Với sự ra đời của AI tổng quát, các mô hình nền tảng (FM) ngày nay, chẳng hạn như mô hình ngôn ngữ lớn (LLM) Claude 2 và Llama 2, có thể thực hiện một loạt nhiệm vụ tổng quát như trả lời câu hỏi, tóm tắt và tạo nội dung trên dữ liệu văn bản. Tuy nhiên, dữ liệu trong thế giới thực tồn tại ở nhiều phương thức, chẳng hạn như văn bản, hình ảnh, video và âm thanh. Lấy một bản trình chiếu PowerPoint làm ví dụ. Nó có thể chứa thông tin ở dạng văn bản hoặc được nhúng trong biểu đồ, bảng và hình ảnh.
Trong bài đăng này, chúng tôi trình bày một giải pháp sử dụng FM đa phương thức như Phần mềm nhúng đa phương thức của Amazon Titan mô hình và LLaVA 1.5 và các dịch vụ AWS bao gồm nền tảng Amazon và Amazon SageMaker để thực hiện các nhiệm vụ tổng hợp tương tự trên dữ liệu đa phương thức.
Tổng quan về giải pháp
Giải pháp này cung cấp cách triển khai để trả lời các câu hỏi bằng cách sử dụng thông tin có trong văn bản và các phần tử hình ảnh của bản trình bày. Thiết kế dựa trên khái niệm Thế hệ tăng cường truy xuất (RAG). Theo truyền thống, RAG được liên kết với dữ liệu văn bản có thể được LLM xử lý. Trong bài đăng này, chúng tôi mở rộng RAG để bao gồm cả hình ảnh. Điều này cung cấp khả năng tìm kiếm mạnh mẽ để trích xuất nội dung có liên quan theo ngữ cảnh từ các yếu tố trực quan như bảng và biểu đồ cùng với văn bản.
Có nhiều cách khác nhau để thiết kế giải pháp RAG bao gồm hình ảnh. Chúng tôi đã trình bày một cách tiếp cận ở đây và sẽ tiếp tục bằng một cách tiếp cận khác trong bài đăng thứ hai của loạt bài gồm ba phần này.
Giải pháp này bao gồm các thành phần sau:
- Mô hình nhúng đa phương thức của Amazon Titan – FM này được sử dụng để tạo phần nhúng cho nội dung trong bộ slide được sử dụng trong bài đăng này. Là một mô hình đa phương thức, mô hình Titan này có thể xử lý văn bản, hình ảnh hoặc sự kết hợp làm đầu vào và tạo ra các phần nhúng. Mô hình Titan Multimodal Embeddings tạo ra các vectơ (phần nhúng) có 1,024 kích thước và được truy cập thông qua Amazon Bedrock.
- Trợ lý ngôn ngữ lớn và tầm nhìn (LLaVA) – LLaVA là một mô hình đa phương thức nguồn mở để hiểu ngôn ngữ và hình ảnh, đồng thời được sử dụng để diễn giải dữ liệu trong các trang trình bày, bao gồm các yếu tố trực quan như biểu đồ và bảng. Chúng tôi sử dụng phiên bản tham số 7 tỷ LLaVA 1.5-7b trong giải pháp này.
- Amazon SageMaker – Mô hình LLaVA được triển khai trên điểm cuối SageMaker bằng cách sử dụng dịch vụ lưu trữ của SageMaker và chúng tôi sử dụng điểm cuối thu được để chạy suy luận dựa trên mô hình LLaVA. Chúng tôi cũng sử dụng sổ ghi chép SageMaker để sắp xếp và trình diễn giải pháp này từ đầu đến cuối.
- Amazon OpenSearch Serverless – OpenSearch Serverless là cấu hình serverless theo yêu cầu dành cho Dịch vụ Tìm kiếm Mở của Amazon. Chúng tôi sử dụng OpenSearch Serverless làm cơ sở dữ liệu vectơ để lưu trữ các phần nhúng được tạo bởi mô hình Titan Multimodal Embeddings. Một chỉ mục được tạo trong bộ sưu tập OpenSearch Serverless đóng vai trò là kho lưu trữ vectơ cho giải pháp RAG của chúng tôi.
- Nhập Amazon OpenSearch (OSI) – OSI là công cụ thu thập dữ liệu không có máy chủ, được quản lý hoàn toàn, cung cấp dữ liệu đến các miền Dịch vụ OpenSearch và các bộ sưu tập OpenSearch Serverless. Trong bài đăng này, chúng tôi sử dụng đường dẫn OSI để phân phối dữ liệu đến kho lưu trữ vectơ OpenSearch Serverless.
Giải pháp xây dựng
Thiết kế giải pháp bao gồm hai phần: nhập và tương tác người dùng. Trong quá trình nhập, chúng tôi xử lý bộ trang trình bày đầu vào bằng cách chuyển đổi từng trang trình bày thành hình ảnh, tạo nội dung nhúng cho những hình ảnh này rồi đưa vào kho dữ liệu vectơ. Các bước này được hoàn thành trước các bước tương tác của người dùng.
Trong giai đoạn tương tác với người dùng, câu hỏi của người dùng sẽ được chuyển đổi thành nội dung nhúng và tìm kiếm tương tự được chạy trên cơ sở dữ liệu vectơ để tìm trang chiếu có khả năng chứa câu trả lời cho câu hỏi của người dùng. Sau đó, chúng tôi cung cấp trang trình bày này (dưới dạng tệp hình ảnh) cho mô hình LLaVA và câu hỏi của người dùng dưới dạng lời nhắc tạo câu trả lời cho truy vấn. Tất cả mã cho bài đăng này đều có sẵn trong GitHub còn lại.
Sơ đồ sau đây minh họa kiến trúc nhập.
