
Hình ảnh từ con đom đóm Adobe
“Có quá nhiều người trong chúng ta. Chúng tôi có quá nhiều tiền, quá nhiều thiết bị và dần dần chúng tôi phát điên.”
Francis Ford Coppola đã không tạo ra một phép ẩn dụ cho các công ty AI chi tiêu quá nhiều và lạc lối, nhưng ông ấy có thể đã làm như vậy. Apocalypse Now rất hoành tráng nhưng cũng là một dự án lâu dài, khó thực hiện và tốn kém, giống như GPT-4. Tôi cho rằng sự phát triển của LLM đã thu hút quá nhiều tiền và quá nhiều thiết bị. Và một số lời cường điệu “chúng tôi vừa phát minh ra trí thông minh chung” là hơi điên rồ. Nhưng bây giờ đến lượt các cộng đồng nguồn mở làm những gì họ làm tốt nhất: cung cấp phần mềm cạnh tranh miễn phí bằng cách sử dụng ít tiền và thiết bị hơn nhiều.
OpenAI đã nhận được hơn 11 tỷ đô la tài trợ và ước tính GPT-3.5 tiêu tốn 5-6 triệu đô la cho mỗi lần đào tạo. Chúng tôi biết rất ít về GPT-4 vì OpenAI không tiết lộ, nhưng tôi nghĩ sẽ an toàn khi cho rằng nó không nhỏ hơn GPT-3.5. Hiện đang có sự thiếu hụt GPU trên toàn thế giới và – để thay đổi – đó không phải là do loại tiền điện tử mới nhất. Các công ty khởi nghiệp AI sáng tạo đang đạt được hơn 100 triệu đô la vòng Series A với mức định giá khổng lồ khi họ không sở hữu bất kỳ IP nào cho LLM mà họ sử dụng để cung cấp năng lượng cho sản phẩm của mình. LLM bandwagon đang ở mức cao và tiền đang chảy.
Có vẻ như đã chết: chỉ những công ty có nguồn vốn dồi dào như Microsoft/OpenAI, Amazon và Google mới đủ khả năng đào tạo các mô hình tham số hàng trăm tỷ. Những mô hình lớn hơn được cho là những mô hình tốt hơn. GPT-3 có vấn đề gì đó? Chỉ cần đợi cho đến khi có phiên bản lớn hơn và mọi chuyện sẽ ổn thôi! Các công ty nhỏ hơn muốn cạnh tranh phải huy động nhiều vốn hơn hoặc phải xây dựng các khu tích hợp hàng hóa trên thị trường ChatGPT. Giới học thuật, với ngân sách nghiên cứu thậm chí còn hạn chế hơn, đã bị đẩy ra ngoài lề.
May mắn thay, một nhóm người thông minh và các dự án nguồn mở đã coi đây là một thách thức hơn là một hạn chế. Các nhà nghiên cứu tại Stanford đã phát hành Alpaca, một mô hình 7 tỷ tham số có hiệu suất gần bằng mô hình 3.5 tỷ tham số của GPT-175. Thiếu tài nguyên để xây dựng bộ đào tạo có kích thước như OpenAI sử dụng, họ đã khéo léo chọn sử dụng LLM nguồn mở đã được đào tạo, LLaMA và tinh chỉnh nó trên một loạt lời nhắc và đầu ra GPT-3.5 để thay thế. Về cơ bản, mô hình đã học được những gì GPT-3.5 làm, điều này hóa ra lại là một chiến lược rất hiệu quả để sao chép hành vi của nó.
Alpaca được cấp phép cho mục đích sử dụng phi thương mại chỉ trong cả mã và dữ liệu vì nó sử dụng mô hình LLaMA phi thương mại nguồn mở và OpenAI rõ ràng không cho phép bất kỳ việc sử dụng API nào của nó để tạo ra các sản phẩm cạnh tranh. Điều đó tạo ra triển vọng hấp dẫn về việc tinh chỉnh một LLM mã nguồn mở khác dựa trên lời nhắc và đầu ra của Alpaca… tạo ra một mô hình giống GPT-3.5 thứ ba với các khả năng cấp phép khác nhau.
Có một điều trớ trêu khác ở đây, đó là tất cả các LLM chính đã được đào tạo về văn bản và hình ảnh có bản quyền có sẵn trên Internet và họ không trả một xu nào cho chủ bản quyền. Các công ty yêu cầu miễn trừ "sử dụng hợp pháp" theo luật bản quyền của Hoa Kỳ với lập luận rằng việc sử dụng là "biến đổi". Tuy nhiên, khi nói đến đầu ra của các mô hình mà họ xây dựng bằng dữ liệu miễn phí, họ thực sự không muốn bất kỳ ai làm điều tương tự với họ. Tôi cho rằng điều này sẽ thay đổi khi những người nắm giữ quyền sáng suốt hơn và có thể sẽ phải hầu tòa vào một lúc nào đó.
