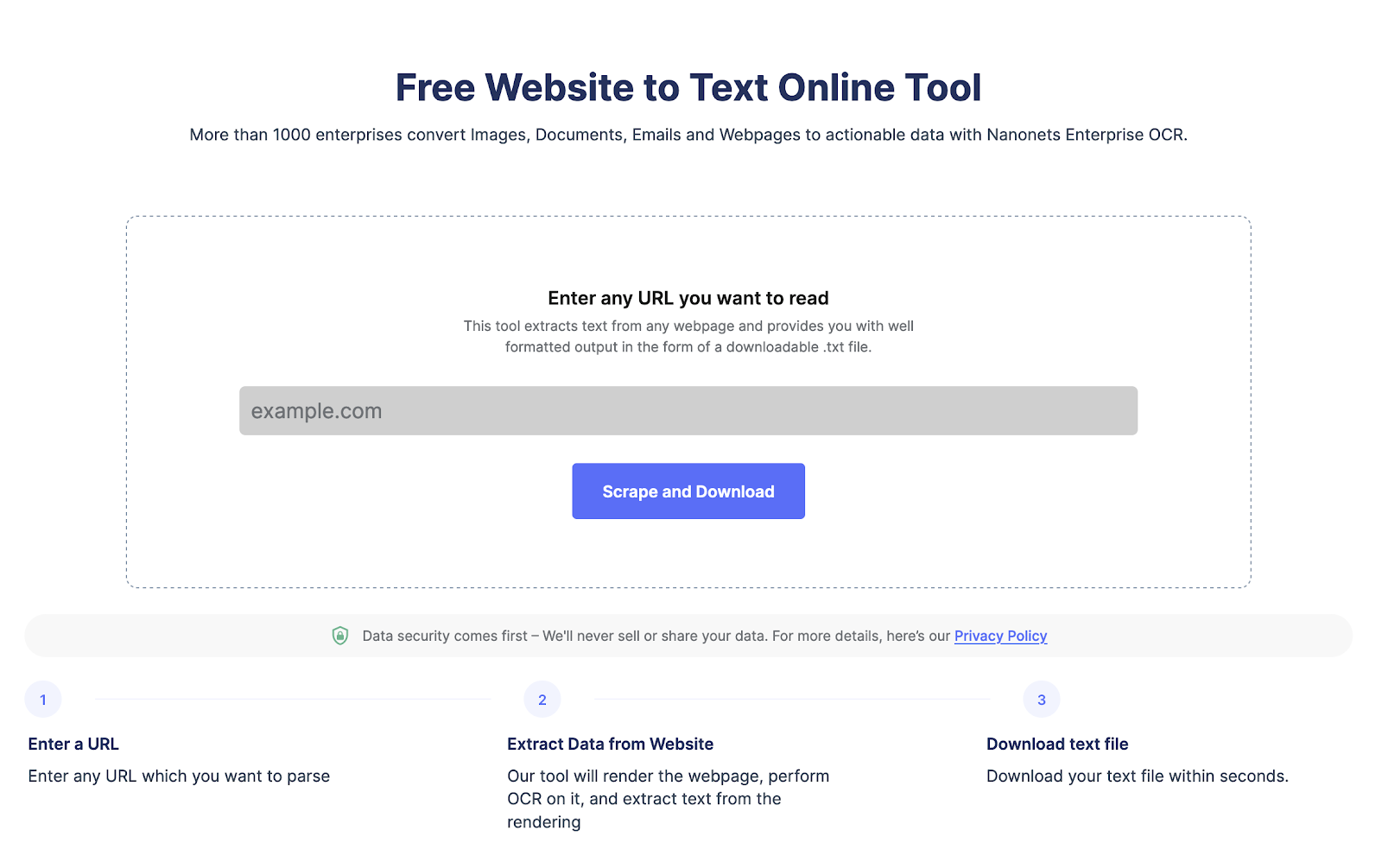
Tìm cách trích xuất dữ liệu từ một trang web?
Chuyển sang Nanonet trang web cạp, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Selenium Web Cạo là gì?
Quét web là quá trình trích xuất dữ liệu từ các trang web. Đó là một kỹ thuật mạnh mẽ cách mạng hóa việc thu thập và phân tích dữ liệu. Với lượng dữ liệu trực tuyến khổng lồ, việc quét web đã trở thành một công cụ thiết yếu cho các doanh nghiệp và cá nhân.
