Gần đây, chúng tôi nhận ra rằng đã lâu rồi chúng tôi không mang đến cho bạn bất kỳ bảng tóm tắt khoa học dữ liệu nào. Và đó không phải là do họ không có sẵn; Các bảng tóm tắt khoa học dữ liệu có ở khắp mọi nơi, từ cơ bản đến nâng cao, bao gồm các chủ đề từ thuật toán, thống kê, mẹo phỏng vấn, v.v.
Nhưng điều gì tạo nên một cheatsheet tốt? Điều gì khiến một cheatsheet xứng đáng được coi là một cheatsheet đặc biệt tốt? Thật khó để đặt ngón tay của bạn vào Chính xác điều gì tạo nên một bản tóm tắt tốt, nhưng rõ ràng là một bản tóm tắt truyền tải thông tin cần thiết một cách chính xác - cho dù thông tin đó có tính chất chung cụ thể - chắc chắn là một khởi đầu tốt. Và đó chính là điều khiến các ứng cử viên của chúng ta ngày nay trở nên đáng chú ý. Vì vậy, hãy đọc tiếp bốn bảng tóm tắt bổ sung được tuyển chọn để hỗ trợ bạn trong quá trình học hoặc ôn tập về khoa học dữ liệu.
lên đầu tiên là Bảng tóm tắt khoa học dữ liệu 2.0 của Aaron Wang, một bản tổng hợp bốn trang về các tóm tắt thống kê, các thuật toán học máy cơ bản cũng như các chủ đề và khái niệm về học sâu. Nó không có nghĩa là đầy đủ mà thay vào đó là tài liệu tham khảo nhanh cho các tình huống như chuẩn bị phỏng vấn và ôn thi cũng như bất kỳ điều gì khác yêu cầu mức độ xem xét chuyên sâu tương tự. Tác giả lưu ý rằng mặc dù những người có hiểu biết cơ bản về thống kê và đại số tuyến tính sẽ thấy tài nguyên này mang lại nhiều lợi ích nhất, nhưng những người mới bắt đầu cũng có thể thu thập được thông tin hữu ích từ nội dung của nó.

Ảnh chụp màn hình từ Aaron Wang Bảng tóm tắt khoa học dữ liệu 2.0
Ưu đãi cheatsheet tiếp theo của chúng tôi hôm nay là nguồn tài nguyên của Aaron Wang dựa trên, Bảng tóm tắt khoa học dữ liệu của Maverick Lin (Việc Wang gọi bản thân mình là 2.0 là một sự ám chỉ trực tiếp đến “bản gốc” của Lin). Chúng ta có thể coi cheatsheet của Lin có chiều sâu hơn của Wang (mặc dù quyết định của Wang thực hiện ít chuyên sâu hơn có vẻ là có chủ ý và là một giải pháp thay thế hữu ích), bao gồm nhiều khái niệm khoa học dữ liệu cơ bản hơn như làm sạch dữ liệu, ý tưởng lập mô hình, thực hiện “ dữ liệu lớn” với Hadoop, SQL và thậm chí cả kiến thức cơ bản về Python.
Rõ ràng điều này sẽ thu hút những người vững chắc hơn trong nhóm “người mới bắt đầu” và thực hiện tốt công việc kích thích sự thèm ăn cũng như giúp người đọc nhận thức được lĩnh vực khoa học dữ liệu rộng lớn cũng như nhiều khái niệm khác nhau mà nó bao gồm. Đây chắc chắn là một nguồn tài nguyên vững chắc khác, đặc biệt nếu người đọc là người mới làm quen với khoa học dữ liệu.

Ảnh chụp màn hình từ Maverick Lin's Bảng dữ liệu khoa học dữ liệu
Khi chúng ta quay ngược thời gian xa hơn — tìm kiếm nguồn cảm hứng cho chiếc áo khoác của Lin — chúng ta bắt gặp William Chen's Probability Cheatsheet 2.0. Cheatsheet của Chen đã thu hút được nhiều sự chú ý và khen ngợi trong nhiều năm, và vì vậy bạn có thể đã từng bắt gặp nó vào một lúc nào đó. Rõ ràng với một trọng tâm khác (được đặt tên), cheatsheet của Chen là một khóa học cấp tốc hoặc xem xét sâu về các khái niệm xác suất, bao gồm nhiều phân phối, hiệp phương sai và các phép biến đổi, kỳ vọng có điều kiện, chuỗi Markov, các công thức quan trọng khác nhau và nhiều hơn nữa.
