Mit der Einführung der neuronalen Suchfunktion für Amazon OpenSearch-Dienst In OpenSearch 2.9 ist die Integration in KI/ML-Modelle jetzt mühelos möglich, um die semantische Suche und andere Anwendungsfälle zu unterstützen. OpenSearch Service unterstützt seit der Einführung seiner k-Nearest Neighbor (k-NN)-Funktion im Jahr 2020 sowohl die lexikalische als auch die Vektorsuche; Allerdings erforderte die Konfiguration der semantischen Suche den Aufbau eines Frameworks zur Integration von Modellen des maschinellen Lernens (ML) zur Aufnahme und Suche. Die neuronale Suchfunktion erleichtert die Text-in-Vektor-Transformation während der Aufnahme und Suche. Wenn Sie während der Suche eine neuronale Abfrage verwenden, wird die Abfrage in eine Vektoreinbettung übersetzt und k-NN wird verwendet, um die nächstgelegenen Vektoreinbettungen aus dem Korpus zurückzugeben.
Um die neuronale Suche nutzen zu können, müssen Sie ein ML-Modell einrichten. Wir empfehlen die Konfiguration von AI/ML-Konnektoren für AWS AI- und ML-Dienste (z. B Amazon Sage Maker or Amazonas Grundgestein) oder Alternativen von Drittanbietern. Ab Version 2.9 des OpenSearch Service werden AI/ML-Konnektoren in die neuronale Suche integriert, um die Übersetzung Ihres Datenkorpus und Ihrer Abfragen in Vektoreinbettungen zu vereinfachen und zu operationalisieren, wodurch ein Großteil der Komplexität der Vektorhydratisierung und -suche beseitigt wird.