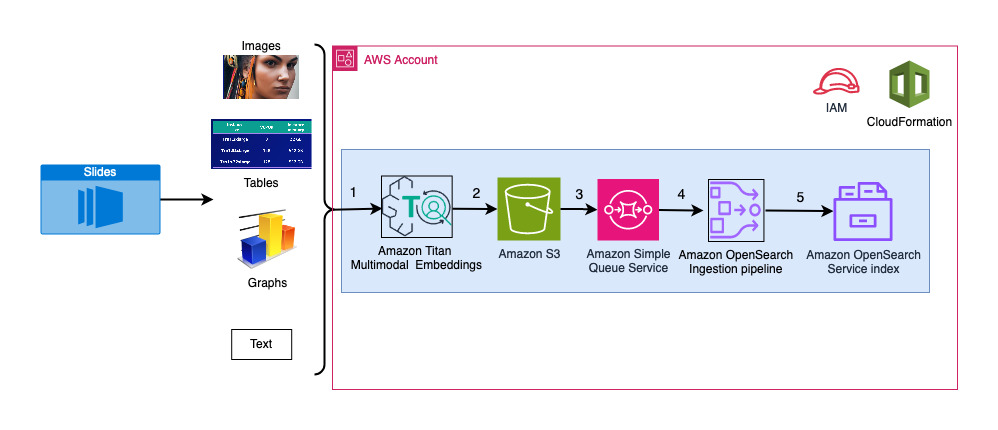
Các bước quy trình làm việc như sau:
- Các trang chiếu được chuyển đổi thành tệp hình ảnh (mỗi trang một trang) ở định dạng JPG và được chuyển sang mô hình Titan Multimodal Embeddings để tạo các phần nhúng. Trong bài đăng này, chúng tôi sử dụng bộ slide có tiêu đề Đào tạo và triển khai Khuếch tán ổn định bằng AWS Trainium & AWS Inferentia từ Hội nghị thượng đỉnh AWS ở Toronto, tháng 2023 năm 31, để trình diễn giải pháp. Bộ tài liệu mẫu có 31 trang trình bày, vì vậy chúng tôi tạo ra 1,024 bộ phần nhúng vectơ, mỗi bộ có XNUMX kích thước. Chúng tôi thêm các trường siêu dữ liệu bổ sung vào các vectơ nhúng được tạo này và tạo tệp JSON. Các trường siêu dữ liệu bổ sung này có thể được sử dụng để thực hiện các truy vấn tìm kiếm phong phú bằng khả năng tìm kiếm mạnh mẽ của OpenSearch.
- Các phần nhúng đã tạo được đặt cùng nhau trong một tệp JSON được tải lên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3).
- Thông qua Thông báo sự kiện của Amazon S3, một sự kiện được đặt trong một Dịch vụ xếp hàng đơn giản trên Amazon Hàng đợi (Amazon SQS).
- Sự kiện này trong hàng đợi SQS đóng vai trò như một yếu tố kích hoạt để chạy quy trình OSI, từ đó nhập dữ liệu (tệp JSON) dưới dạng tài liệu vào chỉ mục OpenSearch Serverless. Lưu ý rằng chỉ mục OpenSearch Serverless được định cấu hình làm phần chìm cho quy trình này và được tạo như một phần của bộ sưu tập OpenSearch Serverless.
Sơ đồ sau minh họa kiến trúc tương tác của người dùng.
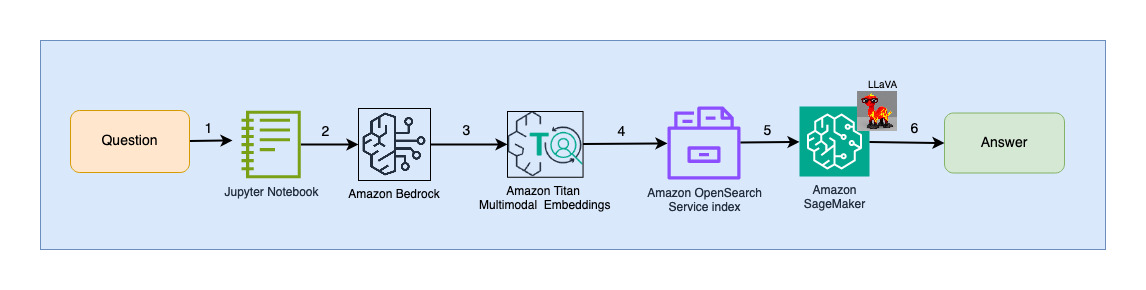
Các bước quy trình làm việc như sau:
- Người dùng gửi câu hỏi liên quan đến bản trình bày đã được nhập.
- Dữ liệu đầu vào của người dùng được chuyển đổi thành các phần nhúng bằng mô hình Titan Multimodal Embeddings được truy cập qua Amazon Bedrock. Tìm kiếm vectơ OpenSearch được thực hiện bằng cách sử dụng các phần nhúng này. Chúng tôi thực hiện tìm kiếm k-hàng xóm gần nhất (k=1) để truy xuất phần nhúng phù hợp nhất phù hợp với truy vấn của người dùng. Đặt k=1 sẽ truy xuất trang trình bày phù hợp nhất với câu hỏi của người dùng.
- Siêu dữ liệu của phản hồi từ OpenSearch Serverless chứa đường dẫn đến hình ảnh tương ứng với trang trình bày phù hợp nhất.
- Lời nhắc được tạo bằng cách kết hợp câu hỏi của người dùng và đường dẫn hình ảnh rồi cung cấp cho LLaVA được lưu trữ trên SageMaker. Mô hình LLaVA có thể hiểu câu hỏi của người dùng và trả lời câu hỏi đó bằng cách kiểm tra dữ liệu trong hình ảnh.
- Kết quả của suy luận này được trả về cho người dùng.
