Trong thời đại kỹ thuật số ngày nay, dữ liệu là trung tâm thành công của mọi tổ chức. Một trong những định dạng được sử dụng phổ biến nhất để trao đổi dữ liệu là XML. Việc phân tích các tệp XML rất quan trọng vì nhiều lý do. Thứ nhất, các tệp XML được sử dụng trong nhiều ngành, bao gồm tài chính, y tế và chính phủ. Việc phân tích tệp XML có thể giúp các tổ chức hiểu rõ hơn về dữ liệu của họ, cho phép họ đưa ra quyết định tốt hơn và cải thiện hoạt động của mình. Việc phân tích các tệp XML cũng có thể giúp tích hợp dữ liệu vì nhiều ứng dụng và hệ thống sử dụng XML làm định dạng dữ liệu tiêu chuẩn. Bằng cách phân tích các tệp XML, các tổ chức có thể dễ dàng tích hợp dữ liệu từ các nguồn khác nhau và đảm bảo tính nhất quán trên các hệ thống của họ. Tuy nhiên, các tệp XML chứa dữ liệu có cấu trúc bán cấu trúc, lồng nhau cao, gây khó khăn cho việc truy cập và phân tích thông tin, đặc biệt nếu tệp lớn và có dung lượng lớn. lược đồ phức tạp, lồng nhau cao.
Các tệp XML rất phù hợp cho các ứng dụng nhưng chúng có thể không tối ưu cho các công cụ phân tích. Để nâng cao hiệu suất truy vấn và cho phép truy cập dễ dàng vào các công cụ phân tích xuôi dòng như amazon Athena, điều quan trọng là phải xử lý trước các tệp XML thành định dạng cột như Parquet. Việc chuyển đổi này cho phép cải thiện hiệu quả và khả năng sử dụng trong quy trình phân tích. Trong bài đăng này, chúng tôi trình bày cách xử lý dữ liệu XML bằng cách sử dụng Keo AWS và Athena.
Tổng quan về giải pháp
Chúng tôi khám phá hai kỹ thuật riêng biệt có thể hợp lý hóa quy trình xử lý tệp XML của bạn:
- Kỹ thuật 1: Sử dụng trình thu thập thông tin AWS Glue và trình chỉnh sửa trực quan AWS Glue – Bạn có thể sử dụng giao diện người dùng AWS Glue kết hợp với trình thu thập thông tin để xác định cấu trúc bảng cho các tệp XML của mình. Cách tiếp cận này cung cấp giao diện thân thiện với người dùng và đặc biệt phù hợp với những cá nhân thích cách tiếp cận đồ họa để quản lý dữ liệu của họ.
- Kỹ thuật 2: Sử dụng AWS Glue DynamicFrames với các lược đồ suy luận và cố định – Trình thu thập thông tin có hạn chế khi xử lý một hàng trong các tệp XML lớn hơn 1 MB. Để khắc phục hạn chế này, chúng tôi sử dụng sổ tay AWS Glue để xây dựng AWS Glue
DynamicFrames, sử dụng cả lược đồ suy luận và lược đồ cố định. Phương pháp này đảm bảo xử lý hiệu quả các tệp XML có hàng có kích thước vượt quá 1 MB.
Trong cả hai cách tiếp cận, mục tiêu cuối cùng của chúng tôi là chuyển đổi các tệp XML sang định dạng Apache Parquet, làm cho chúng sẵn sàng để truy vấn bằng Athena. Với những kỹ thuật này, bạn có thể nâng cao tốc độ xử lý và khả năng truy cập dữ liệu XML của mình, cho phép bạn rút ra những hiểu biết có giá trị một cách dễ dàng.
Điều kiện tiên quyết
Trước khi bạn bắt đầu hướng dẫn này, hãy hoàn thành các điều kiện tiên quyết sau (áp dụng cho cả hai kỹ thuật):
- Tải xuống các tệp XML kỹ thuật1.xml và kỹ thuật2.xml.
- Tải các tập tin lên một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Bạn có thể tải chúng lên cùng một vùng lưu trữ S3 trong các thư mục khác nhau hoặc lên các vùng lưu trữ S3 khác nhau.
- tạo một Quản lý truy cập và nhận dạng AWS (IAM) cho công việc hoặc sổ ghi chép ETL của bạn như được hướng dẫn trong Thiết lập quyền IAM cho AWS Glue Studio.
- Thêm chính sách nội tuyến vào vai trò của bạn bằng iam:PassRole hoạt động:
- Thêm chính sách quyền cho vai trò có quyền truy cập vào nhóm S3 của bạn.
Bây giờ chúng ta đã hoàn thành các điều kiện tiên quyết, hãy chuyển sang triển khai kỹ thuật đầu tiên.
Kỹ thuật 1: Sử dụng trình thu thập thông tin AWS Glue và trình chỉnh sửa trực quan
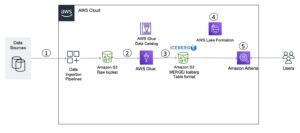
Sơ đồ sau minh họa kiến trúc đơn giản mà bạn có thể sử dụng để triển khai giải pháp.
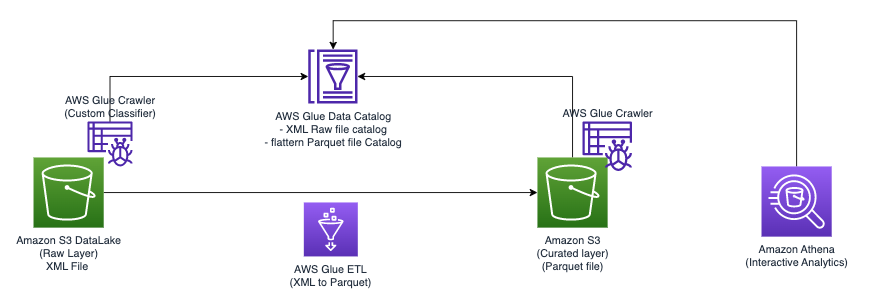
Để phân tích các tệp XML được lưu trữ trong Amazon S3 bằng AWS Glue và Athena, chúng tôi hoàn thành các bước cấp cao sau:
- Tạo trình thu thập thông tin AWS Glue để trích xuất siêu dữ liệu XML và tạo bảng trong Danh mục dữ liệu AWS Glue.
- Xử lý và chuyển đổi dữ liệu XML thành định dạng (như Parquet) phù hợp với Athena bằng cách sử dụng tác vụ trích xuất, chuyển đổi và tải (ETL) của AWS Glue.
- Thiết lập và chạy tác vụ AWS Glue thông qua bảng điều khiển AWS Glue hoặc Giao diện dòng lệnh AWS (AWS CLI).
- Sử dụng dữ liệu đã xử lý (ở định dạng Parquet) với bảng Athena, bật truy vấn SQL.
- Sử dụng giao diện thân thiện với người dùng trong Athena để phân tích dữ liệu XML bằng các truy vấn SQL trên dữ liệu của bạn được lưu trữ trong Amazon S3.
Kiến trúc này là một giải pháp có thể mở rộng và tiết kiệm chi phí để phân tích dữ liệu XML trên Amazon S3 bằng AWS Glue và Athena. Bạn có thể phân tích các tập dữ liệu lớn mà không cần quản lý cơ sở hạ tầng phức tạp.
Chúng tôi sử dụng trình thu thập thông tin AWS Glue để trích xuất siêu dữ liệu tệp XML. Bạn có thể chọn trình phân loại AWS Glue mặc định để phân loại XML cho mục đích chung. Nó tự động phát hiện cấu trúc và lược đồ dữ liệu XML, rất hữu ích cho các định dạng phổ biến.
Chúng tôi cũng sử dụng trình phân loại XML tùy chỉnh trong giải pháp này. Nó được thiết kế cho các lược đồ hoặc định dạng XML cụ thể, cho phép trích xuất siêu dữ liệu chính xác. Điều này lý tưởng cho các định dạng XML không chuẩn hoặc khi bạn cần kiểm soát chi tiết việc phân loại. Trình phân loại tùy chỉnh đảm bảo chỉ trích xuất siêu dữ liệu cần thiết, đơn giản hóa các tác vụ phân tích và xử lý tiếp theo. Cách tiếp cận này tối ưu hóa việc sử dụng các tệp XML của bạn.
Ảnh chụp màn hình sau đây hiển thị ví dụ về tệp XML có thẻ.
