Tầm quan trọng của kho dữ liệu và phân tích được thực hiện trên nền tảng kho dữ liệu đã tăng đều đặn trong những năm qua, với nhiều doanh nghiệp dựa vào các hệ thống này như một nhiệm vụ quan trọng cho cả việc ra quyết định hoạt động ngắn hạn và lập kế hoạch chiến lược dài hạn. Theo truyền thống, kho dữ liệu được làm mới theo chu kỳ hàng loạt, chẳng hạn như hàng tháng, hàng tuần hoặc hàng ngày để doanh nghiệp có thể rút ra nhiều thông tin chi tiết khác nhau từ chúng.
Nhiều tổ chức đang nhận ra rằng việc nhập dữ liệu gần thời gian thực cùng với phân tích nâng cao sẽ mở ra những cơ hội mới. Ví dụ: một tổ chức tài chính có thể dự đoán xem giao dịch thẻ tín dụng có gian lận hay không bằng cách chạy chương trình phát hiện bất thường ở chế độ gần thời gian thực thay vì ở chế độ hàng loạt.
Trong bài đăng này, chúng tôi chỉ ra cách Amazon RedShift có thể cung cấp tất cả các dự đoán nhập trực tuyến và học máy (ML) trong một nền tảng.
Amazon Redshift là kho dữ liệu đám mây nhanh, có thể thay đổi quy mô, bảo mật và được quản lý hoàn toàn, giúp việc phân tích tất cả dữ liệu của bạn bằng cách sử dụng SQL tiêu chuẩn trở nên đơn giản và tiết kiệm chi phí.
Máy học dịch chuyển đỏ của Amazon giúp các nhà phân tích dữ liệu và nhà phát triển cơ sở dữ liệu dễ dàng tạo, đào tạo và áp dụng các mô hình ML bằng các lệnh SQL quen thuộc trong kho dữ liệu Amazon Redshift.
Chúng tôi rất vui mừng được ra mắt Nhập dữ liệu truyền trực tuyến Amazon Redshift cho Luồng dữ liệu Amazon Kinesis và Truyền trực tuyến được quản lý của Amazon cho Apache Kafka (Amazon MSK), cho phép bạn nhập dữ liệu trực tiếp từ luồng dữ liệu Kinesis hoặc chủ đề Kafka mà không cần phải sắp xếp dữ liệu trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Tính năng nhập trực tuyến Amazon Redshift cho phép bạn đạt được độ trễ thấp theo thứ tự giây trong khi nhập hàng trăm megabyte dữ liệu vào kho dữ liệu của mình.
Bài đăng này trình bày cách Amazon Redshift, kho dữ liệu đám mây cho phép bạn xây dựng các dự đoán ML gần thời gian thực bằng cách sử dụng tính năng nhập trực tuyến Amazon Redshift và các tính năng Redshift ML với ngôn ngữ SQL quen thuộc.
Tổng quan về giải pháp
Bằng cách làm theo các bước được nêu trong bài đăng này, bạn sẽ có thể thiết lập ứng dụng trình phát trực tuyến của nhà sản xuất trên một Đám mây điện toán đàn hồi Amazon (Amazon EC2) mô phỏng các giao dịch thẻ tín dụng và đẩy dữ liệu vào Kinesis Data Streams trong thời gian thực. Bạn thiết lập chế độ xem cụ thể hóa Nhập liệu truyền trực tuyến Amazon Redshift trên Amazon Redshift, nơi nhận dữ liệu truyền trực tuyến. Bạn đào tạo và xây dựng mô hình Redshift ML để tạo ra các suy luận theo thời gian thực đối với dữ liệu truyền phát.
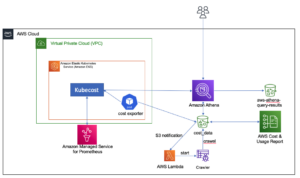
Sơ đồ sau đây minh họa kiến trúc và dòng quy trình.
Quy trình từng bước như sau:
- Phiên bản EC2 mô phỏng một ứng dụng giao dịch thẻ tín dụng, ứng dụng này sẽ chèn các giao dịch thẻ tín dụng vào luồng dữ liệu Kinesis.
- Luồng dữ liệu lưu trữ dữ liệu giao dịch thẻ tín dụng đến.
- Chế độ xem cụ thể hóa Nhập liệu truyền trực tuyến Amazon Redshift được tạo ở đầu luồng dữ liệu, chế độ xem này sẽ tự động nhập dữ liệu truyền trực tuyến vào Amazon Redshift.
