大規模言語モデル (LLM) の人気が高まっており、新しい使用例が常に模索されています。一般に、プロンプト エンジニアリングをコードに組み込むことで、LLM を利用したアプリケーションを構築できます。ただし、既存の LLM のプロンプトでは不十分な場合があります。ここでモデルの微調整が役に立ちます。プロンプト エンジニアリングは入力プロンプトを作成することでモデルの出力をガイドすることですが、微調整はモデルを特定のタスクやドメインにより適したものにするためにカスタム データセットでトレーニングすることです。
モデルを微調整する前に、タスク固有のデータセットを見つける必要があります。一般的に使用されるデータセットの 1 つは、 共通のクロール データセット。 Common Crawl corpus には、2008 年以来定期的に収集されたペタバイト単位のデータが含まれており、生の Web ページ データ、メタデータ抽出、およびテキスト抽出が含まれています。どのデータセットを使用するかを決定することに加えて、微調整の特定のニーズに合わせてデータをクレンジングおよび処理する必要があります。
私たちは最近、最新の Common Crawl データセットのサブセットを前処理し、クリーンなデータを使用して LLM を微調整したいと考えているお客様と協力しました。お客様は、AWS で最もコスト効率の高い方法でこれを実現する方法を探していました。要件について話し合った後、次の使用をお勧めします。 Amazon EMR サーバーレス データ前処理のプラットフォームとして。 EMR サーバーレスは大規模なデータ処理に適しており、インフラストラクチャのメンテナンスの必要がありません。コストに関しては、各ジョブに使用されたリソースと期間に基づいてのみ課金されます。お客様は、EMR サーバーレスを使用して、1 週間以内に数百 TB のデータを前処理することができました。データを前処理した後、次を使用しました。 アマゾンセージメーカー LLM を微調整します。
この投稿では、お客様のユースケースと使用されるアーキテクチャについて説明します。
次のセクションでは、まず Common Crawl データセットと、必要なデータを探索してフィルタリングする方法を紹介します。 アマゾンアテナ スキャンしたデータ サイズに対してのみ料金が発生し、データの迅速な探索とフィルタリングに使用され、コスト効率が高くなります。 EMR サーバーレスは、Spark データ処理のためのコスト効率が高くメンテナンス不要のオプションを提供し、フィルターされたデータの処理に使用されます。次に使用するのは、 Amazon SageMaker ジャンプスタート を微調整する ラマ2モデル 前処理されたデータセットを使用します。 SageMaker JumpStart は、数回クリックするだけでデプロイできる、最も一般的なユースケース向けの一連のソリューションを提供します。 Llama 2 などの LLM を微調整するためのコードを記述する必要はありません。最後に、次を使用して微調整されたモデルをデプロイします。 アマゾンセージメーカー 元の Llama 2 モデルと微調整された Llama XNUMX モデルの間で、同じ質問に対するテキスト出力の違いを比較します。
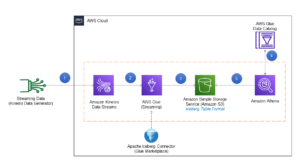
次の図は、このソリューションのアーキテクチャを示しています。
ソリューションの詳細を詳しく調べる前に、次の前提条件の手順を完了してください。
Common Crawl は、50 億を超える Web ページをクロールして取得されたオープン コーパス データセットです。これには、2008 年から始まりペタバイト レベルに達する、複数言語の大量の非構造化データが含まれています。継続的に更新されます。
次の図に示すように、GPT-3 のトレーニングでは、Common Crawl データセットがトレーニング データの 60% を占めます (出典: 言語モデルはほとんどショットの学習者ではありません).
言及する価値のあるもう 1 つの重要なデータセットは、 C4 データセット。 C4 は、Colossal Clean Crawled Corpus の略で、Common Crawl データセットの後処理から派生したデータセットです。 Meta の LLaMA 論文では、使用されたデータセットの概要が説明されており、Common Crawl が 67% (3.3 TB のデータを使用)、C4 が 15% (783 GB のデータを使用) を占めています。この論文では、モデルのパフォーマンスを向上させるために、さまざまに前処理されたデータを組み込むことの重要性を強調しています。元の C4 データは Common Crawl の一部であるにもかかわらず、Meta はこのデータの再処理バージョンを選択しました。
このセクションでは、共通クロール データセットを操作、フィルタリング、処理する一般的な方法について説明します。
Common Crawl の生データセットには、生の Web ページ データ (WARC)、メタデータ (WAT)、およびテキスト抽出 (WET) の 3 種類のデータ ファイルが含まれています。
2013 年以降に収集されたデータは WARC 形式で保存され、対応するメタデータ (WAT) とテキスト抽出データ (WET) が含まれます。データセットは Amazon S3 にあり、毎月更新され、次から直接アクセスできます。 AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzCommon Crawl データセットは、cc-index-table と呼ばれる、データをフィルター処理するためのインデックス テーブルも提供します。
cc-index-table は既存データのインデックスであり、WARC ファイルのテーブルベースのインデックスを提供します。これにより、どの WARC ファイルが特定の URL に対応するかなどの情報を簡単に検索できます。
たとえば、次のコードを使用して、cc-index データをマップする Athena テーブルを作成できます。
前述の SQL ステートメントは、Athena テーブルの作成、パーティションの追加、クエリの実行方法を示しています。
Common Crawl データセットからのデータのフィルター処理
create table SQL ステートメントからわかるように、データのフィルタリングに役立つフィールドがいくつかあります。たとえば、特定の期間中の中国語ドキュメントの数を取得したい場合、SQL ステートメントは次のようになります。
さらに処理を行いたい場合は、結果を別の S3 バケットに保存できます。
フィルタリングされたデータを分析する
共通クロール GitHub リポジトリ には、生データを処理するための PySpark の例がいくつか提供されています。
実行例を見てみましょう server_count.py (Common Crawl GitHub リポジトリによって提供されるサンプル スクリプト) s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
まず、EMR Spark などの Spark 環境が必要です。たとえば、EC2 クラスターで Amazon EMR を起動できます。 us-east-1 (データセットが us-east-1)。 EC2 クラスターで EMR を使用すると、本番環境にジョブを送信する前にテストを実行できます。
EC2 クラスターで EMR を起動した後、クラスターのプライマリ ノードに SSH ログインを行う必要があります。次に、Python 環境をパッケージ化してスクリプトを送信します (「 Conda のドキュメント Miniconda をインストールするには):
warc.path 内のすべての参照を処理するには時間がかかる場合があります。デモの目的では、次の戦略を使用して処理時間を改善できます。
- ファイルをダウンロードする