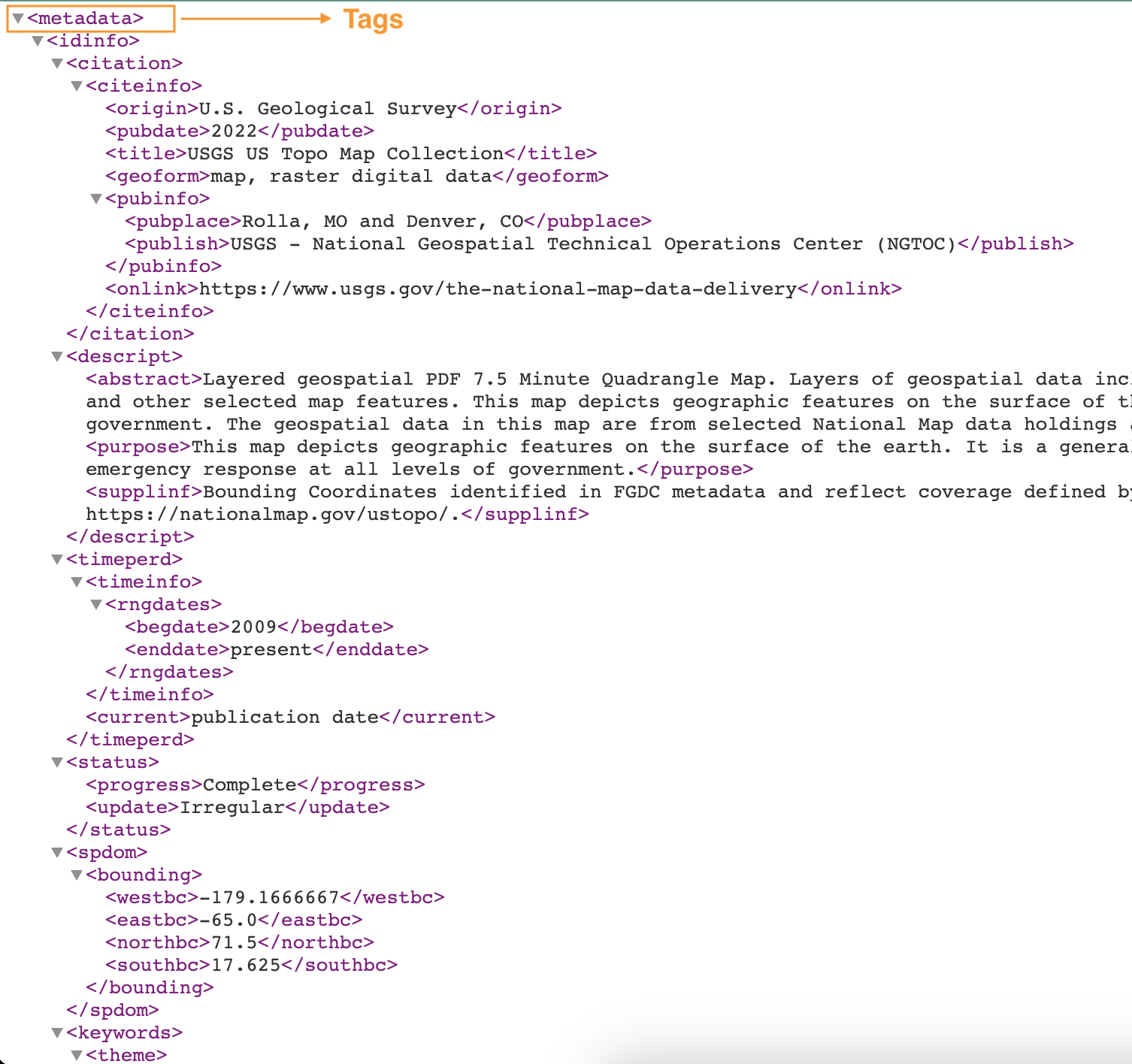
Tạo trình phân loại tùy chỉnh
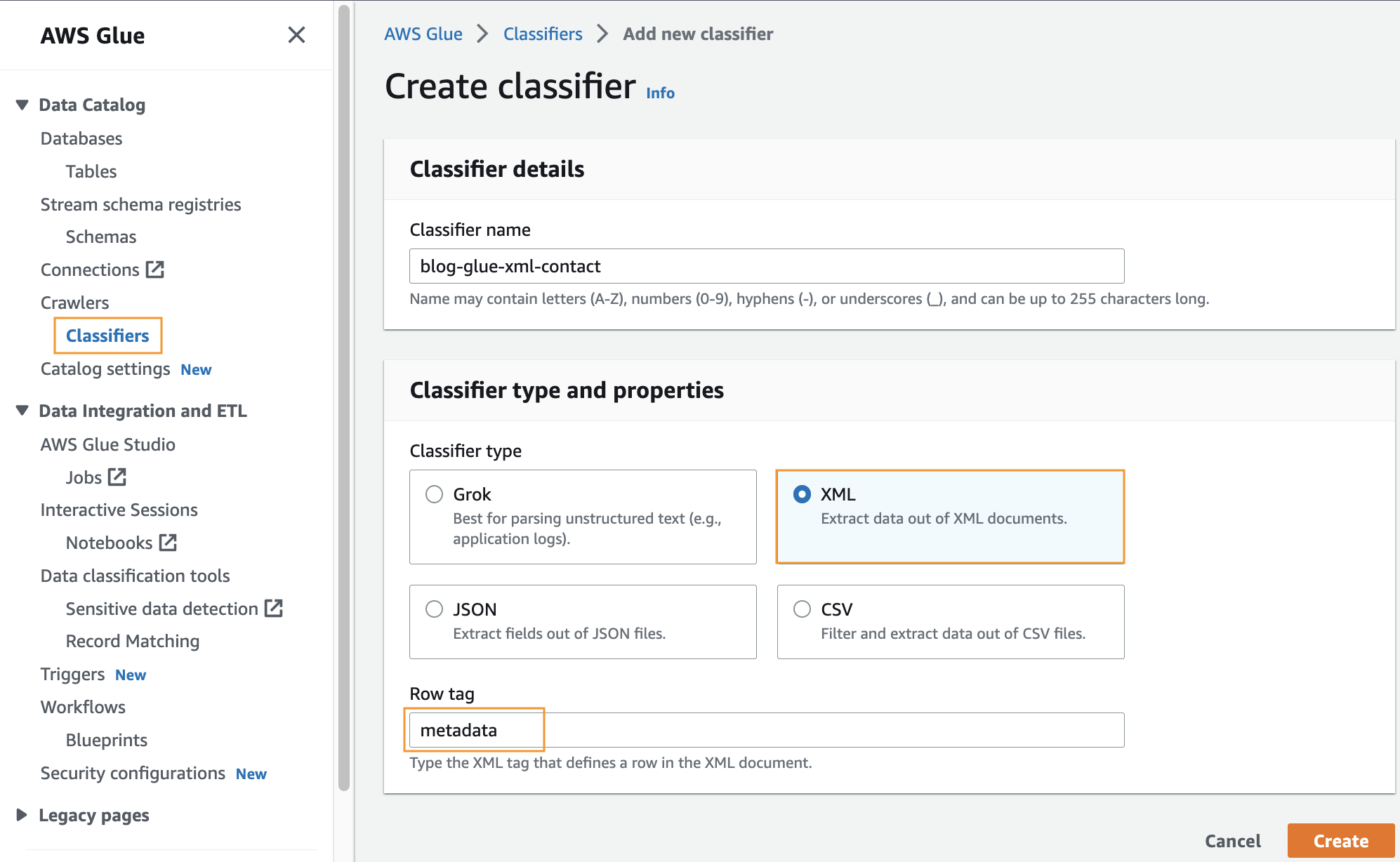
Trong bước này, bạn tạo trình phân loại AWS Glue tùy chỉnh để trích xuất siêu dữ liệu từ tệp XML. Hoàn thành các bước sau:
- Trên bảng điều khiển AWS Keo, bên dưới Trình thu thập thông tin trong ngăn điều hướng, chọn Bộ phân loại.
- Chọn Thêm bộ phân loại.
- Chọn XML như kiểu phân loại.
- Nhập tên cho bộ phân loại, chẳng hạn như
blog-glue-xml-contact. - Trong Thẻ hàng, hãy nhập tên của thẻ gốc chứa siêu dữ liệu (ví dụ:
metadata). - Chọn Tạo.
Tạo Trình thu thập keo AWS để thu thập dữ liệu tệp xml
Trong phần này, chúng tôi đang tạo Trình thu thập thông tin keo để trích xuất siêu dữ liệu từ tệp XML bằng cách sử dụng trình phân loại khách hàng đã tạo ở bước trước.
Tạo cơ sở dữ liệu
- Tới Bảng điều khiển keo AWS, chọn Cơ sở dữ liệu trong khung điều hướng.
- Nhấp vào Thêm cơ sở dữ liệu.
- Cung cấp một cái tên như
blog_glue_xml - Chọn Tạo Cơ sở dữ liệu
Tạo trình thu thập thông tin
Hoàn tất các bước sau để tạo trình thu thập thông tin đầu tiên của bạn:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
- Chọn Tạo trình thu thập thông tin.
- trên Đặt thuộc tính trình thu thập thông tin trang, hãy cung cấp tên cho trình thu thập thông tin mới (chẳng hạn như
blog-glue-parquet), tiếp đó hãy chọn Sau. - trên Chọn nguồn dữ liệu và bộ phân loại trang, chọn Chưa Dưới Cấu hình nguồn dữ liệu.
- Chọn Thêm kho lưu trữ dữ liệu.
- Trong Đường dẫn S3, duyệt đến
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Đảm bảo bạn chọn thư mục XML thay vì tệp bên trong thư mục.
- Các tùy chọn còn lại để mặc định và chọn Thêm nguồn dữ liệu S3.
