アマゾンEMR 6.15発売 AWSレイクフォーメーション Apache Hudi、Apache Iceberg、Delta Lake などの Open Table Format (OTF) 上のきめ細かなアクセス制御 (FGAC) に基づいています。これにより、セキュリティとガバナンスを簡素化できます。 トランザクションデータレイク Apache Spark ジョブでテーブル、列、行レベルのアクセス許可を提供することによって。多くの大企業は、トランザクション データ レイクを使用して洞察を得て意思決定を改善しようとしています。 FGAC 用の Lake Formation と統合された Amazon EMR を使用して、レイクハウス アーキテクチャを構築できます。このサービスの組み合わせにより、安全で制御されたアクセスを確保しながら、トランザクション データ レイクでデータ分析を実行できます。
Amazon EMR レコード サーバー コンポーネントは、テーブル、列、行、セル、およびネストされた属性レベルのデータ フィルタリング機能をサポートしています。これにより、読み取り (タイム トラベルや増分クエリを含む) と書き込み操作 (INSERT などの DML ステートメント) の両方のサポートが Hive、Apache Hudi、Apache Iceberg、Delta Lake 形式に拡張されます。さらに、Amazon EMR のバージョン 6.15 では、クラスター上の Spark History Server、Yarn Timeline Server、Yarn Resource Manager UI などのアプリケーション Web インターフェイスにアクセス制御保護が導入されています。
この投稿では、FGAC を実装する方法を示します。 アパッチ・フディ Lake Formation と統合された Amazon EMR を使用したテーブル。
トランザクション データ レイクの使用例
Amazon EMR の顧客は、データレイクでの ACID トランザクションとタイムトラベルのニーズをサポートするためにオープン テーブル フォーマットを使用することがよくあります。データ レイクのタイム トラベルでは、履歴バージョンを保存することで、監査とコンプライアンス、データの回復とロールバック、再現可能な分析、さまざまな時点でのデータ探索などの利点が得られます。
トランザクション データ レイクのもう 1 つの一般的な使用例は、増分クエリです。増分クエリとは、最後のクエリ以降にデータ レイク内の新規または更新されたデータのみを処理および分析することに重点を置いたクエリ戦略を指します。インクリメンタル クエリの背後にある重要なアイデアは、メタデータまたは変更追跡メカニズムを使用して、最後のクエリ以降に新しいデータまたは変更されたデータを識別することです。これらの変更を特定することで、クエリ エンジンは関連データのみを処理するようにクエリを最適化し、処理時間とリソース要件を大幅に削減できます。
ソリューションの概要
この投稿では、Amazon EMR を使用して Apache Hudi テーブルに FGAC を実装する方法を示します。 アマゾン エラスティック コンピューティング クラウド (Amazon EC2) Lake Formation と統合されました。 Apache Hudi は、増分データ処理とデータ パイプラインの開発を大幅に簡素化するオープンソースのトランザクション データ レイク フレームワークです。この新しい FGAC 機能はすべての OTF をサポートします。ここで Hudi を使用してデモンストレーションすることに加えて、他のブログで他の OTF テーブルについてもフォローアップする予定です。を使用しております ノートPC in Amazon SageMakerスタジオ EMR クラスターを介したさまざまなユーザー アクセス権限を介して Hudi データの読み取りと書き込みを行う。これは、現実世界のデータ アクセス シナリオを反映しています。たとえば、エンジニアリング ユーザーがデータ プラットフォームでのトラブルシューティングを行うために完全なデータ アクセスが必要であるのに対し、データ アナリストは個人を特定できる情報 (PII) を含まないデータのサブセットにのみアクセスする必要がある場合などです。 )。 Lake Formation との統合 Amazon EMR ランタイムロール さらに、データセキュリティ体制を改善し、Amazon EMR ワークロードのデータ制御管理を簡素化できます。このソリューションは、データ アクセスのための安全で制御された環境を保証し、組織内のさまざまなユーザーや役割の多様なニーズとセキュリティ要件を満たします。
次の図は、ソリューションのアーキテクチャを示しています。
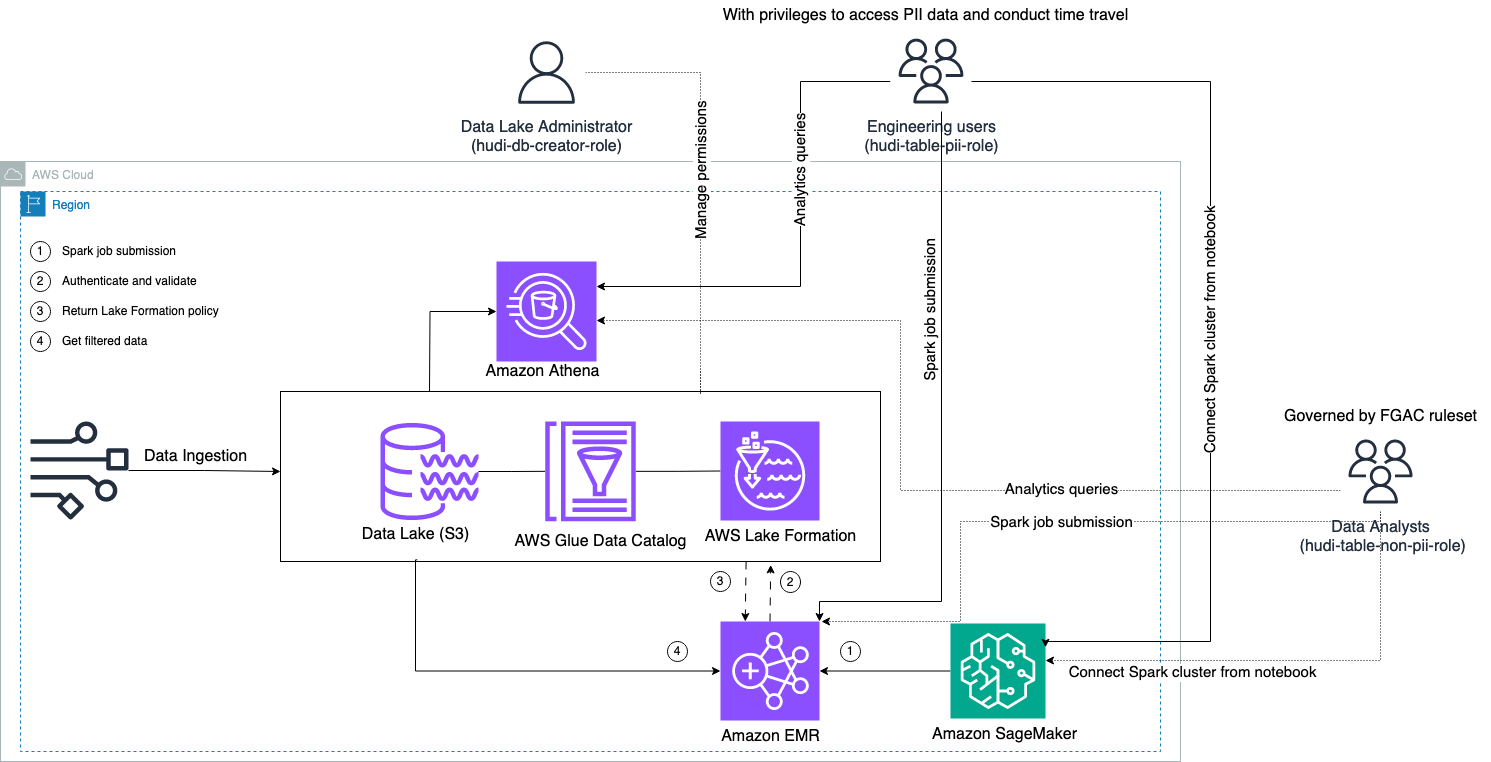
データ取り込みプロセスを実行して、Hudi データセットを更新/挿入 (更新および挿入) します。 Amazon シンプル ストレージ サービス (Amazon S3) バケットを作成し、テーブル スキーマを永続化または更新します。 AWSグルー データカタログ。データの移動がゼロなので、次のようなさまざまな AWS サービスを介して、Lake Formation によって管理される Hudi テーブルにクエリを実行できます。 アマゾンアテナ、Amazon EMR、および アマゾンセージメーカー.
ユーザーがいずれかの EMR クラスター エンドポイント (EMR Steps、Livy、EMR Studio、および SageMaker) を通じて Spark ジョブを送信すると、Lake Formation はユーザーの権限を検証し、PII データなどの機密データをフィルターで除外するように EMR クラスターに指示します。
このソリューションには、Hudi データにアクセスするための異なるレベルの権限を持つ 3 つの異なるタイプのユーザーが存在します。
- hudi-db-creator-role – これは、データベース オブジェクトの作成、変更、削除などの DDL 操作を実行する権限を持つデータ レイク管理者によって使用されます。 Lake Formation でデータ フィルタリング ルールを定義して、行レベルおよび列レベルのデータ アクセス制御を行うことができます。これらの FGAC ルールにより、データ レイクが保護され、必要なデータ プライバシー規制が満たされることが保証されます。
- hudi-テーブル-pii-役割 – これはエンジニアリング ユーザーによって使用されます。エンジニアリング ユーザーは、コピー オン ライト (CoW) とマージ オン リード (MoR) の両方でタイム トラベルおよび増分クエリを実行できます。また、タイムスタンプに基づいて PII データにアクセスする権限も持っています。
- hudi-table-non-pii-role – これはデータ アナリストによって使用されます。データ アナリストのデータ アクセス権は、データ レイク管理者が管理する FGAC 承認ルールによって管理されます。名前や住所などの PII データを含む列は表示されません。さらに、特定の条件を満たさないデータ行にはアクセスできません。たとえば、ユーザーは自分の国に属するデータ行のみにアクセスできます。
前提条件
この投稿で使用されている 3 つのノートブックは、次の場所からダウンロードできます。 GitHubレポ.
