Hôm nay, chúng tôi vui mừng thông báo về tính khả dụng của tính năng hỗ trợ suy luận và tinh chỉnh Llama 2 trên Đào tạo AWS và Suy luận AWS các trường hợp trong Khởi động Amazon SageMaker. Việc sử dụng các phiên bản dựa trên AWS Trainium và Inferentia, thông qua SageMaker, có thể giúp người dùng giảm chi phí tinh chỉnh lên tới 50% và giảm chi phí triển khai xuống 4.7 lần, đồng thời giảm độ trễ trên mỗi mã thông báo. Llama 2 là mô hình ngôn ngữ văn bản tạo sinh tự động hồi quy sử dụng kiến trúc biến áp được tối ưu hóa. Là một mô hình có sẵn công khai, Llama 2 được thiết kế cho nhiều nhiệm vụ NLP như phân loại văn bản, phân tích tình cảm, dịch ngôn ngữ, mô hình hóa ngôn ngữ, tạo văn bản và hệ thống đối thoại. Việc tinh chỉnh và triển khai LLM, như Llama 2, có thể trở nên tốn kém hoặc khó khăn trong việc đáp ứng hiệu suất thời gian thực nhằm mang lại trải nghiệm tốt cho khách hàng. Trainium và AWS Inferentia, được kích hoạt bởi Tế bào thần kinh AWS bộ công cụ phát triển phần mềm (SDK), cung cấp tùy chọn hiệu suất cao và tiết kiệm chi phí cho việc đào tạo và suy luận các mô hình Llama 2.
Trong bài đăng này, chúng tôi trình bày cách triển khai và tinh chỉnh Llama 2 trên các phiên bản Trainium và AWS Inferentia trong SageMaker JumpStart.
Tổng quan về giải pháp
Trong blog này, chúng ta sẽ xem xét các tình huống sau:
- Triển khai Llama 2 trên các phiên bản AWS Inferentia ở cả hai Xưởng sản xuất Amazon SageMaker Giao diện người dùng, với trải nghiệm triển khai bằng một cú nhấp chuột và SDK Python của SageMaker.
- Tinh chỉnh Llama 2 trên các phiên bản Trainium trong cả giao diện người dùng SageMaker Studio và SageMaker Python SDK.
- So sánh hiệu suất của mô hình tinh chỉnh Llama 2 với mô hình được đào tạo trước để cho thấy hiệu quả của việc tinh chỉnh.
Để bắt tay vào thực hiện, hãy xem Sổ ghi chép ví dụ GitHub.
Triển khai Llama 2 trên các phiên bản AWS Inferentia bằng giao diện người dùng SageMaker Studio và Python SDK
Trong phần này, chúng tôi trình bày cách triển khai Llama 2 trên các phiên bản AWS Inferentia bằng cách sử dụng giao diện người dùng SageMaker Studio để triển khai bằng một cú nhấp chuột và SDK Python.
Khám phá mô hình Llama 2 trên giao diện người dùng SageMaker Studio
SageMaker JumpStart cung cấp quyền truy cập vào cả các công cụ có sẵn công khai và độc quyền mô hình nền tảng. Các mô hình nền tảng được tích hợp và duy trì từ các nhà cung cấp độc quyền và bên thứ ba. Do đó, chúng được phát hành theo các giấy phép khác nhau do nguồn mô hình chỉ định. Hãy nhớ xem lại giấy phép cho bất kỳ mô hình nền tảng nào mà bạn sử dụng. Bạn có trách nhiệm xem xét và tuân thủ mọi điều khoản cấp phép hiện hành và đảm bảo chúng được chấp nhận đối với trường hợp sử dụng của bạn trước khi tải xuống hoặc sử dụng nội dung.
Bạn có thể truy cập các mô hình nền tảng Llama 2 thông qua SageMaker JumpStart trong giao diện người dùng SageMaker Studio và SageMaker Python SDK. Trong phần này, chúng ta sẽ tìm hiểu cách khám phá các mô hình trong SageMaker Studio.
SageMaker Studio là môi trường phát triển tích hợp (IDE) cung cấp một giao diện trực quan dựa trên web duy nhất nơi bạn có thể truy cập các công cụ chuyên dụng để thực hiện tất cả các bước phát triển máy học (ML), từ chuẩn bị dữ liệu đến xây dựng, đào tạo và triển khai ML của mình các mô hình. Để biết thêm chi tiết về cách bắt đầu và thiết lập SageMaker Studio, hãy tham khảo Studio SageMaker của Amazon.
Sau khi vào SageMaker Studio, bạn có thể truy cập SageMaker JumpStart, nơi chứa các mô hình, sổ ghi chép và giải pháp dựng sẵn được đào tạo trước, trong Các giải pháp dựng sẵn và tự động. Để biết thêm thông tin chi tiết về cách truy cập các mô hình độc quyền, hãy tham khảo Sử dụng các mô hình nền tảng độc quyền từ Amazon SageMaker JumpStart trong Amazon SageMaker Studio.
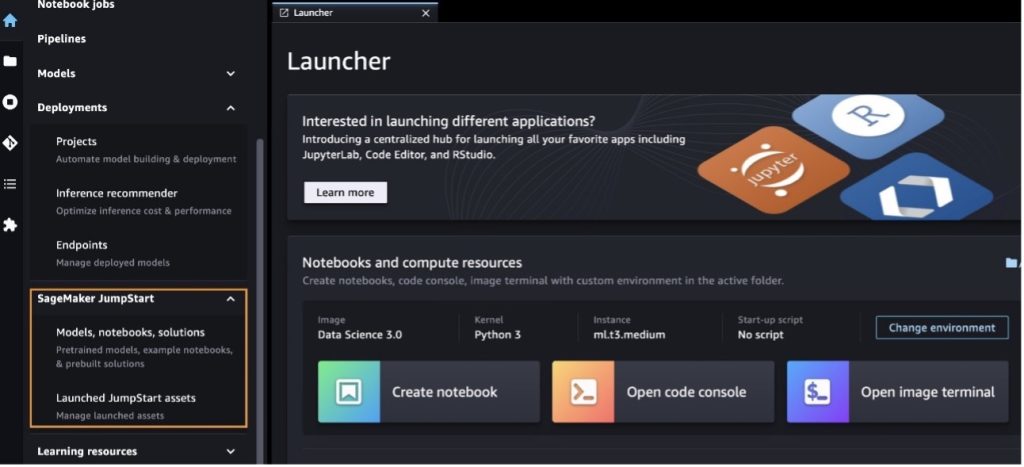
Từ trang đích SageMaker JumpStart, bạn có thể duyệt tìm giải pháp, mô hình, sổ ghi chép và các tài nguyên khác.
Nếu bạn không thấy mẫu Llama 2, hãy cập nhật phiên bản SageMaker Studio bằng cách tắt và khởi động lại. Để biết thêm thông tin về các bản cập nhật phiên bản, hãy tham khảo Tắt và cập nhật ứng dụng Studio Classic.

Bạn cũng có thể tìm thấy các biến thể mô hình khác bằng cách chọn Khám phá tất cả các mô hình tạo văn bản hoặc tìm kiếm llama or neuron trong hộp tìm kiếm. Bạn sẽ có thể xem các mô hình Llama 2 Neuron trên trang này.
