Trong bài Giới thiệu công cụ TCO của AWS ProServe Hadoop Migration Delivery Kit, chúng tôi đã giới thiệu công cụ TCO AWS ProServe Hadoop Migration Delivery Kit (HMDK) và lợi ích của việc di chuyển khối lượng công việc Hadoop tại chỗ sang Amazon EMR. Trong bài đăng này, chúng ta sẽ tìm hiểu sâu về công cụ này, xem qua tất cả các bước từ nhập nhật ký, chuyển đổi, trực quan hóa và thiết kế kiến trúc để tính toán TCO.
Tổng quan về giải pháp
Chúng ta hãy xem nhanh các tính năng chính của công cụ HMDK TCO. Công cụ này cung cấp trình thu thập nhật ký YARN để kết nối Trình quản lý tài nguyên Hadoop nhằm thu thập nhật ký YARN. Bộ phân tích khối lượng công việc Hadoop dựa trên Python, được gọi là bộ phân tích nhật ký YARN, xem xét kỹ lưỡng các ứng dụng Hadoop. Amazon QuickSight bảng điều khiển hiển thị các kết quả từ máy phân tích. Các kết quả tương tự cũng đẩy nhanh quá trình thiết kế các phiên bản EMR trong tương lai. Ngoài ra, một máy tính TCO tạo ra ước tính TCO của cụm EMR được tối ưu hóa để tạo điều kiện thuận lợi cho việc di chuyển.
Bây giờ hãy xem cách thức hoạt động của công cụ này. Sơ đồ sau đây minh họa quy trình làm việc từ đầu đến cuối.

Trong các phần tiếp theo, chúng ta sẽ đi qua năm bước chính của công cụ:
- Thu thập nhật ký lịch sử công việc YARN.
- Chuyển đổi nhật ký lịch sử công việc từ JSON sang CSV.
- Phân tích nhật ký lịch sử công việc.
- Thiết kế cụm EMR để di chuyển.
- Tính TCO.
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo hoàn thành các điều kiện tiên quyết sau:
- Sao chép kho lưu trữ hadoop-di chuyển-đánh giá-tco.
- Cài đặt Python 3 trên máy cục bộ của bạn.
- Có tài khoản AWS với quyền trên AWS Lambda, QuickSight (phiên bản Enterprise) và Hình thành đám mây AWS.
Thu thập nhật ký lịch sử công việc YARN
Đầu tiên, bạn chạy một Trình thu thập nhật ký YARN, start-collector.sh, trên máy cục bộ của bạn. Bước này thu thập nhật ký YARN Hadoop và đặt nhật ký trên máy cục bộ của bạn. Tập lệnh kết nối máy cục bộ của bạn với nút chính Hadoop và giao tiếp với Trình quản lý tài nguyên. Sau đó, nó truy xuất thông tin lịch sử công việc (Nhật ký YARN từ trình quản lý ứng dụng) bằng cách gọi API ứng dụng YARN ResourceManager.
Trước khi chạy trình thu thập nhật ký YARN, bạn cần định cấu hình và thiết lập kết nối (HTTP: 8088 hoặc HTTPS: 8090; HTTPS: 1 được khuyến nghị) để xác minh khả năng truy cập của Trình quản lý tài nguyên YARN và Máy chủ dòng thời gian YARN đã bật (Máy chủ dòng thời gian v2,000 trở lên được hỗ trợ ). Bạn có thể cần xác định chính sách lưu giữ và khoảng thời gian thu thập nhật ký YARN. Để đảm bảo rằng bạn thu thập các bản ghi YARN liên tiếp, bạn có thể sử dụng công việc định kỳ để lên lịch trình thu thập nhật ký trong một khoảng thời gian thích hợp. Ví dụ: đối với cụm Hadoop có 1,000 ứng dụng hàng ngày và cài đặt yarn.resourcemanager.max-completed-applications được đặt thành 7, về mặt lý thuyết, bạn phải chạy trình thu thập nhật ký ít nhất hai lần để lấy tất cả nhật ký YARN. Ngoài ra, chúng tôi khuyên bạn nên thu thập nhật ký YARN ít nhất XNUMX ngày để phân tích khối lượng công việc tổng thể.