ソリューションを展開する前に、次のものが揃っていることを確認してください。
権限を設定するには、次の手順を実行します。
- 管理者 IAM ユーザーで AWS アカウントにログインします。
あなたがにいることを確認してくださいus-east-1領域。
- に S3 バケットを作成します。
us-east-1地域 (たとえば、emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
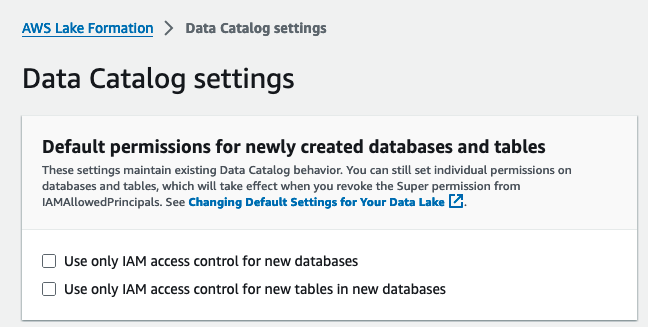
次に、Lake Formation を有効にします。 デフォルトの権限モデルの変更.
- Lake Formation コンソールに管理者ユーザーとしてサインインします。
- 選択する データカタログ設定 下 管理部門 ナビゲーションペインに表示されます。
- 新しく作成されたデータベースとテーブルのデフォルトの権限、選択を解除します 新しいデータベースにはIAMアクセス制御のみを使用する および 新しいデータベースの新しいテーブルには IAM アクセス制御のみを使用する.
- 選択する Save.
あるいは、Lake Formation をデフォルトのオプションで起動した場合に作成されたリソース (データベースとテーブル) の IAMAllowedPrincipals を取り消す必要があります。
最後に、Amazon EMR のキーペアを作成します。
- Amazon EC2コンソールで、 キーペア ナビゲーションペインに表示されます。
- 選択する キーペアを作成する.
- 名前 、名前を入力します (例:
emr-fgac-hudi-keypair). - 選択する キーペアを作成する.
生成されたキー ペア (この投稿では、 emr-fgac-hudi-keypair.pem) はローカル コンピュータに保存されます。
次に、 AWS クラウド9 インタラクティブな開発環境 (IDE)。
- AWS Cloud9 コンソールで、選択します 環境 ナビゲーションペインに表示されます。
- 選択する 環境を作る.
- 名前 ¸ 名前を入力します (たとえば、
emr-fgac-hudi-env). - 他の設定はデフォルトのままにしておきます。
- 選択する 創造する.
- IDE の準備ができたら、選択します Open それを開く。
- AWS Cloud9 IDE では、 File メニュー、選択 ローカルファイルをアップロードする.

- キーペアファイルをアップロードします(
emr-fgac-hudi-keypair.pem). - プラス記号を選択し、 新しいターミナル.
- ターミナルで、次のコマンド ラインを入力します。
コード例は、デモンストレーションのみを目的とした概念実証であることに注意してください。運用システムの場合は、信頼できる証明機関 (CA) を使用して証明書を発行します。参照する Amazon EMR 暗号化を使用して転送中のデータを暗号化するための証明書の提供 詳細については。
AWS CloudFormation 経由でソリューションをデプロイする
私たちは提供します AWS CloudFormation 次のサービスとコンポーネントを自動的にセットアップするテンプレート:
- データレイク用の S3 バケット。これには、サンプル TPC-DS データセットが含まれています。
- セキュリティ構成とパブリック DNS が有効になっている EMR クラスター。
- Lake Formation のきめ細かい権限を持つ EMR ランタイム IAM ロール:
- -hudi-db-creator-role – このロールは、Apache Hudi データベースとテーブルを作成するために使用されます。
- -hudi-table-pii-role – このロールは、PII を含む列を含む、Hudi テーブルのすべての列をクエリする権限を提供します。
- -hudi-table-non-pii-role – このロールは、Lake Formation によって PII 列をフィルタリングして除外された Hudi テーブルをクエリする権限を提供します。
- SageMaker Studio の実行ロールにより、ユーザーは対応する EMR ランタイム ロールを引き受けることができます。
- VPC、サブネット、セキュリティ グループなどのネットワーク リソース。
リソースをデプロイするには、次の手順を実行します。
- 選択する クイック作成スタック CloudFormation スタックを起動します。
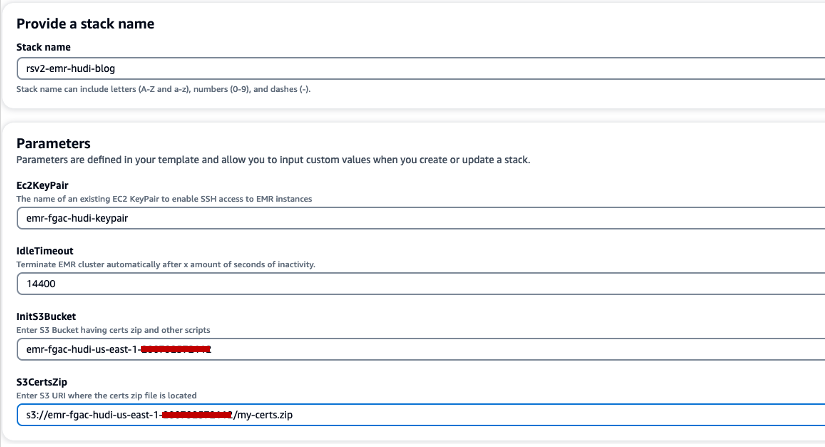
- スタック名、スタック名を入力します (例:
rsv2-emr-hudi-blog). - Ec2KeyPair、キーペアの名前を入力します。
- アイドルタイムアウト、EMR クラスターのアイドル タイムアウトを入力して、使用されていないクラスターに対する料金の支払いを回避します。
- InitS3バケット、Amazon EMR 暗号化証明書 .zip ファイルを保存するために作成した S3 バケット名を入力します。
- S3CertsZip、Amazon EMR 暗号化証明書 .zip ファイルの S3 URI を入力します。
- 選択 AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます.
- 選択する スタックを作成.
CloudFormation スタックのデプロイには約 10 分かかります。
Amazon EMR 統合用に Lake Formation をセットアップする
Lake Formation をセットアップするには、次の手順を実行します。
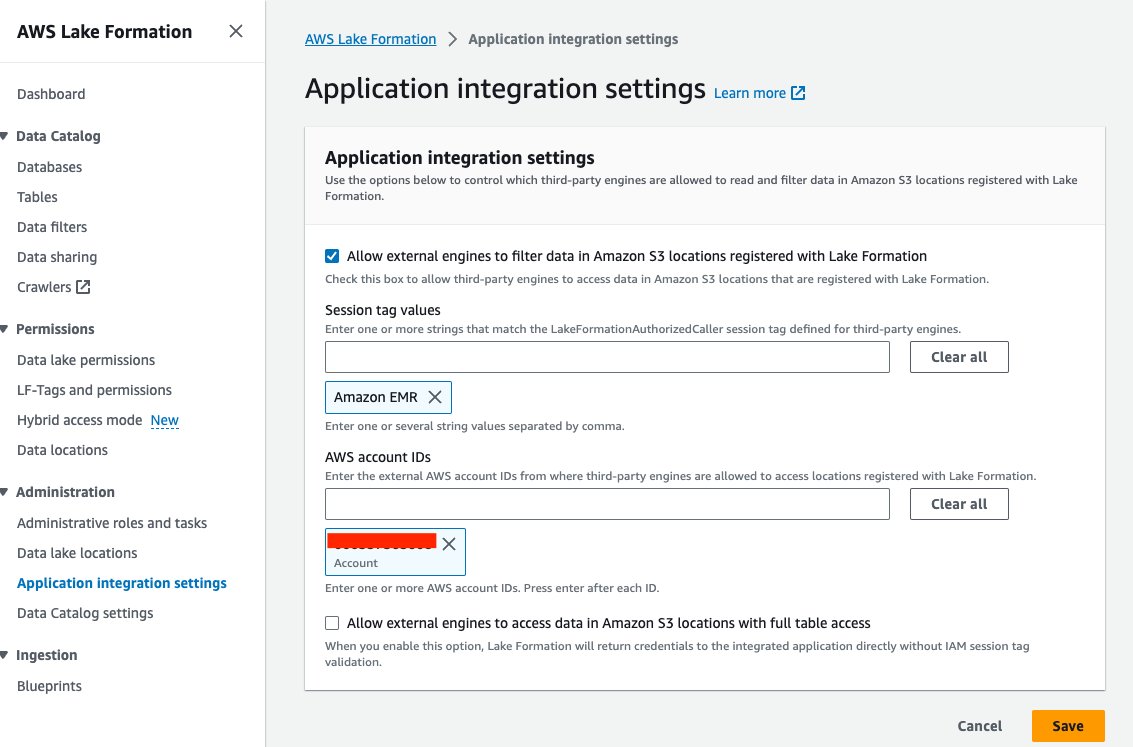
- Lake Formation コンソールで、 アプリケーション統合設定 下 管理部門 ナビゲーションペインに表示されます。
- 選択 外部エンジンが Lake Formation に登録された Amazon S3 ロケーションのデータをフィルタリングできるようにする.