Đây là một điểm riêng biệt và khác biệt so với điểm được nêu ra bởi các tác giả của nguồn mở được cấp phép hạn chế, những người, đối với các sản phẩm AI dành cho Code như CoPilot, phản đối việc mã của họ được sử dụng để đào tạo với lý do giấy phép không được tuân thủ. Vấn đề đối với các tác giả nguồn mở riêng lẻ là họ cần thể hiện vị thế – sao chép thực chất – và rằng họ đã phải gánh chịu những thiệt hại. Và vì các mô hình gây khó khăn cho việc liên kết mã đầu ra với đầu vào (các dòng mã nguồn của tác giả) và không có tổn thất kinh tế (nó được cho là miễn phí), nên việc đưa ra trường hợp khó khăn hơn nhiều. Điều này không giống với những người sáng tạo vì lợi nhuận (ví dụ: nhiếp ảnh gia) có toàn bộ mô hình kinh doanh là cấp phép/bán tác phẩm của họ và những người được đại diện bởi các công ty tổng hợp như Getty Images có thể hiển thị nội dung sao chép.
Một điều thú vị khác về LLaMA là nó ra đời từ Meta. Ban đầu nó chỉ được phát hành cho các nhà nghiên cứu và sau đó bị rò rỉ qua BitTorrent ra thế giới. Meta là một doanh nghiệp khác về cơ bản với OpenAI, Microsoft, Google và Amazon ở chỗ nó không cố gắng bán cho bạn các dịch vụ hoặc phần mềm đám mây và do đó có các ưu đãi rất khác nhau. Nó đã mã nguồn mở các thiết kế máy tính của mình trong quá khứ (OpenCompute) và thấy cộng đồng cải thiện chúng – nó hiểu giá trị của nguồn mở.
Meta có thể trở thành một trong những người đóng góp AI nguồn mở quan trọng nhất. Nó không chỉ có nguồn tài nguyên khổng lồ mà còn được hưởng lợi nếu có sự phát triển của công nghệ AI có sức sản xuất lớn: sẽ có nhiều nội dung hơn để nó kiếm tiền trên mạng xã hội. Meta đã phát hành ba mô hình AI mã nguồn mở khác: ImageBind (lập chỉ mục dữ liệu đa chiều), DINOv2 (thị giác máy tính) và Segment Anything. Cái sau xác định các đối tượng duy nhất trong hình ảnh và được phát hành theo Giấy phép Apache rất dễ dãi.
Cuối cùng, chúng tôi cũng bị cáo buộc rò rỉ một tài liệu nội bộ của Google “Chúng tôi không có lợi nhuận và OpenAI cũng vậy”, tài liệu này có cái nhìn mờ nhạt về các mô hình khép kín so với sự đổi mới của các cộng đồng sản xuất các mô hình nhỏ hơn, rẻ hơn, hoạt động gần bằng hoặc tốt hơn các đối tác nguồn đóng của họ. Tôi nói bị cáo buộc bởi vì không có cách nào để xác minh nguồn của bài viết là nội bộ của Google. Tuy nhiên, nó chứa biểu đồ hấp dẫn này:
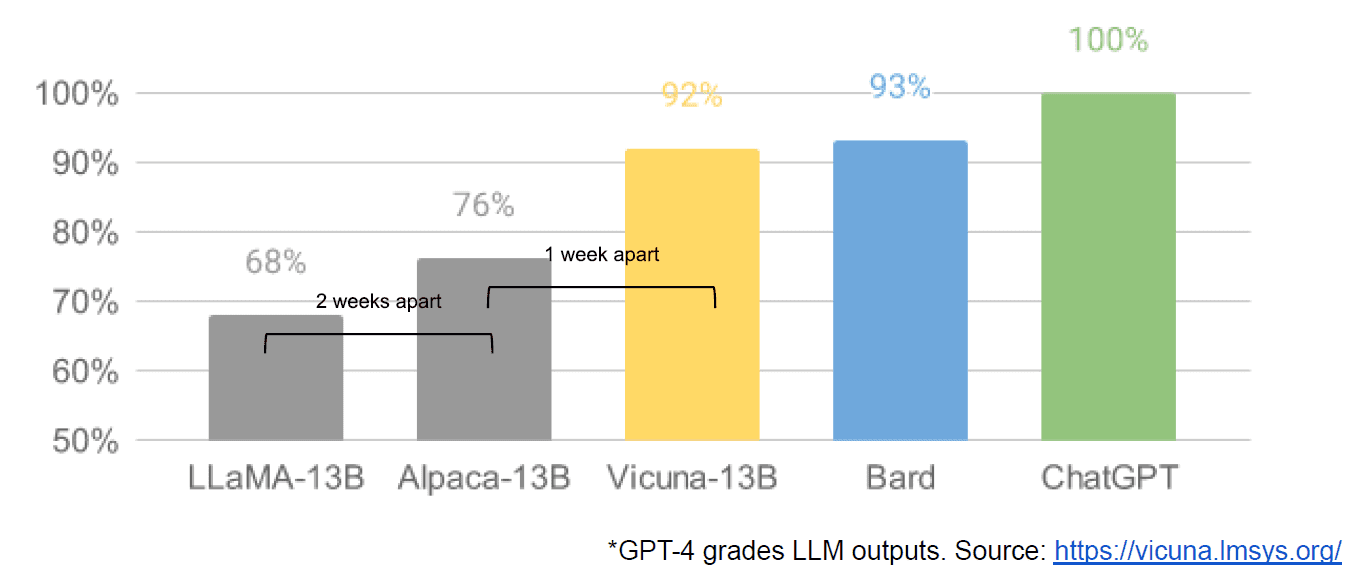
Rõ ràng, trục tung là phân loại đầu ra LLM theo GPT-4.
