Az adattárházak és az adattárház-platformokon végzett elemzések jelentősége az évek során folyamatosan növekszik, és sok vállalkozás támaszkodik ezekre a rendszerekre, mivel mind a rövid távú operatív döntéshozatalban, mind a hosszú távú stratégiai tervezésben kulcsfontosságúak ezekre a rendszerekre. Hagyományosan az adattárházakat kötegelt ciklusokban frissítik, például havonta, hetente vagy naponta, hogy a vállalkozások különféle betekintést nyerhessenek belőlük.
Sok szervezet felismeri, hogy a közel valós idejű adatfeldolgozás és a fejlett elemzés új lehetőségeket nyit meg. Például egy pénzintézet meg tudja jósolni, hogy egy hitelkártya-tranzakció csaló-e, ha egy anomália-észlelő programot közel valós idejű üzemmódban futtat, nem pedig kötegelt módban.
Ebben a bejegyzésben megmutatjuk, hogyan Amazon RedShift képes adatfolyam-feldolgozási és gépi tanulási (ML) előrejelzéseket adni egy platformon.
Az Amazon Redshift egy gyors, méretezhető, biztonságos és teljesen felügyelt felhőalapú adattárház, amely egyszerűvé és költséghatékonyabbá teszi az összes adat szabványos SQL használatával történő elemzését.
Amazon Redshift ML megkönnyíti az adatelemzők és adatbázis-fejlesztők számára az ML-modellek létrehozását, betanítását és alkalmazását az Amazon Redshift adattárházaiban ismert SQL-parancsok segítségével.
Izgatottan várjuk az indulást Amazon Redshift Streaming Ingestion mert Amazon Kinesis adatfolyamok és a Amazon által kezelt adatfolyam az Apache Kafka számára (Amazon MSK), amely lehetővé teszi, hogy közvetlenül egy Kinesis adatfolyamból vagy Kafka-témából töltsön be adatokat anélkül, hogy az adatokat be kellene helyeznie Amazon egyszerű tárolási szolgáltatás (Amazon S3). Az Amazon Redshift adatfolyam-feldolgozás lehetővé teszi, hogy másodperces nagyságrendben alacsony késleltetést érjen el, miközben több száz megabájtnyi adatot tölt be az adattárházába.
Ez a bejegyzés bemutatja, hogy az Amazon Redshift, a felhőalapú adattárház hogyan teszi lehetővé közel valós idejű ML előrejelzések készítését az Amazon Redshift adatfolyam-feldolgozás és a Redshift ML funkcióinak használatával az ismerős SQL nyelven.
Megoldás áttekintése
Az ebben a bejegyzésben ismertetett lépések követésével beállíthat egy produceri streamer alkalmazást egy Amazon rugalmas számítási felhő (Amazon EC2) példány, amely szimulálja a hitelkártya-tranzakciókat, és valós időben továbbítja az adatokat a Kinesis Data Streamsbe. Ön beállított egy Amazon Redshift Streaming Ingestion materializált nézetet az Amazon Redshift-en, ahol a streaming adatok fogadhatók. Megtanít és épít egy Redshift ML modellt, amely valós idejű következtetéseket generál a streaming adatok alapján.
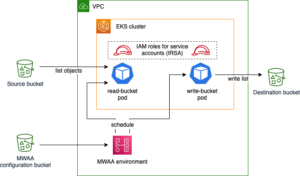
A következő diagram az architektúrát és a folyamatfolyamatot mutatja be.
A lépésenkénti folyamat a következő:
- Az EC2 példány egy hitelkártya-tranzakciós alkalmazást szimulál, amely beilleszti a hitelkártya-tranzakciókat a Kinesis adatfolyamba.
- Az adatfolyam tárolja a bejövő hitelkártya-tranzakciós adatokat.
- Az adatfolyam tetején egy Amazon Redshift Streaming Ingestion materializált nézet jön létre, amely automatikusan feldolgozza a streamelt adatokat az Amazon Redshiftbe.
- A Redshift ML segítségével ML-modellt építhet, taníthat és telepíthet. A Redshift ML modellt előzményi tranzakciós adatok felhasználásával tanítják.
- Ön átalakítja a streaming adatokat, és ML előrejelzéseket generál.
- A kockázat csökkentése érdekében figyelmeztetheti az ügyfeleket, vagy frissítheti az alkalmazást.