Các bước này sẽ được thảo luận chi tiết trong các phần sau. Xem Kết quả phần dành cho ảnh chụp màn hình và thông tin chi tiết về đầu ra.
Điều kiện tiên quyết
Để thực hiện giải pháp được cung cấp trong bài đăng này, bạn nên có một Tài khoản AWS và làm quen với FM, Amazon Bedrock, SageMaker và OpenSearch Service.
Giải pháp này sử dụng mô hình Titan Multimodal Embeddings. Đảm bảo rằng mô hình này được kích hoạt để sử dụng trong Amazon Bedrock. Trên bảng điều khiển Amazon Bedrock, chọn Truy cập mô hình trong ngăn điều hướng. Nếu Titan Multimodal Embeddings được bật, trạng thái truy cập sẽ nêu rõ Chấp thuận quyền truy cập.
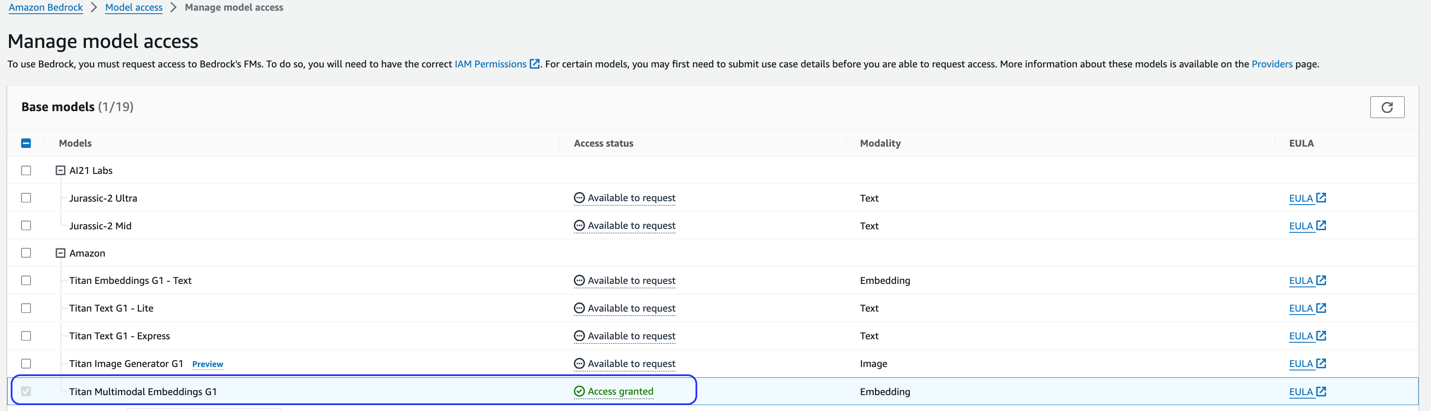
Nếu mô hình không có sẵn, hãy cho phép truy cập vào mô hình bằng cách chọn Quản lý quyền truy cập mô hình, lựa chọn Vật liệu nhúng đa phương thức Titan G1và lựa chọn Yêu cầu quyền truy cập mô hình. Mô hình được kích hoạt để sử dụng ngay lập tức.
Sử dụng mẫu AWS CloudFormation để tạo ngăn xếp giải pháp
Sử dụng một trong những điều sau đây Hình thành đám mây AWS các mẫu (tùy thuộc vào Khu vực của bạn) để khởi chạy các tài nguyên giải pháp.
| Khu vực AWS | liên kết |
|---|---|
us-east-1 |
|
us-west-2 |
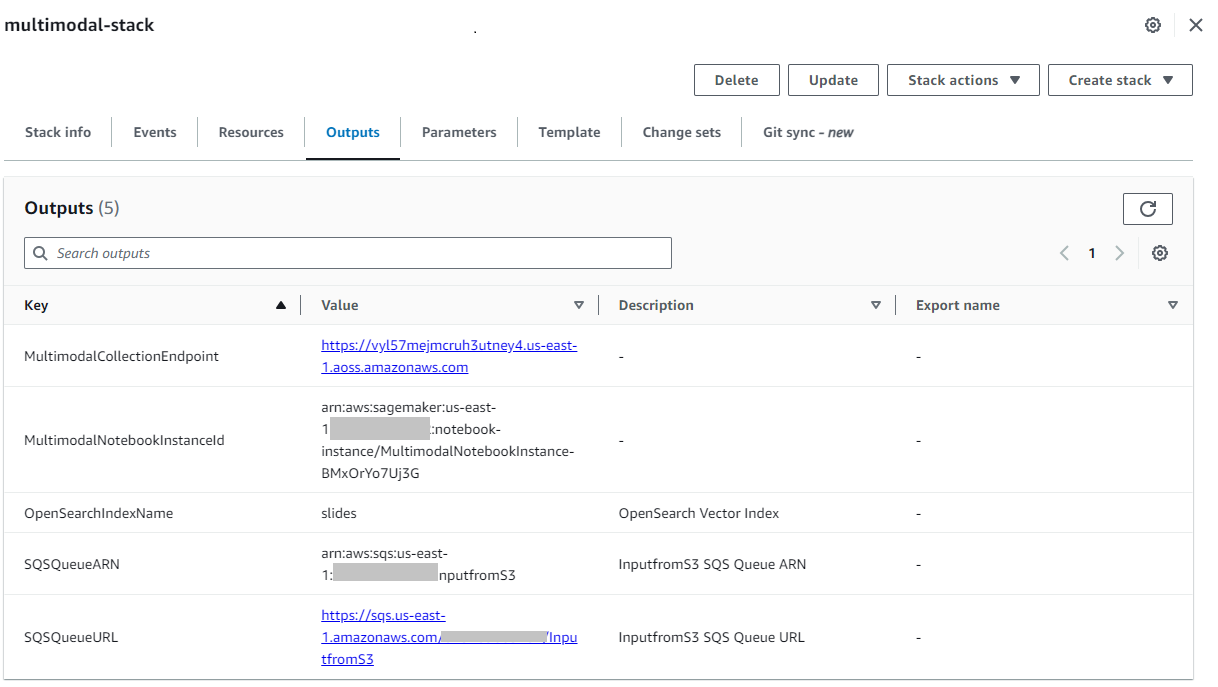
Sau khi ngăn xếp được tạo thành công, hãy điều hướng đến ngăn xếp Kết quả đầu ra trên bảng điều khiển AWS CloudFormation và ghi lại giá trị cho MultimodalCollectionEndpoint, mà chúng tôi sử dụng trong các bước tiếp theo.