In diesem Beitrag zeigen wir, wie man AI/ML-Konnektoren zu externen Modellen über die OpenSearch Service-Konsole konfiguriert.
Die Lösung im Überblick
Dieser Beitrag führt Sie insbesondere durch die Verbindung zu einem Modell in SageMaker. Anschließend führen wir Sie durch die Verwendung des Connectors zum Konfigurieren der semantischen Suche im OpenSearch Service als Beispiel für einen Anwendungsfall, der durch die Verbindung mit einem ML-Modell unterstützt wird. Amazon Bedrock- und SageMaker-Integrationen werden derzeit auf der Benutzeroberfläche der OpenSearch Service-Konsole unterstützt, und die Liste der von der Benutzeroberfläche unterstützten Integrationen von Erst- und Drittanbietern wird weiter wachsen.
Für alle Modelle, die nicht über die Benutzeroberfläche unterstützt werden, können Sie sie stattdessen mithilfe der verfügbaren APIs und des einrichten ML-Blaupausen. Weitere Informationen finden Sie unter Einführung in OpenSearch-Modelle. Blaupausen für jeden Anschluss finden Sie im ML Commons GitHub-Repository.
Voraussetzungen:
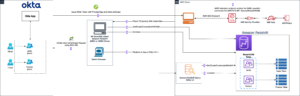
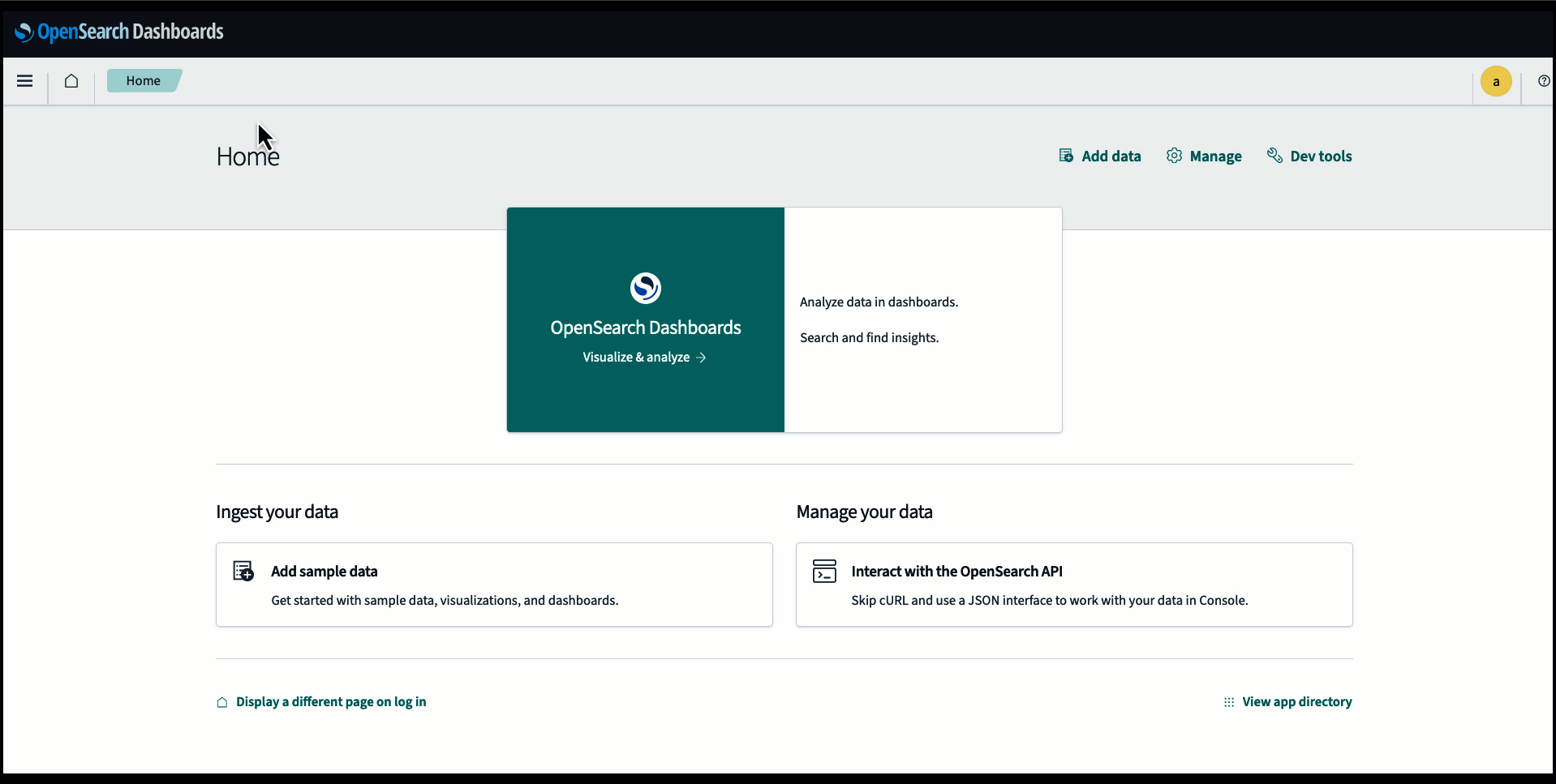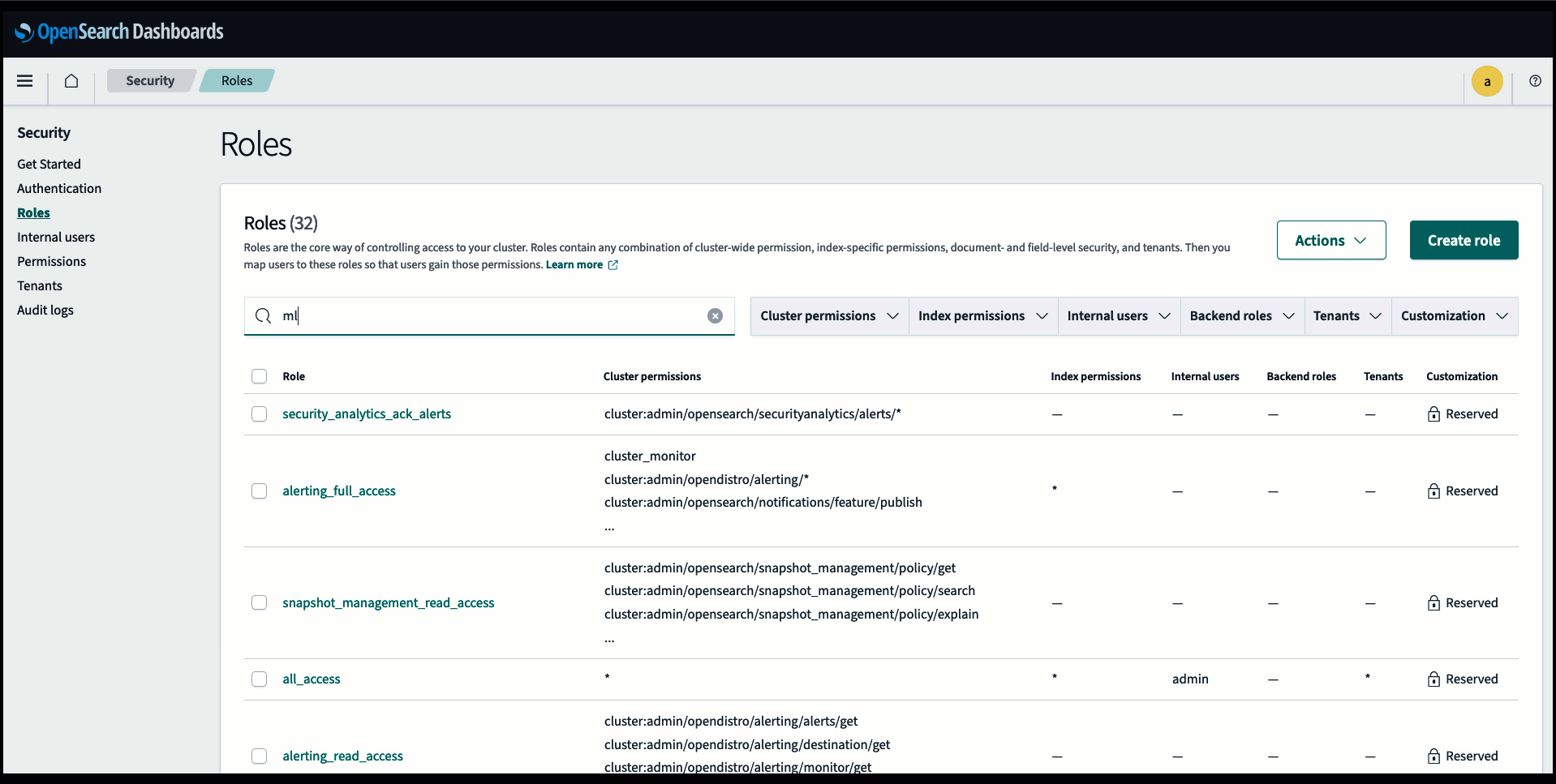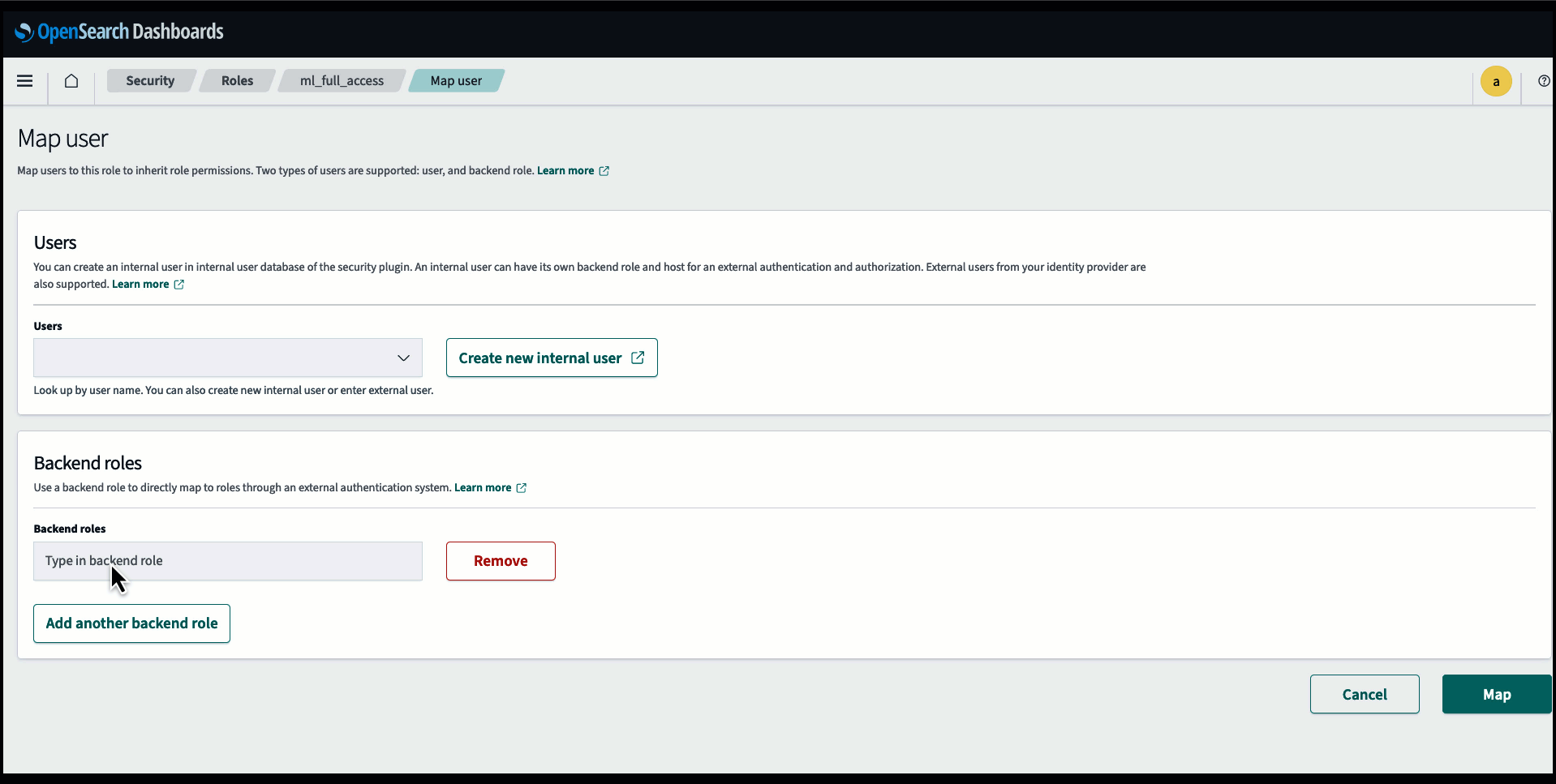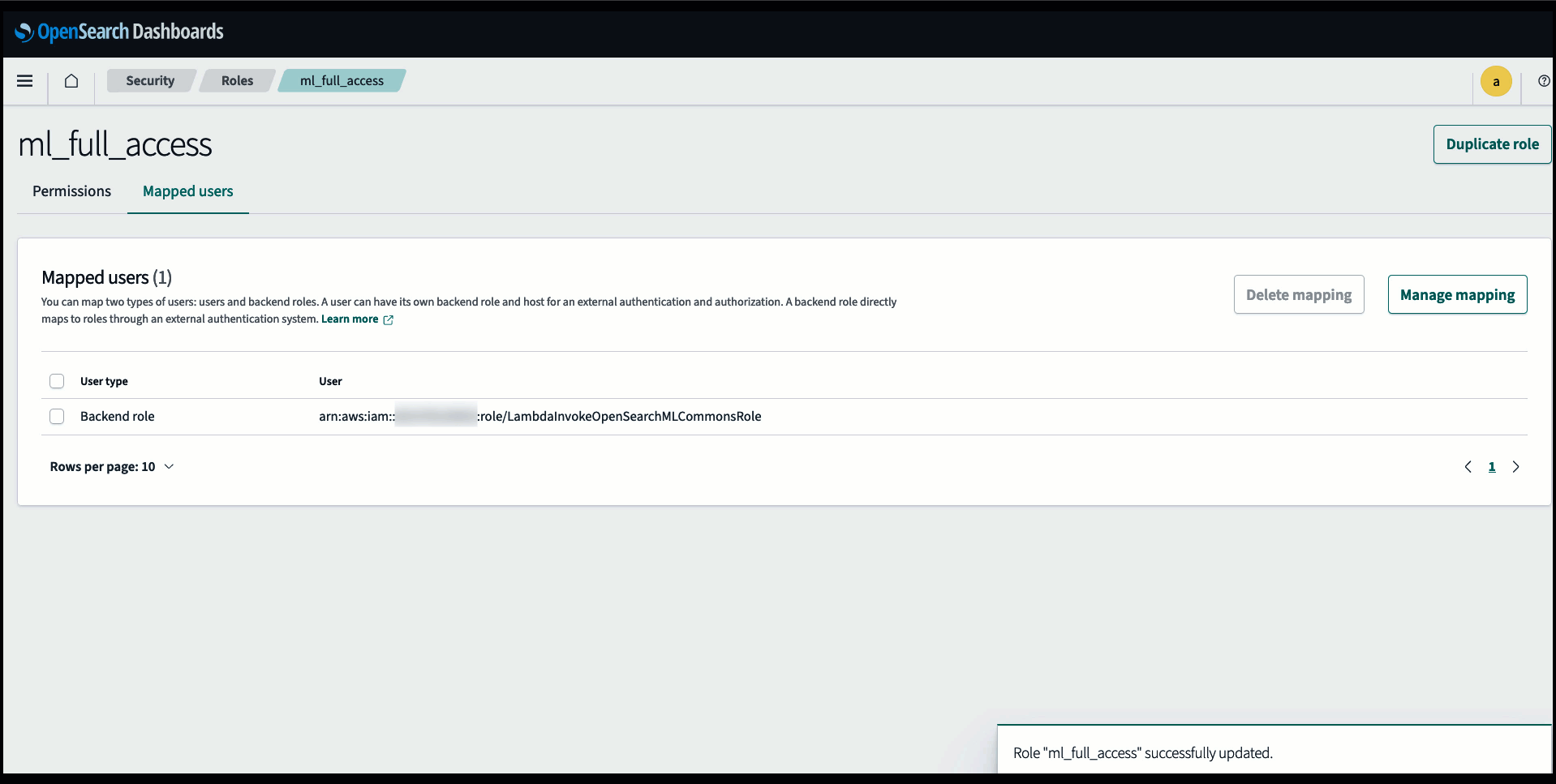
Bevor Sie das Modell über die OpenSearch Service-Konsole verbinden, erstellen Sie eine OpenSearch Service-Domäne. Karte an AWS Identity and Access Management and (IAM)-Rolle mit Namen LambdaInvokeOpenSearchMLCommonsRole als Backend-Rolle auf dem ml_full_access Rolle mithilfe des Sicherheits-Plugins in OpenSearch-Dashboards, wie im folgenden Video gezeigt. Der OpenSearch Service-Integrationsworkflow ist für die Verwendung von vorab ausgefüllt LambdaInvokeOpenSearchMLCommonsRole IAM-Rolle standardmäßig zum Erstellen des Connectors zwischen der OpenSearch Service-Domäne und dem auf SageMaker bereitgestellten Modell. Wenn Sie eine benutzerdefinierte IAM-Rolle für die OpenSearch Service-Konsolenintegrationen verwenden, stellen Sie sicher, dass die benutzerdefinierte Rolle als Backend-Rolle zugeordnet ist ml_full_access Berechtigungen vor der Bereitstellung der Vorlage.
Stellen Sie das Modell mit AWS CloudFormation bereit
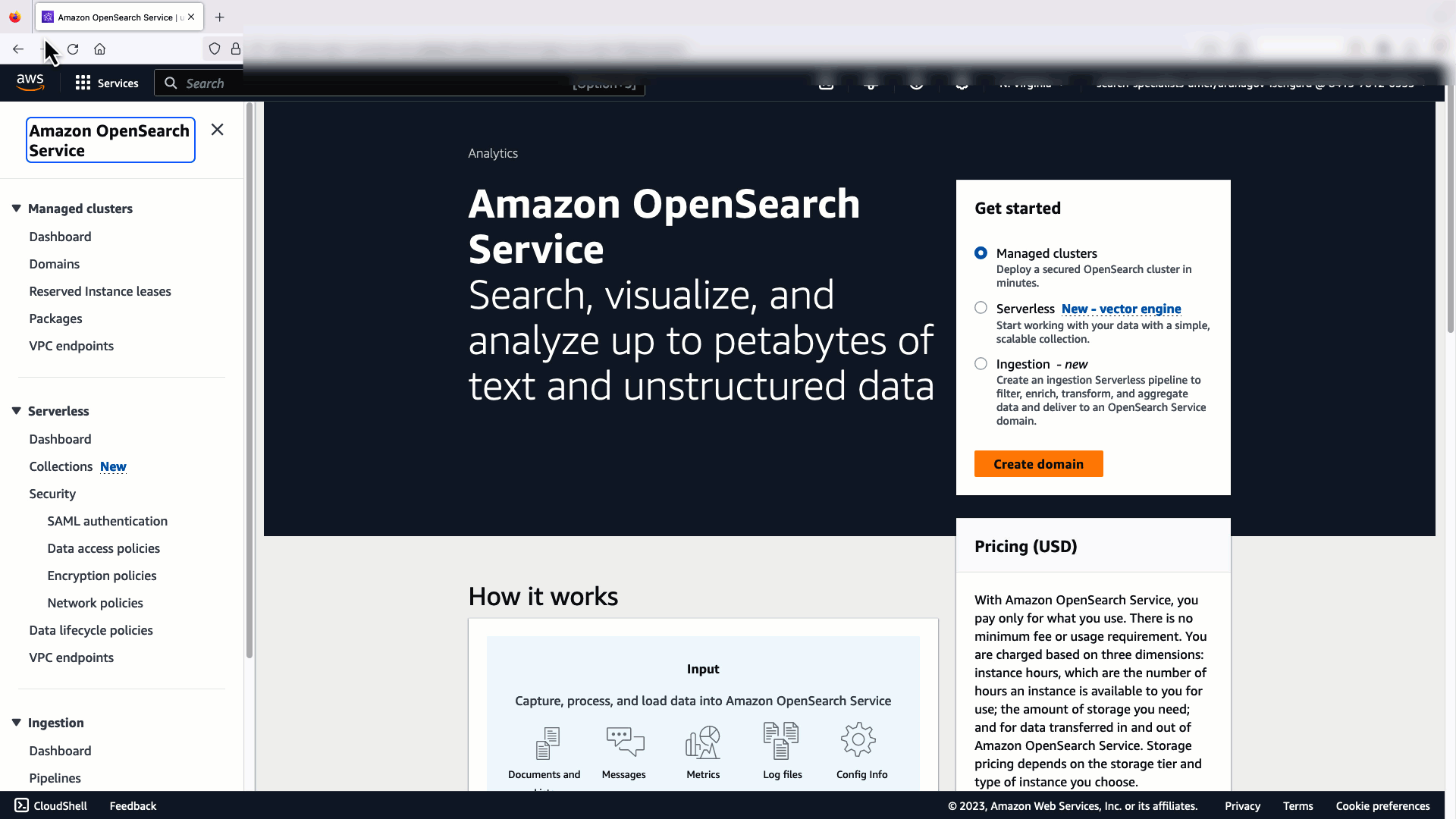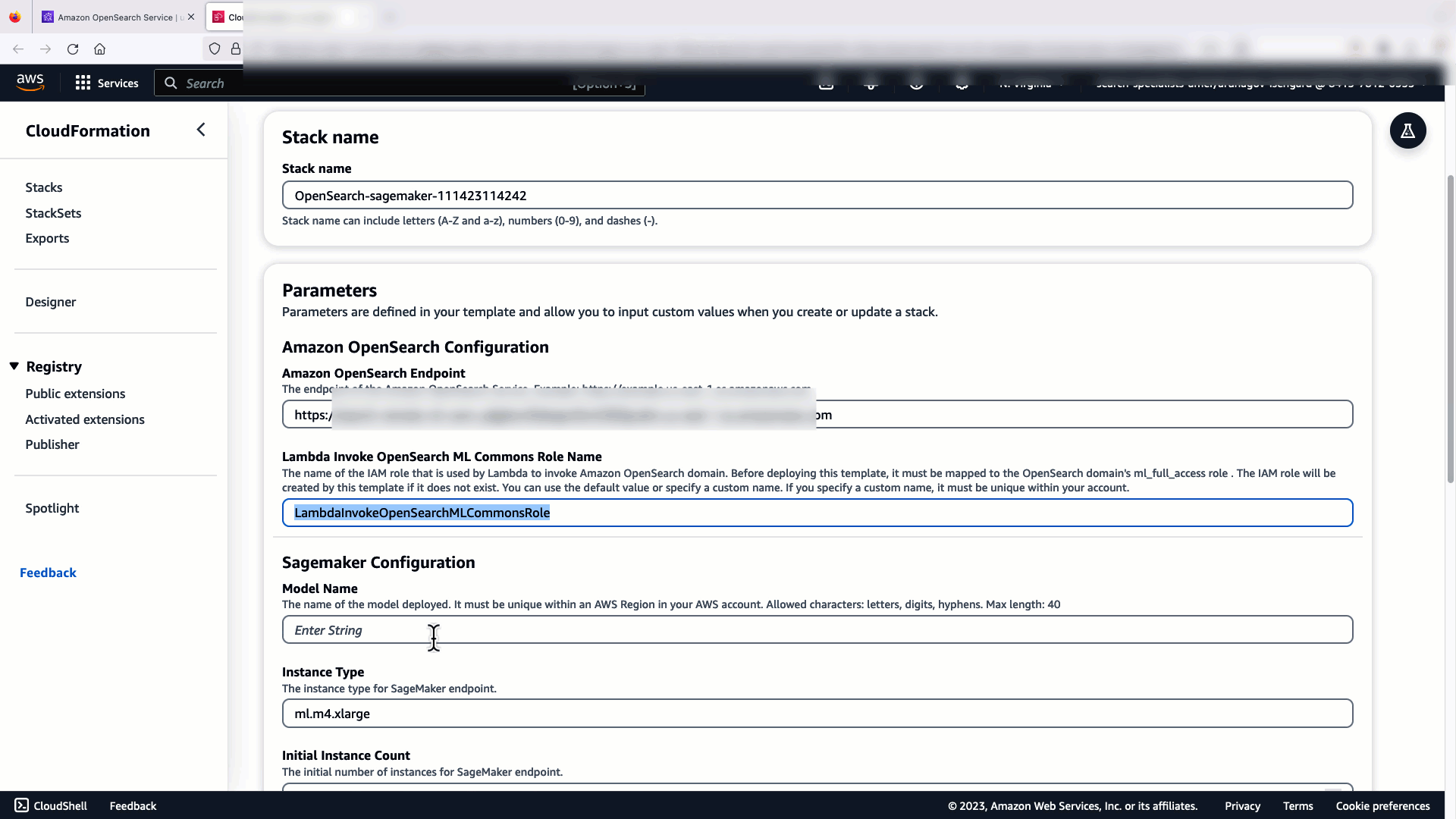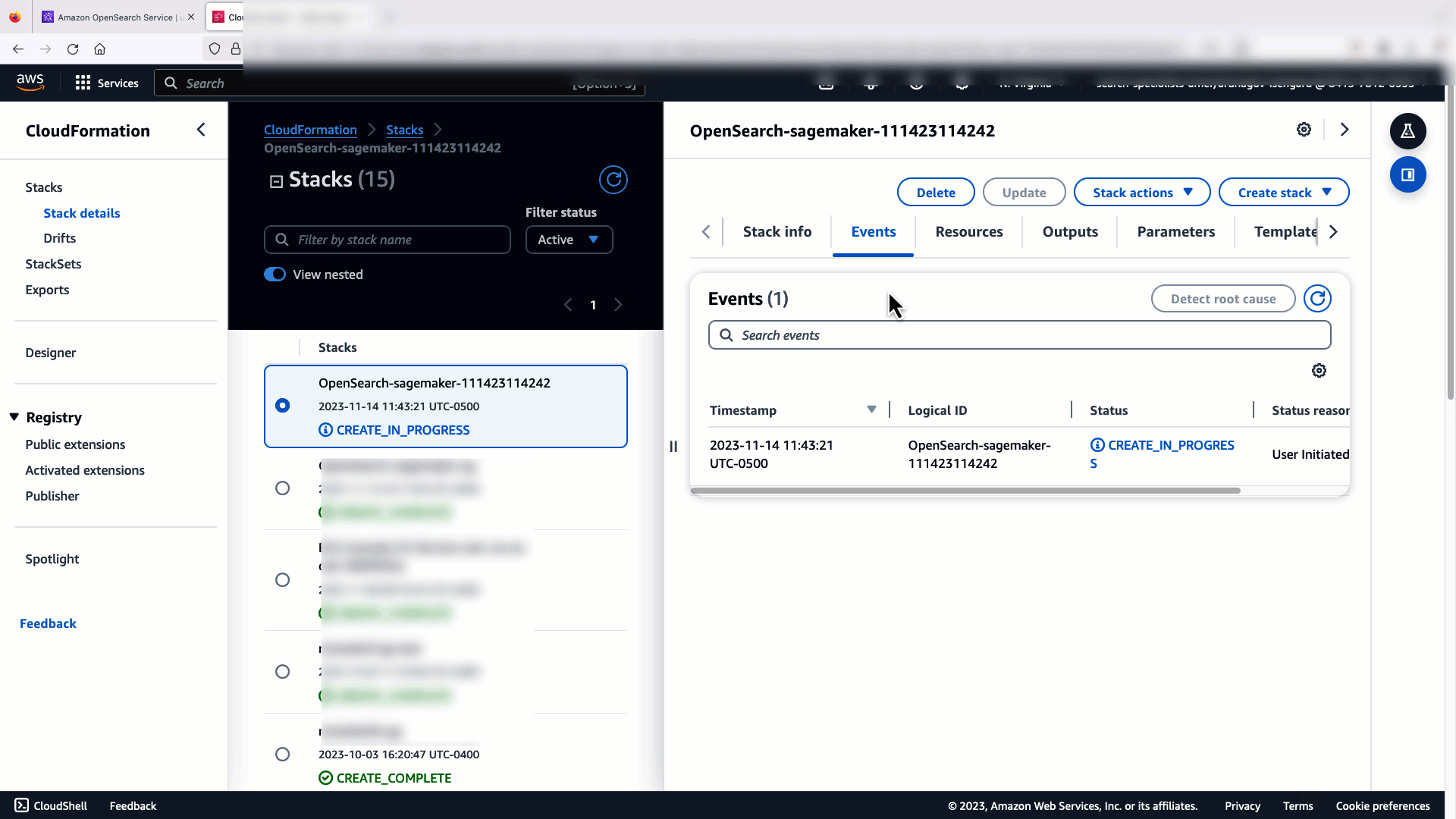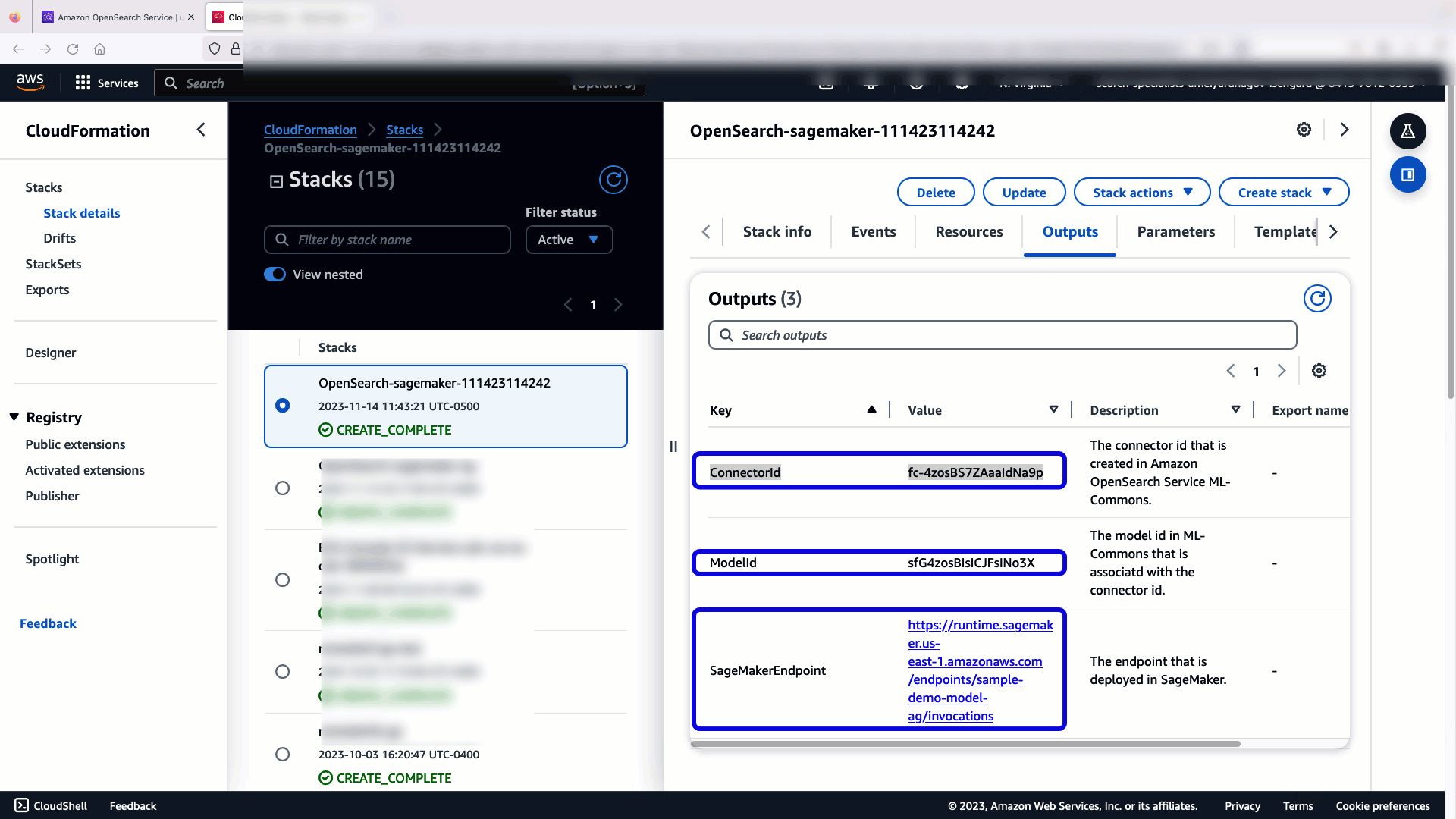
