작성자 별 이미지
이 게시물에서는 Mixtral 8x7b라는 새로운 최첨단 오픈 소스 모델을 살펴보겠습니다. 또한 LLaMA C++ 라이브러리를 사용하여 액세스하는 방법과 줄어든 컴퓨팅 및 메모리에서 대규모 언어 모델을 실행하는 방법도 알아봅니다.
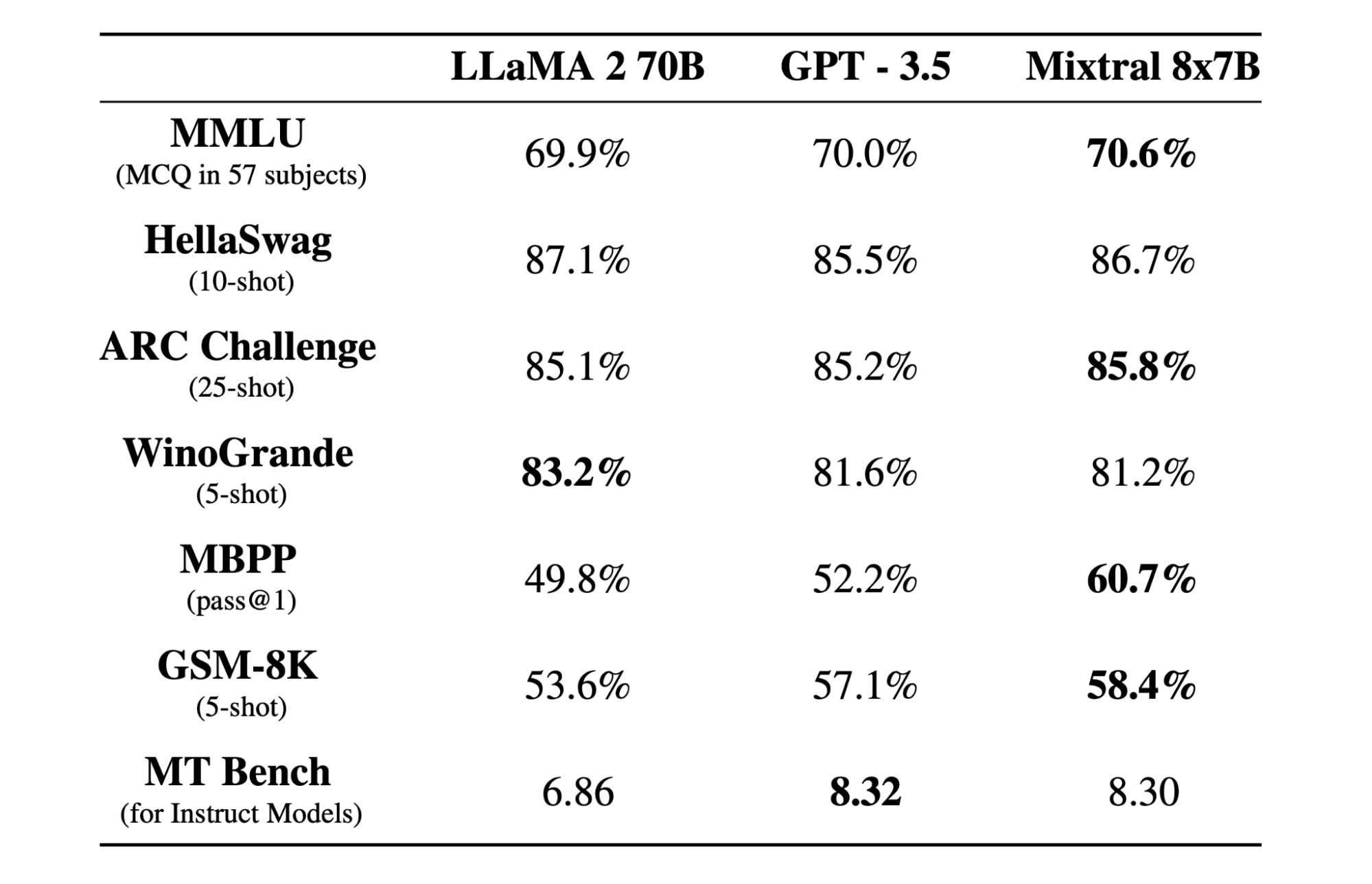
믹스트랄 8x7b Mistral AI에서 만든 개방형 가중치를 갖춘 고품질 SMoE(Sparse Mixture of Experts) 모델입니다. Apache 2.0 라이센스가 부여되었으며 대부분의 벤치마크에서 Llama 2 70B보다 성능이 뛰어나며 추론 속도는 6배 더 빠릅니다. Mixtral은 대부분의 표준 벤치마크에서 GPT3.5와 일치하거나 능가하며 비용/성능 측면에서 최고의 개방형 모델입니다.
