Organisasjoner på tvers av alle bransjer har komplekse databehandlingskrav for sine analytiske brukstilfeller på tvers av ulike analysesystemer, som f.eks datainnsjøer på AWS, datavarehus (Amazon RedShift), Søk (Amazon OpenSearch-tjeneste), NoSQL (Amazon DynamoDB), maskinlæring (Amazon SageMaker), og mer. Analytics-eksperter har i oppgave å hente verdi fra data som er lagret i disse distribuerte systemene for å skape bedre, sikre og kostnadsoptimaliserte opplevelser for kundene deres. For eksempel søker digitale mediebedrifter å kombinere og behandle datasett i interne og eksterne databaser for å bygge enhetlige visninger av kundeprofilene deres, stimulere ideer til innovative funksjoner og øke plattformengasjementet.
I disse scenariene bruker kunder som leter etter en serverløs dataintegrasjon AWS Lim som en kjernekomponent for behandling og katalogisering av data. AWS Glue er godt integrert med AWS-tjenester og partnerprodukter, og gir alternativer for uttrekk, transformasjon og belastning med lav kode/no-kode (ETL) for å aktivere analyse, maskinlæring (ML) eller arbeidsflyter for applikasjonsutvikling. AWS Glue ETL-jobber kan være en komponent i en mer kompleks pipeline. Orkestrere kjøringen av og administrere avhengigheter mellom disse komponentene er en nøkkelfunksjon i en datastrategi. Amazon administrerte arbeidsflyter for Apache Airflows (Amazon MWAA) orkestrerer datapipelines ved hjelp av distribuerte teknologier, inkludert lokale ressurser, AWS-tjenester og tredjepartskomponenter.
I dette innlegget viser vi hvordan du forenkler overvåking av en AWS Glue-jobb orkestrert av Airflow ved å bruke de nyeste funksjonene til Amazon MWAA.
Oversikt over løsning
Dette innlegget diskuterer følgende:
- Hvordan oppgradere et Amazon MWAA-miljø til versjon 2.4.3.
