Etter hvert som datateknologi blir stadig mer kompleks, leter organisasjoner etter nye måter å strømlinjeforme arbeidsflytene sine for databehandling. Mange dataingeniører bruker i dag Apache Airflow til å bygge, planlegge og overvåke datarørledningene deres.
Etter hvert som datavolumet vokser, kan det imidlertid bli en skremmende oppgave å administrere og skalere disse rørledningene. Amazon administrerte arbeidsflyter for Apache Airflow (Amazon MWAA) kan bidra til å forenkle prosessen med å bygge, kjøre og administrere datapipelines. Ved å tilby Apache Airflow som en fullt administrert plattform, lar Amazon MWAA dataingeniører fokusere på å bygge dataarbeidsflyter i stedet for å bekymre seg for infrastruktur.
I dag krever bedrifter og organisasjoner kostnadseffektive og effektive måter å behandle store datamengder på. Amazon EMR-serverløs er en kostnadseffektiv og skalerbar løsning for stordatabehandling som kan håndtere store datamengder. Amazon-leverandøren i Apache Airflow kommer med EMR-serverløse operatører og er allerede inkludert i Amazon MWAA, noe som gjør det enkelt for dataingeniører å bygge skalerbare og pålitelige databehandlingsrørledninger. Du kan bruke EMR Serverless til å kjøre Spark-jobber på dataene, og bruke Amazon MWAA til å administrere arbeidsflytene og avhengighetene mellom disse jobbene. Denne integrasjonen kan også bidra til å redusere kostnadene ved å automatisk skalere ressursene som trengs for å behandle data.
Amazon Athena er en serverløs, interaktiv analysetjeneste bygget på åpen kildekode-rammeverk, som støtter åpne tabeller og filformater. Du kan bruke standard SQL for å samhandle med data. Athena, en serverløs og interaktiv analysetjeneste, gjør dette mulig uten behov for å administrere kompleks infrastruktur.
I dette innlegget bruker vi Amazon MWAA, EMR Serverless og Athena for å bygge en komplett ende-til-ende databehandlingspipeline.
Løsningsoversikt
Følgende diagram illustrerer løsningsarkitekturen.
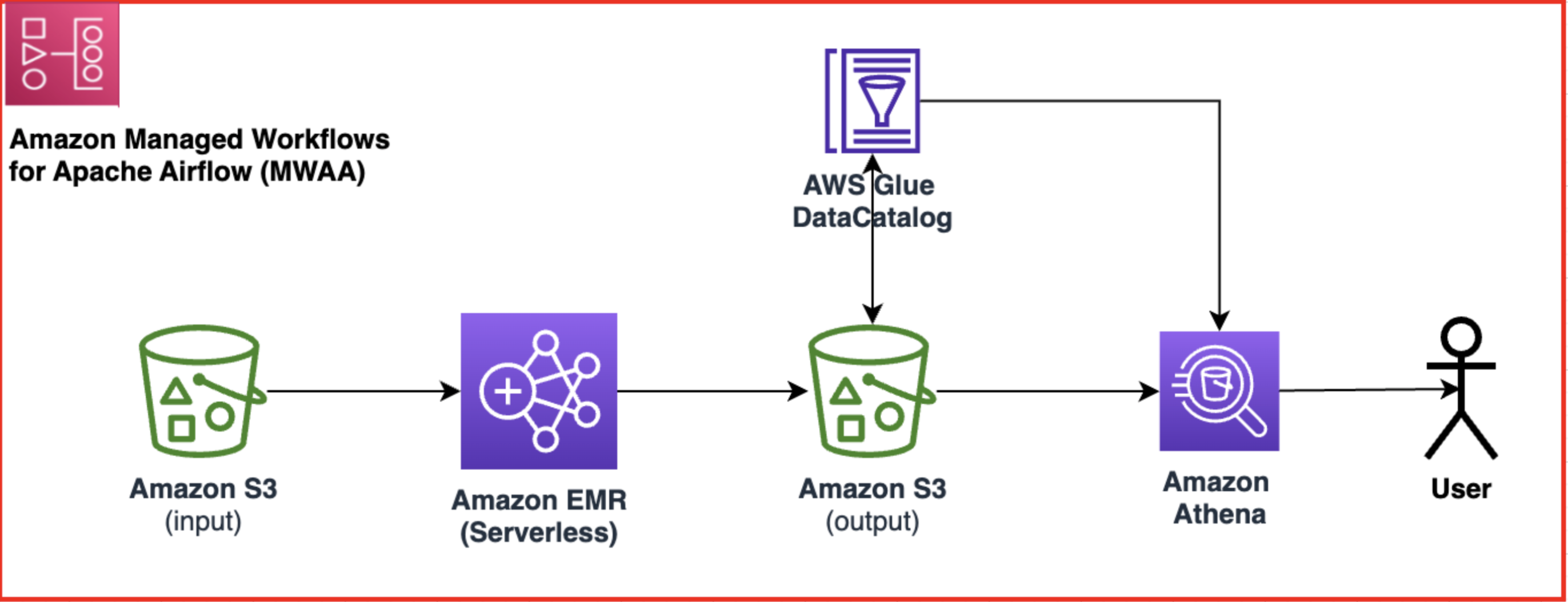
Arbeidsflyten inkluderer følgende trinn:
- Lag en Amazon MWAA-arbeidsflyt som henter data fra inndataene dine Amazon enkel lagringstjeneste (Amazon S3) bøtte.
- Bruk EMR Serverless til å behandle dataene som er lagret i Amazon S3. EMR Serverless skalerer automatisk opp eller ned basert på arbeidsmengden, så du trenger ikke å bekymre deg for å klargjøre eller administrere noen infrastruktur.
- Bruk EMR Serverless til å transformere dataene ved hjelp av PySpark-kode og lagre deretter de transformerte dataene tilbake i S3-bøtten din.
- Bruk Athena til å lage en ekstern tabell basert på S3-datasettet og kjøre spørringer for å analysere de transformerte dataene. Athena bruker AWS Lim Datakatalog for å lagre tabellens metadata.
Forutsetninger
Du bør ha følgende forutsetninger:
Dataforberedelse
For å illustrere bruken av EMR-serverløse jobber med Apache Spark via Amazon MWAA og datavalidering ved bruk av Athena, bruker vi det offentlig tilgjengelige NYC taxi-datasettet. Last ned følgende datasett til din lokale maskin:
- Grønn taxi og gul taxitur poster – Turposter for gule og grønne drosjer, som inkluderer informasjon som hente- og bringedatoer og klokkeslett, steder, reiseavstander og betalingstyper. I vårt eksempel bruker vi de nyeste Parquet-filene for 2022.
- Datasett for Taxi-soneoppslag – Et datasett som gir plasserings-IDer og tilsvarende sonedetaljer for drosjer.
I senere trinn laster vi opp disse datasettene til Amazon S3.
Opprett løsningsressurser
Denne delen skisserer trinnene for å sette opp databehandling og transformasjon.