- Bạn xây dựng, đào tạo và triển khai mô hình ML bằng Redshift ML. Mô hình Redshift ML được đào tạo bằng cách sử dụng dữ liệu giao dịch lịch sử.
- Bạn chuyển đổi dữ liệu phát trực tuyến và tạo các dự đoán ML.
- Bạn có thể cảnh báo khách hàng hoặc cập nhật ứng dụng để giảm thiểu rủi ro.
Hướng dẫn này sử dụng dữ liệu phát trực tuyến giao dịch thẻ tín dụng. Dữ liệu giao dịch thẻ tín dụng là hư cấu và dựa trên mô phỏng. Tập dữ liệu khách hàng cũng là hư cấu và được tạo bằng một số hàm dữ liệu ngẫu nhiên.
Điều kiện tiên quyết
- Tạo một cụm Amazon Redshift.
- Định cấu hình cụm để sử dụng Redshift ML.
- Tạo an Quản lý truy cập và nhận dạng AWS (IAM) người dùng.
- Cập nhật vai trò IAM được đính kèm với cụm Redshift để thêm quyền truy cập vào luồng dữ liệu Kinesis. Để biết thêm thông tin về chính sách bắt buộc, hãy tham khảo Bắt đầu với việc nhập trực tuyến.
- Tạo phiên bản m5.4xlarge EC2. Chúng tôi đã thử nghiệm ứng dụng Producer với phiên bản m5.4xlarge nhưng bạn có thể thoải mái sử dụng loại phiên bản khác. Khi tạo cá thể, hãy sử dụng amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI.
- Để đảm bảo rằng Python3 đã được cài đặt trong phiên bản EC2, hãy chạy lệnh sau để xác minh phiên bản Python của bạn (lưu ý rằng tập lệnh trích xuất dữ liệu chỉ hoạt động trên Python 3):
- Cài đặt các gói phụ thuộc sau để chạy chương trình giả lập:
- Định cấu hình Amazon EC2 bằng cách sử dụng các biến như thông tin đăng nhập AWS được tạo cho người dùng IAM được tạo ở bước 3 ở trên. Ảnh chụp màn hình sau đây cho thấy một ví dụ sử dụng aws cấu hình.

Thiết lập Luồng dữ liệu Kinesis
Amazon Kinesis Data Streams là dịch vụ truyền dữ liệu theo thời gian thực bền bỉ và có khả năng mở rộng quy mô lớn. Nó có thể liên tục thu thập hàng gigabyte dữ liệu mỗi giây từ hàng trăm nghìn nguồn, chẳng hạn như luồng nhấp chuột trên trang web, luồng sự kiện cơ sở dữ liệu, giao dịch tài chính, nguồn cấp dữ liệu truyền thông xã hội, nhật ký CNTT và sự kiện theo dõi vị trí. Dữ liệu được thu thập có sẵn tính bằng mili giây để cho phép các trường hợp sử dụng phân tích thời gian thực, chẳng hạn như bảng điều khiển thời gian thực, phát hiện bất thường theo thời gian thực, định giá động, v.v. Chúng tôi sử dụng Kinesis Data Streams vì đây là giải pháp không cần máy chủ có thể thay đổi quy mô dựa trên mức sử dụng.
Tạo luồng dữ liệu Kinesis
Trước tiên, bạn cần tạo luồng dữ liệu Kinesis để nhận dữ liệu phát trực tuyến:
- Trên bảng điều khiển Amazon Kinesis, chọn luồng dữ liệu trong khung điều hướng.
- Chọn Tạo luồng dữ liệu.
- Trong Tên luồng dữ liệu, đi vào
cust-payment-txn-stream. - Trong chế độ công suất, lựa chọn Theo yêu cầu.

- Đối với các tùy chọn còn lại, hãy chọn các tùy chọn mặc định và làm theo lời nhắc để hoàn tất thiết lập.
- Ghi lại ARN cho luồng dữ liệu đã tạo để sử dụng trong phần tiếp theo khi xác định chính sách IAM của bạn.

Thiết lập quyền
Để một ứng dụng phát trực tuyến ghi vào Luồng dữ liệu Kinesis, ứng dụng đó cần có quyền truy cập vào Kinesis. Bạn có thể sử dụng câu lệnh chính sách sau để cấp cho quy trình giả lập mà bạn đã thiết lập trong phần tiếp theo quyền truy cập vào luồng dữ liệu. Sử dụng ARN của luồng dữ liệu mà bạn đã lưu ở bước trước.
