29 січня відзначається Національний день головоломок, і в цей день ми створили цікавий блог, у якому докладно розповідається про те, як розгадувати судоку за допомогою штучного інтелекту (ШІ).
Вступ
Перед тим як wordle, Головоломка судоку був у моді, і він досі дуже популярний. В останні роки використання оптимізація Методи вирішення головоломки були домінуючою темою. Побачити «Рішення судоку за допомогою оптимізації в Аркієві".
У наш час використання штучного інтелекту зосереджено на машинному навчанні, яке охоплює широкий спектр методів від ласо-регресії до навчання з підкріпленням. Використання ШІ має знову виникла вирішувати комплекс планування виклики. Один із методів, пошук із зворотним відстеженням, широко використовується та ідеально підходить для судоку.
У цьому блозі буде надано детальний опис того, як використовувати цей метод для вирішення судоку. Як виявилося, «зворотне відстеження» можна знайти в механізмах оптимізації та машинного навчання, і воно є наріжним каменем розширеної евристики, яку Arkieva використовує для планування. Алгоритм реалізовано на «мові програмування масивів», функціонально-орієнтованій мові програмування, яка обробляє багатий набір структур масиву.
Основи Судоку
З Вікіпедії: Судоку — це логічна комбінаторна головоломка з розставленням чисел. Мета полягає в тому, щоб заповнити сітку 9×9 цифрами так, щоб кожен стовпець, кожен рядок і кожна з дев’яти підсіток 3×3, які складають сітку (також звані «коробки», «блоки», «регіони», або «підквадрати») містить усі цифри від 1 до 9. Набір головоломок надає частково заповнену сітку, яка зазвичай має унікальне рішення. Готові головоломки завжди є типом латинського квадрата з додатковим обмеженням на вміст окремих областей. Наприклад, одне й те саме ціле число не може з’являтися двічі в одному рядку чи стовпці ігрової дошки 9×9 або в будь-якій із дев’яти підобластей 3×3 ігрової дошки 9×9.
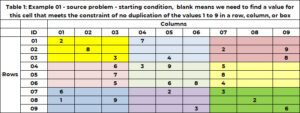
У таблиці 1 є приклад проблеми. Є 9 рядків і 9 стовпців, загалом 81 клітинка. Кожному дозволено мати одне й лише одне з дев’яти цілих чисел від 1 до 9. У початковому рішенні клітинка або має одне значення, яке фіксує значення в цій клітинці до цього значення, або клітинка порожня, що означає, що нам потрібно щоб знайти значення для цієї комірки. Комірка (1,1) має значення 2, а комірка (6,5) — 6. Комірки (1,2) і комірки (2,3) порожні, і алгоритм знайде значення для цих комірок.
Ускладнення
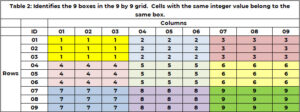
Крім належності до одного і тільки одного рядка та стовпця, комірка належить до одного і тільки 1 ящика. Існує 9 полів, і вони позначені кольором у таблиці 1. У таблиці 2 використовується унікальне ціле число від 1 до 9 для ідентифікації кожного поля чи сітки. Комірки зі значенням рядка (1, 2 або 3) і значенням стовпця (1, 2 або 3) належать до поля 1. Поле 6 містить значення рядка (4, 5, 6) і значення стовпця (7, 8). , 9). Ідентифікатор вікна визначається за формулою BOX_ID = {3x(floor((ROW_ID-1) /3)} + стеля (COL_ID/3). Для клітинки (5,7), 6 = 3x(floor(5-1) ))/3) + стеля (8/3)= 3×1 + 3 = 3+3.
Серце головоломки
Щоб знайти одне ціле число від 1 до 9 для кожної невідомої клітинки, щоб цілі числа від 1 до 9 використовувалися один раз і тільки один раз для кожного стовпця, кожного рядка та кожного поля.
Давайте подивимося на порожню клітинку (1,3). Рядок 1 уже містить значення 2 і 7. Вони не дозволені в цій клітинці. Стовпець 3 вже має значення 3, 5,6, 7,9. Це заборонено. Поле 1 (жовте) містить значення 2, 3 і 8. Це неприпустимо. Наступні значення не допускаються (2,7); (3, 5, 6, 7, 9); (2, 3, 8). Недозволеними унікальними значеннями є (2, 3, 5, 6, 7, 8, 9). Єдиними потенційними значеннями є (1,4).