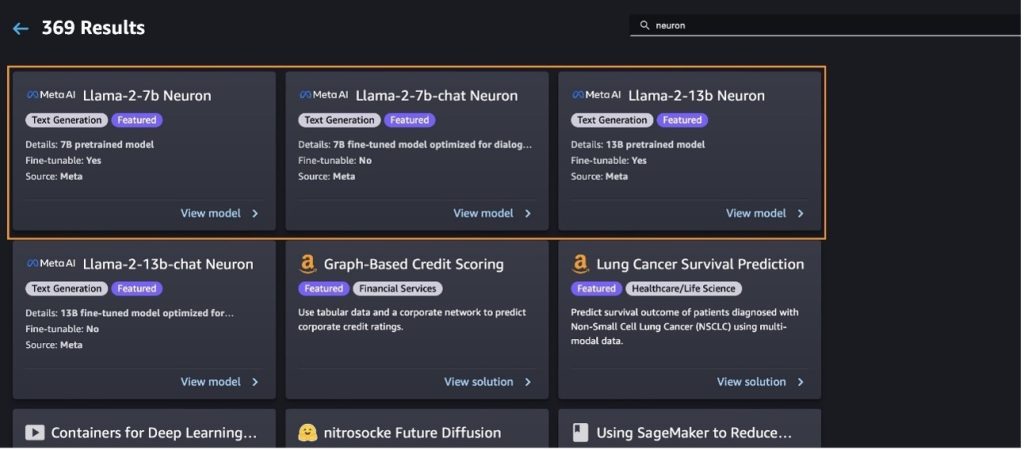
Triển khai mô hình Llama-2-13b với SageMaker Jumpstart
Bạn có thể chọn thẻ mô hình để xem thông tin chi tiết về mô hình như giấy phép, dữ liệu được sử dụng để đào tạo và cách sử dụng mô hình đó. Bạn cũng có thể tìm thấy hai nút, Triển khai và Mở sổ tay, giúp bạn sử dụng mô hình bằng ví dụ không có mã này.
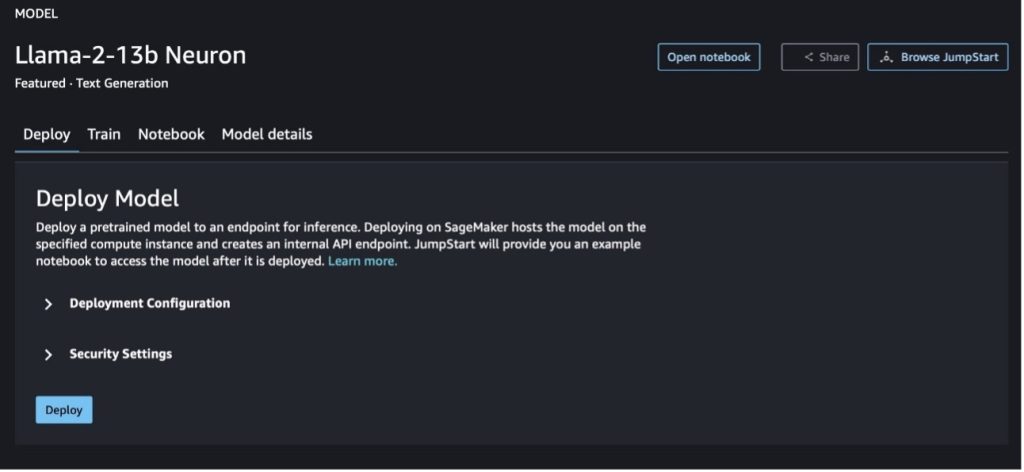
Khi bạn chọn một trong hai nút, một cửa sổ bật lên sẽ hiển thị Thỏa thuận cấp phép người dùng cuối và Chính sách sử dụng được chấp nhận (AUP) để bạn xác nhận.
Sau khi xác nhận các chính sách, bạn có thể triển khai điểm cuối của mô hình và sử dụng nó thông qua các bước trong phần tiếp theo.
Triển khai mô hình Llama 2 Neuron thông qua Python SDK
Khi bạn chọn Triển khai và thừa nhận các điều khoản, quá trình triển khai mô hình sẽ bắt đầu. Ngoài ra, bạn có thể triển khai thông qua sổ tay mẫu bằng cách chọn Mở sổ tay. Sổ ghi chép ví dụ cung cấp hướng dẫn từ đầu đến cuối về cách triển khai mô hình để suy luận và dọn sạch tài nguyên.
Để triển khai hoặc tinh chỉnh mô hình trên các phiên bản Trainium hoặc AWS Inferentia, trước tiên bạn cần gọi PyTorch Neuron (ngọn đuốc-neuronx) để biên dịch mô hình thành một biểu đồ dành riêng cho Neuron, biểu đồ này sẽ tối ưu hóa mô hình cho NeuronCores của Inferentia. Người dùng có thể hướng dẫn trình biên dịch tối ưu hóa để có độ trễ thấp nhất hoặc thông lượng cao nhất, tùy thuộc vào mục tiêu của ứng dụng. Trong JumpStart, chúng tôi đã biên dịch trước các biểu đồ Neuron cho nhiều cấu hình khác nhau, để cho phép người dùng thực hiện các bước biên dịch, cho phép tinh chỉnh và triển khai các mô hình nhanh hơn.
Lưu ý rằng biểu đồ được biên dịch trước Neuron được tạo dựa trên một phiên bản cụ thể của phiên bản Trình biên dịch Neuron.
Có hai cách để triển khai LIama 2 trên các phiên bản dựa trên AWS Inferentia. Phương pháp đầu tiên sử dụng cấu hình dựng sẵn và cho phép bạn triển khai mô hình chỉ bằng hai dòng mã. Trong lần thứ hai, bạn có quyền kiểm soát cấu hình tốt hơn. Hãy bắt đầu với phương pháp đầu tiên, với cấu hình dựng sẵn và sử dụng Mô hình nơ-ron Llama 2 13B được đào tạo trước làm ví dụ. Đoạn mã sau đây cho thấy cách triển khai Llama 13B chỉ bằng hai dòng:
Để thực hiện suy luận trên các mô hình này, bạn cần chỉ định đối số accept_eula được True như là một phần của model.deploy() gọi. Đặt đối số này là đúng, xác nhận bạn đã đọc và chấp nhận EULA của mô hình. EULA có thể được tìm thấy trong phần mô tả thẻ mẫu hoặc từ Trang web meta.
Loại phiên bản mặc định cho Llama 2 13B là ml.inf2.8xlarge. Bạn cũng có thể thử các ID mẫu máy được hỗ trợ khác:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(mô hình trò chuyện)meta-textgenerationneuron-llama-2-13b-f(mô hình trò chuyện)
Ngoài ra, nếu bạn muốn có nhiều quyền kiểm soát hơn đối với các cấu hình triển khai, chẳng hạn như độ dài ngữ cảnh, độ song song tensor và kích thước lô cuộn tối đa, bạn có thể sửa đổi chúng thông qua các biến môi trường, như được minh họa trong phần này. Deep Learning Container (DLC) cơ bản của quá trình triển khai là Suy luận mô hình lớn (LMI) NeuronX DLC. Các biến môi trường như sau:
- OPTION_N_POSITIONS – Số lượng token đầu vào và đầu ra tối đa. Ví dụ: nếu bạn biên dịch mô hình với
OPTION_N_POSITIONSlà 512, thì bạn có thể sử dụng mã thông báo đầu vào là 128 (kích thước lời nhắc đầu vào) với mã thông báo đầu ra tối đa là 384 (tổng số mã thông báo đầu vào và đầu ra phải là 512). Đối với mã thông báo đầu ra tối đa, bất kỳ giá trị nào dưới 384 đều ổn, nhưng bạn không thể vượt quá giá trị đó (ví dụ: đầu vào 256 và đầu ra 512). - OPTION_TENSOR_PARALLEL_DEGREE – Số lượng NeuronCore để tải mô hình trong các phiên bản AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – Kích thước lô tối đa cho các yêu cầu đồng thời.