Định cấu hình trình tạo luồng
Trước khi có thể sử dụng dữ liệu truyền phát trong Amazon Redshift, chúng ta cần một nguồn dữ liệu truyền phát để ghi dữ liệu vào luồng dữ liệu Kinesis. Bài đăng này sử dụng trình tạo dữ liệu được tạo tùy chỉnh và AWS SDK cho Python (Boto3) để xuất bản dữ liệu lên luồng dữ liệu. Để biết hướng dẫn thiết lập, hãy tham khảo Trình mô phỏng nhà sản xuất. Quá trình giả lập này xuất bản dữ liệu phát trực tuyến tới luồng dữ liệu được tạo ở bước trước (cust-payment-txn-stream).
Định cấu hình người tiêu dùng luồng
Phần này nói về cách định cấu hình trình tiêu thụ luồng (chế độ xem nhập dữ liệu phát trực tuyến Amazon Redshift).
Amazon Redshift Streaming Ingestion cung cấp khả năng nhập dữ liệu truyền trực tuyến với tốc độ cao, độ trễ thấp từ Luồng dữ liệu Kinesis vào chế độ xem cụ thể hóa Amazon Redshift. Bạn có thể định cấu hình cụm Amazon Redshift của mình để cho phép nhập trực tuyến và tạo chế độ xem cụ thể hóa với tính năng tự động làm mới, bằng cách sử dụng các câu lệnh SQL, như được mô tả trong Tạo chế độ xem cụ thể hóa trong Amazon Redshift. Quá trình làm mới chế độ xem cụ thể hóa tự động sẽ nhập dữ liệu truyền phát với tốc độ hàng trăm megabyte dữ liệu mỗi giây từ Kinesis Data Streams vào Amazon Redshift. Điều này dẫn đến khả năng truy cập nhanh vào dữ liệu bên ngoài được làm mới nhanh chóng.
Sau khi tạo chế độ xem cụ thể hóa, bạn có thể truy cập dữ liệu của mình từ luồng dữ liệu bằng cách sử dụng SQL và đơn giản hóa các đường dẫn dữ liệu của bạn bằng cách tạo chế độ xem cụ thể hóa ngay trên đầu luồng.
Hoàn thành các bước sau để định cấu hình chế độ xem cụ thể hóa luồng Amazon Redshift:
- Trên bảng điều khiển IAM, hãy chọn các chính sách trong ngăn điều hướng.
- Chọn Tạo chính sách.
- Tạo một chính sách IAM mới gọi là
KinesisStreamPolicy. Đối với định nghĩa chính sách phát trực tuyến, xem Bắt đầu với việc nhập trực tuyến. - Trong ngăn dẫn hướng, chọn Vai trò.
- Chọn Tạo vai trò.
- Chọn Dịch vụ AWS Và chọn Redshift và Redshift có thể tùy chỉnh.
- Tạo một vai trò mới được gọi là
redshift-streaming-rolevà đính kèm chính sáchKinesisStreamPolicy. - Tạo giản đồ bên ngoài để ánh xạ tới Luồng dữ liệu Kinesis :
Giờ đây, bạn có thể tạo chế độ xem cụ thể hóa để sử dụng dữ liệu luồng. Bạn có thể sử dụng loại dữ liệu SUPER để lưu trữ tải trọng theo nguyên trạng ở định dạng JSON hoặc sử dụng các hàm JSON của Amazon Redshift để phân tích cú pháp dữ liệu JSON thành các cột riêng lẻ. Đối với bài đăng này, chúng tôi sử dụng phương pháp thứ hai vì lược đồ được xác định rõ.
- Tạo chế độ xem cụ thể hóa việc nhập dữ liệu trực tuyến
cust_payment_tx_stream. Bằng cách chỉ định AUTO REFRESH YES trong mã sau, bạn có thể bật tự động làm mới chế độ xem nhập trực tuyến, giúp tiết kiệm thời gian bằng cách tránh xây dựng đường dẫn dữ liệu:
Lưu ý rằng json_extract_path_text có giới hạn độ dài là 64 KB. Ngoài ra, bộ lọc from_varbye ghi lớn hơn 65KB.
- Làm mới dữ liệu.
