Trong bài này chúng ta sẽ tìm hiểu cách triển khai và sử dụng mô hình GPT4All trên máy tính chỉ có CPU của bạn (Tôi đang sử dụng một Macbook Pro không có GPU!)

Sử dụng GPT4All trên máy tính của bạn — Ảnh của tác giả
Trong bài viết này, chúng tôi sẽ cài đặt GPT4All trên máy tính cục bộ của mình (một LLM mạnh mẽ) và chúng tôi sẽ khám phá cách tương tác với các tài liệu của chúng tôi bằng python. Tập hợp các tệp PDF hoặc bài báo trực tuyến sẽ là cơ sở kiến thức cho câu hỏi/câu trả lời của chúng tôi.
Từ trang web chính thức GPT4All nó được mô tả là một chatbot miễn phí, chạy cục bộ, nhận biết quyền riêng tư. Không cần GPU hoặc internet.
GTP4All là một hệ sinh thái để đào tạo và triển khai mạnh mẽ và tùy chỉnh các mô hình ngôn ngữ lớn chạy tại địa phương trên CPU cấp tiêu dùng.
Mô hình GPT4All của chúng tôi là một tệp 4GB mà bạn có thể tải xuống và cắm vào phần mềm hệ sinh thái nguồn mở GPT4All. trí tuệ nhân tạo tạo điều kiện cho hệ sinh thái phần mềm an toàn và chất lượng cao, thúc đẩy nỗ lực cho phép các cá nhân và tổ chức dễ dàng đào tạo và triển khai các mô hình ngôn ngữ lớn của riêng họ tại địa phương.
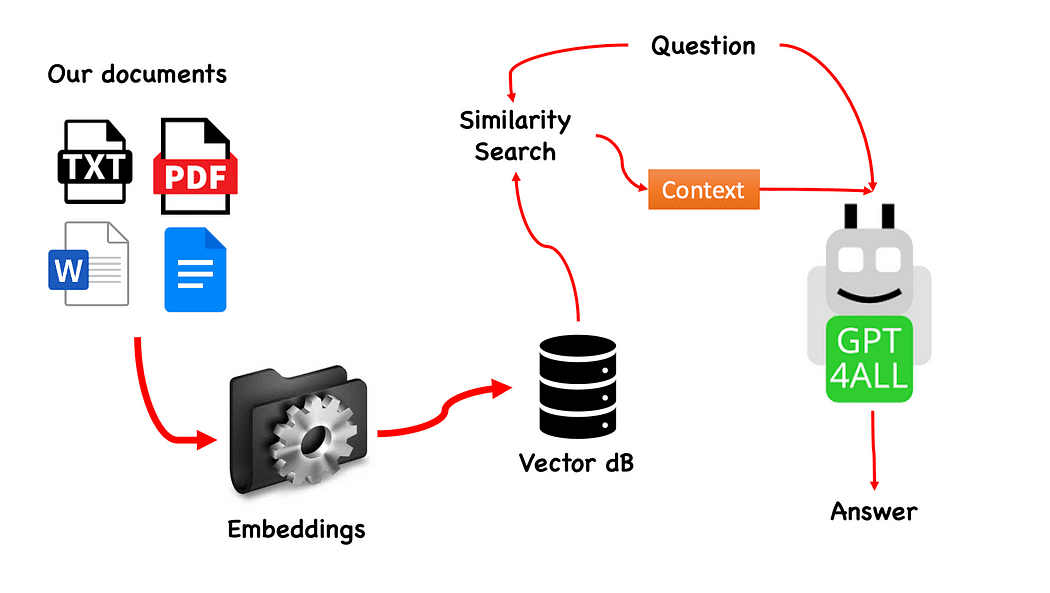
Quy trình làm việc của QnA với GPT4All — do tác giả tạo
Quá trình này thực sự đơn giản (khi bạn biết nó) và cũng có thể được lặp lại với các mô hình khác. Các bước thực hiện như sau:
- tải mô hình GPT4All
- sử dụng chuỗi lang để lấy tài liệu của chúng tôi và tải chúng
- chia tài liệu thành các phần nhỏ có thể tiêu hóa được bằng Embeddings
- Sử dụng FAISS để tạo cơ sở dữ liệu vectơ của chúng tôi với các phần nhúng
- Thực hiện tìm kiếm tương tự (tìm kiếm ngữ nghĩa) trên cơ sở dữ liệu vectơ của chúng tôi dựa trên câu hỏi mà chúng tôi muốn chuyển đến GPT4All: điều này sẽ được sử dụng làm bối cảnh cho câu hỏi của chúng tôi
- Cung cấp câu hỏi và ngữ cảnh cho GPT4All bằng chuỗi lang và chờ đợi câu trả lời.
Vì vậy, những gì chúng ta cần là Embeddings. Phép nhúng là biểu diễn bằng số của một phần thông tin, chẳng hạn như văn bản, tài liệu, hình ảnh, âm thanh, v.v. Biểu diễn nắm bắt ý nghĩa ngữ nghĩa của nội dung được nhúng và đây chính xác là điều chúng ta cần. Đối với dự án này, chúng tôi không thể dựa vào các mô hình GPU nặng: vì vậy chúng tôi sẽ tải xuống mô hình gốc của Alpaca và sử dụng từ chuỗi lang các LlamaCppNhúng. Đừng lo lắng! Mọi thứ được giải thích từng bước
Tạo môi trường ảo
Tạo một thư mục mới cho dự án Python mới của bạn, ví dụ GPT4ALL_Fabio (đặt tên của bạn…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioTiếp theo, tạo một môi trường ảo Python mới. Nếu bạn đã cài đặt nhiều phiên bản python, hãy chỉ định phiên bản bạn muốn: trong trường hợp này, tôi sẽ sử dụng bản cài đặt chính của mình, được liên kết với python 3.10.
python3 -m venv .venvLệnh python3 -m venv .venv tạo một môi trường ảo mới có tên .venv (dấu chấm sẽ tạo một thư mục ẩn tên là venv).
Môi trường ảo cung cấp bản cài đặt Python biệt lập, cho phép bạn cài đặt các gói và phần phụ thuộc chỉ cho một dự án cụ thể mà không ảnh hưởng đến quá trình cài đặt Python trên toàn hệ thống hoặc các dự án khác. Sự cô lập này giúp duy trì tính nhất quán và ngăn ngừa xung đột tiềm ẩn giữa các yêu cầu dự án khác nhau.
Khi môi trường ảo được tạo, bạn có thể kích hoạt nó bằng lệnh sau:
source .venv/bin/activate 
Kích hoạt môi trường ảo
Các thư viện để cài đặt
Đối với dự án chúng tôi đang xây dựng, chúng tôi không cần quá nhiều gói. Chúng tôi chỉ cần:
- liên kết python cho GPT4All
- Langchain để tương tác với các tài liệu của chúng tôi
LangChain là một khuôn khổ để phát triển các ứng dụng được hỗ trợ bởi các mô hình ngôn ngữ. Nó cho phép bạn không chỉ gọi ra một mô hình ngôn ngữ thông qua API mà còn kết nối một mô hình ngôn ngữ với các nguồn dữ liệu khác và cho phép một mô hình ngôn ngữ tương tác với môi trường của nó.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Đối với LangChain, bạn thấy rằng chúng tôi cũng đã chỉ định phiên bản. Thư viện này đang nhận được rất nhiều bản cập nhật gần đây, vì vậy để chắc chắn rằng thiết lập của chúng tôi cũng sẽ hoạt động vào ngày mai, tốt hơn là chỉ định một phiên bản mà chúng tôi biết là đang hoạt động tốt. Không có cấu trúc là một phụ thuộc cần thiết cho trình tải pdf và pytesseract và pdf2hình ảnh là tốt.
LƯU Ý: trên kho lưu trữ GitHub có một tệp tin tests.txt (được đề xuất bởi quảng cáo jl) với tất cả các phiên bản được liên kết với dự án này. Bạn có thể thực hiện cài đặt trong một lần, sau khi tải nó vào thư mục tệp dự án chính bằng lệnh sau:
pip install -r requirements.txtỞ cuối bài viết tôi đã tạo một phần khắc phục sự cố. Repo GitHub cũng đã cập nhật READ.ME với tất cả các thông tin này.
Hãy nhớ rằng một số thư viện có sẵn các phiên bản tùy thuộc vào phiên bản python bạn đang chạy trên môi trường ảo của mình.
Tải xuống trên PC của bạn các mô hình
Đây là một bước thực sự quan trọng.
Đối với dự án, chúng tôi chắc chắn cần GPT4All. Quá trình được mô tả trên Nomic AI thực sự phức tạp và đòi hỏi phần cứng mà không phải ai trong chúng ta cũng có (như tôi). Vì thế đây là liên kết đến mô hình đã được chuyển đổi và sẵn sàng để sử dụng. Chỉ cần nhấp vào tải xuống.
Tải xuống mô hình GPT4All
Như đã mô tả ngắn gọn trong phần giới thiệu, chúng tôi cũng cần mô hình cho phần nhúng, một mô hình mà chúng tôi có thể chạy trên CPU của mình mà không bị hỏng. Nhấn vào liên kết ở đây để tải xuống alpaca-native-7B-ggml đã được chuyển đổi thành 4 bit và sẵn sàng sử dụng để hoạt động như mô hình nhúng của chúng tôi.

Nhấp vào mũi tên tải xuống bên cạnh ggml-model-q4_0.bin
Tại sao chúng ta cần nhúng? Nếu bạn nhớ từ sơ đồ quy trình, bước đầu tiên được yêu cầu, sau khi chúng tôi thu thập tài liệu cho cơ sở tri thức của mình, là nhúng họ. Các nhúng LLamaCPP từ mô hình Alpaca này hoàn toàn phù hợp với công việc và mô hình này cũng khá nhỏ (4 Gb). Nhân tiện, bạn cũng có thể sử dụng mô hình Alpaca cho QnA của mình!
Cập nhật 2023.05.25: Người dùng Mani Windows đang gặp sự cố khi sử dụng các phần mềm nhúng llamaCPP. Điều này chủ yếu xảy ra vì trong quá trình cài đặt gói python llama-cpp-python với:
pip install llama-cpp-pythongói pip sẽ biên dịch từ nguồn thư viện. Windows thường không được cài đặt mặc định CMake hoặc trình biên dịch C trên máy. Nhưng đừng cảnh giác có một giải pháp
Chạy cài đặt llama-cpp-python, do LangChain yêu cầu với llamaEmbeddings, trên windows Trình biên dịch CMake C không được cài đặt theo mặc định, vì vậy bạn không thể xây dựng từ nguồn.
Trên Người dùng Mac có Xtools và trên Linux, thông thường trình biên dịch C đã có sẵn trên HĐH.
Để tránh vấn đề bạn PHẢI sử dụng bánh xe tuân thủ trước.
Đi đây https://github.com/abetlen/llama-cpp-python/releases
và tìm bánh xe phù hợp cho kiến trúc và phiên bản python của bạn — bạn PHẢI dùng Weels Phiên bản 0.1.49 bởi vì các phiên bản cao hơn không tương thích.
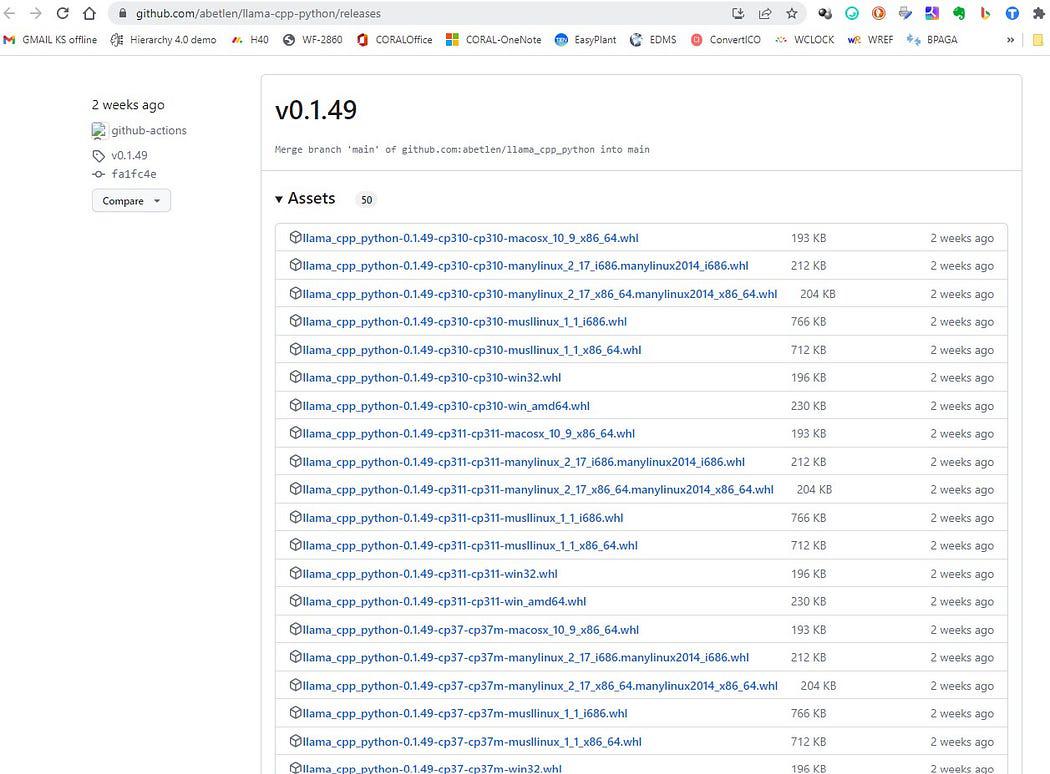
Ảnh chụp màn hình từ https://github.com/abetlen/llama-cpp-python/releases
Trong trường hợp của tôi, tôi có Windows 10, 64 bit, python 3.10
vì vậy tệp của tôi là llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
T vấn đề được theo dõi trên kho lưu trữ GitHub
Sau khi tải xuống, bạn cần đặt hai mô hình vào thư mục mô hình, như hình bên dưới.

Cấu trúc thư mục và nơi đặt các tệp mô hình
Vì chúng tôi muốn kiểm soát tương tác của mình với mô hình GPT, chúng tôi phải tạo một tệp python (hãy gọi nó là pygpt4all_test.py), nhập các phụ thuộc và đưa ra hướng dẫn cho mô hình. Bạn sẽ thấy điều đó khá dễ dàng.
from pygpt4all.models.gpt4all import GPT4AllĐây là ràng buộc trăn cho mô hình của chúng tôi. Bây giờ chúng ta có thể gọi nó và bắt đầu hỏi. Hãy thử một sáng tạo.
Chúng tôi tạo một hàm đọc lệnh gọi lại từ mô hình và yêu cầu GPT4All hoàn thành câu của mình.
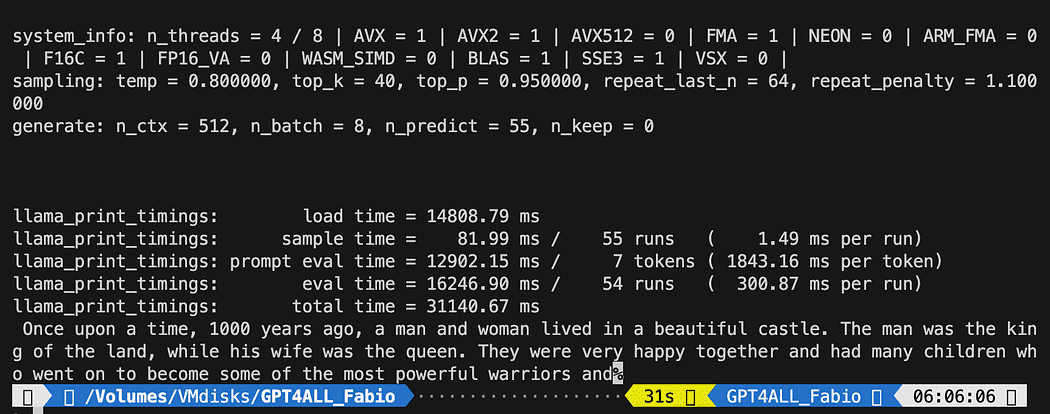
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Câu lệnh đầu tiên nói cho chương trình của chúng ta biết nơi tìm mô hình (hãy nhớ những gì chúng ta đã làm trong phần trên)
Câu lệnh thứ hai yêu cầu mô hình tạo phản hồi và hoàn thành lời nhắc của chúng tôi “Ngày xửa ngày xưa”.
Để chạy nó, hãy đảm bảo rằng môi trường ảo vẫn được kích hoạt và chỉ cần chạy:
python3 pygpt4all_test.pyBạn sẽ thấy văn bản tải của mô hình và phần hoàn thành của câu. Tùy thuộc vào tài nguyên phần cứng của bạn, có thể mất một chút thời gian.
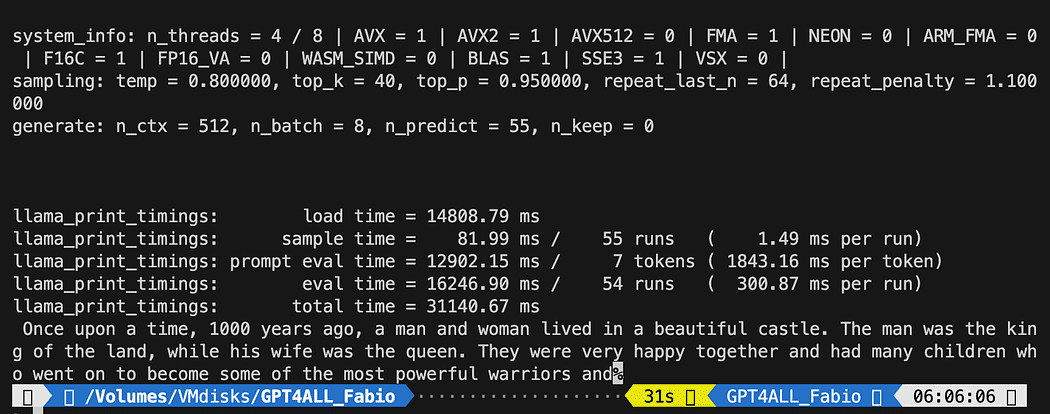
Kết quả có thể khác với kết quả của bạn… Nhưng đối với chúng tôi, điều quan trọng là nó đang hoạt động và chúng tôi có thể tiếp tục với LangChain để tạo một số nội dung nâng cao.
LƯU Ý (cập nhật 2023.05.23): nếu bạn gặp lỗi liên quan đến pygpt4all, hãy kiểm tra phần khắc phục sự cố về chủ đề này với giải pháp do Rajneesh Aggarwal or của Oscar Jung.
LangChain framework là một thư viện thực sự tuyệt vời. Nó cung cấp Các thành phần để làm việc với các mô hình ngôn ngữ theo cách dễ sử dụng và nó cũng cung cấp Chains. Chuỗi có thể được coi là lắp ráp các thành phần này theo những cách cụ thể để hoàn thành tốt nhất một trường hợp sử dụng cụ thể. Chúng được dự định là một giao diện cấp cao hơn mà qua đó mọi người có thể dễ dàng bắt đầu với một trường hợp sử dụng cụ thể. Những chuỗi này cũng được thiết kế để có thể tùy chỉnh.
Trong thử nghiệm python tiếp theo của chúng tôi, chúng tôi sẽ sử dụng một Mẫu lời nhắc. Các mô hình ngôn ngữ lấy văn bản làm đầu vào — văn bản đó thường được gọi là dấu nhắc. Thông thường, đây không chỉ đơn giản là một chuỗi được mã hóa cứng mà là sự kết hợp của một mẫu, một số ví dụ và đầu vào của người dùng. LangChain cung cấp một số lớp và chức năng để giúp việc xây dựng và làm việc với lời nhắc trở nên dễ dàng. Hãy xem làm thế nào chúng ta có thể làm điều đó quá.
Tạo một tệp python mới và gọi nó là my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Chúng tôi đã nhập từ LangChain Mẫu Prompt và Chuỗi và lớp GPT4All llm để có thể tương tác trực tiếp với mô hình GPT của chúng tôi.
Sau đó, sau khi thiết lập đường dẫn llm của chúng tôi (như chúng tôi đã làm trước đây), chúng tôi khởi tạo trình quản lý gọi lại để chúng tôi có thể nắm bắt các phản hồi cho truy vấn của mình.
Để tạo một mẫu thực sự dễ dàng: làm theo hướng dẫn tài liệu hướng dẫn chúng ta có thể sử dụng một cái gì đó như thế này…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Sản phẩm mẫu biến là một chuỗi nhiều dòng chứa cấu trúc tương tác của chúng tôi với mô hình: trong dấu ngoặc nhọn, chúng tôi chèn các biến bên ngoài vào mẫu, trong kịch bản của chúng tôi là câu hỏi.
Vì nó là một biến nên bạn có thể quyết định xem đó là câu hỏi được mã hóa cứng hay câu hỏi do người dùng nhập vào: đây là hai ví dụ.
# Hardcoded question
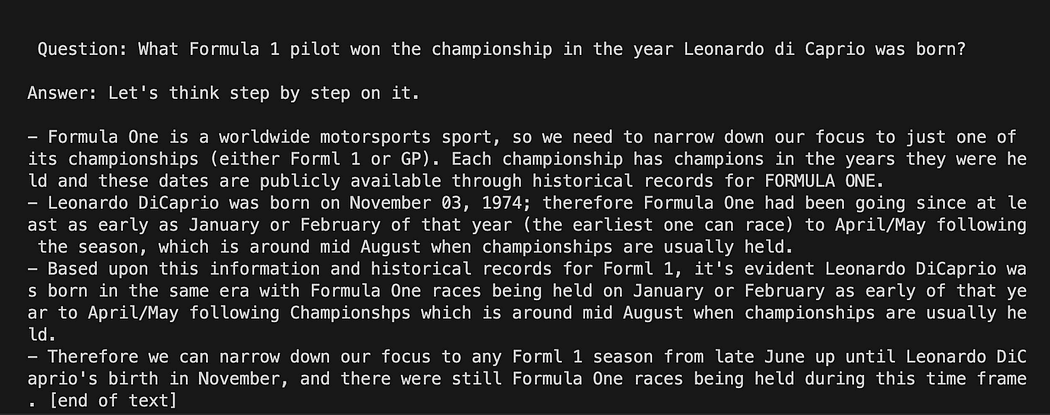
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Đối với lần chạy thử nghiệm của chúng tôi, chúng tôi sẽ nhận xét đầu vào của người dùng. Bây giờ chúng ta chỉ cần liên kết mẫu, câu hỏi và mô hình ngôn ngữ với nhau.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Hãy nhớ xác minh môi trường ảo của bạn vẫn được kích hoạt và chạy lệnh:
python3 my_langchain.pyBạn có thể nhận được một kết quả khác với tôi. Điều tuyệt vời là bạn có thể thấy toàn bộ lý do mà GPT4All đang cố gắng đưa ra câu trả lời cho bạn. Điều chỉnh câu hỏi cũng có thể mang lại cho bạn kết quả tốt hơn.