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzをローカル マシンに保存して解凍し、HDFS または Amazon S3 にアップロードします。これは、.gzip ファイルが分割できないためです。このファイルを並列処理するには、解凍する必要があります。 - 修正します
warc.pathファイルを削除し、その行のほとんどを削除し、ジョブの実行を大幅に高速化するために 2 行だけを残します。
ジョブが完了したら、結果を確認できます。 s3://xxxx-common-crawl/output/、寄木細工形式。
カスタマイズされた所有ロジックを実装する
Common Crawl GitHub リポジトリは、WARC ファイルを処理するための共通のアプローチを提供します。一般に、延長できるのは、 CCSparkJob 単一のメソッドをオーバーライドするには (process_record)、多くの場合、これで十分です。
最近の映画の IMDB レビューを取得する例を見てみましょう。まず、IMDB サイト上のファイルをフィルタリングして除外する必要があります。
その後、IMDB レビュー データを含む WARC ファイル リストを取得し、WARC ファイル名をリストとしてテキスト ファイルに保存できます。
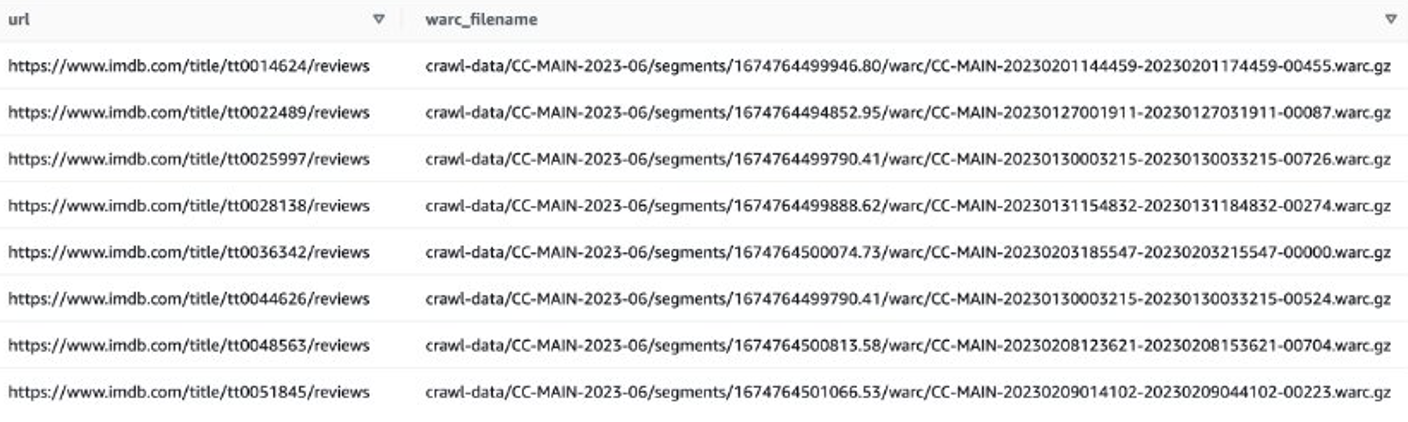
あるいは、EMR Spark を使用して WARC ファイルリストを取得し、Amazon S3 に保存することもできます。例えば:
出力ファイルは次のようになります。 s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
次のステップでは、これらの WARC ファイルからユーザー レビューを抽出します。延長することができます CCSparkJob をオーバーライドするには process_record() 方法:
前述のスクリプトを imdb_extractor.py として保存できます。これは次の手順で使用します。データとスクリプトを準備したら、EMR サーバーレスを使用してフィルタリングされたデータを処理できます。
EMR サーバーレス
EMR サーバーレスは、クラスターやサーバーの構成、管理、スケーリングを行わずに、Apache Spark や Hive などのオープンソース フレームワークを使用してビッグ データ分析アプリケーションを実行するサーバーレス展開オプションです。
EMR サーバーレスを使用すると、変化するデータ ボリュームや処理要件に合わせてリソースのサイズを数秒で変更する自動スケーリングを使用して、あらゆる規模の分析ワークロードを実行できます。 EMR サーバーレスは、アプリケーションに適切な量の容量を提供するためにリソースを自動的にスケールアップおよびスケールダウンします。料金は使用した分だけお支払いいただきます。
Common Crawl データセットの処理は通常 1 回限りの処理タスクであるため、EMR サーバーレス ワークロードに適しています。
EMR サーバーレス アプリケーションを作成する
EMR Studio コンソールで EMR サーバーレス アプリケーションを作成できます。次の手順を実行します。
- EMR Studio コンソールで、 アプリケーション 下 サーバレス ナビゲーションペインに表示されます。
- 選択する アプリケーションを作成する.

- アプリケーションの名前を入力し、Amazon EMR のバージョンを選択します。

- VPC リソースへのアクセスが必要な場合は、カスタマイズされたネットワーク設定を追加します。

- 選択する アプリケーションを作成する.
これで、Spark サーバーレス環境の準備が整います。
ジョブを EMR Spark サーバーレスに送信する前に、実行ロールを作成する必要があります。参照する Amazon EMR サーバーレスの使用開始 のガイドをご参照ください。
EMR サーバーレスを使用して共通のクロール データを処理する
EMR Spark サーバーレス アプリケーションの準備ができたら、次の手順を実行してデータを処理します。
