Thời gian chạy Amazon EMR cho Apache Spark là thời gian chạy được tối ưu hóa hiệu năng cho Apache Spark, tương thích 100% API với Apache Spark nguồn mở. Với Amazon EMR phát hành 6.9.0, thời gian chạy EMR cho Apache Spark hỗ trợ phiên bản Spark 3.3.0 tương đương.
Với Amazon EMR 6.9.0, giờ đây bạn có thể chạy các ứng dụng Apache Spark 3.x của mình nhanh hơn với chi phí thấp hơn mà không yêu cầu bất kỳ thay đổi nào đối với ứng dụng của mình. Trong các thử nghiệm điểm chuẩn hiệu suất của chúng tôi, bắt nguồn từ các thử nghiệm hiệu suất TPC-DS ở quy mô 3 TB, chúng tôi nhận thấy thời gian chạy EMR cho Apache Spark 3.3.0 cung cấp mức cải thiện hiệu suất trung bình 3.5 lần (sử dụng tổng thời gian chạy) so với Apache Spark 3.3.0 nguồn mở. XNUMX.
Trong bài đăng này, chúng tôi phân tích kết quả từ các bài kiểm tra điểm chuẩn chạy ứng dụng TPC-DS trên Apache Spark mã nguồn mở và sau đó là Amazon EMR 6.9, đi kèm với thời gian chạy Spark được tối ưu hóa tương thích với Spark nguồn mở. Chúng tôi đi qua phân tích chi phí chi tiết và cuối cùng cung cấp hướng dẫn từng bước để chạy điểm chuẩn.
Kết quả quan sát được
Để đánh giá các cải tiến về hiệu suất, chúng tôi đã sử dụng tiện ích kiểm tra hiệu suất Spark nguồn mở có nguồn gốc từ bộ công cụ kiểm tra hiệu suất TPC-DS. Chúng tôi đã chạy thử nghiệm trên cụm EMR c5d.9xlarge bảy nút (sáu nút lõi và một nút chính) với thời gian chạy EMR cho Apache Spark và cụm tự quản lý bảy nút thứ hai trên Đám mây điện toán đàn hồi Amazon (Amazon EC2) với phiên bản nguồn mở tương đương của Spark. Chúng tôi đã chạy cả hai thử nghiệm với dữ liệu trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3).
Phân bổ tài nguyên động (DRA) là một tính năng tuyệt vời để sử dụng cho các khối lượng công việc khác nhau. Tuy nhiên, đối với bài tập đo điểm chuẩn trong đó chúng tôi so sánh hai nền tảng hoàn toàn dựa trên hiệu suất và khối lượng dữ liệu thử nghiệm không thay đổi (trong trường hợp của chúng tôi là 3 TB), chúng tôi tin rằng tốt nhất là nên tránh sự thay đổi để chạy so sánh giữa các ứng dụng. Trong các thử nghiệm của chúng tôi ở cả Spark nguồn mở và Amazon EMR, chúng tôi đã tắt DRA trong khi chạy ứng dụng đo điểm chuẩn.
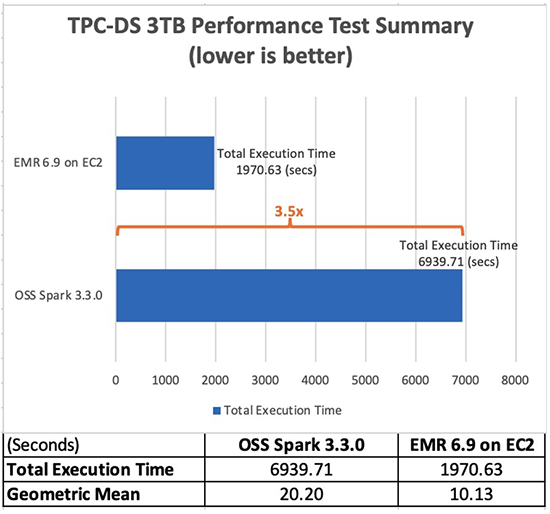
Bảng sau đây hiển thị tổng thời gian chạy công việc cho tất cả truy vấn (tính bằng giây) trong bộ dữ liệu truy vấn 3 TB giữa Amazon EMR phiên bản 6.9.0 và Spark nguồn mở phiên bản 3.3.0. Chúng tôi quan sát thấy rằng các thử nghiệm TPC-DS của chúng tôi có tổng thời gian chạy công việc trên Amazon EMR trên Amazon EC2 nhanh hơn 3.5 lần so với thời gian sử dụng cụm Spark nguồn mở có cùng cấu hình.