Chế độ xem cụ thể hóa luồng Amazon Redshift được Amazon Redshift tự động làm mới cho bạn. Bằng cách này, bạn không cần phải lo lắng về độ ổn định của dữ liệu. Với tính năng tự động làm mới chế độ xem cụ thể hóa, dữ liệu sẽ tự động được tải vào Amazon Redshift khi dữ liệu có sẵn trong luồng. Nếu bạn chọn thực hiện thao tác này theo cách thủ công, hãy sử dụng lệnh sau:
- Bây giờ, hãy truy vấn chế độ xem cụ thể hóa luồng để xem dữ liệu mẫu:

- Bây giờ hãy kiểm tra xem có bao nhiêu bản ghi trong chế độ xem trực tuyến:

Bây giờ, bạn đã hoàn tất thiết lập chế độ xem nhập dữ liệu trực tuyến Amazon Redshift, chế độ này được cập nhật liên tục với dữ liệu giao dịch thẻ tín dụng đến. Trong quá trình thiết lập của mình, tôi thấy rằng có khoảng 67,000 bản ghi đã được đưa vào chế độ xem phát trực tuyến vào thời điểm tôi chạy truy vấn số lượng đã chọn của mình. Con số này có thể khác với bạn.
Dịch chuyển đỏ ML
Với Redshift ML, bạn có thể sử dụng mô hình ML được đào tạo trước hoặc xây dựng mô hình nguyên bản. Để biết thêm thông tin, hãy tham khảo Sử dụng máy học trong Amazon Redshift.
Trong bài đăng này, chúng tôi đào tạo và xây dựng một mô hình ML bằng cách sử dụng bộ dữ liệu lịch sử. Dữ liệu chứa một tx_fraud trường đánh dấu một giao dịch lịch sử là gian lận hay không. Chúng tôi xây dựng một mô hình ML được giám sát bằng cách sử dụng Redshift Auto ML. Mô hình này học hỏi từ bộ dữ liệu này và dự đoán các giao dịch đến khi các giao dịch đó được chạy thông qua các chức năng dự đoán.
Trong các phần sau, chúng tôi trình bày cách thiết lập tập dữ liệu lịch sử và dữ liệu khách hàng.
Tải tập dữ liệu lịch sử
Bảng lịch sử có nhiều trường hơn so với những gì nguồn dữ liệu phát trực tuyến có. Các trường này chứa chi tiêu gần đây nhất của khách hàng và điểm rủi ro cuối cùng, chẳng hạn như số lượng giao dịch gian lận được tính bằng cách chuyển đổi dữ liệu truyền trực tuyến. Ngoài ra còn có các biến phân loại như giao dịch cuối tuần hoặc giao dịch ban đêm.
Để tải dữ liệu lịch sử, hãy chạy các lệnh bằng cách sử dụng Trình chỉnh sửa truy vấn Amazon Redshift.
Tạo bảng lịch sử giao dịch với đoạn mã sau. DDL cũng có thể được tìm thấy trên GitHub.
Hãy kiểm tra xem có bao nhiêu giao dịch được tải:
Kiểm tra xu hướng giao dịch gian lận và không gian lận hàng tháng:
Tạo và tải dữ liệu khách hàng
Bây giờ chúng ta tạo bảng khách hàng và tải dữ liệu chứa email và số điện thoại của khách hàng. Đoạn mã sau tạo bảng, tải dữ liệu và lấy mẫu bảng. Bảng DDL có sẵn trên GitHub.
Dữ liệu thử nghiệm của chúng tôi có khoảng 5,000 khách hàng. Ảnh chụp màn hình sau đây hiển thị dữ liệu khách hàng mẫu.

Xây dựng mô hình ML
Bảng giao dịch thẻ lịch sử của chúng tôi có dữ liệu trong 6 tháng, hiện chúng tôi sử dụng dữ liệu này để đào tạo và thử nghiệm mô hình ML.
Mô hình lấy các trường sau làm đầu vào:
Chúng tôi nhận được tx_fraud dưới dạng đầu ra.
Chúng tôi chia dữ liệu này thành tập dữ liệu huấn luyện và kiểm tra. Các giao dịch từ 2022-04-01 đến 2022-07-31 là dành cho tập huấn luyện. Các giao dịch từ 2022-08-01 đến 2022-09-30 được sử dụng cho bộ thử nghiệm.
