
Hình ảnh của Tác giả
Thời gian đang thay đổi. Nếu bạn muốn trở thành một nhà khoa học dữ liệu vào năm 2023, thì có một số kỹ năng mới mà bạn nên thêm vào danh sách của mình, cũng như hàng loạt kỹ năng hiện có mà lẽ ra bạn phải thành thạo.
Tại sao lại có một bộ kỹ năng phong phú như vậy? Một phần của vấn đề là phạm vi công việc leo thang. Không ai biết nhà khoa học dữ liệu là gì hoặc người ta nên làm gì, ít nhất là nhà tuyển dụng tương lai của bạn. Vì vậy, bất cứ thứ gì có dữ liệu đều được đưa vào danh mục khoa học dữ liệu để bạn giải quyết.
Bạn phải biết cách làm sạch, biến đổi, phân tích thống kê, trực quan hóa, giao tiếp và dự đoán dữ liệu. Không chỉ vậy mà công nghệ mới (hoặc công nghệ gần đây đã trở thành xu hướng chủ đạo) cũng có thể được bổ sung vào trách nhiệm công việc của bạn.
Trong bài viết này, tôi sẽ chia nhỏ 19 kỹ năng hàng đầu bạn cần biết vào năm 2023 để trở thành nhà khoa học dữ liệu.
Dưới đây là tổng quan về mười điều quan trọng nhất.
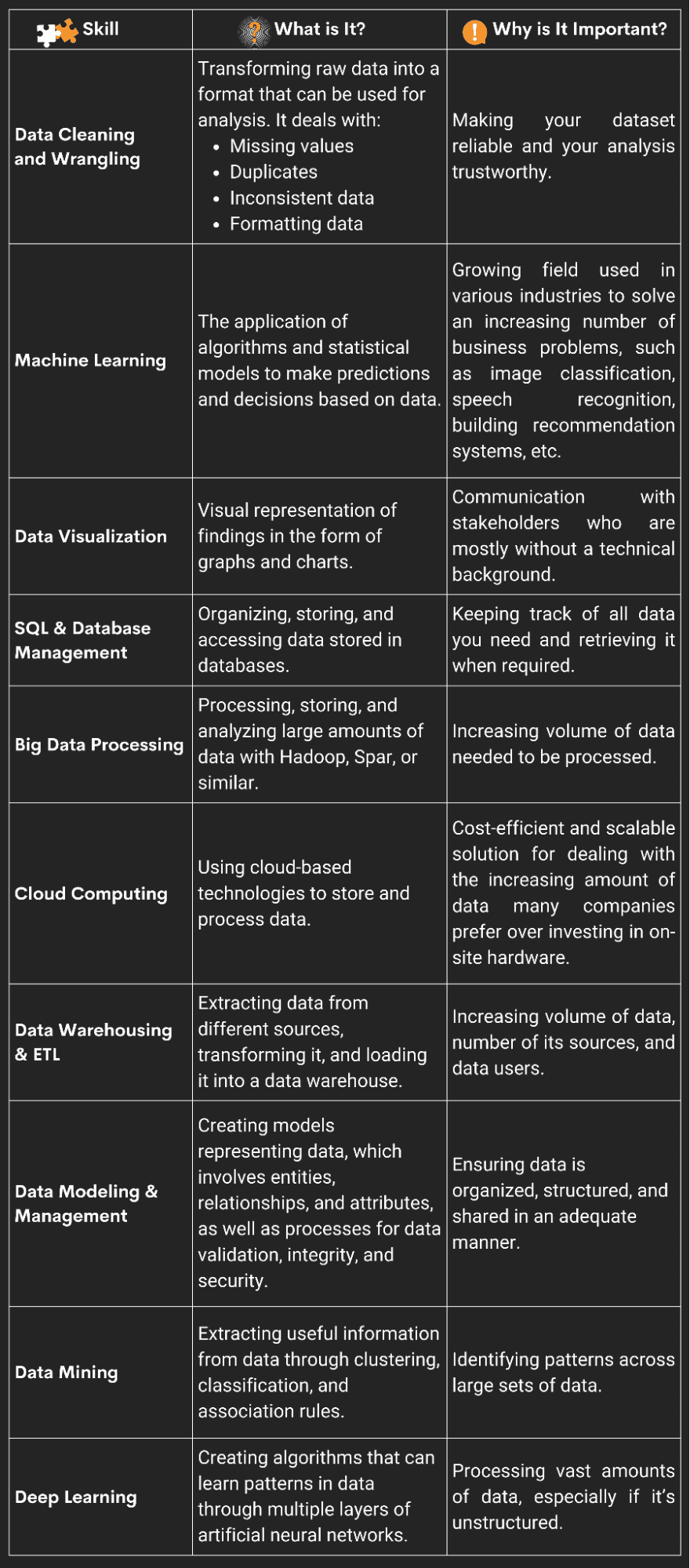
Hình ảnh của Tác giả
Những kỹ năng này sẽ giúp bạn có được một công việc, vượt qua một cuộc phỏng vấn, luôn dẫn đầu và đàm phán để được thăng chức. Trong mỗi phần, tôi sẽ tóm tắt ngắn gọn từng kỹ năng là gì, tại sao nó lại quan trọng và đưa ra một vài địa điểm để học những kỹ năng này.