- Hvordan orkestrere en AWS-limjobb fra en luftstrøm Regissert Acyclic Graph (DAG).
- Airflow Amazon-leverandørpakkens observerbarhetsforbedringer i Amazon MWAA. Du kan nå konsolidere kjørelogger over AWS Glue-jobber på Airflow-konsollen for å forenkle feilsøking av datapipelines. Amazon MWAA-konsollen blir en enkelt referanse for å overvåke og analysere AWS Glue-jobbkjøringer. Tidligere trengte støtteteam for å få tilgang til AWS-administrasjonskonsoll og ta manuelle trinn for denne synligheten. Denne funksjonen er tilgjengelig som standard fra Amazon MWAA versjon 2.4.3.
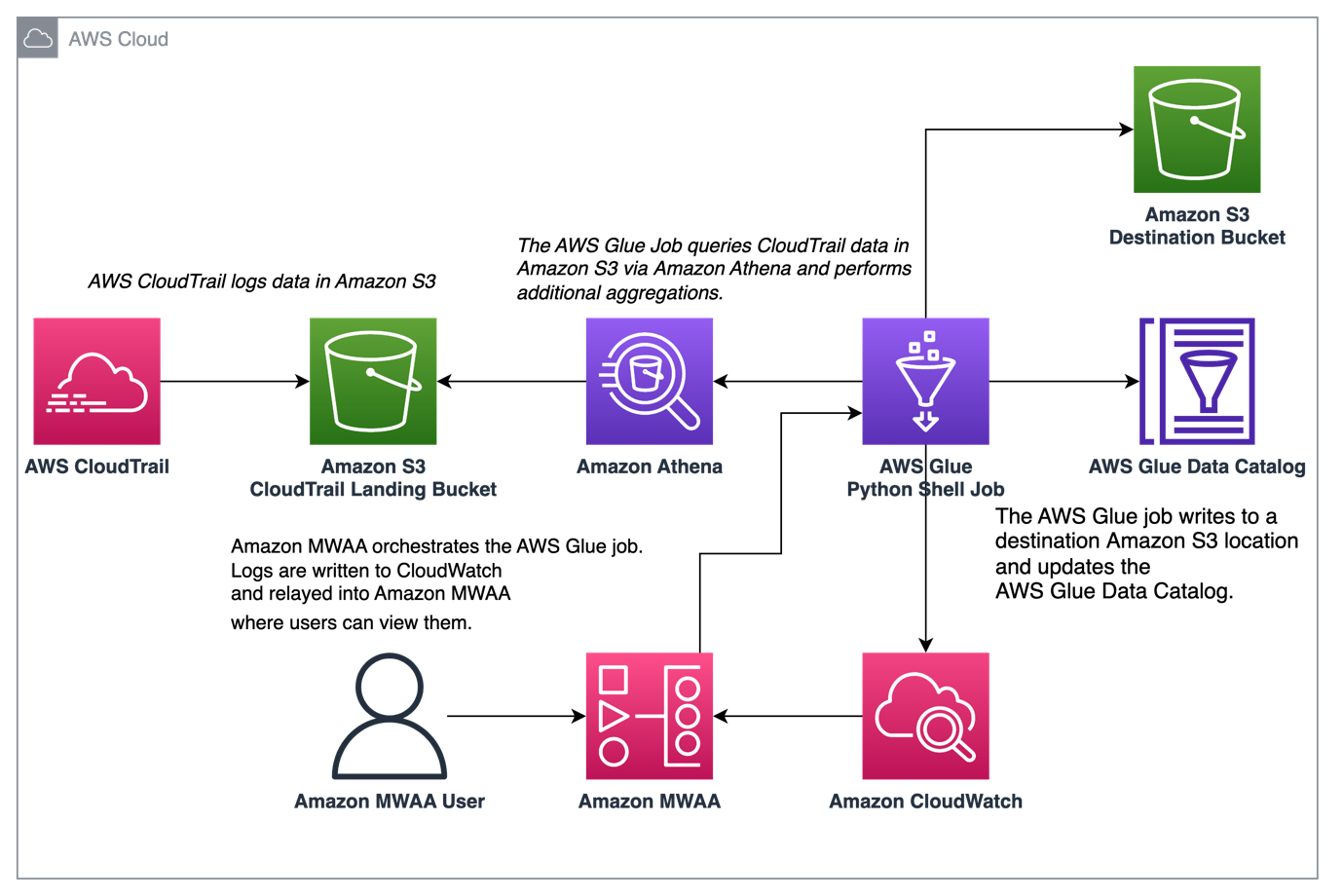
Følgende diagram illustrerer løsningsarkitekturen.
Forutsetninger
Du trenger følgende forutsetninger:
Sett opp Amazon MWAA-miljøet
For instruksjoner om hvordan du lager ditt miljø, se Lag et Amazon MWAA-miljø. For eksisterende brukere anbefaler vi å oppgradere til versjon 2.4.3 for å dra nytte av observerbarhetsforbedringene omtalt i dette innlegget.
Trinnene for å oppgradere Amazon MWAA til versjon 2.4.3 varierer avhengig av om gjeldende versjon er 1.10.12 eller 2.2.2. Vi diskuterer begge alternativene i dette innlegget.
Forutsetninger for å sette opp et Amazon MWAA-miljø
Du må oppfylle følgende forutsetninger:
Oppgrader fra versjon 1.10.12 til 2.4.3
Hvis du bruker Amazon MWAA-versjon 1.10.12, referere til Migrerer til et nytt Amazon MWAA-miljø å oppgradere til 2.4.3.
Oppgrader fra versjon 2.0.2 eller 2.2.2 til 2.4.3
Hvis du bruker Amazon MWAA-miljø versjon 2.2.2 eller lavere, fullfør følgende trinn:
- Lag en requirements.txt for eventuelle tilpassede avhengigheter med spesifikke versjoner som kreves for DAG-ene dine.
- Last opp filen til Amazon S3 på riktig sted der Amazon MWAA-miljøet peker på requirements.txt for installasjon av avhengigheter.
- Følg trinnene i Migrerer til et nytt Amazon MWAA-miljø og velg versjon 2.4.3.