Підходом до рішення було б тимчасово призначити 1 клітинці (1,3), а потім спробувати знайти потенційні значення для іншої клітинки.
Рішення зворотного відстеження: запуск компонентів
Структура масиву
Початковим пунктом є визначення структури масиву для зберігання вихідної проблеми та підтримки пошуку. Таблиця 3 має таку структуру масиву. Стовпець 1 – це унікальний цілий ідентифікатор для кожної комірки. Діапазон значень від 1 до 81. Стовпець 2 – це ідентифікатор рядка комірки. Стовпець 3 – це ідентифікатор стовпця комірки. Стовпець 4 – це ідентифікатор коробки. Стовпець 5 – це значення в клітинці. Зверніть увагу, що клітинці без значення присвоюється нульове значення замість пустого або нульового значення. Це зберігає цей «лише цілочисельний масив» — набагато кращий за продуктивністю.

В APL цей масив зберігатиметься у двовимірному масиві, форма якого дорівнює 2 на 81. Припустімо, що елементи таблиці 5 зберігаються у змінній MAT. Приклади функцій:
Команда MAT[1 2 3;] захоплює перші 3 рядки MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] захищає рядки 1, 2, 3 і лише стовпці 4 і 5
1 2
1 0
1 0
(MAT[;5]=0)/MAT[;1] знаходить усі клітинки, які потребують значення.
ВСТАВИТИ ТАБЛИЦЮ 3
Перевірка працездатності: дублікати
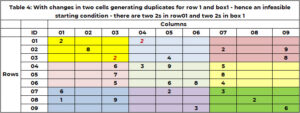
Перш ніж почати пошук, важливо перевірити осудність! Це можливе вихідне рішення. Можливо для Sudoku, якщо тепер є дублікати в будь-якому рядку, стовпці чи полі. Поточне вихідне рішення, наприклад, 1, є можливим. У таблиці 4 наведено приклад, коли вихідний розчин має дублікати. Рядок 1 має два значення 2. Область 1 має два значення 2. Функція «SANITY_DUPE» обробляє цю логіку.
Перевірка працездатності: параметри для клітинок без значень
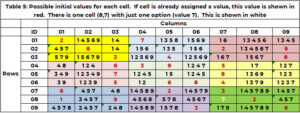
Дуже корисною інформацією були б усі можливі значення для клітинки без значення. Якщо кандидатів немає, то ця головоломка нерозв'язна. Комірка не може приймати значення, на яке вже претендує її сусід. Використовуючи таблицю 1 для комірки (1,3, '1' – цей останній 1 є boxid), її сусідами є рядок 1, стовпець 3 і поле 1. Рядок 1 має значення (2,7); колонка 3 має значення (3,5,6,7,9); поле 1 містить значення (2,3,8). Комірка (1,3.1) не може приймати такі значення (2,3,5,6,7,8,9). Єдиними варіантами для комірки (1,3,1) є (1,4). Для клітинки (4,1,2, 1, 2) значення 3, 5, 6, 7, 9, 4, 1 уже використовуються в рядку 4, стовпці 4,8 та/або полі XNUMX. Єдиними значеннями-кандидатами є (XNUMX) . Функція «SANITY_CAND» обробляє цю логіку.
Таблиця 5 показує кандидатів, наприклад, 1 на початку процесу пошуку. Якщо комірці вже було присвоєно значення у початкових умовах (табл. 1), то це значення повторюється та відображається червоним кольором. Якщо клітинка, для якої потрібно вказати значення, має лише один варіант, він буде позначено білим кольором. Комірка (8,7,9) має одне значення 7 білого кольору. (2,5,8,4,3) заявлено сусіднім стовпцем 7. (1, 2, 9) рядком 8. (3,2,6) вікном 9. Лише значення 7 є незатребуваним.