Selenium là một công cụ phát triển web nguồn mở được sử dụng để tự động hóa các chức năng duyệt web. Nó được phát triển vào năm 2004 và chủ yếu được sử dụng để tự động kiểm tra các trang web và ứng dụng trên nhiều trình duyệt khác nhau, nhưng giờ đây nó đã trở thành một công cụ phổ biến để quét web. Selenium có thể được sử dụng với nhiều ngôn ngữ lập trình, bao gồm Python, Java và C#. Nó cung cấp các API mạnh mẽ để tương tác với trang web, bao gồm điều hướng, nhấp, nhập và cuộn.
Quét web Selenium đề cập đến việc sử dụng công cụ tự động hóa trình duyệt Selenium với Python để trích xuất dữ liệu từ các trang web. Selenium cho phép các nhà phát triển điều khiển trình duyệt web theo chương trình, nghĩa là họ có thể tương tác với các trang web như thể họ là người dùng.
Tại sao nên sử dụng Selenium và Python để quét web?
Python là ngôn ngữ lập trình phổ biến để quét web vì nó có nhiều thư viện và khung giúp dễ dàng trích xuất dữ liệu từ các trang web.
Sử dụng Python và Selenium để quét web mang lại một số lợi thế so với các kỹ thuật quét web khác:
- Trang web động: Các trang web động được tạo bằng JavaScript hoặc các ngôn ngữ kịch bản khác. Các trang này thường chứa các thành phần hiển thị sau khi trang được tải đầy đủ hoặc khi người dùng tương tác với chúng. Selenium có thể tương tác với các phần tử này, làm cho nó trở thành một công cụ mạnh mẽ để thu thập dữ liệu từ các trang web động.
- Tương tác của người dùng: Selenium có thể mô phỏng các tương tác của người dùng như nhấp chuột, gửi biểu mẫu và cuộn. Điều này cho phép bạn loại bỏ các trang web yêu cầu đầu vào của người dùng, chẳng hạn như biểu mẫu đăng nhập.
- Gỡ lỗi: Selenium có thể được chạy trong chế độ gỡ lỗi, cho phép bạn thực hiện từng bước trong quy trình cạo và xem công cụ cạo đang làm gì ở mỗi bước. Điều này rất hữu ích để khắc phục sự cố khi xảy ra sự cố.
Điều kiện tiên quyết để quét web với Selenium:
Python 3 được cài đặt trên hệ thống của bạn.
Đã cài đặt thư viện Selenium. Bạn có thể cài đặt nó bằng pip bằng lệnh sau:
pip install SeleniumĐã cài đặt WebDriver.
WebDriver là một tệp thực thi riêng biệt mà Selenium sử dụng để kiểm soát trình duyệt. Đây là các liên kết tôi tìm thấy để tải xuống WebDriver cho các trình duyệt phổ biến nhất:
Ngoài ra, và đây là cách dễ nhất, bạn cũng có thể cài đặt WebDriver bằng trình quản lý gói như trình quản lý trình điều khiển web. Thao tác này sẽ tự động tải xuống và cài đặt WebDriver thích hợp cho bạn. Để cài đặt trình quản lý trình điều khiển web, bạn có thể sử dụng lệnh sau:
pip install webdriver-managerTrích xuất toàn bộ văn bản từ trang web trong vài giây!
Chuyển sang Nanonet trang web cạp, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Hướng dẫn từng bước để quét web Selenium
Bước 1: Cài đặt và nhập khẩu
Trước khi bắt đầu, chúng tôi đảm bảo rằng chúng tôi đã cài đặt Selenium và trình điều khiển thích hợp. Chúng tôi sẽ sử dụng trình điều khiển Edge trong ví dụ này.
from selenium import webdriver
from Selenium.webdriver.common.keys import Keys
from Selenium.webdriver.common.by import ByBước 2: Cài đặt và truy cập WebDriver
Chúng ta có thể tạo một phiên bản mới của trình điều khiển Edge bằng cách chạy đoạn mã sau:
driver = webdriver.Edge()Bước 3: Truy cập trang web qua Python
Tiếp theo, chúng ta cần truy cập trang web của công cụ tìm kiếm. Trong trường hợp này, chúng tôi sẽ sử dụng Bing.