- 選択する アマゾンEMR for セッションタグの値.
- AWS アカウント ID を入力してください AWS アカウント ID.
- 選択する Save.
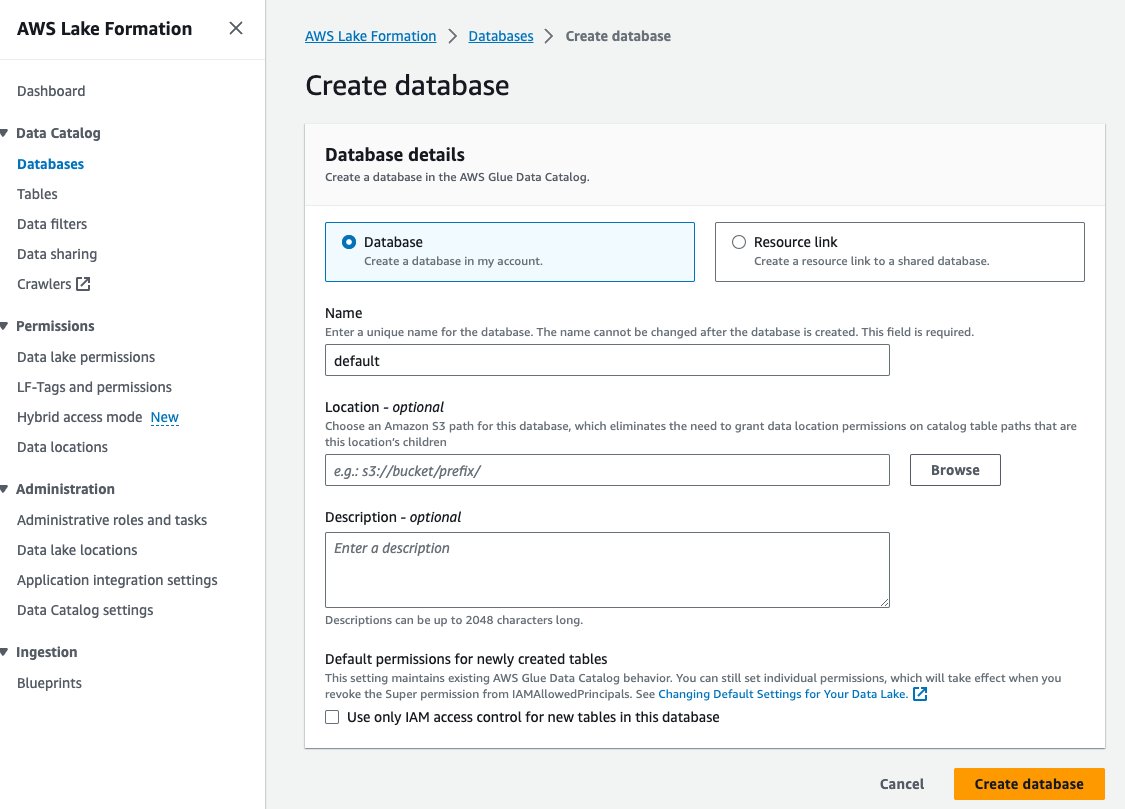
- 選択する データベース 下 データカタログ ナビゲーションペインに表示されます。
- 選択する データベースを作成する.
- 名前 、デフォルトを入力します。
- 選択する データベースを作成する.
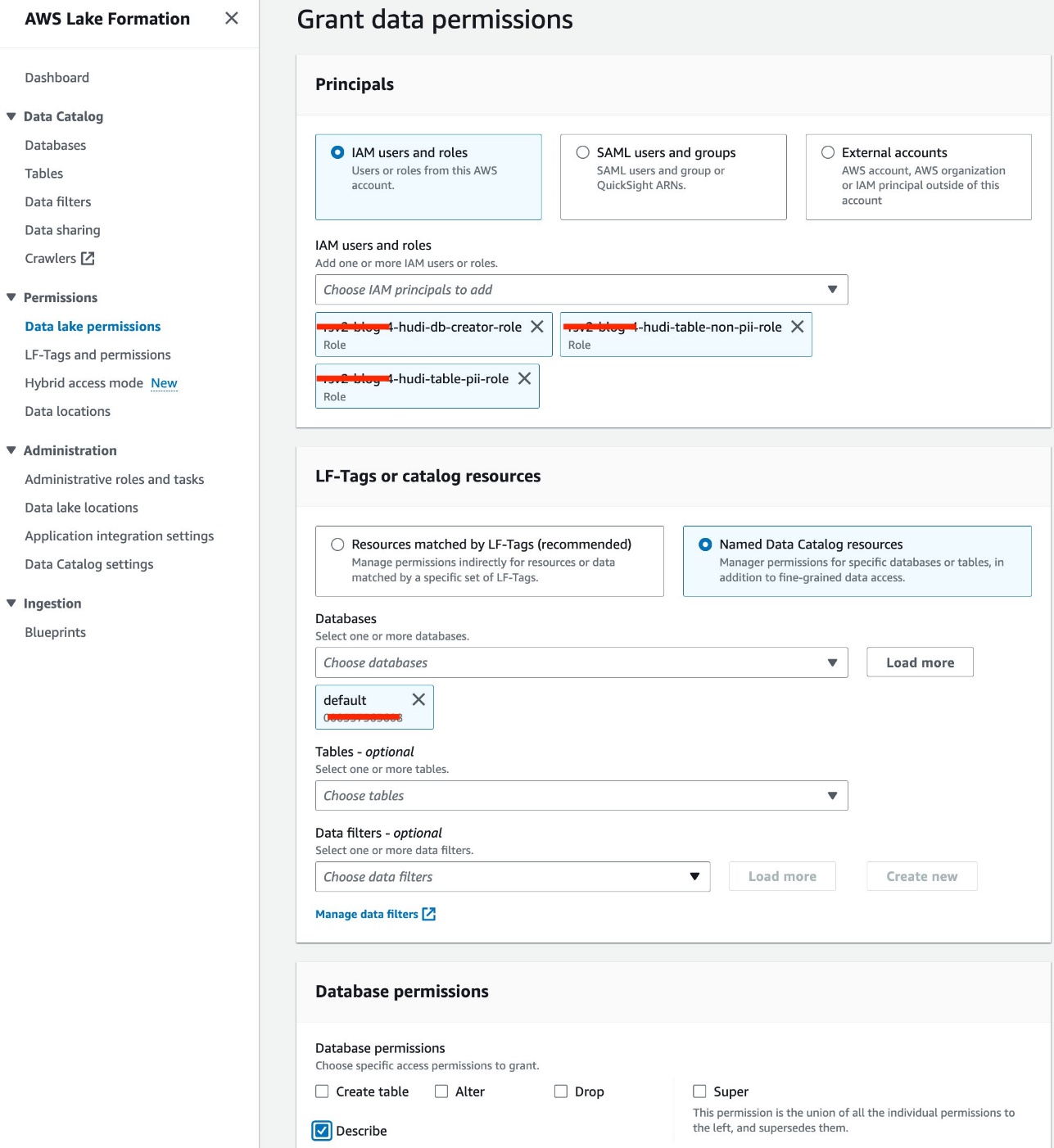
- 選択する データレイクの許可 下 権限 ナビゲーションペインに表示されます。
- 選択する グラント.
- 選択 IAMユーザーとロール.
- IAM ロールを選択します。
- データベース、デフォルトを選択します。
- データベースのアクセス許可選択 説明する.
- 選択する グラント.