Mẫu CloudFormation tạo các tài nguyên sau:
- Vai trò IAM – Sau đây Quản lý truy cập và nhận dạng AWS (IAM) vai trò được tạo. Cập nhật các vai trò này để áp dụng quyền có đặc quyền tối thiểu.
SMExecutionRolevới quyền truy cập đầy đủ vào Amazon S3, SageMaker, OpenSearch Service và Bedrock.OSPipelineExecutionRolecó quyền truy cập vào các hành động cụ thể của Amazon SQS và OSI.
- Sổ ghi chép SageMaker – Tất cả mã cho bài đăng này được chạy qua sổ ghi chép này.
- Bộ sưu tập OpenSearch Serverless – Đây là cơ sở dữ liệu vector để lưu trữ và truy xuất các phần nhúng.
- đường ống OSI – Đây là đường dẫn để nhập dữ liệu vào OpenSearch Serverless.
- Xô S3 – Tất cả dữ liệu cho bài đăng này được lưu trữ trong nhóm này.
- hàng đợi SQS – Các sự kiện để kích hoạt chạy quy trình OSI được đưa vào hàng đợi này.
Mẫu CloudFormation định cấu hình quy trình OSI với quá trình xử lý Amazon S3 và Amazon SQS dưới dạng nguồn và chỉ mục OpenSearch Serverless dưới dạng chìm. Bất kỳ đối tượng nào được tạo trong nhóm S3 và tiền tố được chỉ định (multimodal/osi-embeddings-json) sẽ kích hoạt thông báo SQS, được quy trình OSI sử dụng để nhập dữ liệu vào OpenSearch Serverless.
Mẫu CloudFormation cũng tạo mạng, mã hóavà truy cập dữ liệu các chính sách cần thiết cho bộ sưu tập OpenSearch Serverless. Cập nhật các chính sách này để áp dụng các quyền có đặc quyền tối thiểu.
Lưu ý rằng tên mẫu CloudFormation được tham chiếu trong sổ ghi chép SageMaker. Nếu tên mẫu mặc định bị thay đổi, hãy đảm bảo bạn cập nhật tên đó trong toàn cầu.py
Kiểm tra giải pháp
Sau khi hoàn tất các bước tiên quyết và ngăn xếp CloudFormation đã được tạo thành công, giờ đây bạn đã sẵn sàng thử nghiệm giải pháp:
- Trên bảng điều khiển SageMaker, chọn máy tính xách tay trong khung điều hướng.
- Chọn hình ba gạch
MultimodalNotebookInstanceví dụ sổ ghi chép và chọn Mở JupyterLab.
- In Trình duyệt tệp, duyệt qua thư mục sổ ghi chép để xem sổ ghi chép và các tệp hỗ trợ.
Các sổ ghi chép được đánh số theo thứ tự chúng được chạy. Hướng dẫn và nhận xét trong mỗi sổ ghi chép mô tả các hành động được thực hiện bởi sổ ghi chép đó. Chúng tôi chạy từng cuốn sổ này một.
- Chọn 0_deploy_llava.ipynb để mở nó trong JupyterLab.
- trên chạy menu, chọn Chạy tất cả các ô để chạy mã trong sổ ghi chép này.
Sổ ghi chép này triển khai mô hình LLaVA-v1.5-7B cho điểm cuối SageMaker. Trong sổ ghi chép này, chúng tôi tải xuống mô hình LLaVA-v1.5-7B từ HuggingFace Hub, thay thế tập lệnh inference.py bằng llava_inference.pyvà tạo tệp model.tar.gz cho mô hình này. Tệp model.tar.gz được tải lên Amazon S3 và được sử dụng để triển khai mô hình trên điểm cuối SageMaker. Các llava_inference.py tập lệnh có mã bổ sung để cho phép đọc tệp hình ảnh từ Amazon S3 và chạy suy luận trên đó.
- Chọn 1_data_prep.ipynb để mở nó trong JupyterLab.
- trên chạy menu, chọn Chạy tất cả các ô để chạy mã trong sổ ghi chép này.
Sổ tay này tải xuống sàn trượt, chuyển đổi từng trang chiếu thành định dạng tệp JPG và tải chúng lên bộ chứa S3 được sử dụng cho bài đăng này.
- Chọn 2_data_ingestion.ipynb để mở nó trong JupyterLab.
- trên chạy menu, chọn Chạy tất cả các ô để chạy mã trong sổ ghi chép này.