Перевірка осудності: пошук конфліктів
Інформація, яка визначає всі параметри для клітинок, які потребують значення (опублікована в таблиці 4), дає нам змогу виявити конфлікт перед початком процесу пошуку. Конфлікт виникає, коли дві клітинки, яким потрібно значення, мають лише одного кандидата, значення кандидата однакове, а дві клітинки є сусідами. З таблиці 4 ми знаємо, що єдина клітинка, яка потребує значення та має лише одного кандидата, це клітинка (8,7,9). Наприклад 1, конфлікту немає.
Який би був конфлікт? Якщо єдиним можливим значенням для комірки (3,7,3) було 7 (замість 1, 6, 7), то існує конфлікт. Комірки (8,7) і комірки (3,7) є сусідами – один стовпець. Однак, якби єдиним можливим значенням для комірки (4,9,2) було 7 (замість 1, 2, 7), це не було б конфліктом. Ці клітини не є сусідами.
Підсумок перевірки осудності
- Якщо є дублікати, вихідне рішення неможливе.
- Якщо клітинка, яка потребує значення, не має жодного кандидата, тоді неможливо вирішити цю головоломку. Список значень-кандидатів для кожної комірки можна використовувати, щоб зменшити простір пошуку – як для відстеження, так і для оптимізації.
- Здатність знаходити конфлікти визначає, що головоломка неможлива – не має рішення – без процесу пошуку. Крім того, він визначає «проблемні клітини».
Рішення зворотного відстеження: процес пошуку
Завдяки базовим структурам даних і перевірці правильності ми звертаємо увагу на процес пошуку. Повторювана тема знову полягає в створенні структур даних для підтримки пошуку.
Відстеження пошуку
Масив Tracker веде облік виконаних завдань
- Стовпець 1 – лічильник
- Стовпець 2 – це кількість опцій, які можна призначити цій клітинці
- 1 означає 1 доступний варіант, 2 означає два варіанти тощо.
- 0 означає відсутність доступної опції або скидання до 0 (немає присвоєного значення) і повернення назад
- Стовпець 3 – це клітинка, якій присвоєно номер індексу значення (від 1 до 81)
- Стовпець 4 – це значення, призначене клітинці в історії треків
- Значення 9999 означає, що в цій комірці було знайдено глухий кут
- Значення цілого числа від 1 до 9 включно є значенням, призначеним цій комірці на даному етапі процесу пошуку.
- Значення 0 означає, що ця клітинка потребує призначення
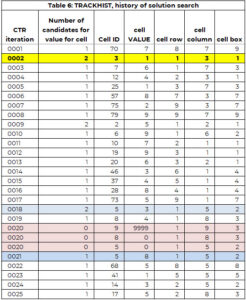
Масив трекера використовується для підтримки процесу пошуку. Масив TRACKHIST має таку ж структуру, що й трекер, але зберігає історію всього процесу пошуку. Таблиця 6 містить частину TRACKHIST для прикладу 1. Це пояснюється більш детально в наступному розділі.
Додатково масив PAV (вектор вектора), відстежує попередньо призначені значення цій клітинці. Це гарантує, що ми не переглянемо невдале рішення – подібно до того, що зроблено в TABU.
Існує додатковий процес журналу, де процес пошуку записує кожен крок.
Початок пошуку
Після завершення бухгалтерського обліку та перевірки здоров’я ми можемо почати процес пошуку. Кроки такі:
- Чи залишилися клітинки, які потребують значення? – якщо ні, то ми закінчили.
- Для кожної комірки, яка потребує значення, знайдіть усі можливі варіанти для кожної комірки. Таблиця 4 містить ці значення на початку процесу вирішення. На кожній ітерації це оновлюється, щоб відповідати значенням, призначеним клітинкам.
- Оцініть варіанти в такому порядку.
- Якщо комірка не має НУЛЬ параметрів, запустіть відстеження
- Знайдіть усі клітинки з одним варіантом, виберіть одну з цих клітинок, зробіть це призначення,
- і оновіть таблицю відстеження, поточне рішення та PAV.
- Якщо всі клітинки мають більше одного параметра, виберіть одну клітинку та одне значення та оновіть
- і оновіть таблицю відстеження, поточне рішення та PAV
Ми використаємо таблицю 6, яка є частиною історії процесу вирішення (називається TRACKHIST), щоб проілюструвати кожен крок.
