Mint gyakorlatilag minden ügyfél, Ön is a lehető legkevesebbet szeretne költeni, miközben a lehető legjobb teljesítményt nyújtja. Ez azt jelenti, hogy figyelni kell az ár-teljesítményre. Val vel Amazon RedShift, akkor a tortádat is megeheted! Az Amazon Redshift akár 4.9-szer alacsonyabb felhasználónkénti költséget és akár 7.9-szer jobb ár-teljesítményt biztosít, mint más felhőalapú adattárházak valós munkaterheléseken olyan fejlett technikák használatával, mint a párhuzamossági skálázás több száz párhuzamos felhasználó támogatására, továbbfejlesztett karakterlánc-kódolás a gyorsabb lekérdezési teljesítmény érdekében , és Amazon Redshift Serverless teljesítménynövelések. Olvassa el, hogy megértse, miért számít az ár-teljesítmény, és hogyan méri az Amazon Redshift ár-teljesítményét, hogy mennyibe kerül egy adott szintű munkaterhelés elérése, nevezetesen a teljesítmény ROI (befektetés megtérülése).
Mivel az ár-teljesítmény számításba az ár és a teljesítmény is beletartozik, kétféleképpen gondolhatunk az ár-teljesítményre. Az első módszer az ár állandó tartása: ha 1 dollárja van elkölteni, mekkora teljesítményt kap az adattárházától? A jobb ár-teljesítményű adatbázis jobb teljesítményt nyújt minden elköltött 1 dollár után. Ezért ha az árat állandó értéken tartja két azonos költségű adattárház összehasonlításakor, a jobb ár-teljesítményű adatbázis gyorsabban futtatja a lekérdezéseket.. A második módszer az ár-teljesítmény vizsgálatára a teljesítmény állandó szinten tartása: ha 10 percen belül be kell fejeznie a munkaterhelést, mennyibe kerül? A jobb ár-teljesítményű adatbázis 10 perc alatt, alacsonyabb költségek mellett lefuttatja a munkát. Ezért, ha a teljesítményt állandó szinten tartjuk, amikor két azonos teljesítményre méretezett adattárházat összehasonlítunk, a jobb ár-teljesítményű adatbázis kevesebbe kerül, és pénzt takarít meg.
Végül az ár-teljesítmény másik fontos szempontja a kiszámíthatóság. A tervezéshez elengedhetetlen, hogy tudjuk, mennyibe fog kerülni az adattárháza az adattárház felhasználóinak számának növekedésével. Nemcsak a legjobb ár-teljesítményt kell nyújtania ma, hanem előre láthatóan méretezhető, és a legjobb ár-teljesítményt nyújtja, ahogy egyre több felhasználó és munkaterhelés lép fel. Egy ideális adattárháznak rendelkeznie kell lineáris skála– az adattárház méretezése a lekérdezési sebesség kétszeresének biztosítására ideális esetben kétszer annyiba (vagy kevesebbbe) kerül.
Ebben a bejegyzésben teljesítményeredményeket osztunk meg annak szemléltetésére, hogy az Amazon Redshift miként kínál lényegesen jobb ár-teljesítményt a vezető alternatív felhő adattárházakhoz képest. Ez azt jelenti, hogy ha ugyanannyit költ az Amazon Redshiftre, mint amennyit a többi adattárházra tenne, akkor jobb teljesítményt érhet el az Amazon Redshift segítségével. Alternatív megoldásként, ha úgy méretezi a Redshift fürtöt, hogy ugyanazt a teljesítményt nyújtsa, alacsonyabb költségeket fog látni ezekhez az alternatívákhoz képest.
Ár-teljesítmény a valós munkaterheléshez
Az Amazon Redshift segítségével nagyon sokféle munkaterhelést hajthat végre, a komplex kivonat-, átalakítás- és betöltési (ETL) alapú jelentések kötegelt feldolgozásától kezdve a valós idejű adatfolyam-elemzéseken át az alacsony késleltetésű üzleti intelligencia (BI) irányítópultokig, amelyek több száz vagy akár több ezer felhasználót kell kiszolgálnia egyidejűleg másodperc alatti válaszidővel, és mindent, ami a kettő között van. Ügyfeleink ár-teljesítményének folyamatos javításának egyik módja az, hogy folyamatosan felülvizsgáljuk a Redshift flotta szoftver- és hardverteljesítmény-telemetriáját, keresve azokat a lehetőségeket és vásárlói használati eseteket, amelyekben tovább javíthatjuk az Amazon Redshift teljesítményét.
Néhány legutóbbi példa a flottatelemetria által vezérelt teljesítményoptimalizálásra:
- Karakterlánc-lekérdezés optimalizálás – Azt elemezve, hogy az Amazon Redshift hogyan dolgozta fel a Redshift flottán belüli különböző adattípusokat, azt találtuk, hogy a karakterlánc-hosszú lekérdezések optimalizálása jelentős előnyökkel járna ügyfeleink munkaterhelésében. (Erről a bejegyzés későbbi részében részletesebben is kitérünk.)
