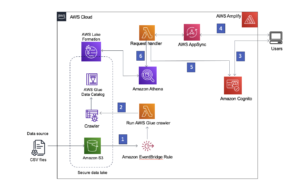
Amazon RedShift er et raskt, fullt administrert petabyte-skala skydatavarehus som gjør det enkelt og kostnadseffektivt å analysere alle dataene dine ved hjelp av standard SQL og dine eksisterende Business Intelligence (BI)-verktøy. Titusenvis av kunder bruker i dag Amazon Redshift til å analysere exabyte med data og kjøre analytiske spørringer, noe som gjør det til det mest brukte skydatavarehuset. Amazon Redshift er tilgjengelig i både serverløse og klargjorte konfigurasjoner.
Amazon Redshift lar deg få direkte tilgang til data som er lagret i Amazon enkel lagringstjeneste (Amazon S3) ved å bruke SQL-spørringer og slå sammen data på tvers av datavarehuset og datainnsjøen. Med Amazon Redshift kan du spørre etter dataene i S3-datasjøen ved hjelp av en sentral AWS Lim metastore fra ditt Redshift-datavarehus.
Amazon Redshift støtter spørring av en rekke dataformater, som CSV, JSON, Parquet og ORC, og tabellformater som Apache Hudi og Delta. Amazon Redshift støtter også spørring av nestede data med komplekse datatyper som struct, array og map.
Med denne muligheten utvider Amazon Redshift ditt datavarehus i petabyte-skala til en datainnsjø i exabyte-skala på Amazon S3 på en kostnadseffektiv måte.
Apache Iceberg er det nyeste tabellformatet som nå støttes i forhåndsvisning av Amazon Redshift. I dette innlegget viser vi deg hvordan du spørre Iceberg-tabeller ved hjelp av Amazon Redshift, og utforske Iceberg-støtte og alternativer.
Løsningsoversikt
Apache isfjell er et åpent tabellformat for svært store petabyte-skala analytiske datasett. Iceberg administrerer store samlinger av filer som tabeller, og den støtter moderne analytiske datainnsjøoperasjoner som innsetting, oppdatering, sletting og tidsreisespørringer på rekordnivå. Iceberg-spesifikasjonen tillater sømløs tabellutvikling som skjema- og partisjonsevolusjon, og designet er optimalisert for bruk på Amazon S3.
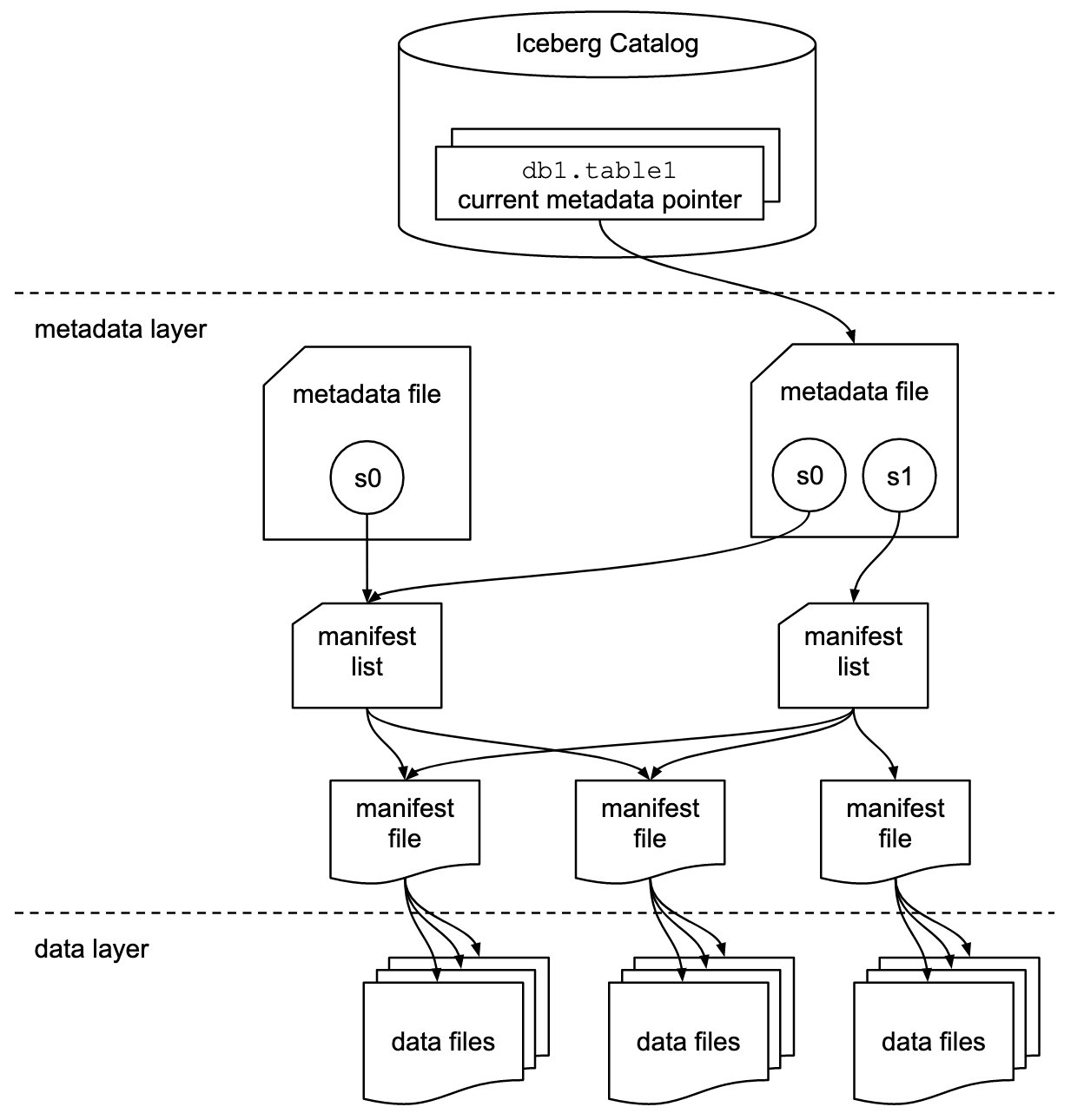
Iceberg lagrer metadatapekeren for alle metadatafilene. Når en SELECT-spørring leser en Iceberg-tabell, går spørringsmotoren først til Iceberg-katalogen, og henter deretter oppføringen av plasseringen til den siste metadatafilen, som vist i følgende diagram.