driver.get("https://www.bing.com")Bước 4: Xác định vị trí thông tin cụ thể mà bạn đang thu thập
Chúng tôi muốn trích xuất số lượng kết quả tìm kiếm cho một tên cụ thể. Chúng ta có thể làm điều này bằng cách định vị phần tử HTML chứa số lượng kết quả tìm kiếm
results = driver.find_elements(By.XPATH, "//*[@id='b_tween']/span")Bước 5: Làm cùng nhau
Bây giờ chúng ta đã có tất cả các phần, chúng ta có thể kết hợp chúng để trích xuất kết quả tìm kiếm cho một tên cụ thể.
try:
search_box = driver.find_element(By.NAME, "q")
search_box.clear()
search_box.send_keys("John Doe") # enter your name in the search box
search_box.submit() # submit the search
results = driver.find_elements(By.XPATH, "//*[@id='b_tween']/span")
for result in results:
text = result.text.split()[1] # extract the number of results
print(text)
# save it to a file
with open("results.txt", "w") as f:
f.write(text)
except Exception as e:
print(f"An error occurred: {e}")Bước 6: Lưu trữ dữ liệu
Cuối cùng, chúng ta có thể lưu trữ dữ liệu được trích xuất trong một tệp văn bản.
với open(“results.txt”, “w”) là f:
f.write(text)Sử dụng proxy với Selenium Wire
Selenium Wire là một thư viện mở rộng chức năng của Selenium bằng cách cho phép bạn kiểm tra và sửa đổi các yêu cầu và phản hồi HTTP. Ví dụ: Nó cũng có thể được sử dụng để định cấu hình proxy cho Selenium WebDriver của bạn một cách dễ dàng
Cài đặt dây Selenium
pip install selenium-wireThiết lập proxy
from selenium import webdriver
from Selenium.webdriver.chrome.options import Options
from seleniumwire import webdriver as wiredriver
PROXY_HOST = 'your.proxy.host'
PROXY_PORT = 'your_proxy_port'
chrome_options = Options()
chrome_options.add_argument('--proxy-server=http://{}:{}'.format(PROXY_HOST, PROXY_PORT))
driver = wiredriver.Chrome(options=chrome_options)Sử dụng Selenium Wire để kiểm tra và sửa đổi các yêu cầu.
for request in driver.requests:
if request.response:
print(request.url, request.response.status_code, request.response.headers['Content-Type'])Trong đoạn mã trên, chúng tôi lặp lại tất cả các yêu cầu do WebDriver thực hiện trong phiên quét web. Đối với mỗi yêu cầu, chúng tôi kiểm tra xem có nhận được phản hồi hay không và in URL, mã trạng thái và loại nội dung của phản hồi
Sử dụng Selenium để trích xuất tất cả các tiêu đề từ một trang web
Đây là một mã Python mẫu sử dụng Selenium để cạo tất cả các tiêu đề của trang web:
from selenium import webdriver
# Initialize the webdriver
driver = webdriver.Chrome()
# Navigate to the webpage
driver.get("https://www.example.com")
# Find all the title elements on the page
title_elements = driver.find_elements_by_tag_name("title")
# Extract the text from each title element
titles = [title.text for title in title_elements]
# Print the list of titles
print(titles)
# Close the webdriver
driver.quit()Trong ví dụ này, trước tiên chúng tôi nhập mô-đun trình điều khiển web từ Selenium, sau đó khởi chạy phiên bản trình điều khiển web Chrome mới. Chúng tôi điều hướng đến trang web mà chúng tôi muốn cạo, sau đó sử dụng phương pháp find_elements_by_tag_name để tìm tất cả các thành phần tiêu đề trên trang.
Sau đó, chúng tôi sử dụng khả năng hiểu danh sách để trích xuất văn bản từ từng thành phần tiêu đề và lưu trữ danh sách tiêu đề kết quả trong một biến có tên là tiêu đề. Cuối cùng, chúng tôi in danh sách tiêu đề và đóng phiên bản trình điều khiển web.
Lưu ý rằng bạn cần cài đặt gói trình điều khiển web Selenium và Chrome trong môi trường Python để mã này hoạt động. Bạn có thể cài đặt chúng bằng pip, như vậy:
pip install selenium chromedriver-binaryNgoài ra, hãy đảm bảo cập nhật URL trong trình điều khiển. lấy một phương thức để trỏ đến trang web bạn muốn cạo.