- Automatizált materializált nézetek – Azt tapasztaltuk, hogy az Amazon Redshift ügyfelei gyakran sok olyan lekérdezést futtatnak, amelyek közös segédlekérdezési mintákkal rendelkeznek. Például több különböző lekérdezés összekapcsolhatja ugyanazt a három táblát ugyanazzal az összekapcsolási feltétellel. Az Amazon Redshift mostantól képes automatikusan létrehozni és karbantartani a materializált nézeteket, majd transzparensen átírni a lekérdezéseket a materializált nézetek gépi tanult segítségével történő használatához. automatizált materializált nézet autonómia funkció az Amazon Redshiftben. Ha engedélyezve van, az automatizált materializált nézetek átláthatóan növelhetik a lekérdezések teljesítményét az ismétlődő lekérdezések esetén, felhasználói beavatkozás nélkül. (Ne feledje, hogy az ebben a bejegyzésben tárgyalt referenciaértékek egyikében sem használtak automatizált materializált nézeteket).
- Magas egyidejű munkaterhelések – Egyre növekvő felhasználási esetet látunk, amikor az Amazon Redshiftet használjuk irányítópultszerű munkaterhelések kiszolgálására. Ezeket a munkaterheléseket egy számjegyű másodperc vagy annál rövidebb kívánt lekérdezési válaszidő jellemzi, miközben egyidejűleg több tíz vagy több száz felhasználó futtat lekérdezéseket egyidejűleg tüskés és gyakran kiszámíthatatlan használati mintával. Ennek prototipikus példája egy Amazon Redshift által támogatott BI-műszerfal, amelyen hétfő reggelente megugrik a forgalom, amikor sok felhasználó kezdi a hetét.
A nagy egyidejű munkaterhelések különösen széles körben alkalmazhatók: a legtöbb adattárházi munkaterhelés párhuzamosan működik, és nem ritka, hogy több száz vagy akár több ezer felhasználó fut le egyidejűleg az Amazon Redshift-en. Az Amazon Redshiftet úgy tervezték, hogy a lekérdezések válaszideje kiszámítható és gyors legyen. A Redshift Serverless ezt automatikusan elvégzi Ön helyett azáltal, hogy szükség szerint hozzáadja és eltávolítja a számításokat, hogy a lekérdezések válaszideje gyors és kiszámítható legyen. Ez azt jelenti, hogy egy Redshift Serverless-támogatású irányítópult, amely gyorsan betöltődik, ha egy vagy két felhasználó hozzáfér, továbbra is gyorsan betöltődik, még akkor is, ha sok felhasználó tölti be egyszerre.