- Mở rộng Trình phân loại tùy chỉnh - tùy chọn, chọn blog-glue-xml-contact, sau đó chọn Sau và giữ các tùy chọn còn lại làm mặc định.
- Chọn vai trò IAM của bạn hoặc chọn Tạo vai trò IAM mới, thêm hậu tố
glue-xml-contact(ví dụ,AWSGlueServiceNotebookRoleBlog), và lựa chọn Sau. - trên Đặt đầu ra và lập lịch trang, dưới Cấu hình đầu ra, chọn
blog_glue_xmlcho Cơ sở dữ liệu mục tiêu. - đăng ký hạng mục thi
console_làm tiền tố được thêm vào bảng (tùy chọn) và bên dưới lịch trình thu thập thông tin, giữ tần số được đặt thành Theo yêu cầu. - Chọn Sau.
- Xem lại tất cả các thông số và chọn Tạo trình thu thập thông tin.
Chạy trình thu thập thông tin
Sau khi bạn tạo trình thu thập thông tin, hãy hoàn tất các bước sau để chạy trình thu thập thông tin:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
- Mở trình thu thập thông tin bạn đã tạo và chọn chạy.
Trình thu thập thông tin sẽ mất 1–2 phút để hoàn thành.
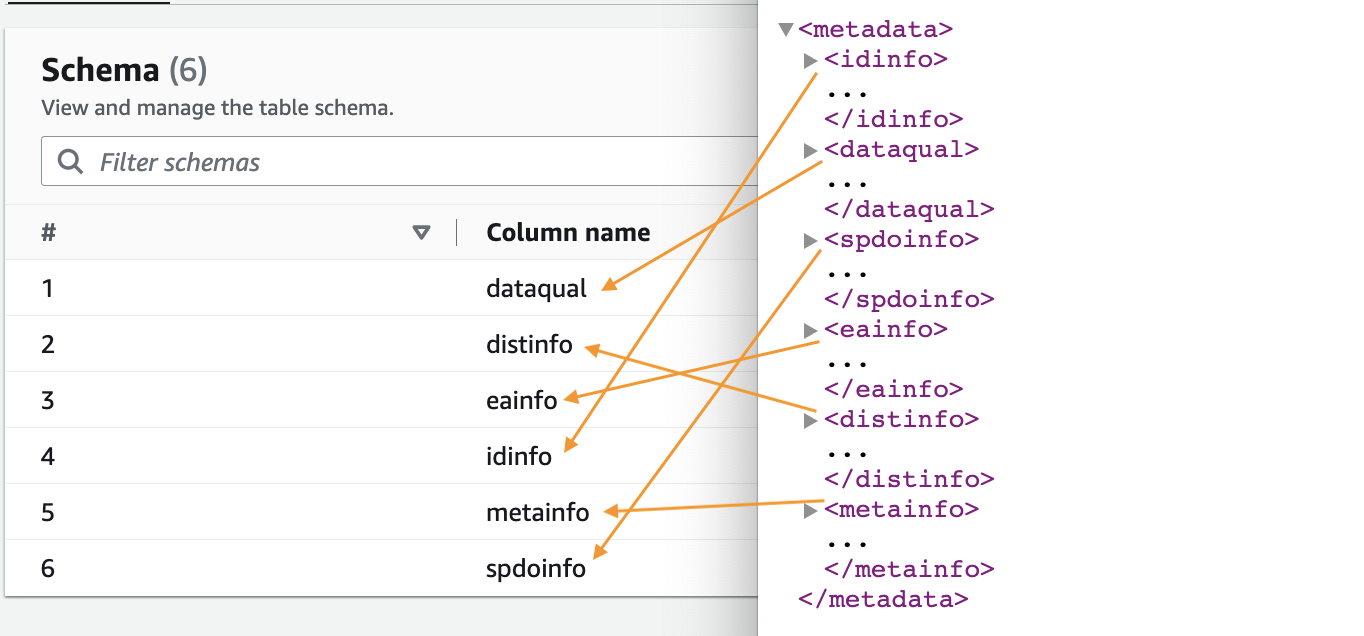
- Khi trình thu thập thông tin hoàn tất, hãy chọn Cơ sở dữ liệu trong khung điều hướng.
- Chọn cơ sở dữ liệu bạn đã tạo và chọn tên bảng để xem lược đồ được trình thu thập thông tin trích xuất.
Tạo tác vụ AWS Glue để chuyển đổi XML sang định dạng Parquet
Ở bước này, bạn tạo tác vụ AWS Glue Studio để chuyển đổi tệp XML thành tệp Parquet. Hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn việc làm trong khung điều hướng.
- Theo Tạo việc làm, lựa chọn Trực quan với một canvas trống.
- Chọn Tạo.
- Đổi tên công việc thành
blog_glue_xml_job.
Bây giờ bạn đã có trình soạn thảo tác vụ trực quan AWS Glue Studio trống. Phía trên cùng của trình chỉnh sửa là các tab dành cho các chế độ xem khác nhau.
- Chọn Script để xem phần vỏ trống của tập lệnh AWS Glue ETL.
Khi chúng tôi thêm các bước mới vào trình chỉnh sửa trực quan, tập lệnh sẽ được cập nhật tự động.
- Chọn Chi tiết công việc tab để xem tất cả các cấu hình công việc.
- Trong Vai trò IAM, chọn
AWSGlueServiceNotebookRoleBlog. - Trong Phiên bản keo, chọn Keo 4.0 – Hỗ trợ Spark 3.3, Scala 2, Python 3.
- Thiết lập Số lượng công nhân yêu cầu để 2.
- Thiết lập Số lần thử lại để 0.
- Chọn Hình ảnh tab để quay lại trình chỉnh sửa trực quan.
- trên nguồn menu thả xuống, chọn Danh mục dữ liệu keo AWS.
- trên Thuộc tính nguồn dữ liệu – Danh mục dữ liệu tab, cung cấp các thông tin sau:
- Trong Cơ sở dữ liệu, chọn
blog_glue_xml. - Trong Bàn, hãy chọn bảng bắt đầu bằng tên console_ mà trình thu thập thông tin đã tạo (ví dụ:
console_geologicalsurvey).
- Trong Cơ sở dữ liệu, chọn
- trên Thuộc tính nút tab, cung cấp các thông tin sau:
- Thay đổi Họ tên đến
geologicalsurveytập dữ liệu. - Chọn Hoạt động và sự biến đổi Thay đổi lược đồ (Áp dụng ánh xạ).
- Chọn Thuộc tính nút và thay đổi tên của phép biến đổi từ Change Schema (Apply Mapping) thành
ApplyMapping. - trên Mục tiêu menu, chọn S3.
- Thay đổi Họ tên đến
- trên Thuộc tính nguồn dữ liệu – S3 tab, cung cấp các thông tin sau:
- Trong Định dạng, lựa chọn Sàn gỗ.
- Trong Loại nén, lựa chọn Không nén.
- Trong Loại nguồn S3, lựa chọn Vị trí S3.
- Trong URL S3, đi vào
s3://${BUCKET_NAME}/output/parquet/. - Chọn Thuộc tính nút và đổi tên thành
Output.
- Chọn Lưu để lưu công việc.
- Chọn chạy để điều hành công việc.
Ảnh chụp màn hình sau đây hiển thị công việc trong trình chỉnh sửa trực quan.