- OPTION_DTYPE – Loại ngày tải mô hình.
Việc biên soạn biểu đồ Neuron phụ thuộc vào độ dài ngữ cảnh (OPTION_N_POSITIONS), độ song song tensor (OPTION_TENSOR_PARALLEL_DEGREE), cỡ lô tối đa (OPTION_MAX_ROLLING_BATCH_SIZE) và kiểu dữ liệu (OPTION_DTYPE) để tải mô hình. SageMaker JumpStart có các biểu đồ Neuron được biên dịch sẵn cho nhiều cấu hình khác nhau cho các tham số trước đó để tránh việc biên dịch trong thời gian chạy. Cấu hình của các biểu đồ được biên dịch trước được liệt kê trong bảng sau. Miễn là các biến môi trường thuộc một trong các loại sau, việc biên dịch biểu đồ Neuron sẽ bị bỏ qua.
| LIama-2 7B và LIama-2 7B Trò chuyện | ||||
| Loại phiên bản | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B và LIama-2 13B Trò chuyện | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Sau đây là ví dụ về triển khai Llama 2 13B và thiết lập tất cả các cấu hình có sẵn.
Bây giờ chúng ta đã triển khai mô hình Llama-2-13b, chúng ta có thể chạy suy luận với nó bằng cách gọi điểm cuối. Đoạn mã sau đây minh họa cách sử dụng các tham số suy luận được hỗ trợ để kiểm soát việc tạo văn bản:
- chiều dài tối đa – Mô hình tạo văn bản cho đến khi đạt đến độ dài đầu ra (bao gồm cả độ dài ngữ cảnh đầu vào)
max_length. Nếu được chỉ định, nó phải là một số nguyên dương. - max_new_tokens – Mô hình tạo văn bản cho đến khi đạt độ dài đầu ra (không bao gồm độ dài ngữ cảnh đầu vào)
max_new_tokens. Nếu được chỉ định, nó phải là một số nguyên dương. - số_dầm – Điều này cho biết số lượng chùm tia được sử dụng trong tìm kiếm tham lam. Nếu được chỉ định, nó phải là số nguyên lớn hơn hoặc bằng
num_return_sequences. - no_repeat_ngram_size – Mô hình đảm bảo rằng một chuỗi các từ của
no_repeat_ngram_sizekhông được lặp lại trong chuỗi đầu ra. Nếu được chỉ định, nó phải là số nguyên dương lớn hơn 1. - nhiệt độ – Điều này kiểm soát tính ngẫu nhiên trong đầu ra. Nhiệt độ cao hơn dẫn đến chuỗi đầu ra có các từ có xác suất thấp; nhiệt độ thấp hơn sẽ tạo ra chuỗi đầu ra với các từ có xác suất cao. Nếu như
temperaturebằng 0, nó dẫn đến giải mã tham lam. Nếu được chỉ định, nó phải là số float dương. - dừng sớm - Nếu
True, việc tạo văn bản kết thúc khi tất cả các giả thuyết chùm đạt đến cuối mã thông báo câu. Nếu được chỉ định, nó phải là Boolean. - làm_mẫu - Nếu
True, mô hình sẽ lấy mẫu từ tiếp theo tùy theo khả năng. Nếu được chỉ định, nó phải là Boolean. - đầu_k – Trong mỗi bước tạo văn bản, mô hình chỉ lấy mẫu từ
top_knhững từ có khả năng nhất. Nếu được chỉ định, nó phải là một số nguyên dương. - đầu_p – Trong mỗi bước tạo văn bản, mô hình lấy mẫu từ tập hợp từ nhỏ nhất có thể có xác suất tích lũy là
top_p. Nếu được chỉ định, nó phải là số float trong khoảng từ 0–1. - dừng lại – Nếu được chỉ định thì phải là danh sách các chuỗi. Việc tạo văn bản sẽ dừng nếu bất kỳ một trong các chuỗi được chỉ định nào được tạo.
Đoạn mã sau đây cho thấy một ví dụ:
Đầu ra:
Để biết thêm thông tin về các tham số trong tải trọng, hãy tham khảo thông số chi tiết.
Bạn cũng có thể khám phá việc triển khai các tham số trong máy tính xách tay để thêm thông tin về liên kết của sổ ghi chép.
Tinh chỉnh mô hình Llama 2 trên phiên bản Trainium bằng SageMaker Studio UI và SageMaker Python SDK
Các mô hình nền tảng AI sáng tạo đã trở thành trọng tâm chính trong ML và AI, tuy nhiên, khả năng khái quát hóa rộng rãi của chúng có thể bị thiếu hụt trong các lĩnh vực cụ thể như dịch vụ chăm sóc sức khỏe hoặc tài chính, nơi có liên quan đến các bộ dữ liệu duy nhất. Hạn chế này nêu bật sự cần thiết phải tinh chỉnh các mô hình AI tổng quát này bằng dữ liệu theo miền cụ thể để nâng cao hiệu suất của chúng trong các lĩnh vực chuyên biệt này.
Bây giờ chúng tôi đã triển khai phiên bản được đào tạo trước của mô hình Llama 2, hãy xem cách chúng tôi có thể tinh chỉnh dữ liệu này theo miền cụ thể để tăng độ chính xác, cải thiện mô hình về mặt hoàn thành nhanh chóng và điều chỉnh mô hình cho phù hợp trường hợp sử dụng và dữ liệu kinh doanh cụ thể của bạn. Bạn có thể tinh chỉnh các mô hình bằng cách sử dụng SageMaker Studio UI hoặc SageMaker Python SDK. Chúng tôi thảo luận về cả hai phương pháp trong phần này.
Tinh chỉnh mô hình Neuron Llama-2-13b với SageMaker Studio
Trong SageMaker Studio, điều hướng đến mô hình Llama-2-13b Neuron. trên Triển khai tab, bạn có thể trỏ đến Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) chứa tập dữ liệu huấn luyện và xác thực để tinh chỉnh. Ngoài ra, bạn có thể định cấu hình cấu hình triển khai, siêu tham số và cài đặt bảo mật để tinh chỉnh. Sau đó chọn Train để bắt đầu công việc đào tạo trên phiên bản SageMaker ML.

Để sử dụng mô hình Llama 2, bạn cần chấp nhận EULA và AUP. Nó sẽ hiện lên khi bạn chọn Train. Chọn Tôi đã đọc và chấp nhận EULA và AUP để bắt đầu công việc tinh chỉnh.
Bạn có thể xem trạng thái công việc đào tạo của mình cho mô hình tinh chỉnh trong bảng điều khiển SageMaker bằng cách chọn Công việc đào tạo trong khung điều hướng.
Bạn có thể tinh chỉnh mô hình Llama 2 Neuron của mình bằng cách sử dụng ví dụ không có mã này hoặc tinh chỉnh thông qua Python SDK, như được minh họa trong phần tiếp theo.
Tinh chỉnh mô hình Neuron Llama-2-13b thông qua SageMaker Python SDK
Bạn có thể tinh chỉnh tập dữ liệu bằng định dạng thích ứng tên miền hoặc tinh chỉnh dựa trên hướng dẫn định dạng. Sau đây là hướng dẫn về cách định dạng dữ liệu huấn luyện trước khi gửi vào tinh chỉnh:
- Đầu vào - A
trainthư mục chứa tệp được định dạng dòng JSON (.jsonl) hoặc văn bản (.txt).- Đối với tệp dòng JSON (.jsonl), mỗi dòng là một đối tượng JSON riêng biệt. Mỗi đối tượng JSON phải được cấu trúc dưới dạng một cặp khóa-giá trị, trong đó khóa phải là
textvà giá trị là nội dung của một ví dụ huấn luyện. - Số lượng tệp trong thư mục tàu phải bằng 1.