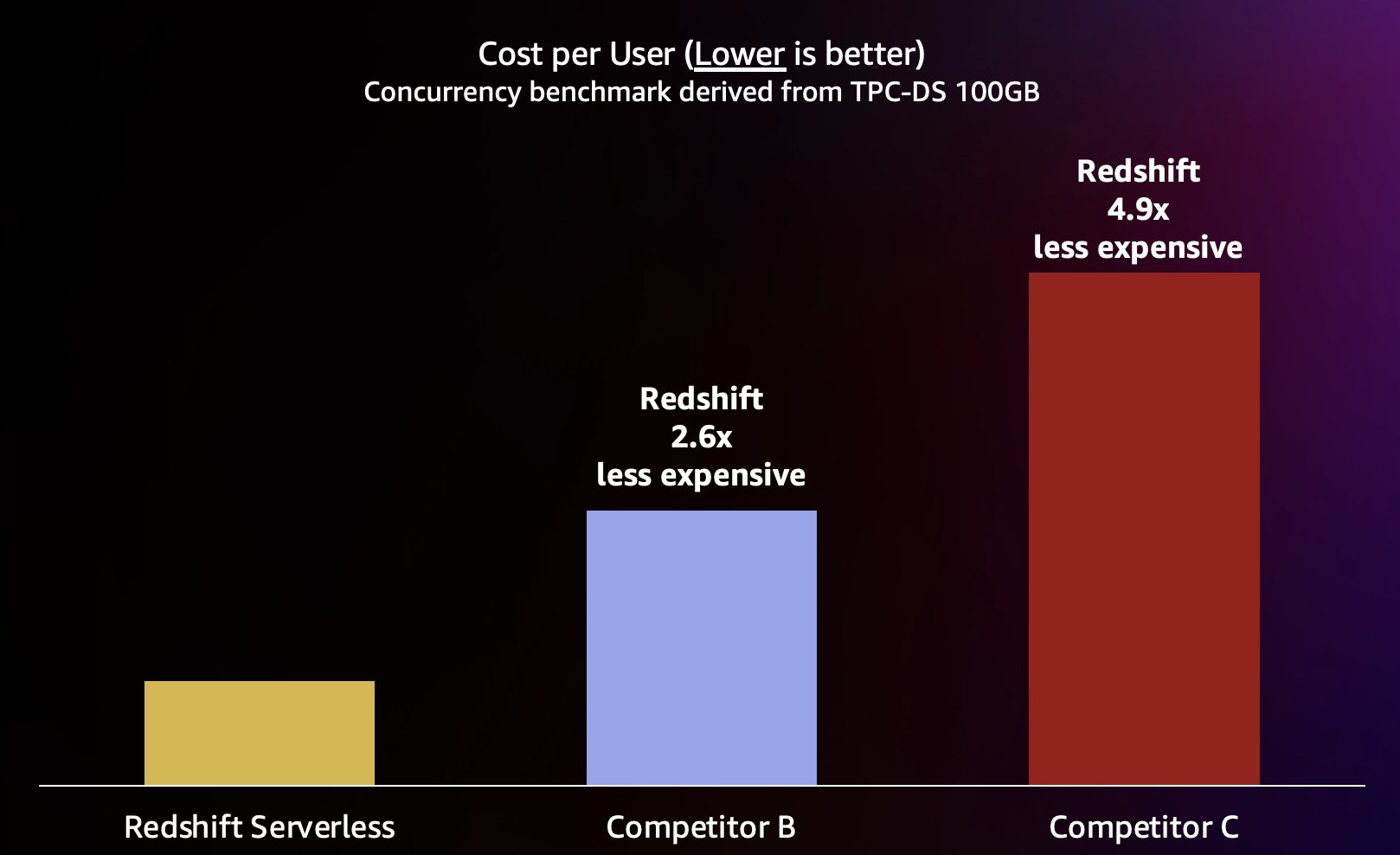
Az ilyen típusú munkaterhelés szimulálásához egy TPC-DS-ből származó benchmarkot használtunk 100 GB-os adatkészlettel. A TPC-DS egy iparági szabvány benchmark, amely számos tipikus adattárház-lekérdezést tartalmaz. Ezen a viszonylag kis, 100 GB-os skálán a lekérdezések ebben a benchmarkban átlagosan néhány másodperc alatt futnak le a Redshift Serverless rendszeren, ami reprezentálja az interaktív BI irányítópultot betöltő felhasználók elvárásait. 1–200 párhuzamos tesztet futtattunk le ennek a benchmarknak, és 1–200 felhasználót szimuláltunk, akik egyszerre próbáltak betölteni egy irányítópultot. Megismételtük a tesztet számos népszerű alternatív felhő adattárral szemben, amelyek szintén támogatják az automatikus méretezést (ha ismeri a bejegyzést Az Amazon Redshift továbbra is vezető szerepet tölt be ár-teljesítményben, nem vettük fel az A versenytársat, mert nem támogatja az automatikus felnagyítást). Megmértük a lekérdezések átlagos válaszidejét, vagyis azt, hogy a felhasználó mennyi ideig várja a lekérdezések befejezését (vagy az irányítópult betöltését). Az eredményeket a következő táblázat mutatja.
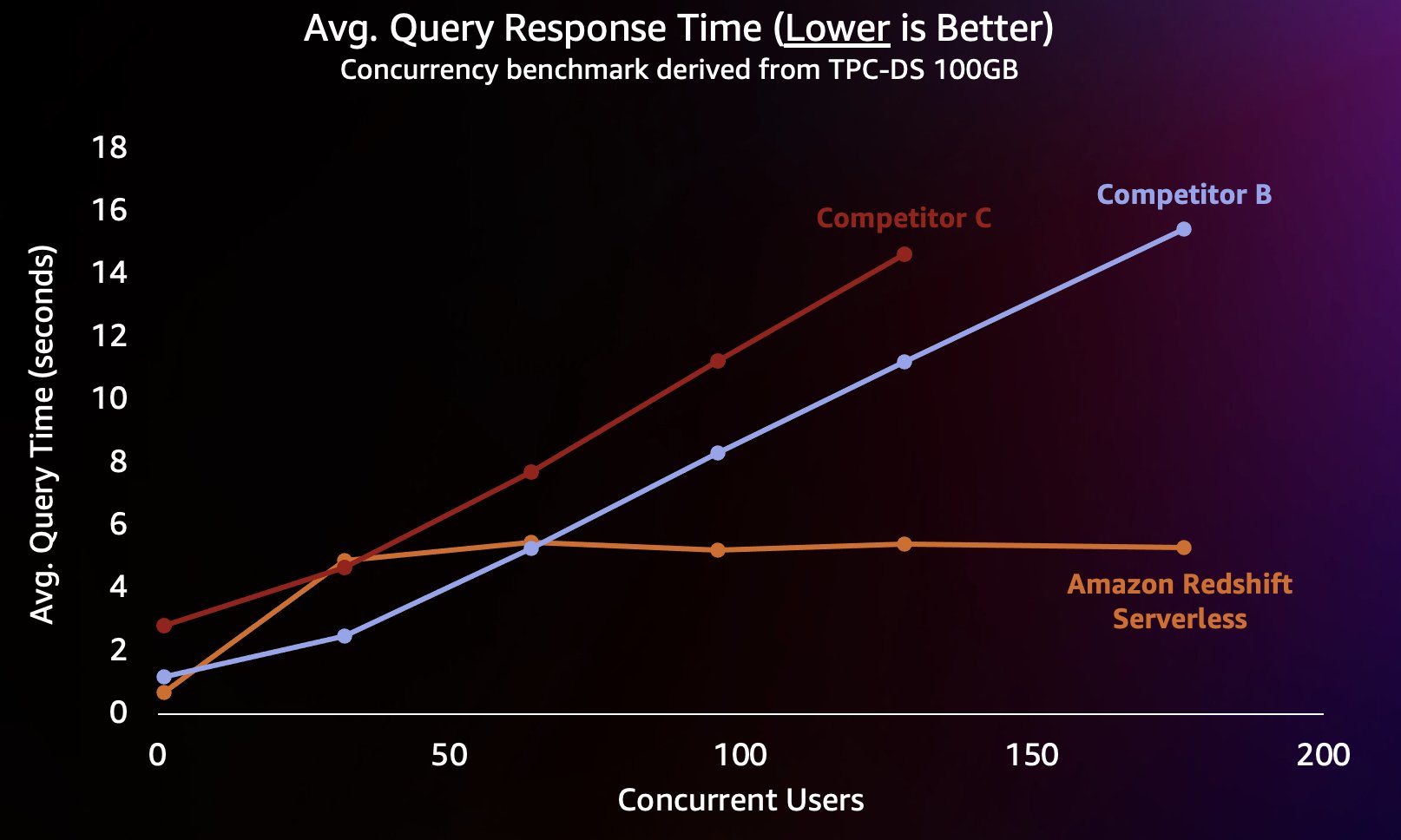
A B versenytárs körülbelül 64 egyidejű lekérdezésig jól skálázódik, ekkor már nem tud további számításokat végezni, és a lekérdezések sorba állnak, ami megnövekszik a lekérdezések válaszidejében. Bár a C versenytárs képes automatikusan skálázni, alacsonyabb lekérdezési teljesítményre skálázódik, mint az Amazon Redshift és a B versenytárs, és nem képes alacsonyan tartani a lekérdezési futásidőt. Ezenkívül nem támogatja a várakozási sorba állítást, amikor kifogy a számítási kapacitás, ami megakadályozza, hogy körülbelül 128 egyidejű felhasználó fölé skálázza. Az ezen túlmenő további lekérdezések beküldését a rendszer elutasítja.