Với 10 trang, bạn có thể hình dung được phạm vi rộng của các chủ đề xác suất được đề cập ở đây. Nhưng đừng để điều đó ngăn cản bạn; Khả năng cô đọng các khái niệm thành những điểm nhấn quan trọng và giải thích bằng tiếng Anh đơn giản trong khi không hy sinh những điểm thiết yếu của Chen là điều đáng chú ý. Nó cũng giàu hình ảnh giải thích, một điều khá hữu ích khi không gian bị hạn chế và mong muốn ngắn gọn là mạnh mẽ.
Tài liệu biên soạn của Chen không chỉ có chất lượng và xứng đáng với thời gian của bạn, với tư cách là người mới bắt đầu hoặc người quan tâm đến bài đánh giá đầy đủ, tôi sẽ làm việc theo thứ tự ngược lại với cách trình bày các tài nguyên này — từ cheatsheet của Chen, đến của Lin, và cuối cùng là của Wang, xây dựng dựa trên các khái niệm khi bạn đi.
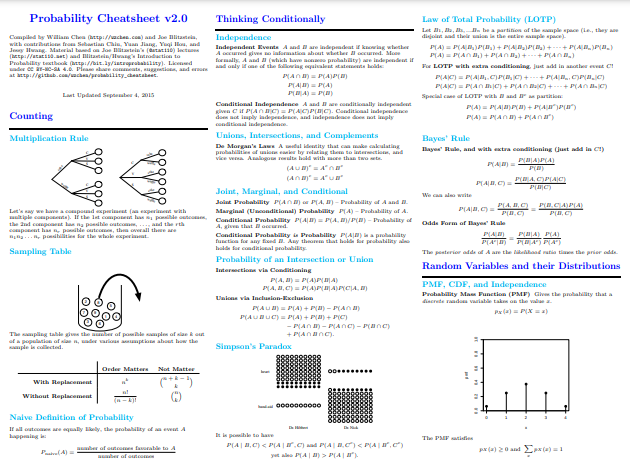
Ảnh chụp màn hình từ William Chen Bảng tính xác suất 2.0
Một nguồn tài nguyên cuối cùng mà tôi đưa vào đây, mặc dù về mặt kỹ thuật không phải là một cheatsheet, là Những vết cắn về học máy của Rishabh Anand. Tự nhận mình là “hướng dẫn phỏng vấn [a]n về các khái niệm, phương pháp thực hành, định nghĩa và lý thuyết phổ biến về Machine Learning”, Anand đã biên soạn một bộ sưu tập kiến thức đa dạng “cắn”, tính hữu ích của nó chắc chắn vượt xa việc chuẩn bị phỏng vấn dự định ban đầu. Các chủ đề được đề cập trong đó bao gồm:
- Số liệu chấm điểm mô hình
- Chia sẻ thông số
- Xác thực chéo k-Fold
- Các kiểu dữ liệu Python
- Cải thiện hiệu suất mô hình
- Mô hình thị giác máy tính
- Sự chú ý và các biến thể của nó
- Xử lý sự mất cân bằng lớp
- Thuật ngữ thị giác máy tính
- Nhân giống ngược vani
- Chính quy
- dự án

Ảnh chụp màn hình từ Vết cắn của máy học
Trong khi “các khái niệm, phương pháp thực hành tốt nhất, định nghĩa và lý thuyết” về học máy được đề cập đến, như đã hứa trong phần mô tả của tài nguyên, những “điểm nhấn” này chắc chắn hướng đến tính thực tế, khiến trang web này bổ sung cho phần lớn tài liệu được đề cập trong ba cheatsheet đã đề cập trước đó. Nếu tôi muốn đề cập đến tất cả tài liệu trong cả bốn tài nguyên trong bài đăng này, tôi chắc chắn sẽ xem xét tài liệu này sau ba tài nguyên còn lại.