Opprett en EMR-serverløs applikasjon
Du kan lage en eller flere EMR-serverløse applikasjoner som bruker åpen kildekode-analyserammeverk som Apache Spark eller Apache Hive. I motsetning til EMR på EC2, trenger du ikke å slette eller avslutte EMR Serverless-applikasjoner. EMR Serverless-applikasjon er bare en definisjon og når den er opprettet, kan den brukes på nytt så lenge det er nødvendig. Dette gjør MWAA-rørledningen enklere ettersom du nå bare må sende inn jobber til en forhåndsopprettet EMR Serverless-applikasjon.
Som standard, EMR Serverless-applikasjonen vil automatisk starte ved innsending av jobb og automatisk stoppe når den er inaktiv i 15 minutter som standard for å sikre kostnadseffektivitet. Du kan endre mengden av inaktiv tid eller velge å slå av funksjonen.
For å lage en applikasjon med EMR Serverless-konsoll, følg instruksjonene i "Opprett en EMR-serverløs applikasjon". Noter applikasjons-ID-en ettersom vi vil bruke den i følgende trinn.
![]()
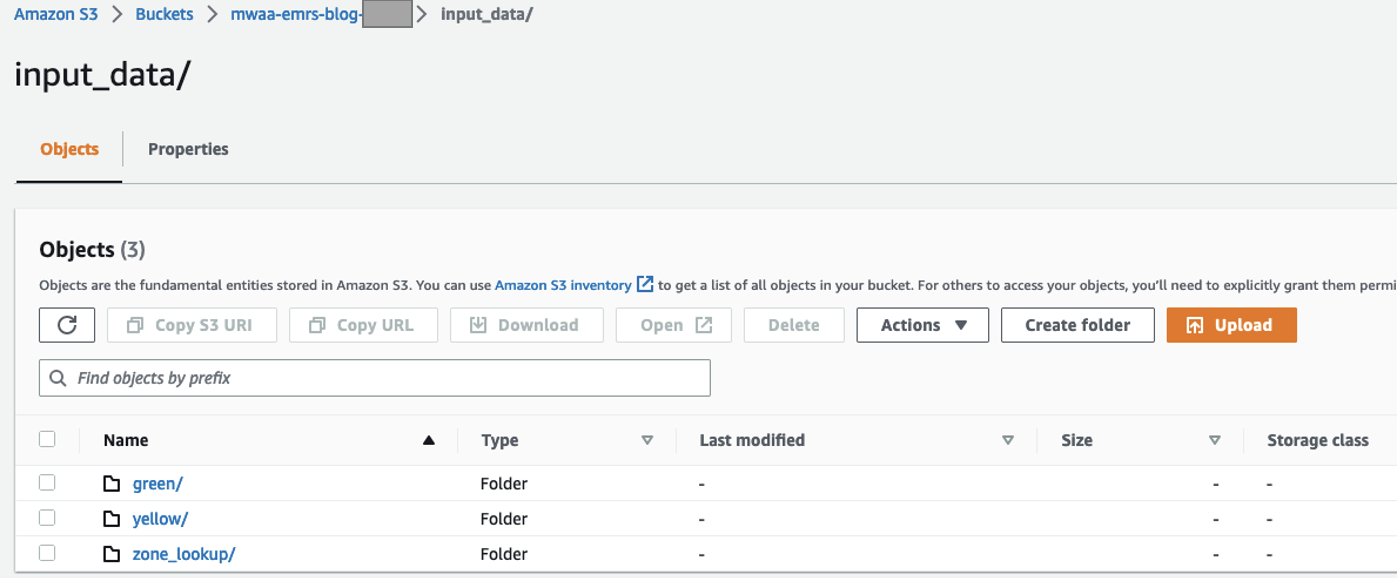
Lag en S3-bøtte og -mapper
Fullfør følgende trinn for å konfigurere S3-bøtten og mappene:
- På Amazon S3 -konsollen, lage en S3 bøtte for å lagre datasettet.
- Legg merke til navnet på S3-bøtten som skal brukes i senere trinn.
- Lag en
input_datamappe for lagring av inndata. - Opprett tre separate mapper i den mappen, én for hvert datasett:
green,yellowogzone_lookup.
Du kan laste ned og arbeide med de nyeste tilgjengelige datasettene. For vår testing bruker vi følgende filer:
- De
green/mappen har filengreen_tripdata_2022-06.parquet - De
yellow/mappen har filenyellow_tripdata_2022-06.parquet - De
zone_lookup/mappen har filentaxi_zone_lookup.csv
Sett opp Amazon MWAA DAG-skriptene
Fullfør følgende trinn for å konfigurere DAG-skriptene dine:
- Last ned følgende skript til din lokale maskin:
- krav.txt – En Python-avhengighet er enhver pakke eller distribusjon som ikke er inkludert i Apache Airflow-baseinstallasjonen for din Apache Airflow-versjon på ditt Amazon MWAA-miljø. For dette innlegget bruker vi Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Dette skriptet er en del av Amazon MWAA DAG og består av følgende oppgaver:
yellow_taxi_zone_lookup,green_taxi_zone_lookupogny_taxi_summary,. Disse oppgavene innebærer å kjøre Spark-jobber for å slå opp taxisoner og generere et datasammendrag . - green_zone.py – Dette PySpark-skriptet leser datafiler for grønne taxiturer og soneoppslag, utfører en sammenføyningsoperasjon for å kombinere dem, og genererer en utdatafil som inneholder grønne taxiturer med soneinformasjon. Den bruker midlertidige visninger for
df_greenogdf_zonedatarammer, utfører kolonnebaserte sammenføyninger og samler data som antall passasjerer, reisedistanse og prisbeløp. Til slutt skaper detoutput_datamappe i den angitte S3-bøtten for å skrive den resulterende datarammen,df_green_zone, som parkettfiler. - yellow_zone.py – Dette PySpark-skriptet behandler datafiler for gul taxitur og soneoppslag ved å slå dem sammen for å generere en utdatafil som inneholder gule taxiturer med soneinformasjon. Skriptet godtar et brukeroppgitt S3-bøttenavn og starter en Spark-økt med applikasjonsnavnet
yellow_zone. Den leser de gule taxifilene og soneoppslagsfilen fra den spesifiserte S3-bøtten, oppretter midlertidige visninger, utfører en sammenføyning basert på lokasjons-ID, og beregner statistikk som passasjertall, reiseavstand og prisbeløp. Til slutt skaper detoutput_datamappe i den angitte S3-bøtten for å skrive den resulterende datarammen,df_yellow_zone, som parkettfiler. - ny_taxi_summary.py – Dette PySpark-skriptet behandler
green_zoneogyellow_zonefiler for å samle statistikk om drosjeturer, gruppering av data etter tjenestesoner og steds-IDer. Det krever et S3-bøttenavn som et kommandolinjeargument, og oppretter en SparkSession med navnny_taxi_summary, leser filene fra S3, utfører en sammenføyning og genererer en ny dataramme med navnny_taxi_summary. Den oppretter en output_data-mappe i den angitte S3-bøtten for å skrive den resulterende datarammen til nye Parkett-filer.
