Amazon RedShift egy gyors, teljesen felügyelt, petabájt méretű felhő adattárház, amely egyszerűvé és költséghatékonysá teszi az összes adat elemzését szabványos SQL és a meglévő üzleti intelligencia (BI) eszközeivel. Napjainkban ügyfelek tízezrei használják az Amazon Redshiftet exabájtnyi adat elemzésére és analitikus lekérdezések futtatására, így ez a legszélesebb körben használt felhőalapú adattárház. Az Amazon Redshift szerver nélküli és kiépített konfigurációban is elérhető.
Az Amazon Redshift segítségével közvetlenül hozzáférhet a tárolt adatokhoz Amazon egyszerű tárolási szolgáltatás (Amazon S3) SQL-lekérdezéseket használva, és egyesítheti az adatokat az adattárházában és a Data Lake-ben. Az Amazon Redshift segítségével lekérdezheti az S3 Data Lake-ben lévő adatokat egy központi segítségével AWS ragasztó metastore a Redshift adattárházból.
Az Amazon Redshift számos adatformátum lekérdezését támogatja, például CSV, JSON, Parquet és ORC, valamint táblázatformátumok, például Apache Hudi és Delta. Az Amazon Redshift támogatja a beágyazott adatok lekérdezését is összetett adattípusokkal, mint például a struktúra, a tömb és a térkép.
Ezzel a képességgel az Amazon Redshift költséghatékony módon kiterjeszti az Ön petabájtos méretű adattárházát egy exabájt méretű adattóra az Amazon S3-on.
Az Apache Iceberg a legújabb táblázatformátum, amelyet az Amazon Redshift előzetes verziójában már támogat. Ebben a bejegyzésben megmutatjuk, hogyan kérdezhet le Iceberg táblákat az Amazon Redshift segítségével, és fedezze fel az Iceberg támogatását és lehetőségeit.
Megoldás áttekintése
Apache jéghegy egy nyílt táblázatformátum nagyon nagy petabájtos méretű analitikai adatkészletekhez. Az Iceberg nagy fájlgyűjteményt kezel táblázatként, és támogatja az olyan modern analitikai adattó-műveleteket, mint a rekordszintű beszúrás, frissítés, törlés és időutazási lekérdezések. Az Iceberg specifikáció lehetővé teszi a zökkenőmentes táblázatfejlesztést, például a séma- és partíciófejlődést, és a kialakítása az Amazon S3-on való használatra optimalizált.
Az Iceberg az összes metaadatfájl metaadat-mutatóját tárolja. Amikor egy SELECT lekérdezés egy Iceberg táblát olvas, a lekérdezőmotor először az Iceberg katalógusba lép, majd lekéri a legutóbbi metaadatfájl helyének bejegyzését, ahogy az a következő ábrán látható.