Itt a Redshift Serverless képes a lekérdezések válaszidejét viszonylag konzisztensen, körülbelül 5 másodpercben tartani, még akkor is, ha több száz felhasználó fut le egyidejűleg. A B és C versenytársak átlagos lekérdezési válaszideje folyamatosan növekszik a raktárak terhelésének növekedésével, ami azt eredményezi, hogy a felhasználóknak hosszabb ideig (akár 16 másodpercig) kell várniuk a visszaküldésre, amikor az adattárház foglalt. Ez azt jelenti, hogy ha a felhasználó megpróbál frissíteni egy irányítópultot (amely újratöltéskor akár több egyidejű lekérdezést is elküldhet), az Amazon Redshift sokkal konzisztensebben tudja tartani a műszerfal betöltési idejét még akkor is, ha az irányítópultot több tíz vagy több száz más tölti be. felhasználók egyidejűleg.
Mivel az Amazon Redshift nagyon magas lekérdezési sebességet tud biztosítani a rövid lekérdezésekhez (amint arról már írtunk Az Amazon Redshift továbbra is vezető szerepet tölt be ár-teljesítményben), képes kezelni ezeket a magasabb egyidejűségeket is, ha hatékonyabban és ezért lényegesen alacsonyabb költséggel skáláz. Ennek számszerűsítéséhez megnézzük az ár-teljesítményt a közzétett használatával igény szerinti árképzés az előző tesztben szereplő egyes raktárakhoz, a következő táblázatban látható módon. Érdemes megjegyezni, hogy használja Fenntartott példányok (RI-k), különösen a teljes előzetes fizetési lehetőséggel vásárolt 3 éves RI-k esetében, a legalacsonyabb költséggel jár az Amazon Redshift futtatása Provisioned fürtökön, ami a legjobb relatív ár-teljesítményt eredményezi az igény szerinti vagy más RI opciókhoz képest.

Tehát az Amazon Redshift nemcsak jobb teljesítményt tud nyújtani magasabb párhuzamosság mellett, hanem lényegesen alacsonyabb költséggel is. Az ár-teljesítmény diagram minden adatpontja megegyezik a benchmark meghatározott egyidejűleg történő futtatásának költségével. Mivel az ár-teljesítmény lineáris, a benchmark bármely egyidejű futtatásának költségét eloszthatjuk az egyidejűséggel (az egyidejű felhasználók száma a diagramon), hogy megtudjuk, mennyibe kerül az egyes új felhasználók hozzáadása ehhez a viszonyítási alaphoz.
Az előző eredmények könnyen megismételhetők. A benchmarkban használt összes lekérdezés elérhető nálunk GitHub tárház a teljesítményt pedig úgy mérik, hogy elindítanak egy adattárházat, engedélyezik a párhuzamossági skálázást az Amazon Redshift-en (vagy a megfelelő automatikus skálázási funkciót más raktárakon), betöltik az adatokat a dobozból (nincs kézi hangolás vagy adatbázis-specifikus beállítás), majd fut egy lekérdezések egyidejű folyama 1–200 párhuzamosságban, 32-es lépésekben minden adattárházban. Ugyanez a GitHub repo hivatkozik az előre generált (és módosítatlan) TPC-DS adatokra Amazon egyszerű tárolási szolgáltatás (Amazon S3) különböző méretekben a hivatalos TPC-DS adatgeneráló készlet segítségével.
A karakterlánc-nehéz munkaterhelések optimalizálása
Ahogy korábban említettük, az Amazon Redshift csapata folyamatosan keresi az új lehetőségeket, hogy még jobb ár-teljesítményt biztosíthasson ügyfeleink számára. Az egyik nemrégiben bevezetett fejlesztés, amely jelentősen javította a teljesítményt, az az optimalizálás, amely felgyorsítja a lekérdezések teljesítményét a karakterlánc-adatokhoz képest. Például meg szeretné keresni a New York-i kiskereskedelmi üzletekből származó teljes bevételt egy olyan lekérdezéssel, mint SELECT sum(price) FROM sales WHERE city = ‘New York’. Ez a lekérdezés predikátumot alkalmaz a karakterlánc adatokra (city = ‘New York’). Ahogy elképzelhető, a karakterlánc-adatfeldolgozás mindenütt jelen van az adattárház-alkalmazásokban.
