Giả sử bạn muốn quét các trang web của đối thủ cạnh tranh để lấy thông tin trang giá của họ. Bạn sẽ làm gì? Sao chép hoặc nhập dữ liệu theo cách thủ công quá chậm, tốn thời gian và dễ bị lỗi. Bạn có thể tự động hóa nó dễ dàng bằng Python.
Hãy xem cách cạo các trang web bằng python trong hướng dẫn này.
Các thư viện quét web Python khác nhau là gì?
Python phổ biến để quét web do có nhiều thư viện bên thứ ba có thể loại bỏ các cấu trúc HTML phức tạp, phân tích cú pháp văn bản và tương tác với biểu mẫu HTML. Ở đây, chúng tôi đã liệt kê một số thư viện quét web Python hàng đầu.
- urllib3 là một thư viện máy khách HTTP mạnh mẽ dành cho Python. Điều này giúp dễ dàng thực hiện các yêu cầu HTTP theo chương trình. Nó xử lý các tiêu đề HTTP, thử lại, chuyển hướng và các chi tiết cấp thấp khác, làm cho nó trở thành một thư viện tuyệt vời để quét web. Nó cũng hỗ trợ xác minh SSL, tổng hợp kết nối và ủy quyền.
- ĐẹpSúp cho phép bạn phân tích các tài liệu HTML và XML. Bạn có thể dễ dàng điều hướng qua cây tài liệu HTML và trích xuất thẻ, tiêu đề meta, thuộc tính, văn bản và nội dung khác bằng API. BeautifulSoup cũng được biết đến với khả năng xử lý lỗi mạnh mẽ.
- Súp cơ khí tự động hóa sự tương tác giữa trình duyệt web và trang web một cách hiệu quả. Nó cung cấp API cấp cao để quét web mô phỏng hành vi của con người. Với MechanicalSoup, bạn có thể tương tác với các biểu mẫu HTML, nhấp vào các nút và tương tác với các phần tử như một người dùng thực.
- yêu cầu là một thư viện Python đơn giản nhưng mạnh mẽ để thực hiện các yêu cầu HTTP. Nó được thiết kế để dễ sử dụng và trực quan, với API rõ ràng và nhất quán. Với Yêu cầu, bạn có thể dễ dàng gửi các yêu cầu GET và POST, đồng thời xử lý cookie, xác thực và các tính năng HTTP khác. Nó cũng được sử dụng rộng rãi trong việc quét web do tính đơn giản và dễ sử dụng của nó.
- Selenium cho phép bạn tự động hóa các trình duyệt web như Chrome, Firefox và Safari và mô phỏng tương tác của con người với các trang web. Bạn có thể nhấp vào nút, điền vào biểu mẫu, cuộn trang và thực hiện các hành động khác. Nó cũng được sử dụng để thử nghiệm các ứng dụng web và tự động hóa các tác vụ lặp đi lặp lại.
- Gấu trúc cho phép lưu trữ và thao tác dữ liệu ở nhiều định dạng khác nhau, bao gồm cơ sở dữ liệu CSV, Excel, JSON và SQL. Sử dụng Pandas, bạn có thể dễ dàng dọn dẹp, chuyển đổi và phân tích dữ liệu được trích xuất từ các trang web.
Trích xuất văn bản từ bất kỳ trang web nào chỉ bằng một cú nhấp chuột. Đi đến Máy quét trang web Nanonets, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Làm cách nào để lấy dữ liệu từ các trang web bằng python?
Chúng ta hãy xem quy trình từng bước sử dụng Python để thu thập dữ liệu trang web.
Bước 1: Chọn Trang web và URL Trang web
Bước đầu tiên là chọn trang web bạn muốn cạo. Đối với hướng dẫn cụ thể này, hãy cạo https://www.imdb.com/. Chúng tôi sẽ cố gắng trích xuất dữ liệu về những bộ phim được xếp hạng cao nhất trên trang web.
Bước 2: Kiểm tra trang web
Bây giờ bước tiếp theo là hiểu cấu trúc trang web. Hiểu các thuộc tính của các yếu tố mà bạn quan tâm là gì. Nhấp chuột phải vào trang web để chọn “Kiểm tra”. Thao tác này sẽ mở mã HTML. Sử dụng công cụ kiểm tra để xem tên của tất cả các phần tử sẽ sử dụng trong mã.
