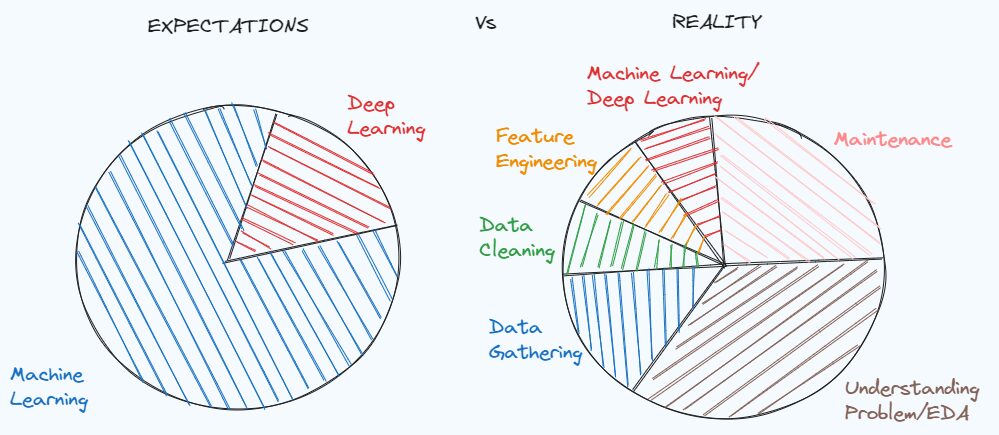
Hình minh họa của tác giả. Lấy cảm hứng từ MEME của Tiến sĩ Angshuman Ghosh
Nắm vững các kỹ thuật tiền xử lý và làm sạch dữ liệu là nền tảng để giải quyết nhiều dự án khoa học dữ liệu. Một minh chứng đơn giản về tầm quan trọng có thể được tìm thấy trong meme về kỳ vọng của một sinh viên học khoa học dữ liệu trước khi đi làm, so với thực tế của công việc nhà khoa học dữ liệu.
Chúng ta có xu hướng lý tưởng hóa vị trí công việc trước khi có trải nghiệm cụ thể, nhưng thực tế là nó luôn khác với những gì chúng ta thực sự mong đợi. Khi làm việc với một vấn đề trong thế giới thực, không có tài liệu về dữ liệu và bộ dữ liệu rất bẩn. Đầu tiên, bạn phải đào sâu vấn đề, hiểu những manh mối nào bạn đang bỏ lỡ và những thông tin nào bạn có thể khai thác.
Sau khi hiểu vấn đề, bạn cần chuẩn bị bộ dữ liệu cho mô hình học máy của mình vì dữ liệu ở trạng thái ban đầu không bao giờ là đủ. Trong bài viết này, tôi sẽ chỉ ra bảy bước có thể giúp bạn xử lý trước và làm sạch tập dữ liệu của mình.
Bước đầu tiên trong dự án khoa học dữ liệu là phân tích khám phá, giúp hiểu vấn đề và đưa ra quyết định trong các bước tiếp theo. Nó có xu hướng bị bỏ qua, nhưng đó là lỗi tồi tệ nhất vì sau này bạn sẽ mất rất nhiều thời gian để tìm ra lý do tại sao mô hình đưa ra lỗi hoặc không hoạt động như mong đợi.
Dựa trên kinh nghiệm của tôi với tư cách là nhà khoa học dữ liệu, tôi sẽ chia phân tích khám phá thành ba phần:
- Kiểm tra cấu trúc của tập dữ liệu, số liệu thống kê, các giá trị bị thiếu, trùng lặp, giá trị duy nhất của các biến phân loại
- Hiểu ý nghĩa và sự phân phối của các biến
- Nghiên cứu mối quan hệ giữa các biến
Để phân tích cách tổ chức tập dữ liệu, có các phương pháp Pandas sau đây có thể giúp bạn:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)]) for c in list(df): print(df[c].value_counts())
Khi cố gắng hiểu các biến, sẽ rất hữu ích nếu chia phân tích thành hai phần nữa: các đặc trưng số và các đặc trưng phân loại. Đầu tiên, chúng ta có thể tập trung vào các tính năng số có thể được hiển thị thông qua biểu đồ và biểu đồ hình hộp. Sau đó, đến lượt các biến phân loại. Trong trường hợp đó là một vấn đề nhị phân, tốt hơn hết là bắt đầu bằng cách xem các lớp có cân bằng không. Sau đó, chúng ta có thể tập trung chú ý vào các biến phân loại còn lại bằng cách sử dụng biểu đồ thanh. Cuối cùng, cuối cùng chúng ta có thể kiểm tra mối tương quan giữa từng cặp biến số. Các hình ảnh trực quan hóa dữ liệu hữu ích khác có thể là biểu đồ phân tán và biểu đồ hộp để quan sát mối quan hệ giữa biến số và biến phân loại.