Ez a bemutató a hitelkártya-tranzakciók streaming adatait használja. A hitelkártya-tranzakciós adatok fiktívek, és a szimulátor. Az ügyféladatkészlet szintén fiktív, és néhány véletlenszerű adatfüggvénnyel jön létre.
Előfeltételek
- Hozzon létre egy Amazon Redshift klasztert.
- Konfigurálja a fürtöt a Redshift ML használatára.
- Teremt an AWS Identity and Access Management (IAM) felhasználó.
- Frissítse a Redshift-fürthöz kapcsolódó IAM-szerepet, hogy tartalmazza a Kinesis-adatfolyam eléréséhez szükséges engedélyeket. A szükséges szabályzattal kapcsolatos további információkért lásd: Kezdő lépések az adatfolyam-feldolgozással.
- Hozzon létre egy m5.4xlarge EC2 példányt. A Producer alkalmazást m5.4xlarge példányban teszteltük, de szabadon használhat más példánytípust is. A példány létrehozásakor használja a amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI.
- Ha meg szeretné győződni arról, hogy a Python3 telepítve van az EC2 példányban, futtassa a következő parancsot a Python-verzió ellenőrzéséhez (vegye figyelembe, hogy az adatkinyerési szkript csak a Python 3-on működik):
- Telepítse a következő függő csomagokat a szimulátor program futtatásához:
- Konfigurálja az Amazon EC2-t a fenti 3. lépésben létrehozott IAM-felhasználó számára létrehozott AWS-hitelesítési adatokkal. A következő képernyőkép egy példát mutat a használatára aws konfigurálása.

Állítsa be a Kinesis adatfolyamokat
Az Amazon Kinesis Data Streams egy masszívan méretezhető és tartós valós idejű adatfolyam-szolgáltatás. Folyamatosan gigabájtnyi adatot képes rögzíteni másodpercenként több százezer forrásból, például webhelyek kattintási folyamaiból, adatbázis-eseményfolyamokból, pénzügyi tranzakciókból, közösségimédia-hírcsatornákból, IT-naplókból és helykövetési eseményekből. Az összegyűjtött adatok ezredmásodpercekben állnak rendelkezésre, így lehetővé válik a valós idejű analitikai felhasználási esetek, például a valós idejű irányítópultok, a valós idejű anomáliák észlelése, a dinamikus árképzés stb. A Kinesis Data Streams szolgáltatást azért használjuk, mert ez egy szerver nélküli megoldás, amely a használat alapján skálázható.
Hozzon létre egy Kinesis adatfolyamot
Először is létre kell hoznia egy Kinesis adatfolyamot a streaming adatok fogadásához:
- Az Amazon Kinesis konzolon válassza a lehetőséget Adatfolyamok a navigációs ablaktáblában.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Adatfolyam létrehozása.
- A Adatfolyam neve, belép
cust-payment-txn-stream. - A Kapacitás módválassza Igény szerint.

- A többi beállításhoz válassza ki az alapértelmezett beállításokat, és kövesse az utasításokat a telepítés befejezéséhez.
- Rögzítse az ARN-t a létrehozott adatfolyamhoz, hogy a következő szakaszban használja az IAM-házirend meghatározásakor.

Engedélyek beállítása
Ahhoz, hogy a streaming alkalmazás a Kinesis Data Streamsbe írhasson, az alkalmazásnak hozzáféréssel kell rendelkeznie a Kinesishez. A következő házirend-nyilatkozat segítségével hozzáférést biztosíthat az adatfolyamhoz a következő szakaszban beállított szimulátorfolyamatnak. Használja az előző lépésben mentett adatfolyam ARN-jét.
Állítsa be az adatfolyam-előállítót
Mielőtt az Amazon Redshiftben streaming adatokat fogyaszthatnánk, szükségünk van egy streaming adatforrásra, amely adatokat ír a Kinesis adatfolyamba. Ez a bejegyzés egyedileg épített adatgenerátort és a AWS SDK Pythonhoz (Boto3) az adatok közzétételéhez az adatfolyamban. A beállítási utasításokat lásd: Producer szimulátor. Ez a szimulátor folyamat közzéteszi a streaming adatokat az előző lépésben létrehozott adatfolyamban (cust-payment-txn-stream).