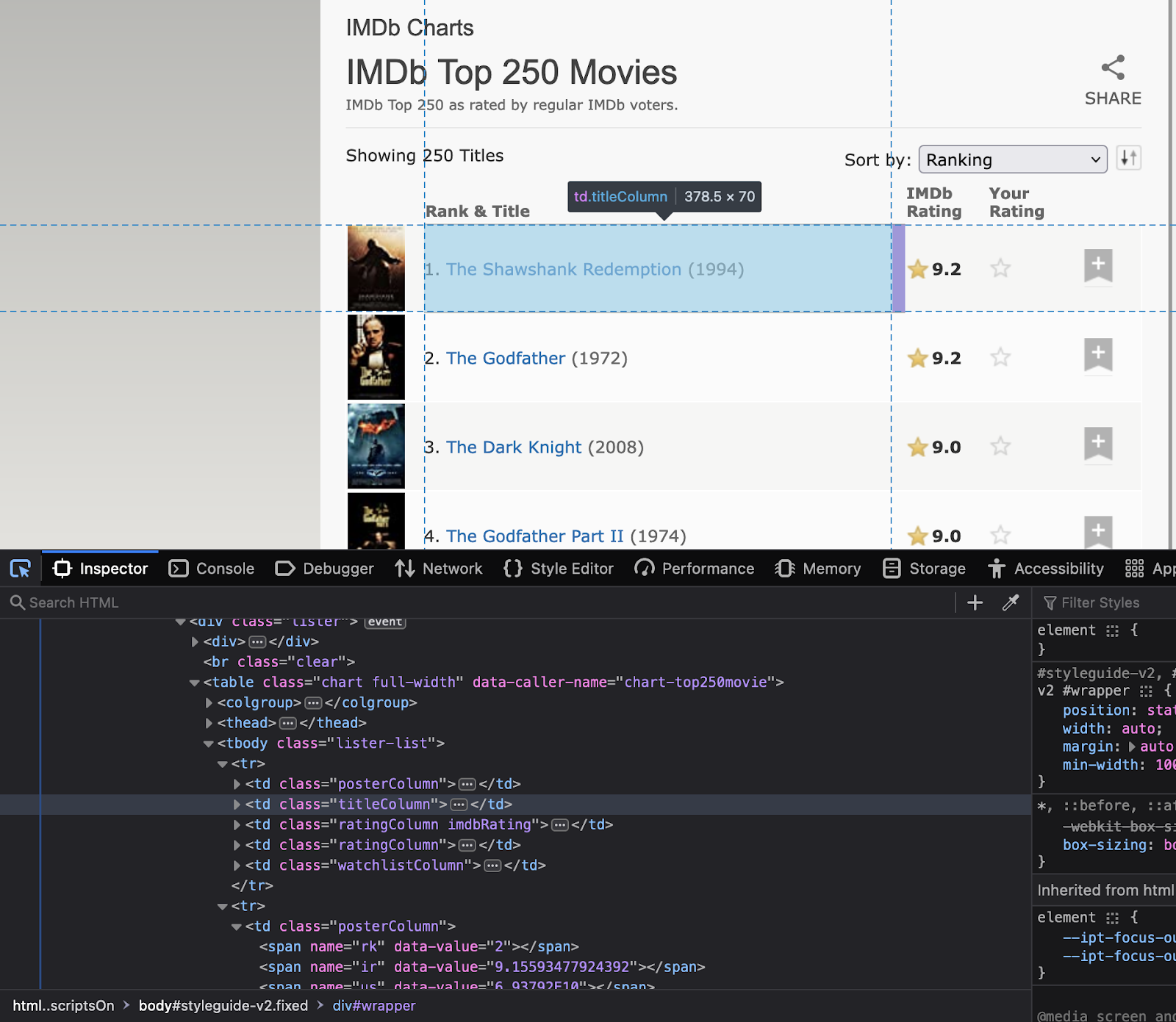
Lưu ý tên lớp và id của các phần tử này vì chúng sẽ được sử dụng trong mã Python.