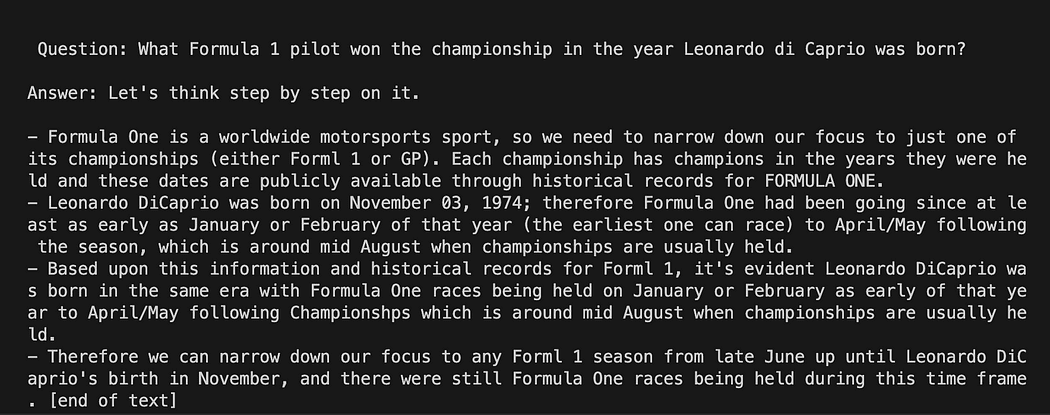
Langchain với Prompt Template trên GPT4All
Ở đây chúng tôi bắt đầu phần tuyệt vời, bởi vì chúng tôi sẽ nói chuyện với các tài liệu của mình bằng GPT4All với tư cách là một chatbot trả lời các câu hỏi của chúng tôi.
Trình tự các bước, đề cập đến Quy trình làm việc của QnA với GPT4All, là tải các tệp pdf của chúng tôi, biến chúng thành nhiều phần. Sau đó, chúng tôi sẽ cần một Cửa hàng Vector để nhúng. Chúng tôi cần cung cấp các tài liệu được chia nhỏ của mình trong một kho lưu trữ vectơ để truy xuất thông tin và sau đó chúng tôi sẽ nhúng chúng cùng với tìm kiếm tương tự trên cơ sở dữ liệu này làm ngữ cảnh cho truy vấn LLM của chúng tôi.
Đối với mục đích này, chúng tôi sẽ sử dụng FAISS trực tiếp từ chuỗi lang thư viện. FAISS là thư viện mã nguồn mở của Facebook AI Research, được thiết kế để nhanh chóng tìm thấy các mục tương tự trong bộ sưu tập lớn dữ liệu nhiều chiều. Nó cung cấp các phương pháp lập chỉ mục và tìm kiếm để giúp phát hiện các mục giống nhau nhất trong tập dữ liệu dễ dàng và nhanh hơn. Nó đặc biệt thuận tiện cho chúng tôi vì nó đơn giản hóa truy xuất thông tin và cho phép chúng tôi lưu cục bộ cơ sở dữ liệu đã tạo: điều này có nghĩa là sau lần tạo đầu tiên, nó sẽ được tải rất nhanh để sử dụng tiếp.
Tạo chỉ số vector db
Tạo một tập tin mới và gọi nó my_know_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeCác thư viện đầu tiên giống như chúng tôi đã sử dụng trước đây: ngoài ra chúng tôi đang sử dụng chuỗi lang để tạo chỉ mục cửa hàng vector, LlamaCppNhúng để tương tác với mô hình Alpaca của chúng tôi (được lượng tử hóa thành 4-bit và được biên dịch bằng thư viện cpp) và trình tải PDF.
Hãy cũng tải các LLM của chúng ta bằng các đường dẫn riêng của chúng: một cho phần nhúng và một cho việc tạo văn bản.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Để kiểm tra, hãy xem liệu chúng tôi có đọc được tất cả các tệp pfd hay không: bước đầu tiên là khai báo 3 chức năng sẽ được sử dụng trên mỗi tài liệu. Đầu tiên là chia văn bản được trích xuất thành nhiều phần, thứ hai là tạo chỉ mục vectơ với siêu dữ liệu (như số trang, v.v.) và cuối cùng là để kiểm tra tìm kiếm tương tự (tôi sẽ giải thích rõ hơn sau).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesBây giờ chúng ta có thể kiểm tra việc tạo chỉ mục cho các tài liệu trong tài liệu thư mục: chúng tôi cần đặt tất cả các tệp pdf của mình ở đó. chuỗi lang cũng có một phương pháp để tải toàn bộ thư mục, bất kể loại tệp: vì quá trình đăng tải phức tạp, tôi sẽ đề cập đến nó trong bài viết tiếp theo về các mô hình LaMini.

thư mục tài liệu của tôi chứa 4 tệp pdf
Chúng tôi sẽ áp dụng các chức năng của mình cho tài liệu đầu tiên trong danh sách
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)Trong những dòng đầu tiên, chúng tôi sử dụng thư viện os để lấy danh sách các tập tin pdf bên trong thư mục tài liệu. Sau đó chúng tôi tải tài liệu đầu tiên (doc_list[0]) từ thư mục tài liệu với chuỗi lang, chia thành nhiều phần và sau đó chúng tôi tạo cơ sở dữ liệu vectơ bằng LLama nhúng.
Như bạn đã thấy, chúng tôi đang sử dụng phương pháp pyPDF. Cái này sử dụng lâu hơn một chút vì bạn phải tải từng tệp một, nhưng tải PDF bằng cách sử dụng pypdf vào mảng tài liệu cho phép bạn có một mảng trong đó mỗi tài liệu chứa nội dung trang và siêu dữ liệu với page con số. Điều này thực sự thuận tiện khi bạn muốn biết các nguồn ngữ cảnh mà chúng tôi sẽ cung cấp cho GPT4All với truy vấn của mình. Đây là ví dụ từ readthedocs:
Ảnh chụp màn hình từ Tài liệu Langchain
Chúng ta có thể chạy tệp python bằng lệnh từ thiết bị đầu cuối:
python3 my_knowledge_qna.pySau khi tải mô hình để nhúng, bạn sẽ thấy các mã thông báo đang hoạt động để lập chỉ mục: đừng lo lắng vì sẽ mất thời gian, đặc biệt nếu bạn chỉ chạy trên CPU, giống như tôi (mất 8 phút).