Để biết thêm chi tiết về cách định cấu hình và lên lịch trình thu thập nhật ký, hãy tham khảo sợi-log-collector GitHub repo.
Chuyển đổi nhật ký lịch sử công việc YARN từ JSON sang CSV
Sau khi nhận được nhật ký YARN, bạn chạy trình tổ chức nhật ký YARN, yarn-log-organizer.py, đây là trình phân tích cú pháp để chuyển đổi nhật ký dựa trên JSON thành tệp CSV. Các tệp CSV đầu ra này là đầu vào cho trình phân tích nhật ký YARN. Trình phân tích cú pháp cũng có các khả năng khác, bao gồm sắp xếp các sự kiện theo thời gian, loại bỏ các cống hiến và hợp nhất nhiều nhật ký.
Để biết thêm thông tin về cách sử dụng trình tổ chức nhật ký YARN, hãy tham khảo repo GitHub sợi-log-tổ chức.
Phân tích nhật ký lịch sử công việc YARN
Tiếp theo, bạn khởi chạy trình phân tích nhật ký YARN để phân tích nhật ký YARN ở định dạng CSV.
Với QuickSight, bạn có thể trực quan hóa dữ liệu nhật ký YARN và tiến hành phân tích đối với các bộ dữ liệu được tạo bởi các mẫu bảng điều khiển được tạo sẵn và một tiện ích con. Tiện ích tự động tạo bảng điều khiển QuickSight trong tài khoản AWS đích, được định cấu hình trong mẫu CloudFormation.
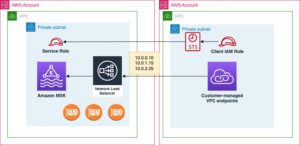
Sơ đồ sau đây minh họa kiến trúc HMDK TCO.

Trình phân tích nhật ký YARN cung cấp bốn chức năng chính:
- Tải lên nhật ký lịch sử công việc YARN đã chuyển đổi ở định dạng CSV (ví dụ:
cluster_yarn_logs_*.csv) Để Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) thùng. Các tệp CSV này là đầu ra từ trình tổ chức nhật ký YARN. - Tạo tệp kê khai JSON (ví dụ:
yarn-log-manifest.json) cho QuickSight và tải nó lên bộ chứa S3: - Triển khai bảng thông tin QuickSight bằng cách sử dụng mẫu CloudFormation ở định dạng YAML. Sau khi triển khai, hãy chọn biểu tượng làm mới cho đến khi bạn thấy trạng thái của ngăn xếp là
CREATE_COMPLETE. Bước này tạo bộ dữ liệu trên bảng điều khiển QuickSight trong tài khoản đích AWS của bạn.
- Trên bảng điều khiển QuickSight, bạn có thể tìm thấy thông tin chuyên sâu về khối lượng công việc Hadoop đã phân tích từ các biểu đồ khác nhau. Những thông tin chi tiết này giúp bạn thiết kế các phiên bản EMR trong tương lai để tăng tốc di chuyển, như được trình bày trong bước tiếp theo.

Thiết kế cụm EMR để di chuyển
Kết quả của trình phân tích nhật ký YARN giúp bạn hiểu khối lượng công việc Hadoop thực tế trên hệ thống hiện có. Bước này đẩy nhanh quá trình thiết kế các phiên bản EMR trong tương lai để di chuyển bằng cách sử dụng một Mẫu Excel. Mẫu chứa danh sách kiểm tra để tiến hành phân tích khối lượng công việc và lập kế hoạch năng lực:
- Các ứng dụng đang chạy trên cluster có được sử dụng phù hợp với công suất hiện tại không?
- Là cụm đang tải tại một thời điểm nhất định hay không? Nếu vậy, khi nào là thời gian?
- Những loại ứng dụng và công cụ nào (chẳng hạn như MR, TEZ hoặc Spark) đang chạy trên cụm và mức sử dụng tài nguyên cho từng loại là gì?