Bước 3: Cài đặt các thư viện quan trọng
Như đã thảo luận trước đó, Python có một số thư viện quét web. Hôm nay, chúng ta sẽ sử dụng các thư viện sau:
- yêu cầu – để thực hiện các yêu cầu HTTP đến trang web
- ĐẹpSúp – để phân tích cú pháp mã HTML
- gấu trúc – để lưu trữ dữ liệu đã cạo trong khung dữ liệu
- thời gian – để thêm độ trễ giữa các yêu cầu để tránh tràn ngập trang web với các yêu cầu
Cài đặt các thư viện bằng lệnh sau
pip install requests beautifulsoup4 pandas timeBước 4: Viết mã Python
Bây giờ là lúc viết mã python chính. Mã sẽ thực hiện các bước sau:
- Sử dụng yêu cầu để gửi yêu cầu HTTP GET
- Sử dụng BeautifulSoup để phân tích mã HTML
- Trích xuất dữ liệu cần thiết từ mã HTML
- Lưu trữ thông tin trong khung dữ liệu gấu trúc
- Thêm độ trễ giữa các yêu cầu để tránh tràn ngập trang web với các yêu cầu
Đây là mã Python để loại bỏ những bộ phim được xếp hạng cao nhất từ IMDb:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# URL of the website to scrape
url = "https://www.imdb.com/chart/top"
# Send an HTTP GET request to the website
response = requests.get(url)
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the relevant information from the HTML code
movies = []
for row in soup.select('tbody.lister-list tr'):
title = row.find('td', class_='titleColumn').find('a').get_text()
year = row.find('td', class_='titleColumn').find('span', class_='secondaryInfo').get_text()[1:-1]
rating = row.find('td', class_='ratingColumn imdbRating').find('strong').get_text()
movies.append([title, year, rating])
# Store the information in a pandas dataframe
df = pd.DataFrame(movies, columns=['Title', 'Year', 'Rating'])
# Add a delay between requests to avoid overwhelming the website with requests
time.sleep(1)Bước 5: Xuất dữ liệu đã trích xuất
Bây giờ, hãy xuất dữ liệu dưới dạng tệp CSV. Chúng tôi sẽ sử dụng thư viện gấu trúc.
# Export the data to a CSV file
df.to_csv('top-rated-movies.csv', index=False)Bước 6: Xác minh dữ liệu được trích xuất
Mở tệp CSV để xác minh rằng dữ liệu đã được thu thập và lưu trữ thành công.
Chúng tôi hy vọng hướng dẫn này sẽ giúp bạn trích xuất dữ liệu từ các trang web một cách dễ dàng.
Trích xuất văn bản từ bất kỳ trang web nào chỉ bằng một cú nhấp chuột. Đi đến Máy quét trang web Nanonets, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Làm cách nào để phân tích cú pháp văn bản từ trang web?
Bạn có thể dễ dàng phân tích văn bản trang web bằng BeautifulSoup hoặc lxml. Dưới đây là các bước liên quan cùng với mã.
- Chúng tôi sẽ gửi yêu cầu HTTP tới URL và nhận nội dung HTML của trang web.
- Sau khi bạn có cấu trúc HTMl, chúng tôi sẽ sử dụng phương thức find() của BeautifulSoup để định vị một thẻ hoặc thuộc tính HTML cụ thể.
- Và sau đó trích xuất nội dung văn bản với thuộc tính văn bản.
Đây là mã về cách phân tích văn bản từ một trang web bằng BeautifulSoup:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.example.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the text content of the webpage
text = soup.get_text()
print(text)Làm cách nào để cạo các biểu mẫu HTML bằng Python?
Để cạo các biểu mẫu HTML bằng Python, bạn có thể sử dụng thư viện như BeautifulSoup, lxml hoặc cơ giới hóa. Dưới đây là các bước chung:
- Gửi yêu cầu HTTP tới URL của trang web có biểu mẫu bạn muốn cạo. Máy chủ đáp ứng yêu cầu bằng cách trả về nội dung HTML của trang web.
- Khi bạn đã truy cập nội dung HTML, bạn có thể sử dụng trình phân tích cú pháp HTML để định vị biểu mẫu bạn muốn cạo. Ví dụ: bạn có thể sử dụng phương thức find() của BeautifulSoup để định vị thẻ biểu mẫu.
- Khi bạn đã định vị biểu mẫu, bạn có thể trích xuất các trường đầu vào và các giá trị tương ứng của chúng bằng trình phân tích cú pháp HTML. Ví dụ: bạn có thể sử dụng phương thức find_all() của BeautifulSoup để định vị tất cả các thẻ đầu vào trong biểu mẫu, sau đó trích xuất các thuộc tính tên và giá trị của chúng.
- Sau đó, bạn có thể sử dụng dữ liệu này để gửi biểu mẫu hoặc thực hiện xử lý dữ liệu tiếp theo.
