
Hình ảnh của Tác giả
Khi làm việc với dữ liệu và các biến khác nhau, việc gán một biến hoặc giá trị lớn hơn biến khác là điều dễ dàng. Chúng ta có thể cho rằng một biến hoặc điểm dữ liệu cụ thể có tác động nhiều hơn đến đầu ra, nhưng chúng ta chắc chắn đến mức nào rằng các biến khác có tác động như nhau?
Trong thống kê, tỷ lệ cơ sở có thể được coi là xác suất của các lớp không có điều kiện về "bằng chứng đặc trưng". Bạn có thể xem lãi suất cơ bản là giả định xác suất trước đó của mình.
Lãi suất cơ bản là công cụ quan trọng trong nghiên cứu. Ví dụ: nếu chúng tôi là một công ty dược phẩm và đang trong quá trình phát triển và tung ra một loại vắc xin mới, chúng tôi muốn xem xét sự thành công của phương pháp điều trị. Nếu chúng tôi có 4000 người sẵn sàng tiêm vắc xin này và tỷ lệ cơ bản của chúng tôi là 1/25.
Điều này có nghĩa là chỉ có 160 người được chữa khỏi thành công trong số 4000 người. Trong thế giới dược phẩm, đây là một tỷ lệ thành công rất thấp. Đây là cách tỷ lệ cơ sở có thể được sử dụng để cải thiện nghiên cứu, độ chính xác và đảm bảo rằng sản phẩm sẽ hoạt động tốt.
Nếu chúng ta tách các từ ra, nó sẽ giúp chúng ta hiểu rõ hơn. Sai lầm có nghĩa là một niềm tin sai lầm hoặc lý luận sai lầm. Nếu bây giờ chúng ta kết hợp điều đó với định nghĩa của chúng ta về lãi suất cơ bản ở trên.
Sai lầm về lãi suất cơ bản, còn được gọi là sai lệch lãi suất cơ bản và bỏ qua lãi suất cơ bản, là khả năng phán đoán một tình huống cụ thể, trong khi không xem xét tất cả các dữ liệu liên quan.
Ngụy biện lãi suất cơ bản có thông tin về lãi suất cơ bản cũng như các thông tin liên quan khác. Điều này có thể do nhiều nguyên nhân khác nhau như không kiểm tra kỹ lưỡng và phân tích dữ liệu một cách chính xác, hoặc sự thiếu hiểu biết để thiên vị một phần cụ thể của dữ liệu.
Sai lầm về lãi suất cơ bản mô tả xu hướng một người nào đó bỏ qua thông tin về lãi suất cơ bản hiện có, thúc đẩy và ủng hộ thông tin mới. Điều này đi ngược lại các quy tắc cơ bản của lập luận dựa trên bằng chứng.
Bạn thường sẽ nghe về điều này xảy ra trong ngành tài chính. Ví dụ: các nhà đầu tư sẽ đưa ra chiến thuật mua hoặc chia sẻ dựa trên những thông tin không hợp lý, dẫn đến sự biến động trên thị trường - mặc dù họ có hiểu biết về tỷ lệ cơ bản.
Vì vậy, bây giờ chúng ta đã hiểu rõ hơn về tỷ lệ cơ bản và ngụy biện tỷ lệ cơ bản. Mức độ liên quan và tác động của nó trong Khoa học dữ liệu là gì?
Chúng ta đã nói về ‘xác suất của các lớp’ và ‘có tính đến tất cả dữ liệu liên quan’. Nếu bạn là nhà khoa học dữ liệu, kỹ sư máy học hoặc mới bắt đầu công việc - bạn sẽ biết xác suất và dữ liệu liên quan quan trọng như thế nào trong việc tạo ra kết quả đầu ra chính xác, quá trình học tập của mô hình học máy của bạn và tạo ra các mô hình hiệu suất cao.
Để phân tích và đưa ra dự đoán về dữ liệu hoặc để mô hình học máy của bạn tạo ra kết quả đầu ra chính xác - bạn cần xem xét từng bit dữ liệu. Khi bạn xem qua dữ liệu của mình vào lần đầu tiên nhìn thấy nó, bạn có thể coi một số phần có liên quan và những phần khác không liên quan. Tuy nhiên, đây là phán đoán của bạn và chưa thực tế cho đến khi có sự phân tích thích hợp.