Annak számszerűsítésére, hogy az ügyfelek munkaterhelése milyen gyakran fér hozzá a karakterláncokhoz, részletes elemzést végeztünk a karakterlánc-adattípusok használatáról az Amazon Redshift által kezelt több tízezer ügyfélfürt flottatelemetriájával. Elemzésünk szerint a klaszterek 90%-ában a karakterlánc oszlopok az összes oszlop legalább 30%-át teszik ki, a klaszterek 50%-ában pedig a string oszlopok az összes oszlop legalább 50%-át. Ezenkívül az Amazon Redshift felhőalapú adattárház platformon futó összes lekérdezés többsége legalább egy karakterlánc-oszlophoz fér hozzá. Egy másik fontos tényező, hogy a karakterlánc-adatok nagyon gyakran alacsony számosságúak, ami azt jelenti, hogy az oszlopok viszonylag kis egyedi értékeket tartalmaznak. Például bár an orders az értékesítési adatokat reprezentáló táblázat több milliárd sort tartalmazhat, an order_status A táblázat oszlopa csak néhány egyedi értéket tartalmazhat a sorok milliárdjai közül, mint pl pending, in processés completed.
Az írás pillanatában az Amazon Redshift legtöbb karakterlánc-oszlopa a következővel van tömörítve LZO or ZSTD algoritmusok. Ezek jó általános célú tömörítési algoritmusok, de nem úgy tervezték őket, hogy kihasználják az alacsony számosságú karakterlánc-adatokat. Különösen megkövetelik az adatok kitömörítését a műveletek előtt, és kevésbé hatékonyak a hardveres memória sávszélességének felhasználásában. Az alacsony számosságú adatokhoz létezik egy másik típusú kódolás, amely optimálisabb lehet: BYTEDICT. Ez a kódolás egy szótár-kódolási sémát használ, amely lehetővé teszi az adatbázismotor számára, hogy közvetlenül működjön a tömörített adatokon anélkül, hogy először ki kellene őket tömöríteni.
Annak érdekében, hogy tovább javítsa az ár-teljesítményt a nehéz terhelések esetén, az Amazon Redshift további teljesítményfejlesztéseket vezet be, amelyek felgyorsítják a szkennelést és a predikátum kiértékelését, a BYTEDICT kódolású, alacsony számú karakterlánc oszlopokhoz képest 5-63-szor gyorsabban (lásd az eredményeket: a következő szakasz) összehasonlítva az alternatív tömörítési kódolásokkal, mint például az LZO vagy a ZSTD. Az Amazon Redshift ezt a teljesítménynövekedést a könnyű, CPU-hatékony, BYTEDICT kódolású, alacsony számosságú karakterlánc-oszlopokon való vektorizálással éri el. Ezek a karakterlánc-feldolgozási optimalizálások hatékonyan használják ki a modern hardver által biztosított memória sávszélességet, lehetővé téve a valós idejű elemzést a karakterlánc adatokon. Ezek az újonnan bevezetett teljesítményképességek optimálisak az alacsony számosságú karakterlánc-oszlopokhoz (akár néhány száz egyedi karakterlánc-érték).
Ha engedélyezi, automatikusan profitálhat ebből az új, nagy teljesítményű karakterlánc-javításból automatikus táblázat optimalizálás az Amazon Redshift adattárházában. Ha nincs engedélyezve az automatikus táblaoptimalizálás a táblákon, ajánlásokat kaphat a következőtől Amazon Redshift Advisor az Amazon Redshift konzolon egy karakterlánc-oszlop BYTEDICT kódolására való alkalmasságáról. Olyan új táblákat is meghatározhat, amelyek alacsony számosságú karakterlánc oszlopokkal rendelkeznek BYTEDICT kódolással. Az Amazon Redshift karakterlánc-javításai mostantól minden AWS-régióban elérhetők, ahol Az Amazon Redshift elérhető.
Teljesítmény eredményei
A karakterlánc-javítások teljesítményhatásának mérésére létrehoztunk egy 10 TB-os (Tera Byte) adatkészletet, amely alacsony számosságú karakterláncadatokból állt. Az adatok három verzióját generáltuk rövid, közepes és hosszú karakterláncok felhasználásával, amelyek megfelelnek az Amazon Redshift flotta telemetriájából származó karakterlánchosszak 25., 50. és 75. százalékának. Ezeket az adatokat kétszer töltöttük be az Amazon Redshiftbe, az egyik esetben LZO tömörítéssel, a másikban pedig BYTEDICT tömörítéssel kódoltuk. Végül megmértük az olyan nehéz lekérdezések teljesítményét, amelyek sok sort (a táblázat 90%-a), közepes számú sort (a táblázat 50%-a) és néhány sort (a táblázat 1%-a) adnak vissza ezekhez az alacsony értékekhez képest. - kardinalitási karakterlánc adatkészletek. A teljesítmény eredményeit a következő táblázat foglalja össze.

A sorok nagy százalékának megfelelő predikátumokkal rendelkező lekérdezések 5–30-szoros javulást értek el az új vektorizált BYTEDICT kódolással az LZO-hoz képest, míg a sorok alacsony százalékának megfelelő predikátumokat tartalmazó lekérdezések 10–63-szoros javulást értek el ebben a belső referenciaértékben.
Redshift szerver nélküli ár-teljesítmény
Az ebben a bejegyzésben bemutatott nagy egyidejűségű teljesítményeredményeken kívül a TPC-DS-ből származó Cloud Data Warehouse benchmarkot is felhasználtuk a Redshift Serverless ár-teljesítményének összehasonlítására más adattárházakkal egy nagyobb, 3 TB-os adatkészlet használatával. Olyan adattárházakat választottunk, amelyek árai hasonlóak voltak, ebben az esetben a 10 dollár óránkénti 32%-án belül, nyilvánosan elérhető, igény szerinti árképzéssel. Ezek az eredmények azt mutatják, hogy az Amazon Redshift RA3 példányokhoz hasonlóan a Redshift Serverless is jobb ár-teljesítményt biztosít a többi vezető felhő adattárházhoz képest. Mint mindig, ezek az eredmények replikálhatók a mi SQL-szkriptjeink használatával GitHub tárház.

Javasoljuk, hogy próbálja ki az Amazon Redshiftet sajátjával bizonyíték a koncepcióra munkaterhelések, mint a legjobb módja annak, hogy megtudja, hogyan tudja az Amazon Redshift megfelelni az adatelemzési igényeinek.
Találja meg a legjobb ár-érték arányt a munkaterheléséhez
Az ebben a bejegyzésben használt referenciaértékek az ipari szabványnak megfelelő TPC-DS benchmarkból származnak, és a következő jellemzőkkel rendelkeznek:
- A séma és az adatok a TPC-DS módosítása nélkül kerülnek felhasználásra.
- A lekérdezések a hivatalos TPC-DS készlettel generálódnak, a lekérdezési paraméterekkel a TPC-DS készlet alapértelmezett véletlenszerű magjával. Ha a raktár nem támogatja az alapértelmezett TPC-DS lekérdezés SQL dialektusát, akkor a rendszer TPC által jóváhagyott lekérdezési változatokat használ egy raktárhoz.
- A teszt 99 TPC-DS SELECT lekérdezést tartalmaz. Nem tartalmazza a karbantartási és átviteli lépéseket.
- Az egyetlen 3 TB-os párhuzamossági teszthez három teljesítményfuttatást hajtottak végre, és minden adattárház esetében a legjobb futtatást végezték el.
- A TPC-DS lekérdezések ár-teljesítménye az óraköltség (USD) szorzata a referenciaérték órákban kifejezett futási idejével, ami megegyezik a referenciaérték futtatásának költségével. A legfrissebb közzétett igény szerinti árazás az összes adattárházhoz használatos, nem pedig a fenntartott példányok árazása, amint azt korábban említettük.
Ezt Cloud Data Warehouse benchmarknak hívjuk, és könnyen reprodukálhatja az előző összehasonlítási eredményeket a szkriptek, lekérdezések és adatok segítségével. GitHub tárház. Ez a bejegyzésben leírt TPC-DS benchmarkokból származik, és mint ilyen, nem hasonlítható össze a közzétett TPC-DS eredményekkel, mivel tesztjeink eredményei nem felelnek meg a hivatalos specifikációnak.
Következtetés
Az Amazon Redshift elkötelezett amellett, hogy az iparág legjobb ár-teljesítményét nyújtsa a legkülönbözőbb munkaterhelések mellett. A Redshift Serverless lineárisan skálázódik a legjobb (legalacsonyabb) ár-teljesítmény mellett, több száz egyidejű felhasználót támogat, miközben konzisztens lekérdezési válaszidőket tart fenn. Az ebben a bejegyzésben tárgyalt teszteredmények alapján az Amazon Redshift akár 2.6-szor jobb ár-teljesítményt mutat ugyanazon a párhuzamossági szinten, mint a legközelebbi versenytárs (B versenytárs). Amint azt korábban említettük, a Reserved Instances és a 3 éves teljes előzetes opció használata a legalacsonyabb költséget nyújtja az Amazon Redshift futtatásához, ami még jobb relatív ár-teljesítményt eredményez az ebben a bejegyzésben használt igény szerinti példányárakhoz képest. Folyamatos teljesítményjavítási megközelítésünk az ügyfelek megszállottságának egyedülálló kombinációját foglalja magában, hogy megértsük az ügyfelek használati eseteit és az azokhoz kapcsolódó skálázhatósági szűk keresztmetszeteket, valamint folyamatos flottaadat-elemzést, hogy azonosítsuk a jelentős teljesítményoptimalizálási lehetőségeket.
Minden munkaterhelés egyedi jellemzőkkel rendelkezik, így ha még csak most kezdi, a bizonyíték a koncepcióra a legjobb módja annak, hogy megértse, hogyan csökkentheti az Amazon Redshift a költségeit, miközben jobb teljesítményt nyújt. Amikor saját koncepcióját futtatja, fontos, hogy a megfelelő mérőszámokra összpontosítson – a lekérdezési teljesítményre (lekérdezések száma óránként), a válaszidőre és az ár-teljesítményre. Adatvezérelt döntést hozhat, ha saját maga futtatja a proof of concept vagy segítséggel az AWS-től vagy a rendszerintegrációs és tanácsadó partner.
Az Amazon Redshift legújabb fejleményeinek frissítéséhez kövesse a Az Amazon Redshift újdonságai táplálkoznak.
A szerzőkről
 Stefan Gromoll Senior Performance Engineer az Amazon Redshift csapatánál, ahol a Redshift teljesítmény méréséért és javításáért felel. Szabadidejében szívesen főz, három fiúval játszik és tűzifát vág.
Stefan Gromoll Senior Performance Engineer az Amazon Redshift csapatánál, ahol a Redshift teljesítmény méréséért és javításáért felel. Szabadidejében szívesen főz, három fiúval játszik és tűzifát vág.
