Trong bài đăng này, chúng tôi giới thiệu cách tinh chỉnh mô hình Llama 2 bằng phương pháp Tinh chỉnh tham số hiệu quả (PEFT) và triển khai mô hình tinh chỉnh trên Suy luận AWS2. Chúng tôi sử dụng Tế bào thần kinh AWS bộ phát triển phần mềm (SDK) để truy cập thiết bị AWS Inferentia2 và hưởng lợi từ hiệu suất cao của thiết bị này. Sau đó, chúng tôi sử dụng một thùng chứa suy luận mô hình lớn được cung cấp bởi Thư viện Java sâu (DJLServing) làm giải pháp phục vụ kiểu mẫu của chúng tôi.
Tổng quan về giải pháp
Tinh chỉnh hiệu quả Llama2 bằng QLoRa
Nhóm mô hình ngôn ngữ lớn (LLM) Llama 2 là tập hợp các mô hình văn bản tổng quát được đào tạo trước và tinh chỉnh có quy mô từ 7 tỷ đến 70 tỷ tham số. Llama 2 đã được đào tạo trước về 2 nghìn tỷ mã thông báo dữ liệu từ các nguồn có sẵn công khai. Khách hàng AWS đôi khi chọn tinh chỉnh các mô hình Llama 2 bằng cách sử dụng dữ liệu của chính khách hàng để đạt được hiệu suất tốt hơn cho các tác vụ tiếp theo. Tuy nhiên, do số lượng tham số lớn của mô hình Llama 2 nên việc tinh chỉnh hoàn toàn có thể cực kỳ tốn kém và mất thời gian. Phương pháp Tinh chỉnh hiệu quả tham số (PEFT) có thể giải quyết vấn đề này bằng cách chỉ tinh chỉnh một số lượng nhỏ các tham số mô hình bổ sung trong khi đóng băng hầu hết các tham số của mô hình được đào tạo trước. Để biết thêm thông tin về PEFT, người ta có thể đọc phần này gửi. Trong bài đăng này, chúng tôi sử dụng QLoRa để tinh chỉnh mô hình Llama 2 7B.
Triển khai Mô hình tinh chỉnh trên Inf2 bằng Amazon SageMaker
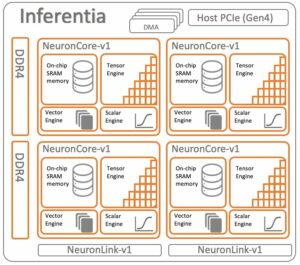
AWS Inferentia2 là công cụ tăng tốc machine learning (ML) được xây dựng có mục đích, được thiết kế cho khối lượng công việc suy luận và mang lại hiệu suất cao với chi phí thấp hơn tới 40% cho khối lượng công việc AI và LLM tổng hợp so với các phiên bản được tối ưu hóa suy luận khác trên AWS. Trong bài đăng này, chúng tôi sử dụng Đám mây điện toán đàn hồi của Amazon (Amazon EC2) Phiên bản Inf2, có AWS Inferentia2, bộ tăng tốc Inferentia2 thế hệ thứ hai, mỗi bộ chứa hai NeuronCores-v2. Mỗi NeuronCore-v2 là một đơn vị tính toán độc lập, không đồng nhất, với bốn công cụ chính: công cụ Tensor, Vector, Scalar và GPSIMD. Nó bao gồm bộ nhớ SRAM được quản lý bằng phần mềm trên chip để tối đa hóa vị trí dữ liệu. Vì một số blog về Inf2 đã được xuất bản nên người đọc có thể tham khảo bài viết này gửi và của chúng tôi tài liệu hướng dẫn để biết thêm thông tin về Inf2.
Để triển khai các mô hình trên Inf2, chúng tôi cần AWS Neuron SDK làm lớp phần mềm chạy trên phần cứng Inf2. AWS Neuron là SDK dùng để chạy khối lượng công việc deep learning trên AWS Inferentia và Đào tạo AWS trường hợp dựa trên. Nó cho phép vòng đời phát triển ML từ đầu đến cuối để xây dựng các mô hình mới, đào tạo và tối ưu hóa các mô hình này cũng như triển khai chúng cho sản xuất. AWS Neuron bao gồm học sâu trình biên dịch, thời gian chạyvà công cụ được tích hợp nguyên bản với các khung phổ biến như TensorFlow và PyTorch. Trong blog này, chúng tôi sẽ sử dụng transformers-neuronx, là một phần của AWS Neuron SDK dành cho quy trình suy luận của bộ giải mã máy biến áp. Nó hỗ trợ một loạt các mô hình phổ biến, bao gồm cả Llama 2.