Đây là một ví dụ về cách cạo một biểu mẫu HTML bằng cách sử dụng cơ giới hóa:
import mechanize
# Create a mechanize browser object
browser = mechanize.Browser()
# Send an HTTP request to the URL of the webpage with the form you want to scrape
browser.open("https://www.example.com/form")
# Select the form to scrape
browser.select_form(nr=0)
# Extract the input fields and their corresponding values
for control in browser.form.controls:
print(control.name, control.value)
# Submit the form
browser.submit()Trích xuất văn bản từ bất kỳ trang web nào chỉ trong một cú nhấp chuột. Đi tới trình quét trang web Nanonets, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
So sánh tất cả các thư viện cạo web Python
Hãy so sánh tất cả các thư viện quét web python. Tất cả chúng đều có sự hỗ trợ cộng đồng tuyệt vời, nhưng chúng khác nhau về tính dễ sử dụng và các trường hợp sử dụng của chúng, như đã đề cập ở phần đầu của blog.
|
Thư viện |
Dễ sử dụng |
HIỆU QUẢ |
Linh hoạt |
Hỗ trợ cộng đồng |
Cân nhắc pháp lý/đạo đức |
|
ĐẹpSúp |
Dễ dàng |
Trung bình |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
Trị liệu |
Trung bình |
Cao |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
Selenium |
Dễ dàng |
Trung bình |
Cao |
Cao |
Thực hiện theo các thực tiễn tốt nhất |
|
yêu cầu |
Dễ dàng |
Cao |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
PyQuery |
Dễ dàng |
Cao |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
LXML |
Trung bình |
Cao |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
Súp cơ khí |
Dễ dàng |
Trung bình |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
ĐẹpSoup4 |
Dễ dàng |
Trung bình |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
|
PySpider |
Dễ dàng |
Cao |
Cao |
Cao |
Tuân thủ Điều khoản sử dụng |
Kết luận
Python là một lựa chọn tuyệt vời để thu thập dữ liệu trang web trong thời gian thực. Một cách khác là sử dụng tự động công cụ cạo trang web lgiống như Nanonet. Bạn có thể dùng công cụ chuyển trang web thành văn bản miễn phí. Tuy nhiên, nếu bạn cần tự động quét web cho các dự án lớn hơn, bạn có thể liên hệ với Nanonets.
Trích xuất văn bản từ bất kỳ trang web nào chỉ bằng một cú nhấp chuột. Đi tới trình quét trang web Nanonets, Thêm URL và nhấp vào “Scrape” và tải xuống văn bản trang web dưới dạng tệp ngay lập tức. Hãy thử nó cho miễn phí.
Câu Hỏi Thường Gặp
Làm cách nào để sử dụng trình phân tích cú pháp HTML để quét web bằng Python?
Để sử dụng trình phân tích cú pháp HTML để quét web bằng Python, bạn có thể sử dụng thư viện như BeautifulSoup hoặc lxml. Dưới đây là các bước chung:
- Gửi yêu cầu HTTP tới URL của trang web bạn muốn truy cập. Máy chủ đáp ứng yêu cầu bằng cách trả về nội dung HTML của trang web.
- Khi bạn đã truy cập nội dung HTML, bạn có thể sử dụng trình phân tích cú pháp HTML để trích xuất dữ liệu bạn cần. Ví dụ: bạn có thể sử dụng phương thức find() của BeautifulSoup để định vị một thẻ hoặc thuộc tính HTML cụ thể, sau đó trích xuất nội dung văn bản bằng thuộc tính văn bản.
Đây là một ví dụ về cách sử dụng BeautifulSoup để quét web:
mãng xà
yêu cầu nhập khẩu
từ bs4 nhập BeautifulSoup
# Gửi yêu cầu HTTP tới URL của trang web bạn muốn truy cập
phản hồi = request.get(“https://www.example.com”)
# Phân tích cú pháp nội dung HTML bằng BeautifulSoup
súp = BeautifulSoup(response.content, “html.parser”)
# Trích xuất dữ liệu cụ thể từ trang web
tiêu đề = súp.title
in (tiêu đề)
Trong ví dụ này, chúng tôi sử dụng BeautifulSoup để phân tích cú pháp nội dung HTML của trang web và trích xuất tiêu đề của trang bằng thuộc tính tiêu đề.
Tại sao Web Scraping được sử dụng?