Amazon Redshift gir nå støtte for Apache Iceberg-tabeller, som lar datainnsjøkunder kjøre skrivebeskyttede analysespørringer på en transaksjonelt konsistent måte. Dette gjør at du enkelt kan administrere og vedlikeholde tabellene dine på transaksjonsdatainnsjøer.
Amazon Redshift støtter Apache Icebergs opprinnelige skjema og partisjonsutviklingsfunksjoner ved å bruke AWS Lim Data Catalog, eliminerer behovet for å endre tabelldefinisjoner for å legge til nye partisjoner eller for å flytte og behandle store datamengder for å endre skjemaet til en eksisterende datainnsjøtabell. Amazon Redshift bruker kolonnestatistikken som er lagret i Apache Iceberg-tabellens metadata for å optimalisere søkeplanene og redusere filskanningene som kreves for å kjøre spørringer.
I dette innlegget bruker vi Gul taxi offentlig datasett fra NYC Taxi & Limousine Commission som våre kildedata. Datasettet inneholder datafiler i Apache Parkett format på Amazon S3. Vi bruker Amazonas Athena for å konvertere dette parkettdatasettet og deretter bruke Amazon Redshift Spectrum for å spørre og bli med i en Redshift lokal tabell, utføre rad-nivå slettinger og oppdateringer og partisjonsutvikling, alt koordinert gjennom AWS Glue Data Catalog i en S3 datainnsjø.
Forutsetninger
Du bør ha følgende forutsetninger:
Konverter parkettdata til et isfjellbord
For dette innlegget trenger du Gul taxi offentlig datasett fra NYC Taxi & Limousine Commission tilgjengelig i isfjell-format. Du kan laste ned filene og deretter bruke Athena til å konvertere parkett-datasettet til et Iceberg-bord, eller referere til Bygg en Apache Iceberg-datainnsjø ved å bruke Amazon Athena, Amazon EMR og AWS Glue blogginnlegg for å lage Iceberg-bordet.
I dette innlegget bruker vi Athena til å konvertere dataene. Fullfør følgende trinn:
- Last ned filene ved å bruke den forrige lenken eller bruk AWS kommandolinjegrensesnitt (AWS CLI) for å kopiere filene fra den offentlige S3-bøtten for år 2020 og 2021 til S3-bøtten din ved å bruke følgende kommando:
For mer informasjon, se Sette opp Amazon Redshift CLI.
- Lag en database
Icebergdbog lag en tabell ved å bruke Athena og peker på filene i parkettformatet ved å bruke følgende setning: - Valider dataene i parketttabellen ved å bruke følgende SQL:

- Lag et isfjellbord i Athena med følgende kode. Du kan se tabelltypeegenskapene som et Iceberg-bord med parkettformat og rask komprimering i det følgende
create tableuttalelse. Du må oppdatere S3-plasseringen før du kjører SQL. Legg også merke til at Iceberg-bordet er partisjonert medYearnøkkel. - Etter at du har opprettet tabellen, laster du dataene inn i Iceberg-tabellen ved å bruke den tidligere lastede Parkett-tabellen
nyc_taxi_yellow_parquetmed følgende SQL: - Når SQL-setningen er fullført, valider dataene i Iceberg-tabellen
nyc_taxi_yellow_iceberg. Dette trinnet er nødvendig før du går til neste trinn. - Du kan validere at nyc_taxi_yellow_iceberg-tabellen er i Iceberg-formattabellen og partisjonert i År-kolonnen ved å bruke følgende kommando:



Lag et eksternt skjema i Amazon Redshift
I denne delen viser vi hvordan du lager et eksternt skjema i Amazon Redshift som peker til AWS Glue-databasen icebergdb for å spørre i Iceberg-tabellen nyc_taxi_yellow_iceberg som vi så i forrige avsnitt ved å bruke Athena.
Logg inn på Redshift via Query Editor v2 eller en SQL-klient og kjør følgende kommando (merk at AWS Glue-databasen icebergdb og regioninformasjon blir brukt):

For å lære om å lage eksterne skjemaer i Amazon Redshift, se lage eksternt skjema
Etter at du har opprettet det eksterne skjemaet spectrum_iceberg_schema, kan du spørre på Iceberg-tabellen i Amazon Redshift.
Spørr Iceberg-tabellen i Amazon Redshift
Kjør følgende spørring i Query Editor v2. Noter det spectrum_iceberg_schema er navnet på det eksterne skjemaet opprettet i Amazon Redshift og nyc_taxi_yellow_iceberg er tabellen i AWS Glue-databasen som brukes i spørringen:
Spørringsdataene i følgende skjermbilde viser at AWS Glue-tabellen med Iceberg-format kan søkes ved hjelp av Redshift Spectrum.

Sjekk forklaringsplanen for spørring i Iceberg-tabellen
Du kan bruke følgende spørring for å få forklaringsplanutdata, som viser formatet er ICEBERG:

Valider oppdateringer for datakonsistens
Etter at oppdateringen er fullført på Iceberg-tabellen, kan du spørre Amazon Redshift for å se den transaksjonelt konsistente visningen av dataene. La oss kjøre en spørring ved å velge en vendorid og for en viss henting og avlevering:

Deretter oppdaterer du verdien av passenger_count til 4 og trip_distance til 9.4 for en vendorid og visse hente- og avleveringsdatoer i Athena:

Til slutt, kjør følgende spørring i Query Editor v2 for å se den oppdaterte verdien av passenger_count og trip_distance:
Som vist i følgende skjermbilde, er oppdateringsoperasjonene på Iceberg-tabellen tilgjengelig i Amazon Redshift.

