Nhận dạng ký tự quang học (OCR), phương pháp chuyển đổi văn bản viết tay / in thành văn bản được mã hóa bằng máy, luôn là lĩnh vực nghiên cứu chính trong thị giác máy tính do có nhiều ứng dụng trên nhiều lĩnh vực khác nhau - Các ngân hàng sử dụng OCR để so sánh các câu lệnh; Các chính phủ sử dụng OCR để thu thập phản hồi khảo sát.

Do sự đa dạng về kiểu chữ viết tay và văn bản in, các phương pháp tiếp cận gần đây của OCR kết hợp học sâu để đạt được độ chính xác cao hơn. Vì học sâu đòi hỏi một lượng lớn dữ liệu để đào tạo mô hình, các công ty như Google có lợi thế hơn trong việc tạo ra các kết quả đầy hứa hẹn với các dịch vụ OCR của họ.
Bài viết này đi sâu vào các chi tiết của Google Vision OCR, bao gồm một hướng dẫn đơn giản về python, phạm vi ứng dụng, giá cả và các lựa chọn thay thế khác.
- Google Cloud Vision OCR là gì?
- Hướng dẫn đơn giản
- Tại sao OCR?
- Các trường hợp sử dụng mẫu
- GIÁ CẢ
- Các tính năng nổi bật của Google Cloud Vision OCR
- Lựa chọn thay thế
- Các vấn đề chung
Google Cloud Vision là gì?

Google Cloud Vision OCR là một phần của Google Cloud Vision API để trích xuất văn bản từ hình ảnh. Cụ thể, có hai chú thích để giúp nhận dạng ký tự:
- Văn bản_Chú thích: Nó trích xuất và xuất văn bản được mã hóa bằng máy từ bất kỳ hình ảnh nào (ví dụ: ảnh chụp quang cảnh đường phố hoặc khung cảnh). Vì ban đầu nó được thiết kế để có thể sử dụng trong các tình huống ánh sáng khác nhau, nên về mặt nào đó, mô hình này mạnh mẽ hơn trong việc đọc các từ thuộc các kiểu khác nhau, nhưng chỉ ở mức độ thưa thớt hơn. Tệp JSON được trả về bao gồm toàn bộ các chuỗi cũng như các từ riêng lẻ và các hộp giới hạn tương ứng của chúng.
- Tài liệu_Văn bản_Chú thích: Điều này được thiết kế đặc biệt cho các tài liệu văn bản được trình bày dày đặc (ví dụ: sách được quét). Do đó, trong khi nó hỗ trợ đọc các văn bản nhỏ hơn và tập trung hơn, nó ít thích ứng hơn với các hình ảnh hoang dã. Thông tin như đoạn văn, khối và ngắt được bao gồm trong tệp JSON đầu ra.
Tìm kiếm giải pháp OCR khắc phục những thiếu sót của Google Cloud Vision hoặc OCR khu vực? Cung cấp Nanonet™ một vòng quay để có độ chính xác cao hơn, tính linh hoạt cao hơn và các loại tài liệu rộng hơn!
Hướng dẫn đơn giản
Phần sau đây giới thiệu một hướng dẫn đơn giản để bắt đầu với API Google Vision, đặc biệt là về cách sử dụng nó cho dịch vụ Google Cloud Vision OCR.
Tổng quan đơn giản
Ý tưởng đằng sau điều này là rất trực quan và đơn giản.
1) Về cơ bản, bạn gửi một hình ảnh (từ xa hoặc từ bộ nhớ cục bộ của bạn) tới API Google Cloud Vision.
2) Hình ảnh được xử lý từ xa trên Google Cloud và tạo ra các định dạng JSON tương ứng đối với chức năng bạn đã gọi.
3) Tệp JSON được trả về dưới dạng đầu ra sau khi hàm được gọi.
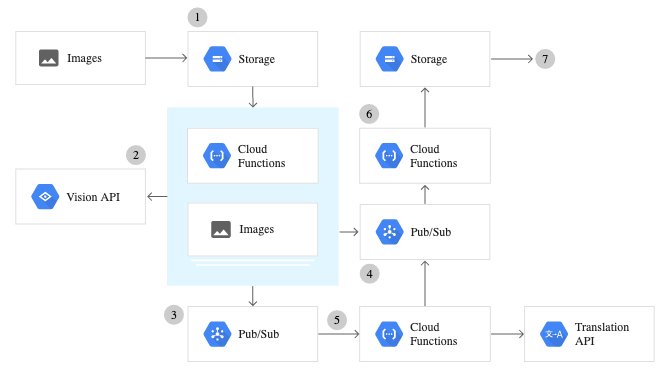
Thiết lập API Google Cloud Vision
Để sử dụng bất kỳ dịch vụ nào do Google Vision API cung cấp, người ta phải định cấu hình Google Cloud Console và thực hiện một loạt các bước để xác thực. Sau đây là tổng quan từng bước về cách thiết lập toàn bộ dịch vụ API Vision.
