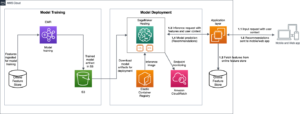
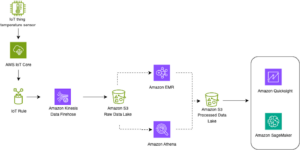
Forbearbeid og finjuster LLM-er raskt og kostnadseffektivt ved å bruke Amazon EMR Serverless og Amazon SageMaker | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 3093108Tidstempel: Februar 1, 2024
AWS Lake Formation 2023 år i gjennomgang | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 3070629Tidstempel: Jan 18, 2024
Håndhev finmasket tilgangskontroll på åpne tabellformater via Amazon EMR integrert med AWS Lake Formation | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 3068089Tidstempel: Jan 17, 2024
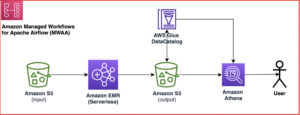
Orkestrere Amazon EMR Serverless Spark-jobber med Amazon MWAA, og datavalidering med Amazon Athena | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 3009324Tidstempel: Desember 12, 2023
Bruk Amazon EMR med S3 Access Grants for å skalere Spark-tilgang til Amazon S3 | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2979941Tidstempel: November 26, 2023
Bruk generativ AI med Amazon EMR, Amazon Bedrock og engelsk SDK for Apache Spark for å låse opp innsikt | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2980843Tidstempel: November 16, 2023
Introduserer Amazon MWAA-støtte for Apache Airflow versjon 2.7.2 og operatører som kan utsettes | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2968217Tidstempel: November 6, 2023
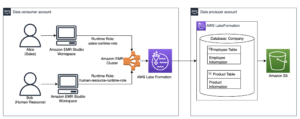
Bruk IAM-kjøretidsroller med Amazon EMR Studio Workspaces og AWS Lake Formation for finmasket tilgangskontroll på tvers av kontoer | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2968219Tidstempel: November 6, 2023
Spark på AWS Lambda: En Apache Spark-kjøretid for AWS Lambda | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2963284Tidstempel: Oktober 30, 2023
Hvordan Meesho bygde en generalisert feed ranker ved hjelp av Amazon SageMaker inference | Amazon Web Services Kildeklynge: AWS maskinlæring Kilde node: 2947465Tidstempel: Oktober 20, 2023
Kjør Apache Hive-arbeidsbelastninger ved å bruke Spark SQL med Amazon EMR på EKS | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2943231Tidstempel: Oktober 18, 2023
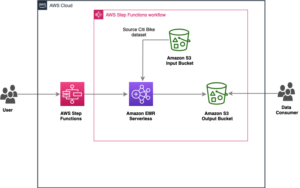
Orkestrere Amazon EMR Serverless-jobber med AWS Step-funksjoner | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2932457Tidstempel: Oktober 12, 2023
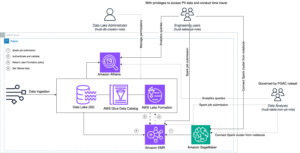
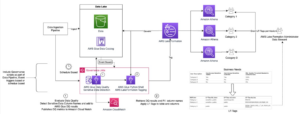
Automatisert datastyring med AWS Glue Data Quality, sensitiv datadeteksjon og AWS Lake Formation | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2934245Tidstempel: Oktober 10, 2023
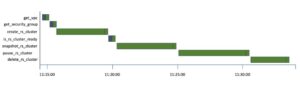
Definer ressursgrenser per team for big data-arbeidsbelastninger ved å bruke Amazon EMR Serverless | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2919310Tidstempel: Oktober 5, 2023
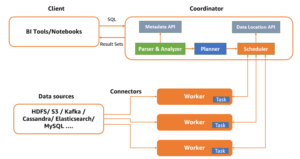
Forespør big data med robusthet ved å bruke Trino i Amazon EMR med Amazon EC2 Spot-forekomster for mindre kostnad | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2923593Tidstempel: Oktober 4, 2023
Apache Iceberg-optimalisering: Løser problemet med små filer i Amazon EMR | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2916743Tidstempel: Oktober 3, 2023
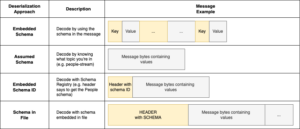
Ikke-JSON-inntak ved bruk av Amazon Kinesis Data Streams, Amazon MSK og Amazon Redshift Streaming | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2913873Tidstempel: Oktober 2, 2023
Introduserer hybrid tilgangsmodus for AWS Glue Data Catalog for å sikre tilgang ved hjelp av AWS Lake Formation og IAM og Amazon S3 policyer | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2903192Tidstempel: September 26, 2023
Kapasitetsstyring og Amazon EMR Managed Scaling forbedringer for Amazon EMR på EC2-klynger | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2869033Tidstempel: September 7, 2023
Spørr Isfjell-tabellene dine i datainnsjø med Amazon Redshift (forhåndsvisning) | Amazon Web Services Kildeklynge: AWS Big Data Kilde node: 2857736Tidstempel: August 31, 2023