Ettersom Roblox har vokst de siste 16+ årene, har omfanget og kompleksiteten til den tekniske infrastrukturen som støtter millioner av oppslukende 3D-samopplevelser også. Antall maskiner vi støtter har mer enn tredoblet seg de siste to årene, fra omtrent 36,000 30 per 2021. juni 145,000 til nesten 1,000 XNUMX i dag. Å støtte disse alltid-på-opplevelsene for mennesker over hele verden krever mer enn XNUMX interne tjenester. For å hjelpe oss med å kontrollere kostnader og nettverksforsinkelse, distribuerer og administrerer vi disse maskinene som en del av en spesialbygd og hybrid privat skyinfrastruktur som hovedsakelig kjører i lokalene.
Infrastrukturen vår støtter for tiden mer enn 70 millioner daglige aktive brukere rundt om i verden, inkludert skaperne som er avhengige av Roblox's økonomi for deres virksomheter. Alle disse millioner av mennesker forventer et veldig høyt nivå av pålitelighet. Gitt den oppslukende naturen til opplevelsene våre, er det en ekstremt lav toleranse for forsinkelser eller latens, enn si avbrudd. Roblox er en plattform for kommunikasjon og tilkobling, der mennesker kommer sammen i oppslukende 3D-opplevelser. Når folk kommuniserer som deres avatarer i et oppslukende rom, er selv mindre forsinkelser eller feil mer merkbare enn de er på en teksttråd eller en telefonkonferanse.
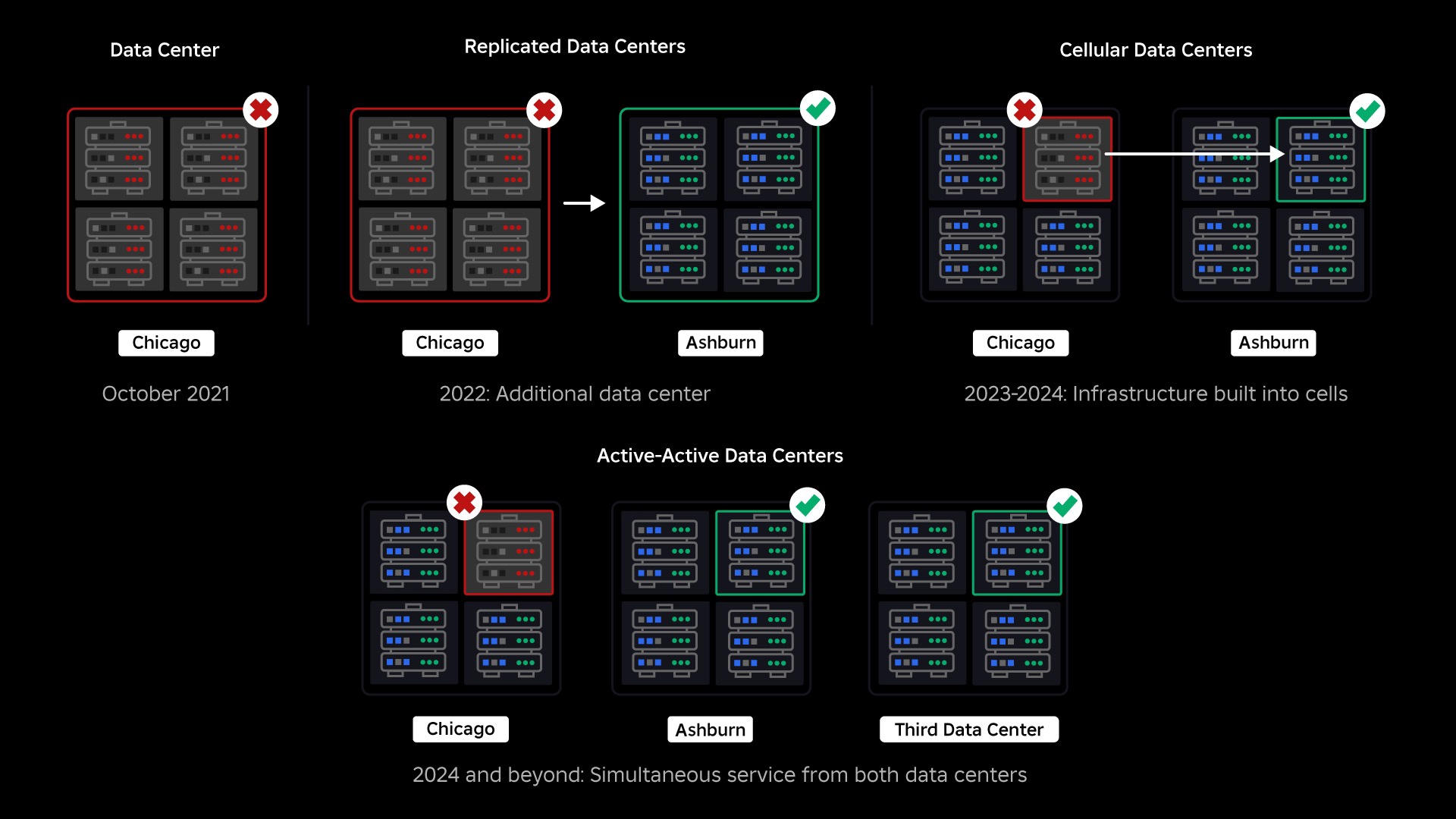
I oktober 2021 opplevde vi en systemomfattende driftsstans. Det begynte i det små, med et problem i én komponent i ett datasenter. Men det spredte seg raskt mens vi undersøkte og resulterte til slutt i et 73-timers driftsbrudd. På den tiden delte vi begge detaljer om hva som skjedde og noen av våre tidlige erfaringer fra problemet. Siden den gang har vi studert disse læringene og arbeidet for å øke motstandskraften til infrastrukturen vår mot de typer feil som oppstår i alle storskala systemer på grunn av faktorer som ekstreme