- Các chu kỳ chạy của các công việc khác nhau (thời gian thực, hàng loạt, đặc biệt) có chạy trong một cụm không?
- Có bất kỳ công việc nào đang chạy theo đợt thông thường không và nếu có thì những khoảng thời gian này là gì? (Ví dụ: cứ sau 10 phút, 1 giờ, 1 ngày.) Bạn có những công việc sử dụng nhiều tài nguyên trong một khoảng thời gian dài không?
- Có công việc nào cần cải thiện hiệu suất không?
- Có tổ chức hoặc cá nhân cụ thể nào độc quyền cụm không?
- Có bất kỳ công việc phát triển và vận hành hỗn hợp nào đang hoạt động trong một cụm không?
Sau khi bạn hoàn thành danh sách kiểm tra, bạn sẽ hiểu rõ hơn về cách thiết kế kiến trúc trong tương lai. Để tối ưu hóa hiệu quả chi phí của cụm EMR, bảng sau đây cung cấp các hướng dẫn chung về việc chọn loại cụm EMR phù hợp và Đám mây điện toán đàn hồi Amazon (Amazon EC2) họ.

Để chọn loại cụm và dòng phiên bản phù hợp, bạn cần thực hiện nhiều vòng phân tích đối với nhật ký YARN dựa trên các tiêu chí khác nhau. Hãy xem xét một số chỉ số chính.
Lịch Trình Sự Kiện
Bạn có thể tìm thấy các mẫu khối lượng công việc dựa trên số lượng ứng dụng Hadoop chạy trong một khoảng thời gian. Ví dụ: biểu đồ hàng ngày hoặc hàng giờ "Số lượng bản ghi theo thời gian bắt đầu" cung cấp thông tin chi tiết sau:
- Trong biểu đồ chuỗi thời gian hàng ngày, bạn so sánh số lần chạy ứng dụng giữa ngày làm việc và ngày nghỉ, và giữa các ngày theo lịch. Nếu các con số tương tự nhau, điều đó có nghĩa là mức độ sử dụng hàng ngày của cụm là tương đương nhau. Mặt khác, nếu độ lệch lớn, tỷ lệ công việc đặc biệt là đáng kể. Bạn cũng có thể tìm ra các công việc hàng tuần hoặc hàng tháng có thể vào những ngày cụ thể. Trong tình huống, bạn có thể dễ dàng xem các ngày cụ thể trong một tuần hoặc một tháng với mức độ tập trung khối lượng công việc cao.
- Trong biểu đồ chuỗi thời gian hàng giờ, bạn hiểu rõ hơn về cách các ứng dụng chạy trong cửa sổ hàng giờ. Bạn có thể tìm giờ cao điểm và thấp điểm trong ngày.
Người dùng
Nhật ký YARN chứa ID người dùng của từng ứng dụng. Thông tin này giúp bạn hiểu ai gửi đơn đăng ký vào hàng đợi. Dựa trên số liệu thống kê về số lần chạy ứng dụng riêng lẻ và tổng hợp trên mỗi hàng đợi và trên mỗi người dùng, bạn có thể xác định phân bổ khối lượng công việc hiện tại theo người dùng. Thông thường, người dùng trong cùng một nhóm có hàng đợi chung. Đôi khi, nhiều đội có hàng chờ chung. Khi thiết kế hàng đợi cho người dùng, giờ đây bạn có thông tin chi tiết để giúp bạn thiết kế và phân bổ khối lượng công việc của ứng dụng cân bằng hơn giữa các hàng đợi so với trước đây.
Các loại ứng dụng
Bạn có thể phân đoạn khối lượng công việc dựa trên các loại ứng dụng khác nhau (chẳng hạn như Hive, Spark, Presto hoặc HBase) và chạy các công cụ (chẳng hạn như MR, Spark hoặc Tez). Đối với khối lượng công việc điện toán nặng, chẳng hạn như công việc MapReduce hoặc Hive-on-MR, hãy sử dụng các phiên bản được tối ưu hóa cho CPU. Đối với các khối lượng công việc sử dụng nhiều bộ nhớ như công việc Hive-on-TEZ, Presto và Spark, hãy sử dụng các phiên bản tối ưu hóa bộ nhớ.
