For å forbedre effektiviteten til en Spark-applikasjon er det viktig å overvåke ytelsen og oppførselen. I dette innlegget viser vi hvordan du publiserer detaljerte Spark-beregninger fra Amazon EMR til Amazon CloudWatch. Dette vil gi deg muligheten til å identifisere flaskehalser samtidig som du optimaliserer ressursutnyttelsen.
CloudWatch gir en robust, skalerbar og kostnadseffektiv overvåkingsløsning for AWS-ressurser og -applikasjoner, med kraftige tilpasningsmuligheter og sømløs integrasjon med andre AWS-tjenester. Som standard sender Amazon EMR grunnleggende beregninger til CloudWatch for å spore aktiviteten og helsen til en klynge. Sparks konfigurerbare metrikksystem lar metrikk samles i en rekke vasker, inkludert HTTP-, JMX- og CSV-filer, men ytterligere konfigurasjon er nødvendig for å gjøre det mulig for Spark å publisere beregninger til CloudWatch.
Løsningsoversikt
Denne løsningen inkluderer Spark-konfigurasjon for å sende beregninger til en tilpasset vask. Den tilpassede vasken samler bare metrikkene som er definert i en Metricfilter.json-fil. Den bruker CloudWatch-agenten til å publisere beregningene til et tilpasset Cloudwatch-navneområde. Bootstrap-handlingsskriptet som følger med er ansvarlig for å installere og konfigurere CloudWatch-agenten og metrisk bibliotek på Amazon Elastic Compute Cloud (Amazon EC2) EMR-forekomster. Et CloudWatch-dashbord kan gi umiddelbar innsikt i ytelsen til en applikasjon.
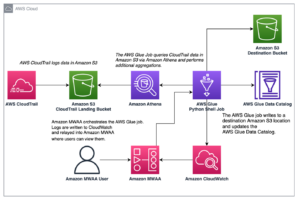
Følgende diagram illustrerer løsningsarkitekturen og arbeidsflyten.
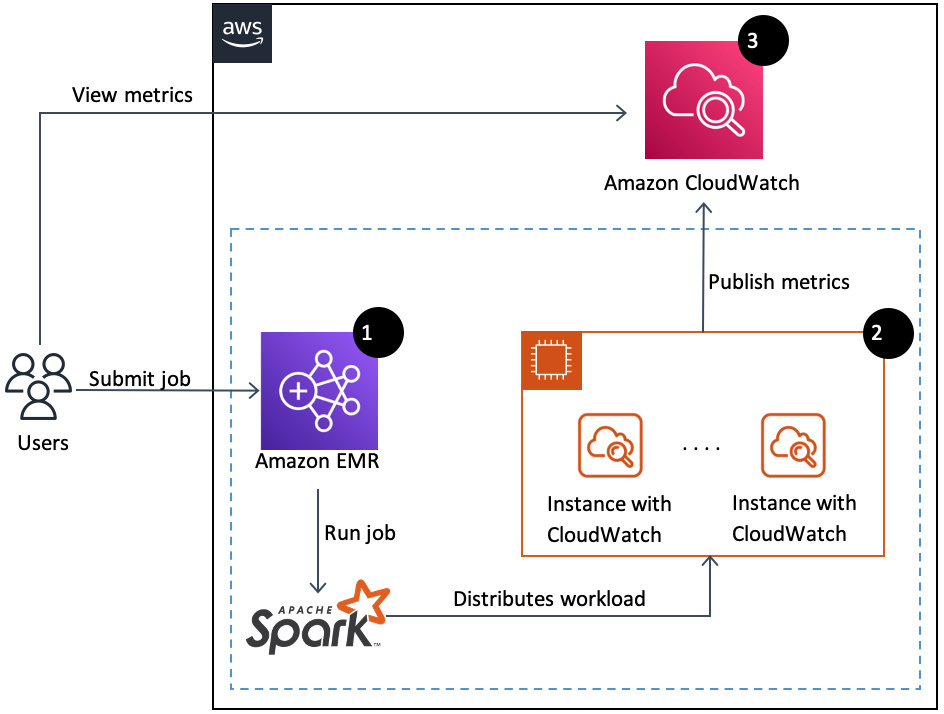
Arbeidsflyten inkluderer følgende trinn:
- Brukere starter en Spark EMR-jobb og oppretter et trinn på EMR-klyngen. Med Apache Spark er arbeidsbelastningen fordelt på de forskjellige nodene i EMR-klyngen.