Chúng tôi thực hiện những điều sau trong sổ ghi chép này:
- Chúng tôi tạo một chỉ mục trong bộ sưu tập OpenSearch Serverless. Chỉ mục này lưu trữ dữ liệu nhúng cho bản trình chiếu. Xem đoạn mã sau:
- Chúng tôi sử dụng mô hình Titan Multimodal Embeddings để chuyển đổi hình ảnh JPG được tạo trong sổ ghi chép trước đó thành các ảnh nhúng vector. Các phần nhúng và siêu dữ liệu bổ sung này (chẳng hạn như đường dẫn S3 của tệp hình ảnh) được lưu trữ trong tệp JSON và được tải lên Amazon S3. Lưu ý rằng một tệp JSON duy nhất sẽ được tạo, chứa tài liệu cho tất cả các trang chiếu (hình ảnh) được chuyển đổi thành phần nhúng. Đoạn mã sau đây cho thấy cách chuyển đổi một hình ảnh (ở dạng chuỗi được mã hóa Base64) thành nội dung nhúng:
- Hành động này kích hoạt đường dẫn Nhập OpenSearch, xử lý tệp và nhập tệp đó vào chỉ mục OpenSearch Serverless. Sau đây là mẫu tệp JSON được tạo. (Một vectơ có bốn chiều được hiển thị trong mã ví dụ. Mô hình Embeddings đa phương thức Titan tạo ra 1,024 chiều.)
- Chọn 3_rag_inference.ipynb để mở nó trong JupyterLab.
- trên chạy menu, chọn Chạy tất cả các ô để chạy mã trong sổ ghi chép này.
Sổ ghi chép này triển khai giải pháp RAG: chúng tôi chuyển câu hỏi của người dùng thành phần nhúng, tìm hình ảnh (trang trình bày) tương tự từ cơ sở dữ liệu vectơ và cung cấp hình ảnh được truy xuất cho LLaVA để tạo câu trả lời cho câu hỏi của người dùng. Chúng tôi sử dụng mẫu lời nhắc sau:
Đoạn mã sau cung cấp quy trình làm việc RAG:
Kết quả
Sau đây là phần tổng hợp một số câu hỏi và câu trả lời của người dùng do quá trình triển khai của chúng tôi tạo ra. Các câu hỏi cột ghi lại câu hỏi của người dùng và Trả lời cột là phản hồi văn bản được tạo bởi LLaVA. Hình ảnh là kết quả khớp trang trình k gần nhất (k=1) được trả về bởi tìm kiếm vectơ OpenSearch Serverless. Slide này được LLaVA diễn giải để đưa ra câu trả lời.
Kết quả RAG đa phương thức
| câu hỏi | Trả lời | Hình ảnh |
|---|---|---|
| Inf2 so sánh hiệu năng với các phiên bản EC2 tương đương như thế nào? Tôi cần những con số. | Theo bản trình bày, các phiên bản Inf2 của AWS Inferentia2 cung cấp thông lượng cao hơn tới 4 lần và độ trễ thấp hơn 10 lần so với các phiên bản EC2 tương đương. |  |
| Theo bánh đà AI/ML, dịch vụ AI/ML của AWS cung cấp những gì? | Các dịch vụ AI/ML của AWS cung cấp khả năng $/perfer tốt hơn, các khả năng mới và đầu tư vào đổi mới. | 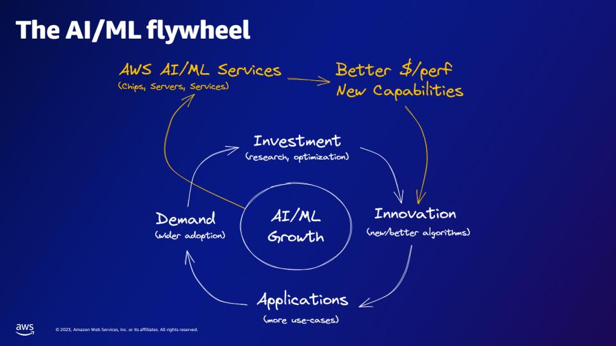 |
| So với GPT-2, GPT-3 có thêm bao nhiêu thông số? Sự khác biệt về mặt số học giữa kích thước tham số của GPT-2 và GPT-3 là gì? | Theo slide, GPT-3 có 175 tỷ tham số, trong khi GPT-2 có 1.5 tỷ tham số. Con số chênh lệch giữa kích thước tham số của GPT-2 và GPT-3 là 173.5 tỷ. | 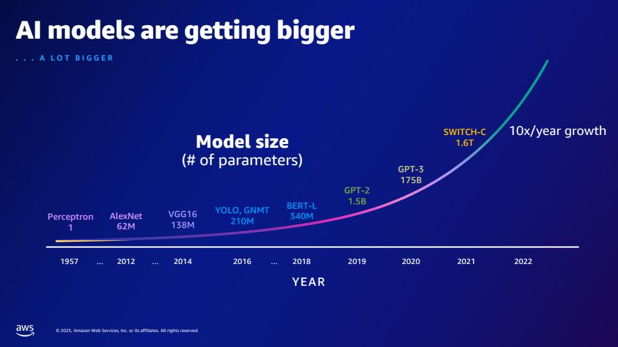 |
| Quark trong vật lý hạt là gì? | Tôi không tìm thấy câu trả lời cho câu hỏi này trong bản trình chiếu. |  |
Hãy thoải mái mở rộng giải pháp này cho các slide của bạn. Chỉ cần cập nhật biến SLIDE_DECK trong Globals.py bằng một URL tới bản trình bày của bạn và chạy các bước nhập được nêu chi tiết trong phần trước.
Mẹo
Bạn có thể sử dụng Bảng thông tin OpenSearch để tương tác với API OpenSearch nhằm chạy thử nghiệm nhanh về chỉ mục và dữ liệu đã nhập của bạn. Ảnh chụp màn hình sau đây hiển thị ví dụ GET trên trang tổng quan OpenSearch.
