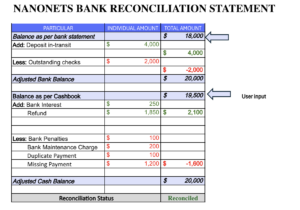
Що таке обробка документів?

Обробка документів — це процес автоматизації вилучення структурованих даних із документів. Це може бути будь-який документ, скажімо, рахунок-фактура, резюме, посвідчення особи тощо. Складною частиною тут є не лише OCR. Існує багато варіантів, доступних за невелику ціну, які можуть витягти текст і надати вам місцезнаходження. Справжнє завдання полягає в тому, щоб точно й автоматично позначити ці фрагменти тексту.
Вплив обробки документів на бізнес
Декілька галузей промисловості значною мірою покладаються на обробку документів у своїй щоденній діяльності. Фінансовим організаціям потрібен доступ до документів SEC, страхових документів, компаніям електронної комерції чи ланцюгу поставок може знадобитися доступ до рахунків-фактур, які використовуються, список можна продовжувати. Точність цієї інформації так само важлива, як і економія часу, тому ми завжди рекомендуємо використовувати передові методи глибокого навчання, які є більш узагальненими та точнішими.
Відповідно до цього звіту PwC, [link] навіть найелементарніший обсяг вилучення структурованих даних може допомогти заощадити 30-50% часу співробітників, витраченого на ручне копіювання та вставлення даних із PDF-файлів до електронних таблиць Excel. Такі моделі, як LayoutLM, безумовно, не є рудиментарними, вони створені як надзвичайно інтелектуальні агенти, здатні точно отримувати масштабні дані в різних випадках використання. Навіть з багатьма нашими власними клієнтами ми скоротили час, необхідний для вилучення даних вручну, з 20 хвилин на документ до 10 секунд. Це масштабна зміна, що дозволяє працівникам бути більш продуктивними та підвищити загальну продуктивність.
Тож де можна застосувати ШІ, подібний до LayoutLM? У Nanonets ми використовували таку технологію для
і багато інших випадків використання.
Чому LayoutLM?
Як модель глибокого навчання розуміє, чи є даний фрагмент тексту описом товару в рахунку-фактурі чи номером рахунку-фактури? Простіше кажучи, як модель навчиться правильно призначати мітки?
Одним із методів є використання вбудованих текстів із масивної мовної моделі, як-от BERT або GPT-3, і запуск через класифікатор, хоча це не дуже ефективно. Існує багато інформації, яку неможливо оцінити лише за допомогою тексту. Або можна використати інформацію на основі зображень. Це було досягнуто за допомогою моделей R-CNN і Faster R-CNN. Однак це ще не повною мірою використовує інформацію, наявну в документах. Інший застосований підхід був із згортковими нейронними мережами Graph, які поєднували інформацію про місцезнаходження та текстову інформацію, але не враховували інформацію про зображення.
Отже, як ми використовуємо всі три виміри інформації, тобто текст, зображення та розташування даного тексту? Ось тут і з’являються такі моделі, як LayoutLM. Незважаючи на те, що LayoutLM була предметом активних досліджень протягом багатьох років тому, вона була однією з перших моделей, яка досягла успіху, об’єднавши частини для створення єдиної моделі, яка виконує маркування з використанням позиційної інформації, текстової інформації, а також інформацію про зображення.
Підручник LayoutLM
У цій статті передбачається, що ви розумієте, що таке модель мови. Якщо ні, не хвилюйтеся, ми також написали статтю про це! Якщо ви хочете дізнатися більше про те, що таке моделі трансформери і що таке увага, тут це чудова стаття Джея Аламмара.
Припускаючи, що ми розібралися з цими речами, давайте почнемо з підручника. Ми будемо використовувати оригінальний документ LayoutLM як основне посилання.
Вилучення тексту OCR
Найперше, що ми робимо з документом, це витягти текстову інформацію з документа та знайти їх відповідне розташування. Під місцезнаходженням ми називаємо так звану «обмежувальну рамку». Обмежувальна рамка — це прямокутник, який охоплює фрагмент тексту на сторінці.

У більшості випадків передбачається, що обмежувальна рамка має початок у верхньому лівому куті, і що додатна вісь x спрямована від початку координат управо на сторінці, а додатна вісь y спрямована від початку до унизу сторінки, одиницею вимірювання вважається один піксель.
