Amazon EMR er en stordatatjeneste som tilbys av AWS for å kjøre Apache Spark og andre åpen kildekode-applikasjoner på AWS for å bygge skalerbare datapipelines på en kostnadseffektiv måte. Overvåking av loggene som genereres fra jobbene som er distribuert på EMR-klynger, er viktig for å hjelpe med å oppdage kritiske problemer i sanntid og raskt identifisere rotårsaker.
Skyver de loggene inn Amazon CloudWatch lar deg sentralisere og drive handlingskraftig intelligens fra loggene dine for å løse driftsproblemer uten å måtte klargjøre servere eller administrere programvare. Du kan umiddelbart begynne å skrive spørringer med aggregeringer, filtre og regulære uttrykk. I tillegg kan du visualisere tidsseriedata, se nærmere på individuelle logghendelser og eksportere søkeresultater til CloudWatch-dashboards.
Å svelge logger som vedvares på Amazon Elastic Compute Cloud (Amazon EC2) forekomster av en EMR-klynge inn i CloudWatch, kan du bruke CloudWatch-agent. Dette gir en enkel måte å sende logger fra en EC2-instans til CloudWatch.
CloudWatch-agenten er en programvarepakke som kjører autonomt og kontinuerlig på dine servere. Du kan installere og konfigurere CloudWatch-agenten for å samle inn system- og applikasjonslogger fra EC2-forekomster, lokale verter og containeriserte applikasjoner. CloudWatch behandler og lagrer loggene som samles inn av CloudWatch-agenten, noe som ytterligere hjelper med ytelse og helseovervåking av infrastrukturen og applikasjonene dine.
I dette innlegget oppretter vi en EMR-klynge og sentraliserer EMR-trinnloggene for jobbene i CloudWatch. Dette vil gjøre det enklere for deg å administrere EMR-klyngen, feilsøke problemer og overvåke ytelsen. Denne løsningen er spesielt nyttig hvis du vil bruke CloudWatch til å samle inn og visualisere sanntidslogger, beregninger og hendelsesdata, og strømlinjeforme infrastrukturen og vedlikeholdet av applikasjoner.
Oversikt over løsning
Løsningen som presenteres i dette innlegget er basert på en spesifikk konfigurasjon der samtidighetsnivået for EMR-trinn er satt til 1. Dette betyr at kun ett trinn kjøres om gangen på klyngen. Det er viktig å merke seg at hvis samtidighetsnivået for EMR-trinn er satt til en verdi større enn 1, kan det hende at løsningen ikke fungerer som forventet. Vi anbefaler på det sterkeste å bekrefte din EMR trinn samtidighet konfigurasjon før du implementerer løsningen presentert i dette innlegget.
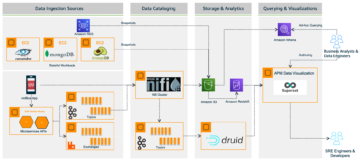
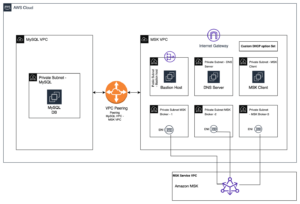
Følgende diagram illustrerer løsningsarkitekturen.
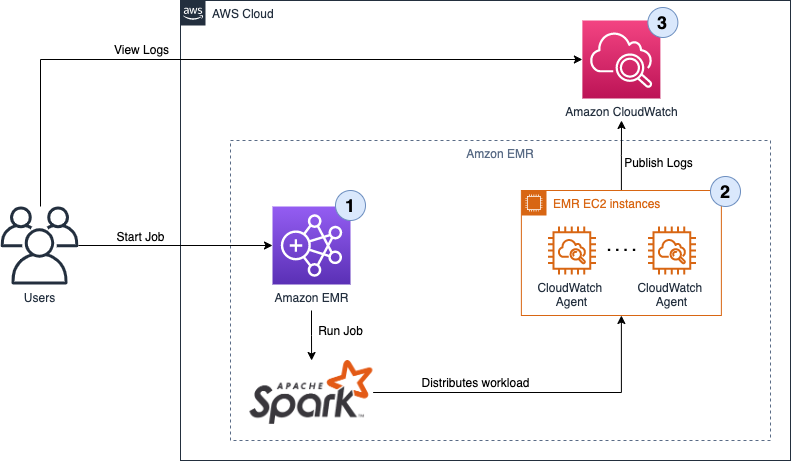
Arbeidsflyten inkluderer følgende trinn:
- Brukere starter en Apache Spark EMR-jobb, og lager et trinn på EMR-klyngen. Ved å bruke Apache Spark blir arbeidsbelastningen fordelt på de forskjellige nodene i EMR-klyngen.