Để triển khai các mô hình trên Amazon SageMaker, chúng tôi thường sử dụng một vùng chứa các thư viện cần thiết, chẳng hạn như Neuron SDK và transformers-neuronx cũng như thành phần phục vụ mô hình. Amazon SageMaker duy trì thùng chứa học sâu (DLC) với các thư viện mã nguồn mở phổ biến để lưu trữ các mô hình lớn. Trong bài đăng này, chúng tôi sử dụng Bộ chứa suy luận mô hình lớn cho Neuron. Vùng chứa này có mọi thứ bạn cần để triển khai mô hình Llama 2 của mình trên Inf2. Để có tài nguyên bắt đầu với LMI trên Amazon SageMaker, vui lòng tham khảo nhiều bài đăng hiện có của chúng tôi (blog 1, blog 2, blog 3) về chủ đề này. Tóm lại, bạn có thể chạy vùng chứa mà không cần viết thêm bất kỳ mã nào. Bạn có thể dùng trình xử lý mặc định để mang lại trải nghiệm người dùng liền mạch và chuyển vào một trong các tên mô hình được hỗ trợ cũng như mọi tham số có thể định cấu hình thời gian tải. Điều này biên dịch và phân phát LLM trên phiên bản Inf2. Ví dụ, để triển khai OpenAssistant/llama2-13b-orca-8k-3319, bạn có thể cung cấp cấu hình sau (như serving.properties tài liệu). TRONG serving.properties, chúng tôi chỉ định loại mô hình là llama2-13b-orca-8k-3319, kích thước lô là 4, độ song song của tensor là 2, và thế là xong. Để biết danh sách đầy đủ các thông số có thể cấu hình, hãy tham khảo Tất cả các tùy chọn cấu hình DJL.
Ngoài ra, bạn có thể viết tệp xử lý mô hình của riêng mình như trong phần này ví dụ, nhưng điều đó đòi hỏi phải triển khai các phương thức tải mô hình và suy luận để đóng vai trò là cầu nối giữa các API DJLServing.
Điều kiện tiên quyết
Danh sách sau đây nêu các điều kiện tiên quyết để triển khai mô hình được mô tả trong bài đăng trên blog này. Bạn có thể triển khai từ Bảng điều khiển quản lý AWS hoặc sử dụng phiên bản mới nhất của Giao diện dòng lệnh AWS (AWS CLI).
Hương
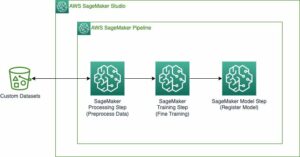
Trong phần sau, chúng tôi sẽ hướng dẫn mã thành hai phần:
- Tinh chỉnh mô hình Llama2-7b và tải các thành phần lạ của mô hình lên vị trí bộ chứa Amazon S3 được chỉ định.
- Triển khai mô hình vào Inferentia2 bằng cách sử dụng vùng chứa phân phối DJL được lưu trữ trong Amazon SageMaker.
Các mẫu mã hoàn chỉnh với hướng dẫn có thể được tìm thấy trong này GitHub kho.
Phần 1: Tinh chỉnh mô hình Llama2-7b bằng PEFT
Chúng tôi sẽ sử dụng phương pháp được giới thiệu gần đây trong bài báo QLoRA: Điều chỉnh bộ điều hợp xếp hạng thấp nhận biết lượng tử hóa để tạo ngôn ngữ bởi Tim Dettmers và cộng sự. QLoRA là một kỹ thuật mới nhằm giảm dung lượng bộ nhớ của các mô hình ngôn ngữ lớn trong quá trình tinh chỉnh mà không làm giảm hiệu suất.