Hudi JAR ファイルを Amazon EMR HDFS にコピーする
に Jupyter ノートブックで Hudi を使用するの場合は、Hudi を使用するように Spark セッションを設定できるように、Amazon EMR ローカル ディレクトリから HDFS ストレージに Hudi JAR ファイルをコピーすることを含む、EMR クラスターの次の手順を完了する必要があります。
- インバウンド SSH トラフィックを許可する (ポート22)。
- の値をコピーします プライマリノードのパブリックDNS (例: EMR クラスターからの ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) まとめ のセクションから無料でダウンロードできます。
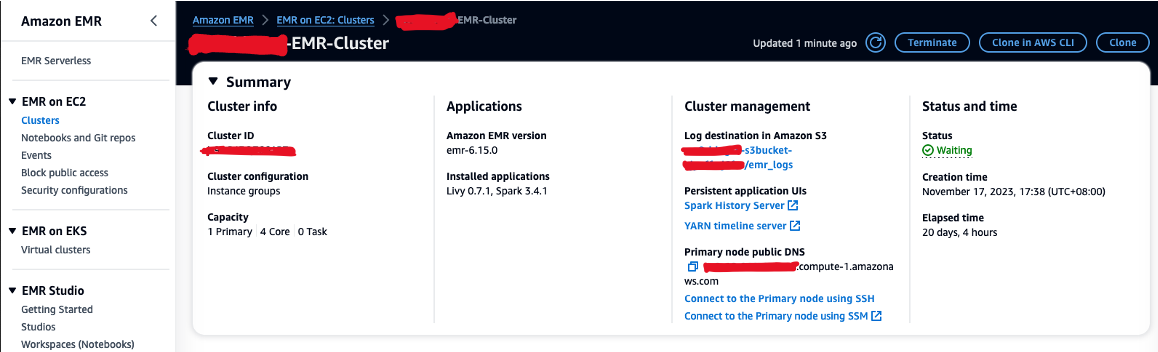
- EC9 キーペアの作成に使用した以前の AWS Cloud2 ターミナルに戻ります。
- 次のコマンドを実行して、EMR プライマリ ノードに SSH 接続します。プレースホルダーを EMR DNS ホスト名に置き換えます。
- 次のコマンドを実行して、Hudi JAR ファイルを HDFS にコピーします。
Lake Formation で Hudi データベースとテーブルを作成する
これで、EMR ランタイム ロールによって有効になった FGAC を使用して Hudi データベースとテーブルを作成する準備が整いました。の EMR ランタイムの役割 は、EMR クラスターにジョブまたはクエリを送信するときに指定できる IAM ロールです。
データベース作成者権限を付与する
まず、Lake Formation データベース作成者に次の権限を与えましょう。<STACK-NAME>-hudi-db-creator-role:
- AWS アカウントに管理者としてログインします。
- Lake Formation コンソールで、 管理者の役割とタスク 下 管理部門 ナビゲーションペインに表示されます。
- AWS ログイン ユーザーがデータ レイク管理者として追加されていることを確認します。
- データベース作成者 セクションでは、選択 グラント.
- IAMユーザーとロール、選択する
<STACK-NAME>-hudi-db-creator-role. - カタログの権限選択 データベースを作成する.
- 選択する グラント.
データレイクの場所を登録する
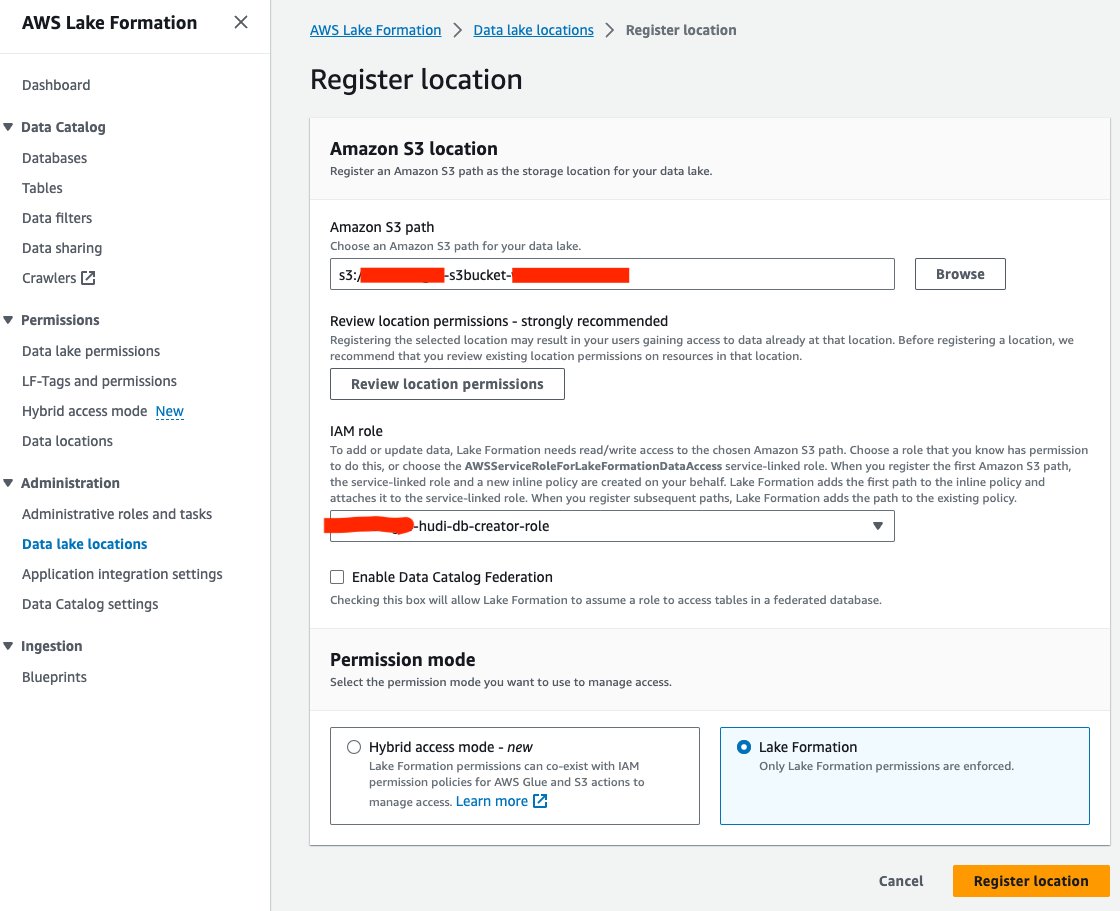
次に、S3 データ レイクの場所を Lake Formation に登録しましょう。
- Lake Formation コンソールで、 データレイクの場所 下 管理部門 ナビゲーションペインに表示されます。
- 選択する 登録場所.
- AmazonS3パスを選択 ブラウズ データ レイク S3 バケットを選択します。 (
<STACK_NAME>s3bucket-XXXXXXX) CloudFormation スタックから作成されました。 - IAMの役割、選択する
<STACK-NAME>-hudi-db-creator-role. - 許可モード選択 湖の形成.
- 選択する 登録場所.
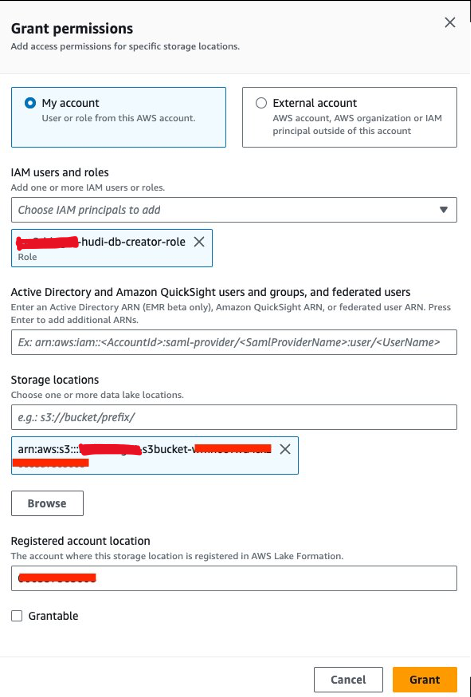
データの場所の権限を付与する
次に、許可する必要があります<STACK-NAME>-hudi-db-creator-roleデータの場所の許可:
- Lake Formation コンソールで、 データの場所 下 権限 ナビゲーションペインに表示されます。
- 選択する グラント.
- IAMユーザーとロール、選択する
<STACK-NAME>-hudi-db-creator-role. - 保管場所、S3 バケットを入力します (
<STACK_NAME>-s3bucket-XXXXXXX). - 選択する グラント.
EMR クラスターに接続する
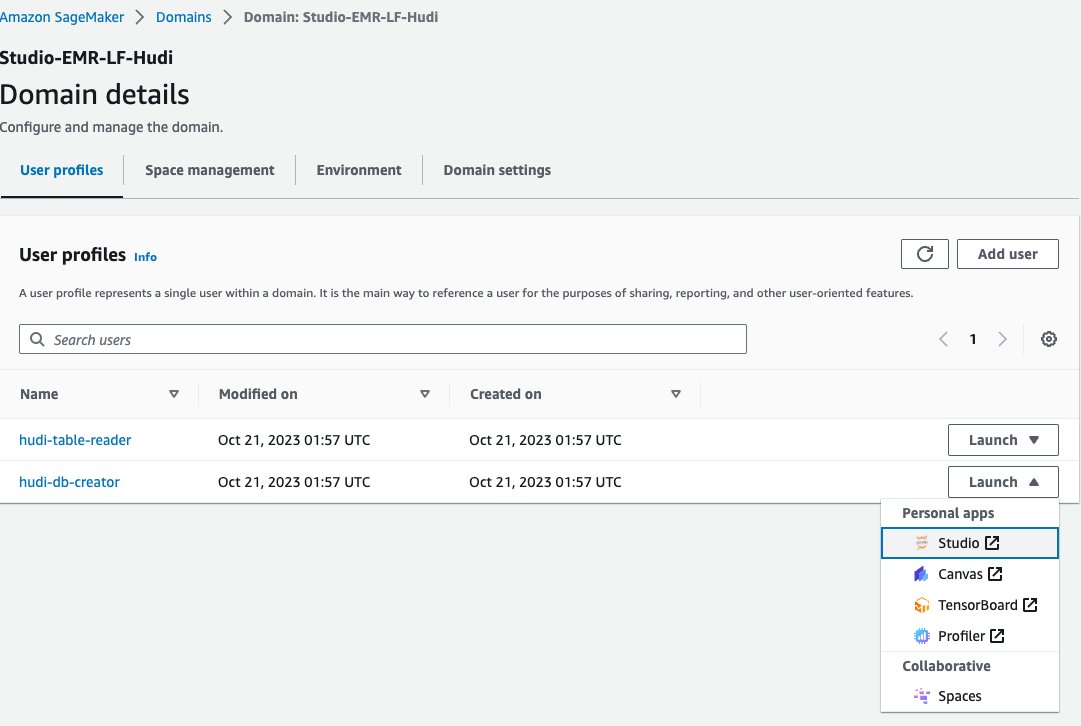
次に、SageMaker Studio で Jupyter ノートブックを使用して、データベース作成者の EMR ランタイム ロールで EMR クラスターに接続してみましょう。
- SageMakerコンソールで、 ドメイン ナビゲーションペインに表示されます。
- ドメインを選択してください
<STACK-NAME>-Studio-EMR-LF-Hudi. - ソフトウェア設定ページで、下図のように 起動する ユーザープロフィールの横にあるメニュー
<STACK-NAME>-hudi-db-creator、選択する Studio.