Das folgende Video zeigt die Schritte zur Verwendung der OpenSearch Service-Konsole, um innerhalb weniger Minuten ein Modell auf Amazon SageMaker bereitzustellen und die Modell-ID über die AI-Konnektoren zu generieren. Der erste Schritt ist die Auswahl Integration im Navigationsbereich der OpenSearch Service AWS-Konsole, der zu einer Liste der verfügbaren Integrationen weiterleitet. Die Integration wird über eine Benutzeroberfläche eingerichtet, die Sie zu den erforderlichen Eingaben auffordert.
Um die Integration einzurichten, müssen Sie lediglich den OpenSearch Service-Domänenendpunkt und einen Modellnamen angeben, um die Modellverbindung eindeutig zu identifizieren. Standardmäßig stellt die Vorlage das Hugging Face-Satztransformermodell bereit. djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Wenn Sie wählen Stapel erstellen, Sie werden zum weitergeleitet AWS CloudFormation Konsole. Die CloudFormation-Vorlage stellt die im folgenden Diagramm beschriebene Architektur bereit.

Der CloudFormation-Stack erstellt eine AWS Lambda Anwendung, die ein Modell bereitstellt Amazon Simple Storage-Service (Amazon S3), erstellt den Connector und generiert die Modell-ID in der Ausgabe. Mit dieser Modell-ID können Sie dann einen semantischen Index erstellen.