 Ravi Animi az Amazon Redshift csapatának Senior Product Management vezetője, és az Amazon Redshift felhőalapú adattárház szolgáltatás több funkcionális területét is felügyeli, beleértve a teljesítményt, a térbeli elemzést, a streaming-feldolgozást és a migrációs stratégiákat. Tapasztalattal rendelkezik relációs adatbázisok, többdimenziós adatbázisok, IoT-technológiák, tárolási és számítási infrastruktúra-szolgáltatások terén, és nemrégiben az AI/deep learning, a számítógépes látás és a robotika alkalmazásának startup alapítója.
Ravi Animi az Amazon Redshift csapatának Senior Product Management vezetője, és az Amazon Redshift felhőalapú adattárház szolgáltatás több funkcionális területét is felügyeli, beleértve a teljesítményt, a térbeli elemzést, a streaming-feldolgozást és a migrációs stratégiákat. Tapasztalattal rendelkezik relációs adatbázisok, többdimenziós adatbázisok, IoT-technológiák, tárolási és számítási infrastruktúra-szolgáltatások terén, és nemrégiben az AI/deep learning, a számítógépes látás és a robotika alkalmazásának startup alapítója.
 Aamer Shah az Amazon Redshift Service csapatának vezető mérnöke.
Aamer Shah az Amazon Redshift Service csapatának vezető mérnöke.
 Sanket Hase az Amazon Redshift Service csapatának szoftverfejlesztési menedzsere.
Sanket Hase az Amazon Redshift Service csapatának szoftverfejlesztési menedzsere.
 Orestis Polychroniou az Amazon Redshift Service csapatának vezető mérnöke.
Orestis Polychroniou az Amazon Redshift Service csapatának vezető mérnöke.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :van
- :is
- :nem
- :ahol
- $ UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Képes
- Rólunk
- gyorsul
- hozzáférés
- igénybe vett
- ér
- át
- hozzáadott
- hozzáadásával
- mellett
- További
- fejlett
- Előny
- biztosított
- ellen
- algoritmusok
- Minden termék
- lehetővé teszi, hogy
- Is
- alternatív
- alternatívák
- Bár
- mindig
- amazon
- Az Amazon Web Services
- összeg
- an
- elemzés
- analitika
- elemzése
- és a
- Másik
- bármilyen
- alkalmazások
- Alkalmazása
- megközelítés
- VANNAK
- területek
- körül
- AS
- megjelenés
- társult
- At
- figyelem
- auto
- Automatizált
- Automatikus
- automatikusan
- elérhető
- átlagos
- AWS
- b
- Sávszélesség
- alapján
- BE
- mert
- előtt
- kezdődik
- hogy
- benchmark
- referenciaértékek
- haszon
- BEST
- Jobb
- között
- Túl
- milliárd
- mindkét
- szűk
- Doboz
- hoz
- széles
- üzleti
- üzleti intelligencia
- elfoglalt
- de
- by
- CAKE
- számított
- számítás
- hívás
- TUD
- képességek
- eset
- esetek
- jellemzők
- jellemzett
- Táblázatos
- aprítás
- választotta
- Város
- felhő
- Fürt
- Oszlop
- Oszlopok
- kombináció
- elkötelezett
- Közös
- hasonló
- összehasonlítani
- képest
- összehasonlítva
- versenyző
- versenytársak
- bonyolult
- megfelelnek
- Kiszámít
- számítógép
- Számítógépes látás
- koncepció
- egyidejű
- feltétel
- lefolytatott
- következetes
- Konzol
- állandó
- állandóan
- alkot
- tanácsadó
- tartalmaz
- folyamatosan
- folytatódik
- tovább
- folyamatos
- folyamatosan
- főzés
- Megfelelő
- Költség
- kiadások
- összekapcsolt
- teremt
- kritikus
- vevő
- Ügyfelek
- műszerfal
- műszerfalak
- dátum
- adatelemzés
- Adatelemzés
- adatfeldolgozás
- adatkészlet
- adattárház
- adattárházak
- adatalapú
- adatbázis
- adatbázisok
- adatkészletek
- találka
- döntés
- alapértelmezett
- meghatározott
- szállít
- átadó
- szállít
- Származtatott
- leírt
- tervezett
- kívánatos
- részlet
- részletes
- Fejlesztés
- fejlesztések
- különböző
- közvetlenül
- megvitatni
- tárgyalt
- Sokféleség
- osszuk
- do
- nem
- Nem
- ne
- hajtott
- minden
- Korábban
- könnyen
- eszik
- Hatékony
- hatékony
- eredményesen
- engedélyezve
- lehetővé téve
- ösztönzése
- Motor
- mérnök
- fokozott
- fokozás
- fejlesztések
- belép
- Egyenértékű
- különösen
- Eter (ETH)
- értékelések
- Még
- minden
- példa
- példák
- vár
- tapasztalat
- kivonat
- tényező
- ismerős
- messze
- GYORS
- gyorsabb
- Funkció
- kevés
- Végül
- Találjon
- befejezni
- vezetéknév
- FLOTTA
- Összpontosít
- következik
- következő
- A
- talált
- alapító
- ból ből
- funkcionális
- további
- Általános rendeltetésű
- generált
- generáció
- kap
- szerzés
- GitHub
- ad
- megy
- jó
- Növekvő
- növekszik
- fogantyú
- hardver
- Legyen
- tekintettel
- he
- Magas
- <p></p>
- övé
- tart
- holding
- óra
- NYITVATARTÁS
- Hogyan
- HTML
- http
- HTTPS
- száz
- Több száz
- ideális
- ideálisan
- azonosítani
- if
- ábrázol
- kép
- Hatás
- fontos
- fontos szempont
- javul
- javított
- javulás
- fejlesztések
- javuló
- in
- tartalmaz
- magában foglalja a
- Beleértve
- Növelje
- <p></p>
- Növeli
- jelzi
- az iparé
- Infrastruktúra
- példa
- példányok
- integráció
- Intelligencia
- interaktív
- belső
- beavatkozás
- bele
- Bevezetett
- bevezetéséről
- beruházás
- jár
- tárgyak internete
- IT
- ITS
- csatlakozik
- jpg
- éppen
- Tart
- készlet
- Ismerve
- nagy
- nagyobb
- a későbbiekben
- legutolsó
- a legújabb fejlemények
- indított
- indítás
- vezető
- vezető
- tanulás
- legkevésbé
- kevesebb
- szint
- könnyűsúlyú
- mint
- kis
- kiszámításának
- betöltés
- terhelések
- található
- Hosszú
- hosszabb
- néz
- keres
- Elő/Utó
- alacsonyabb
- legalacsonyabb
- fenntartása
- fenntartása
- karbantartás
- Többség
- csinál
- sikerült
- vezetés
- menedzser
- kezeli
- kézikönyv
- sok
- Mérkőzés
- számít
- Lehet..