- krav.txt – En Python-avhengighet er enhver pakke eller distribusjon som ikke er inkludert i Apache Airflow-baseinstallasjonen for din Apache Airflow-versjon på ditt Amazon MWAA-miljø. For dette innlegget bruker vi Boto3
- På din lokale maskin, oppdater
blog_dag_mwaa_emrs_ny_taxi.pyskript med følgende informasjon:- Oppdater S3-bøttenavnet på følgende to linjer:
- Oppdater rollenavnet ditt ARN:
- Oppdater EMR Serverless Application ID. Bruk applikasjons-IDen som ble opprettet tidligere.
- Last opp
requirements.txtfilen til S3-bøtten opprettet tidligere
- I S3-bøtten oppretter du en mappe med navnet
dagsog last opp den oppdaterteblog_dag_mwaa_emrs_ny_taxi.pyfil fra din lokale maskin.
- På Amazon S3-konsollen oppretter du en ny mappe med navnet
scriptsinne i S3-bøtten og last opp skriptene til denne mappen fra din lokale maskin.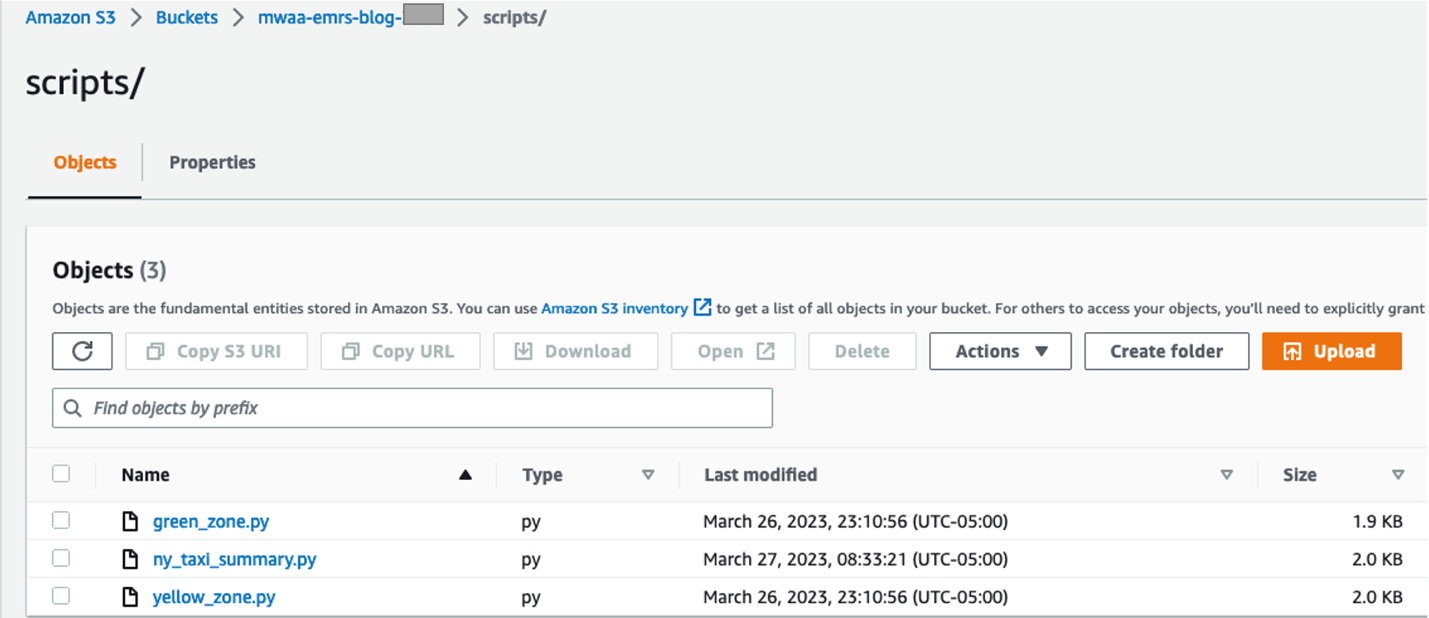
Lag et Amazon MWAA-miljø
For å opprette et Airflow-miljø, fullfør følgende trinn:
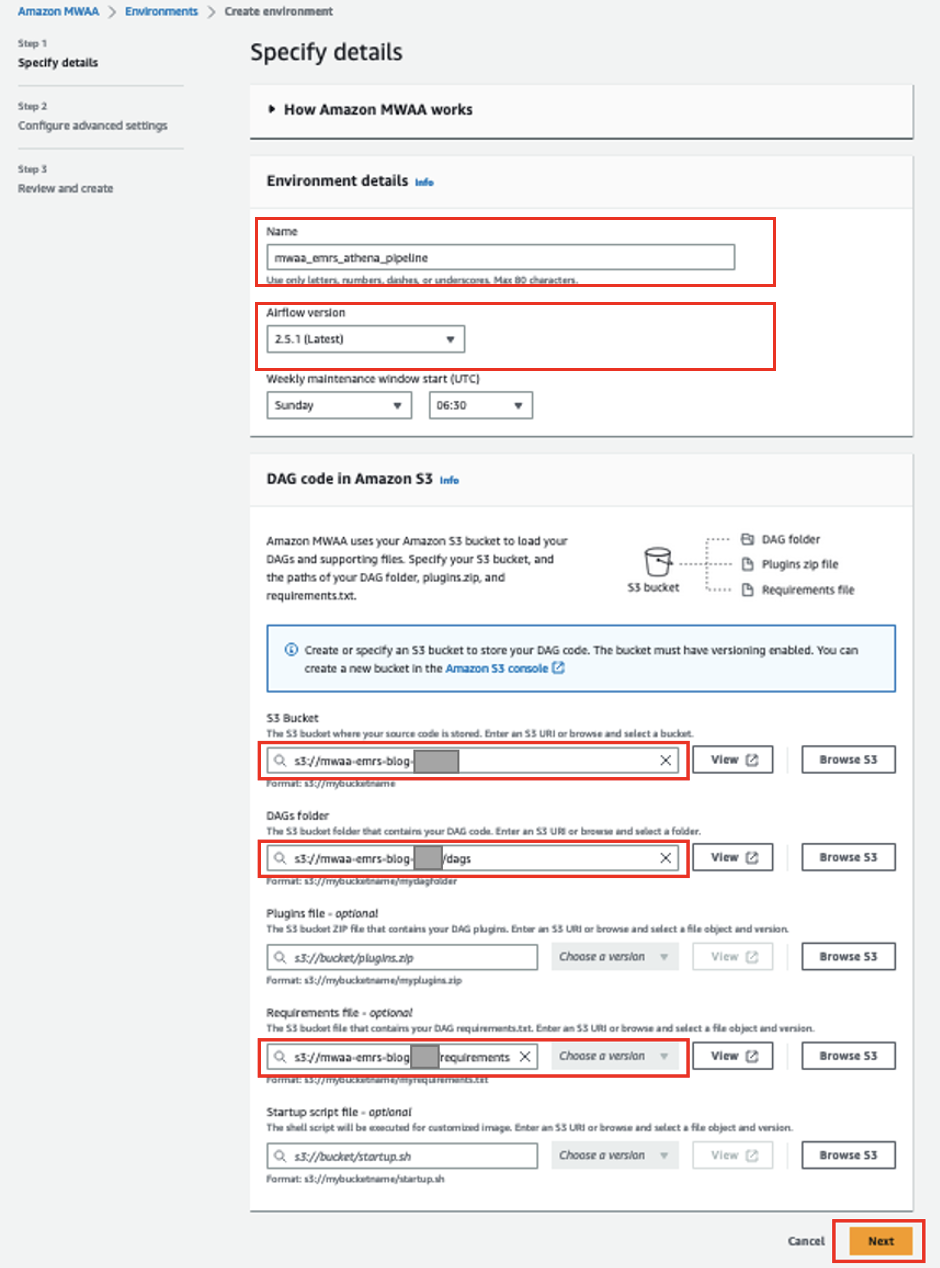
- Velg på Amazon MWAA-konsollen Skap miljø.