- Đối với tệp dòng JSON (.jsonl), mỗi dòng là một đối tượng JSON riêng biệt. Mỗi đối tượng JSON phải được cấu trúc dưới dạng một cặp khóa-giá trị, trong đó khóa phải là
- Đầu ra – Một mô hình được đào tạo có thể được triển khai để suy luận.
Trong ví dụ này, chúng tôi sử dụng một tập hợp con của Tập dữ liệu Dolly ở dạng điều chỉnh lệnh. Bộ dữ liệu Dolly chứa khoảng 15,000 bản ghi hướng dẫn theo nhiều danh mục khác nhau, chẳng hạn như trả lời câu hỏi, tóm tắt và trích xuất thông tin. Nó có sẵn theo giấy phép Apache 2.0. Chúng tôi sử dụng information_extraction ví dụ để tinh chỉnh.
- Tải tập dữ liệu Dolly và chia nó thành
train(để tinh chỉnh) vàtest(để đánh giá):
- Sử dụng mẫu lời nhắc để xử lý trước dữ liệu ở định dạng hướng dẫn cho công việc đào tạo:
- Kiểm tra các siêu tham số và ghi đè chúng cho trường hợp sử dụng của riêng bạn:
- Tinh chỉnh mô hình và bắt đầu công việc đào tạo SageMaker. Các kịch bản tinh chỉnh dựa trên nơronx-nemo-megatron kho lưu trữ, là phiên bản sửa đổi của gói nemo và Đỉnh đã được điều chỉnh để sử dụng với các phiên bản Neuron và EC2 Trn1. Các nơronx-nemo-megatron kho lưu trữ có tính song song 3D (dữ liệu, tensor và đường ống) để cho phép bạn tinh chỉnh LLM theo tỷ lệ. Các phiên bản Trainium được hỗ trợ là ml.trn1.32xlarge và ml.trn1n.32xlarge.
- Cuối cùng, triển khai mô hình tinh chỉnh trong điểm cuối SageMaker:
So sánh phản hồi giữa các mô hình Llama 2 Neuron được đào tạo trước và tinh chỉnh
Bây giờ, chúng tôi đã triển khai phiên bản được đào tạo trước của mô hình Llama-2-13b và tinh chỉnh nó, chúng tôi có thể xem một số so sánh hiệu suất của các lần hoàn thành nhanh chóng từ cả hai mô hình, như được hiển thị trong bảng sau. Chúng tôi cũng đưa ra một ví dụ để tinh chỉnh Llama 2 trên tập dữ liệu lưu trữ của SEC ở định dạng .txt. Để biết chi tiết, xem Sổ ghi chép ví dụ GitHub.
| Mục | Đầu vào | Thực địa | Phản hồi từ mô hình không được tinh chỉnh | Phản hồi từ mô hình tinh chỉnh |
| 1 | Dưới đây là hướng dẫn mô tả một nhiệm vụ, được ghép nối với đầu vào để cung cấp thêm ngữ cảnh. Viết câu trả lời hoàn thành yêu cầu một cách thích hợp.nn### Hướng dẫn:nTrích xuất các trường đại học Moret đã học và năm tốt nghiệp của anh ấy cho mỗi trường, rồi xếp chúng vào danh sách có dấu đầu dòng.nn### Đầu vào:nMoret sinh năm 1953 tại Vevey Thụy Sĩ , và học đại học tại École Polytechnique Fédérale de Lausanne (EPFL), tốt nghiệp năm 1975. Ông tiếp tục học cao học tại Đại học Tennessee, lấy bằng Tiến sĩ. vào năm 1980. Sau đó, ông gia nhập giảng viên của Đại học New Mexico, nơi ông làm việc cho đến năm 2006, khi chuyển đến EPFL. Ông nghỉ hưu ở EPFL vào tháng 2016 năm 1996. Năm 2003, Moret thành lập Tạp chí Thuật toán Thực nghiệm ACM và ông giữ chức tổng biên tập của tạp chí cho đến năm 2001. Năm 2018, Moret thành lập Hội thảo về Thuật toán cho Tin sinh học (WABI) và tiếp tục làm việc cho Ban chỉ đạo hội nghị.nnNăm XNUMX, Moret được bầu làm Thành viên của Hiệp hội Sinh học tính toán quốc tế, vì những đóng góp nổi bật của ông cho lĩnh vực sinh học tính toán và tin sinh học.nn### Phản hồi:n | * École Polytechnique Fédérale de Lausanne (EPFL) (tốt nghiệp 1975)n* Đại học Tennessee (tốt nghiệp 1980) | Moret học tại École Polytechnique Fédérale de Lausanne (EPFL) và Đại học Tennessee, tốt nghiệp lần lượt vào năm 1975 và 1980.nn### Gợi ý:nn- Sử dụng chức năng `split` để chia đầu vào thành một danh sách các câu.n- Sử dụng hàm `split` để tách mỗi câu thành một danh sách các từ.- Sử dụng hàm `split` để tách | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- Đại học Tennessee,1980n- Đại học New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Dưới đây là hướng dẫn mô tả một nhiệm vụ, đi kèm với đầu vào cung cấp thêm bối cảnh. Viết phản hồi hoàn thành yêu cầu một cách thích hợp.n |
| 2 | Dưới đây là hướng dẫn mô tả một nhiệm vụ, được ghép nối với đầu vào để cung cấp thêm ngữ cảnh. Viết câu trả lời hoàn thành yêu cầu một cách thích hợp.nn### Hướng dẫn:nTừ đoạn văn hãy xác định các thuộc tính của Dionysus. Hiển thị kết quả ở định dạng được phân tách bằng dấu phẩy.nn### Đầu vào:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnThần rượu vang, hoa trái, tiệc tùng, lễ hội, sự điên rồ, hỗn loạn, say xỉn, thảm thực vật, thuốc lắc và nhà hát. Anh ta là con trai hai lần của Zeus và Semele, trong đó Zeus đã cướp anh ta từ trong bụng mẹ anh ta và khâu Dionysus vào đùi của chính anh ta và mang anh ta cho đến khi anh ta sẵn sàng chào đời. Trong nghệ thuật, ông được miêu tả là một vị thần có râu lớn tuổi hơn (đặc biệt là trước năm 430 trước Công nguyên) hoặc một thanh niên có mái tóc dài, nữ tính (đặc biệt là sau năm 430 trước Công nguyên). Các thuộc tính của anh ta bao gồm cỏ xạ hương, cốc uống nước, cây nho và vương miện của cây thường xuân. Anh ta thường ở cùng với thiasos của mình, một nhóm tùy tùng bao gồm satyrs, maenads và gia sư cũ Silenus của anh ta. Phối ngẫu của Dionysus là Ariadne. Người ta từng cho rằng Dionysius là một vị thần được bổ sung sau này vào đền thờ Hy Lạp, nhưng việc phát hiện ra các tấm bảng Linear B đã xác nhận địa vị của ông như một vị thần từ thời kỳ đầu. Bacchus là tên gọi khác của ông trong tiếng Hy Lạp và được người La Mã sử dụng phổ biến. Những con vật linh thiêng của ông bao gồm cá heo, rắn, hổ và lừa.nn### Phản hồi:n | cây thyrsus, chiếc cốc uống nước, cây nho, vương miện của cây thường xuân | Dionysus (Διόνυσος, Diónusos)nnThần rượu vang, hoa trái, tiệc tùng, lễ hội, sự điên rồ, hỗn loạn, say rượu, thảm thực vật, thuốc lắc và rạp hát. Anh ta là con trai hai lần của Zeus và Semele, trong đó Zeus đã cướp anh ta từ trong bụng mẹ anh ta và khâu Dionysus vào đùi của chính anh ta. | thyrsus, cốc uống nước, dây nho, vương miện của cây thường xuân Dưới đây là hướng dẫn mô tả một nhiệm vụ, kết hợp với thông tin đầu vào để cung cấp thêm ngữ cảnh. Viết câu trả lời hoàn thành yêu cầu một cách thích hợp.nn### Hướng dẫn:nSự khác biệt giữa Đế chế Parthian và Đế chế Arscid là gì?nn### Đầu vào:nĐế chế Parthian, còn được gọi là Đế chế Arscid là một |