Állítsa be a stream fogyasztót
Ez a szakasz az adatfolyam-fogyasztó (az Amazon Redshift adatfolyam-feldolgozási nézet) konfigurálásáról szól.
Az Amazon Redshift Streaming Ingestion alacsony késleltetésű, nagy sebességű adatfolyam-feldolgozást biztosít a Kinesis Data Streams-ből egy Amazon Redshift materializált nézetbe. Beállíthatja az Amazon Redshift-fürtöt úgy, hogy engedélyezze az adatfolyam-feldolgozást, és SQL-utasítások használatával materializált nézetet hozzon létre az automatikus frissítéssel, ahogyan az itt található. Realizált nézetek létrehozása az Amazon Redshiftben. Az automatikus megvalósult nézetfrissítési folyamat másodpercenként több száz megabájt adatfolyam adatfolyamot fog feldolgozni a Kinesis Data Streamsből az Amazon Redshiftbe. Ez gyors hozzáférést biztosít a külső adatokhoz, amelyek gyorsan frissülnek.
A materializált nézet létrehozása után SQL használatával hozzáférhet az adatokhoz az adatfolyamból, és leegyszerűsítheti az adatfolyamokat azáltal, hogy közvetlenül a folyam tetején hoz létre materializált nézeteket.
Hajtsa végre a következő lépéseket az Amazon Redshift streaming materializált nézetének konfigurálásához:
- Az IAM-konzolon válassza ki a házirendeket a navigációs panelen.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Házirend létrehozása.
- Hozzon létre egy új IAM-házirendet
KinesisStreamPolicy. A streaming szabályzat meghatározását lásd Kezdő lépések az adatfolyam-feldolgozással. - A navigációs panelen válassza a lehetőséget szerepek.
- Válassza a Szerep létrehozása lehetőséget.
- választ AWS szolgáltatás És válasszon A Redshift és a Redshift testreszabható.
- Hozzon létre egy új szerepet, melynek neve
redshift-streaming-roleés csatolja a szabályzatotKinesisStreamPolicy. - Hozzon létre egy külső sémát a Kinesis adatfolyamokhoz való hozzárendeléshez:
Most létrehozhat egy materializált nézetet az adatfolyam adatok felhasználásához. Használhatja a SUPER adattípust a hasznos terhelés JSON formátumban való tárolására, vagy az Amazon Redshift JSON függvényei segítségével a JSON-adatokat egyes oszlopokba elemezheti. Ehhez a bejegyzéshez a második módszert használjuk, mert a séma jól meghatározott.
- Hozza létre az adatfolyam-feldolgozás megvalósult nézetét
cust_payment_tx_stream. Ha a következő kódban az AUTOMATIKUS FRISSÍTÉS IGEN értéket adja meg, engedélyezheti a streaming feldolgozási nézet automatikus frissítését, ami időt takarít meg az adatfolyamok kiépítésének elkerülésével:
Ne feledje, hogy json_extract_path_text 64 KB-os hosszkorlátozással rendelkezik. A from_varbye a 65 KB-nál nagyobb rekordokat is kiszűri.
- Frissítse az adatokat.
Az Amazon Redshift streaming materializált nézetét az Amazon Redshift automatikusan frissíti az Ön számára. Így nem kell aggódnia az adatok elavultsága miatt. A materializált nézet automatikus frissítésével az adatok automatikusan betöltődnek az Amazon Redshiftbe, amint elérhetővé válnak az adatfolyamban. Ha a művelet manuális végrehajtását választja, használja a következő parancsot:
- Most kérdezzük le a streaming materializált nézetet a mintaadatok megtekintéséhez:

- Nézzük meg, hány rekord van most a streaming nézetben:

Most befejezte az Amazon Redshift streaming feldolgozási nézet beállítását, amely folyamatosan frissül a bejövő hitelkártya-tranzakciós adatokkal. Beállításomban azt látom, hogy körülbelül 67,000 XNUMX rekord került be a streamelési nézetbe, amikor lefuttattam a kiválasztási számlálási lekérdezést. Ez a szám számodra eltérő lehet.
Redshift ML
A Redshift ML segítségével előre betanított ML-modellt hozhat létre, vagy natívan építhet egyet. További információkért lásd: A gépi tanulás használata az Amazon Redshiftben.