Oppdater DAG-ene dine
Kunder som oppgraderte fra et eldre Amazon MWAA-miljø må kanskje foreta oppdateringer til eksisterende DAG-er. I Airflow versjon 2.4.3 vil Airflow-miljøet bruke Amazon-leverandørpakken versjon 6.0.0 som standard. Denne pakken kan inneholde noen potensielt ødeleggende endringer, for eksempel endringer i operatørnavn. For eksempel AWSGlueJobOperator har blitt avviklet og erstattet med GlueJobOperator. For å opprettholde kompatibiliteten, oppdater Airflow DAG-ene ved å erstatte eventuelle utdaterte eller ikke-støttede operatører fra tidligere versjoner med de nye. Fullfør følgende trinn:
- naviger til Amazon AWS-operatører.
- Velg riktig versjon installert i Amazon MWAA-forekomsten (6.0.0. som standard) for å finne en liste over støttede Airflow-operatører.
- Gjør de nødvendige endringene i den eksisterende DAG-koden og last opp de modifiserte filene til DAG-plasseringen i Amazon S3.
Ordne AWS Glue-jobben fra Airflow
Denne delen dekker detaljene om orkestrering av en AWS-limjobb i Airflow DAG-er. Airflow letter utviklingen av datarørledninger med avhengigheter mellom heterogene systemer som lokale prosesser, eksterne avhengigheter, andre AWS-tjenester og mer.
Orkestrere CloudTrail-loggaggregering med AWS Glue og Amazon MWAA
I dette eksemplet går vi gjennom et brukstilfelle av å bruke Amazon MWAA til å orkestrere en AWS Glue Python Shell-jobb som vedvarer aggregerte beregninger basert på CloudTrail-logger.
CloudTrail muliggjør synlighet til AWS API-anrop som gjøres på AWS-kontoen din. En vanlig brukssak med disse dataene vil være å samle bruksberegninger for oppdragsgivere som handler på kontoens ressurser for revisjons- og regulatoriske behov.
Ettersom CloudTrail-hendelser logges, leveres de som JSON-filer i Amazon S3, som ikke er ideelle for analytiske spørringer. Vi ønsker å samle disse dataene og vedvare dem som parkettfiler for å gi optimal søkeytelse. Som et første trinn kan vi bruke Athena til å gjøre den første spørringen av dataene før vi gjør ytterligere aggregeringer i AWS Glue-jobben vår. For mer informasjon om å lage en AWS Glue Data Catalog-tabell, se Opprette tabellen for CloudTrail-logger i Athena ved hjelp av partisjonsprojeksjon data. Etter at vi har utforsket dataene via Athena og bestemt hvilke beregninger vi ønsker å beholde i aggregerte tabeller, kan vi opprette en AWS Glue-jobb.
Lag en CloudTrail-tabell i Athena
Først må vi lage en tabell i vår datakatalog som lar CloudTrail-data spørres via Athena. Følgende eksempelspørring oppretter en tabell med to partisjoner på Region og dato (kalt snapshot_date). Sørg for å erstatte plassholderne for CloudTrail-bøtte, AWS-konto-ID og CloudTrail-tabellnavn:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Kjør den foregående spørringen på Athena-konsollen, og legg merke til tabellnavnet og AWS Glue Data Catalog-databasen der den ble opprettet. Vi bruker disse verdiene senere i Airflow DAG-koden.
Eksempel på AWS Lim jobbkode
Følgende kode er et eksempel AWS Glue Python Shell jobb som gjør følgende:
- Tar argumenter (som vi sender fra vår Amazon MWAA DAG) om hvilken dags data som skal behandles
- Bruker AWS SDK for pandaer å kjøre en Athena-spørring for å gjøre den første filtreringen av CloudTrail JSON-dataene utenfor AWS Glue
- Bruker Pandas til å gjøre enkle aggregeringer på de filtrerte dataene
- Sender ut de aggregerte dataene til AWS Glue Data Catalog i en tabell
- Bruker logging under behandling, som vil være synlig i Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Følgende er noen viktige fordeler i denne AWS limjobben:
- Vi bruker en Athena-spørring for å sikre at innledende filtrering gjøres utenfor AWS Glue-jobben vår. Som sådan er en Python Shell-jobb med minimal databehandling fortsatt tilstrekkelig for å samle et stort CloudTrail-datasett.
- Vi sikrer alternativ for analytics-biblioteksett er slått på når du oppretter AWS Glue-jobben vår for å bruke AWS SDK for Pandas-biblioteket.
Opprett en AWS-limjobb
Fullfør følgende trinn for å lage din AWS Glue-jobb:
- Kopier skriptet i den foregående delen og lagre det i en lokal fil. For dette innlegget heter filen
script.py. - Velg på AWS Lim-konsollen ETL jobb i navigasjonsruten.
- Opprett en ny jobb og velg Python Shell script editor.
- Plukke ut Last opp og rediger et eksisterende skript og last opp filen du lagret lokalt.
- Velg Opprett.

- På Jobbdetaljer kategorien, skriv inn et navn for AWS-limjobben din.
- Til IAM-rolle, velg en eksisterende rolle eller opprett en ny rolle som har de nødvendige tillatelsene for Amazon S3, AWS Glue og Athena. Rollen må spørre CloudTrail-tabellen du opprettet tidligere og skrive til en utdataplassering.
Du kan bruke følgende eksempelkode. Erstatt plassholderne med CloudTrail-loggbøtte, utdatatabellnavn, utdata AWS Glue-database, utdata S3-bøtte, CloudTrail-tabellnavn, AWS Glue-database som inneholder CloudTrail-tabellen og AWS-konto-ID.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Til Python-versjon, velg Python 3.9.
- Plukke ut Last inn vanlige analysebiblioteker.
- Til Databehandlingsenheter, velg 1 DPU.
- La de andre alternativene være standard eller juster etter behov.

- Velg Spar for å lagre jobbkonfigurasjonen.
Konfigurer en Amazon MWAA DAG for å orkestrere AWS Glue-jobben
Følgende kode er for en DAG som kan orkestrere AWS Glue-jobben som vi opprettet. Vi drar fordel av følgende nøkkelfunksjoner i denne DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Øk observerbarheten av AWS Glue-jobber i Amazon MWAA
AWS Glue-jobbene skriver logger til Amazon CloudWatch. Med de nylige observerbarhetsforbedringene til Airflows Amazon-leverandørpakke, er disse loggene nå integrert med Airflow-oppgavelogger. Denne konsolideringen gir Airflow-brukere ende-til-ende-synlighet direkte i Airflow-grensesnittet, og eliminerer behovet for å søke i CloudWatch eller AWS Glue-konsollen.
For å bruke denne funksjonen, sørg for at IAM-rollen knyttet til Amazon MWAA-miljøet har følgende tillatelser til å hente og skrive de nødvendige loggene:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Hvis verbose=true, vises AWS Glue-jobbkjøringsloggene i Airflow-oppgaveloggene. Standardinnstillingen er falsk. For mer informasjon, se parametere.
Når aktivert, leser DAG-ene fra AWS Glue-jobbens CloudWatch-loggstrøm og videresender dem til Airflow DAG AWS Glue-jobbtrinnloggene. Dette gir detaljert innsikt i en AWS Glue-jobbs kjøring i sanntid via DAG-loggene. Merk at AWS Glue-jobber genererer en utdata- og feil-CloudWatch-logggruppe basert på henholdsvis jobbens STDOUT og STDERR. Alle logger i utdatalogggruppen og unntaks- eller feillogger fra feillogggruppen videresendes til Amazon MWAA.
AWS-administratorer kan nå begrense et støtteteams tilgang til kun Airflow, noe som gjør Amazon MWAA til den eneste glassruten for jobborkestrering og jobbhelseadministrasjon. Tidligere måtte brukere sjekke AWS Glue-jobbkjøringsstatus i Airflow DAG-trinnene og hente jobbkjøringsidentifikatoren. De trengte deretter å få tilgang til AWS Glue-konsollen for å finne jobbkjøringshistorikken, søke etter jobben av interesse ved å bruke identifikatoren, og til slutt navigere til jobbens CloudWatch-logger for å feilsøke.
Opprett DAG
For å opprette DAG, fullfør følgende trinn:
- Lagre den foregående DAG-koden i en lokal .py-fil, og erstatte de angitte plassholderne.