이미지 출처 : 전문가들의 혼합
Mixtral 8x7B는 디코더 전용 희소 전문가 혼합 네트워크를 사용합니다. 여기에는 8개의 매개변수 그룹에서 선택하는 피드포워드 블록이 포함되며, 라우터 네트워크는 각 토큰에 대해 이러한 그룹 중 12.9개를 선택하고 해당 출력을 추가로 결합합니다. 이 방법은 비용과 대기 시간을 관리하는 동시에 모델의 매개변수 수를 향상시켜 총 매개변수가 46.7B임에도 불구하고 XNUMXB 모델만큼 효율적이게 만듭니다.
Mixtral 8x7B 모델은 32k 토큰의 광범위한 컨텍스트를 처리하는 데 탁월하며 영어, 프랑스어, 이탈리아어, 독일어, 스페인어를 포함한 여러 언어를 지원합니다. 이는 코드 생성에서 강력한 성능을 보여주며 명령 따르기 모델로 미세 조정되어 MT-Bench와 같은 벤치마크에서 높은 점수를 얻을 수 있습니다.
LLaMA.cpp Facebook의 LLM 아키텍처를 기반으로 LLM(대형 언어 모델)을 위한 고성능 인터페이스를 제공하는 C/C++ 라이브러리입니다. 텍스트 생성, 번역, 질문 답변 등 다양한 작업에 사용할 수 있는 가볍고 효율적인 라이브러리입니다. LLaMA.cpp는 LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B 및 GPT4ALL을 포함한 광범위한 LLM을 지원합니다. 모든 운영 체제와 호환되며 CPU와 GPU 모두에서 작동할 수 있습니다.
이 섹션에서는 Colab에서 llama.cpp 웹 애플리케이션을 실행하겠습니다. 몇 줄의 코드만 작성하면 PC나 Google Colab에서 새로운 최첨단 모델 성능을 경험할 수 있습니다.
시작 가이드
먼저 아래 명령줄을 사용하여 llama.cpp GitHub 저장소를 다운로드합니다.