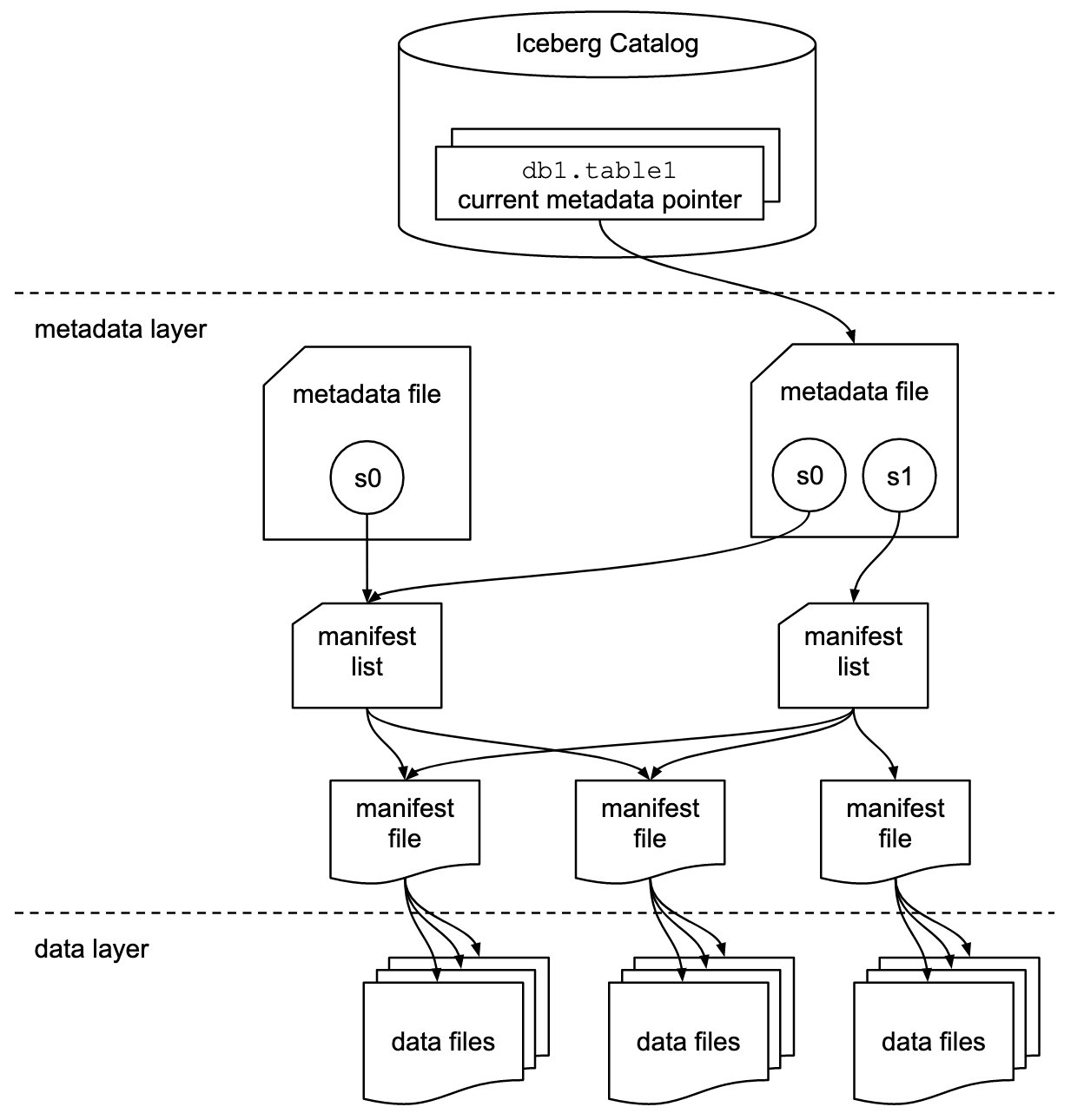
Az Amazon Redshift mostantól támogatja az Apache Iceberg táblákat, amelyek lehetővé teszik a Data Lake ügyfelei számára, hogy csak olvasható elemzési lekérdezéseket hajtsanak végre tranzakciókonzisztens módon. Ez lehetővé teszi a tranzakciós adattókon lévő táblák egyszerű kezelését és karbantartását.
Az Amazon Redshift támogatja az Apache Iceberg natív sémáját és partíciófejlesztési képességeit a AWS ragasztóadat-katalógus, így nincs szükség a tábladefiníciók módosítására új partíciók hozzáadásához vagy nagy mennyiségű adat mozgatásához és feldolgozásához egy meglévő adattó-tábla sémájának megváltoztatásához. Az Amazon Redshift az Apache Iceberg tábla metaadataiban tárolt oszlopstatisztikák segítségével optimalizálja lekérdezési terveit, és csökkenti a lekérdezések futtatásához szükséges fájlvizsgálatokat.