- I hver node (EC2-forekomst) av klyngen ser en CloudWatch-agent på forskjellige loggkataloger, fanger opp nye oppføringer i loggfilene og skyver dem til CloudWatch.
- Brukere kan se trinnloggene for tilgang til de forskjellige logggruppene fra CloudWatch-konsollen. Trinnloggene skrevet av Amazon EMR er som følger:
- controller — Informasjon om behandlingen av trinnet. Hvis trinnet ditt mislykkes under lasting, kan du finne stabelsporet i denne loggen.
- stderr — Standardfeilkanalen til Spark mens den behandler trinnet.
- stdout — Standard utgangskanal til Spark mens den behandler trinnet.
Vi tilbyr en AWS skyformasjon mal i dette innlegget som en generell veiledning. Malen viser hvordan du konfigurerer en CloudWatch-agent på Amazon EMR for å sende Spark-logger til CloudWatch. Du kan se gjennom og tilpasse den etter behov for å inkludere Amazon EMR-sikkerhetskonfigurasjonene dine. Som en beste praksis anbefaler vi å inkludere dine Amazon EMR-sikkerhetskonfigurasjoner i malen til kryptere data under overføring.
Du bør også være klar over at noen av ressursene som distribueres av denne stabelen medfører kostnader når de fortsatt er i bruk.
I de neste avsnittene går vi gjennom følgende trinn:
- Opprett og last opp bootstrap-skriptet til en Amazon enkel lagringstjeneste (Amazon S3) bøtte.
- Bruk CloudFormation-malen til å lage følgende ressurser:
- Overvåk Spark-loggene på CloudWatch-konsollen.
Forutsetninger
Dette innlegget forutsetter at du har følgende:
Opprett og last opp bootstrap-skriptet til en S3-bøtte
For mer informasjon, se Laster opp objekter og Installere og kjøre CloudWatch-agenten på serverne dine.
For å opprette og laste opp bootstrap-skriptet, fullfør følgende trinn:
- Lag en lokal fil med navnet
bootstrap_cloudwatch_agent.shmed følgende innhold: - På Amazon S3-konsollen velger du din S3-bøtte.
- På Objekter kategorien, velg Last opp.
- Velg Legg til filer, og velg deretter bootstrap-skriptet.
- Velg Last opp, velg deretter filnavnet:
bootstrap_cloudwatch_agent.sh. - Velg Kopier S3 URI. Vi bruker denne verdien i et senere trinn.
Tilsett ressurser med CloudFormation-malen
Velg Start Stack for å starte en CloudFormation-stabel i kontoen din og distribuere malen:
![]()
Denne malen oppretter en IAM-rolle, IAM-forekomstprofil, Systems Manager-parameter og EMR-klynge. Klyngen starter Eksempelapplikasjon for Spark PI-estimering. Du vil bli fakturert for AWS-ressursene som brukes hvis du oppretter en stabel fra denne malen.
CloudFormation-veiviseren vil be deg om å endre eller oppgi disse parameterne:
- InstanceType - Det type instans for alle forekomstgrupper. Standard er m4.xlarge.
- InstanceCountCore – Antall instanser i kjerneinstansgruppen. Standard er 2.
- EMRReaseLabel - Det Amazon EMR utgivelsesetikett du vil bruke. Standard er emr-6.9.0.
- BootstrapScriptPath – S3-banen til oppstartsskriptet for CloudWatch-agentinstallasjonen som du kopierte tidligere.
- Subnet – EC2-undernettet der klyngen starter. Du må oppgi denne parameteren.
- EC2KeyPairName – Et valgfritt EC2-nøkkelpar for tilkobling til klyngenoder, som et alternativ til Session Manager.
Overvåk loggstrømmene
Etter at CloudFormation-stakken er implementert, velger du på CloudWatch-konsollen Logggrupper i navigasjonsruten. Filtrer deretter logggruppene etter prefikset /aws/emr/master.
