Tóm tắt
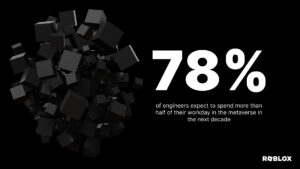
Mỗi ngày trên Roblox, 65.5 triệu người dùng tham gia với hàng triệu trải nghiệm, tổng cộng là 14.0 tỷ giờ hàng quý. Sự tương tác này tạo ra một hồ dữ liệu có quy mô petabyte, được làm phong phú cho mục đích phân tích và học máy (ML). Việc kết hợp các bảng thực tế và thứ nguyên trong hồ dữ liệu của chúng tôi tốn nhiều tài nguyên, vì vậy, để tối ưu hóa điều này và giảm xáo trộn dữ liệu, chúng tôi đã sử dụng Bộ lọc Bloom đã học [1]—cấu trúc dữ liệu thông minh sử dụng ML. Bằng cách dự đoán sự hiện diện, các bộ lọc này cắt giảm đáng kể dữ liệu tham gia, nâng cao hiệu quả và giảm chi phí. Đồng thời, chúng tôi cũng đã cải thiện kiến trúc mô hình của mình và chứng minh những lợi ích đáng kể mà chúng mang lại trong việc giảm bộ nhớ và số giờ sử dụng CPU để xử lý, cũng như tăng độ ổn định khi vận hành.
Giới thiệu
Trong hồ dữ liệu của chúng tôi, các bảng dữ kiện và khối dữ liệu được phân vùng tạm thời để truy cập hiệu quả, trong khi các bảng thứ nguyên thiếu các phân vùng như vậy và việc kết hợp chúng với các bảng dữ kiện trong quá trình cập nhật sẽ tiêu tốn nhiều tài nguyên. Không gian khóa của phép nối được điều khiển bởi phân vùng tạm thời của bảng dữ kiện được nối. Các thực thể thứ nguyên có trong phân vùng tạm thời đó là một tập hợp con nhỏ của những thực thể có trong toàn bộ tập dữ liệu thứ nguyên. Kết quả là phần lớn dữ liệu thứ nguyên được xáo trộn trong các kết nối này cuối cùng sẽ bị loại bỏ. Để tối ưu hóa quá trình này và giảm việc xáo trộn không cần thiết, chúng tôi đã cân nhắc sử dụng Bộ lọc hoa trên các khóa tham gia riêng biệt nhưng phải đối mặt với các vấn đề về kích thước bộ lọc và dung lượng bộ nhớ.
Để giải quyết chúng, chúng tôi đã khám phá Bộ lọc hoa đã học, một giải pháp dựa trên ML giúp giảm kích thước Bộ lọc Bloom trong khi vẫn duy trì tỷ lệ dương tính giả thấp. Sự đổi mới này nâng cao hiệu quả của các hoạt động liên kết bằng cách giảm chi phí tính toán và cải thiện tính ổn định của hệ thống. Sơ đồ sau đây minh họa các quy trình tham gia thông thường và được tối ưu hóa trong môi trường điện toán phân tán của chúng tôi.

Nâng cao hiệu quả tham gia với các bộ lọc Bloom đã học
Để tối ưu hóa sự kết hợp giữa các bảng thực tế và thứ nguyên, chúng tôi đã áp dụng triển khai Bộ lọc Bloom đã học. Chúng tôi đã xây dựng một chỉ mục từ các khóa có trong bảng dữ kiện và sau đó triển khai chỉ mục đó để lọc trước dữ liệu thứ nguyên trước khi thực hiện thao tác nối.