Tốc độ tăng tốc mỗi truy vấn trên Amazon EMR 6.9 có và không có thời gian chạy EMR cho Apache Spark được minh họa trong biểu đồ sau. Trục ngang hiển thị từng truy vấn trong điểm chuẩn 3 TB. Trục dọc hiển thị tốc độ tăng tốc của từng truy vấn do thời gian chạy EMR. Mức tăng hiệu suất đáng chú ý nhanh hơn 10 lần đối với các truy vấn TPC-DS 24b, 72, 95 và 96.

Phân tích chi phí
Các cải tiến hiệu suất của thời gian chạy EMR cho Apache Spark trực tiếp chuyển thành chi phí thấp hơn. Chúng tôi đã có thể tiết kiệm được 67% chi phí khi chạy ứng dụng điểm chuẩn trên Amazon EMR so với chi phí phát sinh khi chạy cùng một ứng dụng trên Spark nguồn mở trên Amazon EC2 với cùng kích thước cụm nhờ giảm số giờ sử dụng Amazon EMR và Amazon Sử dụng EC2. Giá Amazon EMR dành cho các ứng dụng EMR chạy trên các cụm EMR với phiên bản EC2. Giá Amazon EMR được thêm vào giá điện toán và lưu trữ cơ bản, chẳng hạn như giá phiên bản EC2 và Cửa hàng đàn hồi Amazon (Amazon EBS) chi phí (nếu đính kèm khối lượng EBS). Nhìn chung, chi phí điểm chuẩn ước tính ở Khu vực Miền Đông Hoa Kỳ (Bắc Virginia) là 27.01 USD/lần chạy đối với Spark nguồn mở trên Amazon EC2 và 8.82 USD/lần chạy đối với Amazon EMR.
| Công việc chuẩn | Thời gian chạy (Giờ) | Chi phí ước tính | Tổng số phiên bản EC2 | Tổng số vCPU | Tổng bộ nhớ (GiB) | Thiết bị gốc (Amazon EBS) |
|
Spark mã nguồn mở trên Amazon EC2 (1 nút chính và 6 nút lõi) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR trên Amazon EC2 (1 nút chính và 6 nút lõi) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Phân tích chi phí
Sau đây là bảng phân tích chi phí cho công việc Spark nguồn mở trên Amazon EC2 ($27.01):
- Tổng chi phí Amazon EC2 – (7 * $1.728 * 2.23) = (số lượng phiên bản * c5d.9xlarge tỷ lệ hàng giờ * thời gian chạy công việc tính bằng giờ) = $26.97
- Chi phí Amazon EBS – ($0.1/730 * 20 * 7 * 2.23) = (Amazon EBS trên mỗi GB-tỷ lệ giờ * kích thước EBS gốc * số phiên bản * thời gian chạy công việc tính bằng giờ) = $0.042
Sau đây là chi tiết chi phí cho công việc Amazon EMR trên Amazon EC2 ($8.82):
- Tổng chi phí Amazon EMR – (7 * 0.27 USD * 0.63) = ((số nút lõi + số nút chính)* c5d.9xlarge Giá Amazon EMR * thời gian chạy công việc tính bằng giờ) = 1.19 USD
- Tổng chi phí Amazon EC2 – (7 * 1.728 USD * 0.63) = ((số nút lõi + số nút chính)* giá phiên bản c5d.9xlarge * thời gian chạy tác vụ trong giờ) = 7.62 USD
- Chi phí Amazon EBS – ($0.1/730 * 20 GiB * 7 * 0.63) = (Amazon EBS trên GB-tỷ lệ giờ * kích thước EBS * số phiên bản * thời gian chạy công việc tính bằng giờ) = $0.012
Thiết lập điểm chuẩn OSS Spark
Trong các phần sau, chúng tôi cung cấp một phác thảo ngắn gọn về các bước liên quan đến việc thiết lập điểm chuẩn. Để biết hướng dẫn chi tiết với các ví dụ, hãy tham khảo Repo GitHub.
