lượt thích
- tôi
- địa phương
- địa điểm thư viện nào
- thấp hơn
- máy
- học máy
- làm cho
- quản lý
- quản lý
- giám đốc
- nhiều
- me
- Phương tiện truyền thông
- Các thành viên
- Siêu dữ liệu
- phương pháp
- triệu
- ML
- kiểu mẫu
- mô hình
- mojo
- chi tiết
- phim
- Phim Điện Ảnh
- tên
- tên
- Điều hướng
- THÔNG TIN
- Cần
- nhu cầu
- Mới
- tiếp theo
- đêm
- of
- Office
- on
- ONE
- Cơ hội
- or
- tổ chức
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- kết thúc
- riêng
- gói
- trang
- thanh toán
- cửa sổ
- một phần
- niềm đam mê
- con đường
- mỗi
- biểu diễn
- Cá nhân
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- âm mưu
- Phổ biến
- Bài đăng
- poster
- chủ yếu
- vấn đề
- quá trình
- sản xuất
- Các nhà sản xuất
- độc quyền
- cung cấp
- truy vấn
- truy vấn
- Câu hỏi
- giẻ lau
- phạm vi
- Giá
- giá
- xếp hạng
- sẵn sàng
- giới thiệu
- Khuyến nghị
- khuyến nghị
- ghi
- xem
- liên quan
- có liên quan
- Báo cáo
- đòi hỏi
- phản ứng
- phản ứng
- Kết quả
- giữ
- thu hồi
- trở lại
- Vai trò
- HÀNG
- chạy
- sự hài lòng
- tiết kiệm
- Khoa học
- Nhà khoa học
- Tìm kiếm
- Phần
- an toàn
- phân đoạn
- chọn
- ngữ nghĩa
- ngữ nghĩa
- cao cấp
- Không có máy chủ
- dịch vụ
- DỊCH VỤ
- thiết lập
- chị ấy
- bắn
- hiển thị
- giới thiệu
- cho thấy
- Đơn giản
- mô phỏng
- duy nhất
- Kích thước máy
- nhỏ hơn
- So
- giải pháp
- động SOLVE
- Giải quyết
- một số
- nguồn
- nguồn
- chuyên
- riêng
- bắt đầu
- Các bước
- là gắn
- hàng
- lưu trữ
- đơn giản
- đăng ký
- như vậy
- bổ sung
- đồng bộ hóa.
- hệ thống
- Hãy
- nhiệm vụ
- kỹ thuật
- thử nghiệm
- văn bản
- hơn
- việc này
- Sản phẩm
- thông tin
- cung cấp their dịch
- Them
- Theo chủ đề
- sau đó
- Đó
- Kia là
- họ
- điều này
- Thông qua
- thời gian
- titan
- trò chơi
- đến
- tv
- sự hiểu biết
- hiểu
- không có cấu trúc
- up-to-date
- tải lên
- URI
- URL
- sử dụng
- đã sử dụng
- người sử dang
- Người sử dụng
- sử dụng
- khác nhau
- Lớn
- ngành dọc
- Truy cập
- W
- đi bộ
- muốn
- là
- we
- web
- các dịch vụ web
- tuần
- rộng
- Phạm vi rộng
- sẽ
- với
- quy trình làm việc
- đang làm việc
- công trinh
- viết
- X
- năm
- bạn
- trên màn hình
- zephyrnet