- Tạo dự án trong Google Cloud Console - Một dự án cần được tạo để bắt đầu sử dụng bất kỳ dịch vụ Vision nào. Dự án tổ chức các tài nguyên như cộng tác viên, API và thông tin giá cả.
- Bật thanh toán - Để bật API Vision, trước tiên bạn phải bật tính năng thanh toán cho dự án của mình. Chi tiết về giá cả sẽ được đề cập trong phần sau.
- Bật API Vision
- Tạo tài khoản dịch vụ - Tạo tài khoản dịch vụ và liên kết với dự án đã tạo, sau đó tạo khóa tài khoản dịch vụ. Khóa sẽ được xuất và tải xuống dưới dạng tệp JSON vào máy tính của bạn.
- Thiết lập biến môi trường GOOGLE_APPLICATION_CREDENTIALS; Để thiết lập biến môi trường này, hãy chạy biến này trên Mac / Linux hoặc Windows.
- Khối mã cho Mac / Linux
- Khối mã cho Windows
Bạn có thể tìm thấy quy trình chi tiết hơn của các bước nói trên từ tài liệu chính thức do Google Cloud cung cấp tại đây:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Chức năng OCR Google Vision đơn giản bằng Python
API Google Cloud Vision hoạt động với nhiều ngôn ngữ phổ biến, từ Java, Node.js, Python, đến ngôn ngữ riêng của Google là Go. Để đơn giản, chúng tôi giới thiệu một phương thức gọi đơn giản trong Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Nói cách khác, phương thức này do đó gọi hàm văn bản_annotation, sau đó trích xuất thêm các câu trả lời và in thông tin ra. tài liệu_text_annotation cũng có thể được gọi bằng cách sử dụng cùng một cách để truy xuất các văn bản dày đặc. Người ta cũng có thể phát hiện hình ảnh từ xa bằng cách cài đặt hình ảnh thông qua:
image.source.image_uri = urinơi đi tiểu là bồn tiểu của hình ảnh.
Có thể truy xuất thêm chi tiết về các mã tại đây:
https://cloud.google.com/vision
Tìm kiếm một giải pháp OCR khắc phục những thiếu sót của Google Cloud Vision? Cung cấp Nanonet™ một vòng quay để có độ chính xác cao hơn, tính linh hoạt cao hơn và các loại tài liệu rộng hơn!
Mức đầu ra được cung cấp
Để hỗ trợ phân tích thêm dữ liệu của văn bản, hai chức năng OCR của Google cung cấp các mức đầu ra khác nhau cho người dùng sử dụng: văn bản_annotation, cả toàn bộ chuỗi (nếu được Google coi là một câu hoặc cụm từ) và các từ riêng lẻ bên trong; vì tài liệu_text_annotation, vì mô hình được tối ưu hóa cho văn bản dày đặc, trang, khối, đoạn, từ và ngắt đều được cung cấp như một phần của đầu ra.
Nó hoạt động tốt như thế nào?
Làm thế nào mạnh mẽ là các mô hình?
Như đã đề cập trước đây, Google cung cấp hai chức năng cho OCR trong hai trường hợp khác nhau. Phần sau mô tả khả năng của hai chức năng trong việc truy xuất các loại dữ liệu khác nhau.
Dữ liệu in
Loại dữ liệu dễ hiểu nhất là dữ liệu văn bản in, tức là văn bản viết bằng máy tính được in và quét. OCR là bắt buộc khi chúng tôi chỉ có bản in của những dữ liệu này thay vì các văn bản gốc được mã hóa bằng máy. Vì hầu hết các văn bản này đều chặt chẽ và được đóng gói trong các trang, tài liệu_text_annotation sẽ là một lựa chọn tốt hơn.