- I hver node (EC2-forekomst) av klyngen, fanger et Spark-bibliotek opp og sender metriske data til en CloudWatch-agent, som samler metriske data før de skyver dem til CloudWatch hvert 30 sekund.
- Brukere kan se beregningene for tilgang til det tilpassede navneområdet på CloudWatch-konsollen.
Vi tilbyr en AWS skyformasjon mal i dette innlegget som en generell veiledning. Malen viser hvordan du konfigurerer en CloudWatch-agent på Amazon EMR for å sende Spark-beregninger til CloudWatch. Du kan se gjennom og tilpasse den etter behov for å inkludere Amazon EMR-sikkerhetskonfigurasjonene dine. Som en beste praksis anbefaler vi å inkludere dine Amazon EMR-sikkerhetskonfigurasjoner i malen til kryptere data under overføring.
Du bør også være klar over at noen av ressursene som distribueres av denne stabelen medfører kostnader når de fortsatt er i bruk. I tillegg, EMR-beregninger ikke pådra deg CloudWatch-kostnader. Egendefinerte beregninger påløper imidlertid kostnader basert på CloudWatch-verdier. For mer informasjon, se Amazon CloudWatch-priser.
I de neste avsnittene går vi gjennom følgende trinn:
- Opprett og last opp metrikkbiblioteket, installasjonsskriptet og filterdefinisjonen til en Amazon enkel lagringstjeneste (Amazon S3) bøtte.
- Bruk CloudFormation-malen til å lage følgende ressurser:
- Overvåk Spark-beregningene på CloudWatch-konsollen.
Forutsetninger
Dette innlegget forutsetter at du har følgende:
- An AWS-konto.
- En S3-bøtte for lagring av bootstrap-skriptet, biblioteket og metrisk filterdefinisjon.
- En VPC opprettet i Amazon Virtual Private Cloud (Amazon VPC), hvor EMR-klyngen din vil bli lansert.
- Standard IAM-tjenesteroller for Amazon EMR-tillatelser til AWS-tjenester og -ressurser. Du kan opprette disse rollene med kommandoen aws emr create-default-roles i AWS kommandolinjegrensesnitt (AWS CLI).
- Et valgfritt EC2-nøkkelpar, hvis du planlegger å koble til klyngen din gjennom SSH i stedet for Session Manager, en evne til AWS systemansvarlig.
Definer de nødvendige beregningene
For å unngå å sende unødvendige data til CloudWatch implementerer løsningen vår et metrisk filter. Gjennomgå Spark-dokumentasjon for å bli kjent med navneområdene og tilhørende beregninger. Bestem hvilke beregninger som er relevante for din spesifikke applikasjon og ytelsesmål. Ulike applikasjoner kan kreve forskjellige beregninger for å overvåke, avhengig av arbeidsbelastningen, databehandlingskravene og optimaliseringsmålene. Metriske navnene du vil overvåke bør defineres i Metricfilter.json-filen, sammen med tilhørende navneområder.
Vi har laget et eksempel på Metricfilter.json-definisjon, som inkluderer innhenting av beregninger relatert til data I/O, søppelinnsamling, minne og CPU-trykk, og Spark-jobb-, scene- og oppgaveberegninger.
Merk at visse beregninger ikke er tilgjengelige i alle Spark-utgivelsesversjoner (for eksempel ble appStatus introdusert i Spark 3.0).
Opprett og last opp de nødvendige filene til en S3-bøtte
For mer informasjon, se Laster opp objekter og Installere og kjøre CloudWatch-agenten på serverne dine.
For å opprette og laste opp bootstrap-skriptet, fullfør følgende trinn:
- På Amazon S3-konsollen velger du din S3-bøtte.
- På Objekter kategorien, velg Last opp.
- Velg Legg til filer, velg deretter Metricfilter.json, installer.shog eksempeljob.sh filer.
- I tillegg laster du opp
emr-custom-cw-sink-0.0.1.jarmetrics-bibliotekfil som tilsvarer Amazon EMR-utgivelsesversjonen du skal bruke: - Velg Last opp, og legg merke til S3 URIene for filene.