Lưu ý: Việc tinh chỉnh mô hình llama2-7b dưới đây đã được thử nghiệm trên Amazon Sổ tay SageMaker Studio với hạt nhân được tối ưu hóa GPU Python 2.0 bằng cách sử dụng ml.g5.2xlarge loại ví dụ. Cách tốt nhất là chúng tôi khuyên bạn nên sử dụng Xưởng sản xuất Amazon SageMaker Môi trường phát triển tích hợp (IDE) được ra mắt cho riêng bạn Đám mây riêng ảo Amazon (Amazon VPC). Điều này cho phép bạn kiểm soát, giám sát và kiểm tra lưu lượng mạng bên trong và bên ngoài VPC của mình bằng cách sử dụng các khả năng bảo mật và mạng AWS tiêu chuẩn. Để biết thêm thông tin, hãy xem Bảo mật kết nối Amazon SageMaker Studio bằng VPC riêng.
Lượng tử hóa mô hình cơ sở
Trước tiên, chúng tôi tải một mô hình lượng tử hóa với lượng tử hóa 4 bit bằng cách sử dụng Máy biến áp ôm mặt thư viện như sau:
Tải tập dữ liệu đào tạo
Tiếp theo, chúng tôi tải tập dữ liệu để cung cấp cho mô hình cho bước tinh chỉnh như sau:
Đính kèm một lớp bộ điều hợp
Ở đây chúng tôi đính kèm một lớp bộ điều hợp nhỏ, có thể huấn luyện được, được định cấu hình như LoraConfig được định nghĩa trong Ôm Mặt peft thư viện.
Đào tạo một người mẫu
Sử dụng cấu hình LoRA hiển thị ở trên, chúng tôi sẽ tinh chỉnh mô hình Llama2 cùng với các siêu tham số. Đoạn mã để huấn luyện mô hình được hiển thị như sau:
Hợp nhất trọng lượng mô hình
Mô hình tinh chỉnh được thực hiện ở trên đã tạo ra một mô hình mới chứa các trọng số bộ điều hợp LoRA đã được huấn luyện. Trong đoạn mã sau, chúng ta sẽ hợp nhất bộ chuyển đổi với mô hình cơ sở để có thể sử dụng mô hình đã tinh chỉnh cho hoạt động suy luận.
Tải trọng lượng mô hình lên Amazon S3
Ở bước cuối cùng của phần 1, chúng ta sẽ lưu trọng số mô hình đã hợp nhất vào một vị trí Amazon S3 được chỉ định. Trọng lượng mô hình sẽ được vùng chứa phân phát mô hình trong Amazon SageMaker sử dụng để lưu trữ mô hình bằng phiên bản Inferentia2.
Phần 2: Lưu trữ mô hình QLoRA để suy luận với AWS Inf2 bằng SageMaker LMI Container
Trong phần này, chúng ta sẽ hướng dẫn các bước triển khai mô hình tinh chỉnh QLoRA vào môi trường lưu trữ Amazon SageMaker. Chúng tôi sẽ sử dụng một phục vụ DJL vùng chứa từ SageMaker DLC, tích hợp với máy biến áp-neuronx thư viện để lưu trữ mô hình này. Quá trình thiết lập tạo điều kiện thuận lợi cho việc tải mô hình lên bộ tăng tốc AWS Inferentia2, song song hóa mô hình trên nhiều NeuronCore và cho phép phân phát qua điểm cuối HTTP.
Chuẩn bị các tạo phẩm mô hình
DJL hỗ trợ nhiều thư viện tối ưu hóa deep learning, bao gồm Tốc độ sâu, Máy Biến Áp Nhanh Hơn và hơn thế nữa. Đối với cấu hình cụ thể của từng model, chúng tôi cung cấp một serving.properties với các tham số chính, chẳng hạn như tensor_parallel_degree và model_id để xác định các tùy chọn tải mô hình. Các model_id có thể là ID mô hình Khuôn mặt ôm hoặc đường dẫn Amazon S3 nơi lưu trữ trọng số mô hình. Trong ví dụ của chúng tôi, chúng tôi cung cấp vị trí Amazon S3 của mô hình đã tinh chỉnh của chúng tôi. Đoạn mã sau đây hiển thị các thuộc tính được sử dụng để phân phát mô hình:
Hãy tham khảo cái này tài liệu hướng dẫn để biết thêm thông tin về các tùy chọn có thể cấu hình có sẵn thông qua serving.properties. Xin lưu ý rằng chúng tôi sử dụng option.n_position=512 trong blog này để biên dịch AWS Neuron nhanh hơn. Nếu bạn muốn thử độ dài mã thông báo đầu vào lớn hơn thì chúng tôi khuyên người đọc nên biên dịch trước mô hình (xem Mô hình biên dịch trước AOT trên EC2). Nếu không, bạn có thể gặp phải lỗi hết thời gian chờ nếu thời gian biên dịch quá nhiều.