- ノートブックをダウンロードする rsv2-hudi-db-creator-notebook.
- アップロードアイコンを選択します。
- ダウンロードした Jupyter ノートブックを選択し、 Open.
- アップロードされたノートブックを開きます。
- 画像、選択する スパークマジック.
- カーネル、選択する パイスパーク.
- 他の設定はデフォルトのままにして、 選択.
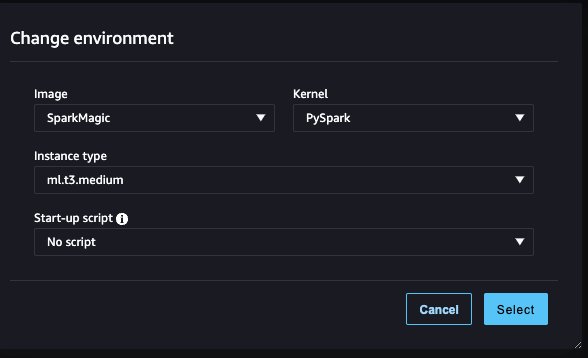
- 選択する クラスタ EMR クラスターに接続します。

- EC2 クラスター上の EMR を選択します (
<STACK-NAME>-EMR-Cluster) CloudFormation スタックで作成されました。 - 選択する お問合せ.
- EMR実行の役割、選択する
<STACK-NAME>-hudi-db-creator-role. - 選択する お問合せ.
データベースとテーブルを作成する
これで、ノートブックの手順に従って Hudi データベースとテーブルを作成できるようになります。主な手順は次のとおりです。
- ノートブックを起動するときに設定します
“spark.sql.catalog.spark_catalog.lf.managed":"true"これは、spark_catalog が Lake Formation によって保護されていることを Spark に通知します。 - 次の Spark SQL を使用して Hudi テーブルを作成します。
- ソーステーブルから Hudi テーブルにデータを挿入します。
- Hudi テーブルにデータを再度挿入します。
FGAC を使用して Lake Formation 経由で Hudi テーブルをクエリする
Hudi データベースとテーブルを作成したら、Lake Formation によるきめ細かいアクセス制御を使用してテーブルにクエリを実行できるようになります。 Copy-On-Write (COW) と Merge-On-Read (MOR) という 2 種類の Hudi テーブルを作成しました。 COW テーブルはデータを列指向形式 (Parquet) で保存し、更新ごとに書き込み中に新しいバージョンのファイルを作成します。これは、更新のたびに Hudi がファイル全体を書き換えることを意味します。これにより、リソースがより多く消費される可能性がありますが、読み取りパフォーマンスが向上します。一方、MOR は、COW が最適ではない場合、特に書き込みや変更が多いワークロードの場合に導入されます。 MOR テーブルでは、更新があるたびに、Hudi は変更されたレコードの行のみを書き込むため、コストが削減され、低遅延の書き込みが可能になります。ただし、読み取りパフォーマンスは COW テーブルに比べて遅くなる可能性があります。
テーブルへのアクセス権限を付与する
IAM ロールを使用します<STACK-NAME>-hudi-table-pii-rolePII 列を含む Hudi COW および MOR をクエリします。まず、Lake Formation 経由でテーブルへのアクセス許可を付与します。
- Lake Formation コンソールで、 データレイクの許可 下 権限 ナビゲーションペインに表示されます。
- 選択する グラント.
- 選択する
<STACK-NAME>-hudi-table-pii-rolefor IAMユーザーとロール. - 選択する
rsv2_blog_hudi_db_1のデータベース データベース. - テーブル類、Jupyter ノートブックで作成した 4 つの Hudi テーブルを選択します。
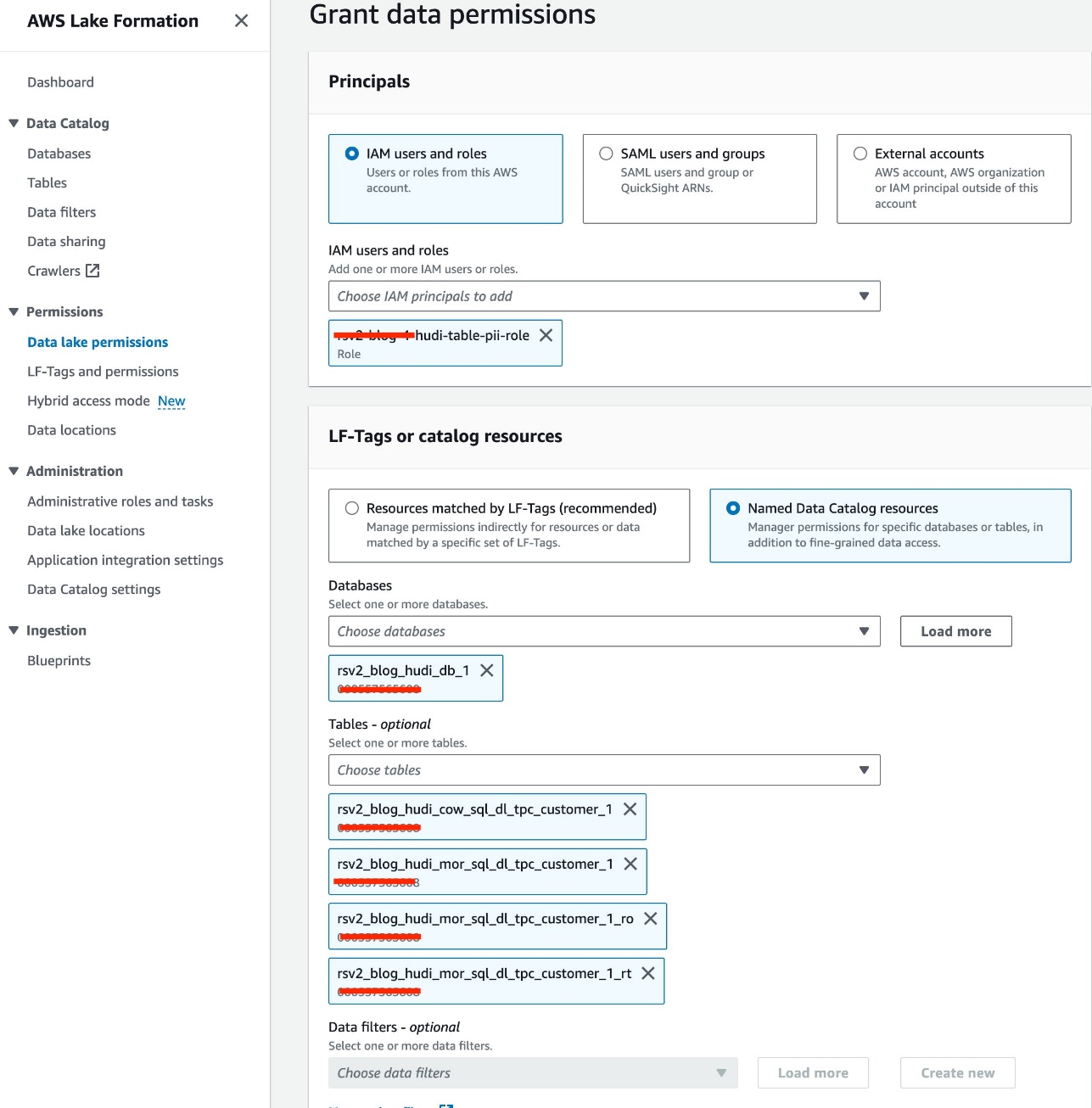
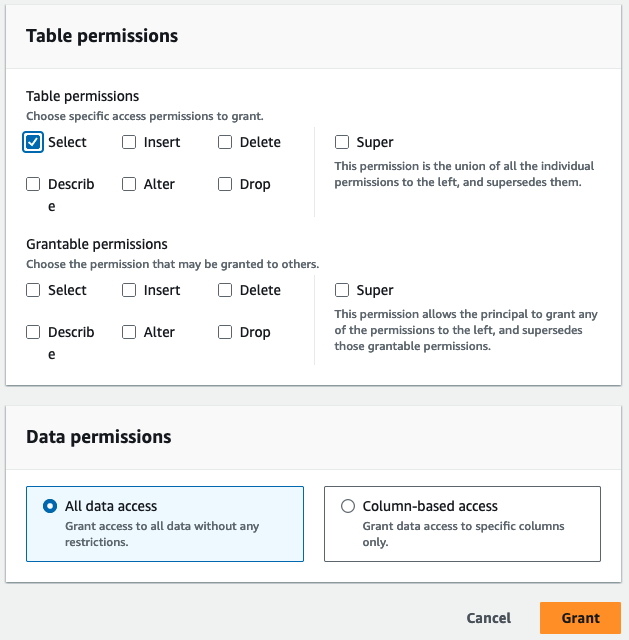
- テーブルのアクセス許可選択 選択.