Ebben a bejegyzésben egy ML-modellt képezünk és építünk egy történelmi adatkészlet felhasználásával. Az adatok tartalmazzák a tx_fraud mező, amely egy korábbi tranzakciót csalárdként jelöl meg vagy sem. Felügyelt ML-modellt építünk a Redshift Auto ML segítségével, amely tanul ebből az adatkészletből, és előrejelzi a bejövő tranzakciókat, amikor azokat az előrejelzési függvényeken keresztül futtatják.
A következő szakaszokban bemutatjuk, hogyan kell beállítani az előzményadatkészletet és az ügyféladatokat.
Töltse be az előzményadatkészletet
Az előzménytáblázat több mezőt tartalmaz, mint a streaming adatforrás. Ezek a mezők az ügyfél legutóbbi költési és végső kockázati pontszámát tartalmazzák, például a streaming adatok átalakításával kiszámított csalárd tranzakciók számát. Vannak kategorikus változók is, például hétvégi vagy éjszakai tranzakciók.
Az előzményadatok betöltéséhez futtassa a parancsokat a Amazon Redshift lekérdezésszerkesztő.
Hozd létre a tranzakciós előzmények táblát a következő kóddal. A DDL is megtalálható a GitHub.
Nézzük meg, hány tranzakció van betöltve:
Tekintse meg a havi csalási és nem csalásos tranzakciók trendjét:
Ügyféladatok létrehozása és betöltése
Most létrehozzuk az ügyféltáblázatot és betöltjük az adatokat, amelyek az ügyfél e-mail-címét és telefonszámát tartalmazzák. A következő kód létrehozza a táblát, betölti az adatokat, és mintát vesz a táblából. A DDL asztal a következő helyen érhető el GitHub.
Vizsgálati adatainknak körülbelül 5,000 vásárlója van. A következő képernyőképen minta ügyféladatok láthatók.

Építsünk ML modellt
A historikus kártyatranzakciós táblázatunk 6 hónap adatait tartalmazza, amelyeket most az ML modell betanítására és tesztelésére használunk.
A modell a következő mezőket használja bemenetként:
Kapunk tx_fraud kimenetként.
Ezeket az adatokat képzési és tesztadatkészletekre bontjuk. A 2022-04-01 és 2022-07-31 közötti tranzakciók a képzési készletre vonatkoznak. A tesztkészlethez a 2022-08-01 és 2022-09-30 közötti tranzakciók kerülnek felhasználásra.
Hozzuk létre az ML-modellt az ismert SQL-lel CREATE MODEL utasítás. A Redshift ML parancs alapvető formáját használjuk. A következő módszert használja Amazon SageMaker Autopilot, amely automatikusan elvégzi az adatok előkészítését, a funkciótervezést, a modellválasztást és a betanítást. Adja meg a kódot tartalmazó S3 vödör nevét.
Az ML modellt nak hívom Cust_cc_txn_fd, és a predikciós függvény, mint fn_customer_cc_fd. A FROM záradék a történelmi tábla beviteli oszlopait mutatja public.cust_payment_tx_history. A célparaméter a következőre van állítva tx_fraud, amely a megjósolni kívánt célváltozó. IAM_Role alapértelmezettre van állítva, mert a fürt ezzel a szerepkörrel van konfigurálva; ha nem, akkor meg kell adnia az Amazon Redshift fürt IAM szerepkörét ARN. beállítottam a max_runtime 3,600 másodpercre, ennyi időt adunk a SageMakernek a folyamat befejezéséhez. A Redshift ML az ebben az időkeretben azonosított legjobb modellt telepíti.
A modell összetettségétől és az adatok mennyiségétől függően eltarthat egy ideig, amíg a modell elérhetővé válik. Ha úgy találja, hogy a modell kiválasztása nem fejeződött be, növelje a következő értékét max_runtime. A maximális érték 9999 lehet.
A CREATE MODEL parancs aszinkron módon fut, ami azt jelenti, hogy a háttérben fut. Használhatja a MUTATÁS MODELLET parancsot a modell állapotának megtekintéséhez. Ha az állapot készen áll, az azt jelenti, hogy a modell betanítva és üzembe helyezve van.
A következő képernyőképek a kimenetünket mutatják.