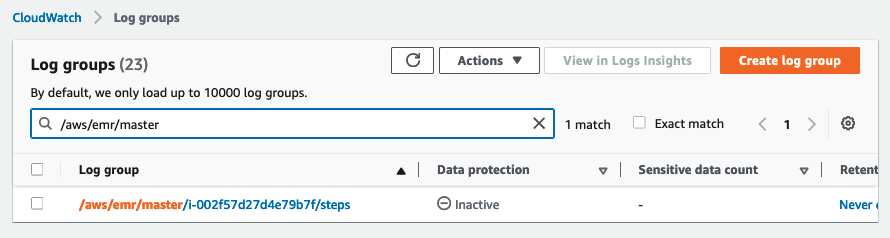
ID-en i logggruppen tilsvarer EC2-forekomst-ID-en til EMR-primærnoden. Hvis du har flere EMR-klynger, kan du bruke denne IDen til å identifisere en bestemt EMR-klynge, basert på den primære node-IDen.
I logggruppen finner du de tre ulike loggstrømmene.
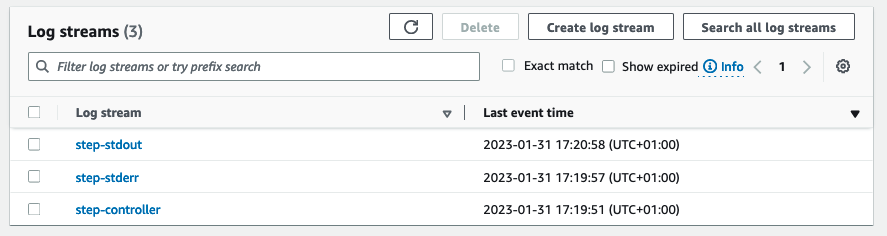
Loggstrømmene inneholder følgende informasjon:
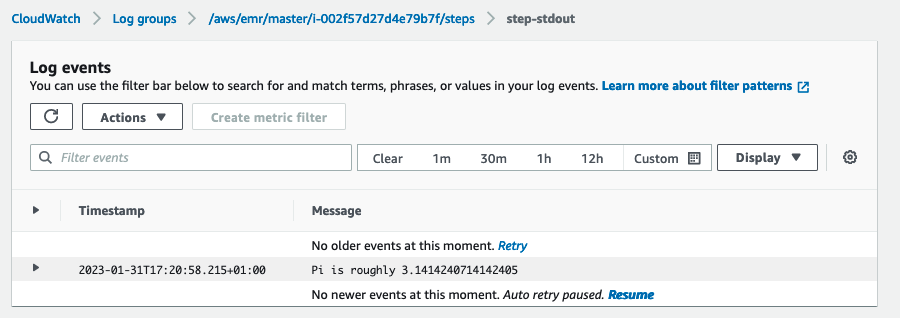
- trinn-stdout – Standard utgangskanal til Spark mens den behandler trinnet.
- trinn-stderr – Standardfeilkanalen til Spark mens den behandler trinnet.
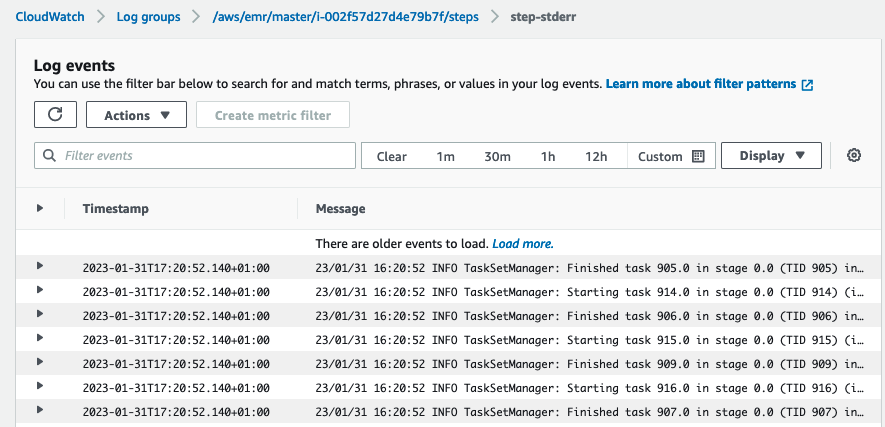
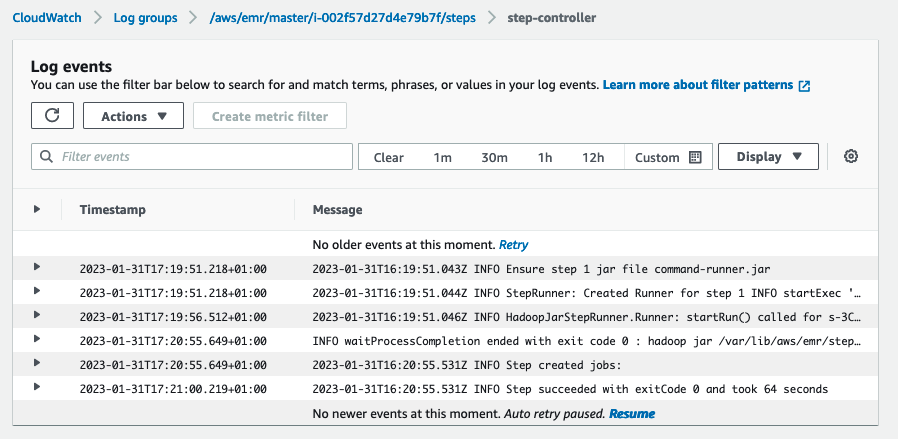
- trinn-kontroller – Informasjon om behandlingen av trinnet. Hvis trinnet ditt mislykkes under lasting, kan du finne stabelsporet i denne loggen.
Rydd opp
For å unngå fremtidige belastninger på kontoen din, slett ressursene du opprettet i denne gjennomgangen. EMR-klyngen vil påløpe kostnader så lenge klyngen er aktiv, så stopp den når du er ferdig.
- På CloudFormation-konsollen, i navigasjonsruten, velg Stabler.
- Velg stabelen du lanserte (
EMR-CloudWatch-Demo), og velg deretter Delete. - Tøm S3-bøtta du opprettet.
- Slett S3-bøtten du opprettet.
konklusjonen
Nå som du har fullført trinnene i denne gjennomgangen, har du CloudWatch-agenten kjørende på klyngevertene dine og konfigurert til å sende EMR-trinnlogger til CloudWatch. Med denne funksjonen kan du effektivt overvåke helsen og ytelsen til Spark-jobbene dine som kjører på Amazon EMR, oppdage kritiske problemer i sanntid og identifisere rotårsaker raskt.
Du kan pakke og distribuere denne løsningen gjennom en CloudFormation-mal som denne eksempelmalen, som oppretter IAM-forekomstprofilrollen, Systems Manager-parameteren og EMR-klyngen.
For å ta dette videre bør du vurdere å bruke disse loggene i CloudWatch-alarmer for varsler på en logg gruppe-metrisk filter. Du kan samle dem med andre alarmer i en sammensatt alarm eller konfigurer alarmhandlinger som sending Amazon enkel varslingstjeneste (Amazon SNS) varsler for å utløse hendelsesdrevne prosesser som f.eks AWS Lambda funksjoner.
om forfatteren
 Ennio Pastore er senior dataarkitekt i AWS Data Lab-teamet. Han er entusiast for alt knyttet til nye teknologier som har en positiv innvirkning på bedrifter og generelt levebrød. Ennio har over 10 års erfaring innen dataanalyse. Han hjelper selskaper med å definere og implementere dataplattformer på tvers av bransjer, som telekommunikasjon, bank, spill, detaljhandel og forsikring.
