
Một mô hình trong một mô hình
Akyürek cho biết, trong cộng đồng nghiên cứu về học máy, nhiều nhà khoa học đã tin rằng các mô hình ngôn ngữ lớn có thể thực hiện việc học theo ngữ cảnh nhờ vào cách chúng được đào tạo. Ví dụ: GPT-3 có hàng trăm tỷ tham số và được đào tạo bằng cách đọc rất nhiều văn bản trên internet, từ các bài viết trên Wikipedia đến các bài đăng trên Reddit. Vì vậy, khi ai đó hiển thị các ví dụ mẫu của một nhiệm vụ mới, có thể họ đã thấy điều gì đó rất giống vì tập dữ liệu huấn luyện của nhiệm vụ đó bao gồm văn bản từ hàng tỷ trang web. Nó lặp lại các mô hình mà nó đã thấy trong quá trình huấn luyện thay vì học cách thực hiện các nhiệm vụ mới. Akyürek đưa ra giả thuyết rằng những người học trong ngữ cảnh không chỉ khớp với các khuôn mẫu đã thấy trước đó mà thay vào đó họ thực sự đang học cách thực hiện các nhiệm vụ mới. Anh ấy và những người khác đã thử nghiệm bằng cách đưa ra lời nhắc cho các mô hình này bằng cách sử dụng dữ liệu tổng hợp mà họ chưa từng thấy ở bất kỳ đâu trước đây và nhận thấy rằng các mô hình vẫn có thể học hỏi chỉ từ một vài ví dụ. Akyürek và các đồng nghiệp của ông nghĩ rằng có lẽ những mô hình mạng thần kinh này có các mô hình học máy nhỏ hơn bên trong mà các mô hình này có thể đào tạo để hoàn thành một nhiệm vụ mới. Ông nói: “Điều đó có thể giải thích gần như tất cả hiện tượng học tập mà chúng ta đã thấy với những mô hình lớn này”. Để kiểm tra giả thuyết này, các nhà nghiên cứu đã sử dụng mô hình mạng thần kinh được gọi là máy biến áp, có kiến trúc tương tự như GPT-3, nhưng đã được đào tạo đặc biệt để học trong ngữ cảnh. Bằng cách khám phá kiến trúc của máy biến áp này, về mặt lý thuyết, họ đã chứng minh rằng nó có thể viết một mô hình tuyến tính trong các trạng thái ẩn của nó. Mạng lưới thần kinh bao gồm nhiều lớp nút được kết nối với nhau để xử lý dữ liệu. Các trạng thái ẩn là các lớp nằm giữa lớp đầu vào và đầu ra. Các đánh giá toán học của họ cho thấy mô hình tuyến tính này được viết ở đâu đó trong các lớp đầu tiên của máy biến áp. Sau đó, máy biến áp có thể cập nhật mô hình tuyến tính bằng cách thực hiện các thuật toán học đơn giản. Về bản chất, mô hình mô phỏng và huấn luyện một phiên bản nhỏ hơn của chính nó.Thăm dò các lớp ẩn
Các nhà nghiên cứu đã khám phá giả thuyết này bằng cách sử dụng các thí nghiệm thăm dò, trong đó họ xem xét các lớp ẩn của máy biến áp để thử và thu hồi một lượng nhất định. “Trong trường hợp này, chúng tôi đã cố gắng khôi phục nghiệm thực tế cho mô hình tuyến tính và chúng tôi có thể chỉ ra rằng tham số được ghi ở trạng thái ẩn. Điều này có nghĩa là mô hình tuyến tính nằm ở đâu đó,” ông nói. Dựa trên công trình lý thuyết này, các nhà nghiên cứu có thể cho phép một máy biến áp thực hiện việc học trong ngữ cảnh bằng cách chỉ thêm hai lớp vào