Trong khi đó không 80% công việc của nhà khoa học dữ liệu, làm sạch và sắp xếp dữ liệu vẫn là một trong những kỹ năng quan trọng nhất mà nhà khoa học dữ liệu có thể thành thạo vào năm 2023.
Làm sạch và sắp xếp dữ liệu là gì?
Làm sạch và sắp xếp dữ liệu là các quá trình chuyển đổi dữ liệu thô sang định dạng có thể được sử dụng để phân tích. Điều này liên quan đến việc xử lý các giá trị bị thiếu, loại bỏ các giá trị trùng lặp, xử lý dữ liệu không nhất quán và định dạng dữ liệu theo cách sẵn sàng để phân tích.
Làm sạch dữ liệu thường đề cập đến việc loại bỏ các giá trị xấu/không chính xác, điền vào bất kỳ khoảng trống nào, tìm các giá trị trùng lặp và mặt khác là đảm bảo tập dữ liệu của bạn không tì vết và chính xác đáng tin cậy như mong đợi. Sắp xếp nó (hoặc nghiền nát nó, xoa bóp nó, hoặc bất kỳ động từ kỳ lạ nào tương tự) có nghĩa là biến nó thành một hình dạng có thể phân tích được. Bạn chuyển đổi nó hoặc ánh xạ nó sang một định dạng khác dễ nhìn hơn.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Hãy hỏi bất kỳ nhà khoa học dữ liệu nào về công việc của họ và một trong những điều đầu tiên họ đề cập sẽ là làm sạch và sắp xếp lại dữ liệu. Dữ liệu không bao giờ đến tay bạn ở dạng đẹp, sạch sẽ và có thể phân tích được, vì vậy điều cực kỳ quan trọng là bạn phải biết cách sắp xếp dữ liệu gọn gàng.
Khả năng làm sạch và sắp xếp lại dữ liệu đảm bảo rằng kết quả phân tích của bạn đáng tin cậy và giúp tránh đưa ra kết luận sai.
Bạn có thể học kỹ năng quan trọng này ở đâu?
Có rất nhiều lựa chọn tuyệt vời để học cách sắp xếp và dọn dẹp dữ liệu. Harvard cung cấp một khóa học mơ ước trên EdX. Bạn cũng có thể tự thực hành bằng cách dọn dẹp và sắp xếp các bộ dữ liệu thô, miễn phí như Thu thập thông tin chung, dữ liệu thu thập dữ liệu web bao gồm hơn 50 tỷ trang web (tại đây), hoặc dữ liệu thời tiết của Brazil (tại đây).
Không, nó không chỉ là một từ thông dụng! Học máy là một kỹ năng rất quan trọng đối với bất kỳ nhà khoa học dữ liệu nào trong tương lai.
Học máy là gì?
Học máy là ứng dụng của các thuật toán và mô hình thống kê để đưa ra dự đoán và quyết định dựa trên dữ liệu.
Đó là một lĩnh vực trí tuệ nhân tạo cho phép máy tính cải thiện hiệu suất của chúng đối với một tác vụ cụ thể bằng cách học hỏi từ dữ liệu mà không cần lập trình rõ ràng. Nó giúp tự động hóa. Bạn sẽ tìm thấy nó trong bất kỳ ngành công nghiệp.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Bạn cần biết về học máy vào năm 2023 vì đây là một lĩnh vực đang phát triển nhanh chóng và đã trở thành một công cụ quan trọng để giải quyết các vấn đề phức tạp và đưa ra dự đoán trong các ngành khác nhau.
Các thuật toán học máy có thể được sử dụng để phân loại hình ảnh, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên và tạo hệ thống đề xuất. Bạn sẽ khó tìm được một ngành không (hoặc không muốn) thực hiện các nhiệm vụ hỗ trợ ML đó.
Thành thạo máy học cho phép nhà khoa học dữ liệu trích xuất những hiểu biết có giá trị từ các tập dữ liệu lớn và phức tạp, đồng thời phát triển các mô hình dự đoán có thể đưa ra các quyết định kinh doanh tốt hơn.
Bạn có thể học kỹ năng quan trọng này ở đâu?
Chúng tôi đã có một kho lưu trữ hơn ba mươi dự án học máy trên ScrataScratch để thể hiện kỹ năng này trong sơ yếu lý lịch của bạn. TensorFlow cũng có một bộ tài nguyên miễn phí tuyệt vời để học máy học.

Hình ảnh của Tác giả
Kỹ năng này khá dễ hiểu. Khi bạn phân tích các con số, các bên liên quan chính sẽ muốn hiểu những phát hiện của bạn bằng các đồ thị và biểu đồ đẹp mắt.
Trực quan hóa dữ liệu là gì?
Trực quan hóa dữ liệu là việc tạo biểu đồ, đồ thị và đồ họa khác để giúp làm cho dữ liệu dễ hiểu hơn. Bạn lấy những con số mà bạn vừa làm sạch, sắp xếp lại hoặc dự đoán và đặt chúng ở một dạng định dạng trực quan nào đó, để truyền đạt xu hướng với những người khác hoặc để giúp phát hiện xu hướng dễ dàng hơn.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Vào năm 2023, khả năng trực quan hóa dữ liệu là điều quan trọng đối với một nhà khoa học dữ liệu. Nó giống như có một siêu năng lực bí mật để khám phá các mô hình và xu hướng ẩn trong dữ liệu mà thoạt nhìn có thể không rõ ràng. Và phần tốt nhất? Bạn có thể chia sẻ những phát hiện của mình với người khác theo cách vừa hấp dẫn vừa đáng nhớ. Là một nhà khoa học dữ liệu, bạn sẽ làm việc với các nhóm thuộc mọi cấp độ kinh nghiệm khác nhau, nhưng một bức tranh sẽ dễ hiểu hơn nhiều so với một hàng số.
Vì vậy, nếu bạn muốn trở thành một nhà khoa học dữ liệu, người có thể truyền đạt những hiểu biết và khám phá của mình một cách hiệu quả, điều quan trọng là bạn phải nắm vững nghệ thuật trực quan hóa dữ liệu.
Bạn có thể học kỹ năng quan trọng này ở đâu?
Đây là danh sách của những nơi miễn phí để tìm hiểu dữ liệu viz.
SQL là một ngôn ngữ truy vấn có cấu trúc. Các nhà khoa học dữ liệu sử dụng SQL để làm việc với cơ sở dữ liệu SQL cũng như quản lý cơ sở dữ liệu và thực hiện các tác vụ lưu trữ dữ liệu.
SQL và quản lý cơ sở dữ liệu là gì?
SQL là một ngôn ngữ rất phổ biến cho phép bạn truy cập và thao tác dữ liệu có cấu trúc. Nó đi đôi với quản lý cơ sở dữ liệu, thường được thực hiện trong SQL. Quản lý cơ sở dữ liệu về cơ bản là cách bạn có thể sắp xếp, lưu trữ và tìm nạp dữ liệu từ một nơi. Cơ sở dữ liệu SQL là một trong những công nghệ phụ trợ hàng đầu để học vào năm 2023, vì vậy nó không chỉ dành cho khoa học dữ liệu.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Là một nhà khoa học dữ liệu, bạn phải theo dõi tất cả dữ liệu, đảm bảo dữ liệu được sắp xếp và truy xuất khi ai đó cần. Đó là những gì quản lý cơ sở dữ liệu và SQL cho phép bạn thực hiện.
Bạn có thể học kỹ năng quan trọng này ở đâu?
Coursera có một tấn các khóa học quản trị/quản lý cơ sở dữ liệu tuyệt vời, có giá phải chăng mà bạn có thể thử. Bạn cũng có thể xem trước một số Câu hỏi phỏng vấn SQL đây, có thể hữu ích để kiểm tra kiến thức của bạn.
Dữ liệu lớn là một từ thông dụng, vâng, nhưng nó cũng là một khái niệm có thật – Oracle định nghĩa nó là “dữ liệu chứa nhiều loại hơn, có khối lượng ngày càng tăng và với tốc độ nhanh hơn” hoặc dữ liệu có ba chữ V.
Xử lý dữ liệu lớn là gì?
Xử lý dữ liệu lớn là khả năng xử lý, lưu trữ và phân tích lượng lớn dữ liệu bằng các công nghệ như Hadoop và Spark.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Vào năm 2023, khả năng xử lý dữ liệu lớn rất quan trọng đối với các nhà khoa học dữ liệu. Khối lượng dữ liệu được tạo tiếp tục tăng theo cấp số nhân và khả năng xử lý cũng như phân tích dữ liệu này một cách hiệu quả là điều cần thiết để đưa ra quyết định sáng suốt và thu được thông tin chi tiết có giá trị. Các nhà khoa học dữ liệu có hiểu biết sâu sắc về các kỹ thuật xử lý dữ liệu lớn sẽ có thể làm việc với các tập dữ liệu lớn một cách dễ dàng và tận dụng tối đa thông tin mà chúng chứa.
Ngoài ra, nhờ tính dài dòng của nó, việc thêm “dữ liệu lớn” vào sơ yếu lý lịch của bạn sẽ không bao giờ gây hại.
Bạn có thể học nó ở đâu?
Tôi yêu Simplilearn Chuỗi hướng dẫn trên YouTube về khái niệm này.