Ebben a bejegyzésben a Sárga taxi nyilvános adatkészlet a NYC Taxi & Limousine Commissiontól mint forrásadataink. Az adatkészlet adatfájlokat tartalmaz Apache parketta formátumban az Amazon S3-on. Használjuk Amazon Athéné ennek a parketta adatkészletnek a konvertálásához, majd használja Amazon Red Shift Spectrum lekérdezni és egy Redshift helyi táblával csatlakozni, sorszintű törléseket és frissítéseket, valamint partíciófejlődést hajtani végre, mindezt az AWS ragasztóadat-katalógusán keresztül koordinálva egy S3 adattóban.
Előfeltételek
A következő előfeltételekkel kell rendelkeznie:
Konvertálja a parkettaadatokat Iceberg asztallá
Ehhez a bejegyzéshez szüksége van a Sárga taxi nyilvános adatkészlet a NYC Taxi & Limousine Commissiontól Iceberg formátumban érhető el. Letöltheti a fájlokat, majd az Athena segítségével konvertálhatja a Parquet adatkészletet Iceberg táblázattá, vagy tekintse meg a Építsen egy Apache Iceberg adattavat az Amazon Athena, az Amazon EMR és az AWS Glue segítségével blogbejegyzést a Jéghegy táblázat létrehozásához.
Ebben a bejegyzésben az Athénét használjuk az adatok konvertálására. Hajtsa végre a következő lépéseket:
- Töltse le a fájlokat az előző hivatkozás segítségével, vagy használja a AWS parancssori interfész (AWS CLI) segítségével másolja át a fájlokat a 3-as és 2020-es nyilvános S2021 tárolóból az S3 tárolóba a következő paranccsal:
További információ: Az Amazon Redshift CLI beállítása.
- Hozzon létre egy adatbázist
Icebergdbés hozzon létre egy táblázatot az Athena használatával, amely a Parquet formátumú fájlokra mutat a következő utasítással: - Érvényesítse a Parquet tábla adatait a következő SQL használatával:

- Hozzon létre egy Iceberg táblát Athénában a következő kóddal. A táblázat típus tulajdonságait Iceberg asztalként láthatja Parquet formátummal és gyors tömörítéssel az alábbiakban
create tablenyilatkozat. Az SQL futtatása előtt frissítenie kell az S3 helyet. Vegye figyelembe azt is, hogy az Iceberg tábla aYearkulcs. - A táblázat létrehozása után töltse be az adatokat az Iceberg táblába a korábban betöltött Parketta tábla segítségével
nyc_taxi_yellow_parqueta következő SQL-lel: - Amikor az SQL utasítás elkészült, ellenőrizze az Iceberg táblában lévő adatokat
nyc_taxi_yellow_iceberg. Ezt a lépést meg kell tenni, mielőtt a következő lépésre lépne. - A következő paranccsal ellenőrizheti, hogy a nyc_taxi_yellow_iceberg tábla Iceberg formátumú-e, és az Év oszlopban particionálva van-e:



Hozzon létre egy külső sémát az Amazon Redshiftben
Ebben a részben bemutatjuk, hogyan hozhat létre külső sémát az Amazon Redshiftben, amely az AWS Glue adatbázisra mutat. icebergdb hogy lekérdezze az Iceberg táblát nyc_taxi_yellow_iceberg amit az előző részben láthattunk az Athena használatával.
Jelentkezzen be a Redshiftbe ezen keresztül Lekérdezésszerkesztő v2 vagy egy SQL-ügyfelet, és futtassa a következő parancsot (vegye figyelembe, hogy az AWS Glue adatbázis icebergdb és régióinformációkat használnak):

Ha többet szeretne megtudni a külső sémák Amazon Redshiftben történő létrehozásáról, tekintse meg a következőt: külső sémát hozzon létre
A külső séma létrehozása után spectrum_iceberg_schema, lekérdezheti az Iceberg táblát az Amazon Redshiftben.