trafikktopper, vær, maskinvarefeil, programvarefeil eller bare mennesker gjør feil. Når disse feilene oppstår, hvordan sikrer vi at et problem i en enkelt komponent, eller gruppe av komponenter, ikke sprer seg til hele systemet? Dette spørsmålet har vært vårt fokus de siste to årene, og mens arbeidet pågår, har det vi har gjort så langt allerede lønnet seg. I første halvdel av 2023 sparte vi for eksempel 125 millioner engasjementstimer per måned sammenlignet med første halvdel av 2022. I dag deler vi arbeidet vi allerede har gjort, samt vår langsiktige visjon for bygging et mer robust infrastruktursystem.
Bygge en bakstopper
Innenfor storskala infrastruktursystemer skjer småskalafeil mange ganger om dagen. Hvis en maskin har et problem og må tas ut av drift, er det håndterbart fordi de fleste selskaper opprettholder flere forekomster av back-end-tjenestene sine. Så når en enkelt forekomst mislykkes, tar andre opp arbeidsmengden. For å løse disse hyppige feilene er forespørsler vanligvis satt til å prøve automatisk på nytt hvis de får en feil.
Dette blir utfordrende når et system eller en person prøver for aggressivt på nytt, noe som kan bli en måte for småskalafeil å spre seg gjennom hele infrastrukturen til andre tjenester og systemer. Hvis nettverket eller en bruker prøver vedvarende nok på nytt, vil det til slutt overbelaste hver forekomst av den tjenesten, og potensielt andre systemer, globalt. Strømbruddet vårt i 2021 var et resultat av noe som er ganske vanlig i store systemer: En feil starter i det små og forplanter seg deretter gjennom systemet, og blir stor så raskt at det er vanskelig å løse før alt går ned.
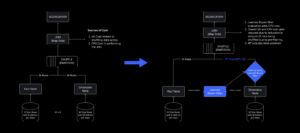