Hoàn thành db vector đầu tiên
Như tôi đã giải thích, phương pháp pyPDF chậm hơn nhưng cung cấp cho chúng tôi dữ liệu bổ sung để tìm kiếm sự tương đồng. Để lặp lại tất cả các tệp của chúng tôi, chúng tôi sẽ sử dụng một phương pháp thuận tiện từ FAISS cho phép chúng tôi HỢP NHẤT các cơ sở dữ liệu khác nhau lại với nhau. Những gì chúng tôi làm bây giờ là chúng tôi sử dụng mã ở trên để tạo db đầu tiên (chúng tôi sẽ gọi nó là db0) và với vòng lặp for, chúng tôi tạo chỉ mục của tệp tiếp theo trong danh sách và hợp nhất nó ngay lập tức với db0.
Đây là mã: lưu ý rằng tôi đã thêm một số nhật ký để cung cấp cho bạn trạng thái của tiến trình sử dụng datetime.datetime.now() và in vùng đồng bằng của thời gian kết thúc và thời gian bắt đầu để tính thời gian thực hiện thao tác (bạn có thể xóa nếu không thích).
Các hướng dẫn hợp nhất là như thế này
# merge dbi with the existing db0
db0.merge_from(dbi)Một trong những hướng dẫn cuối cùng là lưu cục bộ cơ sở dữ liệu của chúng tôi: toàn bộ quá trình tạo có thể mất hàng giờ đồng hồ (tùy thuộc vào số lượng tài liệu bạn có), vì vậy thật tốt khi chúng tôi chỉ phải thực hiện một lần!
# Save the databasae locally
db0.save_local("my_faiss_index")Đây là toàn bộ mã. Chúng tôi sẽ nhận xét nhiều phần về nó khi chúng tôi tương tác với GPT4All đang tải chỉ mục trực tiếp từ thư mục của chúng tôi.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Chạy file python mất 22 phút
Chạy file python mất 22 phút
Đặt câu hỏi cho GPT4All trên tài liệu của bạn
Bây giờ chúng tôi đang ở đây. Chúng tôi có chỉ mục của mình, chúng tôi có thể tải nó và với Mẫu lời nhắc, chúng tôi có thể yêu cầu GPT4All trả lời các câu hỏi của chúng tôi. Chúng tôi bắt đầu với một câu hỏi được mã hóa cứng và sau đó chúng tôi sẽ lặp lại các câu hỏi đầu vào của mình.
Đặt đoạn mã sau vào tệp python db_loading.py và chạy nó bằng lệnh từ terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
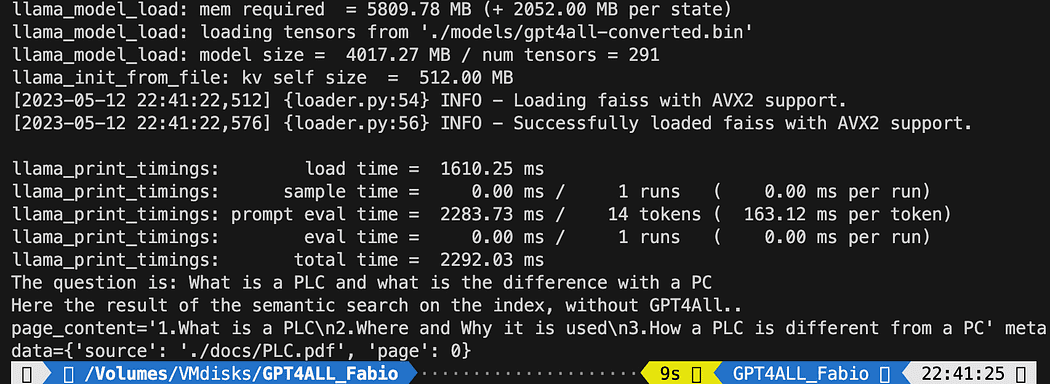
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Văn bản được in là danh sách 3 nguồn phù hợp nhất với truy vấn, cung cấp cho chúng tôi tên tài liệu và số trang.
Kết quả tìm kiếm ngữ nghĩa chạy tệp db_loading.py
Bây giờ chúng ta có thể sử dụng tìm kiếm tương đồng làm ngữ cảnh cho truy vấn của mình bằng cách sử dụng mẫu dấu nhắc. Sau 3 chức năng, chỉ cần thay thế tất cả các mã bằng cách sau:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Sau khi chạy bạn sẽ được kết quả như thế này (nhưng có thể thay đổi). Tuyệt vời không!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Nếu bạn muốn câu hỏi do người dùng nhập thay thế dòng
question = "What is a PLC and what is the difference with a PC"với một cái gì đó như thế này:
question = input("Your question: ")Đã đến lúc bạn thử nghiệm. Đặt các câu hỏi khác nhau về tất cả các chủ đề liên quan đến tài liệu của bạn và xem kết quả. Có một cơ hội lớn để cải thiện, chắc chắn là trên lời nhắc và mẫu: bạn có thể xem qua ở đây cho một số nguồn cảm hứng. Nhưng chuỗi lang tài liệu thực sự tuyệt vời (tôi có thể làm theo nó!!).
Bạn có thể làm theo mã từ bài viết hoặc kiểm tra nó trên repo github của tôi.