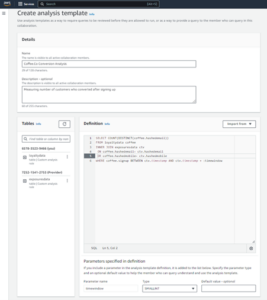
Hãy tạo mô hình ML bằng SQL quen thuộc Câu lệnh TẠO MÔ HÌNH. Chúng tôi sử dụng một dạng cơ bản của lệnh Redshift ML. Phương pháp sau sử dụng Amazon SageMaker Tự động lái, thực hiện chuẩn bị dữ liệu, kỹ thuật tính năng, lựa chọn mô hình và đào tạo tự động cho bạn. Cung cấp tên của bộ chứa S3 có chứa mã.
Tôi gọi mô hình ML là Cust_cc_txn_fd, và chức năng dự đoán như fn_customer_cc_fd. Mệnh đề TỪ hiển thị các cột đầu vào từ bảng lịch sử public.cust_payment_tx_history. Tham số mục tiêu được đặt thành tx_fraud, là biến mục tiêu mà chúng tôi đang cố gắng dự đoán. IAM_Role được đặt thành mặc định vì cụm được cấu hình với vai trò này; nếu không, bạn phải cung cấp ARN vai trò IAM cụm Amazon Redshift của mình. tôi đặt max_runtime đến 3,600 giây, đây là thời gian chúng tôi cung cấp cho SageMaker để hoàn tất quy trình. Redshift ML triển khai mô hình tốt nhất được xác định trong khung thời gian này.
Tùy thuộc vào độ phức tạp của mô hình và lượng dữ liệu, có thể mất một khoảng thời gian để mô hình khả dụng. Nếu bạn thấy lựa chọn mô hình của mình chưa hoàn thành, hãy tăng giá trị cho max_runtime. Bạn có thể đặt giá trị tối đa là 9999.
Lệnh CREATE MODEL được chạy không đồng bộ, có nghĩa là nó chạy ở chế độ nền. Bạn có thể dùng HIỂN THỊ MÔ HÌNH lệnh để xem trạng thái của mô hình. Khi trạng thái hiển thị là Sẵn sàng, điều đó có nghĩa là mô hình được đào tạo và triển khai.
Các ảnh chụp màn hình sau đây hiển thị đầu ra của chúng tôi.



Từ đầu ra, tôi thấy rằng mô hình đã được công nhận chính xác là BinaryClassification, và F1 đã được chọn làm mục tiêu. Các Điểm F1 là một số liệu xem xét cả hai độ chính xác và thu hồi. Nó trả về một giá trị trong khoảng từ 1 (độ chính xác và thu hồi hoàn hảo) đến 0 (điểm thấp nhất có thể). Trong trường hợp của tôi, nó là 0.91. Giá trị càng cao, hiệu suất mô hình càng tốt.
Hãy kiểm tra mô hình này với tập dữ liệu thử nghiệm. Chạy lệnh sau để truy xuất các dự đoán mẫu:

Chúng tôi thấy rằng một số giá trị phù hợp và một số thì không. Hãy so sánh các dự đoán với sự thật cơ bản:

Chúng tôi xác nhận rằng mô hình đang hoạt động và điểm F1 là tốt. Hãy chuyển sang tạo dự đoán về dữ liệu phát trực tuyến.
Dự đoán các giao dịch gian lận
Vì mô hình Redshift ML đã sẵn sàng để sử dụng nên chúng tôi có thể sử dụng mô hình này để chạy các dự đoán đối với quá trình nhập dữ liệu trực tuyến. Tập dữ liệu lịch sử có nhiều trường hơn những gì chúng tôi có trong nguồn dữ liệu phát trực tuyến, nhưng chúng chỉ là các chỉ số tần suất và lần truy cập gần đây về khách hàng và rủi ro cuối cùng đối với một giao dịch gian lận.
Chúng ta có thể áp dụng các phép biến đổi trên dữ liệu phát trực tuyến rất dễ dàng bằng cách nhúng SQL bên trong các dạng xem. tạo Lần đầu tiên xem, tổng hợp dữ liệu phát trực tuyến ở cấp độ khách hàng. Sau đó tạo góc nhìn thứ hai, tổng hợp dữ liệu phát trực tuyến ở cấp độ thiết bị đầu cuối và góc nhìn thứ ba, kết hợp dữ liệu giao dịch đến với dữ liệu tổng hợp của khách hàng và thiết bị đầu cuối, đồng thời gọi tất cả chức năng dự đoán ở một nơi. Mã cho chế độ xem thứ ba như sau:
Chạy một câu lệnh CHỌN trên dạng xem:
Khi bạn chạy câu lệnh SELECT nhiều lần, các giao dịch thẻ tín dụng mới nhất sẽ trải qua các phép biến đổi và dự đoán ML trong thời gian gần như thực.