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.git그런 다음 디렉터리를 저장소로 변경하고 `make` 명령을 사용하여 llama.cpp를 설치합니다. CUDA가 설치된 NVidia GPU용 llama.cpp를 설치하고 있습니다.
%cd llama.cpp
!make LLAMA_CUBLAS=1모델 다운로드
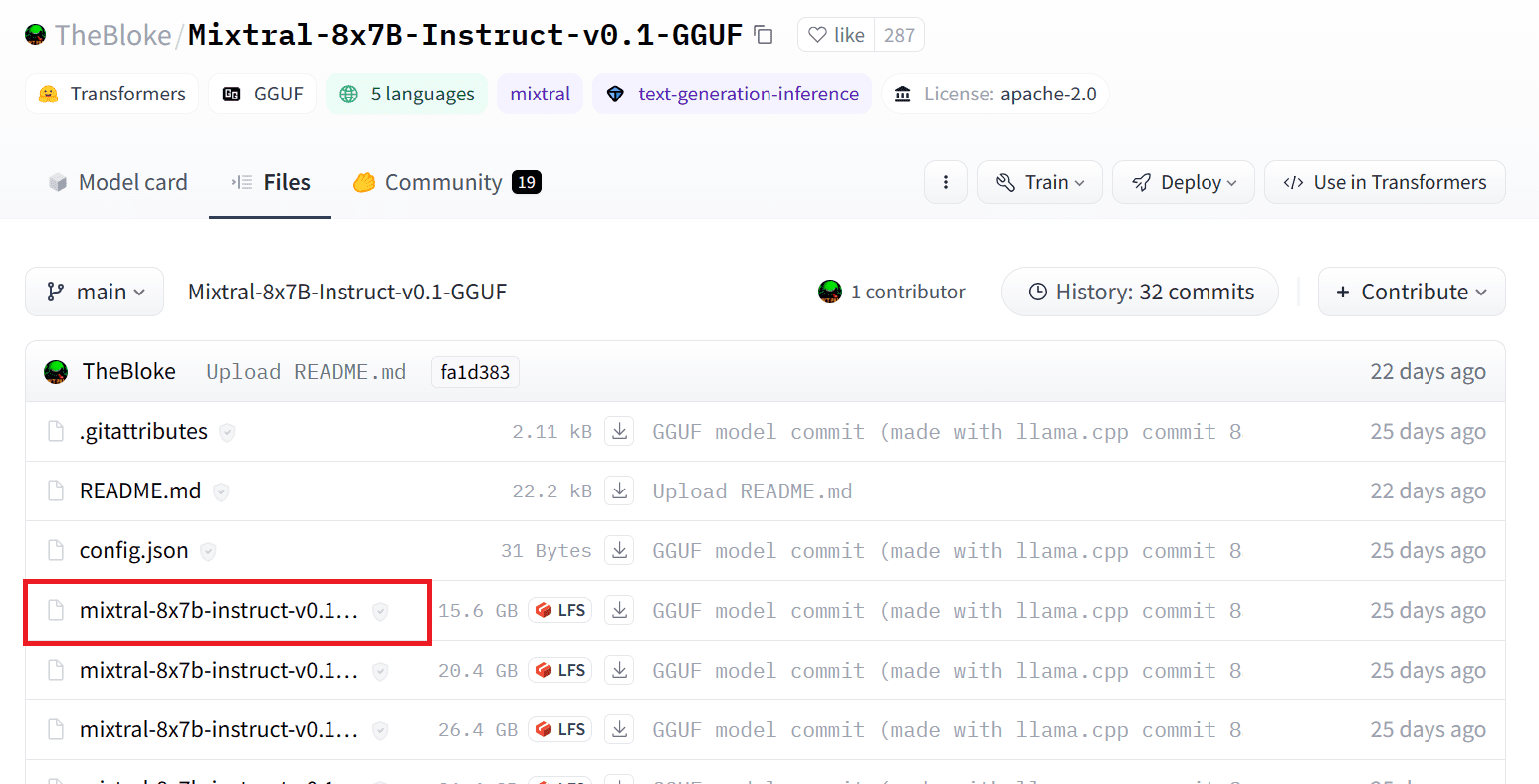
'.gguf' 모델 파일의 적절한 버전을 선택하여 Hugging Face Hub에서 모델을 다운로드할 수 있습니다. 다양한 버전에 대한 자세한 내용은 다음에서 확인할 수 있습니다. TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
이미지 출처 : TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
'wget' 명령을 사용하여 현재 디렉터리에 모델을 다운로드할 수 있습니다.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufLLaMA 서버의 외부 주소
LLaMA 서버를 실행하면 Colab에서는 쓸모가 없는 로컬 호스트 IP가 제공됩니다. Colab 커널 프록시 포트를 사용하여 localhost 프록시에 연결해야 합니다.
아래 코드를 실행하면 전역 하이퍼링크가 표시됩니다. 나중에 이 링크를 사용하여 웹앱에 액세스하겠습니다.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/서버 실행
LLaMA C++ 서버를 실행하려면 모델 파일의 위치와 올바른 포트 번호를 서버 명령에 제공해야 합니다. 포트 번호가 프록시 포트에 대해 이전 단계에서 시작한 번호와 일치하는지 확인하는 것이 중요합니다.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
서버가 로컬로 실행되지 않으므로 이전 단계에서 프록시 포트 하이퍼링크를 클릭하여 채팅 웹앱에 액세스할 수 있습니다.