Khuếch tán ổn định, tổng hợp hình ảnh từ văn bản, là một ví dụ khác về việc AI tạo nguồn mở có thể phát triển nhanh hơn các mô hình độc quyền. Một lần lặp lại gần đây của dự án đó (ControlNet) đã cải thiện nó để nó vượt qua khả năng của Dall-E2. Điều này xuất phát từ rất nhiều sự mày mò trên khắp thế giới, dẫn đến một tốc độ tiến bộ mà khó có tổ chức đơn lẻ nào sánh được. Một số người mày mò đã tìm ra cách làm cho Khuếch tán ổn định nhanh hơn để đào tạo và chạy trên phần cứng rẻ hơn, cho phép nhiều người thực hiện các chu kỳ lặp lại ngắn hơn.
Và vì vậy chúng tôi đã đi vòng tròn đầy đủ. Không có quá nhiều tiền và quá nhiều thiết bị đã truyền cảm hứng cho một mức độ đổi mới xảo quyệt của cả một cộng đồng người bình thường. Thật là một thời gian để trở thành một nhà phát triển AI.
nhà nghỉ Mathew là Giám đốc điều hành của Diffblue, một công ty khởi nghiệp AI For Code. Ông có hơn 25 năm kinh nghiệm đa dạng về lãnh đạo sản phẩm tại các công ty như Anaconda và VMware. Lodge hiện đang phục vụ trong hội đồng Dự án Luật Tốt và là Phó Chủ tịch Hội đồng Quản trị của Hiệp hội Nhiếp ảnh Hoàng gia.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 9
- a
- Có khả năng
- Giới thiệu
- Học viện
- truy cập
- Adobe
- tiến
- Bộ tổng hợp
- AI
- Tất cả
- cáo buộc
- bị cáo buộc
- Ngoài ra
- đàn bà gan dạ
- an
- và
- Một
- bất kì
- bất kỳ ai
- bất cứ điều gì
- Apache
- API
- LÀ
- đối số
- bài viết
- AS
- giả sử
- At
- tác giả
- tác giả
- có sẵn
- Trục
- BE
- bởi vì
- được
- được
- Lợi ích
- BEST
- Hơn
- lớn hơn
- BitTorrent
- bảng
- cả hai
- Ngân sách
- xây dựng
- Xây dựng
- xăn lên
- kinh doanh
- mô hình kinh doanh
- nhưng
- by
- đến
- CAN
- khả năng
- vốn
- trường hợp
- giám đốc điều hành
- Ghế
- thách thức
- thay đổi
- ChatGPT
- rẻ hơn
- chọn
- Vòng tròn
- xin
- trong sáng
- Đóng
- đóng cửa
- đám mây
- dịch vụ điện toán đám mây
- mã
- Đến
- đến
- hàng hóa
- Cộng đồng
- cộng đồng
- Các công ty
- thuyết phục
- cạnh tranh
- cạnh tranh
- Tính
- máy tính
- Tầm nhìn máy tính
- nội dung
- đóng góp
- sao chép
- quyền tác giả
- Chi phí
- có thể
- Tòa án
- tạo
- Tạo
- người sáng tạo
- tiền điện tử
- Hiện nay
- chu kỳ
- dữ liệu
- phân phối
- Phó
- thiết kế
- Nhà phát triển
- Phát triển
- Die
- khác nhau
- khó khăn
- Lôi thôi
- khác biệt
- khác nhau
- do
- tài liệu
- làm
- dont
- e
- Kinh tế
- Hiệu quả
- cho phép
- cuối
- Toàn bộ
- EPIC
- Trang thiết bị
- chủ yếu
- ước tính
- Ngay cả
- ví dụ
- mong đợi
- đắt tiền
- kinh nghiệm
- xa
- nhanh hơn
- hình
- Chảy
- sau
- Trong
- khúc sông cạn
- Miễn phí
- từ
- Full
- về cơ bản
- tài trợ
- hộp số
- Tổng Quát