Вбудовування мови та розташування
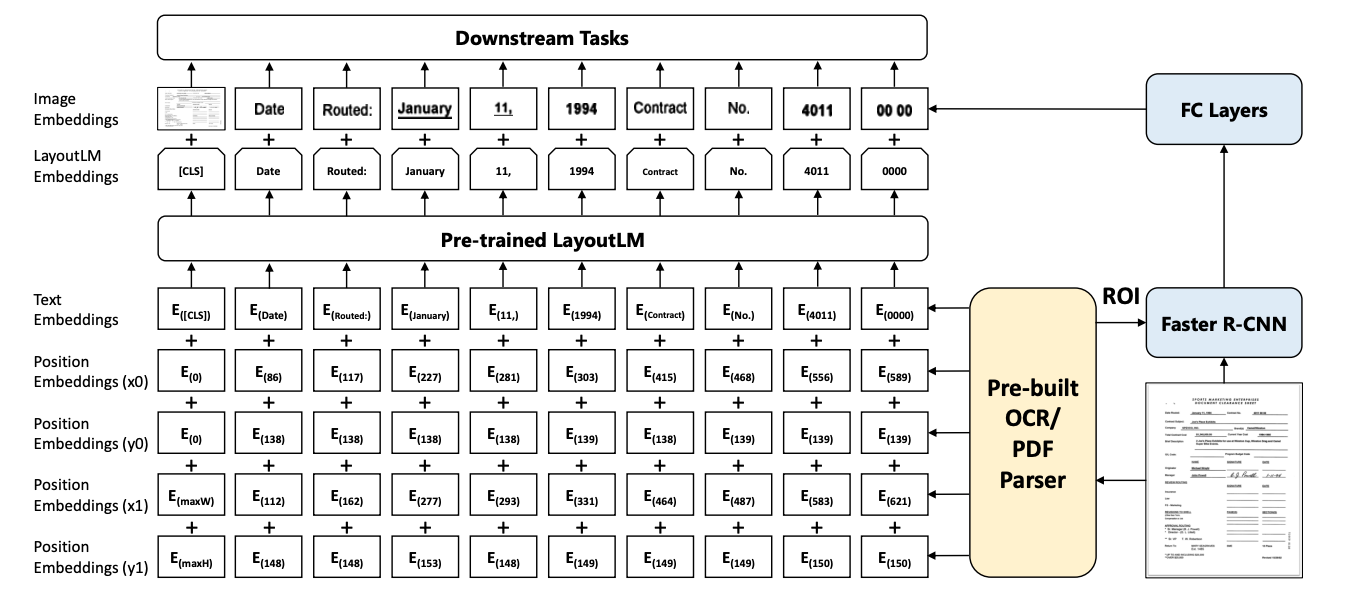
Далі ми використовуємо п’ять різних шарів вбудовування. По-перше, це кодування інформації, пов’язаної з мовою, тобто вставлення тексту.
Інші чотири зарезервовано для вбудовування місцезнаходження. Припускаючи, що ми знаємо значення xmin, ymin, xmax і ymax, ми можемо визначити всю обмежувальну рамку (якщо ви не можете це уявити, ось вам посилання). Ці координати передаються через відповідні шари вбудовування для кодування інформації про місцезнаходження.
Потім п’ять вбудовувань – одне для тексту та чотири для координат – додаються, щоб створити остаточне значення вбудовування, яке передається через LayoutLM. Результат називається вбудовуванням LayoutLM.
Вбудовування зображень
Гаразд, отже, нам вдалося знайти інформацію, пов’язану з текстом і розташуванням, об’єднавши їх вбудовування та передавши її через мовну модель. Тепер як ми обійдемо процес об’єднання інформації, пов’язаної з зображенням, у ньому?
Поки текст і інформація про макет кодуються, паралельно ми використовуємо Faster R-CNN для вилучення областей тексту, пов’язаних із документом. Faster R-CNN — це модель зображення, яка використовується для виявлення об’єктів. У нашому випадку ми використовуємо його для виявлення різних фрагментів тексту (припускаючи, що кожна фраза є об’єктом), а потім пропускаємо сегментовані зображення через повністю пов’язаний рівень, щоб також допомогти створити вбудовування для зображень.