- Til Navn, Tast inn
mwaa_emrs_athena_pipeline. - Til Airflow-versjon, velg den nyeste versjonen (for dette innlegget, 2.5.1).
- Til S3 bøtte, skriv inn stien til S3-bøtten din.
- Til DAGs mappe, skriv inn stien til din
dagsmappe. - Til Krav fil, skriv inn stien til
requirements.txtfilen. - Velg neste.
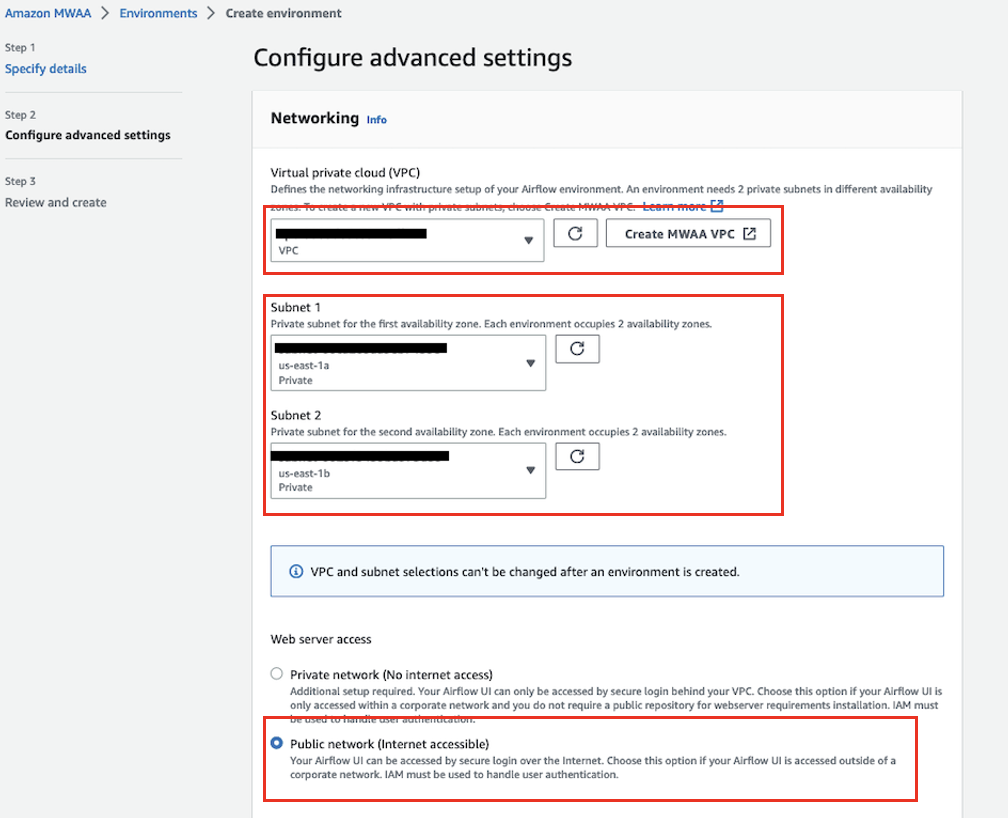
- Til Virtuell privat sky (VPC), velg en VPC som har minimum to private undernett.
Dette vil fylle ut to av de private undernettene i din VPC.
- Under Tilgang til webserver, plukke ut Offentlig nettverk.
Dette gjør det mulig å få tilgang til Apache Airflow UI over internett av brukere som har fått tilgang til IAM-policy for ditt miljø.
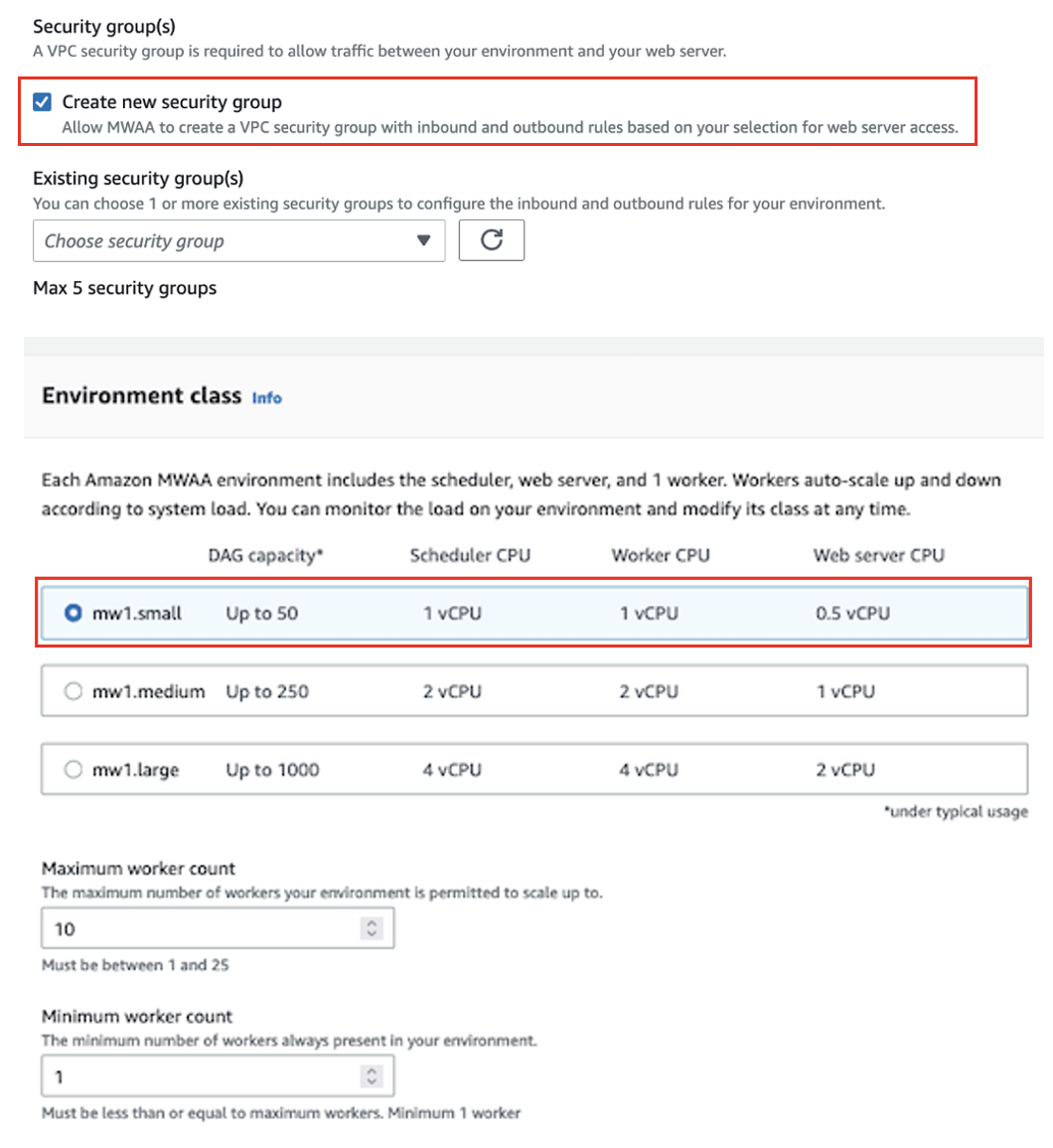
- Til Sikkerhetsgruppe(r), plukke ut Opprett ny sikkerhetsgruppe.