Lag en enhetlig visning av den lokale tabellen og historiske data i Amazon Redshift
Som en moderne dataarkitekturstrategi kan du organisere historiske data eller sjeldnere tilgang til data i datainnsjøen og beholde hyppig tilgang til data i Redshift-datavarehuset. Dette gir fleksibiliteten til å administrere analyser i stor skala og finne den mest kostnadseffektive arkitekturløsningen.
I dette eksemplet laster vi 2 år med data i en Redshift-tabell; resten av dataene forblir på S3-datainnsjøen fordi det søkes sjeldnere etter dette datasettet.
- Bruk følgende kode for å laste 2 år med data i
nyc_taxi_yellow_recentbord i Amazon Redshift, hentet fra Iceberg-bordet:
- Deretter kan du fjerne de siste 2 årene med data fra Iceberg-tabellen ved å bruke følgende kommando i Athena fordi du lastet dataene inn i en Redshift-tabell i forrige trinn:

Etter at du har fullført disse trinnene, har Redshift-tabellen 2 år med data og resten av dataene er i Iceberg-tabellen i Amazon S3.
- Lag en visning ved å bruke
nyc_taxi_yellow_icebergIsfjell bord ognyc_taxi_yellow_recenttabell i Amazon Redshift: - Spør nå i visningen, avhengig av filterforholdene, vil Redshift Spectrum skanne enten isfjelldataene, Redshift-tabellen eller begge deler. Følgende eksempelspørring returnerer et antall poster fra hver av kildetabellene ved å skanne begge tabellene:

Partisjonsutvikling
Isfjell bruker skjult partisjonering, som betyr at du ikke trenger å legge til partisjoner manuelt for Apache Iceberg-bordene dine. Nye partisjonsverdier eller nye partisjonsspesifikasjoner (legg til eller fjern partisjonskolonner) i Apache Iceberg-tabeller oppdages automatisk av Amazon Redshift og ingen manuell operasjon er nødvendig for å oppdatere partisjoner i tabelldefinisjonen. Følgende eksempel viser dette.
I vårt eksempel, hvis Iceberg-bordet nyc_taxi_yellow_iceberg ble opprinnelig oppdelt etter år og senere kolonnen vendorid ble lagt til som en ekstra partisjonskolonne, kan Amazon Redshift sømløst søke i Iceberg-tabellen nyc_taxi_yellow_iceberg med to forskjellige partisjonsordninger over en periode.