På tidspunktet for strømbruddet hadde vi ett aktivt datasenter (med komponenter i det som fungerte som backup). Vi trengte muligheten til å feile manuelt til et nytt datasenter når et problem bragte det eksisterende ned. Vår første prioritet var å sikre at vi hadde en backup-distribusjon av Roblox, så vi bygde den sikkerhetskopien i et nytt datasenter, lokalisert i en annen geografisk region. Det ekstra beskyttelse for det verste tilfellet: et strømbrudd som sprer seg til nok komponenter i et datasenter til at det blir helt ubrukelig. Vi har nå ett datasenter som håndterer arbeidsbelastninger (aktivt) og ett i standby, som fungerer som backup (passivt). Vårt langsiktige mål er å gå fra denne aktiv-passive konfigurasjonen til en aktiv-aktiv konfigurasjon, der begge datasentrene håndterer arbeidsbelastninger, med en lastbalanser som distribuerer forespørsler mellom dem basert på latens, kapasitet og helse. Når dette er på plass, forventer vi å ha enda høyere pålitelighet for hele Roblox og være i stand til å mislykkes over nesten øyeblikkelig i stedet for over flere timer. 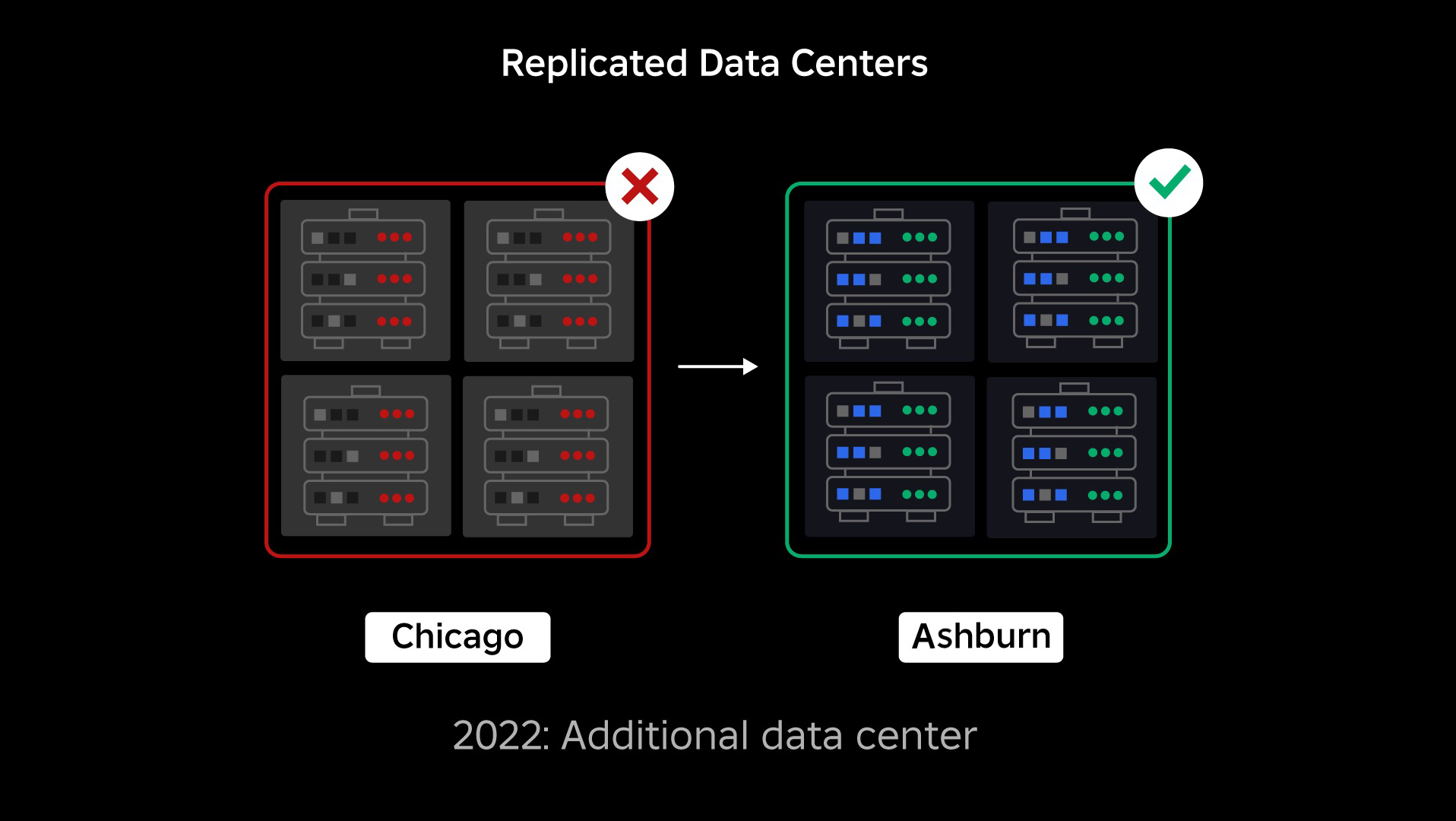
Flytte til en mobilinfrastruktur
Vår neste prioritet var å lage sterke sprengningsvegger inne i hvert datasenter for å redusere muligheten for at et helt datasenter skulle svikte. Celler (noen selskaper kaller dem klynger) er i hovedsak et sett med maskiner og er hvordan vi lager disse veggene. Vi replikerer tjenester både innenfor og på tvers av celler for ekstra redundans. Til syvende og sist ønsker vi at alle tjenester hos Roblox skal kjøre i celler slik at de kan dra nytte av både sterke sprengningsvegger og redundans. Hvis en celle ikke lenger er funksjonell, kan den trygt deaktiveres. Replikering på tvers av celler gjør at tjenesten fortsetter å kjøre mens cellen repareres. I noen tilfeller kan celle-reparasjon bety en fullstendig reprovisionering av cellen. På tvers av industrien er det ganske vanlig å tørke og reprovisionere en individuell maskin, eller et lite sett med maskiner, men å gjøre dette for en hel celle, som inneholder ~1,400 maskiner, er det ikke.