Sự phát triển từ Bộ lọc hoa truyền thống sang Bộ lọc hoa đã học
Mặc dù Bộ lọc Bloom truyền thống hoạt động hiệu quả nhưng nó bổ sung thêm 15-25% bộ nhớ bổ sung cho mỗi nút công nhân cần tải để đạt được tỷ lệ dương tính giả mong muốn của chúng tôi. Nhưng bằng cách khai thác Bộ lọc Bloom đã học, chúng tôi đã đạt được kích thước chỉ mục giảm đáng kể trong khi vẫn duy trì tỷ lệ dương tính giả tương tự. Điều này là do việc chuyển đổi Bộ lọc Bloom thành một bài toán phân loại nhị phân. Nhãn dương cho biết sự hiện diện của các giá trị trong chỉ mục, trong khi nhãn âm có nghĩa là chúng không có.
Việc giới thiệu mô hình ML tạo điều kiện thuận lợi cho việc kiểm tra các giá trị ban đầu, sau đó là Bộ lọc Bloom dự phòng để loại bỏ các kết quả âm tính giả. Kích thước giảm bắt nguồn từ việc biểu diễn nén của mô hình và giảm số lượng khóa mà Bộ lọc Bloom dự phòng yêu cầu. Điều này phân biệt nó với phương pháp tiếp cận Bloom Filter thông thường.
Là một phần của công việc này, chúng tôi đã thiết lập hai số liệu để đánh giá phương pháp Bộ lọc Bloom đã học của mình: kích thước đối tượng được tuần tự hóa cuối cùng của chỉ mục và mức tiêu thụ CPU trong quá trình thực hiện các truy vấn nối.
Điều hướng các thách thức thực hiện
Thử thách ban đầu của chúng tôi là giải quyết một tập dữ liệu huấn luyện có độ lệch cao với một số khóa bảng thứ nguyên trong bảng dữ kiện. Khi làm như vậy, chúng tôi đã quan sát thấy sự chồng chéo của khoảng 2/XNUMX khóa giữa các bảng. Để giải quyết vấn đề này, chúng tôi đã tận dụng phương pháp tiếp cận Sandwich Learned Bloom Filter [XNUMX]. Điều này tích hợp Bộ lọc Bloom truyền thống ban đầu để cân bằng lại việc phân phối tập dữ liệu bằng cách loại bỏ phần lớn các khóa bị thiếu khỏi bảng dữ kiện, loại bỏ hiệu quả các mẫu âm tính khỏi tập dữ liệu. Sau đó, chỉ các khóa có trong Bộ lọc Bloom ban đầu, cùng với các kết quả dương tính giả, mới được chuyển tiếp đến mô hình ML, thường được gọi là “nhà tiên tri đã học”. Cách tiếp cận này mang lại một tập dữ liệu huấn luyện cân bằng tốt cho nhà tiên tri đã học, khắc phục vấn đề sai lệch một cách hiệu quả.

Thử thách thứ hai tập trung vào kiến trúc mô hình và các tính năng đào tạo. Không giống như vấn đề kinh điển về URL lừa đảo [1], các khóa tham gia của chúng tôi (trong hầu hết các trường hợp là giá trị nhận dạng duy nhất cho người dùng/trải nghiệm) vốn không mang tính thông tin. Điều này khiến chúng tôi khám phá các thuộc tính thứ nguyên dưới dạng các tính năng mô hình tiềm năng có thể giúp dự đoán liệu một thực thể thứ nguyên có xuất hiện trong bảng dữ kiện hay không. Ví dụ: hãy tưởng tượng một bảng dữ kiện chứa thông tin phiên của người dùng để trải nghiệm bằng một ngôn ngữ cụ thể. Vị trí địa lý hoặc thuộc tính ưu tiên ngôn ngữ của thứ nguyên người dùng sẽ là những chỉ báo tốt về việc một người dùng cá nhân có hiện diện trong bảng dữ kiện hay không.
Thử thách thứ ba—độ trễ suy luận—cần có các mô hình vừa giảm thiểu kết quả âm tính giả vừa cung cấp phản hồi nhanh chóng. Mô hình cây được tăng cường độ dốc là lựa chọn tối ưu cho các số liệu chính này và chúng tôi đã cắt bớt bộ tính năng của nó để cân bằng độ chính xác và tốc độ.