- Conda 環境を準備し、Amazon S3 にアップロードします。これは、EMR Spark サーバーレスの環境として使用されます。
- 実行するスクリプトを S3 バケットにアップロードします。次の例には、XNUMX つのスクリプトがあります。
- imbd_extractor.py – データセットからコンテンツを抽出するためのカスタマイズされたロジック。内容はこの投稿の前半でご覧いただけます。
- cc-pyspark/sparkcc.py – からの PySpark フレームワークの例 共通クロール GitHub リポジトリを含める必要があります。
- PySpark ジョブを EMR Serverless Spark に送信します。この例を環境で実行するには、次のパラメータを定義します。
- アプリケーションID – EMR サーバーレス アプリケーションのアプリケーション ID。
- 実行ロールアーン – EMR サーバーレス実行ロール。作成するには、を参照してください。 ジョブランタイムロールを作成する.
- WARCファイルの場所 – WARC ファイルの場所。
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtには、この記事の前半で取得したフィルター処理された WARC ファイル リストが含まれています。 - スパーク.sql.warehouse.dir – デフォルトの倉庫の場所 (S3 ディレクトリを使用)。
- スパーク.アーカイブ – 準備された Conda 環境の S3 の場所。
- スパーク.submit.pyFiles – 準備された PySpark スクリプト sparkcc.py。
次のコードを参照してください。
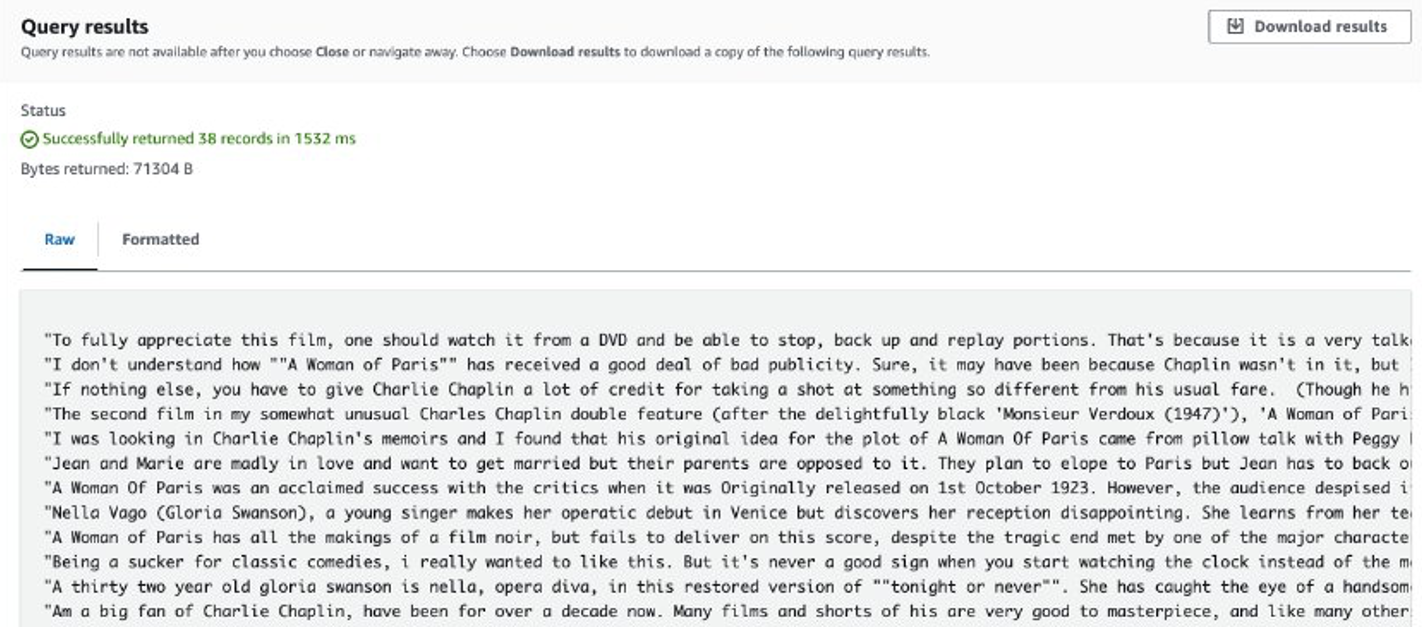
ジョブが完了すると、抽出されたレビューが Amazon S3 に保存されます。内容を確認するには、次のスクリーンショットに示すように、Amazon S3 Select を使用できます。
考慮事項
カスタマイズされたコードで大量のデータを処理する場合に考慮すべき点は次のとおりです。
- 一部のサードパーティの Python ライブラリは Conda では使用できない場合があります。このような場合は、Python 仮想環境に切り替えて PySpark ランタイム環境を構築できます。
- 処理するデータが大量にある場合は、複数の EMR サーバーレス Spark アプリケーションを作成して使用し、並列化してみてください。各アプリケーションはファイル リストのサブセットを処理します。
- Common Crawl データをフィルタリングまたは処理するときに、Amazon S3 で速度低下の問題が発生する可能性があります。これは、データを保存している S3 バケットがパブリックにアクセス可能であり、他のユーザーが同時にデータにアクセスする可能性があるためです。この問題を軽減するには、再試行メカニズムを追加するか、Common Crawl S3 バケットから独自のバケットに特定のデータを同期します。
SageMaker を使用して Llama 2 を微調整する
データを準備したら、それを使用して Llama 2 モデルを微調整できます。これは、コードを書かずに SageMaker JumpStart を使用して行うことができます。詳細については、以下を参照してください。 Amazon SageMaker JumpStart でのテキスト生成用に Llama 2 を微調整する.
このシナリオでは、ドメイン適応の微調整を実行します。このデータセットでは、入力は CSV、JSON、または TXT ファイルで構成されます。すべてのレビュー データを TXT ファイルに入れる必要があります。これを行うには、単純な Spark ジョブを EMR Spark Serverless に送信します。次のサンプル コード スニペットを参照してください。
トレーニング データを準備したら、データの場所を入力します。 トレーニングデータセット、を選択します トレーニング.