- Til Miljøklasse, plukke ut mw1.liten.
- Til Utførelsesrolle, velg Lag en ny rolle.
- Til Rollenavn, skriv inn et navn.
- La de andre konfigurasjonene være standard og velg neste.

- På neste side velger du Opprett miljø.
Det kan ta omtrent 20–30 minutter å lage ditt Amazon MWAA-miljø.
- Når Amazon MWAA miljøstatus endres til Tilgjengelig, naviger til IAM-konsollen og oppdater klyngeutførelsesrollen for å legge til bestå rolleprivilegier til
emr_serverless_execution_role.
Utløs Amazon MWAA DAG
For å utløse DAG, fullfør følgende trinn:
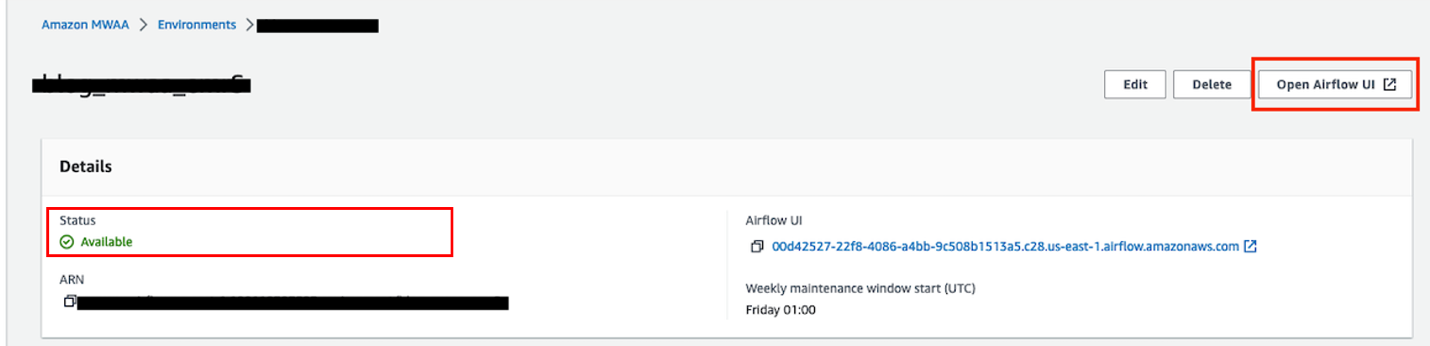
- Velg på Amazon MWAA-konsollen Miljøer i navigasjonsruten.
- Åpne miljøet ditt og velg Åpne Airflow UI.
- Plukke ut
blog_dag_mwaa_emr_ny_taxi, velg avspillingsikonet og velg Trigger DAG.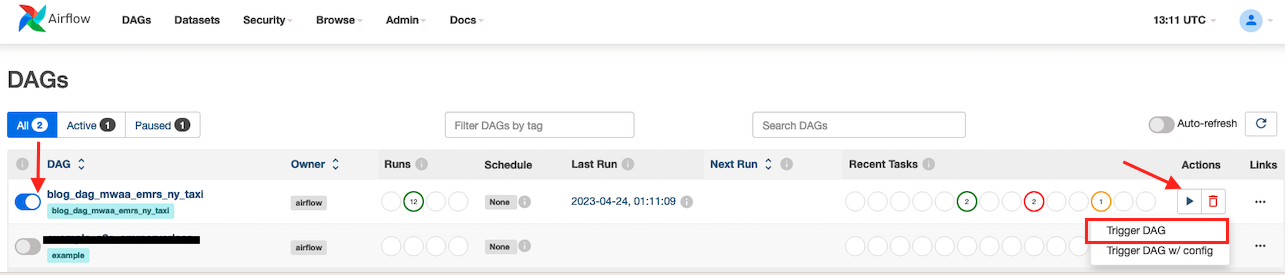
- Når DAG kjører, velg DAG
blog_dag_mwaa_emrs_ny_taxiOg velg Graph for å finne arbeidsflyten for DAG-kjøring.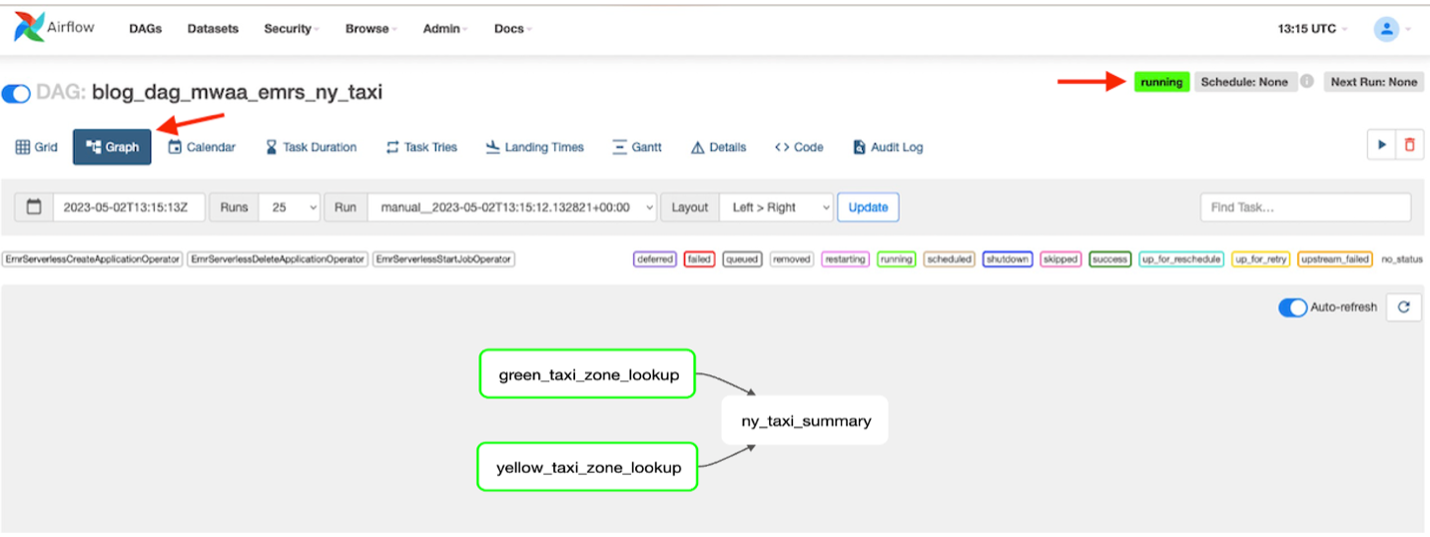
DAG vil bruke omtrent 4–6 minutter på å kjøre alle skriptene. Du vil se alle de komplette oppgavene og den generelle statusen til DAG vil vises som suksess.