Під час першої ітерації (CTR=1) клітинка 70 (рядок 8, стовпець 7, поле 9) вибирається для призначення значення. Є тільки кандидат (7), і це значення призначається клітинці 70. Крім того, значення 7 додається до вектора попередньо призначених значень (PAV) для клітинки 70.
У другій ітерації комірці 30 присвоюється значення 1. Ця комірка мала два потенційних значення. Найменше значення кандидата призначається комірці (лише довільне правило, щоб полегшити логіку).
Процес ідентифікації комірки, якій потрібне значення, і присвоєння значення працює нормально до ітерації (CTR) 20. Комірка 9 потребує значення, але кількість кандидатів дорівнює НУЛЬ. Є два варіанти:
- Немає розв'язку цієї головоломки.
- Ми скасовуємо (повертаємо назад) деякі призначення та переходимо іншим шляхом.
Ми шукали найближче до цього призначення комірки, де було більше ніж один варіант. У цьому прикладі це сталося на ітерації 18, де комірці 5 присвоєно значення 3, але було два потенційних значення для комірки 5 – значення 3 і 8.
Між коміркою 5 (CTR = 18) і коміркою 9 (CTR = 20) комірці 8 присвоєно значення 4 (CTR=19). Ми повертаємо клітинки 8 і 5 до списку «потрібне значення». Це фіксується в другому та третьому записах CTR=20, де значення встановлено на 0. Значення 3 зберігається у векторі PAV для клітинки 5. Тобто пошукова система не може призначити значення 3 клітинці 5.
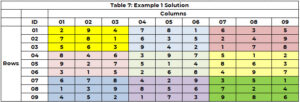
Пошукова система запускається знову, щоб визначити значення для комірки 5 (причому 3 більше не є опцією) і призначає значення 8 комірці 5 (CTR=21). Це продовжується, доки всі клітинки не матимуть значення або не знайдеться клітинка без опцій і немає зворотного шляху. Рішення розміщено в таблиці 7.
Зверніть увагу, якщо є більше одного кандидата на комірку, це шанс для паралельної обробки.
Порівняння з MILP Optimization Solution
На поверхневому рівні представлення головоломки Судоку різко відрізняється. Підхід штучного інтелекту використовує цілі числа і, за будь-якими показниками, є більш чітким та інтуїтивно зрозумілим представленням. Крім того, засоби перевірки розумності надають корисну інформацію, щоб зробити більш сильну формулу. Представництво MILP нескінченно двійкові файли (0/1). Однак двійкові файли є потужними представленнями, враховуючи силу сучасних розв’язувачів MILP.
Однак усередині розв’язувач MILP не зберігає двійкові файли, а використовує метод розрідженого масиву, щоб уникнути збереження всіх нулів. Крім того, алгоритми для розв’язання двійкових файлів з’являються лише у 1980-х і 1990-х роках. Стаття 1983 року Краудер, Джонсон і Падберг повідомляє про одне з перших практичних рішень оптимізації за допомогою двійкових файлів. Вони відзначають важливість розумної попередньої обробки та методів розгалуження та зв’язування як критичних для успішного рішення.
Нещодавній вибух використання програмування обмежень і програмного забезпечення, наприклад локальний розв'язувач чітко продемонстрував важливість використання методів ШІ з оригінальними методами оптимізації, такими як лінійне програмування та найменші квадрати.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- : має
- :є
- : ні
- :де
- $UP
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- здатність
- розмістити
- доданий
- доповнення
- Додатковий
- Додатково
- просунутий
- знову
- AI
- алгоритм
- алгоритми
- ВСІ
- дозволено
- вже
- Також
- завжди
- Amazon
- an
- та
- Інший
- будь-який
- з'являтися
- підхід
- довільний
- ЕСТЬ
- ПЛОЩА
- масив
- штучний
- штучний інтелект
- Штучний інтелект (AI)
- AS
- призначений
- припустити
- At
- увагу
- доступний
- назад
- BE
- було
- перед тим
- належність
- належить
- між
- порожній
- Блог
- рада
- обидва
- пов'язаний
- Box
- коробки
- Філія
- але
- by
- званий
- CAN
- кандидат
- кандидатів
- не може
- захоплений
- стелю
- Святкування
- осередок
- Клітини
- проблеми
- шанс
- перевірка
- контроль
- стверджував,
- ясно
- color
- Колонка
- Колони
- зазвичай
- Зроблено
- комплекс
- Умови
- конфлікт
- Конфлікти
- містить
- зміст
- триває
- Core
- наріжний камінь
- створений
- критичний
- Поточний
- дані
- день
- мертвий
- вирішувати
- description
- деталь
- докладно
- деталі
- певний
- різний
- цифр
- do
- робить
- домінуючий
- зроблений
- Не знаю
- різко
- дублікати
- кожен
- легко
- або
- елементи
- усунутий
- з'являтися
- дозволяє
- охоплює
- кінець
- Нескінченний
- двигун
- Двигуни
- гарантує
- Весь
- і т.д.