Điều này thể hiện sức mạnh của Amazon Redshift—với các lệnh SQL dễ sử dụng, bạn có thể chuyển đổi dữ liệu truyền trực tuyến bằng cách áp dụng các chức năng cửa sổ phức tạp và áp dụng mô hình ML để dự đoán tất cả các giao dịch gian lận trong một bước mà không cần xây dựng đường dẫn dữ liệu phức tạp hay xây dựng và quản lý cơ sở hạ tầng bổ sung.
Mở rộng giải pháp
Vì các luồng dữ liệu trong và các dự đoán ML được thực hiện trong thời gian gần như thực, nên bạn có thể xây dựng các quy trình kinh doanh để cảnh báo cho khách hàng của mình bằng cách sử dụng Dịch vụ thông báo đơn giản của Amazon (Amazon SNS) hoặc bạn có thể khóa tài khoản thẻ tín dụng của khách hàng trong một hệ thống hoạt động.
Bài đăng này không đi sâu vào chi tiết của các hoạt động này, nhưng nếu bạn muốn tìm hiểu thêm về cách xây dựng các giải pháp hướng sự kiện bằng Amazon Redshift, hãy tham khảo phần sau Kho GitHub.
Làm sạch
Để tránh bị tính phí trong tương lai, hãy xóa các tài nguyên đã được tạo như một phần của bài đăng này.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách thiết lập luồng dữ liệu Kinesis, định cấu hình trình tạo và xuất bản dữ liệu lên luồng, sau đó tạo chế độ xem Nhập liệu truyền trực tuyến Amazon Redshift và truy vấn dữ liệu trong Amazon Redshift. Sau khi dữ liệu nằm trong cụm Amazon Redshift, chúng tôi đã trình bày cách đào tạo một mô hình ML và xây dựng một hàm dự đoán, đồng thời áp dụng nó với dữ liệu truyền trực tuyến để tạo ra các dự đoán gần với thời gian thực.
Nếu bạn có bất kỳ phản hồi hoặc câu hỏi nào, vui lòng để lại trong phần bình luận.
Về các tác giả
 Bhanu Pittampally là Kiến trúc sư Giải pháp Chuyên gia Phân tích có trụ sở tại Dallas. Ông chuyên xây dựng các giải pháp phân tích. Nền tảng của anh ấy là về kho dữ liệu—kiến trúc, phát triển và quản trị. Ông đã làm việc trong lĩnh vực dữ liệu và phân tích hơn 15 năm.
Bhanu Pittampally là Kiến trúc sư Giải pháp Chuyên gia Phân tích có trụ sở tại Dallas. Ông chuyên xây dựng các giải pháp phân tích. Nền tảng của anh ấy là về kho dữ liệu—kiến trúc, phát triển và quản trị. Ông đã làm việc trong lĩnh vực dữ liệu và phân tích hơn 15 năm.
 Praveen Kadipikonda là Kiến trúc sư giải pháp chuyên gia phân tích cấp cao tại AWS có trụ sở tại Dallas. Anh ấy giúp khách hàng xây dựng các giải pháp phân tích hiệu quả, hiệu quả và có thể mở rộng. Ông đã làm việc với việc xây dựng cơ sở dữ liệu và các giải pháp kho dữ liệu trong hơn 15 năm.
Praveen Kadipikonda là Kiến trúc sư giải pháp chuyên gia phân tích cấp cao tại AWS có trụ sở tại Dallas. Anh ấy giúp khách hàng xây dựng các giải pháp phân tích hiệu quả, hiệu quả và có thể mở rộng. Ông đã làm việc với việc xây dựng cơ sở dữ liệu và các giải pháp kho dữ liệu trong hơn 15 năm.
 Ritesh Kumar Sinha là Kiến trúc sư giải pháp chuyên gia phân tích có trụ sở tại San Francisco. Ông đã giúp khách hàng xây dựng các giải pháp dữ liệu lớn và kho dữ liệu có thể mở rộng trong hơn 16 năm. Anh ấy thích thiết kế và xây dựng các giải pháp đầu cuối hiệu quả trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách, đi bộ và tập yoga.