Thời gian đã trôi qua
Bạn có thể phân loại các ứng dụng theo thời gian chạy. Mẫu CloudFormation được nhúng sẽ tự động tạo trường elapsedGroup trong bảng điều khiển QuickSight. Điều này cho phép một tính năng chính cho phép bạn quan sát các công việc chạy dài ở một trong bốn biểu đồ trên bảng điều khiển QuickSight. Do đó, bạn có thể thiết kế các kiến trúc tương lai phù hợp cho những công việc lớn này.
Bảng điều khiển QuickSight tương ứng bao gồm bốn biểu đồ. Bạn có thể xem chi tiết từng biểu đồ được liên kết với một nhóm.
| Nhóm Con số |
Thời gian chạy/Thời gian đã trôi qua của một công việc |
| 1 | Ít hơn 10 phút |
| 2 | Từ 10 phút đến 30 phút |
| 3 | từ 30 phút đến 1 giờ |
| 4 | Hơn 1 giờ |
Trong biểu đồ của Nhóm 4, bạn có thể tập trung vào việc xem xét kỹ lưỡng các công việc lớn dựa trên nhiều số liệu khác nhau, bao gồm người dùng, hàng đợi, loại ứng dụng, dòng thời gian, mức sử dụng tài nguyên, v.v. Dựa trên sự cân nhắc này, bạn có thể có các hàng đợi chuyên dụng trên một cụm hoặc cụm EMR chuyên dụng cho các công việc lớn. Trong khi đó, bạn có thể gửi các công việc nhỏ vào hàng đợi được chia sẻ.
Thông tin
Dựa trên các mẫu tiêu thụ tài nguyên (CPU, bộ nhớ), bạn chọn kích thước và dòng phiên bản EC2 phù hợp để đạt hiệu suất và tiết kiệm chi phí. Đối với các ứng dụng chuyên sâu về điện toán, chúng tôi khuyên dùng các phiên bản thuộc dòng CPU được tối ưu hóa. Đối với các ứng dụng sử dụng nhiều bộ nhớ, nên sử dụng dòng phiên bản tối ưu hóa bộ nhớ.
Ngoài ra, dựa trên bản chất của khối lượng công việc ứng dụng và mức sử dụng tài nguyên theo thời gian, bạn có thể chọn cụm EMR liên tục hoặc tạm thời, Amazon EMR trên EKS, hoặc là Amazon EMR không có máy chủ.
Sau khi phân tích nhật ký YARN theo nhiều chỉ số khác nhau, bạn đã sẵn sàng thiết kế kiến trúc EMR trong tương lai. Bảng sau đây liệt kê các ví dụ về các cụm EMR được đề xuất. Bạn có thể tìm thêm chi tiết trong tối ưu hóa-tco-máy tính repo GitHub.

Tính TCO
Cuối cùng, trên máy cục bộ của bạn, hãy chạy tco-input-generator.py để tổng hợp nhật ký lịch sử công việc YARN hàng giờ trước khi sử dụng mẫu Excel để tính toán TCO được tối ưu hóa. Bước này rất quan trọng vì kết quả mô phỏng khối lượng công việc của Hadoop trong các phiên bản EMR trong tương lai.
Điều kiện tiên quyết của mô phỏng TCO là chạy tco-input-generator.py, tạo nhật ký tổng hợp hàng giờ. Tiếp theo, bạn mở một tệp mẫu Excel để bật macro và cung cấp thông tin đầu vào của bạn trong các ô màu lục để tính TCO. Về dữ liệu đầu vào, bạn nhập kích thước dữ liệu thực mà không sao chép và thông số kỹ thuật phần cứng (vCore, mem) của nút chính Hadoop và các nút dữ liệu. Bạn cũng cần chọn và tải lên nhật ký tổng hợp hàng giờ được tạo trước đó. Sau khi bạn đặt các biến mô phỏng TCO, chẳng hạn như Khu vực, loại EC2, tính khả dụng cao của Amazon EMR, hiệu ứng công cụ, chiết khấu Amazon EC2 và Amazon EBS (EDP), chiết khấu khi mua số lượng lớn Amazon S3, tỷ giá nội tệ và tỷ lệ giá tác vụ/lõi EMR EC2 và giá/giờ, trình giả lập TCO sẽ tự động tính toán chi phí tối ưu của các phiên bản EMR trong tương lai trên Amazon EC2. Các ảnh chụp màn hình sau đây cho thấy ví dụ về kết quả TCO của HMDK.