Вбудовування LayoutLM, а також вбудовування зображень об’єднуються для створення остаточного вбудовування, яке потім можна використовувати для виконання подальшої обробки.
Попереднє навчання LayoutLM
Усе вищесказане має сенс, лише якщо ми розуміємо метод, за яким навчався LayoutLM. Зрештою, незалежно від того, які зв’язки ми встановлюємо в нейронній мережі, доки вона не навчена з правильною метою навчання, вона не зовсім розумна. Автори LayoutLM хотіли застосувати метод, схожий на той, який використовувався для попереднього навчання BERT.
Маскована візуальна модель мови (MVLM)
Щоб допомогти моделі дізнатися, який текст міг бути в певному місці, автори випадковим чином замаскували кілька маркерів тексту, зберігаючи інформацію, пов’язану з місцем розташування, і вбудовування. Це дозволило LayoutLM вийти за рамки простого моделювання замаскованої мови, а також допомогло пов’язати вбудовування тексту з модальностями, пов’язаними з розташуванням.
Класифікація документів з кількома мітками (MDC)
Використання всієї інформації в документі для класифікації його за категоріями допомагає моделі зрозуміти, яка інформація має відношення до певного класу документів. Однак автори відзначають, що для великих наборів даних дані про класи документів можуть бути недоступні. Таким чином, вони забезпечили базу результатів як лише навчання MVLM, так і навчання MVLM + MDC.
Точне налаштування LayoutLM для подальших завдань
Існує кілька наступних завдань, які можна виконати за допомогою LayoutLM. Ми обговоримо ті, за які взялися автори.
Розуміння форми
Це завдання пов’язує тип мітки з певним фрагментом тексту. Використовуючи це, ми можемо отримати структуровані дані з будь-якого документа. Враховуючи кінцевий результат, тобто вбудовування LayouLM + вбудовування зображень, вони проходять через повністю пов’язаний рівень, а потім через softmax для прогнозування ймовірностей класу для мітки даного фрагмента тексту.
Отримання Розуміння
У цьому завданні кілька слотів інформації були залишені порожніми на квитанціях, і модель мала правильно розташувати фрагменти тексту у відповідних слотах.
Класифікація зображень документа
Інформація з тексту та зображення документа поєднується, щоб допомогти зрозуміти клас документа, просто пропускаючи його через шар softmax.
Huggingface LayoutLM
Одна з головних причин, чому LayoutLM так багато обговорюється, полягає в тому, що модель була відкритого коду деякий час тому. Це є доступний на Hugging Face, тому використання LayoutLM тепер значно легше.
Перш ніж ми заглибимося в деталі того, як ви можете точно налаштувати LayoutLM для власних потреб, слід взяти до уваги кілька речей.
Встановлення бібліотек
Щоб запустити LayoutLM, вам знадобиться бібліотека transformers від Hugging Face, яка, у свою чергу, залежить від бібліотеки PyTorch. Щоб установити їх (якщо ще не встановлено), виконайте наступні команди
На обмежувальних рамках
Щоб створити єдину схему вбудовування незалежно від розміру зображення, координати обмежувальної рамки нормалізуються в масштабі 1000
конфігурація
Використовуючи клас transformers.LayoutLMConfig, ви можете встановити розмір моделі так, щоб вона найкраще відповідала вашим вимогам, оскільки ці моделі, як правило, важкі та потребують достатньої обчислювальної потужності. Налаштування меншої моделі може допомогти вам запустити його локально. Ти можеш дізнайтеся більше про клас тут.
LayoutLM для класифікації документів (посилання)
Якщо ви хочете виконати класифікацію документів, вам знадобиться клас transformers.LayoutLMForSequenceClassification. Послідовність тут — це послідовність тексту з документа, який ви вилучили. Ось невеликий зразок коду від Hugging Face.co, який пояснює, як ним користуватися
LayoutLM для маркування тексту (посилання)
Для виконання семантичного маркування, тобто призначення міток різним частинам тексту в документі, вам знадобиться клас transformers.LayoutLMForTokenClassification. Ви можете знайти більше деталей на те ж саме.Ось невеликий зразок коду, щоб побачити, як він може працювати для вас
Деякі моменти, які слід зауважити щодо Hugging Face LayoutLM
- Зараз модель Hugging Face LayoutLM використовує бібліотеку з відкритим вихідним кодом Tesseract для вилучення тексту, що є не дуже точним. Ви можете розглянути можливість використання іншого платного інструменту OCR, як-от AWS Texttract або Google Cloud Vision
- Існуюча модель надає лише мовну модель, тобто вбудовування LayoutLM, а не кінцеві шари, які поєднують візуальні функції. МакетLMv2 (обговорюється в наступному розділі) використовує бібліотеку Detectron, щоб також увімкнути вбудовування візуальних функцій.