Hình ảnh của Tác giả
Thật buồn cười - khi nhiều sản phẩm và dịch vụ chuyển sang đám mây, điện toán đám mây trở thành yêu cầu công việc đối với hầu hết mọi công việc kỹ thuật, cho dù đó là DevOps hoặc một nhà khoa học dữ liệu.
Điện toán đám mây là gì?
Điện toán đám mây là việc sử dụng các công nghệ và nền tảng dựa trên đám mây như AWS, Azure hoặc Google Cloud để lưu trữ và xử lý dữ liệu. Nó giống như có một phòng lưu trữ ảo mà bạn có thể truy cập từ bất kỳ đâu vào bất kỳ lúc nào. Thay vì lưu trữ dữ liệu và tài nguyên điện toán trên các máy hoặc máy chủ cục bộ, điện toán đám mây cho phép các tổ chức – và các nhà khoa học dữ liệu – truy cập các tài nguyên này qua internet.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Khi tôi tiếp tục nhấn mạnh, lượng dữ liệu bạn phải làm việc với tư cách là nhà khoa học dữ liệu đang tăng lên. Nhiều công ty sẽ gắn nó trên đám mây hơn là xử lý nó tại chỗ. Việc có khả năng lưu trữ và xử lý dữ liệu này theo cách có thể mở rộng và hiệu quả ngày càng trở nên quan trọng.
Điện toán đám mây cung cấp một giải pháp hiệu quả cho việc này, cho phép các nhà khoa học dữ liệu truy cập vào lượng lớn tài nguyên máy tính và lưu trữ dữ liệu mà không cần đến phần cứng và cơ sở hạ tầng đắt tiền.
Bạn có thể học nó ở đâu?
Tin tốt là vì các công ty sở hữu nhiều đám mây khác nhau, nhiều người trong số họ muốn dạy bạn về nó miễn phí, vì vậy bạn học cách sử dụng đám mây của họ. Google, microsoftvà đàn bà gan dạ tất cả đều có tài nguyên điện toán đám mây tuyệt vời.
“Đợi đã, không phải chúng ta chỉ bao gồm cơ sở dữ liệu sao? Kho dữ liệu là gì?” Tôi nghe bạn hỏi.
Tôi hiểu bạn. Đôi khi, có vẻ như kỹ năng quan trọng nhất về khoa học dữ liệu là giữ cho tất cả các từ viết tắt và biệt ngữ được rõ ràng.
Kho dữ liệu và ETL là gì?
Đầu tiên, hãy phân biệt kho dữ liệu với cơ sở dữ liệu.
Kho lưu trữ dữ liệu hiện tại và lịch sử cho nhiều hệ thống, trong khi cơ sở dữ liệu lưu trữ dữ liệu hiện tại cần thiết để cung cấp năng lượng cho dự án. Cơ sở dữ liệu lưu trữ dữ liệu hiện tại cần thiết để cung cấp năng lượng cho ứng dụng trong khi kho dữ liệu lưu trữ dữ liệu hiện tại và lịch sử cho một hoặc nhiều hệ thống trong một lược đồ cố định và được xác định trước để phân tích dữ liệu.
Nói tóm lại, bạn sẽ sử dụng kho dữ liệu cho dữ liệu của nhiều dự án khác nhau cùng nhau, trong khi cơ sở dữ liệu chủ yếu lưu trữ dữ liệu của một dự án.
ETL là một quy trình liên quan đến kho dữ liệu, viết tắt của trích xuất, chuyển đổi và tải. Một công cụ ETL sẽ trích xuất dữ liệu từ bất kỳ hệ thống nguồn dữ liệu nào bạn muốn, chuyển đổi dữ liệu đó trong khu vực tổ chức (thường là làm sạch, thao tác hoặc “ghép” dữ liệu đó), sau đó tải dữ liệu đó vào kho dữ liệu.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Tôi cảm thấy như mình đã lặp lại điểm này trong mọi kỹ năng, nhưng dữ liệu ngày càng nhiều. Các công ty đang khao khát điều đó và họ sẽ mong đợi bạn quản lý nó. Biết cách quản lý dữ liệu trong các đường ống có thể xây dựng là rất quan trọng.
Bạn có thể học nó ở đâu?
Tôi khuyên bạn nên học cách thực hiện một ETL phù hợp với một ngôn ngữ cụ thể, như SQL hoặc Python. Datacamp đã có một một tốt với Trăn. Microsoft chạy nhiều hơn hướng dẫn trình độ trung cấp để đi qua một tùy chọn SQL.
Mỗi nhà khoa học dữ liệu là một chuyên gia mô hình. Tôi không nói về Giselle Bundchen. Ý tôi là tạo một mô hình về cách dữ liệu được lưu trữ và sắp xếp trong một hệ thống.
Mô hình hóa và quản lý dữ liệu là gì?
Quản lý và mô hình hóa dữ liệu là quá trình tạo ra các mô hình toán học để biểu diễn dữ liệu, cũng như quản lý dữ liệu để duy trì chất lượng, độ chính xác và tính hữu dụng của dữ liệu.
Điều này liên quan đến việc xác định các thực thể, mối quan hệ và thuộc tính dữ liệu, cũng như triển khai các quy trình để xác thực, toàn vẹn và bảo mật dữ liệu.
Nói một cách đơn giản hơn, lập mô hình dữ liệu về cơ bản có nghĩa là bạn đang tạo một bản thiết kế chi tiết về cách tổ chức và kết nối dữ liệu trong hệ thống của chủ lao động. Bạn có thể coi nó giống như việc phác thảo bản thiết kế của một ngôi nhà. Giống như bản thiết kế hiển thị các phòng khác nhau và cách chúng được kết nối, mô hình hóa dữ liệu cho thấy các phần thông tin khác nhau có liên quan và kết nối với nhau như thế nào.
Điều này giúp đảm bảo rằng dữ liệu được lưu trữ và sử dụng một cách nhất quán và hiệu quả.
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Là một nhà khoa học dữ liệu, bạn sẽ chịu trách nhiệm đảm bảo dữ liệu được sắp xếp và cấu trúc theo cách có thể truy cập được. Quản lý và lập mô hình dữ liệu giúp bạn làm việc với dữ liệu, chia sẻ dữ liệu, đảm bảo dữ liệu chính xác và đưa ra quyết định dựa trên dữ liệu đó.
Bạn có thể học nó ở đâu?
Microsoft có một cái tốt intro trên blog của họ, chỉ dài nửa giờ và được đánh giá cao. Đó là một nơi tốt để bắt đầu.

Ảnh byt Tác giả
Nhiều thuật ngữ khoa học dữ liệu vừa bị cướp khỏi các ngành nghề khác, như mô hình hóa và khai thác mỏ. Hãy tìm hiểu ý nghĩa của nó và tại sao nó lại quan trọng.
Khai thác dữ liệu là gì?
Khai thác dữ liệu là quá trình trích xuất thông tin hữu ích từ dữ liệu thông qua các kỹ thuật như phân cụm, phân loại và quy tắc kết hợp. Bạn đang sàng lọc trong cơn lũ dữ liệu thực sự để tìm những mẩu vàng hữu ích. (Có lẽ panning dữ liệu sẽ là một cái tên tốt hơn cho kỹ năng này!)
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Hãy tưởng tượng điều đó: bạn là nhà khoa học dữ liệu vào năm 2023. Bạn có dữ liệu đến từ mười nghìn nguồn khác nhau. Bạn sử dụng kỹ năng nào để xác định các mẫu trên tất cả các nguồn dữ liệu này?
Đó là khai thác dữ liệu.
Bạn có thể học nó ở đâu?
Khai thác dữ liệu thường được đề cập trong các khóa học về dữ liệu lớn hoặc phân tích dữ liệu vì đây là một thành phần khá quan trọng của hai kỹ năng đó. EdX cung cấp một cặp vợ chồng các tùy chọn để tìm hiểu khai thác dữ liệu.
Học sâu khác với học máy một cách tinh tế! Học sâu là một lĩnh vực con của học máy.
Học sâu là gì?
Học sâu là một khía cạnh của học máy tập trung vào việc tạo ra các thuật toán có thể học các mẫu trong dữ liệu thông qua nhiều lớp mạng thần kinh nhân tạo. (Nhân tiện, mạng lưới thần kinh nhân tạo là một loại thuật toán học máy được mô hình hóa tương tự như cấu trúc và chức năng của bộ não con người.)
Tại sao việc trở thành Nhà khoa học dữ liệu vào năm 2023 lại quan trọng?
Trí tuệ nhân tạo ngày càng tinh vi hơn vào năm 2023. Biết kiến thức cơ bản về AI và ML là chưa đủ – bạn cũng nên làm quen với những điều tiên tiến nhất, bởi vì nó sẽ không còn tiên tiến vào ngày mai nữa. Cách đây vài năm, học sâu là điều mới lạ, và bây giờ nó là một điều cần thiết.
Các nhà khoa học dữ liệu sẽ sử dụng học sâu khi các công ty có quyền truy cập vào một lượng dữ liệu thực sự khổng lồ. Nó được sử dụng để xử lý hình ảnh và video hoặc các ứng dụng thị giác máy tính.
Bạn có thể học nó ở đâu?
Tôi thích Hướng dẫn của Simplilearn như một điểm khởi đầu.
Có rất nhiều công nghệ và kỹ thuật mới nhất hữu ích để biết. Những thứ này thậm chí còn nâng cao hơn, chẳng hạn như mạng lưới đối thủ chung, hoặc dựa trên kỹ năng mềm hơn, như kể chuyện dữ liệu hoặc chuyên biệt cho một lĩnh vực như dự báo chuỗi thời gian. Tôi sẽ tóm tắt ngắn gọn những điều này ở đây:
- Xử lý ngôn ngữ tự nhiên (NLP): Một lĩnh vực con của AI xử lý việc xử lý và hiểu ngôn ngữ của con người. Chatbot sử dụng cái này.