Tilsett ressurser med CloudFormation-malen
Velg Start Stack for å starte en CloudFormation-stabel i kontoen din og distribuere malen:
![]()
Denne malen oppretter en IAM-rolle, IAM-forekomstprofil, EMR-klynge og CloudWatch-dashbord. Klyngen starter en grunnleggende Eksempel på gnistapplikasjon. Du vil bli fakturert for AWS-ressursene som brukes hvis du oppretter en stabel fra denne malen.
CloudFormation-veiviseren vil be deg om å endre eller oppgi disse parameterne:
- InstanceType - Det type instans for alle forekomstgrupper. Standard er m5.2xlarge.
- InstanceCountCore – Antall instanser i kjerneinstansgruppen. Standard er 4.
- EMRReaseLabel - Det Amazon EMR utgivelsesetikett du vil bruke. Standard er emr-6.9.0.
- BootstrapScriptPath – S3-banen til installer.sh-installasjonsoppstartsskriptet som du kopierte tidligere.
- MetricFilterPath – S3-banen til Metricfilter.json-definisjonen som du kopierte tidligere.
- MetricsLibraryPath – S3-banen til CloudWatch emr-custom-cw-sink-0.0.1.jar-biblioteket som du kopierte tidligere.
- CloudWatchNamespace – Navnet på det tilpassede CloudWatch-navneområdet som skal brukes.
- SparkDemoApplicationPath – S3-banen til examplejob.sh-skriptet som du kopierte tidligere.
- Subnet – EC2-undernettet der klyngen starter. Du må oppgi denne parameteren.
- EC2KeyPairName – Et valgfritt EC2-nøkkelpar for tilkobling til klyngenoder, som et alternativ til Session Manager.
Se beregningene
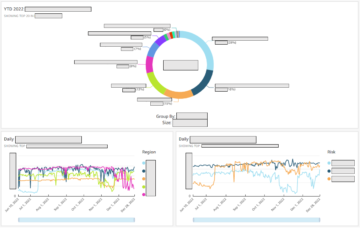
Etter at CloudFormation-stakken er implementert, starter eksempeljobben automatisk og tar omtrent 15 minutter å fullføre. På CloudWatch-konsollen velger du Instrumentbord i navigasjonsruten. Filtrer deretter listen etter prefikset SparkMonitoring.
Eksempeldashbordet inneholder informasjon om klyngen og en oversikt over Spark-jobbene, stadiene og oppgavene. Beregninger er også tilgjengelige under et tilpasset navneområde som begynner med EMRCustomSparkCloudWatchSink.