For at dette skal fungere, må disse cellene stort sett være ensartede, slik at vi raskt og effektivt kan flytte arbeidsbelastninger fra en celle til en annen. Vi har satt visse krav som tjenester må oppfylle før de kjører i en celle. For eksempel må tjenester være containeriserte, noe som gjør dem mye mer bærbare og hindrer noen i å gjøre konfigurasjonsendringer på OS-nivå. Vi har tatt i bruk en infrastruktur-som-kode-filosofi for celler: I vårt kildekodelager inkluderer vi definisjonen av alt som er i en celle, slik at vi raskt kan gjenoppbygge den fra bunnen av ved hjelp av automatiserte verktøy.
Ikke alle tjenester oppfyller for øyeblikket disse kravene, så vi har jobbet for å hjelpe tjenesteeiere med å oppfylle dem der det er mulig, og vi har bygget nye verktøy for å gjøre det enkelt å migrere tjenester til celler når de er klare. For eksempel "striper" vårt nye distribusjonsverktøy automatisk en tjenestedistribusjon på tvers av celler, slik at tjenesteeiere ikke trenger å tenke på replikeringsstrategien. Dette strenghetsnivået gjør migrasjonsprosessen mye mer utfordrende og tidkrevende, men den langsiktige gevinsten vil være et system der:
- Det er mye lettere å begrense en feil og forhindre at den sprer seg til andre celler;
- Våre infrastrukturingeniører kan være mer effektive og bevege seg raskere; og
- Ingeniørene som bygger tjenestene på produktnivå som til slutt blir distribuert i celler, trenger ikke å vite eller bekymre seg for hvilke celler tjenestene deres kjører i.
Løse større utfordringer
I likhet med måten branndører brukes til å holde flammer på, fungerer celler som sterke sprengningsvegger i infrastrukturen vår for å hjelpe til med å dekke det problemet som utløser en feil i en enkelt celle. Til slutt vil alle tjenestene som utgjør Roblox, bli redundant distribuert inne i og på tvers av celler. Når dette arbeidet er fullført, kan problemer fortsatt forplante seg bredt nok til å gjøre en hel celle ubrukelig, men det ville være ekstremt vanskelig for et problem å forplante seg utenfor den cellen. Og hvis vi lykkes med å gjøre celler utskiftbare, vil utvinningen gå betydelig raskere fordi vi vil kunne feile over til en annen celle og forhindre at problemet påvirker sluttbrukere.
Der dette blir vanskelig er å skille disse cellene nok til å redusere muligheten for å spre feil, samtidig som ting holdes presterende og funksjonelle. I et komplekst infrastruktursystem må tjenester kommunisere med hverandre for å dele forespørsler, informasjon, arbeidsbelastninger osv. Når vi replikerer disse tjenestene til celler, må vi tenke gjennom hvordan vi håndterer krysskommunikasjon. I en ideell verden omdirigerer vi trafikk fra én usunn celle til andre friske celler. Men hvordan håndterer vi en «dødsforespørsel» – det er det forårsaker en celle for å være usunn? Hvis vi omdirigerer den spørringen til en annen celle, kan det føre til at cellen blir usunn på akkurat den måten vi prøver å unngå. Vi må finne mekanismer for å flytte "god" trafikk fra usunne celler, samtidig som vi oppdager og svelger trafikken som får cellene til å bli usunne.
På kort sikt har vi distribuert kopier av datatjenester til hver datacelle slik at de fleste forespørsler til datasenteret kan betjenes av én enkelt celle. Vi er også lastbalanserende trafikk på tvers av celler. Ser vi lenger ut, har vi begynt å bygge en neste generasjons tjenesteoppdagelsesprosess som vil bli utnyttet av et tjenestenettverk, som vi håper å fullføre i 2024. Dette vil tillate oss å implementere sofistikerte retningslinjer som vil tillate kommunikasjon på tvers av celler kun når det vil ikke påvirke failover-cellene negativt. I 2024 kommer også en metode for å sende avhengige forespørsler til en tjenesteversjon i samme celle, noe som vil minimere trafikk på tvers av celler og dermed redusere risikoen for utbredelse av feil på tvers av celler.
På toppen blir mer enn 70 prosent av back-end-tjenestetrafikken vår betjent utenfor cellene, og vi har lært mye om hvordan vi lager celler, men vi forventer mer forskning og testing ettersom vi fortsetter å migrere tjenestene våre gjennom 2024 og bortenfor. Etter hvert som vi skrider frem, vil disse sprengningsveggene bli stadig sterkere.