Đối với điểm chuẩn OSS Spark của chúng tôi, chúng tôi sử dụng công cụ mã nguồn mở đá lửa để khởi chạy dựa trên Amazon EC2 của chúng tôi Apache Spark cụm. Flintrock cung cấp một cách nhanh chóng để khởi chạy cụm Apache Spark trên Amazon EC2 bằng cách sử dụng dòng lệnh.
Điều kiện tiên quyết
Hoàn thành các bước điều kiện tiên quyết sau:
- Có Python 3.7.x trở lên.
- Có Pip3 22.2.2 trở lên.
- Thêm thư mục bin Python vào đường dẫn môi trường của bạn. Tệp nhị phân Flintrock sẽ được cài đặt trong đường dẫn này.
- chạy
aws configuređể định cấu hình của bạn Giao diện dòng lệnh AWS (AWS CLI) shell để trỏ đến tài khoản đo điểm chuẩn. tham khảo Cấu hình nhanh với cấu hình aws để được hướng dẫn. - Có một cặp chìa khóa với quyền truy cập tệp hạn chế để truy cập nút chính OSS Spark.
- Tạo vùng chứa S3 mới trong tài khoản thử nghiệm của bạn nếu cần.
- Sao chép dữ liệu nguồn TPC-DS làm đầu vào vào bộ chứa S3 của bạn.
- Xây dựng ứng dụng điểm chuẩn theo các bước được cung cấp trong Các bước xây dựng ứng dụng spark-benchmark-assembly. Ngoài ra, bạn có thể tải xuống bản dựng sẵn spark-điểm chuẩn-hội-3.3.0.jar nếu bạn muốn có một ứng dụng dựa trên Spark 3.3.0.
Triển khai cụm Spark và chạy công việc chuẩn
Hoàn thành các bước sau:
- Cài đặt công cụ Flintrock qua pip như trong Các bước thiết lập OSS Spark Benchmarking.
- Chạy lệnh cấu hình flintrock, sẽ bật lên tệp cấu hình mặc định.
- Sửa đổi mặc định
config.yamltập tin dựa trên nhu cầu của bạn. Ngoài ra, sao chép và dán tập tin config.yaml nội dung vào tệp cấu hình mặc định. Sau đó lưu tập tin vào vị trí của nó. - Cuối cùng, khởi chạy cụm Spark 7 nút trên Amazon EC2 thông qua Flintrock.
Điều này sẽ tạo ra một cụm Spark với một nút chính và sáu nút công nhân. Nếu bạn thấy bất kỳ thông báo lỗi nào, hãy kiểm tra kỹ các giá trị của tệp cấu hình, đặc biệt là các phiên bản Spark và Hadoop cũng như các thuộc tính của nguồn tải xuống và AMI.
Cụm OSS Spark không đi kèm với trình quản lý tài nguyên YARN. Để kích hoạt nó, chúng ta cần cấu hình cụm.
- Tải về Sợi-site.xml và enable-sợi.sh các tệp từ repo GitHub.
- Thay thế với địa chỉ IP của nút chính trong cụm Flintrock của bạn.
Bạn có thể truy xuất địa chỉ IP từ bảng điều khiển Amazon EC2.
- Tải tệp lên tất cả các nút của cụm Spark.
- Chạy tập lệnh kích hoạt sợi.
- Bật hỗ trợ Snappy trong Hadoop (công việc chuẩn đọc dữ liệu nén Snappy).
- Tải xuống tệp JAR của ứng dụng tiện ích điểm chuẩn spark-điểm chuẩn-hội-3.3.0.jar vào máy cục bộ của bạn.
- Sao chép tệp này vào cụm.
- Đăng nhập vào nút chính và bắt đầu YARN.
- Gửi công việc điểm chuẩn trên cụm Spark nguồn mở như trong Gửi công việc điểm chuẩn.
Tóm tắt kết quả
Tải xuống tệp kết quả kiểm tra từ bộ chứa S3 đầu ra s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Thay thế $YOUR_S3_BUCKET với tên bộ chứa S3 của bạn.) Bạn có thể sử dụng bảng điều khiển Amazon S3 và điều hướng đến vị trí đầu ra của S3 hoặc sử dụng AWS CLI.