Truy vấn tham gia được cập nhật của chúng tôi bằng cách sử dụng Bộ lọc Bloom đã học như dưới đây:

Kết quả
Dưới đây là kết quả thử nghiệm của chúng tôi với các bộ lọc Learned Bloom trong hồ dữ liệu của chúng tôi. Chúng tôi đã tích hợp chúng vào năm khối lượng công việc sản xuất, mỗi khối lượng công việc đó sở hữu các đặc điểm dữ liệu khác nhau. Phần tốn kém nhất về mặt tính toán của những khối lượng công việc này là sự kết hợp giữa bảng sự kiện và bảng thứ nguyên. Không gian khóa của các bảng sự kiện chiếm khoảng 30% của bảng chiều. Để bắt đầu, chúng tôi thảo luận về cách Bộ lọc Bloom đã học vượt trội hơn Bộ lọc Bloom truyền thống về kích thước đối tượng được tuần tự hóa cuối cùng. Tiếp theo, chúng tôi hiển thị những cải tiến về hiệu suất mà chúng tôi quan sát được bằng cách tích hợp Bộ lọc Bloom đã học vào quy trình xử lý khối lượng công việc của chúng tôi.
So sánh kích thước bộ lọc Bloom đã học
Như được hiển thị bên dưới, khi xem xét tỷ lệ dương tính giả nhất định, hai biến thể của Bộ lọc Bloom đã học sẽ cải thiện tổng kích thước đối tượng từ 17-42% khi so sánh với Bộ lọc Bloom truyền thống.
Ngoài ra, bằng cách sử dụng một tập hợp con các tính năng nhỏ hơn trong mô hình dựa trên cây được tăng cường độ dốc, chúng tôi chỉ mất một tỷ lệ nhỏ tối ưu hóa trong khi thực hiện suy luận nhanh hơn.

Kết quả sử dụng bộ lọc Bloom đã học
Trong phần này, chúng tôi so sánh hiệu suất của các phép nối dựa trên Bộ lọc Bloom với hiệu suất của các phép nối thông thường trên một số số liệu.
Bảng bên dưới so sánh hiệu suất của khối lượng công việc có và không sử dụng Bộ lọc Bloom đã học. Bộ lọc Bloom đã học với tổng xác suất dương tính giả là 1% thể hiện sự so sánh bên dưới trong khi vẫn duy trì cùng một cấu hình cụm cho cả hai loại kết nối.

Đầu tiên, chúng tôi nhận thấy rằng việc triển khai Bloom Filter vượt trội hơn so với phép nối thông thường tới 60% về số giờ sử dụng CPU. Chúng tôi nhận thấy mức sử dụng CPU của bước quét đối với phương pháp Bộ lọc Bloom đã học đã tăng lên do tính toán bổ sung dành cho việc đánh giá Bộ lọc Bloom. Tuy nhiên, quá trình lọc trước được thực hiện ở bước này đã giảm kích thước dữ liệu bị xáo trộn, giúp giảm mức sử dụng CPU của các bước xuôi dòng, do đó giảm tổng số giờ sử dụng CPU.
Thứ hai, Bộ lọc Bloom đã học có tổng kích thước dữ liệu ít hơn khoảng 80% và tổng số byte xáo trộn được ghi ít hơn khoảng 80% so với phép nối thông thường. Điều này dẫn đến hiệu suất tham gia ổn định hơn như được thảo luận dưới đây.
Chúng tôi cũng nhận thấy mức sử dụng tài nguyên đã giảm trong các khối lượng công việc sản xuất khác đang được thử nghiệm. Trong khoảng thời gian hai tuần trên tất cả năm khối lượng công việc, phương pháp tiếp cận Bộ lọc Bloom đã học đã tạo ra mức trung bình tiết kiệm chi phí hàng ngày of 25%, cũng tính đến việc đào tạo mô hình và tạo chỉ mục.