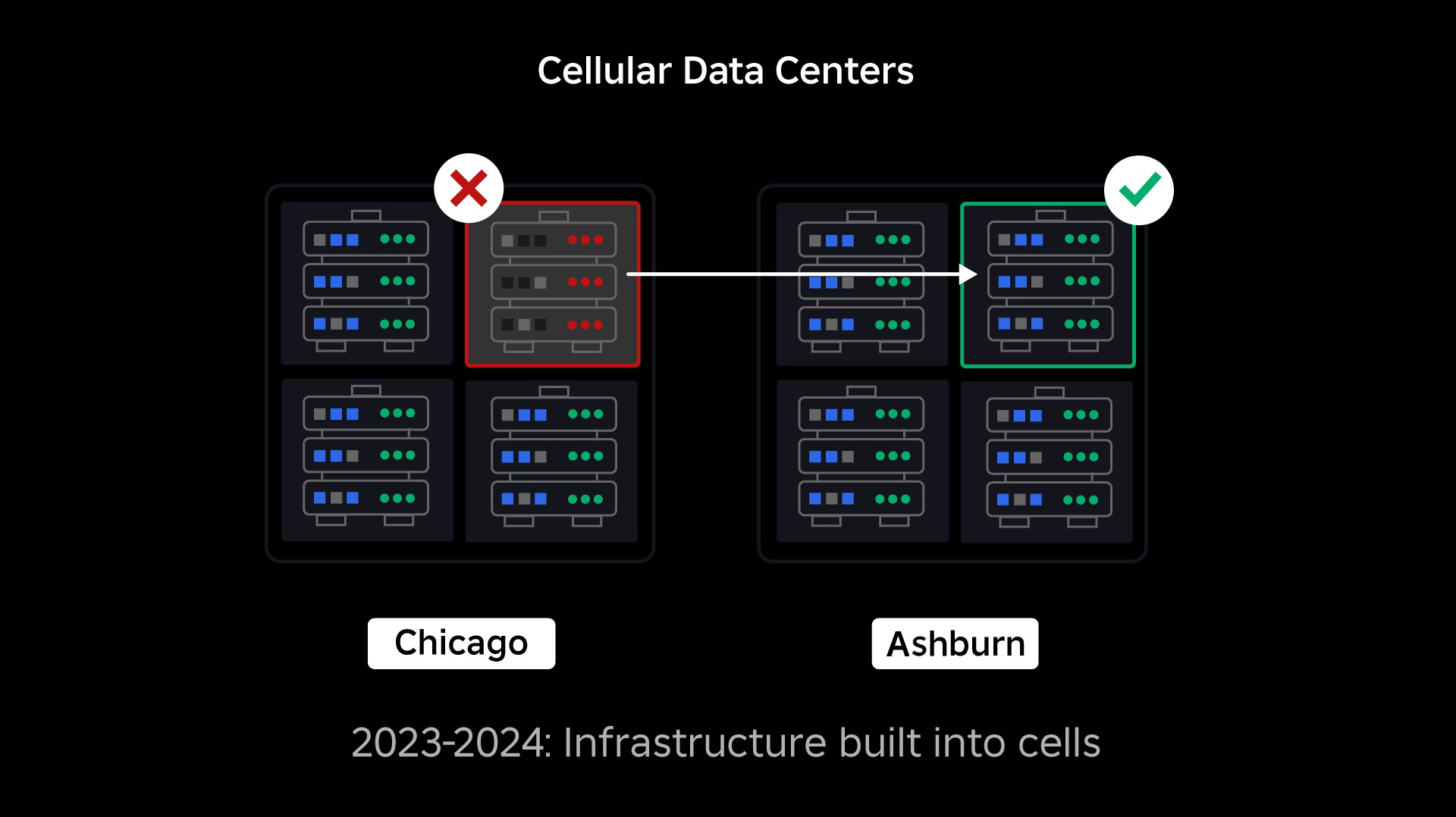
Migrering av en alltid-på-infrastruktur
Roblox er en global plattform som støtter brukere over hele verden, så vi kan ikke flytte tjenester i lav- eller nedetid, noe som ytterligere kompliserer prosessen med å migrere alle maskinene våre til celler og tjenestene våre for å kjøre i disse cellene . Vi har millioner av alltid-på-opplevelser som må fortsette å støttes, selv når vi flytter maskinene de kjører på og tjenestene som støtter dem. Da vi startet denne prosessen, hadde vi ikke titusenvis av maskiner som bare sto ubrukte og tilgjengelige for å migrere disse arbeidsmengdene til.