For å kjøre DAG på nytt, fjern s3://<<your_s3_bucket here >>/output_data/.
For å forstå hvordan Amazon MWAA kjører disse oppgavene, velg eventuelt oppgaven du vil inspisere.

Velg Kjør for å se detaljer om oppgavekjøringen.
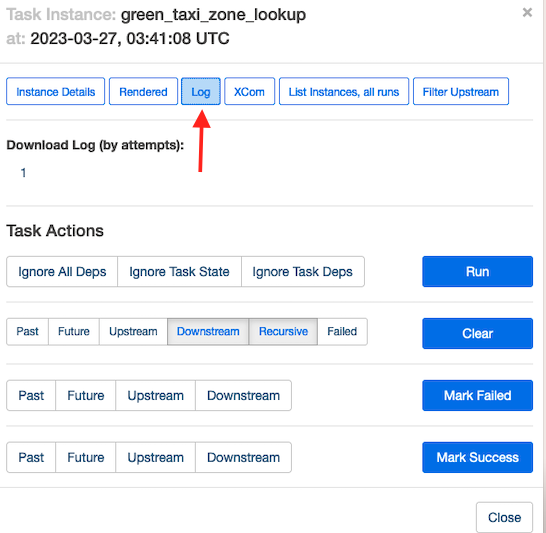
Følgende skjermbilde viser et eksempel på oppgaveloggene.
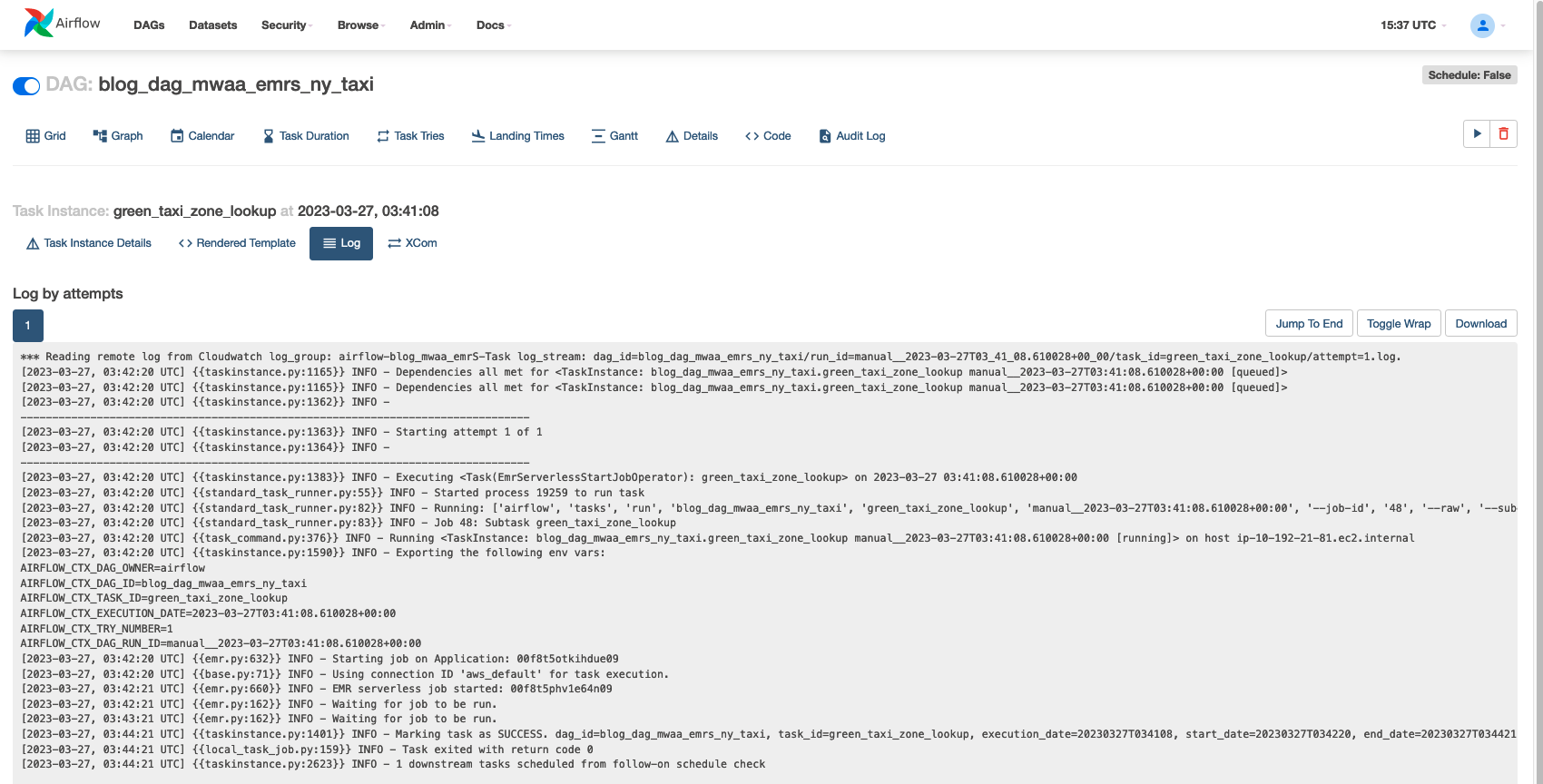
Hvis du liker å dykke dypt i utførelsesloggene, kan du gå til "Applications" på EMR Serverless-konsollen. Apache Spark-driverloggene vil indikere initieringen av jobben din sammen med detaljene for utførende, stadier og oppgaver som ble opprettet av EMR Serverless. Disse loggene kan være nyttige for å overvåke jobbfremgangen din og feilsøke feil.