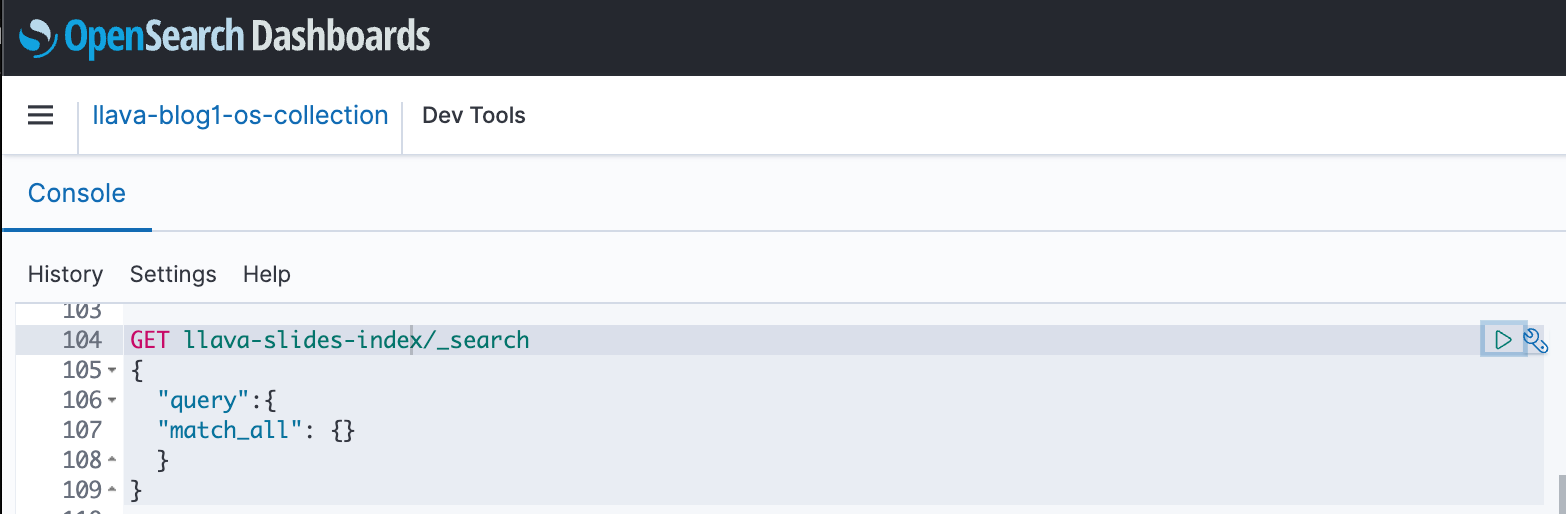
Làm sạch
Để tránh phát sinh phí trong tương lai, hãy xóa tài nguyên bạn đã tạo. Bạn có thể thực hiện việc này bằng cách xóa ngăn xếp thông qua bảng điều khiển CloudFormation.

Ngoài ra, hãy xóa điểm cuối suy luận SageMaker được tạo cho suy luận LLaVA. Bạn có thể làm điều này bằng cách bỏ ghi chú bước dọn dẹp trong 3_rag_inference.ipynb và chạy ô hoặc bằng cách xóa điểm cuối thông qua bảng điều khiển SageMaker: chọn Sự suy luận và Điểm cuối trong ngăn điều hướng, sau đó chọn điểm cuối và xóa điểm cuối đó.
Kết luận
Các doanh nghiệp luôn tạo ra nội dung mới và các slide là một cơ chế phổ biến được sử dụng để chia sẻ và phổ biến thông tin trong nội bộ tổ chức và bên ngoài với khách hàng hoặc tại các hội nghị. Theo thời gian, thông tin phong phú có thể bị chôn vùi và ẩn giấu trong các phương thức phi văn bản như biểu đồ và bảng trong các bản trình chiếu này. Bạn có thể sử dụng giải pháp này và sức mạnh của FM đa phương thức như mô hình Titan Multimodal Embeddings và LLaVA để khám phá thông tin mới hoặc khám phá những quan điểm mới về nội dung trong các bản trình bày.
Chúng tôi khuyến khích bạn tìm hiểu thêm bằng cách khám phá Khởi động Amazon SageMaker, Mô hình Amazon Titan, Amazon Bedrock và OpenSearch Service cũng như xây dựng giải pháp bằng cách triển khai mẫu được cung cấp trong bài đăng này.
Hãy chú ý đến hai bài viết bổ sung như một phần của loạt bài này. Phần 2 trình bày một cách tiếp cận khác mà bạn có thể áp dụng để nói chuyện với bộ slide của mình. Cách tiếp cận này tạo và lưu trữ các suy luận LLaVA và sử dụng các suy luận được lưu trữ đó để trả lời các truy vấn của người dùng. Phần 3 so sánh hai cách tiếp cận.
Giới thiệu về tác giả
 Amit Arora là Kiến trúc sư chuyên gia về AI và ML tại Amazon Web Services, giúp khách hàng doanh nghiệp sử dụng các dịch vụ máy học dựa trên đám mây để nhanh chóng mở rộng quy mô đổi mới của họ. Ông cũng là giảng viên phụ trợ trong chương trình phân tích và khoa học dữ liệu MS tại Đại học Georgetown ở Washington DC
Amit Arora là Kiến trúc sư chuyên gia về AI và ML tại Amazon Web Services, giúp khách hàng doanh nghiệp sử dụng các dịch vụ máy học dựa trên đám mây để nhanh chóng mở rộng quy mô đổi mới của họ. Ông cũng là giảng viên phụ trợ trong chương trình phân tích và khoa học dữ liệu MS tại Đại học Georgetown ở Washington DC
 Manju Prasad là Kiến trúc sư giải pháp cấp cao phụ trách Tài khoản chiến lược tại Amazon Web Services. Cô tập trung vào việc cung cấp hướng dẫn kỹ thuật trong nhiều lĩnh vực khác nhau, bao gồm cả AI/ML cho khách hàng M&E nổi tiếng. Trước khi gia nhập AWS, cô đã thiết kế và xây dựng các giải pháp cho các công ty trong lĩnh vực dịch vụ tài chính cũng như cho các công ty khởi nghiệp.