- 選択する グラント.
PII 列のクエリ
これで、ノートブックを実行して Hudi テーブルをクエリする準備が整いました。前のセクションと同様の手順に従って、SageMaker Studio でノートブックを実行してみましょう。
- SageMakerコンソールで、に移動します
<STACK-NAME>-Studio-EMR-LF-Hudiドメイン。 - ソフトウェア設定ページで、下図のように 起動する 隣のメニュー
<STACK-NAME>-hudi-table-readerユーザープロファイル、選択 Studio. - ダウンロードしたノートブックをアップロードする rsv2-hudi-table-pii-reader-notebook.
- アップロードされたノートブックを開きます。
- ノートブックのセットアップ手順を繰り返して同じ EMR クラスターに接続しますが、ロールを使用します。
<STACK-NAME>-hudi-table-pii-role.
現在の段階では、FGAC 対応の EMR クラスターは、増分クエリとタイムトラベルを実行するために、Hudi のコミット時間列をクエリする必要があります。 Spark の「現在のタイムスタンプ」構文はサポートされていません。 Spark.read()。私たちは、FGAC を有効にした将来の Amazon EMR リリースに両方のアクションのサポートを組み込むことに積極的に取り組んでいます。
これで、ノートブックの手順に従うことができます。以下にいくつかの主要な手順を示します。
- スナップショット クエリを実行します。
- インクリメンタルクエリを実行します。
- タイムトラベルクエリを実行します。
- MOR 読み取りに最適化されたリアルタイム テーブル クエリを実行します。
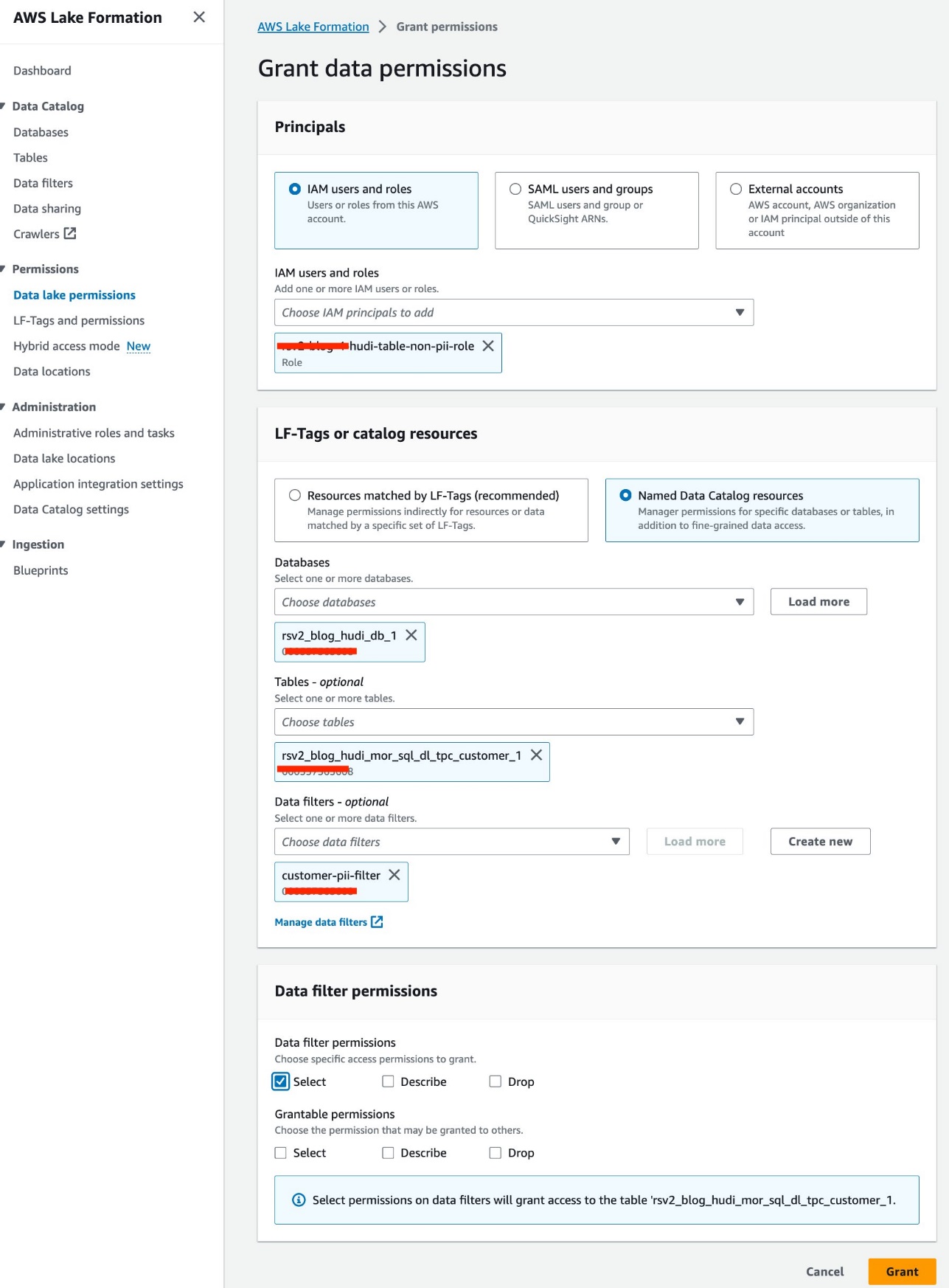
列レベルおよび行レベルのデータ フィルターを使用して Hudi テーブルにクエリを実行する
IAM ロールを使用します<STACK-NAME>-hudi-table-non-pii-roleHudi テーブルにクエリを実行します。このロールは、PII を含む列をクエリすることを許可されていません。 Lake Formation の列レベルと行レベルのデータ フィルターを使用して、きめ細かいアクセス制御を実装します。
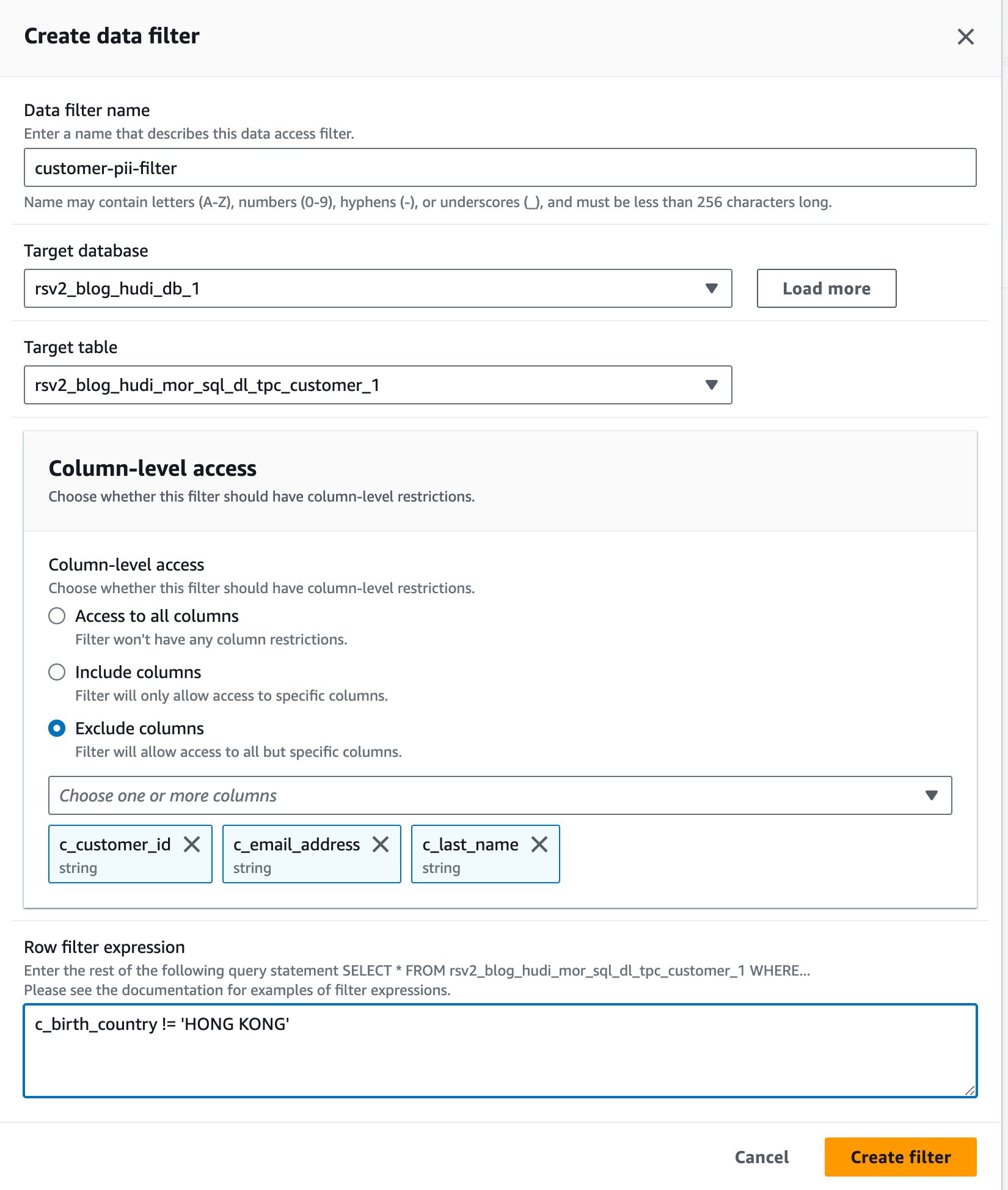
- Lake Formation コンソールで、 データフィルター 下 データカタログ ナビゲーションペインに表示されます。
- 選択する 新しいフィルターを作成する.