Dữ liệu viết tay
Nội dung có thể chứa văn bản viết tay và kiểu dữ liệu viết tay có thể thay đổi đáng kể. Tuy nhiên, Google Vision OCR cung cấp độ chính xác khá cao miễn là các ghi chú viết tay không quá lộn xộn. Tùy thuộc vào cách trình bày phương tiện của dữ liệu viết tay được đóng gói, chúng tôi sử dụng một trong hai hàm trên cơ sở từng trường hợp cụ thể.
Dữ liệu được xoay vòng / In-The-Wild
Khi hình ảnh hoặc ảnh quét được trình bày ở các góc không chính thống hoặc không thẳng hàng, chúng tôi coi chúng là dữ liệu tự nhiên. Văn bản có thể khó bị phát hiện hơn ngay từ đầu và do đó chúng tôi thường sử dụng văn bản_annotation chức năng được thiết kế để xử lý dữ liệu tự nhiên ngay từ đầu. Dựa trên một số thử nghiệm về việc đi qua các văn bản dọc và biển báo đường được chụp ở các góc độ khác nhau, chúng tôi cho thấy Google Vision OCR thực sự hoạt động tốt trên dữ liệu từ các môi trường khác nhau.
Tại sao OCR?
Nhiều dữ liệu chúng ta có ngày nay ở định dạng phi cấu trúc. Ví dụ, với một hình ảnh, một tài liệu được quét hoặc một bức ảnh, trong khi con người có thể nhanh chóng nhận ra văn bản và giải thích thêm ý nghĩa, thì tất cả dữ liệu văn bản chỉ là pixel với màu sắc, không mang lại ý nghĩa thực sự cho máy móc.

Khi các công ty hoặc tập đoàn lớn xử lý khối lượng lớn thủ tục giấy tờ, khối lượng dữ liệu lớn sẽ khiến bất kỳ phân loại hoặc xử lý dữ liệu nào không thể thực hiện chỉ với nỗ lực của con người - đây là lúc văn bản được mã hóa bằng máy trở nên hữu ích.
Sau khi chuyển đổi OCR, thông tin sau đó có thể được phân tích bằng nhiều phương pháp khác nhau tùy thuộc vào bản chất của dữ liệu:
- Đối với dữ liệu số, các phương pháp thống kê có thể được áp dụng trực tiếp để phân tích bất kỳ mối tương quan nào. Chúng tôi cũng có thể áp dụng các phương pháp học máy truyền thống (ví dụ: KNN, K-Means, Hồi quy tuyến tính) hoặc các phương pháp tiếp cận học sâu để tạo ra các mô hình dự đoán cho hồi quy và / hoặc phân loại.
- Đối với dữ liệu văn bản, có thể cần nhiều giai đoạn xử lý hơn. Quá trình phân tích và diễn giải dữ liệu văn bản thành các số liệu thống kê có ý nghĩa thường được gọi là xử lý ngôn ngữ tự nhiên (NLP). Cụ thể, chúng tôi có thể trích xuất các con số hoặc thậm chí ngữ nghĩa / bầu không khí dựa trên nội dung nhất định.
Tất cả những phân tích này có thể cho phép các công ty, đặc biệt là những công ty có lượng lớn dữ liệu mới mỗi ngày, tạo ra các mô hình mạnh mẽ và thậm chí tự động hóa rất nhiều quy trình và thay thế các phương pháp truyền thống tốn nhiều công sức và nhiều lỗi. Phần sau đi sâu vào một số ví dụ chi tiết về cách OCR có thể được sử dụng.
Tìm kiếm một giải pháp OCR khắc phục những thiếu sót của Google Cloud Vision? Cung cấp Nanonet™ một vòng quay để có độ chính xác cao hơn, tính linh hoạt cao hơn và các loại tài liệu rộng hơn!
Các trường hợp sử dụng mẫu
Đọc biển số xe

Có lẽ một trong những ứng dụng phổ biến nhất của OCR ngày nay là ứng dụng trong việc đọc biển số xe. Ở các nước phát triển, các bãi đậu xe thường đi kèm với mô hình đọc biển số xe để xác định thời gian vào, ra, thậm chí là vị trí đậu chính xác của mỗi ô tô. Một số bãi đậu xe thậm chí còn được kết nối với mạng lưới của chính phủ để thu phí đậu xe trực tiếp cho các gia đình - tất cả đều giảm bớt những nỗ lực dư thừa của con người.