Để biết thêm thông tin và hướng dẫn tính toán TCO của HMDK, hãy tham khảo tối ưu hóa-tco-máy tính repo GitHub.
Làm sạch
Sau khi bạn hoàn thành tất cả các bước và kết thúc quá trình kiểm tra, hãy hoàn thành các bước sau để xóa tài nguyên để tránh phát sinh chi phí:
- Trên bảng điều khiển AWS CloudFormation, chọn ngăn xếp bạn đã tạo.
- Chọn Xóa bỏ.
- Chọn Xóa ngăn xếp.
- Làm mới trang cho đến khi bạn thấy trạng thái
DELETE_COMPLETE. - Trên bảng điều khiển Amazon S3, hãy xóa bộ chứa S3 mà bạn đã tạo.
Kết luận
Công cụ AWS ProServe HMDK TCO giúp giảm đáng kể nỗ lực lập kế hoạch di chuyển, đây là nhiệm vụ tốn nhiều thời gian và thách thức trong việc đánh giá khối lượng công việc Hadoop của bạn. Với công cụ HMDK TCO, quá trình đánh giá thường mất 2–3 tuần. Bạn cũng có thể xác định TCO được tính toán của kiến trúc EMR trong tương lai. Với công cụ HMDK TCO, bạn có thể nhanh chóng hiểu được khối lượng công việc và mô hình sử dụng tài nguyên của mình. Với thông tin chuyên sâu do công cụ tạo ra, bạn được trang bị để thiết kế các kiến trúc EMR tối ưu trong tương lai. Trong nhiều trường hợp sử dụng, TCO 1 năm của kiến trúc được tái cấu trúc được tối ưu hóa giúp tiết kiệm chi phí đáng kể (giảm 64–80%) cho điện toán và lưu trữ, so với di chuyển Hadoop nâng và thay đổi.
Để tìm hiểu thêm về cách tăng tốc quá trình di chuyển Hadoop của bạn sang Amazon EMR và công cụ HMDK CTO, hãy tham khảo Kho lưu trữ TCO GitHub của Bộ phân phối di chuyển Hadoop, hoặc liên hệ với AWS-HMDK@amazon.com.
Giới thiệu về tác giả
 Công viên Sungyoul là Quản lý thực hành cấp cao tại AWS ProServe. Anh ấy giúp khách hàng đổi mới hoạt động kinh doanh của họ bằng các dịch vụ AWS Analytics, IoT và AI/ML. Anh ấy có chuyên môn về các dịch vụ và công nghệ dữ liệu lớn và quan tâm đến việc cùng nhau xây dựng kết quả kinh doanh của khách hàng.
Công viên Sungyoul là Quản lý thực hành cấp cao tại AWS ProServe. Anh ấy giúp khách hàng đổi mới hoạt động kinh doanh của họ bằng các dịch vụ AWS Analytics, IoT và AI/ML. Anh ấy có chuyên môn về các dịch vụ và công nghệ dữ liệu lớn và quan tâm đến việc cùng nhau xây dựng kết quả kinh doanh của khách hàng.
 Jiseong Kim là Kiến trúc sư dữ liệu cao cấp tại AWS ProServe. Ông chủ yếu làm việc với các khách hàng doanh nghiệp để giúp di chuyển và hiện đại hóa kho dữ liệu, đồng thời cung cấp hướng dẫn và hỗ trợ kỹ thuật cho các dự án dữ liệu lớn như Hadoop, Spark, kho dữ liệu, xử lý dữ liệu thời gian thực và máy học quy mô lớn. Ông cũng hiểu cách áp dụng công nghệ để giải quyết các vấn đề về dữ liệu lớn và xây dựng kiến trúc dữ liệu được thiết kế tốt.