Kérdezze le az Iceberg táblát az Amazon Redshiftben
Futtassa a következő lekérdezést a Lekérdezésszerkesztő v2-ben. Vegye figyelembe, hogy spectrum_iceberg_schema az Amazon Redshiftben létrehozott külső séma neve és nyc_taxi_yellow_iceberg a lekérdezéshez használt AWS Glue adatbázis táblázata:
A következő képernyőképen megjelenő lekérdezési adatok azt mutatják, hogy az Iceberg formátumú AWS ragasztótábla lekérdezhető a Redshift Spectrum használatával.

Tekintse meg az Iceberg tábla lekérdezésének magyarázó tervét
A következő lekérdezéssel kaphatja meg a terv magyarázó kimenetét, amely megmutatja a formátumot ICEBERG:

Érvényesítse a frissítéseket az adatok konzisztenciája érdekében
Miután a frissítés befejeződött az Iceberg táblán, lekérdezheti az Amazon Redshiftet az adatok tranzakciós szempontból egységes nézetének megtekintéséhez. Futtassunk le egy lekérdezést az a kiválasztásával vendorid és egy bizonyos átvételhez:

Ezután frissítse az értékét passenger_count az 4 és trip_distance 9.4-re a vendorid és bizonyos átvételi és leadási dátumok Athénában:

Végül futtassa a következő lekérdezést a Lekérdezésszerkesztő v2-ben a frissített érték megtekintéséhez passenger_count és a trip_distance:
Amint az a következő képernyőképen látható, az Iceberg táblázat frissítési műveletei elérhetők az Amazon Redshiftben.

Hozzon létre egységes nézetet a helyi táblázatról és az előzményadatokról az Amazon Redshiftben
Modern adatarchitektúra-stratégiaként rendszerezheti az előzményadatokat vagy a ritkábban elérhető adatokat az adattóban, és a gyakran elért adatokat a Redshift adattárházban tárolhatja. Ez rugalmasságot biztosít az analitika nagyarányú kezeléséhez és a legköltséghatékonyabb architektúra megoldás megtalálásához.
Ebben a példában 2 év adatait töltjük be egy Redshift táblába; a többi adat az S3 adattóban marad, mert ezt az adatkészletet ritkábban kérdezik le.
- Használja a következő kódot 2 év adatainak betöltéséhez
nyc_taxi_yellow_recenttáblázat az Amazon Redshiftben, forrás az Iceberg táblából:
- Ezután eltávolíthatja az elmúlt 2 év adatait az Iceberg táblából az Athena következő paranccsal, mert az előző lépésben betöltötte az adatokat egy Redshift táblába:

Miután elvégezte ezeket a lépéseket, a Redshift tábla 2 évnyi adattal rendelkezik, a többi adat pedig az Amazon S3 Iceberg táblájában található.
- Hozzon létre egy nézetet a
nyc_taxi_yellow_icebergJéghegy asztal ésnyc_taxi_yellow_recenttáblázat az Amazon Redshiftben: - Most kérdezze le a nézetet, a szűrő feltételeitől függően a Redshift Spectrum vagy az Iceberg-adatokat, a Redshift táblát vagy mindkettőt megvizsgálja. A következő példalekérdezés számos rekordot ad vissza az egyes forrástáblákból mindkét tábla vizsgálatával:

Partíciófejlődés
Iceberg használ rejtett particionálás, ami azt jelenti, hogy nem kell manuálisan partíciókat hozzáadnia az Apache Iceberg táblákhoz. Az Amazon Redshift automatikusan észleli az Apache Iceberg táblákban található új partícióértékeket vagy új partícióspecifikációkat (partícióoszlopok hozzáadása vagy eltávolítása), és nincs szükség kézi műveletre a partíciók frissítéséhez a tábladefinícióban. A következő példa ezt mutatja be.