Wenn das standardmäßige All-MiniLM-L6-v2-Modell Ihren Zweck nicht erfüllt, können Sie ein beliebiges Texteinbettungsmodell Ihrer Wahl auf dem ausgewählten Modellhost (SageMaker oder Amazon Bedrock) bereitstellen, indem Sie Ihre Modellartefakte als zugängliches S3-Objekt bereitstellen. Alternativ können Sie eine der folgenden Optionen auswählen vorab trainierte Sprachmodelle und stellen Sie es in SageMaker bereit. Anweisungen zum Einrichten Ihres Endpunkts und Ihrer Modelle finden Sie unter Verfügbare Amazon SageMaker-Images.
SageMaker ist ein vollständig verwalteter Dienst, der eine breite Palette von Tools vereint, um leistungsstarkes, kostengünstiges ML für jeden Anwendungsfall zu ermöglichen und wichtige Vorteile wie Modellüberwachung, serverloses Hosting und Workflow-Automatisierung für kontinuierliche Schulung und Bereitstellung bietet. Mit SageMaker können Sie den Lebenszyklus von Texteinbettungsmodellen hosten und verwalten und diese zur Unterstützung semantischer Suchanfragen im OpenSearch Service verwenden. Wenn eine Verbindung besteht, hostet SageMaker Ihre Modelle und OpenSearch Service wird für Abfragen basierend auf Inferenzergebnissen von SageMaker verwendet.