Ứng dụng điểm chuẩn Spark tạo thư mục dấu thời gian và ghi tệp tóm tắt bên trong tiền tố summary.csv. Dấu thời gian và tên tệp của bạn sẽ khác với tên được hiển thị trong ví dụ trước.
Các tệp CSV đầu ra có bốn cột không có tên tiêu đề. Họ đang:
- Tên truy vấn
- thời gian trung bình
- Thời gian tối thiểu
- Thời gian tối đa
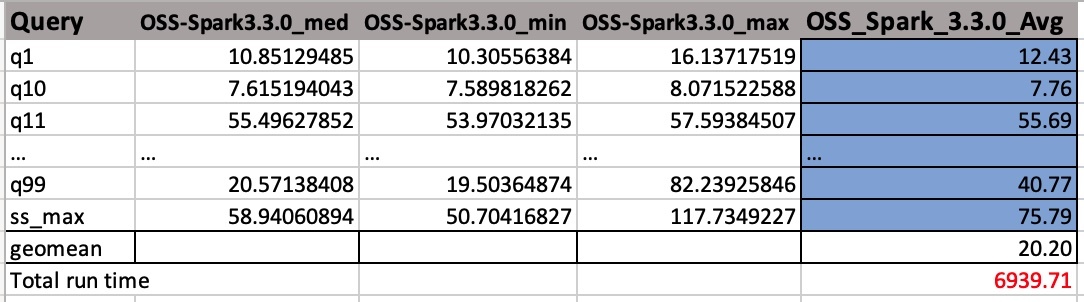
Ảnh chụp màn hình sau đây hiển thị một đầu ra mẫu. Chúng tôi đã thêm tên cột theo cách thủ công. Cách chúng tôi tính trung bình địa lý và tổng thời gian chạy công việc dựa trên các phương tiện số học. Trước tiên, chúng tôi lấy giá trị trung bình của các giá trị trung bình, tối thiểu và tối đa bằng cách sử dụng công thức TRUNG BÌNH(B2:D2). Sau đó, chúng tôi lấy giá trị trung bình hình học của cột Trung bình bằng cách sử dụng công thức GEOMEAN(E2:E105).
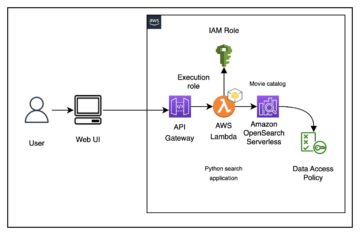
Thiết lập điểm chuẩn Amazon EMR
Để biết hướng dẫn chi tiết, xem Các bước thiết lập EMR Benchmarking.
Điều kiện tiên quyết
Hoàn thành các bước điều kiện tiên quyết sau:
- chạy
aws configuređể định cấu hình trình bao AWS CLI của bạn để trỏ đến tài khoản đo điểm chuẩn. tham khảo Cấu hình nhanh với cấu hình aws để được hướng dẫn. - Tải ứng dụng điểm chuẩn lên Amazon S3.
Triển khai cụm EMR và chạy công việc chuẩn
Hoàn thành các bước sau:
- Khởi động Amazon EMR trong trình bao AWS CLI của bạn bằng cách sử dụng dòng lệnh như minh họa trong Triển khai EMR Cluster và chạy công việc chuẩn.
- Định cấu hình Amazon EMR với một nút chính (c5d.9xlarge) và sáu nút lõi (c5d.9xlarge). tham khảo tạo cụm để biết mô tả chi tiết về các tùy chọn AWS CLI.
- Lưu trữ ID cụm từ phản hồi. Bạn cần điều này trong bước tiếp theo.
- Gửi tác vụ điểm chuẩn trong Amazon EMR bằng cách sử dụng các bước bổ sung trong AWS CLI.
Tóm tắt kết quả
Tóm tắt kết quả từ thùng đầu ra s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT theo cách tương tự như chúng tôi đã làm đối với các kết quả PMNM và so sánh.
Làm sạch
Để tránh bị tính phí trong tương lai, hãy xóa các tài nguyên bạn đã tạo theo hướng dẫn trong Phần dọn dẹp của repo GitHub.
- Dừng cụm EMR và OSS Spark. Bạn cũng có thể xóa chúng nếu không muốn giữ lại nội dung. Bạn có thể xóa các tài nguyên này bằng cách chạy tập lệnh dọn dẹp-điểm chuẩn-env.sh từ một thiết bị đầu cuối trong môi trường điểm chuẩn của bạn.