Fabio Matricardi một nhà giáo dục, giáo viên, kỹ sư và người đam mê học tập. Anh ấy đã giảng dạy cho các sinh viên trẻ trong 15 năm và hiện anh ấy đang đào tạo nhân viên mới tại Key Solution Srl. Anh ấy bắt đầu sự nghiệp của tôi với tư cách là Kỹ sư tự động hóa công nghiệp vào năm 2010. Đam mê lập trình từ khi còn là một thiếu niên, anh ấy đã khám phá ra vẻ đẹp của việc xây dựng phần mềm và Giao diện người máy để mang lại điều gì đó cho cuộc sống. Giảng dạy và huấn luyện là một phần công việc hàng ngày của tôi, cũng như nghiên cứu và học cách trở thành một nhà lãnh đạo nhiệt huyết với các kỹ năng quản lý cập nhật. Hãy tham gia cùng tôi trong hành trình hướng tới một thiết kế tốt hơn, tích hợp hệ thống dự đoán bằng Máy học và Trí tuệ nhân tạo trong toàn bộ vòng đời kỹ thuật.
Nguyên. Đăng lại với sự cho phép.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- EVM tài chính. Giao diện hợp nhất cho tài chính phi tập trung. Truy cập Tại đây.
- Tập đoàn truyền thông lượng tử. Khuếch đại IR/PR. Truy cập Tại đây.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 1
- 10
- 11
- 12
- 13
- 14
- 15 năm
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- có khả năng
- Có khả năng
- Giới thiệu
- ở trên
- hoàn thành
- Hành động
- kích hoạt
- thêm
- Ngoài ra
- thêm vào
- tiên tiến
- ảnh hưởng đến
- Sau
- AI
- ai nghiên cứu
- Tất cả
- cho phép
- cho phép
- Đã
- Ngoài ra
- am
- tuyệt vời
- an
- phân tích
- và
- trả lời
- bất kì
- api
- các ứng dụng
- Đăng Nhập
- kiến trúc
- LÀ
- Mảng
- bài viết
- bài viết
- nhân tạo
- trí tuệ nhân tạo
- AS
- liên kết
- At
- âm thanh
- Tự động
- tự động
- Tự động hóa
- có sẵn
- tránh
- cơ sở
- dựa
- BE
- Làm đẹp
- bởi vì
- được
- trước
- được
- phía dưới
- BEST
- Hơn
- giữa
- Ngoài
- lớn
- BIN
- ràng buộc
- Một chút
- sinh
- một thời gian ngắn
- mang lại
- xây dựng
- Xây dựng
- được xây dựng trong
- Xe buýt
- nhưng
- by
- tính toán
- cuộc gọi
- gọi là
- Cuộc gọi
- CAN
- không thể
- Sức chứa
- chụp
- Tuyển Dụng
- mang
- trường hợp
- Catch
- CD
- nhất định
- chắc chắn
- chuỗi
- chuỗi
- chức vô địch
- chatbot
- ChatGPT
- kiểm tra
- hóa chất
- tốt nghiệp lớp XNUMX
- các lớp học
- Nhấp chuột
- huấn luyện
- mã
- mã số
- thu thập
- bộ sưu tập
- bộ sưu tập
- kết hợp
- bình luận
- thông thường
- giao tiếp
- Giao tiếp
- tương thích
- hoàn thành
- Hoàn thành
- hoàn thành
- phức tạp
- phức tạp
- các thành phần
- máy tính
- máy tính
- Kết nối
- kết nối
- xây dựng
- người tiêu dùng
- chứa
- nội dung
- bối cảnh
- điều khiển
- điều khiển
- điều khiển
- Tiện lợi
- chuyển đổi
- có thể
- che
- CPU
- tạo
- tạo ra
- tạo ra
- Tạo
- tạo
- Sáng tạo
- quan trọng
- tùy biến
- tiền thưởng
- dữ liệu
- Cơ sở dữ liệu
- cơ sở dữ liệu
- Ngày
- ngày giờ
- quyết định
- Mặc định
- xác định
- đồng bằng
- Phụ thuộc
- Tùy
- phụ thuộc
- triển khai
- mô tả
- Thiết kế
- thiết kế
- mong muốn
- phát triển
- thiết bị
- Thiết bị (Devices)
- ĐÃ LÀM
- sự khác biệt
- khác nhau
- tiêu hóa được
- kỹ thuật số
- trực tiếp
- khám phá
- phát hiện
- do
- tài liệu
- tài liệu hướng dẫn
- tài liệu
- làm
- doesn
- thực hiện
- dont
- DOT
- tải về
- lái xe
- suốt trong
- mỗi
- dễ dàng hơn
- dễ dàng
- dễ dàng
- hệ sinh thái
- Hệ sinh thái
- nỗ lực
- nhúng
- nhúng
- nhúng
- nhân viên
- cho phép
- cuối
- ky sư
- Kỹ Sư
- đăng ký hạng mục thi
- người đam mê
- Toàn bộ
- Môi trường
- lôi
- đặc biệt
- vv
- Ether (ETH)
- Ngay cả
- tất cả mọi thứ
- chính xác
- ví dụ
- ví dụ
- thực hiện
- hiện tại
- thử nghiệm
- Giải thích
- Giải thích
- giải thích
- ngoài
- Đối mặt
- tạo điều kiện
- phải đối mặt với
- NHANH
- nhanh hơn
- Tập tin
- Các tập tin
- Tìm kiếm
- cuối
- Tên
- phù hợp với
- dòng chảy
- theo
- sau
- tiếp theo
- sau
- Trong
- hình thức
- định dạng
- công thức
- Công thức 1
- Khung
- từ
- chức năng
- chức năng
- xa hơn
- tạo ra
- tạo ra
- thế hệ
- được
- GitHub
- Cho
- được
- cho
- Cho
- đi
- tốt
- GPU
- cấp
- Xử lý
- xảy ra
- Cứng
- phần cứng
- Có
- he
- nặng
- giúp
- tại đây
- Thành viên ẩn danh
- Cao
- cao hơn
- GIỜ LÀM VIỆC
- Độ đáng tin của
- Hướng dẫn
- HTML
- http
- HTTPS
- Nhân loại
- i
- ICS
- if
- hình ảnh
- ngay
- thực hiện
- nhập khẩu
- quan trọng
- cải thiện
- in
- bao gồm
- chỉ số
- chỉ số
- các cá nhân
- công nghiệp
- Tự động trong công nghiệp
- các ngành công nghiệp
- thông tin
- đầu vào
- đầu ra đầu vào
- đầu vào
- cài đặt, dựng lên
- cài đặt
- ví dụ
- hướng dẫn
- hội nhập
- Sự thông minh
- dự định
- tương tác
- tương tác
- Giao thức
- giao diện
- Internet
- trong
- Giới thiệu
- bị cô lập
- cô lập
- IT
- mặt hàng
- sự lặp lại
- ITS
- Việc làm
- tham gia
- cuộc hành trình
- chỉ
- Xe đẩy
- Key
- Biết
- kiến thức
- Ngôn ngữ
- lớn
- Họ
- một lát sau
- lãnh đạo
- học tập
- Cấp
- thư viện
- Thư viện
- Cuộc sống
- vòng đời
- Lượt thích
- dòng
- LINK
- linux
- Danh sách
- ít
- tải
- loader
- tải
- địa phương
- tại địa phương
- logic
- dài
- còn
- Xem
- Rất nhiều
- mac
- máy
- học máy
- máy móc thiết bị
- Chủ yếu
- phần lớn
- duy trì
- làm cho
- quản lý
- quản lý
- giám đốc
- Quản lý
- sản xuất
- nhiều
- Có thể..