Ritesh Kumar Sinha là Kiến trúc sư giải pháp chuyên gia phân tích có trụ sở tại San Francisco. Ông đã giúp khách hàng xây dựng các giải pháp dữ liệu lớn và kho dữ liệu có thể mở rộng trong hơn 16 năm. Anh ấy thích thiết kế và xây dựng các giải pháp đầu cuối hiệu quả trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách, đi bộ và tập yoga.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- 000 khách hàng
- 1
- 10
- 100
- 11
- 15 năm
- 67
- 7
- 9
- a
- Có khả năng
- Giới thiệu
- ở trên
- truy cập
- Tài khoản
- Đạt được
- Hoạt động
- thêm vào
- quản lý
- tiên tiến
- Sau
- chống lại
- Cảnh báo
- Tất cả
- cho phép
- đàn bà gan dạ
- Amazon EC2
- Amazon Kinesis
- số lượng
- Các nhà phân tích
- Phân tích
- phân tích
- phân tích
- và
- phát hiện bất thường
- Apache
- Các Ứng Dụng
- Đăng Nhập
- Nộp đơn
- kiến trúc
- xung quanh
- đính kèm
- tự động
- Tự động
- tự động
- có sẵn
- tránh
- AWS
- lý lịch
- dựa
- cơ bản
- bởi vì
- trở thành
- BEST
- Hơn
- giữa
- lớn
- Dữ Liệu Lớn.
- mang lại
- xây dựng
- Xây dựng
- kinh doanh
- quy trình kinh doanh
- các doanh nghiệp
- cuộc gọi
- gọi là
- Cuộc gọi
- nắm bắt
- thẻ
- trường hợp
- trường hợp
- tính cách
- tải
- kiểm tra
- Chọn
- City
- đám mây
- cụm
- mã
- Cột
- kết hợp
- đến
- Bình luận
- so sánh
- hoàn thành
- hoàn thành
- phức tạp
- phức tạp
- Tính
- xem xét
- An ủi
- ăn
- người tiêu dùng
- chứa
- chi phí-hiệu quả
- có thể
- tạo
- tạo ra
- tạo ra
- Tạo
- Credentials
- tín dụng
- thẻ tín dụng
- khách hàng
- dữ liệu khách hàng
- khách hàng
- chu kỳ
- tiền thưởng
- Dallas
- dữ liệu
- Chuẩn bị dữ liệu
- kho dữ liệu
- Kho dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- bộ dữ liệu
- Ngày
- Ra quyết định
- Mặc định
- xác định
- cung cấp
- chứng minh
- phụ thuộc
- triển khai
- triển khai
- triển khai
- mô tả
- Thiết kế
- chi tiết
- Phát hiện
- phát triển
- Phát triển
- khác nhau
- trực tiếp
- Không
- làm
- dont
- dow
- năng động
- dễ dàng
- dễ sử dụng
- hiệu lực
- hiệu quả
- cho phép
- cho phép
- Cuối cùng đến cuối
- Kỹ Sư
- đăng ký hạng mục thi
- Ether (ETH)
- Sự kiện
- sự kiện
- ví dụ
- kích thích
- ngoài
- khai thác
- f1
- quen
- NHANH
- Đặc tính
- Tính năng
- thông tin phản hồi
- lĩnh vực
- Lĩnh vực
- bộ lọc
- tài chính
- Tìm kiếm
- cờ
- dòng chảy
- theo
- tiếp theo
- sau
- hình thức
- định dạng
- tìm thấy
- FRAME
- Francisco
- gian lận
- phát hiện gian lận
- Miễn phí
- tần số
- từ
- đầy đủ
- chức năng
- chức năng
- tương lai
- tạo ra
- tạo ra
- tạo ra
- máy phát điện
- được
- Cho
- Go
- tốt
- cấp
- Mặt đất
- Nhóm
- có
- đã giúp
- giúp
- cao hơn
- Đánh dấu
- lịch sử
- lịch sử
- Độ đáng tin của
- Hướng dẫn
- HTML
- HTTPS
- Hàng trăm
- IAM
- xác định
- Bản sắc
- tầm quan trọng
- in
- bao gồm
- Incoming
- Tăng lên
- tăng
- hệ thống riêng biệt,
- thông tin
- Cơ sở hạ tầng
- đầu vào
- Chèn
- những hiểu biết
- cài đặt, dựng lên