A kimenetből azt látom, hogy a modell helyesen lett felismerve BinaryClassification, és az F1 lett kiválasztva célként. A F1 pontszám egy olyan mérőszám, amely mindkettőt figyelembe veszi pontosság és felidézés. 1 (tökéletes pontosság és visszahívás) és 0 (lehető legalacsonyabb pontszám) közötti értéket ad vissza. Az én esetemben ez 0.91. Minél magasabb az érték, annál jobb a modell teljesítménye.
Teszteljük ezt a modellt a tesztadatkészlettel. Futtassa a következő parancsot, amely minta előrejelzéseket kér le:

Látjuk, hogy egyes értékek egyeznek, mások pedig nem. Hasonlítsuk össze a jóslatokat az alapigazsággal:

Ellenőriztük, hogy a modell működik, és az F1 pontszám jó. Térjünk át a streaming adatokra vonatkozó előrejelzések generálására.
A csalárd tranzakciók előrejelzése
Mivel a Redshift ML modell készen áll a használatra, használhatjuk az előrejelzések futtatására a streaming adatbevitel ellen. Az előzményadatkészlet több mezőt tartalmaz, mint ami a streaming adatforrásban található, de ezek csak az ügyféllel és a csalárd tranzakciók terminálkockázatával kapcsolatos frissességi és gyakorisági mutatók.
Az SQL-t a nézetekbe ágyazva nagyon egyszerűen alkalmazhatjuk a streaming adatok tetején a transzformációkat. Hozd létre a első nézet, amely ügyfélszinten összesíti a streaming adatokat. Ezután hozza létre a második nézet, amely terminál szinten összesíti a streaming adatokat, és a harmadik nézet, amely egyesíti a bejövő tranzakciós adatokat az ügyfelek és a terminálok összesített adataival, és egy helyen hívja meg az előrejelzési függvényt. A harmadik nézet kódja a következő:
Futtasson egy SELECT utasítást a nézeten:
A SELECT utasítás ismételt futtatása során a legújabb hitelkártya-tranzakciók szinte valós időben mennek keresztül az átalakításokon és az ML előrejelzéseken.
Ez demonstrálja az Amazon Redshift erejét – a könnyen használható SQL-parancsokkal átalakíthatja a streaming adatokat összetett ablakfüggvények alkalmazásával, és egy ML-modellt alkalmazhat a csalárd tranzakciók előrejelzésére egy lépésben anélkül, hogy bonyolult adatfolyamokat építene fel és kezelne. kiegészítő infrastruktúra.
Bontsa ki a megoldást
Mivel az adatfolyamok és az ML előrejelzések csaknem valós időben készülnek, üzleti folyamatokat építhet fel ügyfelei figyelmeztetésére Amazon Simple Notification Service (Amazon SNS), vagy zárolhatja az ügyfél hitelkártya számláját egy operációs rendszerben.
Ez a bejegyzés nem tér ki ezeknek a műveleteknek a részleteire, de ha többet szeretne megtudni az eseményvezérelt megoldások Amazon Redshift segítségével történő létrehozásáról, olvassa el a következőt GitHub tárház.
Tisztítsuk meg
A jövőbeni költségek elkerülése érdekében törölje a bejegyzés részeként létrehozott forrásokat.
Következtetés
Ebben a bejegyzésben bemutattuk, hogyan kell beállítani egy Kinesis adatfolyamot, konfigurálni a termelőt és közzétenni az adatokat a streamekben, majd létrehozni egy Amazon Redshift Streaming Ingestion nézetet, és lekérdezni az adatokat az Amazon Redshiftben. Miután az adatok az Amazon Redshift klaszterben voltak, bemutattuk, hogyan lehet betanítani egy ML-modellt, felépíteni egy előrejelzési függvényt, és alkalmazni azt a streaming adatokkal szemben, hogy közel valós idejű előrejelzéseket generáljunk.
Ha bármilyen visszajelzése vagy kérdése van, kérjük, hagyja meg őket a megjegyzésekben.
A szerzőkről
 Bhanu Pittampally a dallasi székhelyű Analytics Specialist Solutions Architect. Szakterülete az analitikai megoldások kiépítése. Előélete adattárházak – építészet, fejlesztés és adminisztráció területén – van. Több mint 15 éve dolgozik az adat- és elemzési területen.
Bhanu Pittampally a dallasi székhelyű Analytics Specialist Solutions Architect. Szakterülete az analitikai megoldások kiépítése. Előélete adattárházak – építészet, fejlesztés és adminisztráció területén – van. Több mint 15 éve dolgozik az adat- és elemzési területen.