Các mô hình OCR biển số cũng có thể được sử dụng để phát hiện vi phạm giao thông, giúp giảm thời gian cho cảnh sát nhập dữ liệu của chiếc xe vi phạm theo cách thủ công.
Biên nhận và Quét hóa đơn

Dự báo tài chính và cân đối tài sản và nợ phải trả của công ty là những hoạt động quan trọng đối với bất kỳ công ty nào. Khi các công ty lớn mua hàng với số lượng lớn từ nhiều lĩnh vực trong suốt cả năm, họ phải thu thập và xử lý tỉ mỉ tất cả các hóa đơn và biên lai khi lập báo cáo tài chính.
Với sự trợ giúp của OCR, chúng tôi có thể tạo các đường ống tự động nhận ra một số định dạng hóa đơn và chuyển chúng thành số. Những nỗ lực lao động chỉ được yêu cầu để kiểm tra, và dữ liệu có cấu trúc và các con số có thể cho phép công ty nhanh chóng cân bằng các dòng tiền vào và ra, tạo ra các dự báo tài chính, cũng như đề phòng bất kỳ thao tác xấu nào đối với tài chính của công ty.
Hồ sơ y tế điện

Dữ liệu về bệnh nhân thường nằm rải rác quanh một khu vực, quốc gia, hoặc thậm chí giữa các quốc gia tùy thuộc vào lối sống của từng cá nhân. Do phong cách phòng khám và bệnh viện khác nhau (các bệnh viện lớn có thể có tổ chức cơ sở dữ liệu trong khi các bác sĩ ở các phòng khám nhỏ hơn có thể viết hồ sơ bằng tay), độ tuổi của bệnh nhân (bệnh nhân lớn tuổi có thể được đưa vào một cơ sở dữ liệu cụ thể trước khi cải tạo và kết hợp máy tính), và vị trí của các cá nhân (mọi người có thể chuyển đến một thành phố khác hoặc thậm chí ra nước ngoài), việc duy trì một nền y tế toàn dân có thể thực sự rất khó khăn.
Do đó, một OCR được đào tạo tốt sẽ trở nên tiện dụng khi chuyển EMR từ bệnh viện này sang bệnh viện khác hoặc chuyển đổi dữ liệu viết tay thành văn bản máy - cả hai đều có thể thúc đẩy quá trình tìm hiểu bệnh sử của bệnh nhân một cách nhanh chóng và ngắn gọn.
Biểu mẫu và Khảo sát

Các tổ chức (cho dù là chính phủ hay phi chính phủ) thường có thể yêu cầu phản hồi từ khách hàng hoặc công dân để cải thiện các kế hoạch khuyến mại và sản phẩm hiện tại của họ. Vì các biểu mẫu thường được viết bằng tay nên sẽ rất khó thực hiện bất kỳ phân tích thống kê trực tiếp nào. Do đó, quá trình chuyển đổi dữ liệu phi cấu trúc và các bản khảo sát viết tay thành các số liệu để tạo điều kiện tính toán có thể được hỗ trợ và đẩy nhanh bởi OCR.
Tìm kiếm một giải pháp OCR khắc phục những thiếu sót của Google Cloud Vision? Cung cấp Nanonet™ một vòng quay để có độ chính xác cao hơn, tính linh hoạt cao hơn và các loại tài liệu rộng hơn!
Định giá Cloud Vision
Theo Google trang mạng, cả hai văn bản_annotation và tài liệu_text_annotation được cung cấp ở cùng một mức giá như sau:
Mỗi tháng, 1000 đơn vị đầu tiên được cung cấp miễn phí, với 1000-5000000 được tính phí 1.5 đô la cho mỗi 1000 đơn vị. Sau khi chạm mốc 5000000, giá giảm xuống còn 0.6 đô la trên 1000 đơn vị (Mỗi hình ảnh được gửi qua API Google Vision được coi là một đơn vị).