Minne, CPU, I/O og ytterligere oppgavedistribusjonsberegninger er også inkludert.
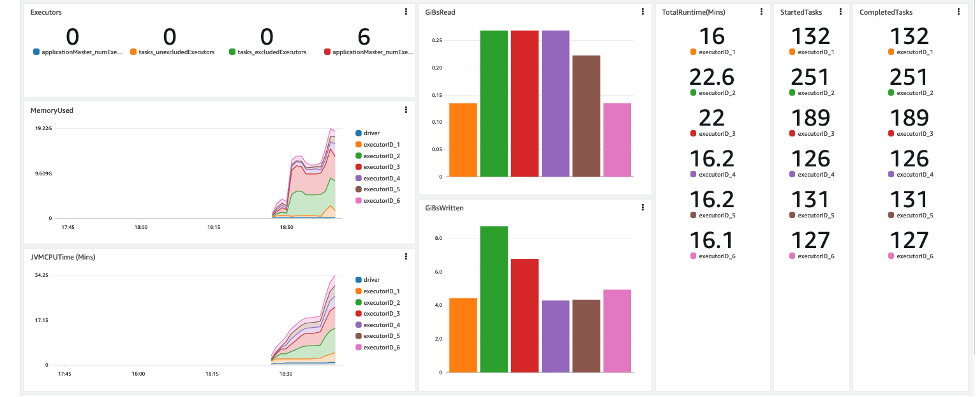
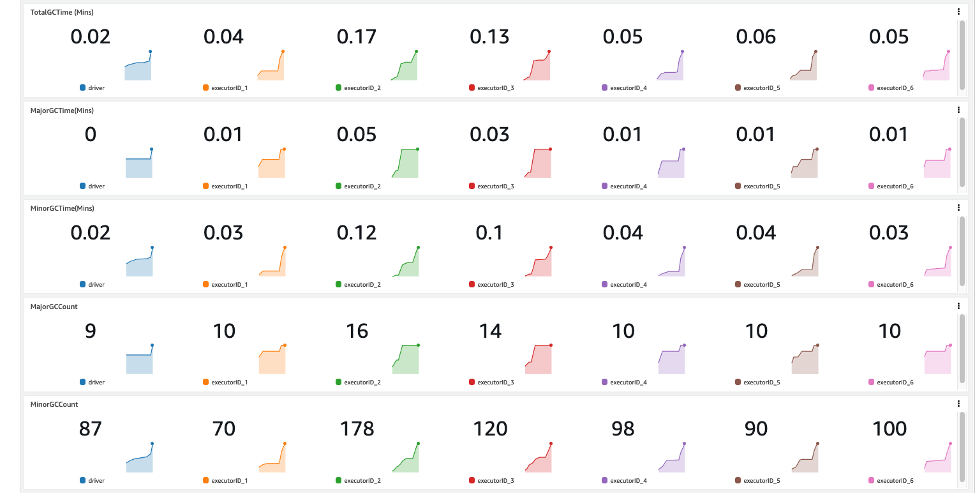
Endelig er detaljerte Java søppelinnsamlingsmålinger tilgjengelige per utfører.
Rydd opp
For å unngå fremtidige belastninger på kontoen din, slett ressursene du opprettet i denne gjennomgangen. EMR-klyngen vil påløpe kostnader så lenge klyngen er aktiv, så stopp den når du er ferdig. Fullfør følgende trinn:
- På CloudFormation-konsollen, i navigasjonsruten, velg Stabler.
- Velg stabelen du lanserte (
EMR-CloudWatch-Demo), og velg deretter Delete. - Tøm S3-bøtta du opprettet.
- Slett S3-bøtten du opprettet.
konklusjonen
Nå som du har fullført trinnene i denne gjennomgangen, kjører CloudWatch-agenten på klyngevertene dine og er konfigurert til å sende Spark-beregninger til CloudWatch. Med denne funksjonen kan du effektivt overvåke helsen og ytelsen til Spark-jobbene dine som kjører på Amazon EMR, oppdage kritiske problemer i sanntid og identifisere rotårsaker raskt.
Du kan pakke og distribuere denne løsningen gjennom en CloudFormation-mal som denne eksempelmalen, som oppretter IAM-forekomstprofilrollen, CloudWatch-dashbordet og EMR-klyngen. Kildekoden for biblioteket er tilgjengelig på GitHub for tilpasning.
For å ta dette videre bør du vurdere å bruke disse beregningene i CloudWatch-alarmer. Du kan samle dem med andre alarmer i en sammensatt alarm eller konfigurer alarmhandlinger som sending Amazon enkel varslingstjeneste (Amazon SNS) varsler for å utløse hendelsesdrevne prosesser som f.eks AWS Lambda funksjoner.
om forfatteren
 Le Clue Lubbe er hovedingeniør ved AWS. Han jobber med våre største bedriftskunder for å løse noen av deres mest komplekse tekniske problemer. Han driver brede løsninger gjennom innovasjon for å påvirke og forbedre livet til våre kunder.