Sau serving.properties tập tin được xác định, chúng tôi sẽ đóng gói tập tin vào một tar.gz dạng, như sau:
Sau đó, chúng tôi sẽ tải tar.gz lên vị trí bộ chứa Amazon S3:
Tạo điểm cuối mô hình Amazon SageMaker
Để sử dụng phiên bản Inf2 để phân phối, chúng tôi sử dụng Amazon Thùng chứa SageMaker LMI với sự hỗ trợ của DJL nơ-ronX. Vui lòng tham khảo điều này gửi để biết thêm thông tin về cách sử dụng bộ chứa DJL NeuronX để suy luận. Đoạn mã sau đây cho biết cách triển khai mô hình bằng SDK Python của Amazon SageMaker:
Điểm cuối của mô hình thử nghiệm
Sau khi mô hình được triển khai thành công, chúng tôi có thể xác thực điểm cuối bằng cách gửi yêu cầu mẫu tới bộ dự đoán:
Đầu ra mẫu được hiển thị như sau:
Trong bối cảnh phân tích dữ liệu, Machine Learning (ML) đề cập đến một kỹ thuật thống kê có khả năng trích xuất sức mạnh dự đoán từ tập dữ liệu với độ phức tạp và độ chính xác ngày càng tăng bằng cách thu hẹp phạm vi thống kê nhiều lần.
Machine Learning không phải là một kỹ thuật thống kê mới mà là sự kết hợp của các kỹ thuật hiện có. Hơn nữa, nó chưa được thiết kế để sử dụng với một tập dữ liệu cụ thể hoặc để tạo ra một kết quả cụ thể. Đúng hơn, nó được thiết kế đủ linh hoạt để thích ứng với bất kỳ tập dữ liệu nào và đưa ra dự đoán về bất kỳ kết quả nào.
Làm sạch
Nếu bạn quyết định không muốn tiếp tục chạy điểm cuối SageMaker nữa, bạn có thể xóa nó bằng cách sử dụng AWS SDK dành cho Python (boto3), AWS CLI hoặc Amazon SageMaker Console. Ngoài ra, bạn cũng có thể tắt Tài nguyên Amazon SageMaker Studio điều đó không còn cần thiết nữa.
Kết luận
Trong bài đăng này, chúng tôi đã hướng dẫn bạn cách tinh chỉnh mô hình Llama2-7b bằng bộ điều hợp LoRA với lượng tử hóa 4 bit bằng một phiên bản GPU duy nhất. Sau đó, chúng tôi đã triển khai mô hình này cho phiên bản Inf2 được lưu trữ trong Amazon SageMaker bằng cách sử dụng vùng chứa phân phối DJL. Cuối cùng, chúng tôi đã xác thực điểm cuối của mô hình Amazon SageMaker bằng dự đoán tạo văn bản bằng SDK SageMaker Python. Hãy tiếp tục và dùng thử, chúng tôi rất mong nhận được phản hồi của bạn. Hãy theo dõi thông tin cập nhật về nhiều khả năng hơn và những cải tiến mới với AWS Inferentia.
Để biết thêm ví dụ về AWS Neuron, hãy xem mẫu aws-neuron.
Về các tác giả
 Ngụy Tế là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao tại AWS. Anh ấy đam mê giúp đỡ khách hàng nâng cao hành trình AWS của họ, tập trung vào các dịch vụ Amazon Machine Learning và các giải pháp dựa trên machine learning. Ngoài công việc, anh thích các hoạt động ngoài trời như cắm trại, câu cá và đi bộ đường dài cùng gia đình.