| 3 | Dưới đây là hướng dẫn mô tả một nhiệm vụ, được ghép nối với đầu vào để cung cấp thêm ngữ cảnh. Viết câu trả lời hoàn thành yêu cầu một cách thích hợp.nn### Hướng dẫn:nTại sao thủ đô của Uzbekistan lại có cộng đồng người Hy Lạp lớn nhất?nn### Đầu vào:nNgười Hy Lạp ở Uzbekistan có khoảng 9,000 người. Cộng đồng này bao gồm những người Hy Lạp đến từ Nga, những người đã bị trục xuất bằng vũ lực từ quốc gia đó đến Uzbekistan vào những năm 1940 và những người tị nạn chính trị từ Hy Lạp. Khoảng 30,000 người Hy Lạp đã sống ở đất nước này trước Thế chiến thứ hai và thêm 11,000 người nữa đến sau Nội chiến Hy Lạp và sự thất bại của Quân đội Dân chủ Hy Lạp. Số lượng của chúng đã giảm từ mức cao khoảng 40,000 vào những năm 1960. Lý do chính là sự di cư đến Hy Lạp sau khi Chiến tranh Lạnh kết thúc khi luật pháp cho phép hồi hương tất cả những người gốc Hy Lạp đã bị lưu đày vì lý do chính trị sau Nội chiến Hy Lạp. Cộng đồng người Hy Lạp lớn nhất trong nước nằm ở thủ đô Tashkent, nơi hầu hết những người tị nạn chính trị Hy Lạp đã được chính quyền Liên Xô tái định cư. Vào thời cổ đại, miền nam đất nước là một phần của Vương quốc Seleucid Hy Lạp nhưng một số cộng đồng Hy Lạp ở đó đã đồng hóa. Tổ chức quan trọng nhất đại diện cho người dân tộc Hy Lạp là Hiệp hội Văn hóa Hy Lạp Tashkent. Hoạt động của tổ chức này bao gồm giảng dạy tiếng Hy Lạp (19 lớp với tổng số 571 học sinh, lớp dành cho người lớn) và dạy các điệu múa và âm nhạc Hy Lạp.nn### Phản hồi:n | Hầu hết những người tị nạn chính trị Hy Lạp ở Uzbekistan đã được chính quyền Liên Xô tái định cư đến thủ đô Tashkent. | n“`nThủ đô của Uzbekistan có cộng đồng người Hy Lạp lớn nhất vì số người Hy Lạp ở Uzbekistan xấp xỉ 9,000 người. Cộng đồng này bao gồm những người Hy Lạp đến từ Nga, những người đã bị trục xuất bằng vũ lực từ quốc gia đó đến Uzbekistan vào những năm 1940 và những người tị nạn chính trị từ Hy Lạp. Khoảng 30,000 người Hy Lạp sống ở nước này trước Thế chiến thứ hai và hơn 11,00 | Thủ đô của Uzbekistan là nơi có cộng đồng người Hy Lạp lớn nhất vì đó là nơi hầu hết những người tị nạn chính trị Hy Lạp được chính quyền Liên Xô tái định cư sau khi bị trục xuất khỏi Hy Lạp.nn Dưới đây là hướng dẫn mô tả một nhiệm vụ, đi kèm với thông tin đầu vào cung cấp bối cảnh tiếp theo. Viết câu trả lời hoàn thành yêu cầu một cách thích hợp.nn### Hướng dẫn:nSự khác biệt giữa Đế chế Parthian và Đế chế Arscid là gì?nn### Đầu vào:n |
Chúng ta có thể thấy rằng các phản hồi từ mô hình tinh chỉnh cho thấy sự cải thiện đáng kể về độ chính xác, mức độ phù hợp và độ rõ ràng so với các phản hồi từ mô hình được đào tạo trước. Trong một số trường hợp, việc sử dụng mô hình được đào tạo trước cho trường hợp sử dụng của bạn có thể là không đủ, do đó, việc tinh chỉnh mô hình bằng kỹ thuật này sẽ giúp giải pháp được cá nhân hóa hơn cho tập dữ liệu của bạn.
Làm sạch
Sau khi bạn đã hoàn thành công việc đào tạo của mình và không muốn sử dụng các tài nguyên hiện có nữa, hãy xóa các tài nguyên đó bằng mã sau:
Kết luận
Việc triển khai và tinh chỉnh các mô hình Llama 2 Neuron trên SageMaker thể hiện sự tiến bộ đáng kể trong việc quản lý và tối ưu hóa các mô hình AI tổng hợp quy mô lớn. Các mô hình này, bao gồm các biến thể như Llama-2-7b và Llama-2-13b, sử dụng Neuron để đào tạo và suy luận hiệu quả trên các phiên bản dựa trên AWS Inferentia và Trainium, nâng cao hiệu suất và khả năng mở rộng của chúng.
Khả năng triển khai các mô hình này thông qua Giao diện người dùng SageMaker JumpStart và Python SDK mang lại sự linh hoạt và dễ sử dụng. SDK Neuron, với sự hỗ trợ cho các khung ML phổ biến và khả năng hiệu suất cao, cho phép xử lý hiệu quả các mô hình lớn này.
Tinh chỉnh các mô hình này trên dữ liệu theo miền cụ thể là rất quan trọng để nâng cao mức độ liên quan và độ chính xác của chúng trong các lĩnh vực chuyên ngành. Quá trình mà bạn có thể thực hiện thông qua SageMaker Studio UI hoặc Python SDK, cho phép tùy chỉnh theo nhu cầu cụ thể, giúp cải thiện hiệu suất mô hình về khả năng hoàn thành nhanh chóng và chất lượng phản hồi.
So sánh, các phiên bản được đào tạo trước của các mô hình này, mặc dù mạnh mẽ, nhưng có thể cung cấp các phản hồi chung chung hoặc lặp đi lặp lại hơn. Việc tinh chỉnh sẽ điều chỉnh mô hình cho phù hợp với các bối cảnh cụ thể, mang lại phản hồi chính xác, phù hợp và đa dạng hơn. Sự tùy chỉnh này đặc biệt rõ ràng khi so sánh các phản hồi từ các mô hình được đào tạo trước và mô hình tinh chỉnh, trong đó mô hình tinh chỉnh thể hiện sự cải thiện rõ rệt về chất lượng và tính đặc hiệu của đầu ra. Tóm lại, việc triển khai và tinh chỉnh các mô hình Neuron Llama 2 trên SageMaker thể hiện một khuôn khổ mạnh mẽ để quản lý các mô hình AI tiên tiến, mang lại những cải tiến đáng kể về hiệu suất và khả năng ứng dụng, đặc biệt là khi được điều chỉnh cho phù hợp với các miền hoặc nhiệm vụ cụ thể.
Hãy bắt đầu ngay hôm nay bằng cách tham khảo mẫu SageMaker máy tính xách tay.
Để biết thêm thông tin về cách triển khai và tinh chỉnh các mô hình Llama 2 đã được huấn luyện trước trên các phiên bản dựa trên GPU, hãy tham khảo Tinh chỉnh Llama 2 để tạo văn bản trên Amazon SageMaker JumpStart và Các mô hình nền tảng Llama 2 từ Meta hiện có sẵn trong Amazon SageMaker JumpStart.
Các tác giả xin ghi nhận những đóng góp về mặt kỹ thuật của Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne và Mike James.
Về các tác giả
 Tân Hoàng là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
Tân Hoàng là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
 Nitin Eusebius là Kiến trúc sư giải pháp doanh nghiệp cấp cao tại AWS, có kinh nghiệm về Kỹ thuật phần mềm, Kiến trúc doanh nghiệp và AI/ML. Anh ấy rất đam mê khám phá các khả năng của AI có thể tạo ra. Anh cộng tác với khách hàng để giúp họ xây dựng các ứng dụng có kiến trúc tốt trên nền tảng AWS và tận tâm giải quyết các thách thức công nghệ cũng như hỗ trợ hành trình đám mây của họ.
Nitin Eusebius là Kiến trúc sư giải pháp doanh nghiệp cấp cao tại AWS, có kinh nghiệm về Kỹ thuật phần mềm, Kiến trúc doanh nghiệp và AI/ML. Anh ấy rất đam mê khám phá các khả năng của AI có thể tạo ra. Anh cộng tác với khách hàng để giúp họ xây dựng các ứng dụng có kiến trúc tốt trên nền tảng AWS và tận tâm giải quyết các thách thức công nghệ cũng như hỗ trợ hành trình đám mây của họ.
 Madhur Prashant hoạt động trong không gian AI tổng quát tại AWS. Anh ấy đam mê sự giao thoa giữa tư duy của con người và AI. Mối quan tâm của anh nằm ở AI có tính sáng tạo, đặc biệt là xây dựng các giải pháp hữu ích và vô hại, và trên hết là tối ưu cho khách hàng. Ngoài công việc, anh ấy thích tập yoga, đi bộ đường dài, dành thời gian với người em song sinh và chơi guitar.
Madhur Prashant hoạt động trong không gian AI tổng quát tại AWS. Anh ấy đam mê sự giao thoa giữa tư duy của con người và AI. Mối quan tâm của anh nằm ở AI có tính sáng tạo, đặc biệt là xây dựng các giải pháp hữu ích và vô hại, và trên hết là tối ưu cho khách hàng. Ngoài công việc, anh ấy thích tập yoga, đi bộ đường dài, dành thời gian với người em song sinh và chơi guitar.
 Dewan Choudhury là Kỹ sư phát triển phần mềm của Amazon Web Services. Anh ấy làm việc trên các thuật toán của Amazon SageMaker và dịch vụ JumpStart. Ngoài việc xây dựng cơ sở hạ tầng AI/ML, anh ấy còn đam mê xây dựng các hệ thống phân tán có thể mở rộng.
Dewan Choudhury là Kỹ sư phát triển phần mềm của Amazon Web Services. Anh ấy làm việc trên các thuật toán của Amazon SageMaker và dịch vụ JumpStart. Ngoài việc xây dựng cơ sở hạ tầng AI/ML, anh ấy còn đam mê xây dựng các hệ thống phân tán có thể mở rộng.
 Hào Châu là Nhà khoa học nghiên cứu của Amazon SageMaker. Trước đó, anh đã nghiên cứu phát triển các phương pháp học máy để phát hiện gian lận cho Amazon Fraud Detector. Anh ấy đam mê áp dụng các kỹ thuật học máy, tối ưu hóa và AI tổng hợp vào các vấn đề khác nhau trong thế giới thực. Ông có bằng Tiến sĩ Kỹ thuật Điện của Đại học Northwestern.
Hào Châu là Nhà khoa học nghiên cứu của Amazon SageMaker. Trước đó, anh đã nghiên cứu phát triển các phương pháp học máy để phát hiện gian lận cho Amazon Fraud Detector. Anh ấy đam mê áp dụng các kỹ thuật học máy, tối ưu hóa và AI tổng hợp vào các vấn đề khác nhau trong thế giới thực. Ông có bằng Tiến sĩ Kỹ thuật Điện của Đại học Northwestern.
 Thanh Lan là Kỹ sư phát triển phần mềm trong AWS. Anh ấy đã làm việc trên một số sản phẩm đầy thử thách ở Amazon, bao gồm các giải pháp suy luận ML hiệu suất cao và hệ thống ghi nhật ký hiệu suất cao. Nhóm của Qing đã khởi chạy thành công mô hình Tỷ tham số đầu tiên trong Quảng cáo Amazon với độ trễ yêu cầu rất thấp. Qing có kiến thức chuyên sâu về tối ưu hóa cơ sở hạ tầng và tăng tốc Deep Learning.
Thanh Lan là Kỹ sư phát triển phần mềm trong AWS. Anh ấy đã làm việc trên một số sản phẩm đầy thử thách ở Amazon, bao gồm các giải pháp suy luận ML hiệu suất cao và hệ thống ghi nhật ký hiệu suất cao. Nhóm của Qing đã khởi chạy thành công mô hình Tỷ tham số đầu tiên trong Quảng cáo Amazon với độ trễ yêu cầu rất thấp. Qing có kiến thức chuyên sâu về tối ưu hóa cơ sở hạ tầng và tăng tốc Deep Learning.
 Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao với các thuật toán tích hợp Amazon SageMaker và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao với các thuật toán tích hợp Amazon SageMaker và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
 Tiến sĩ Li Zhang là Giám đốc sản phẩm-Kỹ thuật chính cho các thuật toán tích hợp của Amazon SageMaker JumpStart và Amazon SageMaker, một dịch vụ giúp các nhà khoa học dữ liệu và người thực hành máy học bắt đầu đào tạo và triển khai các mô hình của họ cũng như sử dụng phương pháp học tăng cường với Amazon SageMaker. Công việc trước đây của ông với tư cách là nhân viên nghiên cứu chính và nhà phát minh bậc thầy tại IBM Research đã giành được giải thưởng bài kiểm tra thời gian tại IEEE INFOCOM.
Tiến sĩ Li Zhang là Giám đốc sản phẩm-Kỹ thuật chính cho các thuật toán tích hợp của Amazon SageMaker JumpStart và Amazon SageMaker, một dịch vụ giúp các nhà khoa học dữ liệu và người thực hành máy học bắt đầu đào tạo và triển khai các mô hình của họ cũng như sử dụng phương pháp học tăng cường với Amazon SageMaker. Công việc trước đây của ông với tư cách là nhân viên nghiên cứu chính và nhà phát minh bậc thầy tại IBM Research đã giành được giải thưởng bài kiểm tra thời gian tại IEEE INFOCOM.
 Kamran Khan, Giám đốc phát triển kinh doanh kỹ thuật cấp cao cho AWS Inferentina/Trianium tại AWS. Ông có hơn một thập kỷ kinh nghiệm giúp khách hàng triển khai và tối ưu hóa khối lượng công việc suy luận và đào tạo deep learning bằng AWS Inferentia và AWS Trainium.
Kamran Khan, Giám đốc phát triển kinh doanh kỹ thuật cấp cao cho AWS Inferentina/Trianium tại AWS. Ông có hơn một thập kỷ kinh nghiệm giúp khách hàng triển khai và tối ưu hóa khối lượng công việc suy luận và đào tạo deep learning bằng AWS Inferentia và AWS Trainium.