Manju Prasad là Kiến trúc sư giải pháp cấp cao phụ trách Tài khoản chiến lược tại Amazon Web Services. Cô tập trung vào việc cung cấp hướng dẫn kỹ thuật trong nhiều lĩnh vực khác nhau, bao gồm cả AI/ML cho khách hàng M&E nổi tiếng. Trước khi gia nhập AWS, cô đã thiết kế và xây dựng các giải pháp cho các công ty trong lĩnh vực dịch vụ tài chính cũng như cho các công ty khởi nghiệp.
 Archana Inapudi là Kiến trúc sư giải pháp cấp cao tại AWS hỗ trợ khách hàng chiến lược. Cô có hơn một thập kỷ kinh nghiệm giúp khách hàng thiết kế và xây dựng các giải pháp cơ sở dữ liệu và phân tích dữ liệu. Cô đam mê sử dụng công nghệ để mang lại giá trị cho khách hàng và đạt được kết quả kinh doanh.
Archana Inapudi là Kiến trúc sư giải pháp cấp cao tại AWS hỗ trợ khách hàng chiến lược. Cô có hơn một thập kỷ kinh nghiệm giúp khách hàng thiết kế và xây dựng các giải pháp cơ sở dữ liệu và phân tích dữ liệu. Cô đam mê sử dụng công nghệ để mang lại giá trị cho khách hàng và đạt được kết quả kinh doanh.
 Antara Raisa là Kiến trúc sư giải pháp AI và ML tại Amazon Web Services hỗ trợ các khách hàng chiến lược có trụ sở tại Dallas, Texas. Cô cũng có kinh nghiệm làm việc trước đây với các đối tác doanh nghiệp lớn tại AWS, nơi cô làm Kiến trúc sư giải pháp thành công cho đối tác cho khách hàng kỹ thuật số gốc.
Antara Raisa là Kiến trúc sư giải pháp AI và ML tại Amazon Web Services hỗ trợ các khách hàng chiến lược có trụ sở tại Dallas, Texas. Cô cũng có kinh nghiệm làm việc trước đây với các đối tác doanh nghiệp lớn tại AWS, nơi cô làm Kiến trúc sư giải pháp thành công cho đối tác cho khách hàng kỹ thuật số gốc.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Có khả năng
- Giới thiệu
- truy cập
- truy cập
- Trợ Lý Giám Đốc
- Đạt được
- Hoạt động
- hành động
- hành vi
- thêm vào
- thêm vào
- phụ tá
- sự xuất hiện
- chống lại
- AI
- AI / ML
- Tất cả
- cho phép
- dọc theo
- Ngoài ra
- đàn bà gan dạ
- Amazon SageMaker
- Amazon Web Services
- an
- phân tích
- và
- Một
- trả lời
- trả lời
- câu trả lời
- bất kì
- api
- Đăng Nhập
- phương pháp tiếp cận
- cách tiếp cận
- kiến trúc
- LÀ
- AS
- xin
- Trợ lý
- liên kết
- At
- âm thanh
- tăng cường
- Xác thực
- có sẵn
- tránh
- AWS
- Hình thành đám mây AWS
- dựa
- BE
- được
- Hơn
- giữa
- Tỷ
- thân hình
- xây dựng
- Xây dựng
- xây dựng
- kinh doanh
- by
- CAN
- khả năng
- khả năng
- chụp
- pin
- thay đổi
- tải
- Chọn
- lựa chọn
- khách hàng
- mã
- bộ sưu tập
- bộ sưu tập
- thu
- Cột
- kết hợp
- kết hợp
- Bình luận
- Chung
- Các công ty
- so sánh
- so sánh
- so
- hoàn thành
- Hoàn thành
- các thành phần
- khái niệm
- hội nghị
- Cấu hình
- cấu hình
- bao gồm
- An ủi
- chứa
- chứa
- chứa
- nội dung
- tạo nội dung
- chuyển đổi
- chuyển đổi
- chuyển đổi
- Tương ứng
- có thể
- bìa
- tạo
- tạo ra
- tạo ra
- Tạo
- tạo
- Credentials
- khách hàng
- khách hàng
- Dallas
- bảng điều khiển
- trang tổng quan
- dữ liệu
- Phân tích dữ liệu
- khoa học dữ liệu
- Cơ sở dữ liệu
- thập kỷ
- boong
- Mặc định
- cung cấp
- cung cấp
- chứng minh
- Tùy
- triển khai
- triển khai
- triển khai
- triển khai
- mô tả
- Thiết kế
- thiết kế
- chi tiết
- chi tiết
- chi tiết
- sơ đồ
- DICT
- ĐÃ LÀM
- sự khác biệt
- khác nhau
- Lôi thôi
- kỹ thuật số
- kích thước
- kích thước
- khám phá
- thảo luận
- Giao diện
- do
- tài liệu
- làm
- lĩnh vực
- tải về
- Tải xuống
- suốt trong
- e
- mỗi
- các yếu tố
- nhúng
- nhúng
- cho phép
- kích hoạt
- mã hóa
- khuyến khích
- cuối
- Điểm cuối
- Động cơ
- đảm bảo
- Doanh nghiệp
- khách hàng doanh nghiệp
- lôi
- Ether (ETH)
- Sự kiện
- sự kiện
- Kiểm tra
- ví dụ
- Trừ
- ngoại lệ
- tồn tại
- kinh nghiệm
- Khám phá
- thêm
- bên ngoài
- trích xuất
- Tính quen thuộc
- Lĩnh vực
- Tập tin
- Các tập tin
- tài chính
- dịch vụ tài chính
- Tìm kiếm
- tập trung
- theo
- tiếp theo
- sau
- Trong
- hình thức