Quét web được sử dụng để quét dữ liệu trang web bằng các công cụ hoặc tập lệnh tự động. Nó có thể được sử dụng cho nhiều mục đích
- Trích xuất dữ liệu từ nhiều trang web và tổng hợp dữ liệu để phân tích thêm.
- Bắt nguồn xu hướng bằng cách cạo dữ liệu thời gian thực trên các dấu thời gian khác nhau.
- Theo dõi xu hướng định giá của đối thủ cạnh tranh.
- Tạo khách hàng tiềm năng bằng cách thu thập email từ các trang web.
Web Scraping là gì?
Quét web Tôi đã sử dụng để trích xuất dữ liệu có cấu trúc từ các trang web HTML không có cấu trúc. Quét web liên quan đến việc sử dụng tự động công cụ cạo web hoặc tập lệnh để phân tích các trang web phức tạp.
Quét web có hợp pháp không?
Quét web là hợp pháp khi bạn đang cố phân tích dữ liệu có sẵn công khai trên một trang web. Nói chung, việc quét web cho mục đích sử dụng cá nhân hoặc phi thương mại là hợp pháp. Tuy nhiên, việc cạo dữ liệu được bảo vệ bởi bản quyền hoặc được coi là bí mật hoặc riêng tư có thể dẫn đến các vấn đề pháp lý.
Trong một số trường hợp, việc quét web có thể vi phạm các điều khoản dịch vụ của một trang web. Nhiều trang web bao gồm các điều khoản cấm tự động cạo nội dung của họ. Nếu chủ sở hữu trang web phát hiện ra rằng ai đó đang lấy cắp nội dung của họ, họ có thể thực hiện hành động pháp lý để ngăn chặn hành động đó.
Tại sao Python tốt cho việc quét web?
Python là ngôn ngữ lập trình phổ biến để quét web vì nó mang lại một số lợi thế:
- Python có cú pháp đơn giản, dễ đọc và dễ dàng cho người mới bắt đầu học.
- Python có một cộng đồng lớn các nhà phát triển phát triển các công cụ cho các tác vụ khác nhau như quét web.
- Python có nhiều thư viện quét web như Beautiful Soup và Scrapy.
- Python có thể thực hiện rất nhiều tác vụ như cạo, trích xuất dữ liệu website ra excel, tương tác với biểu mẫu HTML, v.v.
- Python có khả năng mở rộng, khiến nó phù hợp để thu thập khối lượng dữ liệu lớn.
một ví dụ về cạo web là gì?
Quét web đang trích xuất dữ liệu từ các trang web bằng cách sử dụng các tập lệnh hoặc công cụ tự động. Ví dụ: quét web được sử dụng để quét email từ các trang web để tạo khách hàng tiềm năng. Một ví dụ khác về tìm kiếm trang web là trích xuất thông tin về giá của đối thủ cạnh tranh để cải thiện cấu trúc giá của bạn.
Quét web có cần viết mã không?
Quét web chuyển đổi dữ liệu trang web phi cấu trúc thành định dạng có cấu trúc. Ngoài việc sử dụng mã hóa để quét các trang web, bạn có thể sử dụng các công cụ quét web hoàn toàn không có mã mà không yêu cầu mã hóa nào cả.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://nanonets.com/blog/web-scraping-with-python-tutorial/
- :là
- 1
- 11
- 7
- 77
- a
- sự phong phú
- truy cập
- truy cập
- Hoạt động
- hành động
- lợi thế
- Tất cả
- cho phép
- thay thế
- phân tích
- phân tích
- và
- Một
- ngoài
- api
- các ứng dụng
- LÀ
- AS
- At
- thuộc tính
- Xác thực
- tự động hóa
- Tự động
- tự động hóa
- tự động hóa
- có sẵn
- BE
- đẹp
- bởi vì
- Người mới bắt đầu
- BEST
- giữa
- Blog
- trình duyệt
- trình duyệt
- by
- CAN
- trường hợp
- Chọn