Verdiene for din AWS-konto-ID, AWS Glue-jobbnavn, AWS Glue-database med CloudTrail-tabell og CloudTrail-tabellnavn skal allerede være kjent. Du kan justere utdata S3-bøtten, utdata AWS Glue-databasen og utdatatabellnavnet etter behov, men sørg for at AWS Glue-jobbens IAM-rolle som du brukte tidligere, er konfigurert tilsvarende.
- På Amazon MWAA-konsollen, naviger til miljøet ditt for å se hvor DAG-koden er lagret.
DAGs-mappen er prefikset i S3-bøtten der DAG-filen din skal plasseres.
- Last opp den redigerte filen der.

- Åpne Amazon MWAA-konsollen for å bekrefte at DAG vises i tabellen.

Kjør DAG
For å kjøre DAG, fullfør følgende trinn:
- Velg mellom følgende alternativer:
- Trigger DAG – Dette fører til at gårsdagens data brukes som data som skal behandles
- Trigger DAG m/ konfig – Med dette alternativet kan du sende inn en annen dato, potensielt for utfyllinger, som hentes ved hjelp av
dag_run.confi DAG-koden og deretter sendt inn i AWS Glue-jobben som en parameter

Følgende skjermbilde viser de ekstra konfigurasjonsalternativene hvis du velger det Trigger DAG m/ konfig.

- Overvåk DAG mens den kjører.
- Når DAG er fullført, åpner du kjøringens detaljer.
I den høyre ruten kan du se loggene, eller velge Oppgaveforekomstdetaljer for full oversikt.

- Se AWS Glue-jobbutdataloggene i Amazon MWAA uten å bruke AWS Glue-konsollen takket være
GlueJobOperatorutførlig flagg.

AWS Glue-jobben vil ha skriftlige resultater til utdatatabellen du spesifiserte.
- Spør denne tabellen via Athena for å bekrefte at den var vellykket.
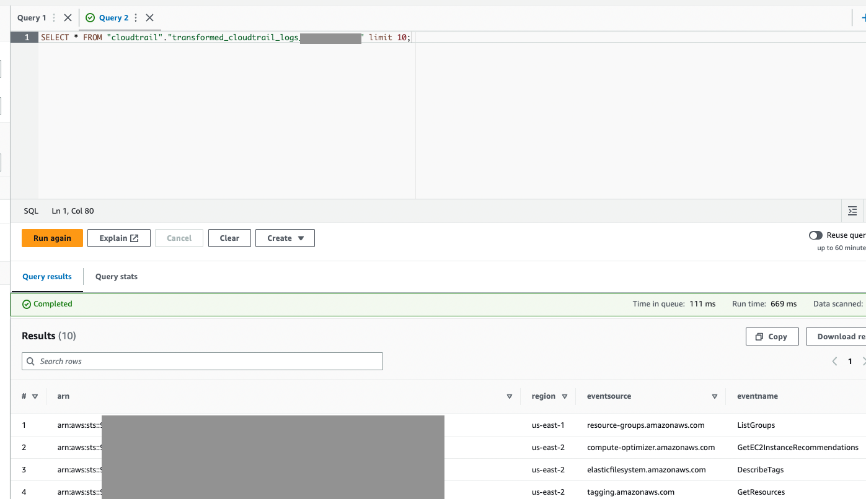
Oppsummering
Amazon MWAA tilbyr nå ett enkelt sted å spore AWS Glue-jobbstatus og lar deg bruke Airflow-konsollen som enkeltglass for jobborkestrering og helsestyring. I dette innlegget gikk vi gjennom trinnene for å orkestrere AWS Glue-jobber via Airflow ved hjelp av GlueJobOperator. Med de nye observerbarhetsforbedringene kan du sømløst feilsøke AWS Glue-jobber i en enhetlig opplevelse. Vi demonstrerte også hvordan du oppgraderer ditt Amazon MWAA-miljø til en kompatibel versjon, oppdaterer avhengigheter og endrer IAM-rollepolicyen tilsvarende.
For mer informasjon om vanlige feilsøkingstrinn, se Feilsøking: Opprette og oppdatere et Amazon MWAA-miljø. For detaljerte detaljer om migrering til et Amazon MWAA-miljø, se Oppgraderer fra 1.10 til 2. For å lære om endringene i åpen kildekode for økt observerbarhet av AWS Glue-jobber i Airflow Amazon-leverandørpakken, se relélogger fra AWS Lim jobber.