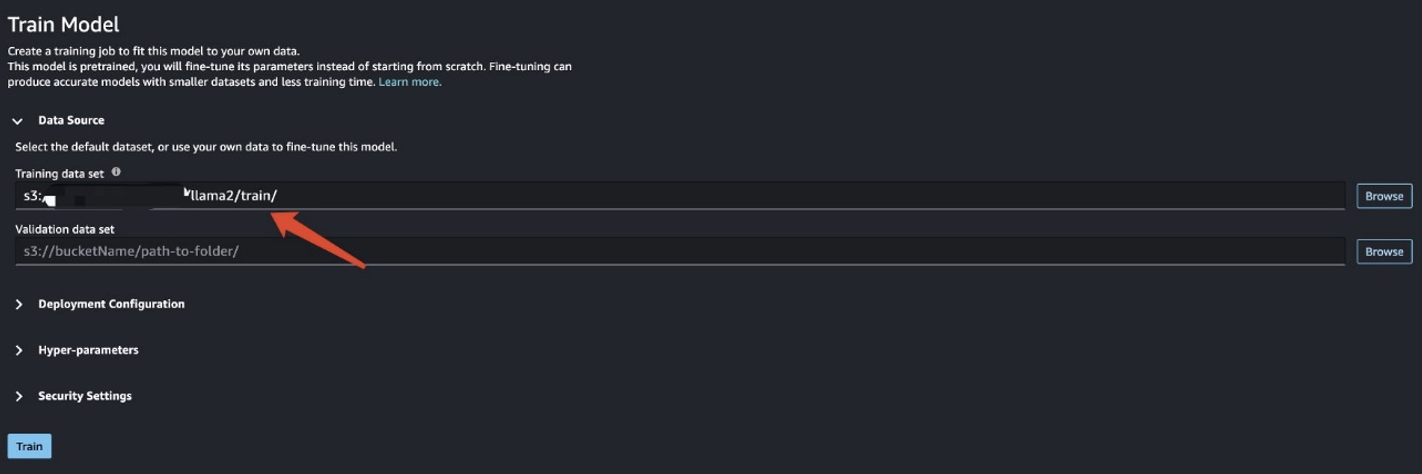
トレーニング ジョブのステータスを追跡できます。
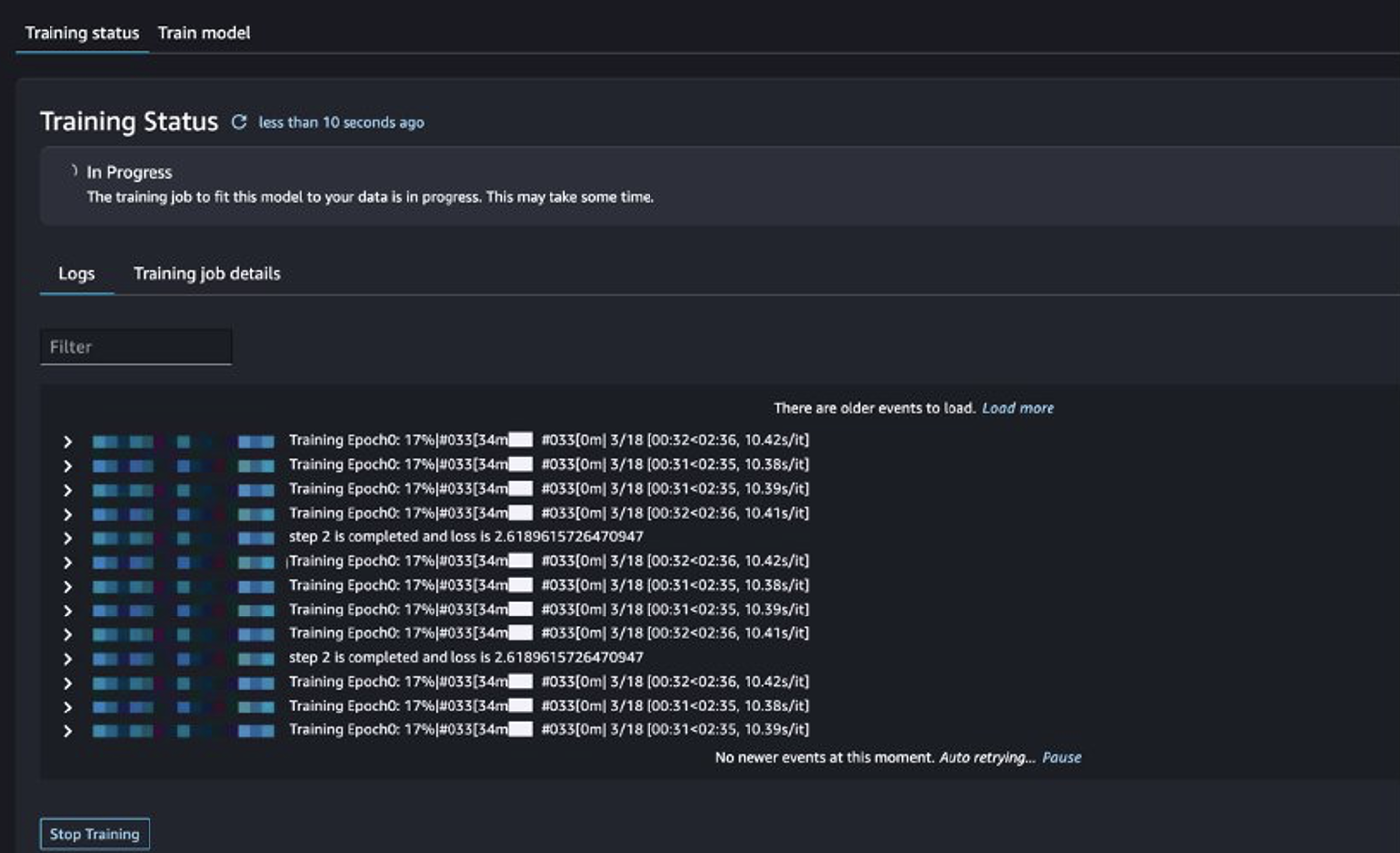
微調整されたモデルを評価する
トレーニングが完了したら、選択します 配備します SageMaker JumpStart で微調整されたモデルをデプロイします。

モデルが正常にデプロイされたら、次を選択します。 ノートブックを開くをクリックすると、Python コードを実行できる準備された Jupyter ノートブックにリダイレクトされます。

ノートブックにはイメージ Data Science 2.0 と Python 3 カーネルを使用できます。
その後、このノートブックで微調整されたモデルと元のモデルを評価できます。
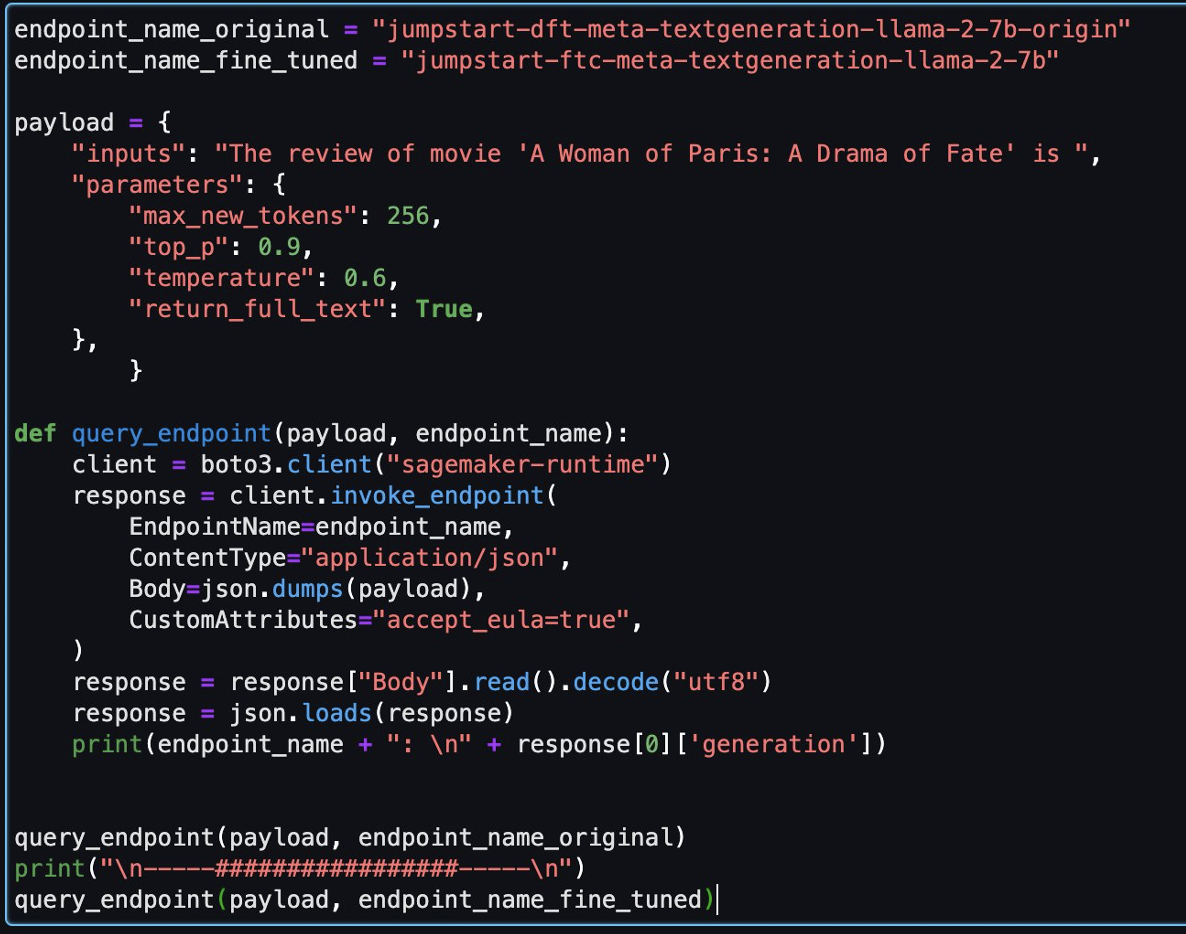
以下は、同じ質問に対して元のモデルと微調整されたモデルによって返された 2 つの応答です。

両方のモデルに「映画『パリの女:運命のドラマ』のレビューは」という同じ文を与え、文を完成させました。
元のモデルは意味のない文を出力します。
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
対照的に、微調整されたモデルの出力は映画のレビューに似ています。
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
明らかに、この特定のシナリオでは、微調整されたモデルのパフォーマンスが向上します。
クリーンアップ
この演習を終了したら、次の手順を実行してリソースをクリーンアップします。
- S3 バケットを削除する クリーンアップされたデータセットを保存します。
- EMRサーバーレス環境を停止する.