- jelenti
- eszközök
- intézkedés
- megmért
- mérő
- közepes
- Találkozik
- Memory design
- említett
- esetleg
- elvándorlás
- jegyzőkönyv
- modern
- hétfő
- pénz
- több
- Ráadásul
- a legtöbb
- sok
- ugyanis
- Szükség
- szükséges
- igények
- Új
- New York
- new york city
- újonnan
- következő
- nem
- megjegyezni
- neves
- megjegyezve,
- Most
- szám
- of
- hivatalos
- gyakran
- on
- Igény szerint
- ONE
- csak
- működik
- hajtású
- Lehetőségek
- optimálisan
- optimalizálás
- optimalizálása
- opció
- Opciók
- or
- Más
- mi
- ki
- felett
- saját
- paraméterek
- különös
- Mintás
- minták
- Fizet
- fizetés
- mert
- százalék
- teljesítmény
- tervezés
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- játék
- pont
- Népszerű
- lehetséges
- állás
- hatalom
- Kiszámítható
- bemutatott
- megakadályozza
- ár
- árazás
- Fő
- feldolgozott
- feldolgozás
- Termékek
- termékmenedzsment
- bizonyíték
- bizonyíték a koncepcióra
- ad
- nyilvánosan
- közzétett
- vásárolt
- lekérdezések
- gyorsan
- véletlen
- Olvass
- való Világ
- real-time
- kap
- új
- nemrég
- ajánlások
- referenciák
- régiók
- Elutasítva..
- relatív
- viszonylag
- eltávolítása
- megismételt
- ismétlő
- többszörözött
- Jelentések
- reprezentatív
- képviselő
- szükség
- fenntartott
- válasz
- felelős
- kapott
- Eredmények
- kiskereskedelem
- visszatérés
- jövedelem
- Kritika
- jobb
- robotika
- ROI
- futás
- futás
- fut
- értékesítés
- azonos
- Megtakarítás
- látta
- skálázhatóság
- Skála
- Mérleg
- skálázás
- vizsgál
- rendszer
- szkriptek
- Második
- másodperc
- Rész
- lát
- mag
- idősebb
- szolgál
- vagy szerver
- szolgáltatás
- Szolgáltatások
- készlet
- felépítés
- számos
- Megosztás
- rövid
- kellene
- előadás
- mutatott
- jelentős
- jelentősen
- Hasonlóképpen
- Egyszerű
- egyszerre
- egyetlen
- Méret
- méretű
- kicsi
- So
- szoftver
- szoftverfejlesztés
- térbeli
- leírás
- meghatározott
- sebesség
- költ
- költött
- tüske
- SQL
- kezdet
- kezdődött
- indítás
- tartózkodás
- folyamatosan
- Lépései
- tárolás
- árnyékolók
- egyértelmű
- stratégiák
- folyam
- folyó
- Húr
- beküldése
- ilyen
- alkalmasság
- támogatás
- Támogató
- rendszer
- táblázat
- Vesz
- meghozott
- csapat
- technikák
- Technologies
- mondd
- tíz
- teszt
- tesztek
- mint
- hogy
- A
- azok
- akkor
- Ott.
- ebből adódóan
- Ezek
- ők
- Szerintem
- ezt
- azok
- ezer
- három
- áteresztőképesség
- idő
- alkalommal
- nak nek
- Ma
- Végösszeg
- forgalom
- Átalakítás
- átláthatóan
- megpróbál
- próbál
- Kétszer
- kettő
- típus
- típusok
- tipikus
- mindenütt jelenlevő
- képtelen
- Ritka
- megért
- egyedi
- kiszámíthatatlan
- -ig
- us
- Használat
- USAdollár
- használ
- használati eset
- használt
- használó
- Felhasználók
- használ
- segítségével
- Értékek
- fajta
- különféle
- nagyon
- nézetek
- gyakorlatilag
- látomás
- várjon
- akar
- Raktár
- volt
- Út..
- módon
- we
- háló
- webes szolgáltatások
- hét
- JÓL
- voltak
- Mit
- amikor
- mivel
- ami
- míg
- miért
- széles
- lesz
- val vel
- belül
- nélkül
- érdemes
- lenne
- írás
- írt
- york
- te
- A te
- zephyrnet