- có nghĩa là
- có nghĩa
- Bộ nhớ
- đi
- sáp nhập
- Siêu dữ liệu
- phương pháp
- phương pháp
- tâm
- phút
- kiểu mẫu
- mô hình
- chi tiết
- hầu hết
- nhiều
- phải
- my
- tên
- tự nhiên
- Cần
- mạng
- Mới
- tiếp theo
- tại
- con số
- số
- vật
- of
- Cung cấp
- on
- hàng loạt
- ONE
- Trực tuyến
- có thể
- mã nguồn mở
- hoạt động
- Hoạt động
- or
- gọi món
- tổ chức
- OS
- Nền tảng khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- đầu ra
- kết thúc
- riêng
- gói
- gói
- trang
- Song song
- một phần
- riêng
- đặc biệt
- vượt qua
- đam mê
- con đường
- PC
- người
- thực hiện
- cho phép
- riêng
- hình ảnh
- mảnh
- phi công
- nhà máy
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- PLC
- xin vui lòng
- cắm
- cổng
- vị trí
- Bài đăng
- tiềm năng
- quyền lực
- nhà máy điện
- -
- mạnh mẽ
- trước
- ngăn chặn
- In
- in ấn
- vấn đề
- quá trình
- xử lý
- Quy trình
- chương trình
- lập trình
- Lập trình
- Tiến độ
- dự án
- dự án
- giao thức
- cung cấp
- mục đích
- đặt
- Python
- chất lượng
- câu hỏi
- Câu hỏi
- Mau
- hơn
- Đọc
- sẵn sàng
- có thật không
- nhận
- gần đây
- gọi
- đề cập
- Bất kể
- đăng ký
- liên quan
- độ tin cậy
- dựa
- nhớ
- tẩy
- lặp đi lặp lại
- thay thế
- báo cáo
- kho
- đại diện
- cần phải
- Yêu cầu
- đòi hỏi
- nghiên cứu
- Thông tin
- phản ứng
- phản ứng
- kết quả
- Kết quả
- trở lại
- Phòng
- chạy
- chạy
- s
- Sự An Toàn
- tương tự
- Lưu
- tiết kiệm
- kịch bản
- Tìm kiếm
- tìm kiếm
- Thứ hai
- Phần
- an toàn
- xem
- cảm biến
- kết án
- Trình tự
- nối tiếp
- thiết lập
- thiết lập
- một số
- bắn
- nên
- thể hiện
- tương tự
- Đơn giản
- đơn giản
- kể từ khi
- duy nhất
- kỹ năng
- nhỏ
- So
- Phần mềm
- giải pháp
- một số
- một cái gì đó
- nguồn
- nguồn
- chuyên nghành
- đặc biệt
- riêng
- quy định
- chia
- Spot
- Bắt đầu
- bắt đầu
- Bắt đầu
- Tuyên bố
- Trạng thái
- Bước
- Các bước
- Vẫn còn
- hàng
- Chuỗi
- cấu trúc
- Sinh viên
- Học tập
- như vậy
- hệ thống
- Hãy
- Thảo luận
- nhiệm vụ
- giáo viên
- Giảng dạy
- thiếu niên
- mẫu
- Thiết bị đầu cuối
- thử nghiệm
- Chạy thử nghiệm
- Kiểm tra
- tạo văn bản
- hơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Đó
- Kia là
- họ
- nghĩ
- điều này
- nghĩ
- Thông qua
- khắp
- thời gian
- đến
- bên nhau
- Tokens
- mai
- quá
- mất
- chủ đề
- Chủ đề
- đối với
- Train
- thử
- hai
- kiểu
- điển hình
- thường
- cập nhật
- Cập nhật
- trên
- us
- Sử dụng
- usb
- sử dụng
- ca sử dụng
- đã sử dụng
- người sử dang
- Người sử dụng
- sử dụng
- thường
- tận dụng
- khác nhau
- xác minh
- phiên bản
- rất
- thông qua
- ảo
- W3
- chờ đợi
- muốn
- là
- Đường..
- cách
- we
- Website
- TỐT
- Điều gì
- Là gì
- Wheel
- khi nào
- cái nào
- CHÚNG TÔI LÀ
- tại sao
- rộng rãi
- sẽ
- cửa sổ
- Người dùng Windows
- với
- ở trong
- không có
- Won
- Công việc
- đang làm việc
- năm
- năm
- bạn
- trẻ
- trên màn hình
- zephyrnet