Như đã đề cập ở trên, tỷ lệ cơ sở ban đầu giúp bạn đảm bảo độ chính xác và tạo ra các mô hình hiệu suất cao. Vậy làm thế nào chúng ta có thể làm điều này trong Khoa học dữ liệu?
Ma trận hỗn loạn
Ma trận nhầm lẫn là một phép đo hiệu suất cung cấp một bản tóm tắt các kết quả dự đoán về một vấn đề phân loại. Các ma trận nhầm lẫn đều dựa trên kết quả: Đúng, Sai, Tích cực và Tiêu cực.
Ma trận nhầm lẫn thể hiện dự đoán của mô hình của chúng tôi trong giai đoạn thử nghiệm. Âm tính giả và dương tính giả trong ma trận nhầm lẫn là ví dụ về sai lầm tỷ lệ cơ bản.
- Tích cực thực sự (TP) - mô hình của bạn được dự đoán là tích cực và kết quả là tích cực
- True Negative (TN) - mô hình của bạn dự đoán là âm tính và nó âm tính
- Dương tính giả (FP) - mô hình của bạn dự đoán là dương tính và nó âm tính
- Âm tính giả (FN) - mô hình của bạn dự đoán âm tính và kết quả là dương tính
Một ma trận nhầm lẫn có thể tính toán 5 số liệu khác nhau để giúp chúng tôi đo lường tính hợp lệ của mô hình của mình:
- Phân loại sai = FP + FN / TP + TN + FP + FN
- Độ chính xác = TP / TP + FP
- Độ chính xác = TP + TN / TP + TN + FP + FN
- Tính đặc hiệu = TN/TN + FP
- Độ nhạy hay còn gọi là Nhớ lại = TP / TP + FN
Để hiểu rõ hơn về ma trận nhầm lẫn, tốt hơn hết bạn nên xem trực quan:
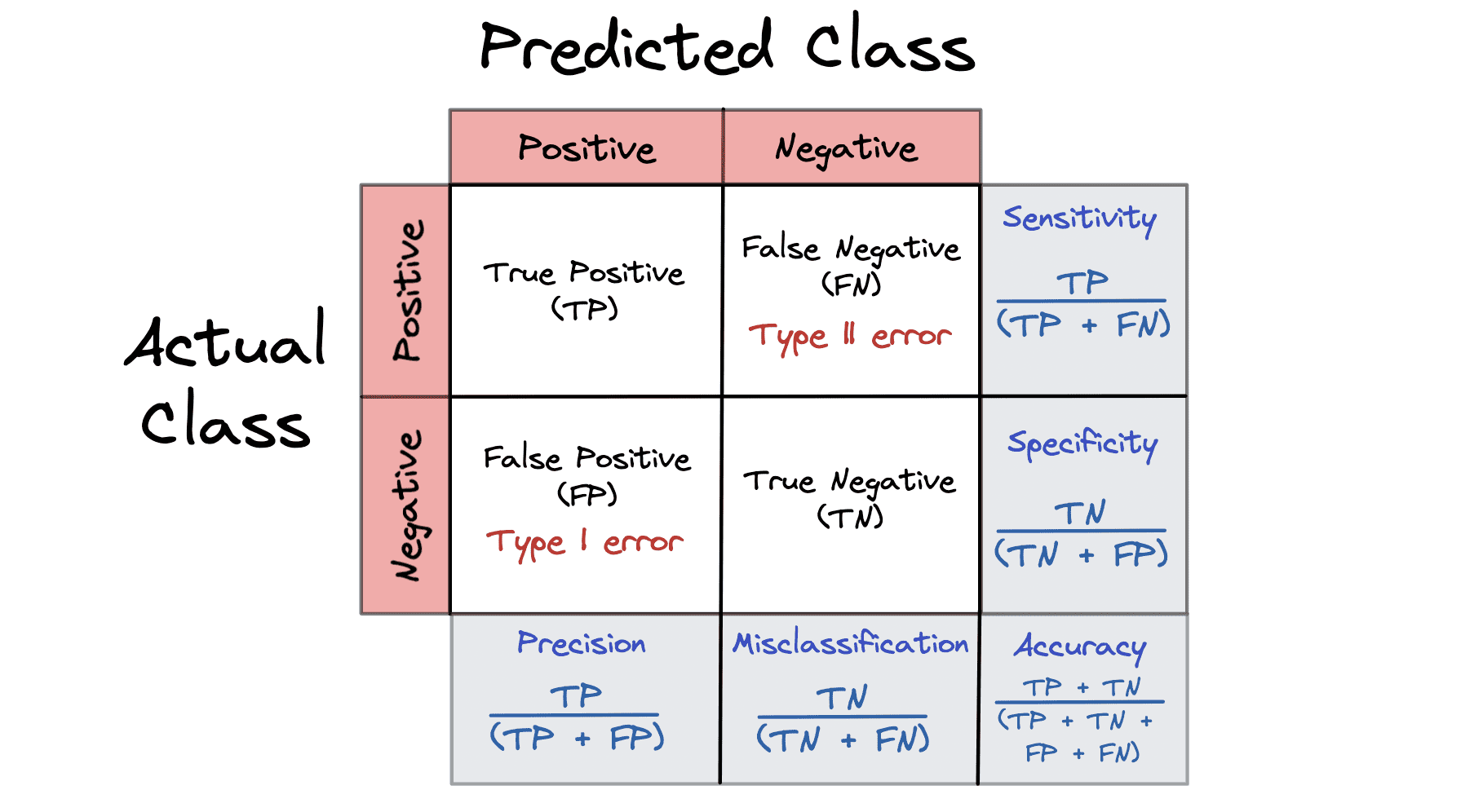
Hình ảnh của Tác giả
Khi xem qua bài viết này, bạn có thể nghĩ ra nhiều nguyên nhân dẫn đến sai lầm về tỷ lệ cơ bản, chẳng hạn như không xem xét tất cả các dữ liệu liên quan, lỗi của con người hoặc thiếu chính xác.
Mặc dù những điều này đều đúng và thêm vào nguyên nhân của sai lầm tỷ giá cơ bản. Tất cả chúng đều liên quan đến vấn đề lớn nhất là bỏ qua thông tin lãi suất cơ bản ngay từ đầu. Thông tin về lãi suất cơ bản thường bị bỏ qua vì nó được coi là không liên quan, tuy nhiên, thông tin về lãi suất cơ bản có thể giúp mọi người tiết kiệm rất nhiều thời gian và tiền bạc. Việc sử dụng thông tin tỷ lệ cơ bản có sẵn cho phép bạn đưa ra xác suất chính xác hơn về việc liệu một sự kiện nhất định có xảy ra hay không.
Sử dụng thông tin về lãi suất cơ bản sẽ giúp bạn tránh được sai lầm về lãi suất cơ bản.
Nhận thức được những sai lầm như ý kiến, quy trình tự động, v.v. - sẽ cho phép bạn giải quyết vấn đề sai lầm về tỷ lệ cơ sở và giảm thiểu các lỗi tiềm ẩn. Khi bạn đang đo xác suất xảy ra một sự kiện nhất định, các phương pháp Bayesian có thể giúp ích trong việc này để giảm sai lầm về tỷ lệ cơ sở.
Tỷ lệ cơ bản rất quan trọng trong khoa học dữ liệu vì nó trang bị cho bạn sự hiểu biết cơ bản về cách đánh giá nghiên cứu hoặc dự án của bạn và tinh chỉnh mô hình của bạn - mang lại sự gia tăng tổng thể về độ chính xác và hiệu suất.