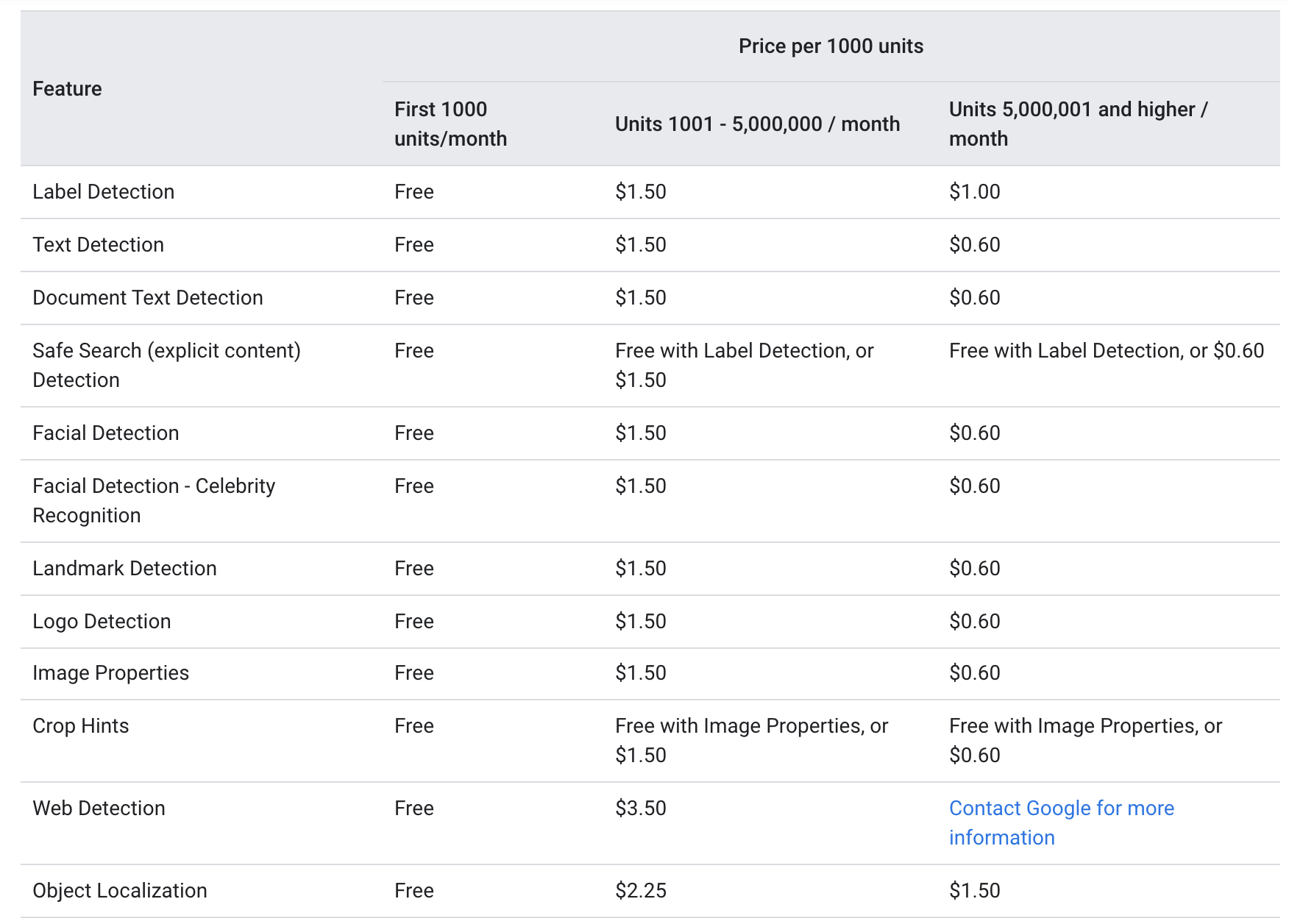
Giá trên cho thấy rằng dịch vụ OCR tương đối phải chăng cho cả các công ty nhỏ với tần suất sử dụng ít hơn cũng như các tập đoàn lớn nơi yêu cầu dịch vụ nhiều hơn 5000000 lần mỗi tháng.
Các tính năng nổi bật của Google Cloud Vision OCR
Google OCR có nhiều lợi ích khác nhau, sau đây chúng tôi mô tả một số lợi ích quan trọng nhất:
- Mạnh - Hai chức năng, phục vụ hai loại tài liệu văn bản phụ thuộc vào quyết định của người dùng, làm cho Google Vision OCR tương đối mạnh mẽ hơn các công cụ OCR một mô hình.
- Hỗ trợ ngôn ngữ - Với cơ sở dữ liệu ngôn ngữ có lẽ là lớn nhất, Google đã khuyên rằng OCR của họ có thể áp dụng cho hơn 60 ngôn ngữ, thử nghiệm trên vài chục ngôn ngữ khác và ánh xạ nhiều ngôn ngữ còn lại sang một mã ngôn ngữ khác hoặc trình nhận dạng ngôn ngữ chung.