- ví dụ
- Viện
- hướng dẫn
- quan tâm
- IT
- tham gia
- json
- Kafka
- Luồng dữ liệu Kinesis
- Ngôn ngữ
- lớn hơn
- Độ trễ
- mới nhất
- phóng
- học tập
- Rời bỏ
- Chiều dài
- Cấp
- LIMIT
- giới hạn
- tải
- tải
- lâu
- Thấp
- máy
- học máy
- thực hiện
- làm cho
- LÀM CHO
- quản lý
- quản lý
- thủ công
- nhiều
- bản đồ
- ồ ạt
- phù hợp
- matplotlib
- tối đa
- có nghĩa
- Phương tiện truyền thông
- phương pháp
- số liệu
- Metrics
- Giảm nhẹ
- ML
- Chế độ
- kiểu mẫu
- mô hình
- hàng tháng
- tháng
- chi tiết
- hầu hết
- di chuyển
- tên
- THÔNG TIN
- Cần
- nhu cầu
- Mới
- tiếp theo
- thông báo
- con số
- cục mịch
- Mục tiêu
- ONE
- mở ra
- hoạt động
- hoạt động
- Hoạt động
- Cơ hội
- Các lựa chọn
- gọi món
- tổ chức
- Nền tảng khác
- nêu
- gói
- gấu trúc
- cửa sổ
- tham số
- một phần
- hoàn hảo
- thực hiện
- hiệu suất
- thực hiện
- quyền
- điện thoại
- Nơi
- lập kế hoạch
- nền tảng
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- xin vui lòng
- Chính sách
- điều luật
- có thể
- Bài đăng
- quyền lực
- Độ chính xác
- dự đoán
- dự đoán
- Dự đoán
- Dự đoán
- trước
- giá
- quá trình
- Quy trình
- sản xuất
- chương trình
- cho
- cung cấp
- công khai
- xuất bản
- Python
- Câu hỏi
- Mau
- ngẫu nhiên
- Reading
- sẵn sàng
- thực
- thời gian thực
- dữ liệu theo thời gian thực
- nhận ra
- nhận
- nhận
- gần đây
- công nhận
- hồ sơ
- NHIỀU LẦN
- thay thế
- cần phải
- tài nguyên
- Thông tin
- REST của
- Kết quả
- Trả về
- Nguy cơ
- Vai trò
- chạy
- chạy
- nhà làm hiền triết
- San
- San Francisco
- khả năng mở rộng
- Quy mô
- ảnh chụp màn hình
- sdk
- sơ sinh
- Thứ hai
- giây
- Phần
- phần
- an toàn
- chọn
- lựa chọn
- Không có máy chủ
- dịch vụ
- định
- thiết lập
- thiết lập
- thiết lập
- thời gian ngắn
- hiển thị
- Chương trình
- Đơn giản
- đơn giản hóa
- mô phỏng
- So
- Mạng xã hội
- truyền thông xã hội
- giải pháp
- Giải pháp
- một số
- nguồn
- nguồn
- chuyên gia
- chuyên
- tiêu
- chia
- SQL
- Traineeship
- Tiêu chuẩn
- bắt đầu
- Tiểu bang
- Tuyên bố
- báo cáo
- Trạng thái
- Bước
- Các bước
- là gắn
- hàng
- cửa hàng
- Chiến lược
- dòng
- trực tuyến
- Dịch vụ truyền trực tuyến
- dòng
- như vậy
- lớn
- hệ thống
- hệ thống
- bàn
- Hãy
- mất
- Các cuộc đàm phán
- Mục tiêu
- Thiết bị đầu cuối
- thử nghiệm
- Sản phẩm
- Thứ ba
- hàng ngàn
- Thông qua
- thời gian
- dấu thời gian
- đến
- hàng đầu
- chủ đề
- theo truyền thống
- Train
- đào tạo
- Hội thảo
- giao dịch
- giao dịch
- Giao dịch
- Chuyển đổi
- biến đổi
- biến đổi
- khuynh hướng
- Cập nhật
- cập nhật
- Sử dụng
- sử dụng
- người sử dang
- xác nhận
- giá trị
- Các giá trị
- khác nhau
- Sự thật
- phiên bản
- Xem
- Lượt xem
- đi bộ
- hương
- Kho
- Kho bãi
- Website
- cuối tuần
- hàng tuần
- Điều gì
- cái nào
- trong khi
- Wikipedia
- sẽ
- không có
- làm việc
- đang làm việc
- công trinh
- viết
- năm
- Yoga
- trên màn hình
- zephyrnet