Nếu bạn muốn xem video về ngụy biện tỷ lệ cơ bản trong lĩnh vực y tế, hãy xem video này: Nghịch lý Xét nghiệm Y khoa
Nisha Arya là Nhà khoa học dữ liệu, Nhà văn kỹ thuật tự do và Quản lý cộng đồng tại KDnuggets. Cô ấy đặc biệt quan tâm đến việc cung cấp lời khuyên hoặc hướng dẫn về nghề nghiệp Khoa học dữ liệu và kiến thức dựa trên lý thuyết về Khoa học dữ liệu. Cô ấy cũng mong muốn khám phá những cách khác nhau mà Trí tuệ nhân tạo có thể mang lại lợi ích cho tuổi thọ con người. Một người ham học hỏi, tìm cách mở rộng kiến thức công nghệ và kỹ năng viết của mình, đồng thời giúp hướng dẫn người khác.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- : có
- :là
- :không phải
- $ LÊN
- a
- Giới thiệu
- ở trên
- chính xác
- chính xác
- tư vấn
- chống lại
- Tất cả
- cho phép
- Ngoài ra
- an
- phân tích
- phân tích
- phân tích
- và
- LÀ
- xung quanh
- bài viết
- nhân tạo
- trí tuệ nhân tạo
- AS
- giả định
- At
- Tự động
- có sẵn
- cơ sở
- dựa
- Bayesian
- BE
- niềm tin
- hưởng lợi
- Hơn
- thiên vị
- lớn nhất
- Một chút
- nới rộng
- Mua
- by
- tính toán
- CAN
- Tuyển Dụng
- Nguyên nhân
- nguyên nhân
- nhất định
- kiểm tra
- các lớp học
- phân loại
- chống lại
- kết hợp
- cộng đồng
- công ty
- nhầm lẫn
- Hãy xem xét
- xem xét
- xem xét
- dữ liệu
- khoa học dữ liệu
- nhà khoa học dữ liệu
- Mặc dù
- phát triển
- khác nhau
- Cửa
- suốt trong
- ky sư
- đảm bảo
- lôi
- lỗi
- vv
- Sự kiện
- Mỗi
- bằng chứng
- Kiểm tra
- ví dụ
- ví dụ
- hiện tại
- khám phá
- Thực tế
- bị lỗi
- lĩnh vực
- tài chính
- Tên
- lần đầu tiên
- biến động
- Chân
- Trong
- freelance
- cơ bản
- nhận được
- Cho
- được
- Đi
- đi
- lớn hơn
- hướng dẫn
- Xảy ra
- Có
- có
- Nghe
- giúp đỡ
- giúp đỡ
- giúp
- hiệu suất cao
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTTPS
- Nhân loại
- Làm ngơ
- Va chạm
- quan trọng
- nâng cao
- in
- Tăng lên
- ngành công nghiệp
- thông tin
- ban đầu
- Sự thông minh
- quan tâm
- trong
- Các nhà đầu tư
- vấn đề
- IT
- ITS
- Xe đẩy
- Keen
- Biết
- kiến thức
- nổi tiếng
- Thiếu sót
- Dẫn
- người học
- học tập
- Cuộc sống
- Lượt thích
- tuổi thọ
- Xem
- Rất nhiều
- Thấp
- máy
- học máy
- làm cho
- Làm
- giám đốc
- thị trường
- Matrix
- Có thể..
- có nghĩa
- đo
- đo lường
- y khoa
- đề cập
- phương pháp
- Metrics
- Might
- kiểu mẫu
- mô hình
- tiền
- chi tiết
- Cần
- tiêu cực
- Mới
- tại
- of
- on
- ONE
- có thể
- Ý kiến
- or
- Nền tảng khác
- Khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- Kết quả
- đầu ra
- tổng thể
- một phần
- đặc biệt
- các bộ phận
- người
- thực hiện
- hiệu suất
- Dược phẩm
- giai đoạn
- Nơi
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- tích cực
- tiềm năng
- cần
- Độ chính xác
- dự đoán
- dự đoán
- Dự đoán
- Trước khi
- xác suất
- có lẽ
- Vấn đề
- quá trình
- Quy trình
- sản xuất
- Sản phẩm
- dự án
- đúng
- đúng
- cung cấp
- cung cấp
- Đẩy
- Tỷ lệ
- Giá
- lý do
- giảm
- sự liên quan
- có liên quan
- đại diện cho
- nghiên cứu
- Kết quả
- quy tắc
- s
- Lưu
- quét
- Khoa học
- Nhà khoa học
- tìm kiếm
- chia sẻ
- tình hình
- kỹ năng
- So
- một số
- Một người nào đó
- riêng
- chia
- số liệu thống kê
- Học tập
- thành công
- Thành công
- như vậy
- TÓM TẮT
- chiến thuật
- Hãy
- dùng
- công nghệ cao
- Kỹ thuật
- thử nghiệm
- Kiểm tra
- hơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Kia là
- điều này
- triệt để
- Thông qua
- thời gian
- đến
- công cụ
- điều trị
- đúng
- hướng dẫn
- thường
- vô điều kiện
- hiểu
- sự hiểu biết
- us
- đã sử dụng
- giá trị
- nhiều
- khác nhau
- Video
- Đồng hồ đeo tay
- cách
- we
- TỐT
- Điều gì
- Là gì
- liệu
- cái nào
- Trong khi
- CHÚNG TÔI LÀ
- sẽ
- sẵn sàng
- mong muốn
- với
- từ
- đang làm việc
- thế giới
- sẽ
- nhà văn
- viết
- bạn
- trên màn hình
- zephyrnet