- Nếu bạn đã sử dụng Đám mây AWS9 làm IDE của bạn để xây dựng tệp JAR ứng dụng điểm chuẩn bằng cách sử dụng Các bước xây dựng ứng dụng spark-benchmark-assembly, bạn cũng có thể muốn xóa môi trường.
Kết luận
Bạn có thể chạy khối lượng công việc Apache Spark của mình nhanh hơn 3.5 lần (dựa trên tổng thời gian chạy) với chi phí thấp hơn mà không cần thực hiện bất kỳ thay đổi nào đối với ứng dụng của mình bằng cách sử dụng Amazon EMR 6.9.0.
Để cập nhật thông tin, hãy đăng ký Blog Dữ liệu lớn RSS feed để tìm hiểu thêm về thời gian chạy EMR cho Apache Spark, các phương pháp hay nhất về cấu hình và lời khuyên điều chỉnh.
Đối với các bài kiểm tra điểm chuẩn trước đây, xem Chạy khối lượng công việc Apache Spark 3.0 nhanh hơn 1.7 lần với thời gian chạy Amazon EMR dành cho Apache Spark. Lưu ý rằng kết quả điểm chuẩn trước đây về hiệu suất gấp 1.7 lần dựa trên giá trị trung bình hình học. Dựa trên giá trị trung bình hình học, hiệu suất trong Amazon EMR 6.9 nhanh hơn hai lần.
Giới thiệu về tác giả
 Sekar Srinivasan là một Kiến trúc sư Giải pháp Chuyên gia Sr. tại AWS, tập trung vào Dữ liệu lớn và Phân tích. Sekar có hơn 20 năm kinh nghiệm làm việc với dữ liệu. Anh ấy đam mê giúp khách hàng xây dựng các giải pháp có thể mở rộng hiện đại hóa kiến trúc của họ và tạo ra thông tin chi tiết từ dữ liệu của họ. Trong thời gian rảnh rỗi, anh ấy thích làm việc cho các dự án phi lợi nhuận, đặc biệt là những dự án tập trung vào giáo dục trẻ em kém may mắn.
Sekar Srinivasan là một Kiến trúc sư Giải pháp Chuyên gia Sr. tại AWS, tập trung vào Dữ liệu lớn và Phân tích. Sekar có hơn 20 năm kinh nghiệm làm việc với dữ liệu. Anh ấy đam mê giúp khách hàng xây dựng các giải pháp có thể mở rộng hiện đại hóa kiến trúc của họ và tạo ra thông tin chi tiết từ dữ liệu của họ. Trong thời gian rảnh rỗi, anh ấy thích làm việc cho các dự án phi lợi nhuận, đặc biệt là những dự án tập trung vào giáo dục trẻ em kém may mắn.
 Prabu Ravichandran là Kiến trúc sư dữ liệu cấp cao của Amazon Web Services, tập trung vào Analytics, kiến trúc và triển khai Data Lake. Anh ấy giúp khách hàng thiết kế kiến trúc và xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng các dịch vụ AWS. Khi rảnh rỗi, Prabu thích đi du lịch và dành thời gian cho gia đình.
Prabu Ravichandran là Kiến trúc sư dữ liệu cấp cao của Amazon Web Services, tập trung vào Analytics, kiến trúc và triển khai Data Lake. Anh ấy giúp khách hàng thiết kế kiến trúc và xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng các dịch vụ AWS. Khi rảnh rỗi, Prabu thích đi du lịch và dành thời gian cho gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 năm
- 7
- 9
- a
- Có khả năng
- Giới thiệu
- ở trên
- truy cập
- Tài khoản
- thêm
- địa chỉ
- tư vấn
- Tất cả
- phân bổ
- đàn bà gan dạ
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- phân tích
- phân tích
- phân tích
- và
- Apache
- Apache Spark
- api
- Các Ứng Dụng
- các ứng dụng
- kiến trúc
- thuộc tính
- Trung bình cộng
- AVG
- AWS
- Trục
- dựa
- Tin
- điểm chuẩn
- BEST
- thực hành tốt nhất
- giữa
- lớn
- Dữ Liệu Lớn.