Jiseong Kim là Kiến trúc sư dữ liệu cao cấp tại AWS ProServe. Ông chủ yếu làm việc với các khách hàng doanh nghiệp để giúp di chuyển và hiện đại hóa kho dữ liệu, đồng thời cung cấp hướng dẫn và hỗ trợ kỹ thuật cho các dự án dữ liệu lớn như Hadoop, Spark, kho dữ liệu, xử lý dữ liệu thời gian thực và máy học quy mô lớn. Ông cũng hiểu cách áp dụng công nghệ để giải quyết các vấn đề về dữ liệu lớn và xây dựng kiến trúc dữ liệu được thiết kế tốt.
 George zhao là Kiến trúc sư dữ liệu cao cấp tại AWS ProServe. Anh ấy là một nhà lãnh đạo phân tích giàu kinh nghiệm làm việc với các khách hàng của AWS để cung cấp các giải pháp dữ liệu hiện đại. Anh ấy cũng là một chuyên gia miền ProServe Amazon EMR, người hỗ trợ các chuyên gia tư vấn của ProServe về các phương pháp hay nhất và bộ phân phối dành cho quá trình di chuyển Hadoop sang Amazon EMR. Lĩnh vực anh ấy quan tâm là hồ dữ liệu và phân phối kiến trúc dữ liệu hiện đại trên đám mây.
George zhao là Kiến trúc sư dữ liệu cao cấp tại AWS ProServe. Anh ấy là một nhà lãnh đạo phân tích giàu kinh nghiệm làm việc với các khách hàng của AWS để cung cấp các giải pháp dữ liệu hiện đại. Anh ấy cũng là một chuyên gia miền ProServe Amazon EMR, người hỗ trợ các chuyên gia tư vấn của ProServe về các phương pháp hay nhất và bộ phân phối dành cho quá trình di chuyển Hadoop sang Amazon EMR. Lĩnh vực anh ấy quan tâm là hồ dữ liệu và phân phối kiến trúc dữ liệu hiện đại trên đám mây.
 Kalen Zhang là Trưởng bộ phận công nghệ toàn cầu về dữ liệu đối tác và phân tích tại AWS. Với tư cách là cố vấn đáng tin cậy về dữ liệu và phân tích, cô đã quản lý các sáng kiến chiến lược để chuyển đổi dữ liệu, dẫn dắt các chương trình hiện đại hóa và di chuyển khối lượng công việc phân tích và dữ liệu cũng như đẩy nhanh hành trình di chuyển của khách hàng với các đối tác trên quy mô lớn. Cô chuyên về các hệ thống phân tán, quản lý dữ liệu doanh nghiệp, phân tích nâng cao và các sáng kiến chiến lược quy mô lớn.
Kalen Zhang là Trưởng bộ phận công nghệ toàn cầu về dữ liệu đối tác và phân tích tại AWS. Với tư cách là cố vấn đáng tin cậy về dữ liệu và phân tích, cô đã quản lý các sáng kiến chiến lược để chuyển đổi dữ liệu, dẫn dắt các chương trình hiện đại hóa và di chuyển khối lượng công việc phân tích và dữ liệu cũng như đẩy nhanh hành trình di chuyển của khách hàng với các đối tác trên quy mô lớn. Cô chuyên về các hệ thống phân tán, quản lý dữ liệu doanh nghiệp, phân tích nâng cao và các sáng kiến chiến lược quy mô lớn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- Có khả năng
- Giới thiệu
- đẩy nhanh tiến độ
- tăng tốc
- tăng tốc
- tăng tốc
- tăng tốc
- khả năng tiếp cận
- Tài khoản
- ngang qua
- Ad
- Ngoài ra
- thêm vào
- thông tin bổ sung
- Ngoài ra
- tiên tiến
- cố vấn
- Sau
- chống lại
- AI / ML
- Tất cả
- đàn bà gan dạ
- Amazon EC2
- Amazon EMR
- trong số
- phân tích
- phân tích
- phân tích
- phân tích
- và
- api
- Các Ứng Dụng
- các ứng dụng
- Đăng Nhập
- thích hợp
- kiến trúc
- KHU VỰC
- thẩm định, lượng định, đánh giá
- Hỗ trợ
- liên kết
- tự động
- sẵn có
- AWS
- Hình thành đám mây AWS
- dựa
- cơ sở
- bởi vì
- được
- Lợi ích
- BEST
- thực hành tốt nhất
- Hơn
- giữa
- lớn
- Dữ Liệu Lớn.