- Phân tích & Dự báo chuỗi thời gian: Nghiên cứu dữ liệu theo thời gian và sử dụng các mô hình thống kê để đưa ra dự đoán về các sự kiện trong tương lai. Bạn có thể sử dụng kỹ năng này để phân tích doanh thu hoặc bán hàng.
- Thiết kế thử nghiệm & Thử nghiệm A/B: Quá trình thiết kế và tiến hành các thí nghiệm có kiểm soát để kiểm tra các giả thuyết và đưa ra quyết định dựa trên dữ liệu.
- Kể chuyện dữ liệu: Khả năng truyền đạt hiệu quả những hiểu biết và phát hiện về dữ liệu cho các bên liên quan phi kỹ thuật. Ngày càng có nhiều bên liên quan quan tâm đến tại sao đằng sau các quyết định dựa trên dữ liệu, vì vậy điều này rất quan trọng.
- Mạng đối thủ chung (GAN): Một loại kiến trúc học sâu trong đó hai mạng thần kinh được đào tạo để làm việc cùng nhau nhằm tạo ra dữ liệu mới giống với một tập dữ liệu nhất định.
- Học chuyển tiếp: Một kỹ thuật máy học trong đó một mô hình được đào tạo trước trên một tác vụ và được tinh chỉnh cho một tác vụ liên quan, giúp cải thiện hiệu suất và giảm lượng dữ liệu đào tạo cần thiết. Các công ty nhỏ hơn bị hạn chế về nguồn lực sẽ thấy điều này hữu ích.
- Học máy tự động (AutoML): Một phương pháp tự động hóa quá trình lựa chọn, đào tạo và triển khai các mô hình máy học.
- Điều chỉnh siêu tham số: Một tiểu thể loại ML khác. Đây là quá trình tối ưu hóa hiệu suất của mô hình máy học bằng cách điều chỉnh các tham số không được học từ dữ liệu, chẳng hạn như tốc độ học hoặc số lớp ẩn.
- AI có thể giải thích (XAI): Một nhánh của AI tập trung vào việc tạo ra các thuật toán và mô hình minh bạch và có thể hiểu được, để con người có thể hiểu được quá trình ra quyết định của chúng. Một lần nữa, giúp các bên liên quan hiểu những gì đang xảy ra.
Nếu bạn muốn trở thành nhà khoa học dữ liệu vào năm 2023, thì 19 kỹ năng này cực kỳ quan trọng. Tin thực sự tuyệt vời là nhiều kỹ năng trong số này có thể tự học được, trong khi những kỹ năng khác bạn có thể học được khi làm việc với vai trò cấp cơ sở hơn như nhân viên dữ liệu hoặc nhà phân tích kinh doanh.
Một số cách học:
- Luôn kiểm tra YouTube. Có rất nhiều tài nguyên miễn phí, toàn diện. Tôi đã liệt kê một số video ở đây, nhưng thực tế có vô số video ngoài kia.
- Các nền tảng như Coursera và EdX thường có chuỗi bài giảng
- Chúng tôi có hơn một nghìn câu hỏi phỏng vấn thực tế để thực hành, cả dựa trên mã hóa và không mã hóa. Chúng tôi cũng cung cấp ví dụ dự án dữ liệu.
Hãy tận hưởng hành trình học hỏi những kỹ năng này để trở thành nhà khoa học dữ liệu vào năm 2023.
Nate Rosidi là một nhà khoa học dữ liệu và trong chiến lược sản phẩm. Anh ấy cũng là một giáo sư trợ giảng dạy phân tích và là người sáng lập StrataScratch, một nền tảng giúp các nhà khoa học dữ liệu chuẩn bị cho cuộc phỏng vấn của họ với các câu hỏi phỏng vấn thực tế từ các công ty hàng đầu. Kết nối với anh ấy trên Twitter: StrataScratch or LinkedIn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html?utm_source=rss&utm_medium=rss&utm_campaign=top-19-skills-you-need-to-know-in-2023-to-be-a-data-scientist
- :là
- $ LÊN
- 2023
- a
- có khả năng
- Có khả năng
- Giới thiệu
- về nó
- hoàn toàn
- truy cập
- có thể truy cập
- chính xác
- chính xác
- Các từ viết tắt
- ngang qua
- thêm
- tiên tiến
- đối thủ
- trước
- AI
- thuật toán
- thuật toán
- Tất cả
- Cho phép
- cho phép
- Đã
- đàn bà gan dạ
- số lượng
- số lượng
- phân tích
- phân tích
- phân tích
- và
- và cơ sở hạ tầng
- Một
- bất cứ nơi nào
- Các Ứng Dụng
- các ứng dụng
- kiến trúc
- LÀ
- KHU VỰC
- đến
- Nghệ thuật
- bài viết
- nhân tạo
- trí tuệ nhân tạo
- mạng lưới thần kinh nhân tạo
- AS
- Hiệp hội
- At
- thuộc tính
- tự động hóa
- Tự động hóa
- Tự động
- AWS
- Azure
- Backend
- dựa
- Về cơ bản
- Khái niệm cơ bản
- BE
- bởi vì
- trở nên
- trở thành
- trở thành
- sau
- được
- BEST
- Hơn
- lớn
- Dữ Liệu Lớn.