Kết luận
Tóm lại, quét web bằng Selenium là một công cụ mạnh mẽ để trích xuất dữ liệu từ các trang web. Nó cho phép bạn tự động hóa quá trình thu thập dữ liệu và có thể giúp bạn tiết kiệm đáng kể thời gian và công sức. Sử dụng Selenium, bạn có thể tương tác với các trang web giống như người dùng và trích xuất dữ liệu bạn cần hiệu quả hơn.
Ngoài ra, bạn có thể sử dụng các công cụ không có mã như Nanonets' trang web scraper công cụ để dễ dàng trích xuất tất cả các phần tử văn bản từ HTML. Nó hoàn toàn miễn phí để sử dụng.
Trích xuất văn bản từ bất kỳ trang web nào chỉ bằng một cú nhấp chuột. Chuyển sang Nanonet trang web cạp, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Hỏi đáp về:
Selenium có tốt hơn BeautifulSoup không?
Selenium và BeautifulSoup là những công cụ phục vụ các mục đích khác nhau trong việc quét web. Mặc dù Selenium chủ yếu được sử dụng để tự động hóa các trình duyệt web, nhưng BeautifulSoup là một thư viện Python để phân tích cú pháp các tài liệu HTML và XML.
Selenium tốt hơn BeautifulSoup khi nói đến việc quét các trang web động. Các trang web động được tạo bằng JavaScript hoặc các ngôn ngữ kịch bản khác. Các trang này thường chứa các thành phần không hiển thị cho đến khi trang được tải đầy đủ hoặc cho đến khi người dùng tương tác với chúng. Selenium có thể tương tác với các phần tử này, làm cho nó trở thành một công cụ mạnh mẽ để thu thập dữ liệu từ các trang web động.
Mặt khác, BeautifulSoup tốt hơn Selenium khi phân tích các tài liệu HTML và XML. BeautifulSoup cung cấp một giao diện đơn giản và trực quan để phân tích cú pháp các tài liệu HTML và XML cũng như trích xuất dữ liệu bạn cần. Nó là một thư viện nhẹ không yêu cầu trình duyệt web, làm cho nó nhanh hơn và hiệu quả hơn Selenium trong một số trường hợp.
Tóm lại, Selenium có tốt hơn BeautifulSoup hay không còn tùy thuộc vào tác vụ. Nếu bạn cần cạo dữ liệu từ các trang web động, thì Selenium là lựa chọn tốt hơn. Tuy nhiên, nếu bạn cần phân tích các tài liệu HTML và XML thì BeautifulSoup là lựa chọn tốt hơn.
Tôi nên sử dụng Selenium hay Scrapy?
Selenium chủ yếu được sử dụng để tự động hóa trình duyệt web và phù hợp nhất để thu thập dữ liệu từ các trang web động. Nếu bạn cần tương tác với các trang web chứa các phần tử không hiển thị cho đến khi trang được tải đầy đủ hoặc cho đến khi người dùng tương tác với chúng, thì Selenium là lựa chọn tốt hơn. Selenium cũng có thể tương tác với các trang web yêu cầu xác thực hoặc các biểu mẫu nhập liệu khác của người dùng.
Mặt khác, Scrapy là một khung quét web dựa trên Python được thiết kế để loại bỏ dữ liệu từ các trang web có cấu trúc. Nó là một công cụ mạnh mẽ và linh hoạt cung cấp nhiều tính năng để thu thập dữ liệu và quét các trang web. Nó có thể được sử dụng để cạo dữ liệu từ nhiều trang hoặc trang web và xử lý các tác vụ cạo phức tạp như theo liên kết và xử lý phân trang. Scrapy cũng hiệu quả hơn Selenium về bộ nhớ và tài nguyên xử lý, khiến nó trở thành lựa chọn tốt hơn cho các dự án quét web quy mô lớn.
Việc bạn nên sử dụng Selenium hay Scrapy tùy thuộc vào các yêu cầu cụ thể của dự án quét web của bạn. Nếu bạn cần cạo dữ liệu từ các trang web động hoặc tương tác với các trang web yêu cầu xác thực hoặc đầu vào của người dùng khác, thì Selenium là lựa chọn tốt hơn. Tuy nhiên, nếu bạn cần cạo dữ liệu từ các trang web có cấu trúc hoặc thực hiện các tác vụ cạo phức tạp, thì Scrapy là lựa chọn tốt hơn.
Ngôn ngữ nào là tốt nhất để quét web?