mạng lưới thần kinh. Akyürek cảnh báo, vẫn còn nhiều chi tiết kỹ thuật cần phải giải quyết trước khi thực hiện được điều đó, nhưng nó có thể giúp các kỹ sư tạo ra các mô hình có thể hoàn thành các nhiệm vụ mới mà không cần phải đào tạo lại với dữ liệu mới. Trong tương lai, Akyürek có kế hoạch tiếp tục khám phá việc học trong ngữ cảnh với các hàm phức tạp hơn các mô hình tuyến tính mà họ đã nghiên cứu trong nghiên cứu này. Họ cũng có thể áp dụng những thí nghiệm này cho các mô hình ngôn ngữ lớn để xem liệu hành vi của chúng có được mô tả bằng các thuật toán học đơn giản hay không. Ngoài ra, anh ấy muốn tìm hiểu sâu hơn về các loại dữ liệu huấn luyện trước có thể hỗ trợ việc học trong ngữ cảnh. “Với công việc này, giờ đây mọi người có thể hình dung cách những mô hình này có thể học hỏi từ các ví dụ điển hình. Vì vậy, tôi hy vọng nó sẽ thay đổi quan điểm của một số người về việc học tập trong bối cảnh,” Akyürek nói. “Những mô hình này không ngu ngốc như mọi người nghĩ. Họ không chỉ ghi nhớ những nhiệm vụ này. Họ có thể học các nhiệm vụ mới và chúng tôi đã chỉ ra cách thực hiện được điều đó.”- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.nanowerk.com/news2/robotics/newsid=62325.php
- 10
- 7
- 9
- a
- Có khả năng
- Giới thiệu
- hoàn thành
- thực sự
- Ngoài ra
- Sau
- alberta
- thuật toán
- thuật toán
- Tất cả
- Đã
- và
- bất cứ nơi nào
- Đăng Nhập
- kiến trúc
- xung quanh
- bài viết
- nhân tạo
- trí tuệ nhân tạo
- Trợ lý
- tác giả
- tác giả
- bởi vì
- trước
- sau
- Tin
- Hơn
- giữa
- tỷ
- Một chút
- Brain
- Xây dựng
- gọi là
- có khả năng
- trường hợp
- nhất định
- Những thay đổi
- mã
- đồng nghiệp
- thu thập
- Đến
- cộng đồng
- hoàn thành
- phức tạp
- sáng tác
- máy tính
- Khoa học Máy tính
- máy tính
- Hội nghị
- tập đoàn
- tiếp tục
- có thể
- tạo
- CSAIL
- tò mò
- dữ liệu
- Ngày
- sâu sắc hơn
- bộ
- mô tả
- Mặc dù
- chi tiết
- ĐÀO
- Giám đốc
- dont
- Cửa
- suốt trong
- kỹ thuật điện
- cho phép
- Kỹ Sư
- Kỹ sư
- bản chất
- đánh giá
- ví dụ
- ví dụ
- thú vị
- Giải thích
- thăm dò
- Khám phá
- Khám phá
- vài
- cố định
- Forward
- tìm thấy
- từ
- chức năng
- tạo ra
- Cho
- Cho
- tốt nghiệp
- giúp đỡ
- Thành viên ẩn danh
- mong
- Độ đáng tin của
- HTTPS
- lớn
- Hàng trăm
- thực hiện
- thực hiện
- quan trọng
- in
- bao gồm
- thông tin
- đầu vào
- ví dụ
- thay vì
- Sự thông minh
- kết nối với nhau
- Quốc Tế
- Internet
- Điều tra
- IT
- chính nó
- tham gia
- nổi tiếng
- phòng thí nghiệm
- Ngôn ngữ
- lớn
- lớn hơn
- lớp
- dẫn
- LEARN
- học tập
- Có khả năng
- nhìn
- nhiều
- lớn
- phù hợp
- toán học
- có nghĩa
- hội viên
- MIT
- kiểu mẫu
- mô hình
- chi tiết
- di chuyển
- Trinh thám
- Cần
- tiêu cực
- mạng
- mạng
- Thần kinh
- mạng lưới thần kinh
- mạng thần kinh
- Mới
- tiếp theo
- các nút
- mở ra
- Khác
- Giấy