- một thời gian ngắn
- xây dựng
- Xây dựng
- kinh doanh
- tính toán
- tính
- tính toán
- tính
- Xem Lịch
- gọi là
- gọi
- khả năng
- Sức chứa
- trường hợp
- Tế bào
- nhất định
- thách thức
- Biểu đồ
- Bảng xếp hạng
- Chọn
- lựa chọn
- đám mây
- cụm
- thu thập
- Thu
- bộ sưu tập
- thu
- thu thập
- COM
- so sánh
- so sánh
- so
- hoàn thành
- Tính
- tập trung
- tập trung
- Tiến hành
- Tiến hành
- Kết nối
- liên quan
- connect
- liên tiếp
- xem xét
- An ủi
- chuyên gia tư vấn
- tiêu thụ
- chứa
- Tương ứng
- Phí Tổn
- tiết kiệm chi phí
- Chi phí
- CPU
- tạo ra
- tạo ra
- tiêu chuẩn
- quan trọng
- CTO
- lưu trữ
- Tiền tệ
- Current
- khách hàng
- khách hàng
- chu kỳ
- tiền thưởng
- bảng điều khiển
- dữ liệu
- Hồ dữ liệu
- quản lý dữ liệu
- xử lý dữ liệu
- bộ dữ liệu
- ngày
- Ngày
- dành riêng
- sâu
- lặn sâu
- cung cấp
- giao hàng
- chứng minh
- triển khai
- Thiết kế
- thiết kế
- chi tiết
- Xác định
- Phát triển
- sai lệch
- khác nhau
- Giảm giá
- phân phát
- phân phối
- hệ thống phân phối
- phân phối
- miền
- xuống
- suốt trong
- mỗi
- dễ dàng
- ebs
- phiên bản
- hiệu lực
- hiệu quả
- những nỗ lực
- nhúng
- cho phép
- kích hoạt
- cho phép
- Cuối cùng đến cuối
- Động cơ
- Động cơ
- đảm bảo
- đăng ký hạng mục thi
- Doanh nghiệp
- khách hàng doanh nghiệp
- đã trang bị
- thành lập
- Ether (ETH)
- sự kiện
- Mỗi
- ví dụ
- ví dụ
- Excel
- hiện tại
- kinh nghiệm
- tạo điều kiện
- gia đình
- gia đình
- Đặc tính
- Tính năng
- lĩnh vực
- Hình
- Tập tin
- Các tập tin
- Tìm kiếm
- hoàn thành
- tiếp theo
- định dạng
- từ
- chức năng
- xa hơn
- tương lai
- Tổng Quát
- tạo ra
- tạo
- được
- nhận được
- GitHub
- Toàn cầu
- màu xanh lá
- Nhóm
- hướng dẫn
- Hadoop
- phần cứng
- giúp đỡ
- giúp
- Cao
- lịch sử
- Tổ ong
- ngay Lê
- toàn diện
- GIỜ LÀM VIỆC
- Độ đáng tin của
- Hướng dẫn
- HTML
- HTTPS
- ICON
- cải thiện
- in
- bao gồm
- Bao gồm
- hệ thống riêng biệt,
- các cá nhân
- thông tin
- khả năng phán đoán
- đổi mới
- đầu vào
- những hiểu biết
- ví dụ
- hướng dẫn
- quan tâm
- lợi ích
- giới thiệu
- iốt
- IT
- Việc làm
- việc làm
- Những hành trình
- json
- Key
- bộ dụng cụ
- hồ
- lớn
- quy mô lớn
- phóng
- dẫn
- lãnh đạo
- LEARN
- học tập
- Led
- Dữ liệu dẫn
- Chức năng
- tải
- địa phương
- dài
- thời gian dài
- Xem