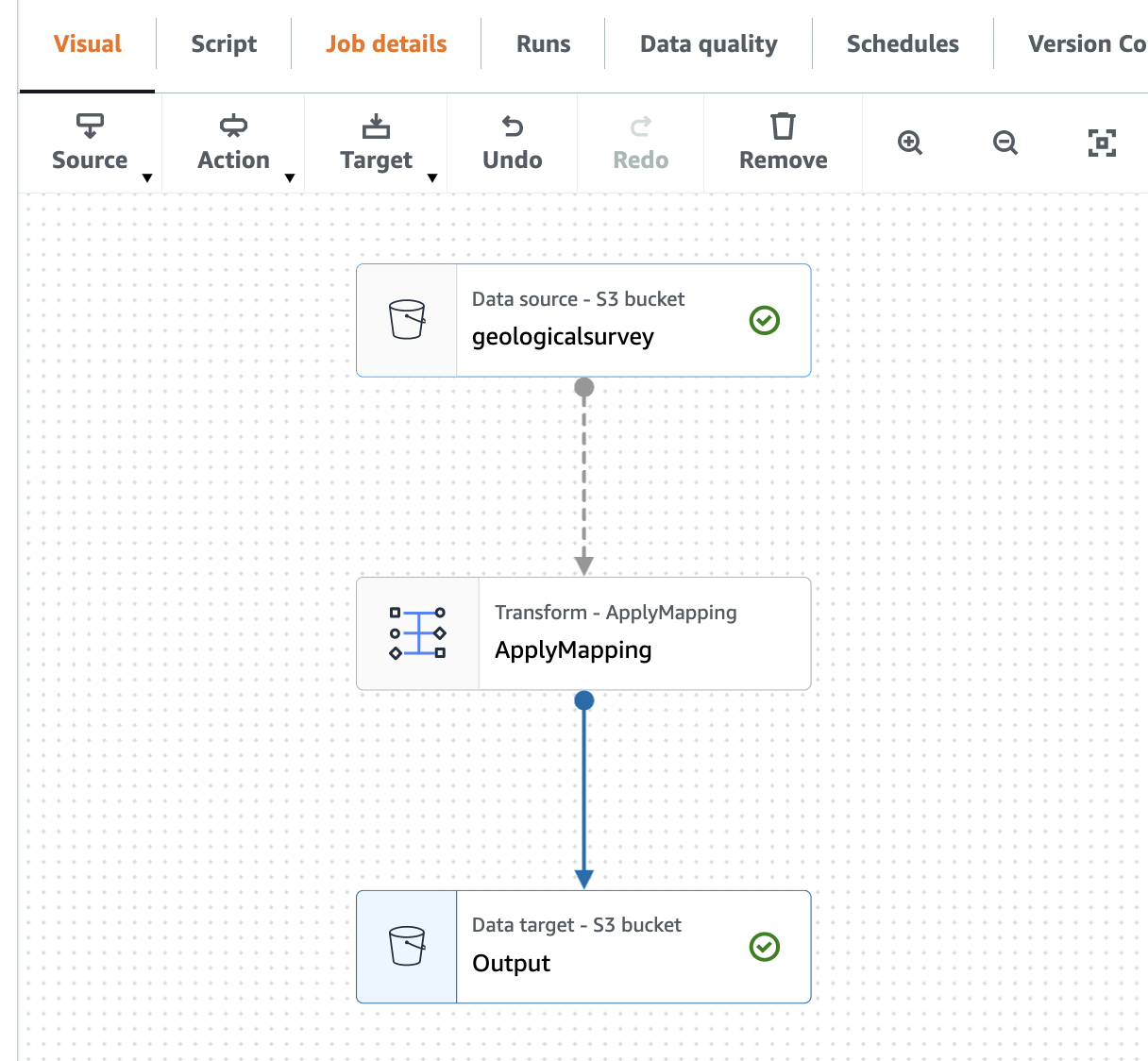
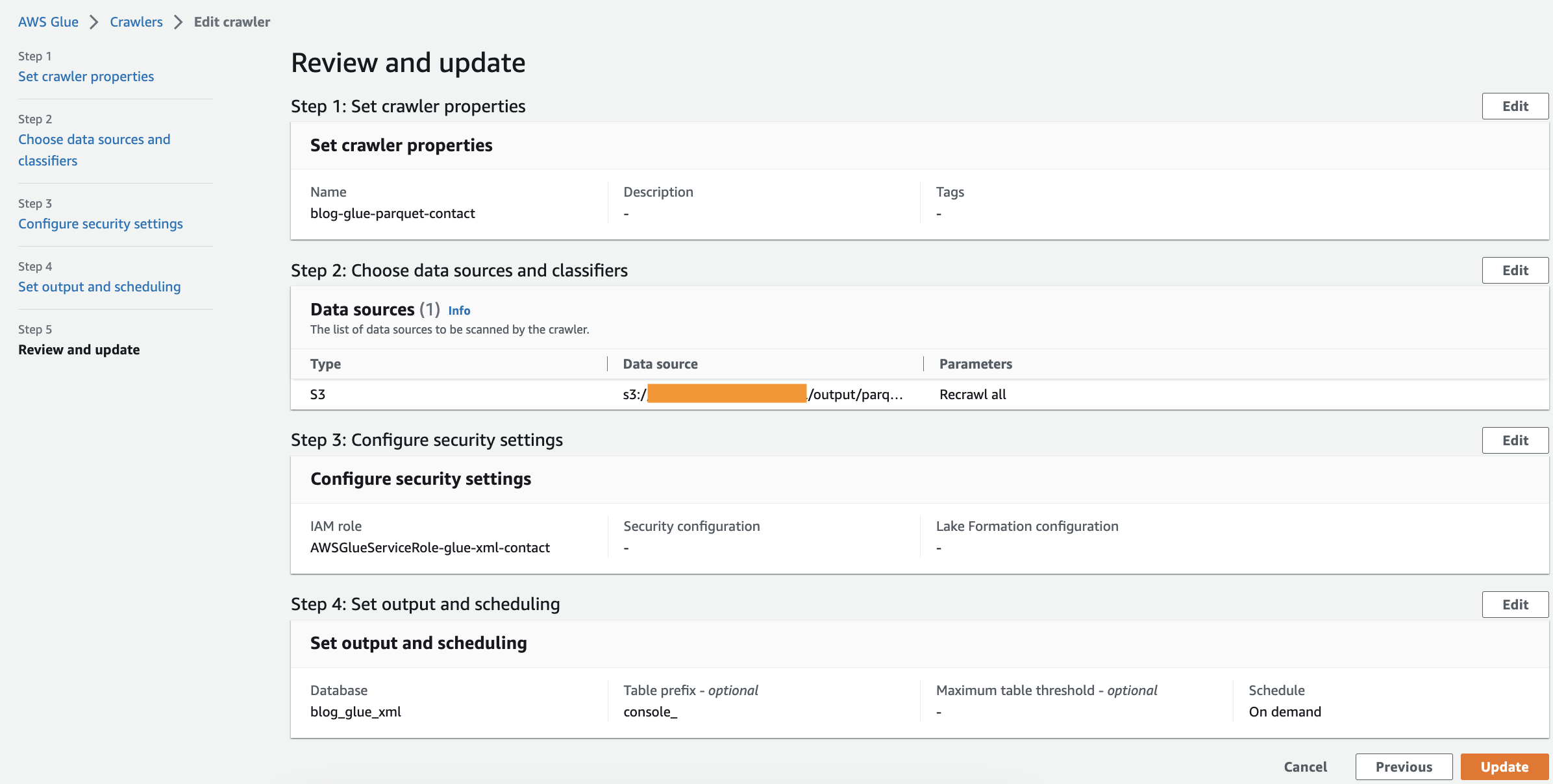
Tạo Trình thu thập thông tin AWS Gue để thu thập dữ liệu tệp Parquet
Ở bước này, bạn tạo trình thu thập thông tin AWS Glue để trích xuất siêu dữ liệu từ tệp Parquet mà bạn đã tạo bằng tác vụ AWS Glue Studio. Lần này, bạn sử dụng trình phân loại mặc định. Hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
- Chọn Tạo trình thu thập thông tin.
- trên Đặt thuộc tính trình thu thập thông tin trang, hãy cung cấp tên cho trình thu thập thông tin mới, chẳng hạn như blog-glue-parquet-contact, sau đó chọn Sau.
- trên Chọn nguồn dữ liệu và bộ phân loại trang, chọn Chưa cho Cấu hình nguồn dữ liệu.
- Chọn Thêm kho lưu trữ dữ liệu.
- Trong Đường dẫn S3, duyệt đến
s3://${BUCKET_NAME}/output/parquet/.
Hãy chắc chắn rằng bạn chọn parquet thư mục chứ không phải tập tin bên trong thư mục.
- Chọn vai trò IAM của bạn được tạo trong phần điều kiện tiên quyết hoặc chọn Tạo vai trò IAM mới (ví dụ,
AWSGlueServiceNotebookRoleBlog), và lựa chọn Sau. - trên Đặt đầu ra và lập lịch trang, dưới Cấu hình đầu ra, chọn
blog_glue_xmlcho Cơ sở dữ liệu. - đăng ký hạng mục thi
parquet_làm tiền tố được thêm vào bảng (tùy chọn) và bên dưới lịch trình thu thập thông tin, giữ tần số được đặt thành Theo yêu cầu. - Chọn Sau.
- Xem lại tất cả các thông số và chọn Tạo trình thu thập thông tin.
Bây giờ bạn có thể chạy trình thu thập thông tin. Quá trình này sẽ mất 1–2 phút để hoàn tất.

Bạn có thể xem trước lược đồ mới tạo cho tệp Parquet trong Danh mục dữ liệu AWS Glue, tương tự như lược đồ của tệp XML.
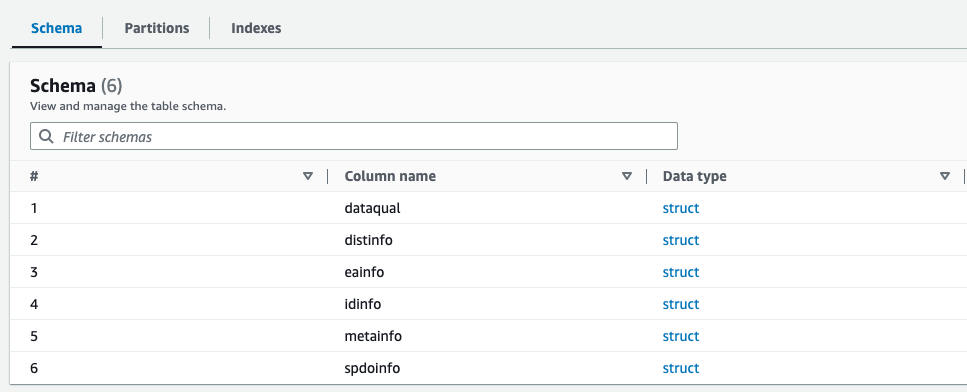
Bây giờ chúng tôi sở hữu dữ liệu phù hợp để sử dụng với Athena. Trong phần tiếp theo, chúng tôi thực hiện truy vấn dữ liệu bằng Athena.