Vi hadde imidlertid et lite antall ekstra maskiner som ble kjøpt inn i påvente av fremtidig vekst. Til å begynne med bygde vi nye celler ved å bruke disse maskinene, og migrerte deretter arbeidsbelastninger til dem. Vi verdsetter effektivitet så vel som pålitelighet, så i stedet for å gå ut og kjøpe flere maskiner når vi gikk tom for «reserve»-maskiner, bygde vi flere celler ved å tørke og omorganisere maskinene vi hadde migrert fra. Deretter migrerte vi arbeidsbelastninger til disse omdefinerte maskinene, og startet prosessen på nytt. Denne prosessen er kompleks – ettersom maskiner erstattes og frigjøres for å bygges inn i celler, frigjøres de ikke på en ideell, ryddig måte. De er fysisk fragmentert på tvers av datahaller, noe som lar oss klargjøre dem på en stykkevis måte, noe som krever en defragmenteringsprosess på maskinvarenivå for å holde maskinvareplasseringene på linje med store fysiske feildomener.
En del av vårt infrastrukturingeniørteam er fokusert på å migrere eksisterende arbeidsbelastninger fra vårt gamle, eller «pre-celle» miljø, til celler. Dette arbeidet vil fortsette til vi har migrert tusenvis av forskjellige infrastrukturtjenester og tusenvis av back-end-tjenester til nybygde celler. Vi forventer at dette vil ta hele neste år og muligens inn i 2025, på grunn av noen kompliserende faktorer. For det første krever dette arbeidet robust verktøy for å bli bygget. For eksempel trenger vi verktøy for å automatisk rebalansere et stort antall tjenester når vi distribuerer en ny celle – uten å påvirke brukerne våre. Vi har også sett tjenester som ble bygget med antagelser om infrastrukturen vår. Vi må revidere disse tjenestene slik at de ikke er avhengige av ting som kan endre seg i fremtiden når vi flytter inn i cellene. Vi har også implementert både en måte å søke etter kjente designmønstre som ikke fungerer godt med mobilarkitektur, samt en metodisk testprosess for hver tjeneste som er migrert. Disse prosessene hjelper oss med å avverge eventuelle brukervendte problemer forårsaket av en tjeneste som er inkompatibel med celler.
I dag blir nærmere 30,000 99.99 maskiner administrert av celler. Det er bare en brøkdel av vår totale flåte, men det har vært en veldig jevn overgang så langt uten noen negativ spillerpåvirkning. Vårt endelige mål er at systemene våre skal oppnå 0.01 prosent brukeroppetid hver måned, noe som betyr at vi ikke vil forstyrre mer enn XNUMX prosent av engasjementstimer. I hele bransjen kan nedetid ikke elimineres helt, men målet vårt er å redusere eventuell Roblox-nedetid i en grad at det er nesten umerkelig.
Fremtidssikrer når vi skalerer
Mens vår tidlige innsats viser seg vellykket, er arbeidet vårt med celler langt fra ferdig. Ettersom Roblox fortsetter å skalere, vil vi fortsette å jobbe for å forbedre effektiviteten og robustheten til systemene våre gjennom denne og andre teknologier. Etter hvert som vi går, vil plattformen bli stadig mer motstandsdyktig mot problemer, og eventuelle problemer som oppstår bør gradvis bli mindre synlige og forstyrrende for menneskene på plattformen vår.
Oppsummert har vi til dags dato:
- Bygget et ekstra datasenter og oppnådde aktiv/passiv status.
- Laget celler i våre aktive og passive datasentre og migrerte mer enn 70 prosent av vår back-end-tjenestetrafikk til disse cellene.
- Sett på plass kravene og beste praksis vi må følge for å holde alle celler ensartede mens vi fortsetter å migrere resten av infrastrukturen vår.
- Startet en kontinuerlig prosess med å bygge sterkere "eksplosjonsvegger" mellom cellene.
Ettersom disse cellene blir mer utskiftbare, vil det være mindre krysstale mellom cellene. Dette åpner for noen veldig interessante muligheter for oss når det gjelder å øke automatiseringen rundt overvåking, feilsøking og til og med automatisk skiftende arbeidsbelastninger.
I september begynte vi også å kjøre aktive/aktive eksperimenter på tvers av datasentrene våre. Dette er en annen mekanisme vi tester for å forbedre påliteligheten og minimere failover-tider. Disse eksperimentene bidro til å identifisere en rekke systemdesignmønstre, i stor grad rundt datatilgang, som vi må omarbeide mens vi presser mot å bli fullt aktiv-aktive. Alt i alt var eksperimentet vellykket nok til å la det kjøre for trafikken fra et begrenset antall brukere.