- Класифікація міток відбувається на рівні слова, тому механізм вилучення тексту OCR насправді повинен переконатися, що всі слова в полі розташовані в безперервній послідовності, інакше одне поле може бути передбачено як два.
МакетLMv2
LayoutLM став революцією в способах вилучення даних із документів. Однак, що стосується досліджень глибокого навчання, моделі з часом лише вдосконалюються. На зміну LayoutLM прийшов LayoutLMv2, де автори внесли кілька суттєвих змін у процес навчання моделі.
Включаючи 1-D просторові вбудовування та вбудовування візуальних маркерів
LayoutLMv2 містив інформацію щодо відносного 1-D розташування, а також загальну інформацію про зображення. Це важливо через нові цілі навчання, які ми зараз обговоримо
Нові цілі навчання
LayoutLMv2 містив деякі змінені цілі навчання. Це такі:
- Моделювання замаскованої візуальної мови: це те саме, що й у LayoutLM
- Вирівнювання текстового зображення: текст був випадковим чином закритий із зображення, тоді як текстові маркери були надані моделі. Для кожного токена модель повинна була дізнатися, чи був заданий текст покритий чи ні. Завдяки цьому модель змогла поєднати інформацію з візуальної та текстової модальностей
- Зіставлення текстового зображення: моделі пропонується перевірити, чи дане зображення відповідає заданому тексту. Негативні зразки або подаються як фальшиві зображення, або взагалі не надаються вбудовані зображення. Це робиться для того, щоб модель дізналася більше про те, як пов’язані текст і зображення.
Використовуючи ці нові методи та вбудовування, модель змогла отримати вищі оцінки F1 майже на всіх тестових наборах даних, як LayoutLM.
- МЕНЮ
- доступ
- рахунки
- точний
- досягнутий
- через
- активний
- просунутий
- агенти
- AI
- ВСІ
- вже
- хоча
- кількість
- Інший
- підхід
- ПЛОЩА
- навколо
- стаття
- authors
- доступний
- AWS
- основа
- буття
- КРАЩЕ
- Біт
- Box
- Cards
- випадків
- виклик
- класифікація
- хмара
- код
- комбінований
- компанія
- обчислення
- конфігурація
- Зв'язки
- розгляду
- витрати
- може
- Клієнти
- дані
- день
- Незважаючи на
- Виявлення
- DID
- різний
- документація
- вниз
- e-commerce
- Ефективний
- дозволяє
- встановити
- перевершувати
- Face
- швидше
- особливість
- риси
- Fed
- фінансовий
- Перший
- після
- породжувати
- GitHub
- допомога
- допомагає
- тут
- Як
- How To
- HTTPS
- зображення
- Impact
- важливо
- удосконалювати
- включені
- промисловості
- інформація
- страхування
- Розумний
- IT
- маркування
- етикетки
- мова
- більше
- УЧИТЬСЯ
- вивчення
- рівень
- бібліотека
- LINK
- список
- локально
- розташування
- місць
- вручну
- масивний
- узгодження
- Матерія
- модель
- Моделі
- найбільш
- мережу
- мереж
- відкрити
- з відкритим вихідним кодом
- операції
- Опції
- порядок
- організації
- Інше
- оплачувану
- Папір
- частина
- влада
- процес
- забезпечує
- PWC
- Причини
- рекомендувати
- звітом
- вимагається
- Вимога
- дослідження
- результати
- резюме
- прогін
- шкала
- схема
- SEC
- сенс
- комплект
- установка
- зсув
- значний
- аналогічний
- простий
- Розмір
- невеликий
- розумний
- So
- що в сім'ї щось
- почалася
- успіх
- поставка
- ланцюжка поставок
- завдання
- Технологія
- тест
- через
- час
- знак
- Жетони
- топ
- Навчання
- розуміти
- використання
- використовувати
- значення
- Що
- Чи
- слова
- Work
- робочі
- років