Vậy là bạn có bốn cheatsheet (hoặc ba cheatsheet và một tài nguyên liền kề với cheatsheet) để sử dụng cho việc học hoặc ôn tập của bạn. Hy vọng điều gì đó ở đây hữu ích cho bạn và tôi mời mọi người chia sẻ những mánh gian lận mà họ thấy hữu ích trong phần bình luận bên dưới.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- có khả năng
- Có khả năng
- ngang qua
- tiên tiến
- Sau
- thuật toán
- Tất cả
- thay thế
- và
- Một
- bất kỳ ai
- kháng cáo
- sự chú ý
- tác giả
- sẵn có
- trở lại
- dựa
- cơ bản
- Khái niệm cơ bản
- Người mới bắt đầu
- được
- phía dưới
- hưởng lợi
- BEST
- thực hành tốt nhất
- Ngoài
- lớn
- Dữ Liệu Lớn.
- thanh toán
- bề rộng
- rộng
- Mang lại
- Xây dựng
- Trại
- ứng cử viên
- chắc chắn
- chuỗi
- chen
- tốt nghiệp lớp XNUMX
- Làm sạch
- Rõ ràng
- bộ sưu tập
- Đến
- Bình luận
- Chung
- bổ túc
- khái niệm
- nội dung
- khóa học mơ ước
- che
- phủ
- bao gồm
- Crash
- Vượt qua
- lưu trữ
- dữ liệu
- khoa học dữ liệu
- quyết định
- sâu
- lặn sâu
- học kĩ càng
- chắc chắn
- chiều sâu
- Mô tả
- khác nhau
- khó khăn
- trực tiếp
- Phân phối
- làm
- xuống
- bao trùm
- Tiếng Anh
- đặc biệt
- thiết yếu
- yếu tố cần thiết
- Ether (ETH)
- Ngay cả
- kỳ thi
- kỳ vọng
- Giải thích
- lĩnh vực
- Hình
- cuối cùng
- Cuối cùng
- Tìm kiếm
- vững chắc
- Tập trung
- tìm thấy
- từ
- Full
- cơ bản
- xa hơn
- bánh răng
- Tổng Quát
- được
- Go
- tốt
- làm tốt lắm
- hướng dẫn
- tại đây
- Hy vọng
- Độ đáng tin của
- HTTPS
- ý tưởng
- mất cân bằng
- tầm quan trọng
- in
- sâu
- bao gồm
- Bao gồm
- thông tin
- Cảm hứng
- thay vì
- Cố ý
- quan tâm
- Phỏng vấn
- giới thiệu
- mời
- IT
- chính nó
- Việc làm
- kiến thức
- Thiếu sót
- học tập
- Cấp
- Hạn chế
- Xem
- tìm kiếm
- máy
- học máy
- làm cho
- LÀM CHO
- Làm
- nhiều
- vật liệu
- bò con bị lạc
- đề cập
- Metrics
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- di chuyển
- tên
- Thiên nhiên
- tiếp theo
- Chú ý
- đáng chú ý
- Khái niệm
- cung cấp
- ONE
- gọi món
- nguyên
- ban đầu
- Nền tảng khác
- riêng
- đặc biệt
- hiệu suất
- Trơn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- điểm
- Bài đăng
- Thực tế
- thực hành
- trình bày
- trước đây
- hứa
- đặt
- Python
- chất lượng
- Nhanh chóng
- khác nhau,
- Đọc
- Người đọc
- độc giả
- nhận ra
- gần đây
- tài nguyên
- Thông tin
- đảo ngược
- xem xét
- Đánh giá
- Giàu
- hy sinh
- Khoa học
- ghi bàn
- tìm kiếm
- dường như
- Chia sẻ
- chia sẻ
- nên
- tương tự
- website
- tình huống
- So
- rắn
- một số
- Một người nào đó
- một cái gì đó
- Không gian
- riêng
- Bắt đầu
- thống kê
- số liệu thống kê
- mạnh mẽ
- như vậy
- Sản phẩm
- Khái niệm cơ bản
- cung cấp their dịch
- số ba
- thời gian
- lời khuyên
- đến
- bây giờ
- hàng đầu
- Chủ đề
- đối với
- biến đổi
- loại
- sự hiểu biết
- sử dụng
- xác nhận
- nhiều
- khác nhau
- tầm nhìn
- Điều gì
- liệu
- cái nào
- trong khi
- CHÚNG TÔI LÀ
- rộng
- sẽ
- ở trong
- Công việc
- sẽ
- năm
- trên màn hình
- zephyrnet