Példánkban, ha az Iceberg tábla nyc_taxi_yellow_iceberg eredetileg évszámra, majd később az oszlopra tagolták vendorid egy további partícióoszlopként került hozzáadásra, akkor az Amazon Redshift zökkenőmentesen lekérdezheti az Iceberg táblát nyc_taxi_yellow_iceberg két különböző partíciós sémával egy idő alatt.

Megfontolások az Iceberg táblák lekérdezésekor az Amazon Redshift használatával
Az előnézeti időszakban vegye figyelembe a következőket, amikor az Amazon Redshiftet Iceberg táblákkal használja:
- Csak az AWS ragasztóadat-katalógusban meghatározott Iceberg táblák támogatottak.
- A CREATE vagy ALTER külső tábla parancsok nem támogatottak, ami azt jelenti, hogy az Iceberg táblának már léteznie kell egy AWS Glue adatbázisban.
- Az időutazási lekérdezések nem támogatottak.
- Az Iceberg 1. és 2. verziója támogatott. Az Iceberg formátumú verziókkal kapcsolatos további részletekért lásd: Formátum verziószámítás.
- Az Iceberg táblákkal támogatott adattípusok listáját lásd: Támogatott adattípusok Apache Iceberg táblákkal (előnézet).
- Az Iceberg tábla lekérdezésének ára ugyanaz, mint az Amazon Redshift segítségével bármely más adatformátum elérése.
Az Iceberg formátumú táblázatok előnézetével kapcsolatos további részletekért lásd: Apache Iceberg táblák használata Amazon Redshifttel (előnézet).
Vásárlói visszajelzés
„A Tinuiti, a legnagyobb független teljesítménymarketing-cég napi rendszerességgel nagy mennyiségű adatot kezel, és robusztus Data Lake- és adattárház-stratégiával kell rendelkeznie, hogy piaci intelligencia-csoportjaink minden ügyféladatunkat könnyen, megfizethető és biztonságosan tárolhassák és elemezzék. , és robusztus módon” – mondja Justin Manus, a Tinuiti technológiai igazgatója. „Az Amazon Redshift támogatása az Apache Iceberg táblákhoz az adattavunkban, amely az igazság egyetlen forrása, megválaszol egy kritikus kihívást a teljesítmény és a hozzáférhetőség optimalizálása terén, és tovább egyszerűsíti adatintegrációs folyamatainkat, hogy hozzáférjen a különböző forrásokból bevitt összes adathoz, és energiát biztosítson az ügyfelek márkapotenciálját.”
Következtetés
Ebben a bejegyzésben példát mutattunk be egy Iceberg-tábla lekérdezésére a Redshiftben az Amazon S3-ban tárolt fájlokkal, amelyeket táblázatként katalogizáltunk az AWS Glue Data Catalog-ban, és bemutattunk néhány kulcsfontosságú funkciót, mint például a hatékony sorszintű frissítés és törlés, és a séma evolúciós élménye a felhasználók számára, hogy az Athena segítségével felszabadítsák a big data hatalmát.
Az Amazon Redshift segítségével lekérdezéseket futtathat Data Lake táblákon különféle fájlokban és táblázatformátumokban, mint pl. Apache Hudi és a Delta-tó, és most ezzel Apache Iceberg (előzetes), amely további lehetőségeket kínál a modern adatarchitektúra igényeihez.
Reméljük, hogy ez remek kiindulópontot ad az Iceberg-táblázatok lekérdezéséhez az Amazon Redshiftben.
A szerzőkről
 Rohit Bansal az AWS analitikai megoldások specialistája. Az Amazon Redshiftre specializálódott, és az ügyfelekkel együttműködve új generációs elemzési megoldásokat hoz létre más AWS Analytics-szolgáltatások felhasználásával.