 Praveen Kadipikonda a dallasi székhelyű AWS senior Analytics Specialist Solutions Architect. Segít ügyfeleinek hatékony, eredményes és méretezhető elemzési megoldások kidolgozásában. Több mint 15 éve foglalkozik adatbázisok és adattárház-megoldások kiépítésével.
Praveen Kadipikonda a dallasi székhelyű AWS senior Analytics Specialist Solutions Architect. Segít ügyfeleinek hatékony, eredményes és méretezhető elemzési megoldások kidolgozásában. Több mint 15 éve foglalkozik adatbázisok és adattárház-megoldások kiépítésével.
 Ritesh Kumar Sinha a San Francisco-i székhelyű Analytics Specialist Solutions Architect. Több mint 16 éve segített ügyfeleinek skálázható adattárház- és big data megoldások kiépítésében. Szeret hatékony, teljes körű megoldásokat tervezni és építeni az AWS-en. Szabadidejében szeret olvasni, sétálni és jógázni.
Ritesh Kumar Sinha a San Francisco-i székhelyű Analytics Specialist Solutions Architect. Több mint 16 éve segített ügyfeleinek skálázható adattárház- és big data megoldások kiépítésében. Szeret hatékony, teljes körű megoldásokat tervezni és építeni az AWS-en. Szabadidejében szeret olvasni, sétálni és jógázni.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- 000 vásárló
- 1
- 10
- 100
- 11
- 15 év
- 67
- 7
- 9
- a
- Képes
- Rólunk
- felett
- hozzáférés
- Fiók
- Elérése
- Akció
- További
- igazgatás
- fejlett
- Után
- ellen
- Éber
- Minden termék
- lehetővé teszi, hogy
- amazon
- Amazon EC2
- Amazon kinezis
- összeg
- Az elemzők
- Analitikus
- analitika
- elemez
- és a
- anomália észlelése
- Apache
- Alkalmazás
- alkalmaz
- Alkalmazása
- építészet
- körül
- csatolja
- auto
- Automatikus
- automatikusan
- elérhető
- elkerülve
- AWS
- háttér
- alapján
- alapvető
- mert
- válik
- BEST
- Jobb
- között
- Nagy
- Big adatok
- hoz
- épít
- Épület
- üzleti
- üzleti folyamatok
- vállalkozások
- hívás
- hívott
- kéri
- elfog
- kártya
- eset
- esetek
- karakter
- díjak
- ellenőrizze
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- Város
- felhő
- Fürt
- kód
- Oszlopok
- kombájnok
- érkező
- Hozzászólások
- összehasonlítani
- teljes
- kitöltésével
- bonyolult
- bonyolultság
- Kiszámít
- úgy véli,
- Konzol
- fogyaszt
- fogyasztó
- tartalmaz
- költséghatékony
- tudott
- teremt
- készítette
- teremt
- létrehozása
- Hitelesítő adatok
- hitel
- hitelkártya
- vevő
- ügyféladatok
- Ügyfelek
- ciklusok
- napi
- Dallas
- dátum
- Adatok előkészítése
- adattárház
- adattárházak
- adatbázis
- adatbázisok
- adatkészletek
- találka
- Döntéshozatal
- alapértelmezett
- meghatározó
- szállít
- igazolták
- függő
- telepíteni
- telepített
- bevet
- leírt
- Design
- részletek
- Érzékelés
- fejlesztők
- Fejlesztés
- különböző
- közvetlenül
- Nem
- Ennek
- ne
- dow
- dinamikus
- könnyen
- könnyen használható
- hatás
- hatékony
- lehetővé
- lehetővé teszi
- végtől végig
- Mérnöki
- belép
- Eter (ETH)
- esemény
- események
- példa
- izgatott
- külső
- kitermelés
- f1
- ismerős
- GYORS
- Funkció
- Jellemzők
- Visszacsatolás
- mező
- Fields
- Szűrők
- pénzügyi
- Találjon
- zászlók
- áramlási
- következik
- következő
- következik
- forma
- formátum
- talált
- KERET
- Francisco
- csalás
- csalások felderítése
- Ingyenes
- Frekvencia
- ból ből