Le Clue Lubbe er hovedingeniør ved AWS. Han jobber med våre største bedriftskunder for å løse noen av deres mest komplekse tekniske problemer. Han driver brede løsninger gjennom innovasjon for å påvirke og forbedre livet til våre kunder.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- ChartPrime. Hev handelsspillet ditt med ChartPrime. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/monitor-apache-spark-applications-on-amazon-emr-with-amazon-cloudwatch/
- :er
- :ikke
- :hvor
- 1
- 100
- 107
- 15%
- 20
- 30
- 9
- a
- evne
- Tilgang
- Logg inn
- kjent
- tvers
- Handling
- handlinger
- aktiv
- aktivitet
- Ytterligere
- I tillegg
- Agent
- alarm
- Alle
- tillater
- langs
- også
- alternativ
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- og
- Apache
- Apache Spark
- Søknad
- søknader
- ca
- arkitektonisk
- arkitektur
- ER
- AS
- assosiert
- antar
- At
- forfatter
- automatisk
- tilgjengelig
- unngå
- klar
- AWS
- basert
- grunnleggende
- BE
- før du
- BEST
- Bootstrap
- bred
- men
- by
- CAN
- evne
- fanger
- fange
- årsaker
- viss
- avgifter
- Velg
- Cluster
- kode
- samle
- samling
- innsamler
- fullføre
- Terminado
- komplekse
- Beregn
- Konfigurasjon
- konfigurert
- Koble
- Tilkobling
- Vurder
- Konsoll
- Kjerne
- tilsvarer
- kostnadseffektiv
- Kostnader
- kunne
- prosessor
- skape
- opprettet
- skaper
- Opprette
- kritisk
- skikk
- Kunder
- tilpasning
- tilpasse
- dashbord
- dato
- databehandling
- Misligholde
- definert
- definisjon
- demonstrere
- demonstrerer
- avhengig
- utplassere
- utplassert
- Distribueres
- detaljert
- Bestem
- forskjellig
- distribueres
- distribusjon
- gjort
- ikke
- stasjoner
- hver enkelt
- Tidligere
- effektivt
- effektivitet
- muliggjøre
- ingeniør
- Enterprise
- bedriftskunder
- avgjørende
- Eter (ETH)
- eksempel
- Trekk
- filet
- Filer
- filtrere
- etter
- Til
- fra
- funksjoner
- videre
- framtid
- general
- få
- Gi
- Go
- Mål
- Gruppe
- Gruppens
- veilede
- Ha
- he
- Helse
- Vertskapet
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- identifisere
- identifisering
- if
- illustrerer
- illustrerer
- Påvirkning
- redskaper
- forbedre
- in
- inkludere
- inkludert
- inkluderer
- Inkludert
- informasjon
- Innovasjon
- innsikt
- installasjon
- installere
- f.eks
- instant
- integrering
- inn
- introdusert
- saker
- IT
- DET ER
- Java
- Jobb
- Jobb
- JSON
- nøkkel
- største
- lansere
- lansert
- lanseringer
- Bibliotek
- Life
- i likhet med
- linje
- Liste
- Lang
- leder
- Kan..
- Minne
- metrisk
- Metrics
- minutter
- modifisere
- Overvåke
- overvåking
- mer
- mest
- må
- navn
- navn
- Navigasjon
- nødvendig
- neste
- node
- noder
- note
- varsling
- varslinger
- Antall
- mål
- of
- on
- bare
- optimalisering
- optimalisere
- alternativer
- or
- Annen
- vår
- oversikt
- pakke
- par
- brød
- parameter
- parametere
- banen
- for
- ytelse
- tillatelser
- fly
- plato
- Platon Data Intelligence
- PlatonData
- portrett
- Post
- kraftig
- praksis
- press
- prising
- Principal
- privat
- problemer
- Prosesser
- prosessering
- Profil
- gi
- gir
- publisere
- Skyv
- skyver
- Skyver
- raskt
- heller
- ekte
- sanntids
- anbefaler
- i slekt
- slipp
- relevant
- forbli
- krever
- påkrevd
- Krav
- ressurs
- ressursutnyttelse
- Ressurser
- ansvarlig
- anmeldelse
- robust
- Rolle
- roller
- root
- rennende
- skalerbar
- sømløs
- Seksjon
- seksjoner
- sikkerhet
- se
- send
- sending
- sender
- tjeneste
- Tjenester
- Session
- bør
- Enkelt
- So
- løsning
- Solutions
- LØSE
- noen
- kilde
- kildekoden
- Spark
- spesifikk
- stable
- Scene
- stadier
- Begynn
- Start
- starter
- Trinn
- Steps
- Stopp
- lagring
- subnett
- vellykket
- slik
- SAMMENDRAG
- system
- Systemer
- Ta
- tar
- Oppgave
- oppgaver
- Teknisk
- mal
- enn
- Det
- De
- Kilden
- deres
- Dem
- deretter
- Disse
- de
- denne
- Gjennom
- tid
- til
- spor
- utløse
- etter
- bruke
- brukt
- ved hjelp av
- bruker
- variasjon
- versjon
- Se
- virtuelle
- walkthrough
- ønsker
- var
- we
- web
- webtjenester
- når
- hvilken
- mens
- vil
- med
- arbeidsflyt
- virker
- X
- yaml
- du
- Din
- zephyrnet