Rohit Bansal az AWS analitikai megoldások specialistája. Az Amazon Redshiftre specializálódott, és az ügyfelekkel együttműködve új generációs elemzési megoldásokat hoz létre más AWS Analytics-szolgáltatások felhasználásával.
 Satish Sathiya az Amazon Redshift vezető termékmérnöke. Ő egy lelkes big data rajongó, aki világszerte együttműködik ügyfeleivel, hogy sikereket érjen el, és megfeleljen az adattárházzal és a Data Lake architektúrával kapcsolatos igényeiknek.
Satish Sathiya az Amazon Redshift vezető termékmérnöke. Ő egy lelkes big data rajongó, aki világszerte együttműködik ügyfeleivel, hogy sikereket érjen el, és megfeleljen az adattárházzal és a Data Lake architektúrával kapcsolatos igényeiknek.
 Ranjan Burman az AWS analitikai megoldások specialistája. Az Amazon Redshiftre specializálódott, és segít ügyfeleinek skálázható elemzési megoldások kidolgozásában. Több mint 16 éves tapasztalattal rendelkezik különböző adatbázis- és adattárolási technológiák terén. Szenvedélye az automatizálás és az ügyfelek problémáinak felhőmegoldásokkal történő megoldása.
Ranjan Burman az AWS analitikai megoldások specialistája. Az Amazon Redshiftre specializálódott, és segít ügyfeleinek skálázható elemzési megoldások kidolgozásában. Több mint 16 éves tapasztalattal rendelkezik különböző adatbázis- és adattárolási technológiák terén. Szenvedélye az automatizálás és az ügyfelek problémáinak felhőmegoldásokkal történő megoldása.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Autóipar / elektromos járművek, Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- ChartPrime. Emelje fel kereskedési játékát a ChartPrime segítségével. Hozzáférés itt.
- BlockOffsets. A környezetvédelmi ellentételezési tulajdon korszerűsítése. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Rólunk
- hozzáférés
- igénybe vett
- megközelíthetőség
- Hozzáférés
- Elérése
- át
- hozzá
- hozzáadott
- További
- címek
- megfizethető
- Minden termék
- lehetővé teszi, hogy
- már
- Is
- amazon
- Amazon Athéné
- Amazon EMR
- Az Amazon Web Services
- Összegek
- an
- Analitikus
- Analitikai
- analitika
- elemez
- és a
- bármilyen
- Apache
- építészet
- VANNAK
- körül
- Sor
- AS
- At
- automatikusan
- automatizálás
- elérhető
- AWS
- AWS ragasztó
- alap
- mert
- előtt
- hogy
- Nagy
- Big adatok
- kötés
- Blog
- mindkét
- márka
- épít
- üzleti
- üzleti intelligencia
- by
- TUD
- képességek
- képesség
- katalógus
- központi
- bizonyos
- kihívás
- változik
- fő
- Főmérnöke
- vásárló
- felhő
- kód
- gyűjtemény
- Oszlop
- Oszlopok
- teljes
- bonyolult
- Körülmények
- Fontolja
- megfontolások
- következetes
- tartalmaz
- megtérít
- összehangolt
- költséghatékony
- teremt
- készítette
- létrehozása
- kritikai
- vevő
- ügyféladatok
- Ügyfelek
- napi
- dátum
- adatintegráció
- adattó
- adattárház
- adatbázis
- adatkészletek
- Időpontok
- alapértelmezett
- meghatározott
- definíció
- definíciók
- Delta
- bizonyítani
- igazolták
- mutatja
- attól
- Design
- részletek
- észlelt
- Dev
- különböző
- közvetlenül
- ne
- kétszeresére
- letöltés