Ngụy Tế là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao tại AWS. Anh ấy đam mê giúp đỡ khách hàng nâng cao hành trình AWS của họ, tập trung vào các dịch vụ Amazon Machine Learning và các giải pháp dựa trên machine learning. Ngoài công việc, anh thích các hoạt động ngoài trời như cắm trại, câu cá và đi bộ đường dài cùng gia đình.
 Qingwetôi lý là Chuyên gia Máy học tại Amazon Web Services. Ông nhận bằng Tiến sĩ. trong Nghiên cứu Hoạt động sau khi ông phá vỡ tài khoản tài trợ nghiên cứu của cố vấn và không thực hiện được giải Nobel mà ông đã hứa. Hiện anh đang giúp khách hàng trong ngành dịch vụ tài chính và bảo hiểm xây dựng các giải pháp máy học trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách và dạy học.
Qingwetôi lý là Chuyên gia Máy học tại Amazon Web Services. Ông nhận bằng Tiến sĩ. trong Nghiên cứu Hoạt động sau khi ông phá vỡ tài khoản tài trợ nghiên cứu của cố vấn và không thực hiện được giải Nobel mà ông đã hứa. Hiện anh đang giúp khách hàng trong ngành dịch vụ tài chính và bảo hiểm xây dựng các giải pháp máy học trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách và dạy học.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/fine-tune-llama-2-using-qlora-and-deploy-it-on-amazon-sagemaker-with-aws-inferentia2/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 1
- 10
- 100
- 11
- 15%
- 16
- 19
- 24
- 300
- 7
- 70
- 8
- a
- Giới thiệu
- ở trên
- gia tốc
- máy gia tốc
- truy cập
- Tài khoản
- chính xác
- Đạt được
- ngang qua
- hoạt động
- thích ứng
- thêm vào
- Ngoài ra
- địa chỉ
- tiến
- Sau
- trước
- AI
- AI / ML
- AL
- cho phép
- dọc theo
- Alpha
- Ngoài ra
- đàn bà gan dạ
- Học máy Amazon
- Amazon SageMaker
- Xưởng sản xuất Amazon SageMaker
- Amazon Web Services
- an
- phân tích
- và
- bất kì
- API
- Đăng Nhập
- phương pháp tiếp cận
- LÀ
- AS
- At
- đính kèm
- tự động
- có sẵn
- AWS
- Suy luận AWS
- banh
- cơ sở
- dựa
- trạm trộn
- BE
- được
- hưởng lợi
- BEST
- Hơn
- giữa
- Tỷ
- Blog
- blog
- CẦU
- Broke
- xây dựng
- nhưng
- by
- cắm trại
- CAN
- khả năng
- có khả năng
- Chọn
- đám mây
- mã
- bộ sưu tập
- kết hợp
- hoàn thành
- phức tạp
- thành phần
- Tính
- Cấu hình
- cấu hình
- Kết nối
- An ủi
- Container
- chứa
- bối cảnh
- điều khiển
- Phí Tổn
- có thể
- tạo ra
- Hiện nay
- khách hàng
- dữ liệu
- phân tích dữ liệu
- quyết định
- sâu
- học kĩ càng
- Mặc định
- định nghĩa
- xác định
- Bằng cấp
- cung cấp
- cung cấp
- triển khai
- triển khai
- triển khai
- mô tả
- thiết kế
- Phát triển
- thiết bị
- phu bến tàu
- xuống
- hai
- suốt trong
- năng động
- E&T
- mỗi
- hay
- cho phép
- Cuối cùng đến cuối
- Điểm cuối
- thiết bị đầu cuối
- Động cơ
- Động cơ
- đủ
- Môi trường
- lôi
- vv
- Ether (ETH)
- tất cả mọi thứ
- ví dụ
- ví dụ
- Thực thi
- hiện tại
- đắt tiền
- kinh nghiệm
- thêm
- Đối mặt
- tạo điều kiện
- thất bại
- sai
- gia đình
- nhanh hơn
- Với
- thông tin phản hồi
- Tập tin
- cuối cùng
- Cuối cùng
- tài chính
- dịch vụ tài chính
- Tên
- Đánh bắt cá
- linh hoạt
- tập trung
- theo
- sau
- tiếp theo
- sau
- Dấu chân
- Trong
- định dạng
- tìm thấy
- 4
- khung
- