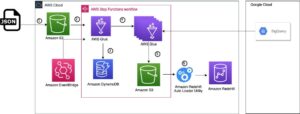
Amazon EMR har gleden av å kunngjøre integrasjon med Amazon Simple Storage Service (Amazon S3) Access Grants som forenkler Amazon S3-tillatelsesadministrasjon og lar deg håndheve granulær tilgang i stor skala. Med denne integrasjonen kan du skalere jobbbasert Amazon S3-tilgang for Apache Spark-jobber på tvers av alle Amazon EMR-distribusjonsalternativer og håndheve granulær Amazon S3-tilgang for bedre sikkerhetsstilling.
I dette innlegget vil vi gå gjennom noen forskjellige scenarier for hvordan du bruker Amazon S3 Access Grants. Før vi begynner å gå gjennom Amazon EMR- og Amazon S3 Access Grants-integrasjonen, setter vi opp og konfigurerer S3 Access Grants. Da bruker vi AWS skyformasjon mal nedenfor for å lage en Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) Cluster, en EMR Serverless-applikasjon og to forskjellige jobbroller.
Etter oppsettet kjører vi noen scenarier for hvordan du kan bruke Amazon EMR med S3 Access Grants. Først kjører vi en batch-jobb på EMR på Amazon EC2 for å importere CSV-data og konvertere til Parkett. For det andre bruker vi Amazon EMR Studio med en interaktiv EMR Serverless-applikasjon for å analysere dataene. Til slutt viser vi hvordan du konfigurerer tilgang på tvers av kontoer for Amazon S3 Access Grants. Mange kunder bruker forskjellige kontoer på tvers av organisasjonen og til og med utenfor organisasjonen for å dele data. Amazon S3 Access Grants gjør det enkelt å gi tilgang på tvers av kontoer til dataene dine selv når du filtrerer etter forskjellige prefikser.
I tillegg til dette innlegget kan du lære mer om Amazon S3 Access Grants fra Skalering av datatilgang med Amazon S3 Access Grants.
Forutsetninger
Før du starter AWS CloudFormation-stakken, sørg for at du har følgende:
- En AWS-konto som gir tilgang til AWS-tjenester
- Den siste versjonen av AWS Command Line Interface (AWS CLI)
- En AWS Identity and Access Management (AWS IAM) bruker med en tilgangsnøkkel og hemmelig nøkkel for å konfigurere AWS CLI, og tillatelser til å opprette en IAM-rolle, IAM-policyer og stabler i AWS CloudFormation
- En annen AWS-konto hvis du ønsker å teste funksjonaliteten på tvers av kontoer
walkthrough
Opprett ressurser med AWS CloudFormation
For å bruke Amazon S3 Access Grants, trenger du en klynge med Amazon EMR 6.15.0 eller nyere. For mer informasjon, se dokumentasjonen for bruk av Amazon S3 Access Grants med en Amazon EMR-klynge, En Amazon EMR på EKS-klyngen, Og en Amazon EMR Serverless-applikasjon. For formålet med dette innlegget antar vi at du har to forskjellige typer datatilgangsbrukere i organisasjonen din – analyseingeniører med lese- og skrivetilgang til dataene i boken og forretningsanalytikere med skrivebeskyttet tilgang. Vi vil bruke to forskjellige AWS IAM-roller, men du kan også koble din egen identitetsleverandør direkte til IAM Identity Center hvis du vil.
Her er arkitekturen for denne første delen. AWS CloudFormation-stakken oppretter følgende AWS-ressurser:
- En Virtual Private Cloud (VPC)-stabel med private og offentlige undernett til bruk med EMR Studio, rutetabeller og Network Address Translation (NAT) gateway.
- En Amazon S3-bøtte for EMR-artefakter som loggfiler, Spark-kode og Jupyter-notatbøker.
- En Amazon S3-bøtte med eksempeldata som kan brukes med S3 Access Grants.
- En Amazon EMR-klynge konfigurert for bruk kjøretidsroller og S3 Access Grants.
- En Amazon EMR Serverless-applikasjon konfigurert til å bruke S3 Access Grants.
- Et Amazon EMR Studio hvor brukere kan logge på og lage arbeidsområdenotatbøker med EMR Serverless-applikasjonen.