- định dạng
- Nền tảng
- 4
- Miễn phí
- từ
- Full
- đầy đủ
- tương lai
- tạo ra
- tạo ra
- tạo
- thế hệ
- thế hệ
- Trí tuệ nhân tạo
- Georgetown
- được
- GitHub
- đi
- đồ thị
- hướng dẫn
- Có
- he
- hữu ích
- giúp đỡ
- tại đây
- Thành viên ẩn danh
- cao hơn
- Số lượt truy cập
- chủ nhà
- tổ chức
- lưu trữ
- host
- Độ đáng tin của
- Tuy nhiên
- HTML
- http
- HTTPS
- Hub
- ÔmKhuôn Mặt
- i
- IAM
- Bản sắc
- if
- minh họa
- hình ảnh
- hình ảnh
- ngay
- thực hiện
- thực hiện
- thực hiện
- in
- bao gồm
- bao gồm
- Bao gồm
- chỉ số
- CHỈ SỐ
- thông tin
- sự đổi mới
- đổi mới
- đầu vào
- ví dụ
- trường hợp
- hướng dẫn
- tương tác
- tương tác
- nội bộ
- trong
- đầu tư
- IT
- tham gia
- jpg
- json
- tháng sáu
- Ngôn ngữ
- lớn
- Độ trễ
- phóng
- LEARN
- học tập
- giảng viên
- Lượt thích
- LINK
- Loài đà mã ở nam mỹ
- địa phương
- thấp hơn
- máy
- học máy
- làm cho
- quản lý
- quản lý
- nhiều
- Trận đấu
- phù hợp
- cơ chế
- Menu
- Siêu dữ liệu
- phương pháp
- ML
- phương thức
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- MS
- nhiều
- tên
- tự nhiên
- Điều hướng
- THÔNG TIN
- Cần
- Mới
- Không áp dụng
- ghi
- máy tính xách tay
- máy tính xách tay
- thông báo
- tại
- đánh số
- số
- đối tượng
- of
- cung cấp
- on
- Theo yêu cầu
- ONE
- có thể
- mở
- mã nguồn mở
- or
- cơ quan
- OS
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- kết quả
- đầu ra
- kết thúc
- cửa sổ
- tham số
- thông số
- một phần
- hạt
- đối tác
- Đối tác
- các bộ phận
- thông qua
- đam mê
- con đường
- mỗi
- thực hiện
- hiệu suất
- thực hiện
- quyền
- quan điểm
- giai đoạn
- Vật lý
- Những bức ảnh
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Chính sách
- Bài đăng
- bài viết
- có khả năng
- quyền lực
- mạnh mẽ
- Predictor
- trình bày
- trình bày
- trước
- Trước khi
- quá trình
- xử lý
- Quy trình
- xử lý
- chương trình
- tài sản
- cho
- cung cấp
- cung cấp
- cung cấp
- đặt
- quark
- truy vấn
- truy vấn
- câu hỏi
- Câu hỏi
- Nhanh chóng
- giẻ lau
- phạm vi
- nhanh chóng
- Reading
- sẵn sàng
- thế giới thực
- nhận
- tham khảo
- khu
- liên quan
- có liên quan
- vẫn
- thay thế
- yêu cầu
- cần phải
- Thông tin
- Trả lời
- phản ứng
- phản ứng
- kết quả
- kết quả
- Kết quả
- thu hồi
- trở lại
- Giàu
- vai trò
- chạy
- chạy
- nhà làm hiền triết
- Suy luận của SageMaker
- tương tự
- nói
- Quy mô
- Khoa học
- ảnh chụp màn hình
- kịch bản
- Tìm kiếm
- Thứ hai
- Phần
- phần
- ngành
- xem
- chọn
- lựa chọn
- cao cấp
- Trình tự
- Loạt Sách
- Không có máy chủ
- phục vụ
- dịch vụ
- DỊCH VỤ
- Phiên
- bộ
- thiết lập
- thiết lập
- Chia sẻ
- chị ấy
- nên
- thể hiện
- Chương trình
- tương tự
- Đơn giản
- đơn giản
- duy nhất
- Kích thước máy
- Trượt
- Slides
- đoạn
- So
- giải pháp
- Giải pháp
- một số
- nguồn
- chuyên gia
- riêng
- quy định
- ổn định
- ngăn xếp
- khởi động
- Tiểu bang
- Trạng thái
- Bước
- Các bước
- là gắn
- hàng
- lưu trữ
- cửa hàng
- Chiến lược
- Chuỗi
- tiếp theo
- thành công
- Thành công
- như vậy
- Hội nghị thượng đỉnh
- Hỗ trợ
- chắc chắn
- bàn
- Hãy
- Thảo luận
- nhiệm vụ
- Kỹ thuật
- Công nghệ
- mẫu
- mẫu
- thử nghiệm
- kiểm tra
- texas
- văn bản
- văn bản
- việc này
- Sản phẩm
- thông tin
- cung cấp their dịch
- sau đó
- Kia là
- điều này
- những
- thông lượng
- thời gian
- titan
- có tiêu đề
- đến
- hôm nay
- bên nhau
- toronto
- theo truyền thống
- đi qua
- kích hoạt
- kích hoạt
- đúng
- thử
- XOAY
- hai
- kiểu
- khám phá
- hiểu
- sự hiểu biết
- trường đại học
- Cập nhật
- tải lên
- URL
- sử dụng
- đã sử dụng
- người sử dang
- sử dụng
- sử dụng
- giá trị
- biến
- nhiều
- phiên bản
- thông qua
- Video
- Xem
- tầm nhìn
- trực quan
- Washington
- cách
- we
- web
- các dịch vụ web
- TỐT
- Điều gì
- Là gì
- cái nào
- trong khi
- sẽ
- với
- ở trong
- làm việc
- quy trình làm việc
- đang làm việc
- bạn
- trên màn hình
- zephyrnet