Do lượng dữ liệu được xáo trộn trong khi thực hiện liên kết giảm đi, chúng tôi có thể giảm đáng kể chi phí vận hành của quy trình phân tích đồng thời làm cho nó ổn định hơn. Biểu đồ sau đây cho thấy sự thay đổi (sử dụng hệ số biến đổi) trong thời lượng chạy (tường) clock time) cho khối lượng công việc tham gia thông thường và khối lượng công việc dựa trên Bộ lọc Bloom đã học trong khoảng thời gian hai tuần cho năm khối lượng công việc mà chúng tôi đã thử nghiệm. Quá trình chạy bằng Bộ lọc Bloom đã học ổn định hơn—thời gian nhất quán hơn—điều này mở ra khả năng chuyển chúng sang các tài nguyên điện toán tạm thời không đáng tin cậy rẻ hơn.

dự án
[1] T. Kraska, A. Beutel, EH Chi, J. Dean và N. Polyzotis. Trường hợp về cấu trúc chỉ mục đã học. https://arxiv.org/abs/1712.01208, 2017.
[2] M. Mitzenmacher. Tối ưu hóa bộ lọc Bloom đã học bằng cách kẹp.
https://arxiv.org/abs/1803.01474, 2018.
¹Tính đến 3 tháng kết thúc vào ngày 30 tháng 2023 năm XNUMX
²Tính đến 3 tháng kết thúc vào ngày 30 tháng 2023 năm XNUMX
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://blog.roblox.com/2023/11/roblox-reduces-spark-join-query-costs-machine-learning-optimized-bloom-filters/
- :là
- :không phải
- $ LÊN
- 1
- 14
- 2017
- 2018
- 30
- 65
- a
- Có khả năng
- Giới thiệu
- vắng mặt
- truy cập
- Trợ Lý Giám Đốc
- đạt được
- ngang qua
- Ngoài ra
- thêm vào
- địa chỉ
- giải quyết
- Thêm
- con nuôi
- Tất cả
- dọc theo
- Ngoài ra
- số lượng
- an
- phân tích
- và
- phương pháp tiếp cận
- khoảng
- kiến trúc
- LÀ
- AS
- At
- thuộc tính
- Trung bình cộng
- sao lưu
- Cân đối
- dựa
- BE
- bởi vì
- trước
- bắt đầu
- được
- phía dưới
- Lợi ích
- giữa
- thiên vị
- có thành kiến
- Tỷ
- Blog
- Hoa
- Thúc đẩy mạnh mẽ
- cả hai
- nhưng
- by
- CAN
- trường hợp
- trường hợp
- trung tâm
- thách thức
- đặc điểm
- Biểu đồ
- rẻ hơn
- kiểm tra
- sự lựa chọn
- cổ điển
- phân loại
- Đồng hồ
- cụm
- so sánh
- so
- sự so sánh
- tính toán
- Tính
- máy tính
- Cấu hình
- xem xét
- thích hợp
- tiêu thụ
- chứa
- thông thường
- Phí Tổn
- Chi phí
- CPU
- tạo
- dữ liệu
- Hồ dữ liệu
- ngày
- chứng minh
- chứng minh
- triển khai
- mong muốn
- khác nhau
- kích thước
- thảo luận
- thảo luận
- khác biệt
- phân phối
- phân phối máy tính
- phân phối
- làm
- thực hiện
- điều khiển
- hai
- suốt trong
- e
- mỗi
- hiệu quả
- hiệu quả
- hiệu quả
- loại bỏ
- ôm
- kết thúc
- thuê
- Nâng cao
- tăng cường
- Làm giàu
- Toàn bộ
- thực thể
- thực thể
- Môi trường
- thành lập
- đánh giá
- cuối cùng
- ví dụ
- thực hiện
- đắt tiền
- Kinh nghiệm
- thí nghiệm
- khám phá
- Khám phá
- phải đối mặt
- tạo điều kiện
- thực tế
- sai
- nhanh hơn
- Đặc tính
- Tính năng
- vài
- lọc