- To AWS IAM-roller vi skal bruke for EMR-jobbkjøringene våre: en for Amazon EC2 med skrivetilgang og en annen for serverløs med lesetilgang.
- Én AWS IAM-rolle som vil bli brukt av S3 Access Grants for å få tilgang til samlingsdata (dvs. rollen som skal brukes når du registrerer et sted med S3 Access Grants. S3 Access Grants bruker denne rollen til å opprette midlertidig legitimasjon).
Gjør følgende for å komme i gang:
- Velg Launch Stack:

- Godta standardinnstillingene og velg Jeg erkjenner at denne malen kan skape IAM-ressurser.
AWS CloudFormation-stakken tar omtrent 10–15 minutter å fullføre. Når stabelen er ferdig, går du til utganger-fanen der du finner nødvendig informasjon for følgende trinn.
Opprett Amazon S3 Access Grants-ressurser
Først skal vi opprette en Amazon S3 Access Grants-ressurser på kontoen vår. Vi oppretter en S3 Access Grants-forekomst, en S3 Access Grants-plassering som refererer til databøtten vår opprettet av AWS CloudFormation-stakken som bare er tilgjengelig for databøtten vår AWS IAM-rolle, og gir forskjellige tilgangsnivåer til leser- og skribentrollene våre.

For å opprette de nødvendige S3 Access Grants-ressursene, bruk følgende AWS CLI-kommandoer som en administrativ bruker og erstatte alle feltene mellom pilene med utdata fra CloudFormation-stakken.
Deretter oppretter vi et nytt S3 Access Grants-sted. Hva er en plassering? Amazon S3 Access Grants fungerer ved å selge AWS IAM-legitimasjon med tilgang til et bestemt S3-prefiks. En S3 Access Grants-lokasjon vil bli knyttet til en AWS IAM-rolle som disse midlertidige øktene vil bli opprettet fra.
I vårt tilfelle skal vi dekke AWS IAM-rollen til bøtten opprettet med AWS CloudFormation-stabelen vår og gi tilgang til databøtterollen opprettet av stabelen. Gå til utdata-fanen for å finne verdiene som skal erstattes med følgende kodebit:
Legg merke til AccessGrantsLocationId verdi i svaret. Vi trenger det for de neste trinnene der vi skal gå gjennom å lage de nødvendige S3 Access Grants for å begrense lese- og skrivetilgangen til bøtten din.
- For lese/skrive-brukeren, bruk
s3-control create-access-grantfor å gi READWRITE tilgang til prefikset "output/*": - For den leste brukeren, bruk
s3control create-access-grantigjen for kun å tillate READ-tilgang til samme prefiks:
Demo Scenario 1: Amazon EMR på EC2 Spark Job for å generere parkettdata
Nå som vi har konfigurert Amazon EMR-miljøene våre og gitt tilgang til rollene våre via S3 Access Grants, er det viktig å merke seg at de to AWS IAM-rollene for EMR-klyngen og EMR Serverless-applikasjonen vår har en IAM-policy som kun tillater tilgang til vår EMR-artefakterbøtte. De har ingen IAM-tilgang til S3-databøtten vår, og bruker i stedet S3 Access Grants for å hente kortvarige påloggingsopplysninger med scope til bøtte og prefiks. Spesielt er rollene gitt s3:GetDataAccess og s3:GetDataAccessGrantsInstanceForPrefix tillatelser til å be om tilgang via den spesifikke S3 Access Grants-forekomsten som er opprettet i vår region. Dette lar deg enkelt administrere S3-tilgangen på ett sted på en svært omfattende og detaljert måte som forbedrer sikkerheten din. Ved å kombinere S3 Access Grants med jobbroller på EMR på Amazon Elastic Kubernetes Service (Amazon EX) og EMR Serverless samt kjøretidsroller for Amazon EMR-trinn Fra og med EMR 6.7.0 kan du enkelt administrere tilgangskontroll for individuelle jobber eller forespørsler. S3 Access Grants er tilgjengelig på EMR 6.15.0 og senere. La oss først kjøre en Spark-jobb på EMR på EC2 som vår analyseingeniør for å konvertere noen prøvedata til Parkett.
For dette, bruk eksempelkoden gitt i converter.py. Last ned filen og kopier den til EMR_ARTIFACTS_BUCKET opprettet av AWS CloudFormation-stabelen. Vi sender inn jobben vår med ReadWrite AWS IAM-rollen. Merk at for EMR-klyngen konfigurerte vi S3 Access Grants til å falle tilbake til IAM-rollen hvis tilgang ikke er gitt av S3 Access Grants. De DATA_WRITER_ROLE har lesetilgang til EMR-artefakterbøtten gjennom en IAM-policy slik at den kan lese skriptet vårt. Som før, bytt ut alle verdiene med <> symboler fra Utganger fanen i CloudFormation-stakken.
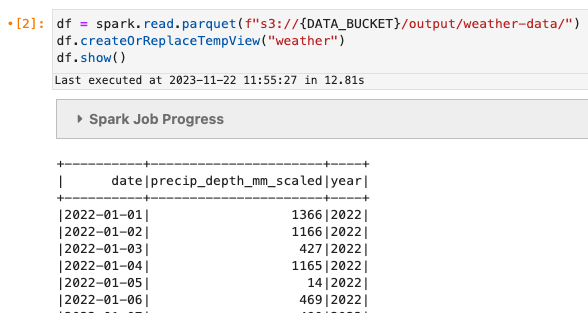
Når jobben er ferdig, bør vi se noen parkettdata s3://<DATA_BUCKET>/output/weather-data/. Du kan se status for jobben i Steps fanen av EMR-konsoll.
Demoscenario 2: EMR Studio med en interaktiv EMR-serverløs applikasjon for å analysere data
La oss nå gå videre og logge på EMR Studio og koble til EMR Serverless-applikasjonen din med ReadOnly-kjøretidsrollen for å analysere dataene fra scenario 1. Først må vi aktivere det interaktive endepunktet på Serverless-applikasjonen din.
- Velg EMRStudioURL i Utganger-fanen av AWS CloudFormation-stabelen din.
- Plukke ut applikasjoner under server~~POS=TRUNC seksjon på venstre side.

- Velg EMRBlog søknad, deretter Handling dropdown, og Configure.
- Utvid Interaktivt endepunkt delen og sørg for at Aktiver interaktivt endepunkt er sjekket.

- Rull ned og klikk Konfigurer programmet for å lagre endringene.
- Tilbake på Applikasjoner-siden, velg EMRBlog søknad, deretter Start applikasjonen knapp.
Deretter oppretter du et nytt arbeidsområde i studioet vårt.
- Velg arbeidsområder på venstre side, deretter Lag arbeidsområde knapp.
- Skriv inn et arbeidsområdenavn, la de gjenværende standardinnstillingene stå og velg Opprett arbeidsområde.
- Etter å ha opprettet arbeidsområdet, bør det starte i en ny fane om noen få sekunder.
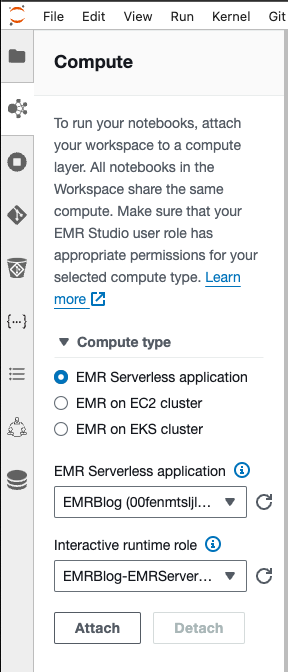
Koble nå Workspace til din EMR Serverless-applikasjon.
- Velg EMR Compute knappen på venstre side som vist i følgende kode.
- Velg EMR-serverløs som beregningstype.
- Velg EMRBlog applikasjonen og kjøretidsrollen som starter med EMRBlog.
- Velg Fest. Vinduet vil oppdateres og du kan åpne en ny PySpark notatbok og følg med nedenfor. For å utføre koden selv, last ned AccessGrantsReadOnly.ipynb notatbok og last det opp til arbeidsområdet ditt ved hjelp av Last opp filer knappen i filleseren.
La oss lese dataene raskt.
Vi gjør en enkel telling(*):

Du kan også se at hvis vi prøver å skrive data inn i utdatastedet, får vi en Amazon S3-feil.

Mens du også kan gi lignende tilgang via AWS IAM-policyer, kan Amazon S3 Access Grants være nyttig for situasjoner der organisasjonen din har vokst ut av å administrere tilgang via IAM, ønsker å kartlegge S3 Access Grants til IAM Identity Center-prinsipper eller roller, eller tidligere har brukt EMR Filsystem (EMRFS) rolletilordninger. S3 Access Grants-legitimasjon er også midlertidig og gir sikrere tilgang til dataene dine. I tillegg, som vist nedenfor, drar tilgang på tvers av kontoer også fordel av enkelheten til S3 Access Grants.
Demo Scenario 3 – Tilgang på tvers av kontoer
Et av de andre mer vanlige tilgangsmønstrene er tilgang til data på tvers av kontoer. Dette mønsteret har blitt stadig mer vanlig med fremveksten av datanettverk, der dataprodusenter og forbrukere er desentralisert på tvers av forskjellige AWS-kontoer.
Tidligere krevde tilgang på tvers av kontoer konfigurering av komplekse funksjoner på tvers av kontoer og leverandører av tilpasset legitimasjon når du konfigurerer Spark-jobben din. Med S3 Access Grants trenger vi bare å gjøre følgende:
- Opprett en Amazon EMR-jobbrolle og klynge i en andre dataforbrukerkonto
- Dataprodusentkontoen gir tilgang til dataforbrukerkontoen med en ny forekomstressurspolicy
- Dataprodusentkontoen oppretter en tilgangsbevilgning for jobbrollen dataforbruker
Og det er det! Hvis du har en annen konto tilgjengelig, fortsett og distribuer denne AWS CloudFormation-stakken i dataforbrukerkontoen for å opprette en ny EMR-serverløs applikasjon og jobbrolle. Hvis ikke, bare følg med nedenfor. AWS CloudFormation-stakken skal være ferdig opprettet på under ett minutt. Deretter, la oss gå videre og gi våre dataforbrukere tilgang til S3 Access Grants-forekomsten i vår dataprodusentkonto.
- Erstatt
<DATA_PRODUCER_ACCOUNT_ID>og<DATA_CONSUMER_ACCOUNT_ID>med de relevante 12-sifrede AWS-konto-ID-ene. - Du må kanskje også endre regionen i kommandoen og policyen.
- Og gi deretter READ-tilgang til utdatamappen til vår EMR Serverless-jobbrolle i dataforbrukerkontoen.
Nå som vi har gjort det, kan vi lese data i dataforbrukerkontoen fra bøtten i dataprodusentkontoen. Vi kjører bare en enkel COUNT(*) en gang til. Bytt ut <APPLICATION_ID>, <DATA_CONSUMER_JOB_ROLE>og <DATA_CONSUMER_LOG_BUCKET> med verdiene fra Utdata-fanen på AWS CloudFormation-stakken opprettet i den andre kontoen din.
Og erstatte <DATA_PRODUCER_BUCKET> med bøtte fra din første konto.
Vent til jobben når en fullført tilstand, og hent deretter standardloggen fra bøtten din, og erstatt <APPLICATION_ID>, <JOB_RUN_ID> fra jobben ovenfor, og <DATA_CONSUMER_LOG_BUCKET>.
Hvis du er på en unix-basert maskin og har pistol installert, så kan du bruke følgende kommando som din administrative bruker.
Merk at denne kommandoen bare bruker AWS IAM-rollepolitikk, ikke Amazon S3 Access Grants.
Ellers kan du bruke få-dashbord-for-job-run kommandoen og åpne den resulterende URL-adressen i nettleseren din for å se driverstdout-loggene i Utførere-fanen i Spark-grensesnittet.
Rydder opp
For å unngå å pådra seg fremtidige kostnader for eksempelressurser i AWS-kontoene dine, sørg for å utføre følgende trinn:
- Du må manuelt slette Amazon EMR Studio-arbeidsområdet opprettet i den første delen av innlegget
- Tøm Amazon S3-bøttene som er opprettet av AWS CloudFormation-stablene
- Sørg for at du sletter Amazon S3 Access Grants, ressurspolicyer og S3 Access Grants-plassering opprettet i trinnene ovenfor ved å bruke
delete-access-grant,delete-access-grants-instance-resource-policy,delete-access-grants-locationogdelete-access-grants-instancekommandoer. - Slett AWS CloudFormation-stablene som er opprettet i hver konto
Sammenligning med AWS IAM-rollekartlegging
I 2018 introduserte EMR EMRFS rollekartlegging som en måte å gi autorisasjon på lagringsnivå ved å konfigurere EMRFS med flere IAM-roller. Selv om den var effektiv, krevde rollekartlegging administrering av brukere eller grupper lokalt på EMR-klyngen din i tillegg til å opprettholde tilordningene mellom disse identitetene og deres tilsvarende IAM-roller. I kombinasjon med kjøretidsroller på EMR på EC2 og jobbroller for EMR på EKS og EMR-serverløs, er det nå enklere å gi tilgang til dine data på S3 direkte til den aktuelle rektor på per-jobb-basis.
konklusjonen
I dette innlegget viste vi deg hvordan du setter opp og bruker Amazon S3 Access Grants med Amazon EMR for enkelt å administrere datatilgang for Amazon EMR-arbeidsbelastningene dine. Med S3 Access Grants og EMR kan du enkelt konfigurere tilgang til data på S3 for IAM-identiteter eller bruke bedriftskatalogen i IAM Identity Center som identitetskilde. S3 Access Grants støttes på tvers av EMR på EC2, EMR på EKS og EMR Serverless fra og med EMR-versjon 6.15.0.
Å lære mer, se S3 Access Grants og EMR-dokumentasjon og still gjerne spørsmål i kommentarfeltet!
Om forfatteren
 Damon Cortesi er en ledende utvikleradvokat med Amazon Web Services. Han bygger verktøy og innhold for å gjøre livene til dataingeniører enklere. Når han ikke jobber hardt, bygger han fortsatt datapipelines og deler logger på fritiden.
Damon Cortesi er en ledende utvikleradvokat med Amazon Web Services. Han bygger verktøy og innhold for å gjøre livene til dataingeniører enklere. Når han ikke jobber hardt, bygger han fortsatt datapipelines og deler logger på fritiden.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/use-amazon-emr-with-s3-access-grants-to-scale-spark-access-to-amazon-s3/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 107
- 11
- 1232
- 15%
- 20
- 2018
- 500
- 7
- 8
- a
- Om oss
- ovenfor
- adgang
- tilgangsstyring
- Tilgang til data
- tilgjengelig
- Tilgang
- Logg inn
- kontoer
- anerkjenne
- tvers
- Handling
- handlinger
- tillegg
- adresse
- administrativ
- advokat
- en gang til
- fremover
- Alle
- tillate
- tillater
- langs
- også
- Amazon
- Amazon EC2
- Amazon Elastic Kubernetes-tjeneste
- Amazon EMR
- Amazon Web Services
- an
- analytikere
- analytics
- analysere
- og
- Kunngjøre
- En annen
- noen
- Apache
- Apache Spark
- Søknad
- søknader
- ca
- arkitektur
- ER
- AS
- spør
- assosiert
- anta
- At
- autorisasjon
- tilgjengelig
- unngå
- AWS
- AWS skyformasjon
- tilbake
- basis
- BE
- bli
- før du
- Begynnelsen
- under
- Fordeler
- Bedre
- mellom
- nett~~POS=TRUNC leseren~~POS=HEADCOMP
- bygger
- virksomhet
- men
- knapp
- by
- CAN
- saken
- sentrum
- endring
- Endringer
- sjekket
- Velg
- klikk
- kunde
- Cloud
- Cluster
- kode
- kombinasjon
- kombinere
- Felles
- fullføre
- Terminado
- komplekse
- Beregn
- konfigurert
- konfigurering
- Koble
- forbruker
- Forbrukere
- innhold
- fortsette
- kontroll
- konvertere
- Bedriftens
- Tilsvarende
- Kostnader
- skape
- opprettet
- skaper
- Opprette
- Credentials
- skikk
- Kunder
- dato
- data tilgang
- desentralisert
- Misligholde
- mislighold
- utplassere
- distribusjon
- Utvikler
- forskjellig
- direkte
- do
- dokumentasjon
- gjort
- ned
- nedlasting
- sjåfør
- e
- hver enkelt
- enklere
- lett
- lett
- effekt
- Effektiv
- veksten
- muliggjøre
- Endpoint
- håndheve
- ingeniør
- Ingeniører
- Forbedrer
- sikre
- miljøer
- feil
- Eter (ETH)
- Selv
- eksempler
- henrette
- Fall
- Mote
- føler
- Noen få
- Felt
- filet
- Filer
- filtrering
- Endelig
- Finn
- ferdig
- Først
- følge
- etter
- Til
- Gratis
- fra
- framtid
- gateway
- generere
- få
- Gi
- Go
- skal
- fikk
- innvilge
- innvilget
- tilskudd
- Gruppe
- Gruppens
- praktisk
- Hard
- Ha
- he
- hjelpe
- svært
- hans
- Hive
- Hvordan
- Hvordan
- HTML
- HTTPS
- i
- IAM
- ID
- identiteter
- Identitet
- styring av identitet og tilgang
- ids
- if
- importere
- viktig
- in
- stadig
- individuelt
- informasjon
- f.eks
- i stedet
- integrering
- interaktiv
- Interface
- inn
- introdusert
- IT
- Jobb
- Jobb
- jpg
- bare
- nøkkel
- Kubernetes
- seinere
- siste
- lansere
- LÆRE
- Permisjon
- nivåer
- i likhet med
- BEGRENSE
- linje
- Bor
- lokalt
- plassering
- logg
- Logg inn
- maskin
- opprettholde
- gjøre
- administrer
- ledelse
- administrerende
- manuelt
- mange
- kart
- kartlegging
- Kan..
- mesh
- minutt
- minutter
- mer
- flere
- må
- navn
- nødvendig
- Trenger
- nettverk
- Ny
- neste
- Nei.
- note
- bærbare
- notatbøker
- nå
- of
- on
- gang
- ONE
- bare
- åpen
- alternativer
- or
- rekkefølge
- organisasjon
- Annen
- vår
- produksjon
- utganger
- utenfor
- egen
- side
- del
- Spesielt
- Mønster
- mønstre
- tillatelse
- tillatelser
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- fornøyd
- Politikk
- politikk
- Post
- tidligere
- Principal
- rektorer
- privat
- produsent
- Produsentene
- gi
- forutsatt
- leverandør
- tilbydere
- gir
- gi
- offentlig
- formål
- spørsmål
- spørsmål
- Rask
- å nå
- Lese
- Reader
- refererer
- region
- registrering
- slipp
- relevant
- gjenværende
- erstatte
- anmode
- påkrevd
- ressurs
- Ressurser
- svar
- resulterende
- Rolle
- roller
- Rute
- Kjør
- går
- samme
- Spar
- Skala
- scenario
- scenarier
- omfang
- script
- Sekund
- sekunder
- Secret
- Seksjon
- sikre
- sikkerhet
- se
- velg
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sesjoner
- sett
- innstilling
- oppsett
- Del
- bør
- Vis
- viste
- vist
- side
- lignende
- Enkelt
- enkelhet
- forenkler
- situasjoner
- tekstutdrag
- So
- noen
- kilde
- Spark
- spesifikk
- spesielt
- spagaten
- SQL
- stable
- Stabler
- startet
- Start
- starter
- Tilstand
- Uttalelse
- status
- Steps
- Still
- lagring
- studio
- send
- subnett
- suksess
- Støttes
- sikker
- system
- Ta
- tar
- mal
- midlertidig
- test
- Det
- De
- deres
- deretter
- Disse
- de
- denne
- De
- Gjennom
- tid
- til
- verktøy
- Oversettelse
- prøve
- to
- typen
- typer
- ui
- etter
- URL
- bruke
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- bruke
- verdi
- Verdier
- versjon
- av
- Se
- virtuelle
- gå
- walking
- ønsker
- Vei..
- we
- Vær
- web
- webtjenester
- VI VIL
- Hva
- Hva er
- når
- hvilken
- mens
- vil
- vindu
- med
- Arbeid
- virker
- skrive
- forfatter
- yaml
- år
- du
- Din
- deg selv
- zephyrnet