Truy vấn tệp Parquet bằng Athena
Athena không hỗ trợ truy vấn Định dạng tệp XML, đó là lý do tại sao bạn đã chuyển đổi tệp XML thành Parquet để truy vấn và sử dụng dữ liệu hiệu quả hơn ký hiệu dấu chấm để truy vấn các kiểu phức tạp và cấu trúc lồng nhau.
Mã ví dụ sau sử dụng ký hiệu dấu chấm để truy vấn dữ liệu lồng nhau:
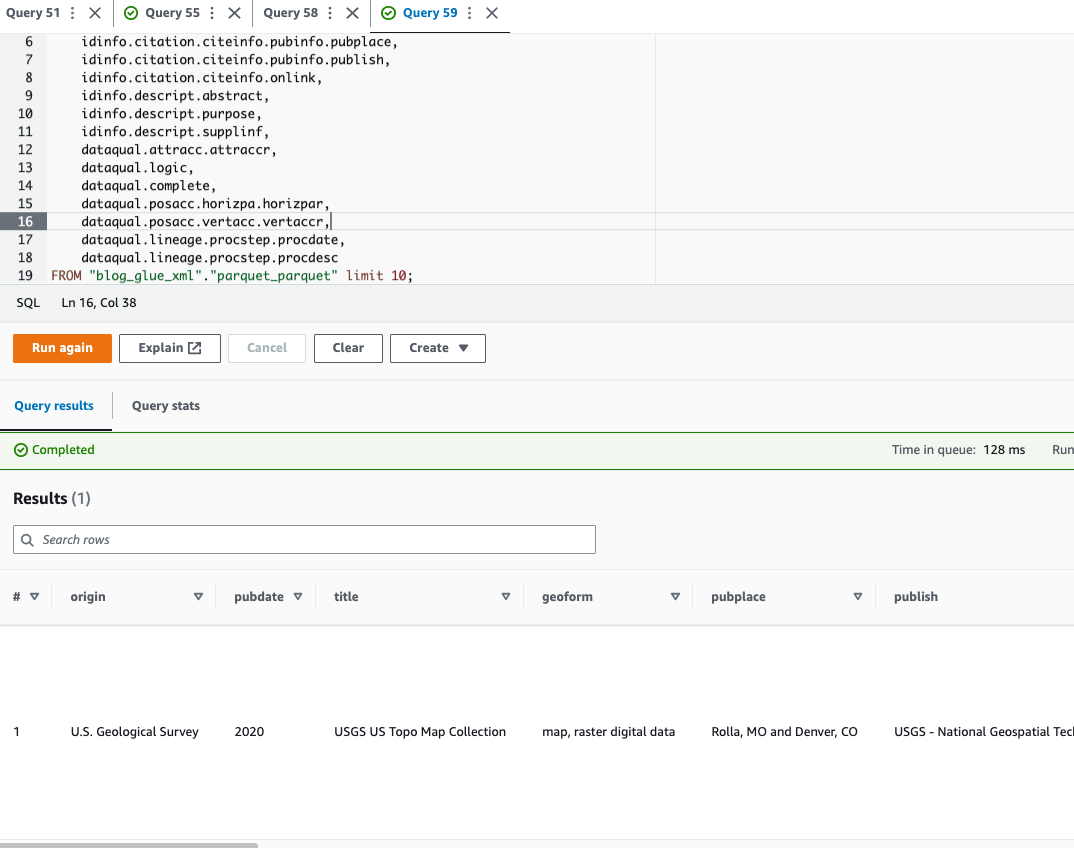
Bây giờ chúng ta đã hoàn thành kỹ thuật 1, chúng ta hãy chuyển sang tìm hiểu về kỹ thuật 2.
Kỹ thuật 2: Sử dụng AWS Glue DynamicFrames với các lược đồ suy luận và cố định
Trong phần trước, chúng ta đã đề cập đến quy trình xử lý một tệp XML nhỏ bằng trình thu thập thông tin AWS Glue để tạo bảng, tác vụ AWS Glue để chuyển đổi tệp sang định dạng Parquet và Athena để truy cập dữ liệu Parquet. Tuy nhiên, trình thu thập thông tin gặp phải những hạn chế khi xử lý các tệp XML vượt quá Kích thước 1 MB. Trong phần này, chúng ta đi sâu vào chủ đề xử lý hàng loạt các tệp XML lớn hơn, cần phân tích cú pháp bổ sung để trích xuất các sự kiện riêng lẻ và tiến hành phân tích bằng Athena.
Cách tiếp cận của chúng tôi liên quan đến việc đọc các tệp XML thông qua AWS Glue Khung động, sử dụng cả lược đồ suy luận và lược đồ cố định. Sau đó, chúng tôi trích xuất các sự kiện riêng lẻ ở định dạng Parquet bằng cách sử dụng quan hệ hóa chuyển đổi, cho phép chúng tôi truy vấn và phân tích chúng một cách liền mạch bằng Athena.
Để triển khai giải pháp này, bạn hoàn thành các bước cấp cao sau:
- Tạo sổ ghi chép AWS Glue để đọc và phân tích tệp XML.
- Sử dụng
DynamicFramesvớiInferSchemađể đọc tệp XML. - Sử dụng hàm quan hệ hóa để hủy lồng bất kỳ mảng nào.
- Chuyển đổi dữ liệu sang định dạng Parquet.
- Truy vấn dữ liệu Parquet bằng Athena.
- Lặp lại các bước trước đó, nhưng lần này chuyển một lược đồ tới
DynamicFramesthay vì sử dụngInferSchema.
Tệp XML dữ liệu dân số xe điện có phần mở rộng response thẻ ở cấp độ gốc của nó. Thẻ này chứa một mảng row các thẻ được lồng bên trong nó. Thẻ hàng là một mảng chứa một tập hợp các thẻ hàng khác, cung cấp thông tin về một chiếc xe, bao gồm nhãn hiệu, kiểu xe và các chi tiết liên quan khác. Ảnh chụp màn hình sau đây hiển thị một ví dụ.

Tạo sổ tay keo AWS
Để tạo sổ ghi chép AWS Glue, hãy hoàn thành các bước sau:
- Mở Xưởng keo AWS bảng điều khiển, chọn việc làm trong khung điều hướng.
- Chọn Máy tính xách tay Jupyter Và chọn Tạo.
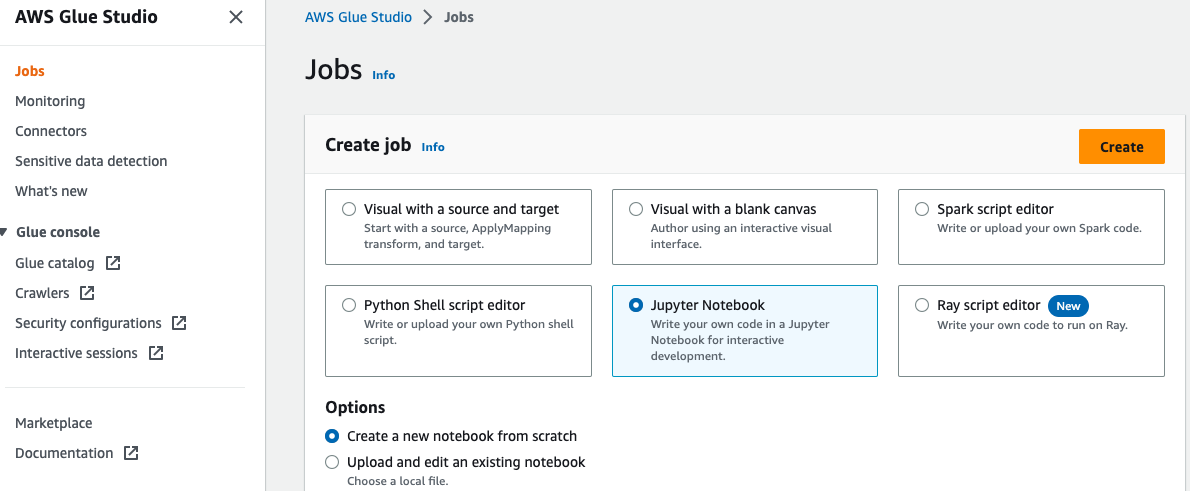
- Nhập tên cho tác vụ AWS Glue của bạn, chẳng hạn như
blog_glue_xml_job_Jupyter. - Chọn vai trò mà bạn đã tạo trong điều kiện tiên quyết (
AWSGlueServiceNotebookRoleBlog).