Python là một trong những ngôn ngữ phổ biến nhất để quét web do tính dễ sử dụng, nhiều thư viện và các khung quét mạnh mẽ như Scrapy, request, beautifulSoup và Selenium. Python cũng dễ học và sử dụng, khiến nó trở thành lựa chọn tuyệt vời cho người mới bắt đầu
Nhiều ngôn ngữ lập trình có thể được sử dụng để quét web, nhưng một số ngôn ngữ phù hợp hơn cho nhiệm vụ này so với các ngôn ngữ khác. Ngôn ngữ tốt nhất để quét web phụ thuộc vào nhiều yếu tố khác nhau, chẳng hạn như mức độ phức tạp của tác vụ, trang web mục tiêu và sở thích cá nhân của bạn.
Các ngôn ngữ khác như R, JavaScript và PHP cũng có thể được sử dụng tùy thuộc vào các yêu cầu cụ thể của dự án quét web của bạn.
Tại sao Selenium lại quan trọng trong việc quét web?
Selenium là một công cụ quan trọng trong việc quét web vì nhiều lý do:
Quét các trang web động: Nhiều trang web ngày nay sử dụng nội dung động và tương tác của người dùng để hiển thị dữ liệu. Điều này có nghĩa là rất nhiều nội dung trên trang web được tải thông qua JavaScript hoặc AJAX. Selenium rất hiệu quả trong việc quét các trang web động này vì nó có thể tương tác với các phần tử trên trang và mô phỏng các tương tác của người dùng như cuộn và nhấp. Điều này giúp việc thu thập dữ liệu từ các trang web phụ thuộc nhiều vào nội dung động trở nên dễ dàng hơn. Nó phù hợp nhất để xử lý cookie và phiên, kiểm tra tự động, khả năng tương thích giữa các trình duyệt và khả năng mở rộng:
Bạn có thể sử dụng Selenium và BeautifulSoup cùng nhau không?
Có, Bạn có thể sử dụng chúng cùng nhau. Selenium chủ yếu tương tác với các trang web và mô phỏng các tương tác của người dùng như nhấp, cuộn và điền vào biểu mẫu. Mặt khác, BeautifulSoup là một thư viện Python được sử dụng để phân tích cú pháp các tài liệu HTML và XML và trích xuất dữ liệu từ chúng. Bằng cách kết hợp Selenium và BeautifulSoup, bạn có thể tạo một công cụ quét web mạnh mẽ để tương tác với các trang web và trích xuất dữ liệu từ chúng. Selenium có thể xử lý nội dung động và tương tác của người dùng, trong khi BeautifulSoup có thể phân tích cú pháp HTML và trích xuất dữ liệu từ nguồn trang.
Tuy nhiên, điều đáng chú ý là việc sử dụng cả hai công cụ cùng nhau có thể tốn nhiều tài nguyên hơn và chậm hơn so với chỉ một công cụ. Vì vậy, điều cần thiết là đánh giá các yêu cầu của dự án quét web của bạn và chọn các công cụ phù hợp cho công việc.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://nanonets.com/blog/web-scraping-with-selenium/
- :là
- $ LÊN
- 1
- 10
- 7
- a
- ở trên
- truy cập
- ngang qua
- lợi thế
- Tất cả
- Cho phép
- cho phép
- phân tích
- và
- API
- thích hợp
- ứng dụng
- LÀ
- AS
- At
- Xác thực
- tự động hóa
- Tự động
- tự động
- tự động hóa
- Tự động hóa
- BE
- bởi vì
- trở nên
- bắt đầu
- BEST
- Hơn
- Bing
- Hộp
- trình duyệt
- trình duyệt
- Duyệt
- các doanh nghiệp
- by
- gọi là
- CAN
- trường hợp
- trường hợp
- kiểm tra
- sự lựa chọn
- Chọn
- cơ rôm
- Nhấp chuột
- Đóng
- mã
- Thu
- bộ sưu tập
- COM
- kết hợp
- kết hợp
- Chung
- khả năng tương thích
- hoàn thành
- hoàn toàn