Til slutt anbefaler vi å besøke AWS Big Data-blogg for annet materiale om analyser, ML og datastyring på AWS.
Om forfatterne
 Rushabh Lokhande er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han hjelper kunder med å implementere big data, maskinlæring og analyseløsninger. Utenom jobben liker han å tilbringe tid med familien, lese, løpe og spille golf.
Rushabh Lokhande er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han hjelper kunder med å implementere big data, maskinlæring og analyseløsninger. Utenom jobben liker han å tilbringe tid med familien, lese, løpe og spille golf.
 Ryan Gomes er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han brenner for å hjelpe kunder med å oppnå bedre resultater gjennom analyser og maskinlæringsløsninger i skyen. Utenom jobben liker han å trene, lage mat og tilbringe kvalitetstid med venner og familie.
Ryan Gomes er en data- og ML-ingeniør med AWS Professional Services Analytics Practice. Han brenner for å hjelpe kunder med å oppnå bedre resultater gjennom analyser og maskinlæringsløsninger i skyen. Utenom jobben liker han å trene, lage mat og tilbringe kvalitetstid med venner og familie.
 Vishwa Gupta er en senior dataarkitekt med AWS Professional Services Analytics Practice. Han hjelper kunder med å implementere big data og analyseløsninger. Utenom jobben liker han å tilbringe tid med familien, reise og prøve ny mat.
Vishwa Gupta er en senior dataarkitekt med AWS Professional Services Analytics Practice. Han hjelper kunder med å implementere big data og analyseløsninger. Utenom jobben liker han å tilbringe tid med familien, reise og prøve ny mat.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 12
- 8
- a
- Om oss
- adgang
- tilsvar
- Logg inn
- Oppnå
- tvers
- Handling
- asyklisk
- Ytterligere
- Fordel
- fordeler
- Etter
- aggregering
- Alle
- tillate
- tillater
- allerede
- også
- Amazon
- Amazon Web Services
- an
- Analytisk
- analytics
- analysere
- og
- noen
- Apache
- api
- Søknad
- Applikasjonutvikling
- hensiktsmessig
- arkitektur
- ER
- argument
- argumenter
- AS
- At
- attributter
- revisjon
- tilgjengelig
- AWS
- AWS Lim
- AWS profesjonelle tjenester
- basert
- BE
- blir
- vært
- før du
- være
- Bedre
- mellom
- Stor
- Store data
- både
- Breaking
- bygge
- men
- by
- som heter
- Samtaler
- CAN
- saken
- saker
- katalog
- årsaker
- endring
- Endringer
- sjekk
- Velg
- Cloud
- kode
- COM
- kombinere
- kommentere
- Felles
- Selskaper
- kompatibilitet
- kompatibel
- fullføre
- komplekse
- komponent
- komponenter
- Beregn
- Konfigurasjon
- Bekrefte
- Konsoll
- konsolidere
- konsolidering
- matlaging
- Kjerne
- dekker
- skape
- opprettet
- skaper
- Opprette
- Gjeldende
- skikk
- kunde
- Kunder
- DAG
- dato
- dataintegrasjon
- databehandling
- datastrategi
- datavarehus
- Database
- databaser
- datasett
- Dato
- datoer
- dato tid
- Dager
- besluttet
- Misligholde
- levert
- demonstrert
- avhengig
- foreldet
- detaljert
- detaljer
- Utvikling
- avvike
- forskjellig
- digitalt
- Digitale medier
- direkte
- diskutere
- distribueres
- distribuerte systemer
- do
- gjør
- gjør
- gjort
- under
- e
- Tidligere
- letter
- effekt
- eliminere
- ellers
- muliggjøre
- aktivert
- muliggjør
- ende til ende
- engasjement
- ingeniør
- forbedringer
- sikre
- Enter
- Miljø
- feil
- Eter (ETH)
- hendelser
- eksempel
- Unntatt
- unntak
- eksisterer
- eksisterende
- finnes
- erfaring
- Erfaringer
- utforsket
- uttrykk
- utvendig
- trekke ut
- Mislyktes
- falsk
- familie
- Trekk
- kjennetegnet
- Egenskaper
- filet
- Filer
- filtrering
- Endelig
- Finn
- fitness
- etter
- mat
- Til
- format
- venner
- fra
- fullt
- samle
- generere
- glass
- Go
- golf
- styresett
- Gruppe
- Hadoop
- Ha
- he
- Helse
- hjelpe
- hjelper
- historie
- Hive
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- ID
- ideell
- Ideer
- identifikator
- if
- illustrerer
- iverksette
- importere
- in
- dyptgående
- inkludere
- Inkludert
- Øke
- økt
- indikert
- bransjer
- info
- informasjon
- innledende
- innovative
- innsikt
- installere
- f.eks
- instruksjoner
- integrert
- integrering
- interesse
- intern
- inn
- IT
- Jobb
- Jobb
- jpg
- JSON
- nøkkel
- kjent
- stor
- seinere
- siste
- LÆRE
- læring
- Bibliotek
- BEGRENSE
- Liste
- laste
- lokal
- lokalt
- plassering
- logg
- logget
- logging
- ser
- maskin
- maskinlæring
- laget
- vedlikeholde
- gjøre
- Making
- fikk til
- ledelse
- administrerende
- håndbok
- materiale
- Kan..