- Dễ sử dụng - Bản thân mô hình này là một phần của thư viện Google Vision được tích hợp sẵn. Sau quá trình định cấu hình khóa API (khóa API này được yêu cầu bởi hầu hết các công cụ OCR), phương thức gọi hàm có thể được sử dụng trong nhiều ngôn ngữ một cách rất đơn giản.
- Khả năng mở rộng - Chiến lược giá của Google khuyến khích người dùng mở rộng quy mô sử dụng API, vì việc sử dụng nhiều hơn dẫn đến giá trung bình rẻ hơn.
- Tốc độ - Nền tảng lưu trữ của Google Cloud đồng hành một cách tuyệt vời với việc sử dụng API. Bằng cách tải hình ảnh lên ổ đĩa, thời gian phản hồi của API có thể rất nhanh và có thể mở rộng.

Tìm kiếm một giải pháp OCR khắc phục những thiếu sót của Google Cloud Vision? Cung cấp Nanonet™ một vòng quay để có độ chính xác cao hơn, tính linh hoạt cao hơn và các loại tài liệu rộng hơn!
Lựa chọn thay thế
Sau đây là một số dịch vụ OCR thay thế khác với API Google Vision, cùng với những ưu điểm và nhược điểm của từng dịch vụ.
ABBYY
ABBYY FineReader PDF là một OCR được phát triển bởi ABBYY, tập trung đặc biệt vào đọc pdf.
- Ưu điểm: ABBYY thân thiện với chi phí hơn nhiều cho người dùng cá nhân vì giá được phân đoạn thành các lĩnh vực nhỏ hơn (1000, 2000 trang, v.v.). Nó cũng hướng tới những khách hàng không phải là kỹ thuật vì nó là một ứng dụng đã được thương mại hóa.
- Nhược điểm: Phần mềm chỉ tập trung vào định dạng PDF và giá cả trở nên rất đắt khi thực hiện OCR quy mô lớn.
- Khi nào nên sử dụng: Đối với người dùng cá nhân chỉ muốn xử lý nhanh các tệp PDF, ABBYY có thể là một lựa chọn khả thi hơn so với API Google Vision mang lại sự linh hoạt hơn nhưng yêu cầu mã bổ sung.
microsoft
Microsoft Azure cũng cung cấp API Đọc cho OCR.
- Ưu điểm: Microsoft cung cấp mức giá rẻ hơn cho số lượng dữ liệu lớn hơn được sử dụng. Lưu trữ đám mây Azure cung cấp các dịch vụ tương tự như Google Cloud.
- Nhược điểm: Không có cấp miễn phí, trong khi các tùy chọn khác cung cấp các lệnh gọi API miễn phí với mức sử dụng thấp.
- Khi nào nên sử dụng: Các đường ống sản xuất OCR quy mô rất lớn có thể được hưởng lợi từ việc định giá của Microsoft.
Kofax
Tương tự như ABBYY, Kofax cũng cung cấp khả năng đọc OCR của các tệp PDF
- Ưu điểm: Giá cố định cho việc sử dụng cá nhân và chiết khấu được cung cấp cho doanh nghiệp. Hỗ trợ khách hàng 24/7 cũng được cung cấp.
- Nhược điểm: Chất lượng được khẳng định là không cao bằng ABBYY.
- Khi nào nên sử dụng: Doanh nghiệp nhỏ, yêu cầu sử dụng thấp.
Văn bản AWS
AWS Textract có vai trò rất giống với API Google Vision. Các dịch vụ và giá cả của họ rất giống nhau, vì vậy việc áp dụng cái nào hoàn toàn dựa trên sở thích của khách hàng.
Ống nano
Không giống như các dịch vụ đã thảo luận trước đây, OCR của Nanonets được phân loại sâu hơn thành các danh mục cụ thể, với các mô hình mạnh mẽ được đào tạo trên từng loại dữ liệu (ví dụ: biên lai, hóa đơn, giấy phép lái xe).
- Ưu điểm: OCR dành riêng cho danh mục, do đó cung cấp kết quả tốt hơn về độ chính xác khi các công ty yêu cầu OCR cho các ứng dụng cụ thể.