LLaMA C++ 웹앱
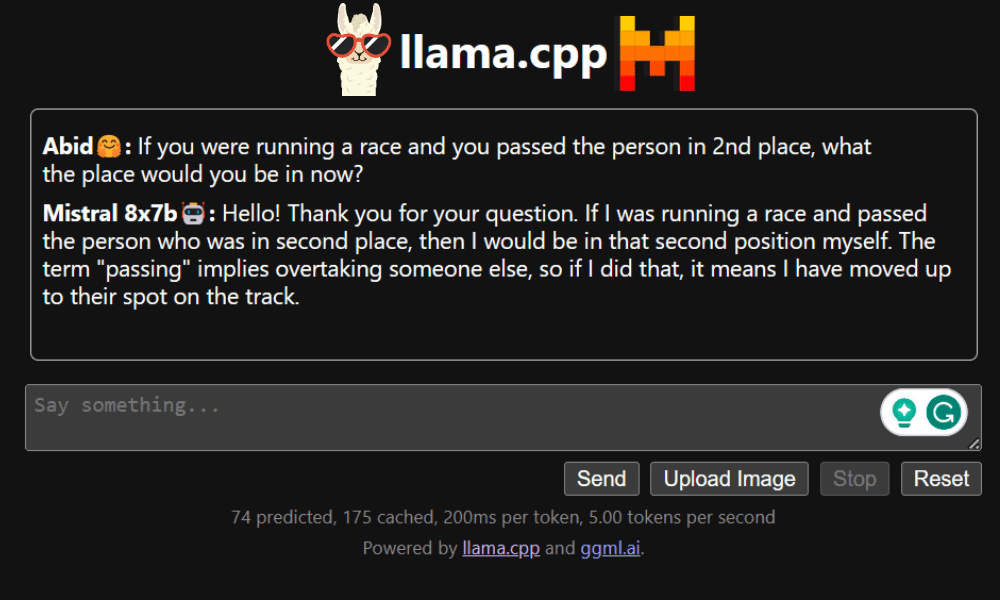
챗봇을 사용하기 전에 먼저 사용자 정의해야 합니다. 프롬프트 섹션에서 "LLaMA"를 모델 이름으로 바꾸십시오. 또한 생성된 응답을 구별하기 위해 사용자 이름과 봇 이름을 수정합니다.
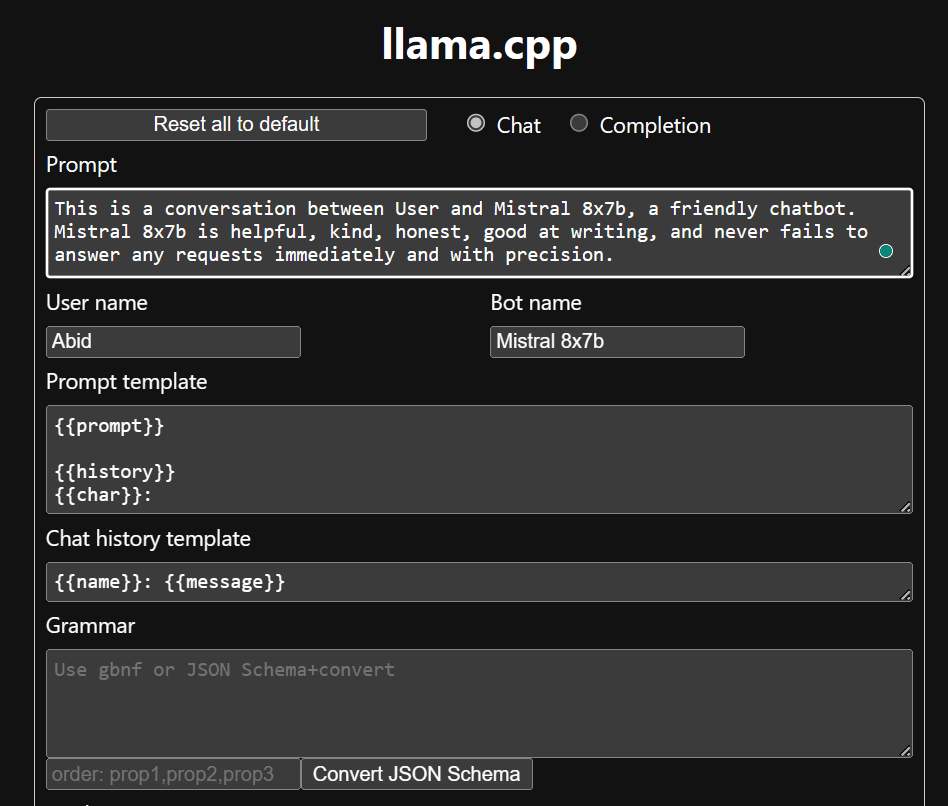
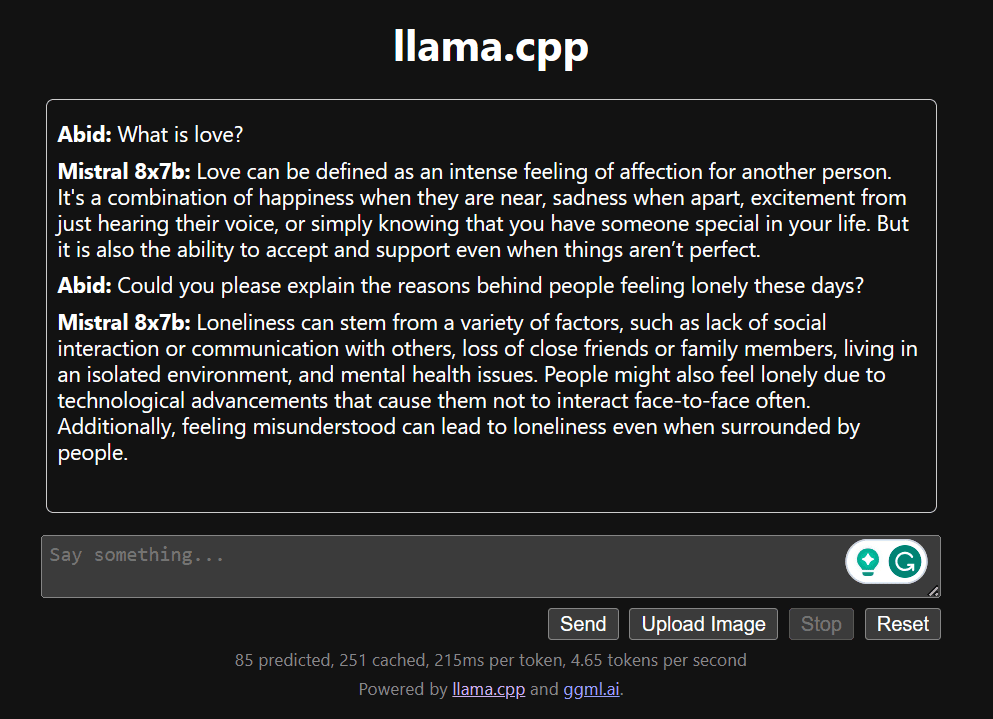
아래로 스크롤하고 채팅 섹션에 입력하여 채팅을 시작하세요. 다른 오픈소스 모델이 제대로 답변하지 못한 기술적인 질문을 자유롭게 질문해 보세요.
앱에 문제가 발생하면 내 Google Colab을 사용하여 직접 실행해볼 수 있습니다: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
이 튜토리얼은 LLaMA C++ 라이브러리를 사용하여 Google Colab에서 고급 오픈 소스 모델인 Mixtral 8x7b를 실행하는 방법에 대한 포괄적인 가이드를 제공합니다. 다른 모델과 비교하여 Mixtral 8x7b는 뛰어난 성능과 효율성을 제공하므로 대규모 언어 모델을 실험하고 싶지만 광범위한 계산 리소스가 없는 사람들에게 탁월한 솔루션입니다. 노트북이나 무료 클라우드 컴퓨팅에서 쉽게 실행할 수 있습니다. 사용자 친화적이며 다른 사람들이 사용하고 실험할 수 있도록 채팅 앱을 배포할 수도 있습니다.
대규모 모델을 실행하기 위한 이 간단한 솔루션이 도움이 되었기를 바랍니다. 나는 항상 간단하고 더 나은 옵션을 찾고 있습니다. 더 나은 해결책이 있다면 알려주세요. 다음에 다루도록 하겠습니다.