- phức tạp
- phức tạp
- phần kết luận
- chứa
- nội dung
- điều khiển
- bánh quy
- tạo
- tạo ra
- Qua trình duyệt
- dữ liệu
- xử lý
- phụ thuộc
- Tùy
- phụ thuộc
- thiết kế
- phát triển
- phát triển
- Phát triển
- khác nhau
- Giao diện
- tài liệu
- DOE
- làm
- tải về
- trình điều khiển
- suốt trong
- năng động
- e
- mỗi
- dễ sử dụng
- dễ dàng hơn
- dễ nhất
- dễ dàng
- Cạnh
- Hiệu quả
- hiệu quả
- hiệu quả
- nỗ lực
- thành phần
- các yếu tố
- Động cơ
- đăng ký hạng mục thi
- Môi trường
- lôi
- thiết yếu
- Ether (ETH)
- đánh giá
- ví dụ
- Trừ
- ngoại lệ
- trích xuất
- trích xuất dữ liệu
- các yếu tố
- nhanh hơn
- Tính năng
- Tập tin
- Cuối cùng
- Tìm kiếm
- Tên
- linh hoạt
- tiếp theo
- Trong
- hình thức
- các hình thức
- tìm thấy
- Khung
- khung
- Miễn phí
- từ
- đầy đủ
- chức năng
- chức năng
- được
- Go
- tuyệt vời
- hướng dẫn
- tay
- xử lý
- Xử lý
- Có
- cái đầu
- nặng nề
- tại đây
- chủ nhà
- Tuy nhiên
- HTML
- http
- HTTPS
- Nhân loại
- i
- nhập khẩu
- quan trọng
- in
- Bao gồm
- các cá nhân
- thông tin
- đầu vào
- cài đặt, dựng lên
- ví dụ
- tương tác
- tương tác
- tương tác
- tương tác
- Giao thức
- trực quan
- IT
- ITS
- Java
- JavaScript
- Việc làm
- nhà vệ sinh
- JOHN DOE
- chỉ một
- phím
- Ngôn ngữ
- Ngôn ngữ
- lớn
- quy mô lớn
- LEARN
- thư viện
- Thư viện
- trọng lượng nhẹ
- Lượt thích
- liên kết
- Danh sách
- Rất nhiều
- thực hiện
- làm cho
- LÀM CHO
- Làm
- giám đốc
- nhiều
- có nghĩa là
- có nghĩa
- Bộ nhớ
- phương pháp
- Chế độ
- sửa đổi
- mô-đun
- chi tiết
- hiệu quả hơn
- hầu hết
- Phổ biến nhất
- nhiều
- tên
- Điều hướng
- điều hướng
- Cần
- Mới
- con số
- xảy ra
- of
- Cung cấp
- on
- ONE
- Trực tuyến
- mã nguồn mở
- Các lựa chọn
- Nền tảng khác
- Khác
- gói
- gói
- trang
- Sự đánh số trang
- riêng
- thực hiện
- riêng
- PHP
- miếng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- Phổ biến
- mạnh mẽ
- chủ yếu
- In
- quá trình
- xử lý
- Lập trình
- ngôn ngữ lập trình
- dự án
- dự án
- cung cấp
- Proxy
- mục đích
- Python
- lý do
- nhận
- đề cập
- về
- đều đặn
- yêu cầu
- yêu cầu
- yêu cầu
- Yêu cầu
- nguồn lực chuyên sâu
- Thông tin
- phản ứng
- kết quả
- kết quả
- Kết quả
- cuộc cách mạng
- mạnh mẽ
- chạy
- chạy
- s
- Lưu
- khả năng mở rộng
- cào
- cuộn
- Tìm kiếm
- công cụ tìm kiếm
- lựa chọn
- riêng biệt
- phục vụ
- Phiên
- phiên
- một số
- nên
- có ý nghĩa
- Đơn giản
- So
- một số
- nguồn
- riêng
- Trạng thái
- Bước
- hàng
- cấu trúc
- Đệ trình
- trình
- như vậy
- TÓM TẮT
- hệ thống
- Mục tiêu
- Nhiệm vụ
- nhiệm vụ
- kỹ thuật
- thử nghiệm
- Kiểm tra
- việc này
- Sản phẩm
- Them
- Kia là
- điều
- Thông qua
- thời gian
- Yêu sách
- trò chơi
- đến
- bây giờ
- bên nhau
- công cụ
- công cụ
- Cập nhật
- URL
- sử dụng
- người sử dang
- Người sử dụng
- khác nhau
- Lớn
- thông qua
- có thể nhìn thấy
- W
- Đường..
- web
- trình duyệt web
- Trình duyệt web
- phát triển web
- rút trích nội dung trang web
- Website
- trang web
- Điều gì
- liệu
- cái nào
- trong khi
- sẽ
- Dây điện
- với
- Công việc
- giá trị
- Sai
- XML
- trên màn hình
- zephyrnet