- SageMaker エンドポイントを削除する LLM モデルをホストします。
- SageMaker ドメインを削除する それがあなたのノートブックを実行します。
作成したアプリケーションは、デフォルトで 15 分間非アクティブ状態が続くと自動的に停止します。
通常、Athena 環境を使用していないときは料金が発生しないため、Athena 環境をクリーンアップする必要はありません。
まとめ
この投稿では、Common Crawl データセットと、EMR サーバーレスを使用して LLM 微調整用のデータを処理する方法を紹介しました。次に、SageMaker JumpStart を使用して LLM を微調整し、コードなしでデプロイする方法をデモしました。 EMR サーバーレスのその他の使用例については、以下を参照してください。 Amazon EMR サーバーレス。 Amazon SageMaker JumpStart でのモデルのホスティングと微調整の詳細については、以下を参照してください。 Sagemaker JumpStart ドキュメント.
著者について
 唐世建 アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。
唐世建 アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。
 マシュー・リーム アマゾン ウェブ サービスのシニア ソリューション アーキテクチャ マネージャーです。
マシュー・リーム アマゾン ウェブ サービスのシニア ソリューション アーキテクチャ マネージャーです。
 ダレイ・シュウ アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。
ダレイ・シュウ アマゾン ウェブ サービスの分析スペシャリスト ソリューション アーキテクトです。
 シャオ・ユアンジュン アマゾン ウェブ サービスのシニア ソリューション アーキテクトです。
シャオ・ユアンジュン アマゾン ウェブ サービスのシニア ソリューション アーキテクトです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :は
- :not
- :どこ
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 視聴者の38%が
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- できる
- 私たちについて
- アクセス
- アクセス
- アクセス可能な
- 会計
- アカウント
- 達成する
- 活性化する
- 加えます
- 添加
- アフリカ
- 後
- すべて
- ことができます
- また
- 驚くべき
- Amazon
- アマゾンEMR
- アマゾンセージメーカー
- Amazon SageMaker ジャンプスタート
- Amazon Webサービス
- 量
- 金額
- an
- 分析論
- および
- 別の
- どれか
- アパッチ
- Apache Spark
- 申し込み
- アプローチ
- 建築
- です
- AS
- At
- オーストラリア人
- オートマチック
- 自動的に
- 利用できます
- AWS
- 背景
- ベース
- 基礎
- BE
- 美しい
- なぜなら
- になる
- 始まる
- さ
- より良いです
- の間に
- ビッグ
- ビッグデータ
- 10億
- ボディ
- 両言語で
- ビルド
- by
- 呼ばれます
- 缶
- 取得することができます
- 容量
- キャリー
- 場合
- 例
- 変化
- 文字
- 課金
- チェック
- 中国語
- 選択する
- class
- クライアント
- クラスタ
- コード
- COM
- コマンドと
- 一般に
- 比較します
- コンプリート
- 構成する
- 検討
- からなる
- 領事
- 絶えず
- 含む
- 含まれています
- 中身
- 連続的に
- コントラスト
- 対応する
- 対応する
- 費用
- コスト効率の良い
- 可能性
- カウント
- カバー
- 作ります
- 作成した
- カスタム
- 顧客
- カスタマイズ
- データ
- データ分析
- データ処理
- データサイエンス
- データセット
- デイビス
- 取引
- 特価
- 深いです
- デフォルト
- 定義します
- デモ
- 実証します
- 実証
- 展開します
- 展開
- 展開
- 派生
- にもかかわらず
- 細部
- 決定
- ダイアグラム
- の違い
- 異なって
- 指示された
- 直接に
- 議論
- ダイビング
- do
- ドキュメント
- ドメイン
- ドメイン
- ドナルド
- ドント
- ダウン
- ドラマ
- ドライバー
- デュレーション
- 間に
- 各
- 前
- 簡単に
- 排除
- 強調
- 出会い
- エンジニアリング
- 強化
- 入力します
- 環境
- エーテル(ETH)
- 評価する
- 例
- 例
- 実行
- 運動
- 既存の
- 存在
- 探る
- 調査済み
- 伸ばす
- 外部
- エキス
- 抽出
- 抽出物
- フォールズ
- false
- 速いです
- 運命
- 特集
- 少数の
- フィールズ
- File
- filter
- フィルタリング
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 仕上げ
- 名
- フォロー中
- 次
- 形式でアーカイブしたプロジェクトを保存します.