Betraktninger når du spør i Iceberg-tabeller med Amazon Redshift
I løpet av forhåndsvisningsperioden bør du vurdere følgende når du bruker Amazon Redshift med Iceberg-tabeller:
- Bare Iceberg-tabeller definert i AWS Glue Data Catalog støttes.
- CREATE eller ALTER eksterne tabellkommandoer støttes ikke, noe som betyr at Iceberg-tabellen allerede bør eksistere i en AWS Glue-database.
- Tidsreisespørringer støttes ikke.
- Iceberg versjon 1 og 2 støttes. For mer informasjon om Iceberg-formatversjoner, se Formatversjon.
- For en liste over støttede datatyper med Iceberg-tabeller, se Støttede datatyper med Apache Iceberg-tabeller (forhåndsvisning).
- Prissetting for å spørre etter en Iceberg-tabell er den samme som å få tilgang til andre dataformater ved å bruke Amazon Redshift.
For ytterligere detaljer om hensyn til forhåndsvisning av Iceberg-formattabeller, se Bruke Apache Iceberg-bord med Amazon Redshift (forhåndsvisning).
Kundefeedback
"Tinuiti, det største uavhengige ytelsesmarkedsføringsfirmaet, håndterer store datamengder på daglig basis og må ha en robust datainnsjø og datavarehusstrategi for at våre markedsintelligensteam skal lagre og analysere alle kundedataene våre på en enkel, rimelig og sikker måte. , og robust måte, sier Justin Manus, Chief Technology Officer hos Tinuiti. «Amazon Redshifts støtte for Apache Iceberg-tabeller i vår datainnsjø, som er den eneste kilden til sannhet, adresserer en kritisk utfordring med å optimalisere ytelse og tilgjengelighet og forenkler ytterligere dataintegrasjonspipelines for å få tilgang til alle dataene som er inntatt fra forskjellige kilder og for å drive vår kundenes merkevarepotensial."
konklusjonen
I dette innlegget viste vi deg et eksempel på å spørre en Iceberg-tabell i Redshift ved hjelp av filer lagret i Amazon S3, katalogisert som en tabell i AWS Glue Data Catalog, og demonstrerte noen av nøkkelfunksjonene som effektiv oppdatering og sletting på radnivå, og skjemautviklingsopplevelsen slik at brukere kan låse opp kraften til big data ved hjelp av Athena.
Du kan bruke Amazon Redshift til å kjøre spørringer på datainnsjøtabeller i forskjellige filer og tabellformater, som f.eks. Apache Hudi og Deltasjøen, og nå med Apache Iceberg (forhåndsvisning), som gir flere alternativer for dine moderne dataarkitekturbehov.
Vi håper dette gir deg et godt utgangspunkt for å spørre etter Iceberg-tabeller i Amazon Redshift.
Om forfatterne
 Rohit Bansal er en Analytics Specialist Solutions Architect hos AWS. Han spesialiserer seg på Amazon Redshift og jobber med kunder for å bygge neste generasjons analyseløsninger ved å bruke andre AWS Analytics-tjenester.
Rohit Bansal er en Analytics Specialist Solutions Architect hos AWS. Han spesialiserer seg på Amazon Redshift og jobber med kunder for å bygge neste generasjons analyseløsninger ved å bruke andre AWS Analytics-tjenester.
 Satish Sathiya er senior produktingeniør hos Amazon Redshift. Han er en ivrig big data-entusiast som samarbeider med kunder over hele verden for å oppnå suksess og møte deres behov for datavarehus og datainnsjøarkitektur.
Satish Sathiya er senior produktingeniør hos Amazon Redshift. Han er en ivrig big data-entusiast som samarbeider med kunder over hele verden for å oppnå suksess og møte deres behov for datavarehus og datainnsjøarkitektur.
 Ranjan Burman er en Analytics Specialist Solutions Architect hos AWS. Han spesialiserer seg på Amazon Redshift og hjelper kunder med å bygge skalerbare analytiske løsninger. Han har mer enn 16 års erfaring innen forskjellige database- og datavarehusteknologier. Han brenner for å automatisere og løse kundeproblemer med skyløsninger.
Ranjan Burman er en Analytics Specialist Solutions Architect hos AWS. Han spesialiserer seg på Amazon Redshift og hjelper kunder med å bygge skalerbare analytiske løsninger. Han har mer enn 16 års erfaring innen forskjellige database- og datavarehusteknologier. Han brenner for å automatisere og løse kundeproblemer med skyløsninger.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- ChartPrime. Hev handelsspillet ditt med ChartPrime. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Om oss