- Rất nhiều
- máy
- học máy
- macro
- Chủ yếu
- làm cho
- quản lý
- giám đốc
- Quản lý
- nhiều
- có nghĩa
- Trong khi đó
- Bộ nhớ
- sáp nhập
- Metrics
- di cư
- phút
- hỗn hợp
- hiện đại
- hiện đại hóa
- tháng
- hàng tháng
- chi tiết
- nhiều
- Thiên nhiên
- Cần
- tiếp theo
- nút
- các nút
- con số
- số
- tuân theo
- có được
- ONE
- mở
- hoạt động
- hoạt động
- tối ưu
- tối ưu hóa
- tối ưu hóa
- tối ưu
- tổ chức
- Nền tảng khác
- riêng
- đối tác
- Đối tác
- mô hình
- Đỉnh
- thực hiện
- hiệu suất
- thời gian
- cho phép
- Nơi
- lập kế hoạch
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- điều luật
- có thể
- Bài đăng
- thực hành
- thực hành
- điều kiện tiên quyết
- trước đây
- giá
- chính
- Trước khi
- vấn đề
- xử lý
- Khóa Học
- dự án
- đúng
- đề xuất
- cho
- cung cấp
- Python
- Mau
- Tỷ lệ
- tỉ lệ
- đạt
- sẵn sàng
- thời gian thực
- dữ liệu theo thời gian thực
- giới thiệu
- đề nghị
- hồ sơ
- làm giảm
- về
- khu
- đều đặn
- loại bỏ
- nhân rộng
- tài nguyên
- Thông tin
- Kết quả
- giữ
- vòng
- chạy
- chạy
- tương tự
- Tiết kiệm
- Quy mô
- lịch trình
- ảnh chụp màn hình
- phần
- phân khúc
- cao cấp
- Loạt Sách
- DỊCH VỤ
- định
- thiết lập
- một số
- chia sẻ
- hiển thị
- giới thiệu
- có ý nghĩa
- đáng kể
- tương tự
- Đơn giản
- mô phỏng
- mô phỏng
- tình hình
- Kích thước máy
- nhỏ
- So
- Giải pháp
- động SOLVE
- một số
- Spark
- chuyên gia
- chuyên
- Đặc biệt
- riêng
- thông số kỹ thuật
- ngăn xếp
- bắt đầu
- số liệu thống kê
- Trạng thái
- Bước
- Các bước
- là gắn
- Chiến lược
- trình
- như vậy
- Hỗ trợ
- hệ thống
- hệ thống
- bàn
- phù hợp
- mất
- Mục tiêu
- nhiệm vụ
- nhóm
- đội
- công nghệ cao
- Kỹ thuật
- Công nghệ
- mẫu
- mẫu
- Kiểm tra
- Sản phẩm
- Tương lai
- cung cấp their dịch
- vì thế
- Thông qua
- thời gian
- Chuỗi thời gian
- mất thời gian
- timeline
- đến
- bên nhau
- công cụ
- Chuyển đổi
- Chuyển đổi
- chuyển đổi
- đúng
- đáng tin cậy
- loại
- Dưới
- hiểu
- sự hiểu biết
- hiểu
- Sử dụng
- sử dụng
- người sử dang
- Người sử dụng
- thường
- khác nhau
- xác minh
- hình dung
- khối lượng
- đi bộ
- Kho bãi
- tuần
- hàng tuần
- tuần
- Điều gì
- Là gì
- cái nào
- CHÚNG TÔI LÀ
- cửa sổ
- không có
- quy trình làm việc
- đang làm việc
- công trinh
- khoai mỡ
- trên màn hình
- zephyrnet