Vi er glade for å fortsette å drive dette arbeidet fremover for å gi plattformen større effektivitet og robusthet. Dette arbeidet med celler og aktiv aktiv infrastruktur, sammen med vår andre innsats, vil gjøre det mulig for oss å vokse til et pålitelig, høyytende verktøy for millioner av mennesker og fortsette å skalere mens vi jobber for å koble sammen en milliard mennesker i ekte tid.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- evne
- I stand
- Om oss
- adgang
- Oppnå
- oppnådd
- tvers
- Handling
- skuespill
- aktiv
- la til
- Ytterligere
- adresse
- vedtatt
- en gang til
- aggressivt
- justert
- Alle
- tillate
- alene
- langs
- allerede
- også
- an
- og
- En annen
- forutse
- forventning
- noen
- noen
- ca
- arkitektur
- ER
- rundt
- AS
- antagelser
- At
- Automatisert
- automatisk
- Automatisering
- tilgjengelig
- avatarer
- unngå
- Back-end
- Backup
- swing
- balansering
- basert
- BE
- fordi
- bli
- blir
- bli
- vært
- før du
- begynt
- være
- nytte
- BEST
- beste praksis
- mellom
- Beyond
- Stor
- større
- Milliarder
- Blogg
- både
- bringe
- brakte
- bugs
- bygge
- Bygning
- bygget
- bedrifter
- men
- Kjøpe
- by
- ring
- CAN
- kan ikke
- Kapasitet
- saker
- Årsak
- forårsaket
- forårsaker
- celle
- Celler
- mobilnettet
- sentrum
- Sentre
- viss
- utfordrende
- endring
- Endringer
- Lukke
- Cloud
- sky infrastruktur
- kode
- Kom
- kommer
- Felles
- kommunisere
- kommunisere
- Kommunikasjon
- Selskaper
- sammenlignet
- fullføre
- helt
- komplekse
- kompleksitet
- komponent
- komponenter
- Beregn
- databehandling
- Konferanse
- Konfigurasjon
- Koble
- tilkobling
- inneholde
- inneholder
- fortsette
- fortsetter
- kontinuerlig
- kontroll
- kopier
- Kostnader
- kunne
- skape
- Opprette
- skaperne
- I dag
- Custom-bygget
- daglig
- dato
- data tilgang
- Datasenter
- datasentre
- Dato
- dag
- definisjon
- Grad
- forsinkelser
- avhenge
- avhengig
- utplassere
- utplassert
- distribusjon
- utforming
- designmønstre
- gJORDE
- forskjellig
- vanskelig
- regi
- Funnet
- Avbryte
- forstyrrende
- distribusjon
- do
- gjør
- gjør
- domener
- gjort
- ikke
- dører
- ned
- nedetid
- kjøring
- to
- under
- hver enkelt
- Tidlig
- enklere
- lett
- effektivitet
- effektiv
- effektivt
- innsats
- eliminert
- muliggjør
- slutt
- engasjement
- Ingeniørarbeid
- Ingeniører
- nok
- sikre
- Hele
- fullstendig
- Miljø
- feil
- feil
- hovedsak
- etc
- Selv
- etter hvert
- Hver
- alt
- eksempel
- opphisset
- eksisterende
- forvente
- erfaren
- Erfaringer
- eksperiment
- eksperimenter
- ekstrem
- ekstremt
- faktorer
- FAIL
- sviktende
- mislykkes
- Failure
- feil
- ganske
- langt
- Mote
- raskere
- Finn
- Brann
- Først
- FLÅTE
- Fokus
- fokuserte
- følge
- Til
- Forward
- brøkdel
- fragmentert
- Gratis
- hyppig
- fra
- fullt
- fullt
- funksjonelle
- videre
- framtid
- fremtidig vekst
- generelt
- geografisk
- få
- få
- gitt
- Global
- Globalt
- Go
- mål
- Går
- skal
- større
- Gruppe
- Grow
- voksen
- Vekst
- HAD
- Halvparten
- håndtere
- Håndtering
- skje
- Hard
- maskinvare
- Ha
- hode
- Helse
- sunt
- hjelpe
- hjulpet
- Høy
- høyere
- håp
- TIMER
- Hvordan
- Hvordan
- Men
- HTTPS
- Mennesker
- Hybrid
- ideell
- identifisere
- if
- oppslukende
- Påvirkning
- slag
- iverksette
- implementert
- forbedre
- in
- inkludere
- Inkludert
- uforenlig
- Øke
- økende
- stadig
- individuelt
- industri
- informasjon
- Infrastruktur
- innsiden
- f.eks
- forekomster
- øyeblikkelig
- interessant
- intern
- inn
- utstedelse
- saker
- IT
- juni
- bare
- Hold
- holde
- Vet
- kjent
- stor
- storskala
- i stor grad
- Ventetid
- lært
- Permisjon
- forlater
- Legacy
- mindre
- la
- Nivå
- utnyttet
- i likhet med
- Begrenset
- laste
- ligger
- steder
- langsiktig
- lenger
- ser
- Lot
- Lav
- maskin
- maskiner
- vedlikeholde
- gjøre
- GJØR AT
- Making
- administrer
- fikk til
- manuelt
- mange
- max bredde
- bety
- betyr
- mekanisme
- mekanismer
- Møt
- mesh
- metode
- metodisk
- kunne
- migrere
- migrert
- Migrere
- migrasjon
- millioner
- millioner
- minimere
- mindre
- feil
- overvåking
- Måned
- mer
- mer effektivt
- mest
- flytte
- mye
- flere
- må
- Natur
- nesten
- Trenger
- nødvendig
- negativ
- negativt
- nettverk
- Ny
- nylig
- neste
- neste generasjon
- Nei.