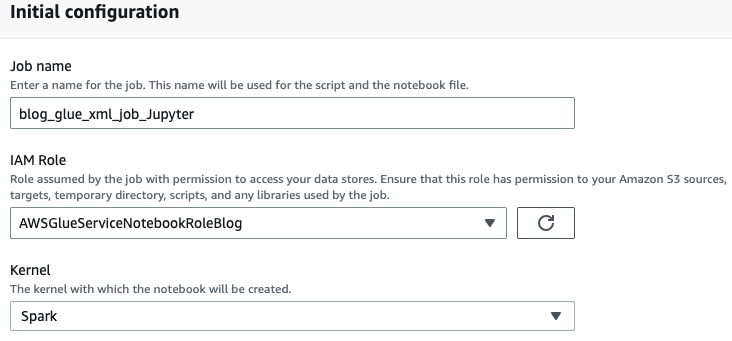
Sổ ghi chép AWS Glue đi kèm với một ví dụ có sẵn minh họa cách truy vấn cơ sở dữ liệu và ghi kết quả đầu ra vào Amazon S3.
- Điều chỉnh thời gian chờ (tính bằng phút) như minh họa trong ảnh chụp màn hình sau và chạy ô để tạo phiên tương tác AWS Glue.
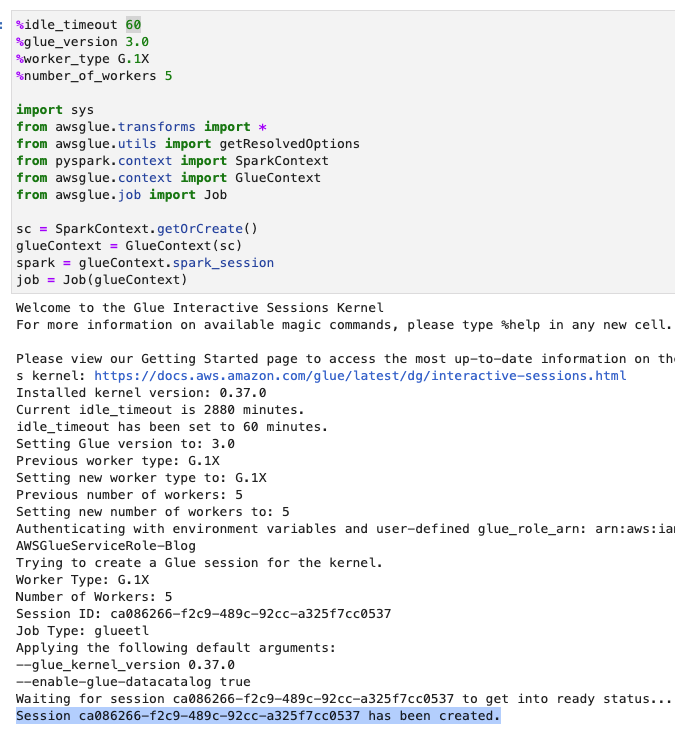
Tạo các biến cơ bản
Sau khi bạn tạo phiên tương tác, ở cuối sổ ghi chép, hãy tạo một ô mới với các biến sau (cung cấp tên nhóm của riêng bạn):
Đọc tệp XML suy ra lược đồ
Nếu bạn không chuyển lược đồ cho DynamicFrame, nó sẽ suy ra lược đồ của các tệp. Để đọc dữ liệu bằng khung động, bạn có thể sử dụng lệnh sau:
In lược đồ DynamicFrame
In lược đồ với đoạn mã sau:
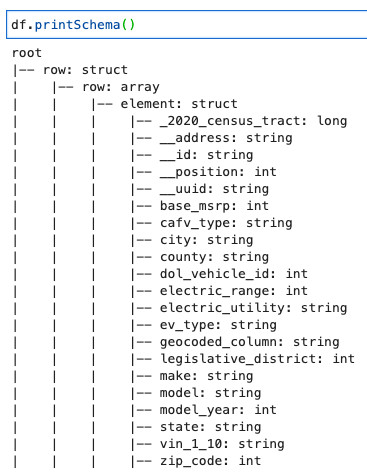
Lược đồ hiển thị một cấu trúc lồng nhau với một row mảng chứa nhiều phần tử. Để tách cấu trúc này thành các dòng, bạn có thể sử dụng AWS Glue quan hệ hóa sự biến đổi:
Chúng tôi chỉ quan tâm đến thông tin chứa trong mảng hàng và chúng tôi có thể xem lược đồ bằng cách sử dụng lệnh sau:
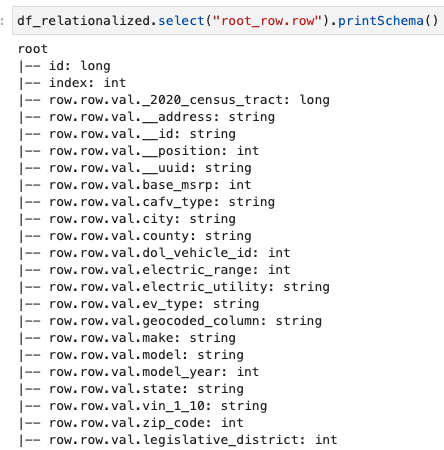
Tên cột chứa row.row, tương ứng với cấu trúc mảng và cột mảng trong tập dữ liệu. Chúng tôi không đổi tên các cột trong bài đăng này; để biết hướng dẫn thực hiện, hãy tham khảo Tự động hóa ánh xạ động và đổi tên tên cột trong tệp dữ liệu bằng AWS Glue: Phần 1. Sau đó, bạn có thể chuyển đổi dữ liệu sang định dạng Parquet và tạo bảng AWS Glue bằng lệnh sau:
Keo AWS DynamicFrame cung cấp các tính năng mà bạn có thể sử dụng trong tập lệnh ETL của mình để tạo và cập nhật lược đồ trong Danh mục dữ liệu. Chúng tôi sử dụng updateBehavior tham số để tạo bảng trực tiếp trong Danh mục dữ liệu. Với phương pháp này, chúng tôi không cần chạy trình thu thập thông tin AWS Glue sau khi công việc AWS Glue hoàn tất.

Đọc tệp XML bằng cách đặt lược đồ
Một cách khác để đọc tệp là xác định trước một lược đồ. Để thực hiện việc này, hãy hoàn thành các bước sau:
- Nhập các loại dữ liệu AWS Glue:
- Tạo một lược đồ cho tệp XML:
- Truyền lược đồ khi đọc tệp XML:
- Bỏ tổ hợp dữ liệu như trước:
- Chuyển đổi tập dữ liệu sang Parquet và tạo bảng AWS Glue:
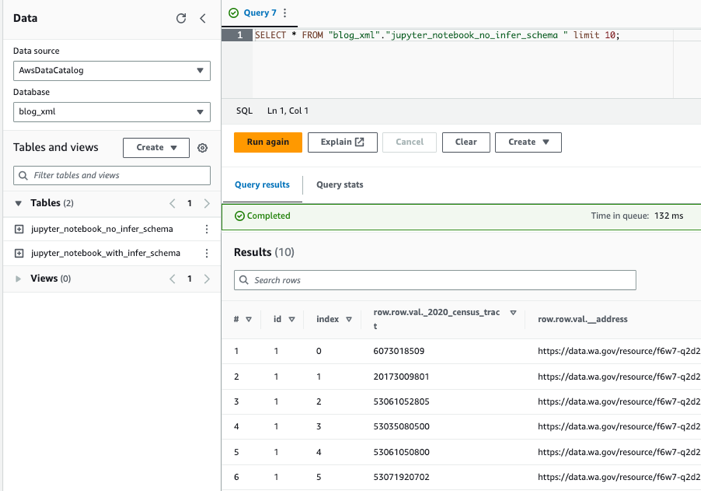
Truy vấn các bảng bằng Athena
Bây giờ chúng ta đã tạo cả hai bảng, chúng ta có thể truy vấn các bảng bằng Athena. Ví dụ: chúng ta có thể sử dụng truy vấn sau:
Clean Up
Trong bài đăng này, chúng tôi đã tạo vai trò IAM, sổ ghi chép AWS Glue Jupyter và hai bảng trong Danh mục dữ liệu AWS Glue. Chúng tôi cũng đã tải một số tệp lên vùng lưu trữ S3. Để dọn sạch các đối tượng này, hãy hoàn thành các bước sau:
- Trên bảng điều khiển IAM, hãy xóa vai trò bạn đã tạo.
- Trên bảng điều khiển AWS Glue Studio, hãy xóa trình phân loại tùy chỉnh, trình thu thập thông tin, công việc ETL và sổ ghi chép Jupyter.
- Điều hướng đến Danh mục dữ liệu AWS Glue và xóa các bảng bạn đã tạo.
- Trên bảng điều khiển Amazon S3, điều hướng đến nhóm bạn đã tạo và xóa các thư mục có tên
temp,infer_schemavàno_infer_schema.
Chìa khóa chính
Trong AWS Glue, có một tính năng tên là InferSchema trong keo AWS DynamicFrames. Nó tự động tìm ra cấu trúc của khung dữ liệu dựa trên dữ liệu chứa trong đó. Ngược lại, việc xác định lược đồ có nghĩa là nêu rõ cấu trúc của khung dữ liệu trước khi tải dữ liệu.