- teljesen
- funkció
- funkciók
- jövő
- generál
- generált
- generáló
- generátor
- kap
- Ad
- Go
- jó
- biztosít
- Földi
- Csoport
- tekintettel
- segített
- segít
- <p></p>
- Kiemel
- történeti
- történelem
- Hogyan
- How To
- HTML
- HTTPS
- Több száz
- IAM
- azonosított
- Identitás
- fontosság
- in
- tartalmaz
- Bejövő
- Növelje
- növekvő
- egyéni
- információ
- Infrastruktúra
- bemenet
- Betétek
- meglátások
- telepíteni
- példa
- Intézet
- utasítás
- érdekelt
- IT
- csatlakozik
- json
- Kafka
- Kinesis adatfolyamok
- nyelv
- nagyobb
- Késleltetés
- legutolsó
- indít
- tanulás
- Szabadság
- Hossz
- szint
- LIMIT
- korlátozás
- kiszámításának
- terhelések
- hosszú lejáratú
- Elő/Utó
- gép
- gépi tanulás
- készült
- csinál
- KÉSZÍT
- sikerült
- kezelése
- kézzel
- sok
- térkép
- masszívan
- egyező
- matplotlib
- max
- eszközök
- Média
- módszer
- metrikus
- Metrics
- Enyhít
- ML
- Mód
- modell
- modellek
- havi
- hónap
- több
- a legtöbb
- mozog
- név
- Navigáció
- Szükség
- igények
- Új
- következő
- bejelentés
- szám
- számtalan
- célkitűzés
- ONE
- nyit
- működés
- operatív
- Művelet
- Lehetőségek
- Opciók
- érdekében
- szervezetek
- Más
- vázolt
- csomagok
- pandák
- üvegtábla
- paraméter
- rész
- tökéletes
- teljesít
- teljesítmény
- Előadja
- engedélyek
- telefon
- Hely
- tervezés
- emelvény
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- Politikák
- politika
- lehetséges
- állás
- hatalom
- Pontosság
- előre
- előrejelzés
- Tippek
- jósolja
- előző
- árazás
- folyamat
- Folyamatok
- termelő
- Program
- ad
- biztosít
- nyilvános
- közzétesz
- Piton
- Kérdések
- gyorsan
- véletlen
- Olvasás
- kész
- igazi
- real-time
- valós idejű adatok
- felismerve
- kap
- kapott
- új
- elismert
- nyilvántartások
- TÖBBSZÖR
- cserélni
- kötelező
- forrás
- Tudástár
- REST
- Eredmények
- Visszatér
- Kockázat
- Szerep
- futás
- futás
- sagemaker
- San
- San Francisco
- skálázható
- Skála
- screenshotok
- sdk
- tengeren született
- Második
- másodperc
- Rész
- szakaszok
- biztonság
- kiválasztott
- kiválasztás
- vagy szerver
- szolgáltatás
- készlet
- beállítás
- beállítások
- felépítés
- rövid időszak
- előadás
- Műsorok
- Egyszerű
- egyszerűsítése
- szimulátor
- So
- Közösség
- Közösségi média
- megoldások
- Megoldások
- néhány
- forrás
- Források
- szakember
- specializálódott
- költ
- osztott
- SQL
- Színpad
- standard
- kezdődött
- Állami
- nyilatkozat
- nyilatkozatok
- Állapot
- Lépés
- Lépései
- tárolás
- tárolni
- árnyékolók
- Stratégiai
- folyam
- folyó
- Streaming szolgáltatás
- patakok
- ilyen
- szuper
- rendszer
- Systems
- táblázat
- Vesz
- tart
- Talks
- cél
- terminál
- teszt
- A
- Harmadik
- ezer
- Keresztül
- idő
- időbélyeg
- nak nek
- felső
- téma
- hagyományosan
- Vonat
- kiképzett
- Képzések
- tranzakció
- ügyleti
- Tranzakciók
- Átalakítás
- transzformációk
- transzformáló
- tendencia
- Frissítések
- frissítve
- Használat
- használ
- használó
- érvényesített
- érték
- Értékek
- különféle
- Valóság
- változat
- Megnézem
- nézetek
- gyalogos
- végigjátszás
- Raktár
- Raktározás
- weboldal
- hétvége
- heti
- Mit
- ami
- míg
- Wikipedia
- lesz
- nélkül
- dolgozott
- dolgozó
- művek
- ír
- év
- Jóga
- A te
- zephyrnet