- cơ rôm
- tốt nghiệp lớp XNUMX
- Nhấp chuột
- khách hàng
- Đóng
- mã
- Lập trình
- COM
- cộng đồng
- so sánh
- đối thủ
- hoàn toàn
- phức tạp
- phần kết luận
- liên quan
- xem xét
- thích hợp
- liên lạc
- nội dung
- điều khiển
- điều khiển
- bánh quy
- quyền tác giả
- Tương ứng
- tạo
- dữ liệu
- xử lý dữ liệu
- cơ sở dữ liệu
- chậm trễ
- thiết kế
- chi tiết
- phát triển
- phát triển
- khác nhau
- khác nhau
- Khám phá
- thảo luận
- tài liệu
- tài liệu
- tải về
- Sớm hơn
- dễ sử dụng
- dễ dàng
- hiệu quả
- các yếu tố
- lôi
- Ether (ETH)
- ví dụ
- Excel
- tuyệt vời
- xuất khẩu
- trích xuất
- trích xuất dữ liệu
- Tính năng
- Lĩnh vực
- Tập tin
- điền
- Firefox
- Tên
- tiếp theo
- Trong
- hình thức
- định dạng
- các hình thức
- Miễn phí
- từ
- xa hơn
- Tổng Quát
- thế hệ
- được
- tốt
- xử lý
- Xử lý
- Xử lý
- Có
- cái đầu
- tiêu đề
- giúp đỡ
- tại đây
- cấp độ cao
- mong
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- lớn
- Nhân loại
- i
- nhập khẩu
- quan trọng
- nâng cao
- in
- bao gồm
- Bao gồm
- thông tin
- đầu vào
- cài đặt, dựng lên
- Cài đặt
- tương tác
- tương tác
- tương tác
- quan tâm
- trực quan
- tham gia
- các vấn đề
- IT
- ITS
- json
- chỉ một
- nổi tiếng
- Ngôn ngữ
- lớn
- lớn hơn
- dẫn
- Dẫn
- LEARN
- Hợp pháp
- Hành động pháp lý
- Vấn đề pháp lý
- thư viện
- Thư viện
- Lượt thích
- Liệt kê
- nằm
- Xem
- Rất nhiều
- Chủ yếu
- LÀM CHO
- Làm
- thao túng
- thủ công
- nhiều
- đề cập
- Siêu dữ liệu
- phương pháp
- chi tiết
- Phim Điện Ảnh
- nhiều
- tên
- tên
- Điều hướng
- Cần
- tiếp theo
- Phi thương mại
- vật
- of
- Cung cấp
- on
- ONE
- mở
- Tùy chọn
- Nền tảng khác
- chủ sở hữu
- trang
- gấu trúc
- riêng
- thực hiện
- riêng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Phổ biến
- Bài đăng
- mạnh mẽ
- giá
- riêng
- quá trình
- xử lý
- Lập trình
- cấm
- dự án
- bảo vệ
- cung cấp
- công khai
- mục đích
- Python
- giá
- thực
- thời gian thực
- dữ liệu theo thời gian thực
- đều đặn
- có liên quan
- lặp đi lặp lại
- yêu cầu
- yêu cầu
- yêu cầu
- cần phải
- phản ứng
- trở về
- Nhấp chuột phải
- mạnh mẽ
- HÀNG
- s
- Safari
- khả năng mở rộng
- cào
- kịch bản
- di chuyển
- dịch vụ
- một số
- Đơn giản
- đơn giản
- chậm
- một số
- Một người nào đó
- nhịp cầu
- riêng
- SQL
- SSL
- Bắt đầu
- Bước
- Các bước
- Dừng
- hàng
- lưu trữ
- mạnh mẽ
- cấu trúc
- cấu trúc
- trình
- Thành công
- như vậy
- phù hợp
- hỗ trợ
- Hỗ trợ
- cú pháp
- TAG
- Hãy
- nhiệm vụ
- TD
- về
- điều khoản dịch vụ
- Kiểm tra
- việc này
- Sản phẩm
- thông tin
- cung cấp their dịch
- Them
- Kia là
- của bên thứ ba
- Thông qua
- thời gian
- mất thời gian
- Yêu sách
- trò chơi
- đến
- bây giờ
- quá
- công cụ
- công cụ
- hàng đầu
- Chuyển đổi
- Xu hướng
- hướng dẫn
- hiểu
- URL
- sử dụng
- người sử dang
- giá trị
- Các giá trị
- khác nhau
- Xác minh
- xác minh
- khối lượng
- web
- Ứng dụng web
- trình duyệt web
- Trình duyệt web
- rút trích nội dung trang web
- Website
- trang web
- Điều gì
- cái nào
- rộng rãi
- sẽ
- với
- ở trong
- viết
- XML
- năm
- trên màn hình
- zephyrnet