- minden
- könnyen
- könnyű
- szerkesztő
- hatékony
- bármelyik
- megszüntetése
- lehetővé teszi
- Motor
- mérnök
- rajongó
- belépés
- Eter (ETH)
- evolúció
- példa
- létezik
- létező
- tapasztalat
- Magyarázza
- feltárása
- nyúlik
- külső
- külön-
- GYORS
- Jellemzők
- filé
- Fájlok
- szűrő
- Találjon
- Cég
- vezetéknév
- Rugalmasság
- következő
- A
- formátum
- gyakran
- ból ből
- teljesen
- további
- kap
- ad
- földgolyó
- Goes
- nagy
- Csoport
- Fogantyúk
- Legyen
- he
- segít
- történeti
- remény
- Hogyan
- How To
- HTML
- http
- HTTPS
- if
- in
- független
- információ
- integráció
- Intelligencia
- bele
- IT
- ITS
- csatlakozik
- jpg
- json
- Justin
- Tart
- Kulcs
- tó
- nagy
- legnagyobb
- keresztnév
- a későbbiekben
- legutolsó
- TANUL
- kevesebb
- mint
- LIMIT
- vonal
- LINK
- Lista
- kiszámításának
- helyi
- elhelyezkedés
- fenntartása
- KÉSZÍT
- Gyártás
- kezelése
- sikerült
- kezeli
- mód
- kézikönyv
- kézzel
- térkép
- piacára
- Marketing
- eszközök
- Találkozik
- Metaadatok
- modern
- több
- a legtöbb
- mozog
- mozgó
- kell
- név
- bennszülött
- Szükség
- szükséges
- igények
- Új
- következő
- következő generációs
- nem
- megjegyezni
- Most
- szám
- NYC
- of
- Tiszt
- on
- nyitva
- működés
- Művelet
- Optimalizálja
- optimalizált
- optimalizálása
- Opciók
- or
- eredetileg
- Más
- mi
- teljesítmény
- felett
- oldal
- szenvedélyes
- teljesít
- teljesítmény
- időszak
- terv
- tervek
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- állás
- potenciális
- hatalom
- előfeltételek
- Preview
- előző
- korábban
- problémák
- folyamat
- Termékek
- ingatlanait
- biztosít
- nyilvános
- lekérdezések
- Olvasás
- nyilvántartások
- csökkenteni
- vidék
- eltávolítása
- cserélni
- kötelező
- REST
- Visszatér
- erős
- futás
- futás
- azonos
- látta
- azt mondja,
- skálázható
- Skála
- beolvasás
- letapogatás
- vizsgál
- rendszerek
- zökkenőmentes
- zökkenőmentesen
- Rész
- biztonság
- lát
- idősebb
- vagy szerver
- Szolgáltatások
- készlet
- kellene
- előadás
- kimutatta,
- mutatott
- Műsorok
- Egyszerű
- egyetlen
- megoldások
- Megoldások
- Megoldása
- néhány
- forrás
- Források
- Sourcing
- szakember
- specializálódott
- leírás
- szemüveg
- Spektrum
- SQL
- standard
- Kezdve
- nyilatkozat
- statisztika
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- árnyékolók
- Stratégia
- Húr
- siker
- ilyen
- támogatás
- Támogatott
- Támogatja
- táblázat
- csapat
- Technologies
- Technológia
- tíz
- mint
- hogy
- A
- The Source
- azok
- akkor
- Ezek
- ezt
- ezer
- Keresztül
- idő
- időutazás
- időbélyeg
- nak nek
- Ma
- szerszámok
- ügyleti
- utazás
- igazság
- kettő
- típus
- típusok
- egységes
- unió
- kinyit
- Frissítések
- frissítve
- Frissítés
- Használat
- használ
- használt
- Felhasználók
- használ
- segítségével
- ÉRVÉNYESÍT
- érték
- Értékek
- fajta
- különféle
- nagyon
- keresztül
- Megnézem
- kötetek
- Raktár
- Raktározás
- volt
- Út..
- we
- háló
- webes szolgáltatások
- amikor
- ami
- WHO
- széles
- széles körben
- lesz
- val vel
- művek
- év
- év
- te
- A te
- zephyrnet