XML, là định dạng dựa trên văn bản, không hạn chế các kiểu dữ liệu của các cột của nó. Điều này có thể gây ra sự cố với hàm InferSchema. Ví dụ: trong lần chạy đầu tiên, một tệp có cột A có giá trị là 2 sẽ tạo ra tệp Parquet có cột A là số nguyên. Trong lần chạy thứ hai, một tệp mới có cột A có giá trị C, dẫn đến tệp Parquet có cột A dưới dạng chuỗi. Hiện tại có hai tệp trên S3, mỗi tệp có một cột A chứa các loại dữ liệu khác nhau, điều này có thể gây ra sự cố ở phía dưới.
Điều tương tự cũng xảy ra với các kiểu dữ liệu phức tạp như cấu trúc hoặc mảng lồng nhau. Ví dụ: nếu một tệp có một mục nhập thẻ được gọi là transaction, nó được suy ra như một cấu trúc. Nhưng nếu một tệp khác có cùng thẻ thì nó được suy ra là một mảng
Bất chấp những vấn đề về kiểu dữ liệu này, InferSchema rất hữu ích khi bạn không biết lược đồ hoặc việc xác định lược đồ theo cách thủ công là không thực tế. Tuy nhiên, nó không lý tưởng cho các tập dữ liệu lớn hoặc thay đổi liên tục. Việc xác định lược đồ chính xác hơn, đặc biệt là với các kiểu dữ liệu phức tạp, nhưng có các vấn đề riêng, chẳng hạn như yêu cầu nỗ lực thủ công và không linh hoạt trước các thay đổi dữ liệu.
InferSchema có những hạn chế, như suy luận kiểu dữ liệu không chính xác và các vấn đề khi xử lý giá trị null. Việc xác định lược đồ cũng có những hạn chế, chẳng hạn như nỗ lực thủ công và các lỗi tiềm ẩn.
Việc lựa chọn giữa suy luận và xác định lược đồ tùy thuộc vào nhu cầu của dự án. InferSchema rất phù hợp để khám phá nhanh các tập dữ liệu nhỏ, trong khi việc xác định lược đồ sẽ tốt hơn cho các tập dữ liệu lớn hơn, phức tạp đòi hỏi độ chính xác và nhất quán. Hãy xem xét sự cân bằng và ràng buộc của từng phương pháp để chọn phương pháp phù hợp nhất với dự án của bạn.
Kết luận
Trong bài đăng này, chúng tôi đã khám phá hai kỹ thuật quản lý dữ liệu XML bằng AWS Glue, mỗi kỹ thuật được điều chỉnh để giải quyết các nhu cầu và thách thức cụ thể mà bạn có thể gặp phải.
Kỹ thuật 1 cung cấp một đường dẫn thân thiện với người dùng cho những ai thích giao diện đồ họa. Bạn có thể sử dụng trình thu thập thông tin AWS Glue và trình chỉnh sửa trực quan để dễ dàng xác định cấu trúc bảng cho tệp XML của mình. Cách tiếp cận này đơn giản hóa quy trình quản lý dữ liệu và đặc biệt hấp dẫn đối với những người đang tìm kiếm một cách đơn giản để xử lý dữ liệu của họ.
Tuy nhiên, chúng tôi nhận thấy rằng trình thu thập thông tin có những hạn chế, cụ thể là khi xử lý các tệp XML có hàng lớn hơn 1 MB. Đây là lúc kỹ thuật 2 xuất hiện để giải cứu. Bằng cách khai thác AWS Glue DynamicFrames với cả lược đồ suy luận và lược đồ cố định, đồng thời sử dụng sổ ghi chép AWS Glue, bạn có thể xử lý các tệp XML ở mọi kích thước một cách hiệu quả. Phương pháp này cung cấp một giải pháp mạnh mẽ đảm bảo xử lý liền mạch ngay cả đối với các tệp XML có hàng vượt quá giới hạn 1 MB.
Khi bạn điều hướng thế giới quản lý dữ liệu, việc có những kỹ thuật này trong bộ công cụ sẽ giúp bạn đưa ra quyết định sáng suốt dựa trên các yêu cầu cụ thể của dự án. Cho dù bạn thích sự đơn giản của kỹ thuật 1 hay khả năng mở rộng của kỹ thuật 2, AWS Glue đều mang lại sự linh hoạt mà bạn cần để xử lý dữ liệu XML một cách hiệu quả.
Về các tác giả
 Navinit Shuklađóng vai trò là Kiến trúc sư giải pháp chuyên gia AWS, tập trung vào Phân tích. Anh ấy có niềm đam mê mãnh liệt trong việc hỗ trợ khách hàng khám phá những hiểu biết sâu sắc có giá trị từ dữ liệu của họ. Thông qua chuyên môn của mình, anh xây dựng các giải pháp đổi mới giúp các doanh nghiệp có được những lựa chọn sáng suốt và dựa trên dữ liệu. Đáng chú ý, Navnit Shukla là tác giả xuất sắc của cuốn sách có tựa đề “Sắp xếp dữ liệu trên AWS.
Navinit Shuklađóng vai trò là Kiến trúc sư giải pháp chuyên gia AWS, tập trung vào Phân tích. Anh ấy có niềm đam mê mãnh liệt trong việc hỗ trợ khách hàng khám phá những hiểu biết sâu sắc có giá trị từ dữ liệu của họ. Thông qua chuyên môn của mình, anh xây dựng các giải pháp đổi mới giúp các doanh nghiệp có được những lựa chọn sáng suốt và dựa trên dữ liệu. Đáng chú ý, Navnit Shukla là tác giả xuất sắc của cuốn sách có tựa đề “Sắp xếp dữ liệu trên AWS.
 Patrick Muller làm việc với tư cách là Kiến trúc sư phòng thí nghiệm dữ liệu cấp cao tại AWS. Trách nhiệm chính của anh là hỗ trợ khách hàng biến ý tưởng của họ thành sản phẩm dữ liệu sẵn sàng sản xuất. Khi rảnh rỗi, Patrick thích chơi bóng đá, xem phim và đi du lịch.
Patrick Muller làm việc với tư cách là Kiến trúc sư phòng thí nghiệm dữ liệu cấp cao tại AWS. Trách nhiệm chính của anh là hỗ trợ khách hàng biến ý tưởng của họ thành sản phẩm dữ liệu sẵn sàng sản xuất. Khi rảnh rỗi, Patrick thích chơi bóng đá, xem phim và đi du lịch.
 Amgh Gaikwad là Nhà phát triển giải pháp cấp cao tại Amazon Web Services. Anh giúp khách hàng toàn cầu xây dựng và triển khai các giải pháp AI/ML trên AWS. Công việc của anh chủ yếu tập trung vào thị giác máy tính và xử lý ngôn ngữ tự nhiên, đồng thời giúp khách hàng tối ưu hóa khối lượng công việc AI/ML của họ để đảm bảo tính bền vững. Amogh đã nhận bằng thạc sĩ Khoa học Máy tính chuyên về Học máy.
Amgh Gaikwad là Nhà phát triển giải pháp cấp cao tại Amazon Web Services. Anh giúp khách hàng toàn cầu xây dựng và triển khai các giải pháp AI/ML trên AWS. Công việc của anh chủ yếu tập trung vào thị giác máy tính và xử lý ngôn ngữ tự nhiên, đồng thời giúp khách hàng tối ưu hóa khối lượng công việc AI/ML của họ để đảm bảo tính bền vững. Amogh đã nhận bằng thạc sĩ Khoa học Máy tính chuyên về Học máy.
 Sheela Sonone là Kiến trúc sư thường trú cấp cao tại AWS. Cô giúp khách hàng AWS đưa ra những lựa chọn và cân nhắc sáng suốt trong việc tăng tốc dữ liệu, phân tích cũng như khối lượng công việc và triển khai AI/ML của họ. Trong thời gian rảnh rỗi, cô thích dành thời gian cho gia đình - thường là trên sân tennis.