 Joe Senerchia là Giám đốc sản phẩm cấp cao tại AWS. Anh xác định và xây dựng các phiên bản Amazon EC2 dành cho deep learning, trí tuệ nhân tạo và khối lượng công việc điện toán hiệu năng cao.
Joe Senerchia là Giám đốc sản phẩm cấp cao tại AWS. Anh xác định và xây dựng các phiên bản Amazon EC2 dành cho deep learning, trí tuệ nhân tạo và khối lượng công việc điện toán hiệu năng cao.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- có khả năng
- Có khả năng
- Giới thiệu
- tăng tốc
- Chấp nhận
- chấp nhận được
- chấp nhận
- truy cập
- chính xác
- chính xác
- công nhận
- ACM
- hoạt động
- hoạt động
- Adam
- thích ứng
- thích ứng
- thích nghi
- thêm vào
- Ngoài ra
- người lớn
- tiên tiến
- thăng tiến
- Quảng cáo
- Sau
- Hiệp định
- AI
- Mô hình AI
- AI / ML
- thuật toán
- Tất cả
- cho phép
- cho phép
- cho phép
- Ngoài ra
- đàn bà gan dạ
- Amazon EC2
- Phát hiện gian lận Amazon
- Amazon SageMaker
- Khởi động Amazon SageMaker
- Amazon Web Services
- trong số
- an
- phân tích
- Xưa
- và
- động vật
- Thông báo
- Một
- bất kì
- nữa không
- Apache
- ngoài
- áp dụng
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- Nộp đơn
- thích hợp
- khoảng
- kiến trúc
- LÀ
- KHU VỰC
- khu vực
- đối số
- Quân đội
- đến
- Nghệ thuật
- nhân tạo
- trí tuệ nhân tạo
- AS
- trợ giúp
- Hiệp hội
- At
- Tiếp viên
- thuộc tính
- Thẩm quyền
- tác giả
- Tự động
- sẵn có
- có sẵn
- tránh
- AWS
- Suy luận AWS
- b
- dựa
- BE
- Chùm tia
- bởi vì
- trở nên
- được
- trước
- được
- Tin
- phía dưới
- giữa
- Ngoài
- lớn nhất
- sinh học
- Blog
- sinh
- cả hai
- Hộp
- rộng
- xây dựng
- Xây dựng
- xây dựng
- được xây dựng trong
- kinh doanh
- phát triển kinh doanh
- nhưng
- nút
- nút
- by
- cuộc gọi
- đến
- CAN
- khả năng
- vốn
- thẻ
- thực hiện
- trường hợp
- trường hợp
- đố
- Phân loại
- thách thức
- thách thức
- thay đổi
- Chaos
- trò chuyện trên mạng
- chánh
- sự lựa chọn
- Chọn
- lựa chọn
- Christopher
- City
- dân sự
- rõ ràng
- các lớp học
- cổ điển
- phân loại
- giống cá lăng
- đám mây
- tập hợp
- mã
- lạnh
- ủy ban
- Chung
- Cộng đồng
- cộng đồng
- công ty
- so
- so sánh
- so sánh
- Hoàn thành
- Hoàn thành
- tính toán
- máy tính
- phần kết luận
- đồng thời
- Tiến hành
- Hội nghị
- hội nghị
- Cấu hình
- Xác nhận
- An ủi
- chứa
- Container
- chứa
- nội dung
- bối cảnh
- bối cảnh
- đóng góp
- điều khiển
- điều khiển
- Phí Tổn
- tốn kém
- Chi phí
- đất nước
- tạo ra
- Vương miện
- quan trọng
- văn hóa
- Cup
- khách hàng
- kinh nghiệm khach hang
- khách hàng
- tùy biến
- dữ liệu
- bộ dữ liệu
- Ngày
- de
- thập kỷ
- Tháng mười hai
- Giải mã
- dành riêng
- sâu
- học kĩ càng
- sâu
- Mặc định
- Xác định
- Bằng cấp
- cung cấp
- dân chủ
- chứng minh
- chứng minh
- chứng minh
- Tùy
- phụ thuộc
- triển khai
- triển khai
- triển khai
- triển khai
- mô tả
- Mô tả
- được chỉ định
- thiết kế
- chi tiết
- chi tiết
- Phát hiện
- phát triển
- phát triển
- Phát triển
- Đối thoại
- ĐÃ LÀM
- sự khác biệt
- khác nhau
- khám phá
- phát hiện
- thảo luận
- Giao diện
- phân phối
- hệ thống phân phối
- khác nhau
- làm
- làm
- Dolly
- miền
- lĩnh vực
- dont
- xuống
- mỗi
- Đầu
- kiếm
- dễ dàng
- dễ sử dụng
- biên tập viên
- Hiệu quả
- hiệu quả
- hiệu quả
- hay
- bầu
- kỹ thuật điện
- Empire
- kích hoạt
- cho phép
- cho phép
- cuối
- Cuối cùng đến cuối
- Điểm cuối
- ky sư
- Kỹ Sư
- nâng cao
- tăng cường
- đủ
- đảm bảo
- Doanh nghiệp
- Giải pháp doanh nghiệp
- Môi trường
- môi trường
- như nhau
- equals
- đặc biệt
- Ether (ETH)
- đánh giá
- đánh giá
- hiển nhiên
- ví dụ
- ví dụ
- kích thích
- loại trừ
- hiện tại
- kinh nghiệm
- kinh nghiệm
- thử nghiệm
- khám phá
- Khám phá
- khai thác
- Rơi
- sai
- nhanh hơn
- đồng bào
- lễ hội
- vài
- Lĩnh vực
- Tập tin
- Các tập tin
- Nộp hồ sơ
- tài chính
- dịch vụ tài chính
- Tìm kiếm
- cuối
- Tên
- Linh hoạt
- Phao
- Tập trung
- tập trung
- tiếp theo
- sau
- Trong
- Buộc
- định dạng
- tìm thấy
- Nền tảng
- Thành lập
- Khung
- khung
- gian lận
- phát hiện gian lận
- từ
- chức năng
- xa hơn
- tạo ra
- tạo
- thế hệ
- thế hệ
- Trí tuệ nhân tạo
- được
- Go
- Thiên Chúa
- tốt
- có
- tốt nghiệp
- đồ thị
- đồ thị
- lớn hơn
- Hy lạp
- Tham lam
- người Hy Lạp
- Nhóm
- hướng dẫn
- cây đàn guitar
- có
- Xử lý
- Tay bài
- vui mừng
- Có
- he
- chăm sóc sức khỏe
- Được tổ chức
- giúp đỡ
- hữu ích
- giúp đỡ
- giúp
- Cao
- hiệu suất cao
- cao hơn
- cao nhất
- nổi bật
- đi bộ đường dài
- anh ta
- của mình
- giữ
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- Nhân loại
- i
- IBM
- ICLR
- xác định
- id
- IEEE
- if
- ii
- Illinois
- thực hiện
- nhập khẩu
- quan trọng
- nâng cao
- cải thiện
- cải thiện
- cải tiến
- in
- sâu
- bao gồm
- bao gồm
- Bao gồm
- Tăng lên
- chỉ
- thông tin
- khai thác thông tin
- Cơ sở hạ tầng
- cơ sở hạ tầng
- đầu vào
- đầu vào
- ví dụ
- trường hợp
- hướng dẫn
- tích hợp
- Sự thông minh
- lợi ích
- Giao thức
- Quốc Tế
- ngã tư
- trong
- tham gia
- IT
- ITS
- james
- Việc làm
- việc làm
- gia nhập
- jonathan
- tạp chí
- cuộc hành trình
- jpg
- json
- chỉ
- Key
- Vương quốc
- bộ dụng cụ
- Bộ công cụ (SDK)
- kiến thức
- nổi tiếng
- hạ cánh
- trang đích
- Ngôn ngữ
- lớn
- quy mô lớn
- Độ trễ
- một lát sau
- phát động
- Luật
- hàng đầu
- học tập
- Chiều dài
- li
- Giấy phép
- giấy phép
- nói dối
- Cuộc sống
- Lượt thích
- khả năng
- Có khả năng
- giới hạn
- Dòng
- dòng
- LINK
- Danh sách
- Liệt kê
- Loài đà mã ở nam mỹ
- tải
- địa phương
- khai thác gỗ
- dài
- Xem
- yêu
- Thấp
- thấp hơn
- hạ
- thấp nhất
- máy
- học máy
- thực hiện
- Chủ yếu
- làm cho
- Làm
- giám đốc
- quản lý
- Manan Shah
- nhiều
- chủ
- tối đa
- Có thể..