- Media
- Møt
- melding
- Metrics
- Migrere
- minimal
- ML
- modifisert
- moduler
- Overvåke
- overvåking
- mer
- må
- navn
- navn
- Naviger
- Navigasjon
- nødvendig
- Trenger
- nødvendig
- behov
- Ny
- ingenting
- nå
- of
- tilby
- on
- ONE
- seg
- bare
- åpen
- åpen kildekode
- åpen kildekode
- operatør
- operatører
- optimal
- Alternativ
- alternativer
- or
- orkestrert
- orkestre
- Annen
- vår
- utfall
- produksjon
- utenfor
- pakke
- pandaer
- brød
- parametere
- partner
- passere
- bestått
- lidenskapelig
- ytelse
- tillatelser
- vedvarer
- rørledning
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- poeng
- politikk
- Post
- potensielt
- praksis
- forutsetninger
- forrige
- tidligere
- prosess
- Prosesser
- prosessering
- Produkter
- profesjonell
- fagfolk
- Profiler
- Projeksjon
- leverandør
- tilbydere
- gir
- Python
- kvalitet
- spørsmål
- heve
- område
- Lese
- Lesning
- ekte
- sanntids
- nylig
- anbefaler
- region
- regulatorer
- Relay
- erstatte
- erstattet
- påkrevd
- Krav
- ressurs
- Ressurser
- henholdsvis
- svar
- Resultater
- beholde
- ikke sant
- Rolle
- RAD
- Kjør
- rennende
- s
- Spar
- scenarier
- SDK
- sømløst
- Søk
- Seksjon
- sikre
- se
- Søke
- senior
- server~~POS=TRUNC
- Tjenester
- innstilling
- oppsett
- Shell
- bør
- Vis
- Viser
- Enkelt
- forenkle
- siden
- enkelt
- Snapshot
- løsning
- Solutions
- noen
- spesifikk
- spesifisert
- utgifter
- Uttalelse
- status
- Trinn
- Steps
- Still
- lagring
- lagret
- Strategi
- stream
- String
- vellykket
- slik
- tilstrekkelig
- støtte
- Støttes
- Systemer
- bord
- Ta
- ta
- Oppgave
- lag
- Technologies
- mal
- Takk
- Det
- De
- deres
- Dem
- deretter
- Der.
- Disse
- de
- tredjeparts
- denne
- Gjennom
- tid
- til
- spor
- Transform
- Traveling
- sant
- prøve
- tirsdag
- snudde
- to
- typen
- ui
- enhetlig
- enhet
- Oppdater
- oppdateringer
- oppdatering
- oppgradering
- oppgradert
- Opplasting
- bruk
- bruke
- bruk sak
- brukt
- Brukere
- ved hjelp av
- verdi
- Verdier
- versjon
- av
- Se
- visninger
- synlighet
- synlig
- gikk
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- Hva
- når
- om
- hvilken
- HVEM
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- ville
- skrive
- skrevet
- du
- Din
- zephyrnet