- thế hệ
- Trí tuệ nhân tạo
- tốt
- GPU
- đồ thị
- tuyệt vời
- có
- Cứng
- phần cứng
- Có
- có
- he
- tại đây
- Cao
- cao
- người
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTTPS
- lớn
- Hype
- i
- xác định
- if
- hình ảnh
- quan trọng
- nâng cao
- cải thiện
- in
- Ưu đãi
- hệ thống riêng biệt,
- sự đổi mới
- đầu vào
- ĐIÊN
- lấy cảm hứng từ
- thay vì
- Tổ chức giáo dục
- tích hợp
- thú vị
- nội bộ
- Internet
- Phát minh
- IP
- trớ trêu
- IT
- sự lặp lại
- ITS
- chỉ
- Xe đẩy
- Biết
- hạ cánh
- mới nhất
- Luật
- lớp
- Lãnh đạo
- học
- trái
- ít
- Cấp
- Giấy phép
- Cấp phép
- Cấp phép
- Lượt thích
- dòng
- LINK
- ít
- Loài đà mã ở nam mỹ
- dài
- nhìn
- tìm kiếm
- thua
- sự mất
- Rất nhiều
- chính
- làm cho
- Làm
- nhiều
- thị trường
- lớn
- Trận đấu
- Có thể..
- Phương tiện truyền thông
- Siêu dữ liệu
- microsoft
- kiểu mẫu
- mô hình
- Kiếm tiền
- tiền
- chi tiết
- hầu hết
- nhiều
- Cần
- Cũng không
- Không
- Phi thương mại
- tại
- vật
- đối tượng
- of
- on
- ONE
- có thể
- mở
- mã nguồn mở
- dự án nguồn mở
- OpenAI
- or
- bình thường
- ban đầu
- Nền tảng khác
- ra
- đầu ra
- kết thúc
- riêng
- Hòa bình
- tham số
- qua
- Trả
- người
- thực hiện
- hiệu suất
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Điểm
- khả năng
- quyền lực
- Vấn đề
- Sản phẩm
- Sản phẩm
- dự án
- dự án
- độc quyền
- tương lai
- nâng cao
- nâng lên
- hơn
- có thật không
- gần đây
- phát hành
- đại diện
- nghiên cứu
- nhà nghiên cứu
- Thông tin
- sự hạn chế
- kết quả
- quyền
- vòng
- hoàng gia
- chạy
- s
- an toàn
- tương tự
- nói
- đã xem
- phân khúc
- bán
- riêng biệt
- Loạt Sách
- Dòng A
- phục vụ
- DỊCH VỤ
- định
- sự thiếu
- hiển thị
- kể từ khi
- duy nhất
- Kích thước máy
- nhỏ hơn
- thông minh
- So
- Mạng xã hội
- truyền thông xã hội
- Xã hội
- Phần mềm
- một số
- một cái gì đó
- nguồn
- mã nguồn
- tiêu
- ổn định
- stanford
- bắt đầu-up
- khởi động
- Chiến lược
- như vậy
- đề nghị
- phải
- vượt qua
- Hãy
- Lấy
- mất
- Công nghệ
- hơn
- việc này
- Sản phẩm
- Nguồn
- thế giới
- cung cấp their dịch
- Them
- sau đó
- Đó
- họ
- điều
- nghĩ
- Thứ ba
- điều này
- những
- số ba
- thời gian
- đến
- quá
- mất
- Train
- đào tạo
- Hội thảo
- XOAY
- biến
- Dưới
- hiểu
- độc đáo
- không giống
- cho đến khi
- us
- sử dụng
- đã sử dụng
- sử dụng
- sử dụng
- Định giá
- giá trị
- xác minh
- phiên bản
- thẳng đứng
- rất
- thông qua
- Xem
- tầm nhìn
- vmware
- vs
- chờ đợi
- muốn
- là
- Đường..
- we
- đi
- là
- Điều gì
- khi nào
- cái nào
- CHÚNG TÔI LÀ
- toàn bộ
- có
- sẽ
- WISE
- với
- Công việc
- thế giới
- Sai
- bạn
- zephyrnet