Sehen Sie sich das bereitgestellte Modell über OpenSearch Dashboards an
Um zu überprüfen, ob die CloudFormation-Vorlage das Modell erfolgreich in der OpenSearch-Service-Domäne bereitgestellt hat, und um die Modell-ID zu erhalten, können Sie die ML Commons REST GET API über die OpenSearch Dashboards Dev Tools verwenden.
Die GET _plugins REST API bietet jetzt zusätzliche APIs, um auch den Modellstatus anzuzeigen. Mit dem folgenden Befehl können Sie den Status eines Remote-Modells anzeigen:
Wie im folgenden Screenshot gezeigt, a DEPLOYED Der Status in der Antwort gibt an, dass das Modell erfolgreich im OpenSearch Service-Cluster bereitgestellt wurde.

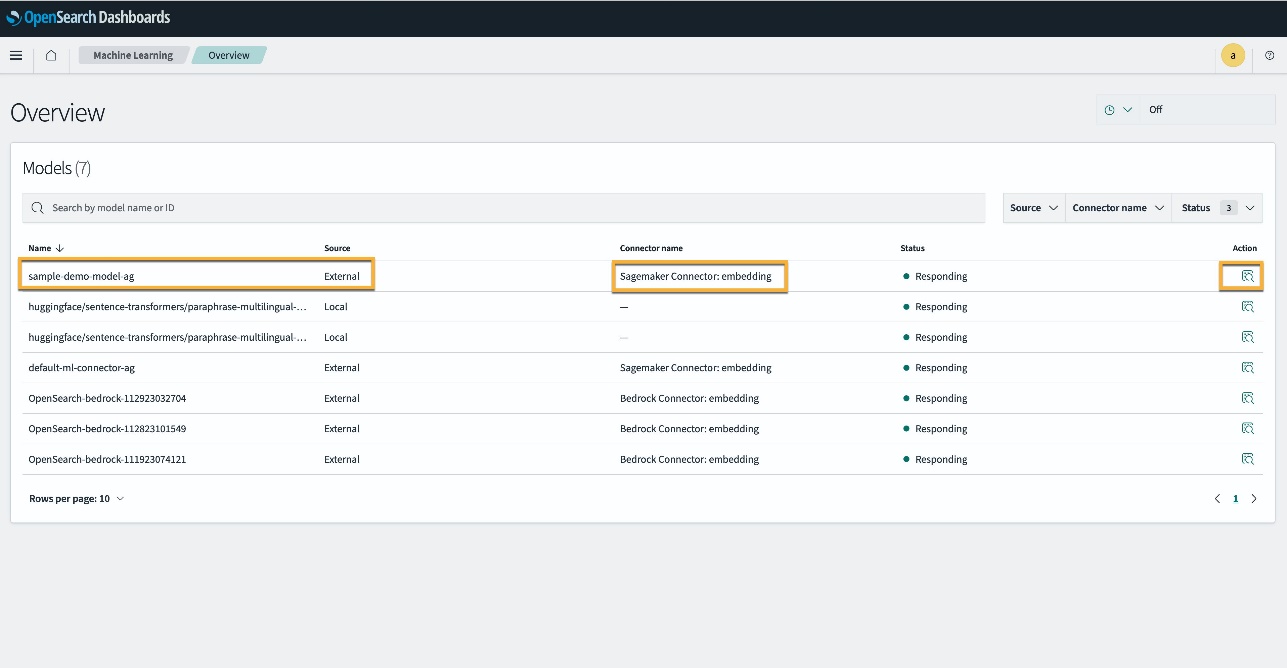
Alternativ können Sie das auf Ihrer OpenSearch Service-Domäne bereitgestellte Modell mithilfe von anzeigen Maschinelles lernen Seite von OpenSearch Dashboards.

Auf dieser Seite werden die Modellinformationen und der Status aller bereitgestellten Modelle aufgelistet.

Erstellen Sie die neuronale Pipeline mithilfe der Modell-ID
Wenn der Status des Modells entweder angezeigt wird DEPLOYED in Dev Tools oder grün und Als Reaktion In OpenSearch-Dashboards können Sie die Modell-ID zum Aufbau Ihrer neuronalen Aufnahmepipeline verwenden. Die folgende Aufnahmepipeline wird in den OpenSearch Dashboards Dev Tools Ihrer Domain ausgeführt. Stellen Sie sicher, dass Sie die Modell-ID durch die eindeutige ID ersetzen, die für das in Ihrer Domain bereitgestellte Modell generiert wurde.

Erstellen Sie den semantischen Suchindex mit der neuronalen Pipeline als Standardpipeline
Sie können jetzt Ihre Indexzuordnung mit der Standardpipeline definieren, die für die Verwendung der neuen neuronalen Pipeline konfiguriert ist, die Sie im vorherigen Schritt erstellt haben. Stellen Sie sicher, dass die Vektorfelder als deklariert sind knn_vector und die Abmessungen sind für das Modell geeignet, das auf SageMaker bereitgestellt wird. Wenn Sie die Standardkonfiguration zum Bereitstellen des reinen MiniLM-L6-v2-Modells auf SageMaker beibehalten haben, behalten Sie die folgenden Einstellungen bei und führen Sie den Befehl in Dev Tools aus.

Nehmen Sie Beispieldokumente auf, um Vektoren zu generieren
Für diese Demo können Sie das aufnehmen Beispiel-Demostore-Produktkatalog für den Einzelhandel zu den neuen semantic_demostore Index. Ersetzen Sie den Benutzernamen, das Passwort und den Domänenendpunkt durch Ihre Domäneninformationen und erfassen Sie Rohdaten in OpenSearch Service:

Validieren Sie den neuen semantic_demostore-Index
Nachdem Sie Ihren Datensatz nun in die OpenSearch Service-Domäne aufgenommen haben, überprüfen Sie mithilfe einer einfachen Suche, ob die erforderlichen Vektoren generiert werden, um alle Felder abzurufen. Überprüfen Sie, ob die Felder als definiert sind knn_vectors die erforderlichen Vektoren haben.

Vergleichen Sie die lexikalische Suche und die semantische Suche mithilfe der neuronalen Suche mithilfe des Tools „Suchergebnisse vergleichen“.
Das Tool „Suchergebnisse vergleichen“. auf OpenSearch Dashboards ist für Produktions-Workloads verfügbar. Sie können zu navigieren Suchergebnisse vergleichen Seite und vergleichen Sie Abfrageergebnisse zwischen lexikalischer Suche und neuronaler Suche, die für die Verwendung der zuvor generierten Modell-ID konfiguriert sind.