아비드 알리 아완 (@1abidaliawan)은 기계 학습 모델 구축을 좋아하는 공인 데이터 과학자 전문가입니다. 현재 그는 콘텐츠 제작에 집중하고 있으며 머신 러닝 및 데이터 과학 기술에 대한 기술 블로그를 작성하고 있습니다. Abid는 기술 관리 석사 학위와 통신 공학 학사 학위를 보유하고 있습니다. 그의 비전은 정신 질환으로 고생하는 학생들을 위해 그래프 신경망을 사용하여 AI 제품을 만드는 것입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :이다
- :아니
- 1
- 12
- 27
- 46
- 7
- 8
- a
- 할 수 있는
- ACCESS
- 액세스
- 달성
- 또한
- 주소
- 많은
- AI
- All
- 또한
- 항상
- am
- an
- 및
- 답변
- 아파치
- 앱
- 어플리케이션
- 적당한
- 아키텍처
- 있군요
- AS
- 문의
- 기반으로
- BE
- 시작하다
- 이하
- 벤치 마크
- BEST
- 더 나은
- 사이에
- 블록
- 블로그
- 봇
- 두
- 빌드
- 건물
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- C + +
- 라는
- CAN
- 인증
- 이전 단계로 돌아가기
- 잡담
- 채팅 봇
- 채팅
- 선택
- 클라우드
- 암호
- 결합
- 비교
- 호환
- 포괄적 인
- 계산
- 계산
- 컴퓨팅
- 연결
- 함유량
- 콘텐츠 제작
- 문맥
- 수정
- 비용
- 엄호
- 만든
- 창조
- Current
- 현재
- 사용자 정의
- 데이터
- 데이터 과학
- 데이터 과학자
- 도
- 제공
- 보여줍니다
- 배포
- 무례
- 드러내다
- do
- 아래 (down)
- 다운로드
- 마다
- 용이하게
- 효율성
- 효율적인
- 교전
- 엔지니어링
- 영어
- 강화
- 조차
- 우수한
- 경험
- 실험
- 전문가
- 탐험
- 광대 한
- 페이스메이크업
- 페이스북
- 실패한
- 매
- 빠른
- 세 연령의 아시안이
- 를
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 초점
- 럭셔리
- 발견
- 무료
- 프랑스어
- 에
- 기능
- 생성
- 세대
- 독일 사람
- 얻을
- GitHub의
- 주기
- 글로벌
- 구글
- GPU
- GPU
- 그래프
- 그래프 신경망
- 여러 떼
- 안내
- 처리
- 있다
- 데
- he
- 도움이
- 높은
- 고성능
- 높은 품질의
- 그의
- 보유
- 기대
- 방법
- How To
- HTTPS
- 허브
- i
- if
- 질병
- import
- 중대한
- in
- 포함
- 정보
- 시작
- 설치
- 설치
- 인터페이스
- 으로
- 포함
- IP
- 문제
- IT
- 이탈리아 사람
- 너 겟츠
- 알아
- 언어
- 언어
- 휴대용 퍼스널 컴퓨터
- 넓은
- 숨어 있음
- 후에
- 배우다
- 배우기
- 하자
- 도서관
- 라이센스
- 경량의
- 처럼
- 라인
- 라인
- LINK
- 링크드인
- 야마
- 장소 상에서
- 위치
- 찾고
- loves
- 기계
- 기계 학습
- 확인
- 유튜브 영상을 만드는 것은
- 구축
- 관리
- 석사
- 성냥
- me
- 메모리
- 정신
- 정신 질환
- 방법
- 혼합물
- 모델
- 모델
- 수정
- 배우기
- 가장
- 여러
- my
- name
- 필요
- 네트워크
- 신경
- 신경망
- 신제품
- 다음 것
- 번호
- 엔비디아
- of
- on
- ONE
- 열 수
- 오픈 소스
- 운영
- 운영체제
- 옵션
- or
- 기타
- 기타
- 우리의
- 초과 수익률
- 출력
- 출력
- 자신의
- 매개 변수
- 매개 변수
- PC
- 성능
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 부디
- 게시하다
- 너무 이른
- 프로덕트
- 링크를
- 정확히
- 제공
- 제공
- 대리
- 문제
- 문의
- 범위
- 감소
- 에 관한
- 교체
- 저장소
- 연구
- 제품 자료
- 응답
- 라우터
- 달리기
- 달리는
- s
- 과학
- 과학자
- 점수
- 스크롤
- 섹션
- 선택
- 섬기는 사람
- 단순, 간단, 편리
- 이후
- 해결책
- 출처
- 스페인어
- 표준
- 최첨단
- 단계
- 강한
- 고민
- 학생들
- 우수한
- 지원
- 확인
- 시스템은
- 작업
- 테크니컬
- 기술
- Technology
- 전기 통신
- 본문
- 텍스트 생성
- 그
- XNUMXD덴탈의
- 그들의
- Bowman의
- 이
- 그
- 시간
- 에
- 토큰
- 토큰
- 금액
- 번역
- 시도
- 지도 시간
- 두
- 아래에
- us
- 사용
- 익숙한
- 사용자
- 사용하기 쉬운
- 사용
- 사용
- 종류
- 여러
- 버전
- 시력
- 필요
- we
- 웹
- 웹 응용 프로그램
- 어느
- 동안
- 누구
- 넓은
- 넓은 범위
- 의지
- 과
- 쓰기
- 당신
- 너의
- 제퍼 넷