Sheela Sonone là Kiến trúc sư thường trú cấp cao tại AWS. Cô giúp khách hàng AWS đưa ra những lựa chọn và cân nhắc sáng suốt trong việc tăng tốc dữ liệu, phân tích cũng như khối lượng công việc và triển khai AI/ML của họ. Trong thời gian rảnh rỗi, cô thích dành thời gian cho gia đình - thường là trên sân tennis.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Giới thiệu
- TÓM TẮT
- tăng tốc
- truy cập
- khả năng tiếp cận
- thực hiện
- chính xác
- ngang qua
- Hoạt động
- thêm vào
- thêm
- thêm vào
- địa chỉ
- Sau
- tuổi
- AI / ML
- Tất cả
- cho phép
- Cho phép
- cho phép
- Ngoài ra
- thay thế
- đàn bà gan dạ
- amazon Athena
- Amazon Web Services
- an
- phân tích
- phân tích
- phân tích
- phân tích
- và
- Một
- bất kì
- Apache
- hấp dẫn
- các ứng dụng
- Đăng Nhập
- phương pháp tiếp cận
- cách tiếp cận
- kiến trúc
- LÀ
- Mảng
- AS
- hỗ trợ
- trợ giúp
- At
- tác giả
- tự động
- có sẵn
- AWS
- Keo AWS
- trở lại
- dựa
- cơ bản
- BE
- bởi vì
- trước
- bắt đầu
- được
- BEST
- Hơn
- giữa
- trống
- cuốn sách
- cả hai
- xây dựng
- các doanh nghiệp
- nhưng
- by
- gọi là
- CAN
- Danh mục hàng
- Nguyên nhân
- pin
- thách thức
- thay đổi
- Những thay đổi
- thay đổi
- lựa chọn
- Chọn
- City
- phân loại
- khách hàng
- mã
- Cột
- Cột
- COM
- đến
- Chung
- thông thường
- hoàn thành
- Hoàn thành
- phức tạp
- máy tính
- Khoa học Máy tính
- Tầm nhìn máy tính
- điều kiện
- Tiến hành
- kết hợp
- Hãy xem xét
- An ủi
- liên tục
- khó khăn
- xây dựng
- chứa
- chứa
- chứa
- Ngược lại
- điều khiển
- chuyển đổi
- chuyển đổi
- chi phí-hiệu quả
- Giải pháp hiệu quả
- hạt
- Tòa án
- phủ
- thu thập thông tin
- tạo
- tạo ra
- Tạo
- quan trọng
- khách hàng
- khách hàng
- khách hàng
- dữ liệu
- tích hợp dữ liệu
- quản lý dữ liệu
- hướng dữ liệu
- Cơ sở dữ liệu
- bộ dữ liệu
- xử lý
- quyết định
- Mặc định
- định nghĩa
- xác định
- đào sâu
- chứng minh
- phụ thuộc
- triển khai
- thiết kế
- chi tiết
- chi tiết
- Nhà phát triển
- khác nhau
- khó khăn
- kỹ thuật số
- thời đại kỹ thuật số
- trực tiếp
- khám phá
- khác biệt
- do
- Không
- thực hiện
- dont
- DOT
- suốt trong
- năng động
- mỗi
- dễ dàng
- dễ dàng
- dễ dàng
- biên tập viên
- hiệu lực
- hiệu quả
- hiệu quả
- hiệu quả
- hiệu quả
- nỗ lực
- dễ dàng
- Điện
- xe điện
- các yếu tố
- thuê mướn
- trao quyền
- trao quyền
- trống
- cho phép
- cho phép
- gặp gỡ
- cuối
- Động cơ
- nâng cao
- đảm bảo
- đảm bảo
- đăng ký hạng mục thi
- sự nhiệt tình
- nhập
- lỗi
- đặc biệt
- Ether (ETH)
- Ngay cả
- sự kiện
- Mỗi
- ví dụ
- quá
- trao đổi
- chuyên môn
- thăm dò
- khám phá
- Khám phá
- trích xuất
- khai thác
- gia đình
- Đặc tính
- Tính năng
- Số liệu
- Tập tin
- Các tập tin
- tài chính
- Tên
- cố định
- Linh hoạt
- Tập trung
- tập trung
- tiếp theo
- Trong
- định dạng
- FRAME
- Miễn phí
- tần số
- từ
- chức năng
- Thu được
- mục đích chung
- tạo ra
- Toàn cầu
- Go
- mục tiêu
- Chính phủ
- tuyệt vời
- xử lý
- Xử lý
- xảy ra
- Khai thác
- Có
- có
- he
- chăm sóc sức khỏe
- Trái Tim
- giúp đỡ
- giúp đỡ
- giúp
- cô
- cấp độ cao
- cao
- của mình
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- IAM
- lý tưởng
- ý tưởng
- Bản sắc
- if
- minh họa
- thực hiện
- triển khai
- thực hiện
- nhập khẩu
- nâng cao
- cải thiện
- in
- Bao gồm
- hệ thống riêng biệt,
- các cá nhân
- các ngành công nghiệp
- thông tin
- thông báo
- Cơ sở hạ tầng
- sáng tạo
- trong
- những hiểu biết
- thay vì
- hướng dẫn
- tích hợp
- hội nhập
- tương tác
- quan tâm
- Giao thức
- trong
- liên quan đến
- các vấn đề
- IT
- ITS
- Việc làm
- việc làm
- jpg
- json
- Máy tính xách tay Jupyter
- Giữ
- Biết
- phòng thí nghiệm
- Ngôn ngữ
- lớn
- lớn hơn
- hàng đầu
- LEARN
- học tập
- Cấp
- Lượt thích
- LIMIT
- giới hạn
- hạn chế
- Dòng
- dòng
- tải
- tải
- logic
- tìm kiếm
- máy
- học máy
- Chủ yếu
- phần lớn
- làm cho
- Làm
- quản lý
- quản lý
- nhãn hiệu
- thủ công
- nhiều
- lập bản đồ
- thạc sĩ
- Có thể..
- có nghĩa
- Menu
- Siêu dữ liệu
- phương pháp
- phút
- kiểu mẫu
- chi tiết
- hiệu quả hơn
- hầu hết
- di chuyển
- Phim Điện Ảnh
- nhiều
- tên
- Được đặt theo tên
- tên
- Tự nhiên
- Ngôn ngữ tự nhiên
- Xử lý ngôn ngữ tự nhiên
- Điều hướng
- THÔNG TIN
- cần thiết
- Cần
- nhu cầu
- Mới
- mới
- tiếp theo
- đáng chú ý
- máy tính xách tay
- tại
- con số
- đối tượng
- of
- Cung cấp
- on
- ONE
- có thể
- Hoạt động
- tối ưu
- Tối ưu hóa
- Tối ưu hóa
- Các lựa chọn
- or
- gọi món
- tổ chức
- Xuất xứ
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- đầu ra
- kết thúc
- Vượt qua
- riêng
- trang
- cửa sổ
- tham số
- thông số
- một phần
- đặc biệt
- vượt qua
- con đường
- patrick
- thực hiện
- hiệu suất
- quyền
- chọn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chơi
- điều luật
- dân số
- có
- Bài đăng
- tiềm năng
- cần
- thích hơn
- điều kiện tiên quyết
- Xem trước
- trước
- vấn đề
- quá trình
- xử lý
- xử lý
- Sản phẩm
- dự án
- dự án
- tài sản
- cho
- cung cấp
- xuất bản
- mục đích
- Python
- truy vấn
- Nhanh chóng
- hơn
- Đọc
- sẵn sàng
- Reading
- lý do
- nhận
- công nhận
- xem
- có liên quan
- Yêu cầu
- giải cứu
- tài nguyên
- phản ứng
- trách nhiệm
- REST của
- hạn chế
- sự hạn chế
- Kết quả
- mạnh mẽ
- Vai trò
- nguồn gốc
- HÀNG
- chạy
- tương tự
- Lưu
- Scala
- khả năng mở rộng
- khả năng mở rộng
- Khoa học
- kịch bản
- liền mạch
- liền mạch
- Thứ hai
- Phần
- xem
- cao cấp
- DỊCH VỤ
- Phiên
- định
- thiết lập
- một số
- chị ấy
- Shell
- nên
- hiển thị
- thể hiện
- Chương trình
- tương tự
- Đơn giản
- đơn giản
- đơn giản hóa
- duy nhất
- Kích thước máy
- nhỏ
- So
- Bóng đá
- giải pháp
- Giải pháp
- một số
- nguồn
- nguồn
- Spark
- chuyên gia
- chuyên
- riêng
- đặc biệt
- tốc độ
- Chi
- SQL
- Tiêu chuẩn
- bắt đầu
- Tiểu bang
- Tuyên bố
- nêu
- Bước
- Các bước
- là gắn
- lưu trữ
- đơn giản
- hợp lý hóa
- Chuỗi
- mạnh mẽ
- cấu trúc
- cấu trúc
- phòng thu
- thành công
- như vậy
- phù hợp
- hỗ trợ
- chắc chắn
- Tính bền vững
- hệ thống
- bàn
- TAG
- phù hợp
- Hãy
- mất
- nhiệm vụ
- kỹ thuật
- quần vợt
- hơn
- việc này
- Sản phẩm
- thông tin
- thế giới
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- điều này
- những
- Thông qua
- thời gian
- Yêu sách
- có tiêu đề
- đến
- hôm nay
- bộ công cụ
- hàng đầu
- chủ đề
- Chuyển đổi
- Chuyển đổi
- Đi du lịch
- Quay
- hướng dẫn
- hai
- kiểu
- loại
- cuối cùng
- Dưới
- Cập nhật
- cập nhật
- tải lên
- us
- khả năng sử dụng
- sử dụng
- đã sử dụng
- người sử dang
- Giao diện người dùng
- sử dụng
- sử dụng
- sử dụng
- thường
- Bằng cách sử dụng
- Quý báu
- giá trị
- Các giá trị
- xe
- phiên bản
- thông qua
- Xem
- Lượt xem
- tầm nhìn
- xem
- Đường..
- we
- web
- các dịch vụ web
- Điều gì
- khi nào
- trong khi
- liệu
- cái nào
- CHÚNG TÔI LÀ
- tại sao
- sẽ
- với
- ở trong
- không có
- Công việc
- quy trình làm việc
- Luồng công việc
- công trinh
- thế giới
- viết
- XML
- bạn
- trên màn hình
- zephyrnet