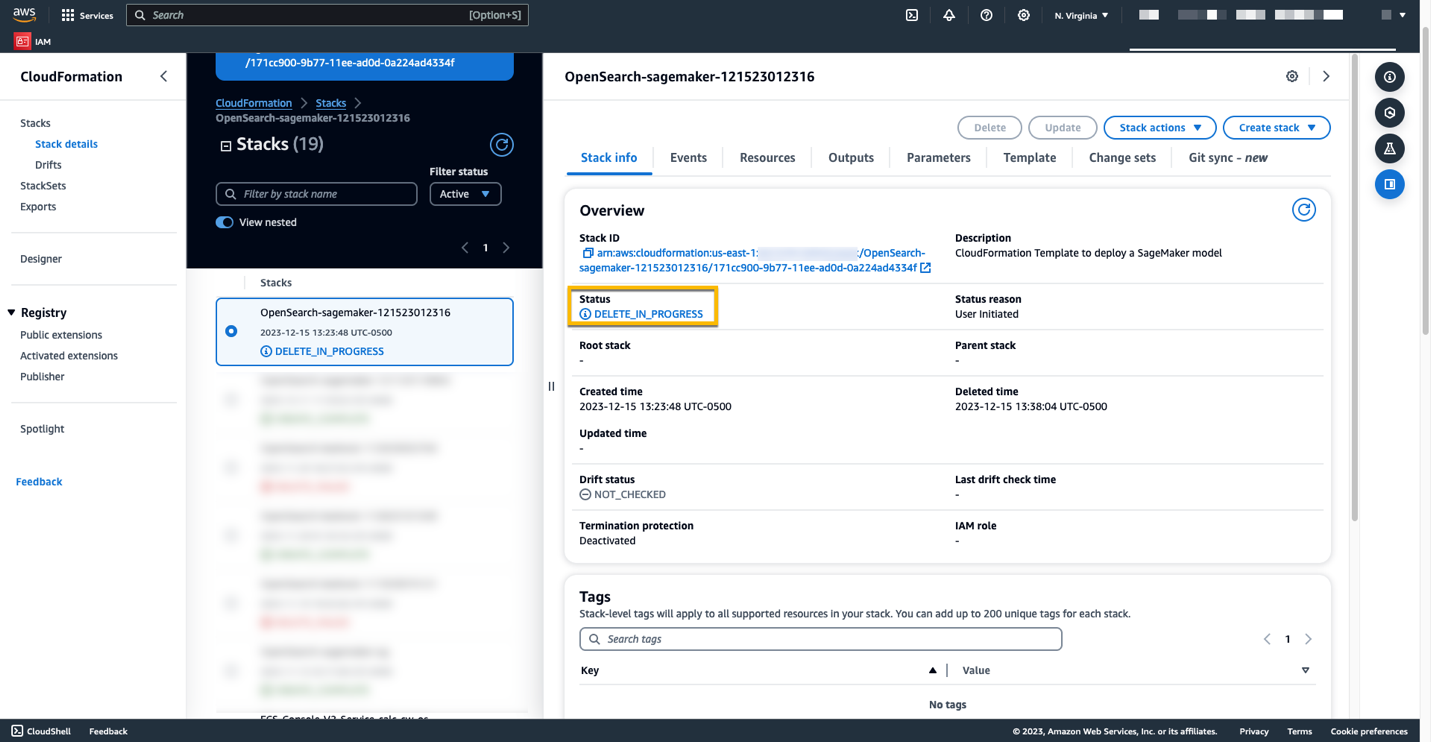
Aufräumen
Sie können die von Ihnen erstellten Ressourcen gemäß den Anweisungen in diesem Beitrag löschen, indem Sie den CloudFormation-Stack löschen. Dadurch werden die Lambda-Ressourcen und der S3-Bucket gelöscht, die das in SageMaker bereitgestellte Modell enthalten. Führen Sie die folgenden Schritte aus:
- Navigieren Sie in der AWS CloudFormation-Konsole zu Ihrer Stack-Detailseite.
- Auswählen Löschen.

- Auswählen Löschen zu bestätigen.

Sie können den Fortschritt des Stapellöschens in der AWS CloudFormation-Konsole überwachen.
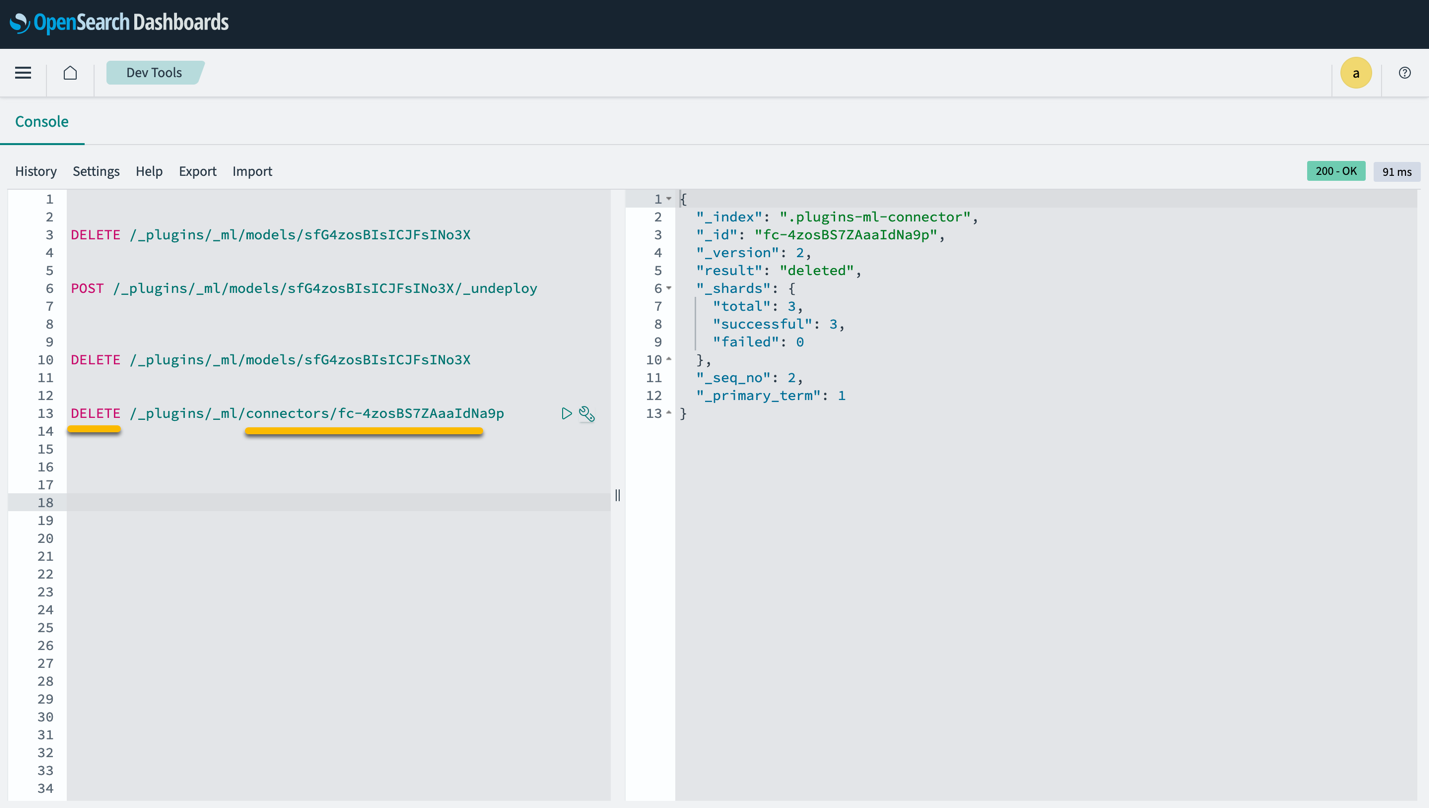
Beachten Sie, dass durch das Löschen des CloudFormation-Stacks nicht das auf der SageMaker-Domäne bereitgestellte Modell und der erstellte AI/ML-Connector gelöscht werden. Dies liegt daran, dass diese Modelle und der Connector mehreren Indizes innerhalb der Domäne zugeordnet werden können. Um ein Modell und den zugehörigen Connector gezielt zu löschen, verwenden Sie die Modell-APIs, wie in den folgenden Screenshots gezeigt.