- Tỷ
- Blog
- Brain
- Chi nhánh
- Nghỉ giải lao
- một thời gian ngắn
- kinh doanh
- by
- CAN
- Phân loại
- thay đổi
- Bảng xếp hạng
- chatbot
- kiểm tra
- phân loại
- Phân loại
- Làm sạch
- đám mây
- điện toán đám mây
- tập hợp
- COM
- đến
- Chung
- thông thường
- giao tiếp
- Các công ty
- phức tạp
- thành phần
- sáng tác
- toàn diện
- máy tính
- Tầm nhìn máy tính
- Ứng dụng Thị giác Máy tính
- máy tính
- máy tính
- khái niệm
- Tiến hành
- Kết nối
- kết nối
- thích hợp
- chứa
- liên tiếp
- kiểm soát
- chuyển đổi
- có thể
- Coursera
- các khóa học
- che
- phủ
- tạo
- Tạo
- tạo
- quan trọng
- quan trọng
- Current
- đường cong
- cắt
- dữ liệu
- Phân tích dữ liệu
- khai thác dữ liệu
- xử lý dữ liệu
- khoa học dữ liệu
- nhà khoa học dữ liệu
- tập dữ liệu
- bộ dữ liệu
- lưu trữ dữ liệu
- trực quan hóa dữ liệu
- kho dữ liệu
- Kho dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- bộ dữ liệu
- nhiều
- xử lý
- Ra quyết định
- quyết định
- sâu
- học kĩ càng
- xác định
- triển khai
- Thiết kế
- thiết kế
- phát triển
- khác nhau
- phân biệt
- Không
- xuống
- rút ra
- lái xe
- bản sao
- mỗi
- dễ dàng hơn
- dễ dàng
- Cạnh
- edx
- Hiệu quả
- hiệu quả
- hiệu quả
- hay
- cho phép
- tương tác
- đủ
- đảm bảo
- đảm bảo
- thực thể
- thiết yếu
- Ether (ETH)
- Ngay cả
- sự kiện
- Mỗi
- hiện tại
- mong đợi
- dự kiến
- kinh nghiệm
- số mũ
- mở rộng
- trích xuất
- quen
- vài
- lĩnh vực
- Tìm kiếm
- tìm kiếm
- Tên
- cố định
- lũ lụt
- tập trung
- tập trung
- Trong
- định dạng
- người sáng lập
- Miễn phí
- từ
- chức năng
- buồn cười
- tương lai
- đạt được
- GAN
- tạo ra
- tạo ra
- thế hệ
- mạng lưới nghịch cảnh
- được
- nhận được
- được
- Liếc nhìn
- Go
- Đi
- Vàng
- tốt
- Google Cloud
- đồ họa
- đồ thị
- tuyệt vời
- lớn hơn
- Các nhóm
- Phát triển
- Phát triển
- Hadoop
- Một nửa
- tay
- xử lý
- Xử lý
- Xử lý
- Tay bài
- Xảy ra
- phần cứng
- harvard
- Có
- có
- Nghe
- giúp đỡ
- giúp đỡ
- giúp
- tại đây
- Thành viên ẩn danh
- làm nổi bật
- cao
- lịch sử
- House
- Độ đáng tin của
- Hướng dẫn
- HTTPS
- Nhân loại
- Con người
- Hungry
- i
- TÔI SẼ
- xác định
- hình ảnh
- hình ảnh
- thực hiện
- quan trọng
- nâng cao
- cải thiện
- in
- tăng
- lên
- các ngành công nghiệp
- ngành công nghiệp
- thông tin
- thông báo
- Cơ sở hạ tầng
- những hiểu biết
- thay vì
- tính toàn vẹn
- Sự thông minh
- quan tâm
- Internet
- Phỏng vấn
- Câu hỏi phỏng vấn
- Phỏng vấn
- IT
- ITS
- biệt ngữ
- Việc làm
- cuộc hành trình
- Xe đẩy
- Giữ
- giữ
- Key
- Loại
- Biết
- Biết
- kiến thức
- Quốc gia
- Ngôn ngữ
- lớn
- lớp
- LEARN
- học
- học tập
- Bài giảng
- cho phép
- niveaux
- Lượt thích
- Liệt kê
- tải
- địa phương
- dài
- yêu
- máy
- học máy
- Máy móc
- Mainstream
- duy trì
- làm cho
- LÀM CHO
- Làm
- quản lý
- quản lý
- thao túng
- cách thức
- nhiều
- bản đồ
- chủ
- toán học
- chất
- Vấn đề
- có nghĩa
- phương pháp
- microsoft
- Might
- Khai thác mỏ
- mất tích
- ML
- kiểu mẫu
- người mẫu
- mô hình