Ennio Pastore er senior dataarkitekt i AWS Data Lab-teamet. Han er entusiast for alt knyttet til nye teknologier som har en positiv innvirkning på bedrifter og generelt levebrød. Ennio har over 10 års erfaring innen dataanalyse. Han hjelper selskaper med å definere og implementere dataplattformer på tvers av bransjer, som telekommunikasjon, bank, spill, detaljhandel og forsikring.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/push-amazon-emr-step-logs-from-amazon-ec2-instances-to-amazon-cloudwatch-logs/
- :er
- 1
- 10
- 100
- 9
- a
- Om oss
- Tilgang
- Logg inn
- tvers
- handlinger
- aktiv
- tillegg
- adresse
- Agent
- alarm
- varsler
- Alle
- alternativ
- Amazon
- Amazon EC2
- Amazon EMR
- analytics
- og
- Apache
- Apache Spark
- Søknad
- søknader
- arkitektur
- ER
- AS
- At
- autonomt
- AWS
- Banking
- basert
- BE
- før du
- begynne
- BEST
- Stor
- Store data
- Bootstrap
- bygge
- bedrifter
- by
- CAN
- fange
- årsaker
- Kanal
- avgifter
- Velg
- Cluster
- samle
- Selskaper
- fullføre
- Terminado
- Beregn
- Konfigurasjon
- Tilkobling
- Vurder
- Konsoll
- innhold
- kontinuerlig
- Kjerne
- tilsvarer
- kostnadseffektiv
- Kostnader
- kunne
- skape
- opprettet
- skaper
- Opprette
- kritisk
- tilpasse
- dato
- Data Analytics
- Misligholde
- demonstrerer
- utplassere
- utplassert
- Distribueres
- forskjellig
- kataloger
- distribueres
- ned
- stasjonen
- hver enkelt
- Tidligere
- enklere
- savner
- effektivt
- muliggjør
- entusiast
- feil
- avgjørende
- Eter (ETH)
- Event
- hendelser
- alt
- eksempel
- forventet
- erfaring
- eksportere
- uttrykkene
- mislykkes
- Trekk
- filet
- Filer
- filtrere
- filtre
- Finn
- etter
- følger
- Til
- fra
- funksjoner
- videre
- framtid
- gaming
- general
- generert
- Go
- større
- Gruppe
- Gruppens
- veilede
- Ha
- Helse
- hjelpe
- nyttig
- hjelper
- svært
- Vertskapet
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- IAM
- ID
- identifisere
- identifisering
- Påvirkning
- iverksette
- implementere
- viktig
- in
- inkludere
- inkluderer
- Inkludert
- individuelt
- bransjer
- informasjon
- Infrastruktur
- installere
- installere
- f.eks
- forsikring
- Intelligens
- saker
- IT
- Jobb
- Jobb
- jpg
- JSON
- lab
- lansere
- lansert
- lanseringer
- Nivå
- i likhet med
- lasting
- lokal
- Lang
- vedlikehold
- gjøre
- administrer
- leder
- måte
- midler
- Metrics
- modifisere
- Overvåke
- overvåking
- mer
- flere
- navn
- oppkalt
- Navigasjon
- nødvendig
- trenger
- Ny
- Ny teknologi
- neste
- node
- noder
- varsling
- varslinger
- Antall
- of
- tilbudt
- on
- ONE
- åpen kildekode
- operasjonell
- Annen
- produksjon
- pakke
- brød
- parameter
- parametere
- Spesielt
- spesielt
- banen
- ytelse
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- positiv
- Post
- praksis
- presentert
- primære
- Prosesser
- prosessering
- Profil
- gi
- gir
- forsyning
- Skyv
- Skyver
- raskt
- ekte
- sanntids
- anbefaler
- regelmessig
- i slekt
- slipp
- forbli
- Ressurser
- Resultater
- detaljhandel
- anmeldelse
- Rolle
- root
- Kjør
- rennende
- skalerbar
- seksjoner
- sikkerhet
- sending
- senior
- Serien
- tjeneste
- Session
- sett
- bør
- Enkelt
- So
- Software
- løsning
- noen
- Spark
- spesifikk
- stable
- Standard
- Begynn
- Start
- starter
- Trinn
- Steps
- Stopp
- lagring
- butikker
- effektivisering
- bekker
- subnett
- vellykket
- slik
- sudo
- system
- Systemer
- Ta
- lag
- Technologies
- telekommunikasjon
- mal
- Det
- De
- Dem
- Disse
- tre
- Gjennom
- tid
- Tidsserier
- til
- spore
- utløse
- bruke
- verdi
- verifisere
- Se
- walkthrough
- klokker
- Vei..
- hvilken
- mens
- vil
- med
- uten
- Arbeid
- arbeidsflyt
- skriving
- skrevet
- yaml
- år
- Din
- zephyrnet