- Nhược điểm: Nanonet OCR có thể ít áp dụng hơn cho các cài đặt tự nhiên do các mô hình được điều chỉnh và cụ thể cao
- Khi nào nên sử dụng: Nếu các công ty yêu cầu OCR cho một loại dữ liệu cụ thể như hóa đơn, Nanonet có thể là một lựa chọn thân thiện với chi phí và có độ chính xác cao.
Bạn có thể dùng thử Nanonets Online OCR tại đây.
Các vấn đề thường gặp với Cloud Vision
Trong phần cuối cùng này, chúng tôi mong muốn giải quyết một số câu hỏi từ Stackoverflow liên quan đến việc quét tài liệu và OCR
Nhận dạng tài liệu bằng mạng nơ-ron
Đây là cách sử dụng chính xác của Google OCR! Làm theo các bước ở trên để quét tài liệu và thực hiện truy xuất văn bản.
Nắm bắt các chi tiết quan trọng nhất sau OCR
Ý tưởng phân tích cú pháp các nội dung có ý nghĩa nhất bên trong bất kỳ tài liệu nào được gọi là xử lý ngôn ngữ tự nhiên. Vì mọi tài liệu chứa thông tin như vậy ở các định dạng khác nhau, nên áp dụng một số phương pháp tiếp cận ML để làm như vậy. Tất nhiên, nếu tất cả các thẻ có cùng định dạng, các phương pháp dựa trên quy tắc để truy xuất văn bản có các ký tự chính nhất định (ví dụ: nếu nó chứa @ thì đó là một email) cũng sẽ hoạt động.
Nó có thể chạy ngoại tuyến không?
Link: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Tiếc là không có. API gọi Google Cloud OCR từ xa và bạn không thể làm việc ngoại tuyến vì API tốn tiền.
Nó có thể phát hiện xem một văn bản được in đậm hay in nghiêng không?
Không. Google OCR rất có thể sẽ phát hiện nội dung văn bản ngay cả khi nó được in đậm hoặc in nghiêng nhưng mô hình OCR không được thiết kế để hiểu các loại phông chữ.
Cập nhật: Đã thêm thông tin dựa trên các truy vấn từ độc giả.
- &
- a
- tăng tốc
- Tài khoản
- chính xác
- ngang qua
- hoạt động
- địa chỉ
- lợi thế
- Tất cả
- thay thế
- lựa chọn thay thế
- luôn luôn
- số lượng
- phân tích
- phân tích
- Một
- api
- API
- ứng dụng
- áp dụng
- Các Ứng Dụng
- các ứng dụng
- áp dụng
- cách tiếp cận
- KHU VỰC
- xung quanh
- bài viết
- Tài sản
- Xác thực
- tự động hóa
- Tự động
- Trung bình cộng
- Azure
- Đám mây Azure
- lý lịch
- Ngân hàng
- cơ sở
- trước
- hưởng lợi
- Lợi ích
- thanh toán
- Chặn
- đậm
- Sách
- biên giới
- nghỉ giải lao
- xe hơi
- Thẻ
- nhất định
- nhân vật
- phí
- tính phí
- rẻ hơn
- kiểm tra
- City
- phân loại
- đám mây
- Đám mây lưu trữ
- mã
- Chung
- Các công ty
- công ty
- so
- hoàn toàn
- máy tính
- máy tính
- kết nối
- Hãy xem xét
- An ủi
- chứa
- nội dung
- nội dung
- Chuyển đổi
- Tổng công ty
- Tương ứng
- Chi phí
- có thể
- nước
- đất nước
- tạo
- tạo ra
- Tạo
- Current
- khách hàng
- Hỗ trợ khách hàng
- khách hàng
- dữ liệu
- phân tích dữ liệu
- xử lý dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- ngày
- xử lý
- quyết định
- sâu
- phụ thuộc
- Tùy
- mô tả
- thiết kế
- chi tiết
- chi tiết
- phát hiện
- Xác định
- phát triển
- khác nhau
- khó khăn
- trực tiếp
- trực tiếp
- SỰ ĐA DẠNG
- Các bác sĩ
- tài liệu
- lĩnh vực
- xuống