- 発見
- フレームワーク
- フレームワーク
- から
- さらに
- 一般に
- 生成
- 世代
- 取得する
- Gitの
- GitHubの
- 案内
- 持ってる
- 助けます
- ハイブ
- ホスティング
- ホスト
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- 何百
- i
- IAM
- ID
- if
- 説明する
- 画像
- import
- 重要
- 改善します
- in
- 含まれました
- 含ま
- 組み込む
- の増加
- index
- 情報
- インフラ
- 入力
- install
- 対話
- に
- 紹介する
- 導入
- 問題
- IT
- ITS
- ジャック
- ジョブ
- Jobs > Create New Job
- JSON
- ジュピターノート
- ただ
- キープ
- キー
- 言語
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- 大規模
- 最新の
- 起動する
- 発射
- つながる
- う
- レベル
- ライブラリ
- ような
- LIMIT
- ライン
- リスト
- リスト
- ラマ
- LLM
- ローカル
- 位置して
- 場所
- ロジック
- ログイン
- 見て
- 探して
- 検索
- 機械
- メンテナンス
- make
- 作成
- マネージャー
- 管理する
- 多くの
- 地図
- 大規模な
- 五月..
- メカニズム
- 大会
- ミーツ
- 言及する
- Meta
- 方法
- 分
- 軽減する
- モデル
- monthly
- 他には?
- 最も
- 映画
- 動画
- ずっと
- の試合に
- 名
- 名
- ナビゲーション
- 必要
- 必要
- ネットワーク
- 新作
- 次の
- いいえ
- ノート
- ノートPC
- 得
- 10月
- of
- on
- ONE
- の
- 開いた
- オープンソース
- オプション
- or
- オリジナル
- その他
- でる
- 概説
- 出力
- outputs
- が
- オーバーライド
- 自分の
- パック
- パッケージ
- ペイン
- 紙素材
- 並列シミュレーションの設定
- パラメータ
- パリ
- 部
- path
- パス
- 支払う
- のワークプ
- パフォーマンス
- 公演
- 実行する
- 期間
- ペタバイト
- Peter Bauman
- カメラマン
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プロット
- ポイント
- 人気
- ポスト
- パワード
- プレ
- 先行
- 準備
- 準備
- 主要な
- プロセス
- 処理されました
- 処理
- 生産
- プロンプト
- 提供します
- 提供
- は、大阪で
- 提供
- 公然と
- 目的
- 置きます
- Python
- クエリー
- 質問
- すぐに
- Raw
- 生データ
- 到達
- 読む
- 準備
- 最近
- 最近
- 推奨される
- 記録
- 参照する
- リファレンス
- 定期的に
- 関係
- リリース
- 修理
- replace
- リクエスト
- の提出が必要です
- 要件
- リソース
- 応答
- 回答
- 結果
- 結果
- レビュー
- レビュー
- 右
- 職種
- ローリー
- ラン
- ランニング
- 実行
- セージメーカー
- 同じ
- Save
- 規模
- 秤
- スケーリング
- スキャン
- シナリオ
- 科学
- スクリプト
- スクリプト
- 秒
- セクション
- セクション
- セグメント
- select
- 自己
- シニア
- 文
- サーバレス
- サーバ
- サービス
- セッションに
- 設定
- いくつかの
- 彼女
- ショート
- すべき
- 示す
- 意義
- 同様の
- から
- ウェブサイト
- サイズ
- 速度を落とす
- スニペット
- So
- 溶液
- ソリューション
- スープ
- ソース
- スパーク
- 専門家
- 特定の
- SQL
- ssh
- 開始
- 起動
- ステートメント
- 文
- Status:
- 手順
- ステップ
- まだ
- Force Stop
- 店舗
- 保存され
- 店舗
- ストーリー
- 簡単な
- 作戦
- 文字列
- 研究
- 提出する
- 提出する
- 首尾よく
- そのような
- 十分な
- 適当
- スイッチ
- 同期。
- テーブル
- 取る
- ターゲット
- 仕事
- タスク
- テンソルフロー
- 条件
- テスト
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト生成
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- サードパーティ
- この
- 三
- 介して
- 時間
- タイムスタンプ
- 〜へ
- 追跡する
- トレーニング
- 旅行
- true
- 試します
- 2
- 下
- 非構造化
- 更新しました
- URL
- つかいます
- 使用事例
- 中古
- ユーザー
- ユーザー レビュー
- users
- 活用
- バージョン
- バーチャル
- ボリューム
- 歩く
- 欲しいです
- wanted
- 倉庫
- ました
- 仕方..
- 方法
- we
- ウェブ
- Webサービス
- 週間
- WELL
- この試験は
- いつ
- 一方
- which
- while
- 誰
- 野生生物
- 意志
- ウィリアム
- 以内
- 無し
- 女性
- 働いていました
- 価値
- 書きます
- 書き込み
- 産出
- 貴社
- あなたの
- ゼファーネット