Som standard vil EMR Serverless lagre applikasjonslogger sikkert i Amazon EMR-administrert lagring i en periode på 30 dager. Du kan imidlertid også spesifisere Amazon S3 eller Amazon CloudWatch som dine loggleveringsalternativer under jobbinnlevering.

Valider det endelige resultatsettet med Athena
La oss validere dataene som er lastet inn av prosessen ved å bruke Athena SQL-spørringer.
- Velg på Athena-konsollen Spørringsredaktør i navigasjonsruten.
- Hvis du bruker Athena for første gang, under innstillinger, velg Administrer og angi S3-bøtteplasseringen som du opprettet tidligere (
<S3_BUCKET_NAME>/athena), og velg deretter Spar.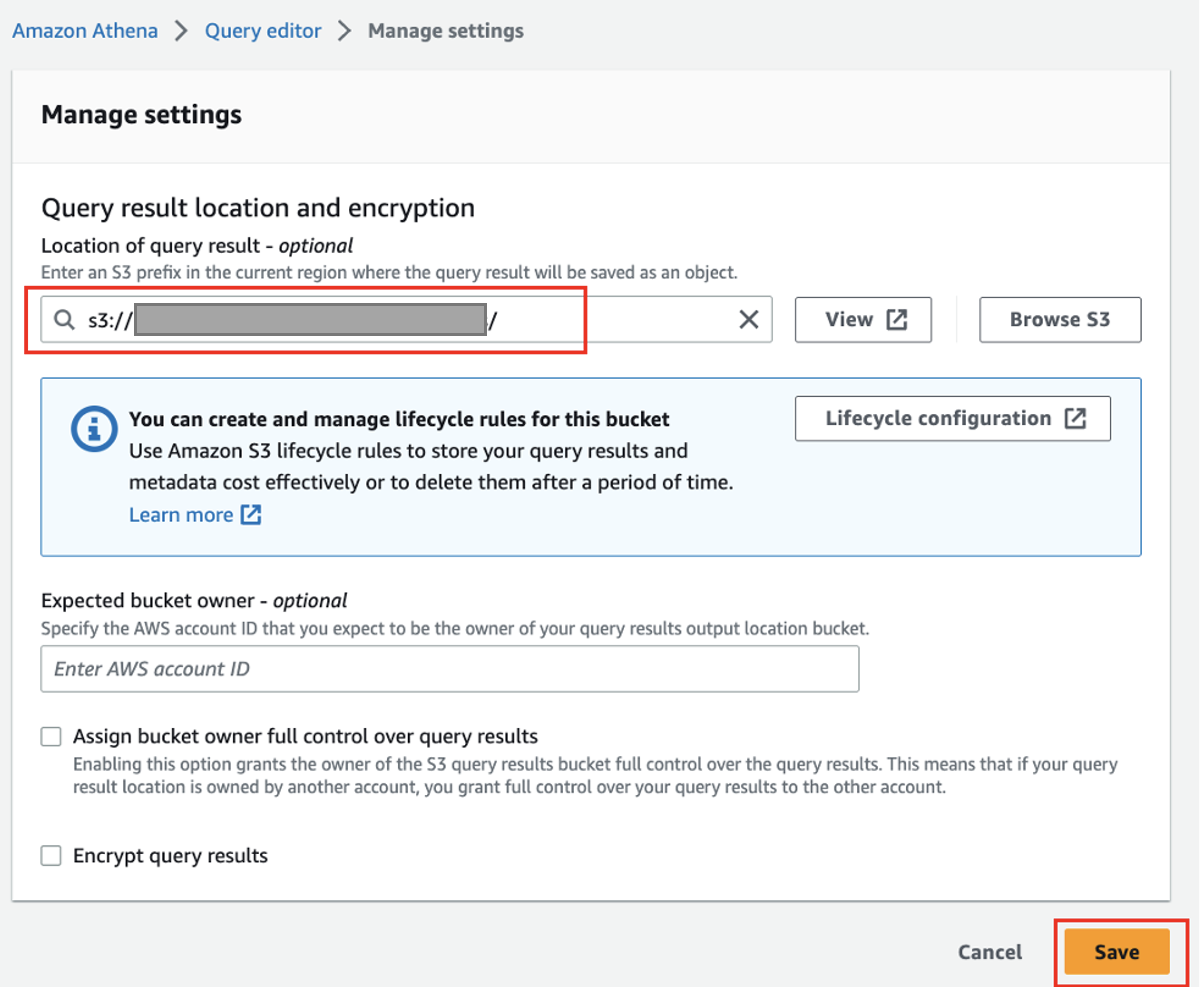
- I spørringsredigeringsprogrammet skriver du inn følgende spørring for å opprette en ekstern tabell:

Kjør følgende spørring på den nylig opprettede ny_taxi_summary tabell for å hente de første 10 radene for å validere dataene:

Rydd opp
For å forhindre fremtidige belastninger, fullfør følgende trinn:
- På Amazon S3-konsollen sletter du S3-bøtten du opprettet for å lagre Amazon MWAA DAG, skript og logger.
- På Athena-konsollen slipper du tabellen du opprettet:
- På Amazon MWAA-konsollen, naviger til miljøet du opprettet og velg Delete.

- Slett applikasjonen på EMR Studio-konsollen.
For å slette applikasjonen, naviger til Liste applikasjoner side. Velg programmet du opprettet og velg Handlinger → Stopp for å stoppe applikasjonen. Etter at applikasjonen er i STOPP-status, velger du den samme applikasjonen og velger Handlinger → Slett.

konklusjonen
Datateknikk er en kritisk komponent i mange organisasjoner, og ettersom datavolumene fortsetter å vokse, er det viktig å finne måter å strømlinjeforme databehandlingsarbeidsflytene på. Kombinasjonen av Amazon MWAA, EMR Serverless og Athena gir en kraftig løsning for å bygge, kjøre og administrere datapipelines effektivt. Med denne ende-til-ende databehandlingspipeline kan dataingeniører enkelt behandle og analysere store datamengder raskt og kostnadseffektivt uten behov for å administrere kompleks infrastruktur. Integreringen av disse AWS-tjenestene gir en robust og skalerbar løsning for databehandling, og hjelper organisasjoner med å ta informerte beslutninger basert på deres datainnsikt.
Nå som du har sett hvordan du sender inn Spark-jobber på EMR Serverless via Amazon MWAA, oppfordrer vi deg til å bruke Amazon MWAA for å lage en arbeidsflyt som kjører PySpark-jobber via EMR Serverless.
Vi tar gjerne imot tilbakemeldinger og forespørsler. Ta gjerne kontakt med oss hvis du har spørsmål eller kommentarer.