- chi tiết
- hầu hết
- di chuyển
- nhiều
- tên
- Tự nhiên
- Ngôn ngữ tự nhiên
- Xử lý ngôn ngữ tự nhiên
- Cần
- cần thiết
- cần
- nhu cầu
- mạng
- Thần kinh
- mạng thần kinh
- Mới
- tin tức
- nlp
- phi kỹ thuật
- tiểu thuyết
- con số
- số
- Rõ ràng
- of
- cung cấp
- Cung cấp
- on
- ONE
- tối ưu hóa
- Tùy chọn
- Các lựa chọn
- oracle
- tổ chức
- Tổ chức
- Nền tảng khác
- Khác
- nếu không thì
- tổng quan
- riêng
- thông số
- một phần
- mô hình
- thực hiện
- hiệu suất
- chọn
- hình ảnh
- miếng
- Nơi
- Nơi
- nền tảng
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Rất nhiều
- Điểm
- Phổ biến
- quyền lực
- thực tế
- thực hành
- dự đoán
- dự đoán
- Dự đoán
- Chuẩn bị
- khá
- Xem trước
- Vấn đề
- vấn đề
- quá trình
- Quy trình
- xử lý
- Sản phẩm
- Sản phẩm
- Sản phẩm và dịch vụ
- Giáo sư
- lập trình
- dự án
- dự án
- xúc tiến
- đúng
- cung cấp
- đặt
- Python
- chất lượng
- Câu hỏi
- nhanh chóng
- Tỷ lệ
- hơn
- Nguyên
- dữ liệu thô
- RE
- đạt
- sẵn sàng
- thực
- gần đây
- công nhận
- giới thiệu
- Khuyến nghị
- giảm
- đề cập
- liên quan
- Mối quan hệ
- loại bỏ
- lặp đi lặp lại
- kho
- đại diện
- cần phải
- yêu cầu
- giống
- Thông tin
- trách nhiệm
- chịu trách nhiệm
- Kết quả
- tiếp tục
- doanh thu
- Thoát khỏi
- Vai trò
- Phòng
- phòng
- danh sách
- HÀNG
- quy tắc
- s
- bán hàng
- khả năng mở rộng
- Khoa học
- Nhà khoa học
- các nhà khoa học
- phạm vi
- Bí mật
- Phần
- an ninh
- lựa chọn
- Loạt Sách
- DỊCH VỤ
- định
- bộ
- một số
- Hình dạng
- Chia sẻ
- ngắn
- nên
- hiển thị
- Chương trình
- tương tự
- kể từ khi
- duy nhất
- kỹ năng
- kỹ năng
- nhỏ hơn
- lẻn
- So
- giải pháp
- Giải quyết
- một số
- Một người nào đó
- tinh vi
- nguồn
- nguồn
- Spark
- chuyên gia
- chuyên nghành
- riêng
- phát biểu
- Spot
- SQL
- dàn dựng
- các bên liên quan
- Bắt đầu
- Bắt đầu
- thống kê
- ở lại
- dính
- Vẫn còn
- là gắn
- hàng
- lưu trữ
- cửa hàng
- kể chuyện
- ngay
- Chiến lược
- cấu trúc
- cấu trúc
- Học tập
- như vậy
- tóm tắt
- lớn
- siêu cường
- hệ thống
- hệ thống
- Hãy
- dùng
- nói
- Nhiệm vụ
- nhiệm vụ
- Giảng dạy
- kỹ thuật
- Công nghệ
- Công nghệ
- 10
- tensorflow
- về
- thử nghiệm
- Kiểm tra
- việc này
- Sản phẩm
- Khái niệm cơ bản
- thông tin
- cung cấp their dịch
- Them
- Đó
- Kia là
- điều
- số ba
- Thông qua
- thời gian
- Chuỗi thời gian
- đến
- bên nhau
- mai
- quá
- công cụ
- hàng đầu
- theo dõi
- đào tạo
- Hội thảo
- Chuyển đổi
- biến đổi
- minh bạch
- Xu hướng
- đáng tin cậy
- hướng dẫn
- thường
- hiểu
- sự hiểu biết
- hiểu
- sử dụng
- thông tin hữu ích
- thường
- xác nhận
- Quý báu
- Các giá trị
- nhiều
- khác nhau
- Lớn
- Thành phố Velo
- Video
- Video
- ảo
- tầm nhìn
- hình dung
- khối lượng
- khối lượng
- Kho
- Kho bãi
- Đường..
- cách
- Thời tiết
- web
- TỐT
- Điều gì
- liệu
- cái nào
- trong khi
- CHÚNG TÔI LÀ
- sẽ
- với
- không có
- Công việc
- làm việc cùng nhau
- đang làm việc
- sẽ
- năm
- trên màn hình
- youtube
- zephyrnet