- データフィルター名、 入る
customer-pii-filter. - 選択する
rsv2_blog_hudi_db_1for 対象データベース. - 選択する
rsv2_blog_hudi_mor_sql_dl_customer_1for 対象表. - 選択 列を除外する を選択して
c_customer_id,c_email_address,c_last_name列。 - 入力します
c_birth_country != 'HONG KONG'for 行フィルター式. - 選択する フィルターを作成.
- 選択する データレイクの許可 下 権限 ナビゲーションペインに表示されます。
- 選択する グラント.
- 選択する
<STACK-NAME>-hudi-table-non-pii-rolefor IAMユーザーとロール. - 選択する
rsv2_blog_hudi_db_1for データベース. - 選択する
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1for テーブル類. - 選択する
customer-pii-filterfor データフィルター. - データ フィルターのアクセス許可選択 選択.
- 選択する グラント.
同様の手順に従って、SageMaker Studio でノートブックを実行してみましょう。
- SageMaker コンソールで、ドメインに移動します。
Studio-EMR-LF-Hudi. - ソフトウェア設定ページで、下図のように 起動する のメニュー
hudi-table-readerユーザープロファイル、選択 Studio. - ダウンロードしたノートブックをアップロードする rsv2-hudi-table-non-pii-reader-notebook 選択して Open.
- ノートブックのセットアップ手順を繰り返して同じ EMR クラスターに接続しますが、ロールを選択します
<STACK-NAME>-hudi-table-non-pii-role.
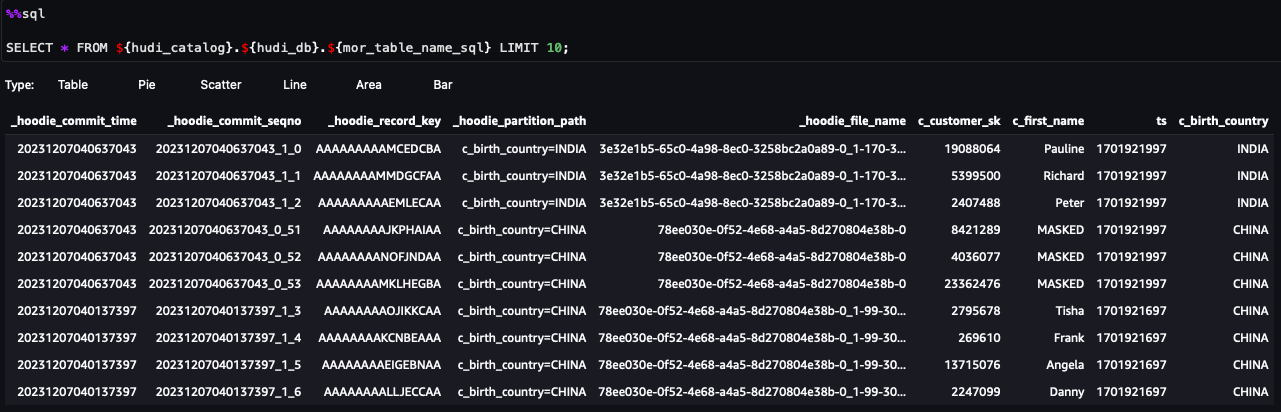
これで、ノートブックの手順に従うことができます。クエリ結果から、Lake Formation データ フィルターを介した FGAC が適用されていることがわかります。ロールは PII 列を参照できませんc_customer_id,c_last_name,c_email_address。また、からの行HONG KONGフィルタリングされています。
クリーンアップ
ソリューションの実験が完了したら、予期せぬコストが発生しないように、次の手順でリソースをクリーンアップすることをお勧めします。
- SageMaker Studio アプリをシャットダウンします。 ユーザープロファイルの場合。
EMR クラスターは、アイドル タイムアウト値の後に自動的に削除されます。
- 削除 AmazonElasticファイルシステム ドメイン用に作成された (Amazon EFS) ボリューム。
- S3バケットを空にします CloudFormation スタックによって作成されます。
- AWS CloudFormation コンソールでスタックを削除します。
まとめ
この投稿では、OTF テーブルの 1 つのタイプである Ahachi Hudi を使用して、Amazon EMR できめ細かいアクセス制御を強制するこの新機能を実証しました。 Lake Formation で OTF テーブルに対する詳細な権限を定義し、EMR クラスター上の Spark SQL クエリを介してそれらを適用できます。また、スナップショット クエリ、増分クエリ、タイム トラベル、DML クエリの実行などのトランザクション データ レイク機能を使用することもできます。この新機能はすべての OTF テーブルをカバーしていることに注意してください。
この機能は、Amazon EMR リリース 6.15 から開始されます。 地域 Amazon EMR が利用できる場所。 Amazon EMR と Lake Formation の統合により、ビッグデータを自信を持って管理および処理できるため、データのセキュリティとガバナンスを維持しながら洞察を引き出し、情報に基づいた意思決定を促進できます。
詳細については、を参照してください。 Amazon EMR で Lake Formation を有効にする AWS ソリューションアーキテクトにお気軽にお問い合わせください。データの取り組みとともにお手伝いいたします。
著者について
 レイモンドライ は、大企業顧客のニーズに応えることを専門とするシニア ソリューション アーキテクトです。彼の専門知識は、複雑なエンタープライズ システムとデータベースの AWS への移行、エンタープライズ データ ウェアハウジングとデータ レイク プラットフォームの構築における顧客の支援にあります。 Raymond は、AI/ML ユースケースのソリューションの特定と設計に優れており、特に AWS サーバーレス ソリューションとイベント駆動型アーキテクチャの設計に重点を置いています。
レイモンドライ は、大企業顧客のニーズに応えることを専門とするシニア ソリューション アーキテクトです。彼の専門知識は、複雑なエンタープライズ システムとデータベースの AWS への移行、エンタープライズ データ ウェアハウジングとデータ レイク プラットフォームの構築における顧客の支援にあります。 Raymond は、AI/ML ユースケースのソリューションの特定と設計に優れており、特に AWS サーバーレス ソリューションとイベント駆動型アーキテクチャの設計に重点を置いています。
 ビン・ワン博士号を持つ彼は、AWS のシニア分析スペシャリスト ソリューション アーキテクトであり、特に広告に重点を置いた ML 業界で 12 年以上の経験を誇ります。彼は、自然言語処理 (NLP)、レコメンダー システム、多様な ML アルゴリズム、および ML 操作に関する専門知識を持っています。彼は、現実世界の問題を解決するために ML/DL およびビッグ データ技術を適用することに深い情熱を持っています。
ビン・ワン博士号を持つ彼は、AWS のシニア分析スペシャリスト ソリューション アーキテクトであり、特に広告に重点を置いた ML 業界で 12 年以上の経験を誇ります。彼は、自然言語処理 (NLP)、レコメンダー システム、多様な ML アルゴリズム、および ML 操作に関する専門知識を持っています。彼は、現実世界の問題を解決するために ML/DL およびビッグ データ技術を適用することに深い情熱を持っています。
 アディティヤ・シャー AWS のソフトウェア開発エンジニアです。彼はデータベースとデータ ウェアハウス エンジンに興味があり、Apache Hive や Apache Spark などのエンジンのパフォーマンスの最適化、セキュリティ コンプライアンス、ACID コンプライアンスに取り組んできました。
アディティヤ・シャー AWS のソフトウェア開発エンジニアです。彼はデータベースとデータ ウェアハウス エンジンに興味があり、Apache Hive や Apache Spark などのエンジンのパフォーマンスの最適化、セキュリティ コンプライアンス、ACID コンプライアンスに取り組んできました。
 メロディーヤン AWSのAmazonEMRのシニアビッグデータソリューションアーキテクトです。 彼女は経験豊富な分析リーダーであり、AWSのお客様と協力して、データ変換の成功を支援するためのベストプラクティスのガイダンスと技術的なアドバイスを提供しています。 彼女の関心分野は、オープンソースのフレームワークと自動化、データエンジニアリング、DataOpsです。
メロディーヤン AWSのAmazonEMRのシニアビッグデータソリューションアーキテクトです。 彼女は経験豊富な分析リーダーであり、AWSのお客様と協力して、データ変換の成功を支援するためのベストプラクティスのガイダンスと技術的なアドバイスを提供しています。 彼女の関心分野は、オープンソースのフレームワークと自動化、データエンジニアリング、DataOpsです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 視聴者の38%が
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- 私たちについて
- アクセス
- 認める
- 行動
- 積極的に
- 追加されました
- さらに
- アドレス
- 管理人
- 管理者
- 広告運用
- アドバイス
- 後
- 再び
- AI / ML
- アルゴリズム
- すべて
- 許す
- 許可されて
- ことができます
- 並んで
- また
- Amazon
- Amazon EC2
- アマゾンEMR
- Amazon Webサービス
- an
- 分析
- アナリスト
- 分析的
- 分析論
- 分析する
- および
- どれか
- アパッチ
- Apache Spark
- 申し込み