- приклад
- пояснені
- вибух
- не вдалося
- далеко
- реально
- заповнювати
- знайти
- знахідки
- кінець
- Перший
- фіксований
- увагу
- стежити
- після
- для
- формула
- рецептура
- знайдений
- від
- веселощі
- функція
- Функції
- отримання
- даний
- сітка
- було
- Ручки
- Мати
- Серце
- корисний
- історія
- Як
- How To
- Однак
- HTML
- HTTPS
- ID
- ідентифікує
- ідентифікувати
- ідентифікує
- if
- ілюструвати
- реалізовані
- значення
- in
- Включно
- індекс
- зазначений
- вказуючи
- індивідуальний
- інформація
- інформує
- всередині
- замість
- Інститут
- Інтелект
- внутрішньо
- інтуїтивний
- IT
- ітерація
- ЙОГО
- Джонсон
- JPG
- просто
- тримати
- збережений
- Знати
- мова
- останній
- пізніше
- Latin
- вивчення
- найменш
- залишити
- рівень
- лінійний
- список
- журнал
- логіка
- довше
- подивитися
- подивився
- шукати
- машина
- навчання за допомогою машини
- made
- зробити
- макс-ширина
- Може..
- засоби
- вимір
- метод
- методика
- сучасний
- більше
- National
- Необхідність
- потреби
- сусіди
- дев'ять
- немає
- увагу
- зараз
- номер
- мета
- спостерігати
- сталося
- of
- on
- один раз
- ONE
- тільки
- оптимізація
- варіант
- Опції
- or
- порядок
- оригінал
- наші
- з
- Папір
- Паралельні
- частина
- шлях
- ідеальний
- продуктивність
- частина
- місце
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- точка
- популярний
- це можливо
- розміщені
- потужний
- Практичний
- раніше
- Проблема
- процес
- обробка
- Програмування
- забезпечувати
- забезпечує
- put
- головоломка
- Пазли
- Лють
- діапазон
- останній
- повторювані
- червоний
- зменшити
- райони
- регресія
- навчання
- повторний
- Звіти
- подання
- ROW
- Правило
- то ж
- планування
- Пошук
- Пошукова система
- другий
- розділ
- Захищає
- побачити
- вибрати
- обраний
- комплект
- Форма
- показаний
- Шоу
- аналогічний
- один
- So
- Софтвер
- рішення
- Рішення
- ВИРІШИТИ
- деякі
- Source
- Простір
- площа
- квадрати
- старт
- Починаючи
- починається
- Крок
- заходи
- Як і раніше
- зберігати
- зберігати
- сила
- більш сильний
- структура
- структур
- успішний
- такі
- чудовий
- підтримка
- поверхню
- таблиця
- снасті
- Приймати
- ніж
- Що
- Команда
- Джерело
- тема
- потім
- Там.
- Ці
- вони
- третій
- це
- міцніше
- times
- до
- Усього:
- трек
- Відстеження
- намагатися
- ПЕРЕГЛЯД
- повороти
- Двічі
- два
- тип
- типово
- створеного
- невідомий
- до
- Оновити
- оновлений
- us
- використання
- використовуваний
- використовує
- використання
- значення
- Цінності
- змінна
- дуже
- було
- we
- були
- Що
- Що таке
- коли
- який
- білий
- широкий
- Широкий діапазон
- Вікіпедія
- волі
- з
- без
- працює
- б
- років
- жовтий
- зефірнет
- нуль