Ở bước đầu tiên, chúng tôi đã điều tra xem có thiếu sót nào trong mỗi biến hay không. Trong trường hợp có các giá trị bị thiếu, chúng ta cần hiểu cách xử lý vấn đề. Cách dễ nhất là xóa các biến hoặc hàng chứa giá trị NaN, nhưng chúng tôi muốn tránh cách này vì chúng tôi có nguy cơ mất thông tin hữu ích có thể giúp mô hình học máy của chúng tôi giải quyết vấn đề.
Nếu chúng ta đang xử lý một biến số, có một số cách tiếp cận để lấp đầy nó. Phương pháp phổ biến nhất bao gồm điền các giá trị còn thiếu bằng giá trị trung bình/trung bình của tính năng đó:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
Một cách khác là thay thế các khoảng trống bằng nhóm theo quy nạp:
df['price'].fillna(df.group('type_building')['price'].transform('mean'),
inplace=True)
Nó có thể là một lựa chọn tốt hơn trong trường hợp có mối quan hệ chặt chẽ giữa một tính năng số và một tính năng phân loại.
Theo cách tương tự, chúng ta có thể điền vào các giá trị còn thiếu của phân loại dựa trên chế độ của biến đó:
df['type_building'].fillna(df['type_building'].mode()[0])Nếu có các bản sao trong tập dữ liệu, tốt hơn là xóa các hàng trùng lặp:
df = df.drop_duplicates()
Mặc dù việc quyết định cách xử lý các bản sao rất đơn giản, nhưng việc xử lý các giá trị ngoại lai có thể là một thách thức. Bạn cần tự hỏi mình “Drop or not Drop Outliers?”.
Các ngoại lệ sẽ bị xóa nếu bạn chắc chắn rằng chúng chỉ cung cấp thông tin ồn ào. Ví dụ: tập dữ liệu chứa hai người có 200 tuổi, trong khi phạm vi độ tuổi nằm trong khoảng từ 0 đến 90. Trong trường hợp đó, tốt hơn là xóa hai điểm dữ liệu này.
df = df[df.Age=90]
Thật không may, hầu hết thời gian loại bỏ các ngoại lệ có thể dẫn đến mất thông tin quan trọng. Cách hiệu quả nhất là áp dụng phép biến đổi logarit cho đặc trưng số.
Một kỹ thuật khác mà tôi đã khám phá ra trong lần trải nghiệm cuối cùng của mình là phương pháp cắt bớt. Trong kỹ thuật này, bạn chọn giới hạn trên và giới hạn dưới, có thể là phần trăm 0.1 và phần trăm 0.9. Các giá trị của đối tượng bên dưới giới hạn dưới sẽ được thay thế bằng giá trị giới hạn dưới, trong khi các giá trị của biến phía trên giới hạn trên sẽ được thay thế bằng giá trị giới hạn trên.
for c in columns_with_outliers: transform= 'clipped_'+ c lower_limit = df[c].quantile(0.10) upper_limit = df[c].quantile(0.90) df[transform] = df[c].clip(lower_limit, upper_limit, axis = 0)Giai đoạn tiếp theo là chuyển đổi các tính năng phân loại thành các tính năng số. Thật vậy, mô hình học máy chỉ có thể hoạt động với các số chứ không phải chuỗi.
Trước khi tiếp tục, bạn nên phân biệt giữa hai loại biến phân loại: biến không thứ tự và biến thứ tự.
Ví dụ về các biến không thứ tự là giới tính, tình trạng hôn nhân, loại công việc. Vì vậy, sẽ không có thứ tự nếu biến không tuân theo thứ tự, khác với các đặc điểm thứ tự. Một ví dụ về các biến thứ tự có thể là trình độ học vấn với các giá trị “thời thơ ấu”, “sơ cấp”, “trung học” và “đại học” và thu nhập với các mức “thấp”, “trung bình” và “cao”.