- Chặn
- Breakdown
- xây dựng
- Xây dựng
- trường hợp
- thay đổi
- Những thay đổi
- tải
- Biểu đồ
- cụm
- Cột
- Cột
- Đến
- so sánh
- sự so sánh
- tương thích
- Tính
- Cấu hình
- An ủi
- nội dung
- Trung tâm
- Phí Tổn
- tiết kiệm chi phí
- Chi phí
- tạo
- tạo ra
- tạo ra
- khách hàng
- dữ liệu
- Hồ dữ liệu
- Ngày
- Mặc định
- Nguồn gốc
- Mô tả
- chi tiết
- thiết bị
- ĐÃ LÀM
- khác nhau
- trực tiếp
- bị vô hiệu hóa
- Không
- dont
- tải về
- mỗi
- Đông
- ebs
- Đào tạo
- cho phép
- Môi trường
- Tương đương
- lôi
- đặc biệt
- ước tính
- Ether (ETH)
- đánh giá
- ví dụ
- ví dụ
- Tập thể dục
- kinh nghiệm
- gia đình
- nhanh hơn
- Đặc tính
- Tập tin
- Các tập tin
- Cuối cùng
- Tên
- tập trung
- tập trung xem
- tiếp theo
- công thức
- tìm thấy
- Miễn phí
- từ
- tương lai
- thu nhập
- tạo ra
- GitHub
- tuyệt vời
- Hadoop
- giúp đỡ
- giúp
- Ngang
- GIỜ LÀM VIỆC
- Tuy nhiên
- HTML
- HTTPS
- thực hiện
- cải thiện
- cải tiến
- in
- đầu vào
- những hiểu biết
- ví dụ
- hướng dẫn
- tham gia
- IP
- Địa chỉ IP
- IT
- Việc làm
- Giữ
- hồ
- phóng
- LEARN
- Dòng
- địa phương
- địa điểm thư viện nào
- máy
- Làm
- giám đốc
- cách thức
- thủ công
- tối đa
- có nghĩa
- Bộ nhớ
- tin nhắn
- chi tiết
- tên
- tên
- Điều hướng
- Cần
- cần thiết
- nhu cầu
- Mới
- tiếp theo
- nút
- các nút
- phi lợi nhuận
- Nổi bật
- con số
- ONE
- mã nguồn mở
- tối ưu hóa
- Các lựa chọn
- gọi món
- Oss
- đề cương
- tổng thể
- đam mê
- qua
- con đường
- hiệu suất
- quyền
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- Rất tiếc
- Bài đăng
- thực hành
- giá
- Giá
- giá
- chính
- riêng
- dự án
- cho
- cung cấp
- cung cấp
- hoàn toàn
- Python
- Nhanh chóng
- Tỷ lệ
- nhận ra
- Giảm
- khu
- phát hành
- thay thế
- tài nguyên
- Thông tin
- phản ứng
- Hạn chế
- kết quả
- Kết quả
- mạnh mẽ
- nguồn gốc
- chạy
- chạy
- tương tự
- Lưu
- Tiết kiệm
- khả năng mở rộng
- Quy mô
- Thứ hai
- giây
- Phần
- phần
- cao cấp
- DỊCH VỤ
- thiết lập
- thiết lập
- Shell
- nên
- thể hiện
- Chương trình
- Đơn giản
- Six
- Kích thước máy
- Giải pháp
- nguồn
- Spark
- chuyên gia
- Chi
- Bắt đầu
- Bước
- Các bước
- là gắn
- đăng ký
- như vậy
- TÓM TẮT
- hỗ trợ
- Hỗ trợ
- bàn
- Hãy
- Thiết bị đầu cuối
- thử nghiệm
- kiểm tra
- Sản phẩm
- cung cấp their dịch
- Thông qua
- thời gian
- thời gian
- dấu thời gian
- đến
- công cụ
- bộ công cụ
- Tổng số:
- dịch
- Đi du lịch
- cơ bản
- kém may mắn
- us
- Sử dụng
- sử dụng
- tiện ích
- Các giá trị
- phiên bản
- thông qua
- virginia
- khối lượng
- web
- các dịch vụ web
- cái nào
- trong khi
- sẽ
- không có
- Công việc
- công nhân
- đang làm việc
- X
- XML
- khoai mỡ
- năm
- trên màn hình
- zephyrnet