- tham số
- thông số
- mô hình
- người
- của người dân
- thực hiện
- có lẽ
- hiện tượng
- kế hoạch
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Thơ
- tích cực
- có thể
- bài viết
- dự đoán
- trình bày
- khá
- trước đây
- Hiệu trưởng
- quá trình
- Quy trình
- Giáo sư
- Lập trình
- chứng minh
- số lượng, lượng
- Reading
- Phục hồi
- vẫn
- nghiên cứu
- Cộng đồng nghiên cứu
- nhà nghiên cứu
- Kết quả
- đào tạo lại
- tương tự
- nói
- Khoa học
- Nhà khoa học
- các nhà khoa học
- nhìn thấy
- dường như
- cao cấp
- kết án
- tình cảm
- một số
- hiển thị
- thể hiện
- Chương trình
- tương tự
- Đơn giản
- nhỏ
- nhỏ hơn
- So
- giải pháp
- Giải quyết
- một số
- Một người nào đó
- một cái gì đó
- một nơi nào đó
- đặc biệt
- stanford
- Đại học Stanford
- Bang
- số liệu thống kê
- Bước
- Vẫn còn
- Sinh viên
- nghiên cứu
- sợi tổng hợp
- dữ liệu tổng hợp
- Hãy
- Nhiệm vụ
- nhiệm vụ
- Kỹ thuật
- thử nghiệm
- Sản phẩm
- cung cấp their dịch
- lý thuyết
- nghĩ
- đến
- đối với
- Train
- đào tạo
- Hội thảo
- tàu hỏa
- loại
- thường
- sự hiểu biết
- trường đại học
- Cập nhật
- cập nhật
- Cập nhật
- cập nhật
- phiên bản
- Lượt xem
- trang web
- Điều gì
- liệu
- cái nào
- Wikipedia
- sẽ
- ở trong
- không có
- Công việc
- tập thể dục
- sẽ
- viết
- viết
- X
- zephyrnet
Thêm từ công trình nano
Phát hiện các hạt nano có nguồn gốc từ tế bào ung thư nhờ ánh sáng laser siêu hiệu quả
Nút nguồn: 2919767
Dấu thời gian: Tháng Mười 6, 2023
Sử dụng vật liệu nano rẻ tiền để lọc carbon dioxide từ khí thải công nghiệp
Nút nguồn: 2753630
Dấu thời gian: Tháng Bảy 6, 2023

Băng 'thông minh' theo dõi vết thương và cung cấp phương pháp điều trị có mục tiêu
Nút nguồn: 2538905
Dấu thời gian: Tháng 24, 2023
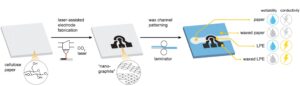
Kỹ thuật graphen hóa do laser gây ra thúc đẩy các đường dẫn điện trong các thiết bị dựa trên giấy vi lỏng
Nút nguồn: 2724415
Dấu thời gian: Tháng Sáu 15, 2023

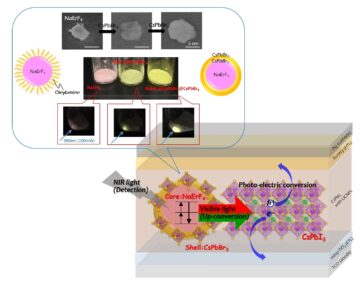
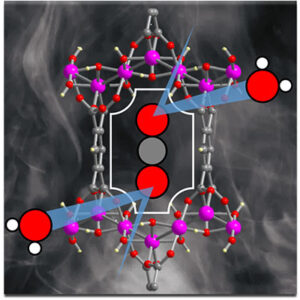
Phương pháp phát hiện ánh sáng cận hồng ngoại mới sử dụng vật liệu nano chuyển đổi ngược
Nút nguồn: 1790812
Dấu thời gian: Tháng Mười Hai 23, 2022
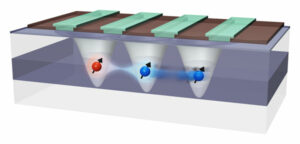
Kết nối các qubit silicon ở xa để nhân rộng máy tính lượng tử
Nút nguồn: 2559199
Dấu thời gian: Tháng 31, 2023
Thảm gel lắc lư giúp các tế bào cơ hoạt động cùng nhau
Nút nguồn: 2946503
Dấu thời gian: Tháng Mười 20, 2023
Các hạt nano giúp biến ánh sáng thành các electron hòa tan dễ dàng hơn
Nút nguồn: 1905538
Dấu thời gian: Jan 17, 2023

Vi khuẩn ưa kim loại có thể thay thế quá trình xử lý đất hiếm bằng hóa chất
Nút nguồn: 2914288
Dấu thời gian: Tháng Mười 2, 2023

Tia laser cường độ cao chiếu ánh sáng mới vào động lực điện tử của chất lỏng
Nút nguồn: 2911792
Dấu thời gian: Tháng Chín 28, 2023