Om forfatterne
 Rahul Sonawane er en Principal Analytics Solutions Architect hos AWS med AI/ML og Analytics som sitt spesialområde.
Rahul Sonawane er en Principal Analytics Solutions Architect hos AWS med AI/ML og Analytics som sitt spesialområde.
 Gaurav Parekh er en løsningsarkitekt som hjelper AWS-kunder med å bygge moderne arkitektur i stor skala. Han har spesialisert seg på dataanalyse og nettverksbygging. Utenom jobben liker Gaurav å spille cricket, fotball og volleyball.
Gaurav Parekh er en løsningsarkitekt som hjelper AWS-kunder med å bygge moderne arkitektur i stor skala. Han har spesialisert seg på dataanalyse og nettverksbygging. Utenom jobben liker Gaurav å spille cricket, fotball og volleyball.
Revisjonshistorikk
Desember 2023: Dette innlegget ble gjennomgått for teknisk nøyaktighet av Santosh Gantaram, Sr. Technical Account Manager.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- : har
- :er
- :ikke
- $OPP
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- Om oss
- godtar
- adgang
- aksesseres
- Logg inn
- nøyaktighet
- legge til
- Etter
- aggregat
- AI / ML
- Alle
- tillater
- langs
- allerede
- også
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- beløp
- beløp
- an
- analytics
- analysere
- og
- noen
- Apache
- Apache Spark
- Søknad
- søknader
- ca
- arkitektur
- ER
- AREA
- argument
- AS
- At
- automatisk
- tilgjengelig
- AWS
- tilbake
- basen
- basert
- BE
- bli
- blir
- mellom
- Stor
- Store data
- bygge
- Bygning
- bygget
- bedrifter
- by
- beregner
- CAN
- katalog
- endring
- Endringer
- avgifter
- Velg
- klassifisering
- Cloud
- Cluster
- kode
- kombinasjon
- kombinere
- kommer
- kommentarer
- fullføre
- komplekse
- komponent
- består
- Konsoll
- fortsette
- Tilsvarende
- Kostnad
- kostnadseffektiv
- Kostnader
- skape
- opprettet
- skaper
- cricket
- kritisk
- Kunder
- DAG
- dato
- Data Analytics
- databehandling
- datasett
- datoer
- Dager
- avgjørelser
- dyp
- Misligholde
- definisjon
- levering
- avhengig
- Avhengighet
- detaljer
- avstand
- distribusjon
- dykk
- do
- ikke
- dobbelt
- ned
- nedlasting
- sjåfør
- Drop
- under
- e
- hver enkelt
- Tidligere
- lett
- lett
- redaktør
- effektivitet
- effektiv
- effektivt
- oppmuntre
- ende til ende
- Ingeniørarbeid
- Ingeniører
- sikre
- Enter
- Miljø
- avgjørende
- Eter (ETH)
- eksempel
- gjennomføring
- utvendig
- ekstra
- feil
- Trekk
- tilbakemelding
- føler
- filet
- Filer
- slutt~~POS=TRUNC
- Finn
- Først
- første gang
- Fokus
- følge
- etter
- Til
- format
- RAMME
- rammer
- Gratis
- fra
- fullt
- framtid
- generere
- genererer
- genererer
- innvilget
- Grønn
- Grow
- Vokser
- Hadoop
- håndtere
- Ha
- he
- hjelpe
- nyttig
- hjelpe
- her.
- hans
- Hive
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ids
- if
- illustrere
- illustrerer
- in
- inkludere
- inkludert
- inkluderer
- stadig
- indikerer
- informasjon
- informert
- Infrastruktur
- Starter
- initiering
- inngang
- forespørsler
- innsiden
- innsikt
- installere
- i stedet
- instruksjoner
- integrering
- samhandle
- interaktiv
- Internet
- involvere
- IT
- Jobb
- Jobb
- bli medlem
- sammenføyning
- tiltrer
- jpg
- bare
- stor
- til slutt
- seinere
- siste
- i likhet med
- BEGRENSE
- linje
- linjer
- lokal
- plassering
- steder
- logg
- Lang
- ser
- oppslag
- maskin
- gjøre
- GJØR AT
- Making
- administrer
- fikk til
- leder
- administrerende
- mange
- Kan..
- metadata
- minimum
- minutter
- Moderne
- modifisere
- Overvåke
- mer
- navn
- oppkalt
- Naviger
- Navigasjon
- Trenger
- nødvendig
- nettverk
- Ny
- neste
- none
- nå
- NYC
- of
- off
- on
- gang
- ONE
- bare
- åpen
- åpen kildekode
- drift
- operatører
- alternativer
- or
- organisasjoner
- Annen
- vår
- ut
- skisserer
- produksjon
- utenfor
- enn
- samlet
- pakke
- side
- brød
- del
- banen
- betaling
- utfører
- perioden
- rørledning
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- spiller
- vær så snill
- politikk
- mulig
- Post
- kraftig
- forutsetninger
- forebygge
- Principal
- privat
- prosess
- Prosesser
- prosessering
- Progress
- leverandør
- gir
- gi
- offentlig
- Python
- spørsmål
- spørsmål
- raskt
- å nå
- nylig
- poster
- redusere
- pålitelig
- fjerne
- krever
- Krever
- Ressurser
- resultere
- resulterende
- anmeldt
- Ride
- rides
- robust
- Rolle
- RAD
- Kjør
- rennende
- går
- s
- samme
- skalerbar
- Skala
- vekter
- skalering
- planlegge
- script
- skript
- Seksjon
- sikkert
- sikkerhet
- se
- sett
- velg
- separat
- server
- server~~POS=TRUNC
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- bør
- Vis
- Viser
- Enkelt
- forenkle
- So
- Fotball
- løsning
- Solutions
- kilde
- Spark
- spesialisert
- Spesialitet
- spesifisert
- SQL
- stadier
- Standard
- Tilstand
- statistikk
- status
- Steps
- Stopp
- stoppet
- lagring
- oppbevare
- lagret
- effektivisere
- String
- studio
- innsending
- send
- subnett
- slik
- SAMMENDRAG
- Støtte
- bord
- Ta
- Oppgave
- oppgaver
- Teknisk
- midlertidig
- Testing
- Det
- De
- deres
- Dem
- deretter
- Disse
- denne
- tre
- tid
- ganger
- til
- i dag
- Transform
- Transformation
- forvandlet
- utløse
- tur
- SVING
- to
- typer
- ui
- etter
- forstå
- I motsetning til
- Oppdater
- oppdatert
- us
- bruke
- Brukere
- bruker
- ved hjelp av
- bruker
- VALIDERE
- validering
- versjon
- av
- Se
- visninger
- volum
- volumer
- ønsker
- var
- måter
- we
- web
- webtjenester
- velkommen
- var
- når
- hvilken
- vil
- med
- uten
- Arbeid
- arbeidsflyt
- arbeidsflyt
- bekymring
- bekymringsfull
- skrive
- gul
- du
- Din
- zephyrnet
- soner