- bộ lọc
- cuối cùng
- năm
- sau
- tiếp theo
- Dấu chân
- Trong
- tìm thấy
- từ
- tạo ra
- tạo
- Địa lý
- được
- tốt
- Khai thác
- Có
- giúp đỡ
- đã giúp
- cao
- Đánh
- GIỜ LÀM VIỆC
- Độ đáng tin của
- Tuy nhiên
- HTTPS
- định danh
- if
- minh họa
- hình ảnh
- thực hiện
- nâng cao
- cải thiện
- cải tiến
- cải thiện
- in
- bao gồm
- Tăng lên
- tăng
- chỉ số
- chỉ
- Các chỉ số
- hệ thống riêng biệt,
- thông tin
- thông tin
- vốn có
- ban đầu
- sự đổi mới
- tích hợp
- Tích hợp
- Tích hợp
- tương tác
- trong
- Giới thiệu
- vấn đề
- các vấn đề
- IT
- ITS
- tham gia
- gia nhập
- tham gia
- Tham gia
- tháng sáu
- Key
- phím
- Nhãn
- Thiếu sót
- hồ
- Ngôn ngữ
- Dẫn
- học
- học tập
- Led
- ít
- tận dụng
- tải
- địa điểm thư viện nào
- tìm kiếm
- thua
- Thấp
- máy
- học máy
- duy trì
- Đa số
- Làm
- max-width
- nghĩa là
- Bộ nhớ
- Metrics
- triệu
- hàng triệu
- mất tích
- ML
- kiểu mẫu
- mô hình
- tháng
- chi tiết
- hầu hết
- di chuyển
- nhiều
- cần
- tiêu cực
- âm
- tiếp theo
- nút
- con số
- vật
- quan sát
- of
- cung cấp
- thường
- on
- có thể
- mở ra
- hoạt động
- hoạt động
- Hoạt động
- tối ưu
- tối ưu hóa
- Tối ưu hóa
- tối ưu hóa
- tối ưu hóa
- or
- oracle
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- vượt trội
- kết thúc
- khắc phục
- một phần
- riêng
- mỗi
- tỷ lệ phần trăm
- hiệu suất
- biểu diễn
- thời gian
- Lừa đảo
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- tích cực
- khả năng
- tiềm năng
- Độ chính xác
- dự đoán
- dự đoán
- sự hiện diện
- trình bày
- xác suất
- Vấn đề
- quá trình
- Quy trình
- xử lý
- Sản lượng
- cung cấp
- mục đích
- truy vấn
- nhanh
- Tỷ lệ
- Giá
- tái cân bằng
- giảm
- Giảm
- làm giảm
- giảm
- gọi
- đều đặn
- loại bỏ
- đại diện
- cần phải
- tài nguyên
- nguồn lực chuyên sâu
- Thông tin
- phản ứng
- kết quả
- dẫn
- Kết quả
- ROBLOX
- chạy
- chạy
- tương tự
- thấy
- quét
- Thứ hai
- Phần
- Phiên
- định
- một số
- hiển thị
- thể hiện
- Chương trình
- Shuffle
- đáng kể
- Kích thước máy
- nhỏ
- nhỏ hơn
- So
- giải pháp
- Không gian
- Spark
- tốc độ
- tiêu
- Tính ổn định
- ổn định
- thân cây
- Bước
- Các bước
- cấu trúc
- Sau đó
- đáng kể
- như vậy
- hệ thống
- T
- bàn
- giải quyết
- về
- hơn
- việc này
- Sản phẩm
- Them
- Kia là
- họ
- Thứ ba
- điều này
- Như vậy
- thời gian
- đến
- Tổng số:
- truyền thống
- Hội thảo
- Chuyển đổi
- cây
- hai
- loại
- Dưới
- độc đáo
- không giống
- cập nhật
- Cập nhật
- us
- Sử dụng
- sử dụng
- đã sử dụng
- người sử dang
- Người sử dụng
- sử dụng
- Các giá trị
- Tường
- là
- Đường..
- we
- tuần
- TỐT
- là
- khi nào
- liệu
- cái nào
- trong khi
- Wikipedia
- với
- không có
- Công việc
- công nhân
- sẽ
- viết
- zephyrnet