Erstens undeploy das Modell aus dem OpenSearch Service-Domänenspeicher:

Anschließend können Sie das Modell aus dem Modellindex löschen:

Löschen Sie abschließend den Connector aus dem Connector-Index:
Zusammenfassung
In diesem Beitrag haben Sie erfahren, wie Sie ein Modell in SageMaker bereitstellen, den AI/ML-Connector mithilfe der OpenSearch Service-Konsole erstellen und den neuronalen Suchindex erstellen. Die Möglichkeit, AI/ML-Konnektoren im OpenSearch Service zu konfigurieren, vereinfacht den Vektorhydratationsprozess, indem die Integrationen in externe Modelle nativ erfolgen. Mithilfe der neuronalen Aufnahmepipeline und der neuronalen Suche, die die Modell-ID verwenden, um die Vektoreinbettung im laufenden Betrieb während der Aufnahme und Suche zu generieren, können Sie in wenigen Minuten einen neuronalen Suchindex erstellen.
Weitere Informationen zu diesen AI/ML-Konnektoren finden Sie unter Amazon OpenSearch Service AI-Konnektoren für AWS-Dienste, AWS CloudFormation-Vorlagenintegrationen für die semantische Suche und Erstellen von Konnektoren für ML-Plattformen von Drittanbietern.
Über die Autoren
 Aruna Govindaraju ist ein Amazon OpenSearch Specialist Solutions Architect und hat mit vielen kommerziellen und Open-Source-Suchmaschinen zusammengearbeitet. Ihre Leidenschaft gilt der Suche, Relevanz und Benutzererfahrung. Ihre Expertise in der Korrelation von Endbenutzersignalen mit dem Suchmaschinenverhalten hat vielen Kunden dabei geholfen, ihr Sucherlebnis zu verbessern.
Aruna Govindaraju ist ein Amazon OpenSearch Specialist Solutions Architect und hat mit vielen kommerziellen und Open-Source-Suchmaschinen zusammengearbeitet. Ihre Leidenschaft gilt der Suche, Relevanz und Benutzererfahrung. Ihre Expertise in der Korrelation von Endbenutzersignalen mit dem Suchmaschinenverhalten hat vielen Kunden dabei geholfen, ihr Sucherlebnis zu verbessern.
 Dagney Braun ist Hauptproduktmanager bei AWS mit Schwerpunkt auf OpenSearch.
Dagney Braun ist Hauptproduktmanager bei AWS mit Schwerpunkt auf OpenSearch.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :hast
- :Ist
- :nicht
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- Fähigkeit
- Über Uns
- Zugang
- zugänglich
- Zusätzliche
- AI
- AI / ML
- Alle
- erlaubt
- ebenfalls
- Alternativen
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- und
- jedem
- Bienen
- APIs
- Anwendung
- angemessen
- Architektur
- SIND
- AS
- damit verbundenen
- At
- Automation
- verfügbar
- AWS
- AWS CloudFormation
- Backend
- basierend
- BE
- weil
- Verhalten
- Vorteile
- zwischen
- beide
- Brings
- breit
- bauen
- Building
- by
- CAN
- Häuser
- Fälle
- Katalog
- Wahl
- Auswählen
- gewählt
- Cluster
- kommerziell
- Unterhaus
- vergleichen
- abschließen
- Komplexität
- Konfiguration
- konfiguriert
- konfigurieren
- Schichtannahme
- Sie
- Sich zusammenschliessen
- Verbindung
- Konsul (Console)
- enthalten
- fortsetzen
- kontinuierlich
- korreliert
- erstellen
- erstellt
- schafft
- Zur Zeit
- Original
- Kunden
- Dashboards
- technische Daten
- Standard
- definieren
- definiert
- liefern
- Demo
- zeigen
- zeigt
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- setzt ein
- Beschreibung
- detailliert
- Details
- Entwickler
- Abmessungen
- Größe
- Unterlagen
- Tut nicht
- Domain
- im
- jeder
- Früher
- mühelos
- entweder
- Einbettung
- ermöglichen
- Endpunkt
- Motor
- Motor (en)
- gewährleisten
- Äther (ETH)
- Beispiel
- ERFAHRUNGEN
- Expertise
- extern
- Gesicht
- erleichtert
- Merkmal
- Felder
- Finden Sie
- Vorname
- konzentriert
- Folgende
- Aussichten für
- Unser Ansatz
- für
- voll
- erzeugen
- erzeugt
- erzeugt
- bekommen
- gif
- GitHub
- Grün
- Wachsen Sie über sich hinaus
- Guide
- Haben
- dazu beigetragen,
- hier (auf dänisch)
- Hohe Leistungsfähigkeit
- Gastgeber
- Hosting
- Gastgeber
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- Umarmendes Gesicht
- Hydratation
- IAM
- ID
- identifizieren
- Identitätsschutz
- if
- zu unterstützen,
- in
- Index
- Indizes
- zeigt
- Information
- Eingänge
- beantragen müssen
- Anleitung
- integrieren
- Integration
- Integrationen
- in
- Einleitung
- IT
- SEINE
- jpg
- JSON
- Behalten
- Wesentliche
- Sprache
- starten
- LERNEN
- gelernt
- lernen
- Lebenszyklus
- Liste
- Listen
- kostengünstig
- Maschine
- Maschinelles Lernen
- um
- Making
- verwalten
- verwaltet
- Manager
- viele
- Karte
- Mapping
- Memory
- Methode
- Minuten
- ML
- Modell
- für
- Überwachen
- Überwachung
- mehr
- viel
- mehrere
- sollen
- Name
- nativen
- Navigieren
- Menü
- notwendig,
- Need
- Neural
- Neu
- jetzt an
- Objekt
- of
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Open-Source-
- or
- Andere
- Möglichkeiten für das Ausgangssignal:
- Seite
- Brot
- leidenschaftlich
- Passwort
- Berechtigungen
- Pipeline
- Plato
- Datenintelligenz von Plato
- PlatoData
- Plugin
- Post
- Werkzeuge
- angetriebene
- früher
- Principal
- Vor
- Prozessdefinierung
- Prozessoren
- Produkt
- Produkt-Manager
- Produktion
- Fortschritt
- immobilien
- die
- bietet
- Bereitstellung
- Zweck
- Abfragen
- Roh
- Rohdaten
- empfehlen
- siehe
- entfernt
- Entfernen
- ersetzen
- falls angefordert
- Downloads
- Antwort
- REST
- Die Ergebnisse
- Einzelhandel
- behielt
- Rückkehr
- Rollen
- Routen
- Führen Sie
- sagemaker
- Screenshots
- Suche
- Suchmaschine
- Suchmaschinen
- Sicherheitdienst
- sehen
- wählen
- brauchen
- Serverlos
- Lösungen
- kompensieren
- Einstellungen
- sie
- gezeigt
- Konzerte
- Signale
- Einfacher
- Vereinfacht
- vereinfachen
- da
- Lösungen
- Quelle
- Spezialist
- speziell
- Stapel
- Beginnen Sie
- Status
- Schritt
- Shritte
- Lagerung
- Erfolgreich
- so
- Unterstützte
- sicher
- Vorlage
- Text
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- damit
- Diese
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- Durch
- zu
- gemeinsam
- Werkzeuge
- Ausbildung
- Transformation
- Übersetzungen
- was immer dies auch sein sollte.
- tippe
- ui
- einzigartiges
- einzigartig
- -
- Anwendungsfall
- benutzt
- Mitglied
- Benutzererfahrung
- Verwendung von
- BESTÄTIGEN
- überprüfen
- Version
- Video
- Anzeigen
- geht
- wurde
- we
- Netz
- Web-Services
- wann
- welche
- werden wir
- mit
- .
- gearbeitet
- Arbeitsablauf.
- Workflow-Automatisierung
- U
- Ihr
- Zephyrnet