- lái xe
- lái xe
- mỗi
- nới lỏng
- Cạnh
- nỗ lực
- những nỗ lực
- xuất hiện
- cho phép
- khuyến khích
- doanh nghiệp
- Môi trường
- đặc biệt
- chủ yếu
- vv
- ví dụ
- Ra
- Chất chiết xuất
- gia đình
- NHANH
- Tính năng
- thông tin phản hồi
- Lệ Phí
- Tài chính
- tài chính
- Công ty
- Tên
- cố định
- Linh hoạt
- tập trung
- theo
- tiếp theo
- định dạng
- các hình thức
- tìm thấy
- Miễn phí
- từ
- chức năng
- chức năng
- xa hơn
- Tổng Quát
- nhận được
- chính phủ
- Chính phủ
- lớn hơn
- xử lý
- giúp đỡ
- tại đây
- Cao
- cao hơn
- cao
- lịch sử
- bệnh viện
- Độ đáng tin của
- Hướng dẫn
- HTTPS
- Nhân loại
- Con người
- ý tưởng
- hình ảnh
- hình ảnh
- quan trọng
- không thể
- nâng cao
- bao gồm
- bao gồm
- Bao gồm
- hệ thống riêng biệt,
- các cá nhân
- Thông tin
- thông tin
- ví dụ
- trực quan
- các vấn đề
- IT
- chính nó
- Java
- giữ
- Key
- nhân công
- Ngôn ngữ
- Ngôn ngữ
- lớn
- lớn hơn
- lớn nhất
- Dẫn
- học tập
- Cấp
- niveaux
- Thư viện
- Giấy phép
- giấy phép
- lối sống
- Có khả năng
- LINK
- địa phương
- địa điểm thư viện nào
- . Các địa điểm
- dài
- máy
- học máy
- Máy móc
- chính
- làm cho
- cách thức
- thủ công
- Maps
- dấu
- lớn
- có nghĩa là
- có ý nghĩa
- y khoa
- trung bình
- đề cập
- phương pháp
- microsoft
- ML
- kiểu mẫu
- mô hình
- tiền
- tháng
- chi tiết
- hầu hết
- di chuyển
- nhiều
- Tự nhiên
- Thiên nhiên
- nhu cầu
- mạng
- Tuy nhiên
- Chú ý
- con số
- số
- nhiều
- cung cấp
- Cung cấp
- chính thức
- Ngoại tuyến
- Trực tuyến
- tối ưu hóa
- Tùy chọn
- Các lựa chọn
- gọi món
- Tổ chức
- Nền tảng khác
- riêng
- đóng gói
- bãi đậu xe
- một phần
- riêng
- đặc biệt
- Đi qua
- người
- có lẽ
- kế hoạch
- nền tảng
- Công an
- Phổ biến
- mạnh mẽ
- giá
- giá
- quá trình
- Quy trình
- xử lý
- Sản lượng
- Sản phẩm
- dự án
- dự
- hứa hẹn
- quảng cáo
- cho
- cung cấp
- cung cấp
- cung cấp
- mua hàng
- chất lượng
- Mau
- phạm vi
- khác nhau,
- RE
- độc giả
- Reading
- gần đây
- công nhận
- hồ sơ
- về
- khu
- xa
- yêu cầu
- cần phải
- Yêu cầu
- đòi hỏi
- nghiên cứu
- Thông tin
- phản ứng
- REST của
- Kết quả
- đường
- Vai trò
- chạy
- tương tự
- khả năng mở rộng
- Quy mô
- quét
- quét
- Ngành
- ý nghĩa
- Loạt Sách
- dịch vụ
- DỊCH VỤ
- phục vụ
- định
- thiết lập
- có ý nghĩa
- Dấu hiệu
- tương tự
- Đơn giản
- kể từ khi
- nhỏ
- So
- Phần mềm
- rắn
- giải pháp
- một số
- riêng
- đặc biệt
- Quay
- giai đoạn
- bắt đầu
- báo cáo
- thống kê
- số liệu thống kê
- là gắn
- Chiến lược
- đường phố
- cấu trúc
- hỗ trợ
- Hỗ trợ
- Khảo sát
- về
- Sản phẩm
- vì thế
- Thông qua
- khắp
- thời gian
- thời gian
- bây giờ
- đối với
- truyền thống
- giao thông
- Hội thảo
- Chuyển nhượng
- biến đổi
- loại
- Dưới
- hiểu
- sự hiểu biết
- các đơn vị
- phổ cập
- sử dụng
- Người sử dụng
- thường
- khác nhau
- tầm nhìn
- khối lượng
- Đồng hồ đeo tay
- liệu
- trong khi
- CHÚNG TÔI LÀ
- rộng hơn
- cửa sổ
- ở trong
- từ
- Công việc
- công trinh
- sẽ
- X
- năm
- trên màn hình