- nå
- Antall
- tall
- forekomme
- oktober
- of
- off
- on
- gang
- ONE
- pågående
- bare
- Muligheter
- Opportunity
- or
- OS
- Annen
- andre
- vår
- ut
- brudd
- brudd
- enn
- samlet
- eiere
- del
- passiv
- Past
- mønstre
- betalende
- Topp
- Ansatte
- for
- prosent
- utfører
- vedvarende
- person
- filosofi
- fysisk
- fysisk
- plukke
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Politikk
- bærbar
- del
- mulighet
- mulig
- muligens
- potensielt
- praksis
- forebygge
- forhindrer
- primært
- prioritet
- privat
- prosess
- Prosesser
- Progress
- gradvis
- forplantning
- beskyttelse
- beviser
- forsyning
- kjøpt
- Skyv
- spørsmål
- spørsmål
- raskt
- heller
- klar
- ekte
- sanntids
- rebalansere
- utvinning
- omdirigere
- redusere
- region
- pålitelighet
- pålitelig
- avhengige
- reparasjon
- erstattet
- replikering
- Repository
- forespørsler
- Krav
- Krever
- forskning
- resiliens
- spenstig
- løse
- REST
- resultere
- resulterte
- revidere
- Risiko
- Roblox
- robust
- Kjør
- rennende
- går
- trygt
- samme
- lagret
- Skala
- scenario
- skraper
- Søk
- Sekund
- sett
- separering
- September
- servert
- tjeneste
- Tjenester
- servering
- sett
- flere
- Del
- delt
- deling
- skift
- SKIFTENDE
- Kort
- bør
- betydelig
- siden
- enkelt
- Sittende
- liten
- glatter
- So
- så langt
- Software
- noen
- noe
- sofistikert
- kilde
- kildekoden
- Rom
- pigger
- spre
- sprer
- Begynn
- startet
- starter
- status
- Still
- Strategi
- sterk
- sterkere
- Studerer
- lykkes
- vellykket
- vellykket
- SAMMENDRAG
- støtte
- Støttes
- Støtte
- Støtter
- system
- Systemer
- Ta
- tatt
- lag
- Teknisk
- Technologies
- titus
- begrep
- vilkår
- Testing
- tekst
- enn
- Det
- De
- Fremtiden
- verden
- deres
- Dem
- deretter
- Der.
- derved
- Disse
- de
- ting
- tror
- denne
- De
- tusener
- Gjennom
- hele
- tid
- ganger
- til
- i dag
- sammen
- toleranse
- også
- verktøy
- verktøy
- Totalt
- mot
- trafikk
- overgang
- utløsende
- prøver
- to
- typer
- ultimate
- Til syvende og sist
- låser opp
- til
- ubrukt
- upon
- oppetid
- us
- brukt
- Bruker
- Brukere
- ved hjelp av
- verktøyet
- verdi
- versjon
- veldig
- synlig
- syn
- ønsker
- var
- Vei..
- we
- Vær
- VI VIL
- var
- Hva
- uansett
- når
- hvilken
- mens
- HVEM
- bred
- vil
- tørke
- med
- innenfor
- Arbeid
- arbeidet
- arbeid
- verden
- bekymring
- ville
- år
- år
- zephyrnet