Khi chúng ta xử lý các biến không theo thứ tự, Mã hóa một lần nóng là kỹ thuật phổ biến nhất được tính đến để chuyển đổi các biến này thành số.
Trong phương pháp này, chúng tôi tạo một biến nhị phân mới cho từng cấp độ của tính năng phân loại. Giá trị của mỗi biến nhị phân là 1 khi tên của cấp độ trùng với giá trị của cấp độ, 0 nếu không.
from sklearn.preprocessing import OneHotEncoder data_to_encode = df[cols_to_encode]
encoder = OneHotEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
dummy_variables = encoder.get_feature_names_out(cols_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=encoder.get_feature_names_out(cols_to_encode)) final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
Khi biến là thứ tự, kỹ thuật phổ biến nhất được sử dụng là Mã hóa thứ tự, bao gồm chuyển đổi các giá trị duy nhất của biến phân loại thành số nguyên tuân theo thứ tự. Ví dụ: các mức “thấp”, “Trung bình” và “Cao” của thu nhập sẽ được mã hóa tương ứng là 0,1 và 2.
from sklearn.preprocessing import OrdinalEncoder data_to_encode = df[cols_to_encode]
encoder = OrdinalEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=["Income"]) final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
Có những kỹ thuật mã hóa khả thi khác nếu bạn muốn khám phá tại đây. bạn có thể xem qua tại đây trong trường hợp bạn quan tâm đến các lựa chọn thay thế.
Đã đến lúc chia tập dữ liệu thành ba tập hợp con cố định: lựa chọn phổ biến nhất là sử dụng 60% để đào tạo, 20% để xác thực và 20% để kiểm tra. Khi số lượng dữ liệu tăng lên, tỷ lệ phần trăm dành cho đào tạo tăng lên và tỷ lệ phần trăm để xác thực và kiểm tra giảm xuống.
Điều quan trọng là phải có ba tập hợp con vì tập huấn luyện được sử dụng để huấn luyện mô hình, trong khi tập hợp lệ và tập kiểm tra có thể hữu ích để hiểu mô hình đang hoạt động như thế nào trên dữ liệu mới.
Để phân chia tập dữ liệu, chúng ta có thể sử dụng train_test_split của scikit-learning:
from sklearn.model_selection import train_test_split X = final_df.drop(['y'],axis=1)
y = final_df['y'] train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123) df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]
Trong trường hợp chúng ta đang giải quyết vấn đề phân loại và các lớp không cân bằng, tốt hơn là thiết lập đối số phân tầng để đảm bảo rằng có cùng tỷ lệ các lớp trong các tập huấn luyện, xác thực và kiểm tra.
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)
Xác thực chéo phân tầng này cũng giúp đảm bảo rằng có cùng tỷ lệ phần trăm của biến mục tiêu trong ba tập hợp con và mang lại hiệu suất chính xác hơn cho mô hình.
Có các mô hình học máy, như Hồi quy tuyến tính, Hồi quy logistic, KNN, Máy vectơ hỗ trợ và Mạng thần kinh, yêu cầu các tính năng mở rộng. Tính năng mở rộng quy mô chỉ giúp các biến nằm trong cùng một phạm vi, không thay đổi phân phối.
Có ba kỹ thuật nhân rộng tính năng phổ biến nhất là Chuẩn hóa, Chuẩn hóa và Mở rộng mạnh mẽ.
Chuẩn hóa, còn được gọi là chia tỷ lệ tối thiểu-tối đa, bao gồm ánh xạ giá trị của một biến vào một phạm vi từ 0 đến 1. Điều này có thể thực hiện được bằng cách trừ giá trị nhỏ nhất của đối tượng khỏi giá trị đối tượng và sau đó chia cho hiệu giữa giá trị lớn nhất và tối thiểu của tính năng đó.
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Một cách tiếp cận phổ biến khác là Chuẩn hóa, giúp thay đổi tỷ lệ các giá trị của một cột để tôn trọng các thuộc tính của phân phối chuẩn chuẩn, được đặc trưng bởi giá trị trung bình bằng 0 và phương sai bằng 1.
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Nếu đối tượng địa lý chứa các giá trị ngoại lai không thể xóa được, thì phương pháp thích hợp hơn là Chia tỷ lệ mạnh mẽ, phương pháp này sẽ thay đổi tỷ lệ các giá trị của đối tượng địa lý dựa trên số liệu thống kê mạnh mẽ, trung vị, phần tư thứ nhất và thứ ba. Giá trị được thay đổi tỷ lệ thu được bằng cách trừ giá trị trung bình khỏi giá trị ban đầu, sau đó, chia cho Phạm vi liên vùng, là sự khác biệt giữa phần tư thứ 75 và 25 của đối tượng địa lý.
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Nói chung, tốt hơn là tính toán số liệu thống kê dựa trên tập huấn luyện và sau đó sử dụng chúng để thay đổi tỷ lệ các giá trị trên cả tập huấn luyện, xác thực và kiểm tra. Điều này là do chúng tôi cho rằng chúng tôi chỉ có dữ liệu huấn luyện và sau đó, chúng tôi muốn thử nghiệm mô hình của mình trên dữ liệu mới, dữ liệu này sẽ có phân phối tương tự như tập huấn luyện.
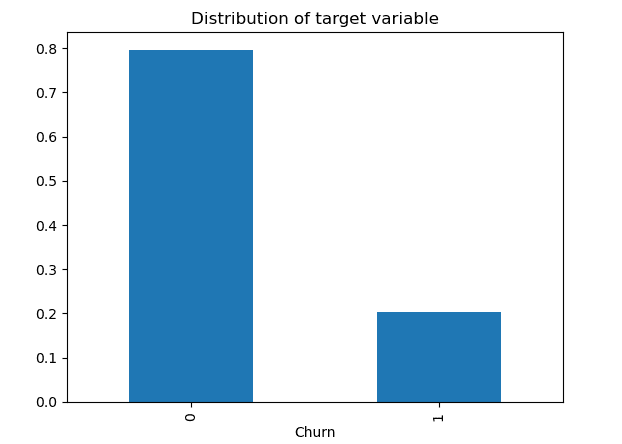
Bước này chỉ được đưa vào khi chúng ta đang giải bài toán phân loại và chúng ta thấy rằng các lớp không cân bằng.
Trong trường hợp có sự khác biệt nhỏ giữa các lớp, ví dụ lớp 1 chứa 40% số quan sát và lớp 2 chứa 60% còn lại, chúng ta không cần áp dụng các kỹ thuật lấy mẫu quá mức hoặc lấy mẫu dưới để thay đổi số lượng mẫu trong một trong các lớp. các lớp học. Chúng ta có thể tránh nhìn vào độ chính xác vì nó chỉ là thước đo tốt khi tập dữ liệu được cân bằng và chúng ta chỉ nên quan tâm đến các thước đo đánh giá, như độ chính xác, thu hồi và điểm f1.
Nhưng có thể xảy ra trường hợp lớp tích cực có tỷ lệ điểm dữ liệu rất thấp (0.2) so với lớp tiêu cực (0.8). Việc học máy có thể không hoạt động tốt với lớp có ít quan sát hơn, dẫn đến không giải quyết được nhiệm vụ.
Để khắc phục vấn đề này, có hai khả năng: lấy mẫu dưới lớp đa số và lấy mẫu quá mức cho lớp thiểu số. Lấy mẫu thiếu bao gồm việc giảm số lượng mẫu bằng cách xóa ngẫu nhiên một số điểm dữ liệu khỏi lớp đa số, trong khi Lấy mẫu quá mức làm tăng số lượng quan sát trong lớp thiểu số bằng cách thêm ngẫu nhiên các điểm dữ liệu từ lớp ít phổ biến hơn. Có imblearn cho phép cân bằng tập dữ liệu với một vài dòng mã:
# undersampling
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# oversampling
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Tuy nhiên, việc loại bỏ hoặc sao chép một số quan sát đôi khi có thể không hiệu quả trong việc cải thiện hiệu suất của mô hình. Sẽ tốt hơn nếu tạo các điểm dữ liệu nhân tạo mới trong lớp thiểu số. Một kỹ thuật được đề xuất để giải quyết vấn đề này là SMOTE, được biết đến với việc tạo các bản ghi tổng hợp trong lớp ít được đại diện hơn. Giống như KNN, ý tưởng là xác định k hàng xóm gần nhất của các quan sát thuộc nhóm thiểu số, dựa trên một khoảng cách cụ thể, như t. Sau khi một điểm mới được tạo tại một vị trí ngẫu nhiên giữa k hàng xóm gần nhất này. Quá trình này sẽ tiếp tục tạo ra các điểm mới cho đến khi bộ dữ liệu được cân bằng hoàn toàn.
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Tôi nên nhấn mạnh rằng các phương pháp này chỉ nên được áp dụng để lấy mẫu lại tập huấn luyện. Chúng tôi muốn rằng mô hình máy của chúng tôi học theo cách mạnh mẽ và sau đó, chúng tôi có thể áp dụng nó để đưa ra dự đoán về dữ liệu mới.
Tôi hy vọng bạn đã tìm thấy hướng dẫn toàn diện này hữu ích. Có thể khó bắt đầu dự án khoa học dữ liệu đầu tiên của chúng tôi nếu không biết tất cả các kỹ thuật này. Bạn có thể tìm thấy tất cả mã của tôi tại đây.
Chắc chắn có những phương pháp khác mà tôi không trình bày trong bài viết, nhưng tôi muốn tập trung vào những phương pháp phổ biến và được biết đến nhiều nhất. bạn có ý kiến khác? Thả chúng trong phần bình luận nếu bạn có đề xuất sâu sắc.
Tài nguyên hữu ích:
Eugenia Anello hiện là nghiên cứu viên tại Khoa Kỹ thuật Thông tin của Đại học Padova, Ý. Dự án nghiên cứu của cô tập trung vào Học tập liên tục kết hợp với Phát hiện bất thường.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/08/7-steps-mastering-data-cleaning-preprocessing-techniques.html?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-data-cleaning-and-preprocessing-techniques
- : có
- :là
- :không phải
- $ LÊN
- 1
- 10
- 11
- 14
- 17
- 200
- 23
- 7
- 8
- 9
- 90
- a
- Có khả năng
- Giới thiệu
- ở trên
- Tài khoản
- chính xác
- chính xác
- thêm
- Sau
- tuổi
- Tất cả
- cho phép
- Đã
- Ngoài ra
- lựa chọn thay thế
- luôn luôn
- am
- an
- phân tích
- phân tích
- và
- phát hiện bất thường
- áp dụng
- Đăng Nhập
- phương pháp tiếp cận
- cách tiếp cận
- LÀ
- đối số
- bài viết
- nhân tạo
- AS
- At
- sự chú ý
- tác giả
- tránh
- nhận thức
- Trục
- Cân đối
- thanh
- dựa
- BE
- bởi vì
- trước
- được
- phía dưới
- Hơn
- giữa
- cả hai
- ràng buộc
- nhưng
- by
- tính toán
- gọi là
- CAN
- không thể
- mà
- trường hợp
- thách thức
- thay đổi
- kiểm tra
- sự lựa chọn
- Chọn
- tốt nghiệp lớp XNUMX
- các lớp học
- phân loại
- Làm sạch
- mã
- Cột
- kết hợp
- Bình luận
- Chung
- so
- hoàn toàn
- toàn diện
- điều kiện
- bao gồm
- chứa
- chuyển đổi
- chuyển đổi
- Tương quan
- che
- tạo
- Tạo
- Hiện nay
- dữ liệu
- điểm dữ liệu
- khoa học dữ liệu
- nhà khoa học dữ liệu
- xử lý
- Quyết định
- quyết định
- giảm
- sâu
- bộ
- Phát hiện
- sự khác biệt
- khác nhau
- ĐÀO
- phát hiện
- khoảng cách
- phân biệt
- phân phối
- do
- tài liệu hướng dẫn
- Không
- dont
- dr
- Rơi
- bản sao
- suốt trong
- mỗi
- dễ nhất
- Đào tạo
- hiệu quả
- cuối
- Kỹ Sư
- đủ
- đảm bảo
- như nhau
- lôi
- lỗi
- đánh giá
- ví dụ
- mong đợi
- mong đợi
- dự kiến
- kinh nghiệm
- khám phá
- trích xuất
- không
- Đặc tính
- Tính năng
- đồng bào
- vài
- điền
- đổ đầy
- Cuối cùng
- Tìm kiếm
- Tên
- cố định
- Tập trung
- tập trung
- theo
- tiếp theo
- Trong
- tìm thấy
- thường xuyên
- từ
- cơ bản
- xa hơn
- Giới Tính
- Tổng Quát
- tạo ra
- tạo ra
- Cho
- cho
- đi
- tốt
- Nhóm
- Phát triển
- xử lý
- xảy ra
- Cứng
- Có
- có
- giúp đỡ
- giúp
- cô
- tại đây
- Đánh dấu
- mong
- Độ đáng tin của
- Hướng dẫn
- HTTPS
- i
- ý tưởng
- xác định
- if
- nhập khẩu
- quan trọng
- cải thiện
- in
- bao gồm
- lợi tức
- Tăng
- chỉ số
- thông tin
- ban đầu
- sâu sắc
- lấy cảm hứng từ
- quan tâm
- trong
- vấn đề
- IT
- Italy
- ITS
- Việc làm
- jpg
- chỉ
- Xe đẩy
- Giữ
- nổi tiếng
- Họ
- một lát sau
- dẫn
- hàng đầu
- học tập
- ít
- Cấp
- niveaux
- Lượt thích
- dòng
- địa điểm thư viện nào
- Xem
- tìm kiếm
- thua
- mất
- Rất nhiều
- Thấp
- thấp hơn
- máy
- học máy
- Đa số
- làm cho
- lập bản đồ
- Làm chủ
- tối đa
- Có thể..
- nghĩa là
- có nghĩa là
- đo
- các biện pháp
- meme
- phương pháp
- phương pháp
- tối thiểu
- dân tộc thiểu số
- mất tích
- Chế độ
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- Phổ biến nhất
- my
- tên
- Cần
- tiêu cực
- người hàng xóm
- mạng
- Thần kinh
- mạng thần kinh
- không bao giờ
- Mới
- tiếp theo
- Không
- bình thường
- con số
- số
- tuân theo
- thu được
- of
- on
- ONE
- những
- có thể
- Tùy chọn
- or
- gọi món
- nguyên
- Nền tảng khác
- nếu không thì
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- Vượt qua
- đôi
- gấu trúc
- riêng
- các bộ phận
- người
- tỷ lệ phần trăm
- thực hiện
- hiệu suất
- biểu diễn
- biểu diễn
- giai đoạn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- điểm
- Phổ biến
- vị trí
- tích cực
- khả năng
- có thể
- Độ chính xác
- Dự đoán
- thích hơn
- thích hợp hơn
- ưa thích
- Chuẩn bị
- giá
- Vấn đề
- quá trình
- dự án
- dự án
- tài sản
- tỷ lệ
- đề xuất
- cho
- số lượng, lượng
- Quora
- ngẫu nhiên
- phạm vi
- thế giới thực
- Thực tế
- có thật không
- lý do
- hồ sơ
- giảm
- hồi quy
- quan hệ
- mối quan hệ
- Mối quan hệ
- còn lại
- tẩy
- Đã loại bỏ
- loại bỏ
- thay thế
- đại diện
- yêu cầu
- nghiên cứu
- Thông tin
- tôn trọng
- tương ứng
- Nguy cơ
- mạnh mẽ
- tương tự
- mở rộng quy mô
- Khoa học
- Nhà khoa học
- học hỏi
- định
- bộ
- XNUMX
- một số
- nên
- hiển thị
- tương tự
- Đơn giản
- kể từ khi
- So
- động SOLVE
- Giải quyết
- một số
- chia
- Tiêu chuẩn
- Bắt đầu
- số liệu thống kê
- Trạng thái
- Bước
- Các bước
- mạnh mẽ
- cấu trúc
- Sinh viên
- Học tập
- hỗ trợ
- chắc chắn
- chắc chắn
- sợi tổng hợp
- T
- Hãy
- Lấy
- dùng
- Mục tiêu
- Nhiệm vụ
- kỹ thuật
- thử nghiệm
- Kiểm tra
- hơn
- việc này
- Sản phẩm
- Them
- sau đó
- Đó
- Kia là
- họ
- Thứ ba
- điều này
- số ba
- Thông qua
- thời gian
- đến
- Train
- Hội thảo
- Chuyển đổi
- Chuyển đổi
- XOAY
- hướng dẫn
- hai
- kiểu
- loại
- hiểu
- sự hiểu biết
- độc đáo
- trường đại học
- cho đến khi
- sử dụng
- đã sử dụng
- thông tin hữu ích
- sử dụng
- xác nhận
- giá trị
- Các giá trị
- rất
- muốn
- Đường..
- we
- TỐT
- Điều gì
- khi nào
- cái nào
- trong khi
- tại sao
- sẽ
- với
- ở trong
- không có
- Công việc
- đang làm việc
- tệ nhất
- sẽ
- X
- năm
- bạn
- trên màn hình
- mình
- zephyrnet