- 適用された
- 申し込む
- 適用
- 建築家
- 建築
- です
- エリア
- 周りに
- AS
- アシスト
- 援助
- 支援する
- 引き受けます
- At
- 監査
- 権威
- 許可
- 自動的に
- オートメーション
- 利用できます
- 避ける
- AWS
- AWS クラウド9
- AWS CloudFormation
- AWSレイクフォーメーション
- バック
- ベース
- BE
- き
- 背後に
- さ
- 利点
- ほかに
- BEST
- ビッグ
- ビッグデータ
- ブログ
- 自慢
- 両言語で
- ビルド
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- CA
- 缶
- できる
- キャリー
- 携帯
- 場合
- 例
- カタログ
- ケータリング
- 一定
- 証明書
- 証明書
- 認証
- 変化する
- 変更
- 変更
- 中国
- 選択する
- クリーニング
- Cloud9
- クラスタ
- コード
- コラム
- コラム
- COM
- 組み合わせ
- コミット
- 企業
- 比べ
- コンプリート
- コンプライアンス
- コンポーネント
- コンポーネント
- 計算
- コンピュータ
- コンセプト
- 条件
- プロフェッショナルな方法で
- 自信を持って
- お問合せ
- 領事
- 構築
- 接触
- 含む
- 含まれています
- コントロール
- 制御
- controls
- 複写
- 対応する
- 費用
- コスト
- 国
- カバー
- 作ります
- 作成した
- 作成します。
- 作成
- クリエイター
- 電流プローブ
- カスタム
- Customers
- データ
- データアクセス
- データ分析
- データレイク
- データプライバシー
- データ処理
- データセキュリティ
- データウェアハウス
- データベース
- データベースを追加しました
- 意思決定
- 深く
- デフォルト
- 定義します
- デルタ
- 実証します
- デモ
- 展開します
- 展開
- 設計
- 設計
- 細部
- 開発
- 異なります
- 明確な
- 異なる
- DNS
- do
- ありません
- そうではありません
- ドメイン
- 行われ
- ドント
- ダウン
- ダウンロード
- ドリブン
- 間に
- 各
- ほかに
- enable
- 使用可能
- 可能
- 暗号化
- end
- エンドポイント
- 強制します
- エンジン
- エンジニア
- エンジニアリング
- エンジン
- 確保
- 確実に
- 確保する
- 入力します
- Enterprise
- 企業顧客
- 全体
- 環境
- エーテル(ETH)
- イベント
- あらゆる
- 例
- 実行
- 存在
- 体験
- 経験豊かな
- 専門知識
- 探査
- 拡張する
- 外部
- 容易化する
- 速いです
- 特徴
- 特徴
- 感じます
- File
- filter
- フィルタリング
- フィルター
- 名
- フォーカス
- 焦点を当てて
- フォロー中
- 次
- 形式でアーカイブしたプロジェクトを保存します.
- 形成
- 4
- フレームワーク
- フレームワーク
- 無料版
- から
- 満たす
- フル
- 機能性
- さらに
- 未来
- 利得
- 生成された
- ガバナンス
- 支配
- 助成金
- 大いに
- グループ
- グループの
- ガイダンス
- ハンド
- 持ってる
- he
- 彼女の
- こちら
- 強調表示された
- 彼の
- 歴史的
- history
- ハイブ
- ホン
- 香港
- お家の掃除
- 認定条件
- How To
- しかしながら
- HTML
- HTTP
- HTTPS
- IAM
- ICON
- ID
- アイデア
- 識別する
- 識別
- アイドル
- if
- 説明する
- 実装する
- 改善します
- in
- 含ま
- 含めて
- 組み込む
- インクリメンタル
- インド
- 産業を変えます
- 知らせます
- 情報
- 情報に基づく
- 洞察
- 統合された
- 統合
- 統合
- 相互作用的
- 興味がある
- 利益
- インタフェース
- 内部
- に
- 複雑な
- 導入
- 紹介します
- 問題
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- 旅
- JPG
- ジュピターノート
- キー
- 香港
- 湖
- 言語
- 大
- 姓
- 起動する
- 打ち上げ
- リーダー
- LEARN
- レベル
- ある
- ような
- LIMIT
- ライン
- ローカル
- 場所
- 場所
- ログイン
- 主要な
- make
- 管理します
- マネージド
- 管理
- マネージャー
- 多くの
- 五月..
- 手段
- メカニズム
- ご相談
- メニュー
- かもしれない
- 移行中
- 分
- ML
- MLアルゴリズム
- 修正されました
- 他には?
- 運動
- 名
- 名
- ナチュラル
- 自然言語
- 自然言語処理
- ナビゲート
- ナビゲーション
- 必要
- ニーズ
- 新作
- 新機能
- 新しく
- 次の
- NLP
- 注意
- ノート
- ノートPC
- 今
- オブジェクト
- of
- 頻繁に
- on
- ONE
- の
- 開いた
- オープンソース
- opensslの
- 業務執行統括
- 最適な
- 最適化
- オプション
- オプション
- or
- 注文
- 組織
- その他
- でる
- が
- ペア
- ペイン
- 特定の
- 特に
- 情熱的な
- 支払い
- パフォーマンス
- 実行
- 許可
- パーミッション
- 個人的に
- 博士号
- 敬虔な
- プレースホルダー
- プラットフォーム
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- さらに
- ポイント
- 人気
- 所持
- ポスト
- 練習
- 保存する
- 前
- 主要な
- プライバシー
- 特権
- 特権
- 問題
- プロセス
- 処理
- 生産
- プロフィール
- 対応プロファイル
- 証明
- 概念実証
- 保護された
- 保護
- 提供します
- は、大阪で
- 提供
- 公共
- 目的
- クエリ
- 読む
- リーディング
- 準備
- 現実の世界
- への
- 推奨する
- 記録
- 回復
- 軽減
- 縮小
- 参照する
- 指し
- 反映
- 地域
- 登録
- 登録された
- 規制
- リリース
- リリース
- 関連した
- replace
- の提出が必要です
- 要件
- リソースを追加する。
- リソースを大量に消費する
- リソース
- 結果
- 結果
- 権利
- 職種
- 役割
- 行
- RSA
- ルール
- ラン
- ランニング
- セージメーカー
- 同じ
- Save
- セクション
- 安全に
- セキュア
- セキュリティ
- Seek
- select
- シニア
- 敏感な
- サーバレス
- サービス
- セッション
- セッションに
- セット
- 設定
- 彼女
- 符号
- 著しく
- 同様の
- 簡単な拡張で
- 簡素化する
- 簡素化する
- から
- Snapshot
- So
- ソフトウェア
- ソフトウェア開発
- 溶液
- ソリューション
- 解決する
- 一部
- ソース
- スパーク
- 専門家
- 専門にする
- SQL
- スタック
- ステージ
- start
- 開始
- 起動
- 文
- ステップ
- ストレージ利用料
- 店舗
- 戦略
- 文字列
- 研究
- 提出する
- サブネット
- 成功
- そのような
- 概要
- サポート
- サポート
- 確か
- 構文
- システム
- テーブル
- TAG
- 取り
- 技術的
- テクニック
- template
- ターミナル
- それ
- ソース
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- この
- 三
- 介して
- 時間
- タイムトラベル
- タイムライン
- 〜へ
- 追跡
- トランザクション
- トランザクションの
- 変換
- トランジット
- 旅行
- true
- 信頼されている
- Ts
- 2
- type
- ui
- 下
- 予期しない
- 未知の
- ロック解除
- アップデイト
- 更新しました
- 支持
- アップロード
- URI
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 検証します
- 値
- さまざまな
- バージョン
- 、
- 視認性
- ボリューム
- 倉庫
- 倉庫保管
- we
- ウェブ
- Webサービス
- いつ
- 一方
- which
- while
- 誰
- 意志
- 以内
- 働いていました
- ワーキング
- 書きます
- 年
- 貴社
- あなたの
- ゼファーネット
- ゼロ
- 〒