- adgang
- aksesseres
- tilgjengelighet
- Tilgang
- Oppnå
- tvers
- legge til
- la til
- Ytterligere
- adresser
- rimelig
- Alle
- tillater
- allerede
- også
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- beløp
- an
- analytisk
- Analytisk
- analytics
- analysere
- og
- noen
- Apache
- arkitektur
- ER
- rundt
- Array
- AS
- At
- automatisk
- Automatisere
- tilgjengelig
- AWS
- AWS Lim
- basis
- fordi
- før du
- være
- Stor
- Store data
- bindende
- Blogg
- både
- merke
- bygge
- virksomhet
- business intelligence
- by
- CAN
- evner
- evne
- katalog
- sentral
- viss
- utfordre
- endring
- sjef
- Chief Technology Officer
- kunde
- Cloud
- kode
- samlinger
- Kolonne
- kolonner
- fullføre
- komplekse
- forhold
- Vurder
- betraktninger
- konsistent
- inneholder
- konvertere
- koordinert
- kostnadseffektiv
- skape
- opprettet
- Opprette
- kritisk
- kunde
- kunde Data
- Kunder
- daglig
- dato
- dataintegrasjon
- Data Lake
- datalager
- Database
- datasett
- datoer
- Misligholde
- definert
- definisjon
- definisjoner
- Delta
- demonstrere
- demonstrert
- demonstrerer
- avhengig
- utforming
- detaljer
- oppdaget
- dev
- forskjellig
- direkte
- ikke
- dobbelt
- nedlasting
- hver enkelt
- lett
- lett
- redaktør
- effektiv
- enten
- eliminere
- muliggjør
- Motor
- ingeniør
- entusiast
- entry
- Eter (ETH)
- evolusjon
- eksempel
- eksisterer
- eksisterende
- erfaring
- Forklar
- utforske
- strekker
- utvendig
- ekstra
- FAST
- Egenskaper
- filet
- Filer
- filtrere
- Finn
- Firm
- Først
- fleksibilitet
- etter
- Til
- format
- ofte
- fra
- fullt
- videre
- få
- gir
- globus
- Går
- flott
- Gruppe
- Håndterer
- Ha
- he
- hjelper
- historisk
- håp
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- if
- in
- uavhengig
- informasjon
- integrering
- Intelligens
- inn
- IT
- DET ER
- bli medlem
- jpg
- JSON
- Justin
- Hold
- nøkkel
- innsjø
- stor
- største
- Siste
- seinere
- siste
- LÆRE
- mindre
- i likhet med
- BEGRENSE
- linje
- LINK
- Liste
- laste
- lokal
- plassering
- vedlikeholde
- GJØR AT
- Making
- administrer
- fikk til
- forvalter
- måte
- håndbok
- manuelt
- kart
- marked
- Marketing
- midler
- Møt
- metadata
- Moderne
- mer
- mest
- flytte
- flytting
- må
- navn
- innfødt
- Trenger
- nødvendig
- behov
- Ny
- neste
- neste generasjon
- Nei.
- note
- nå
- Antall
- NYC
- of
- Offiser
- on
- åpen
- drift
- Drift
- Optimalisere
- optimalisert
- optimalisere
- alternativer
- or
- opprinnelig
- Annen
- vår
- produksjon
- enn
- side
- lidenskapelig
- utføre
- ytelse
- perioden
- fly
- planer
- plato
- Platon Data Intelligence
- PlatonData
- Point
- Post
- potensiell
- makt
- forutsetninger
- Forhåndsvisning
- forrige
- tidligere
- problemer
- prosess
- Produkt
- egenskaper
- gir
- offentlig
- spørsmål
- Lesning
- poster
- redusere
- region
- fjerne
- erstatte
- påkrevd
- REST
- avkastning
- robust
- Kjør
- rennende
- samme
- så
- sier
- skalerbar
- Skala
- skanne
- skanning
- skanner
- ordninger
- sømløs
- sømløst
- Seksjon
- sikre
- se
- senior
- server~~POS=TRUNC
- Tjenester
- sett
- bør
- Vis
- viste
- vist
- Viser
- Enkelt
- enkelt
- løsning
- Solutions
- løse
- noen
- kilde
- Kilder
- Sourcing
- spesialist
- spesialisert
- spesifikasjon
- specs
- Spectrum
- SQL
- Standard
- Start
- Uttalelse
- statistikk
- Trinn
- Steps
- lagring
- oppbevare
- lagret
- butikker
- Strategi
- String
- suksess
- slik
- støtte
- Støttes
- Støtter
- bord
- lag
- Technologies
- Teknologi
- titus
- enn
- Det
- De
- Kilden
- deres
- deretter
- Disse
- denne
- tusener
- Gjennom
- tid
- tidsreiser
- tidsstempel
- til
- i dag
- verktøy
- transaksjonell
- reiser
- Sannhet
- to
- typen
- typer
- enhetlig
- union
- låse opp
- Oppdater
- oppdatert
- oppdateringer
- bruk
- bruke
- brukt
- Brukere
- bruker
- ved hjelp av
- VALIDERE
- verdi
- Verdier
- variasjon
- ulike
- veldig
- av
- Se
- volumer
- Warehouse
- lager
- var
- Vei..
- we
- web
- webtjenester
- når
- hvilken
- HVEM
- bred
- allment
- vil
- med
- virker
- år
- år
- du
- Din
- zephyrnet