- có nghĩa là
- Gặp gỡ
- hội viên
- Siêu dữ liệu
- phương pháp
- phương pháp
- Mexico
- Might
- làm biếng
- tâm
- ML
- kiểu mẫu
- người mẫu
- mô hình
- sửa đổi
- sửa đổi
- chi tiết
- hầu hết
- chuyển
- Âm nhạc
- phải
- tên
- Tự nhiên
- Ngôn ngữ tự nhiên
- Xử lý ngôn ngữ tự nhiên
- Điều hướng
- THÔNG TIN
- Cần
- nhu cầu
- Thần kinh
- Mới
- tiếp theo
- nlp
- Đại học Northwestern
- máy tính xách tay
- máy tính xách tay
- tại
- con số
- số
- vật
- mục tiêu
- of
- cung cấp
- cung cấp
- Cung cấp
- Cung cấp
- thường
- Xưa
- cũ
- on
- hàng loạt
- ONE
- có thể
- tối ưu
- tối ưu hóa
- Tối ưu hóa
- tối ưu hóa
- tối ưu hóa
- Tùy chọn
- or
- cơ quan
- Nền tảng khác
- đầu ra
- bên ngoài
- nổi bật
- kết thúc
- riêng
- gói
- trang
- đôi
- ghép đôi
- cửa sổ
- Giấy
- giấy tờ
- Song song
- thông số
- một phần
- đặc biệt
- các bên tham gia
- đi qua
- đam mê
- qua
- mỗi
- thực hiện
- hiệu suất
- thời gian
- Cá nhân
- Bằng tiến sĩ
- đường ống dẫn
- nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chơi
- xin vui lòng
- Điểm
- Chính sách
- điều luật
- chính trị
- pop-up
- Phổ biến
- tích cực
- khả năng
- có thể
- Bài đăng
- mạnh mẽ
- trước
- Độ chính xác
- chuẩn bị
- chính
- Hiệu trưởng
- xác suất
- vấn đề
- quá trình
- xử lý
- Sản phẩm
- giám đốc sản xuất
- Sản phẩm
- độc quyền
- cho
- nhà cung cấp
- cung cấp
- công khai
- công bố
- đặt
- Python
- ngọn đuốc
- chất lượng
- câu hỏi
- ngẫu nhiên
- đạt
- Đạt
- Đọc
- sẵn sàng
- thực
- thế giới thực
- thời gian thực
- lý do
- lý do
- hồ sơ
- xem
- tham khảo
- người tị nạn
- phát hành
- sự liên quan
- có liên quan
- Đã di dời
- vẫn
- vẫn còn
- lặp đi lặp lại
- lặp đi lặp lại
- thay thế
- kho
- đại diện
- đại diện
- yêu cầu
- yêu cầu
- cần phải
- nghiên cứu
- nhà nghiên cứu
- Thông tin
- tương ứng
- phản ứng
- phản ứng
- chịu trách nhiệm
- kết quả
- Kết quả
- trở lại
- xem xét
- xem xét
- mạnh mẽ
- Lăn
- hoàng gia
- chạy
- Nga
- nhà làm hiền triết
- khả năng mở rộng
- khả năng mở rộng
- Quy mô
- kịch bản
- Nhà khoa học
- các nhà khoa học
- kịch bản
- sdk
- Tìm kiếm
- tìm kiếm
- SEC
- -Sự nộp SEC
- Thứ hai
- Phần
- an ninh
- xem
- cao cấp
- gởi
- kết án
- tình cảm
- riêng biệt
- Trình tự
- Loạt Sách
- Dòng A
- dịch vụ
- DỊCH VỤ
- định
- thiết lập
- thiết lập
- một số
- ngắn
- nên
- hiển thị
- thể hiện
- Chương trình
- có ý nghĩa
- Đơn giản
- kể từ khi
- duy nhất
- Kích thước máy
- đoạn
- So
- Xã hội
- Phần mềm
- phát triển phần mềm
- bộ phát triển phần mềm
- kỹ thuật phần mềm
- giải pháp
- Giải pháp
- Giải quyết
- một số
- Con trai
- nguồn
- miền Nam
- Liên Xô
- Không gian
- chuyên nghành
- riêng
- đặc biệt
- tính cụ thể
- quy định
- Chi
- chia
- Nhân sự
- Bắt đầu
- bắt đầu
- Tiểu bang
- thống kê
- Trạng thái
- chỉ đạo
- Bước
- Các bước
- Dừng
- là gắn
- cấu trúc
- Sinh viên
- nghiên cứu
- nghiên cứu
- phòng thu
- Thành công
- như vậy
- hỗ trợ
- Hỗ trợ
- chắc chắn
- switzerland
- hệ thống
- hệ thống
- bàn
- phù hợp
- Nhiệm vụ
- nhiệm vụ
- Giảng dạy
- nhóm
- Kỹ thuật
- kỹ thuật
- kỹ thuật
- Công nghệ
- mẫu
- tennessee
- về
- thử nghiệm
- văn bản
- Phân loại văn bản
- tạo văn bản
- hơn
- việc này
- Sản phẩm
- Khu vực
- Thủ đô
- Nhà hát
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- Suy nghĩ
- của bên thứ ba
- điều này
- những
- Thông qua
- thông lượng
- hổ
- thời gian
- thời gian
- đến
- bây giờ
- mã thông báo
- Tokens
- công cụ
- Tổng số:
- Train
- đào tạo
- Hội thảo
- biến áp
- Dịch
- đúng
- thử
- sinh đôi
- hai
- kiểu
- ui
- Dưới
- cơ bản
- độc đáo
- Các trường Đại học
- trường đại học
- cho đến khi
- Cập nhật
- Cập nhật
- Sử dụng
- sử dụng
- ca sử dụng
- đã sử dụng
- người sử dang
- Người sử dụng
- sử dụng
- sử dụng
- sử dụng
- uzbekistan
- xác nhận
- giá trị
- nhiều
- khác nhau
- phiên bản
- rất
- thông qua
- Xem
- cây nho
- trực quan
- đi bộ
- muốn
- chiến tranh
- là
- cách
- we
- web
- các dịch vụ web
- Dựa trên web
- đi
- là
- khi nào
- cái nào
- trong khi
- CHÚNG TÔI LÀ
- sẽ
- RƯỢU NHO
- với
- Won
- Từ
- từ
- Công việc
- làm việc
- đang làm việc
- công trinh
- hội thảo
- thế giới
- sẽ
- viết
- năm
- Yoga
- bạn
- trên màn hình
- thiếu niên
- zephyrnet
- Zeus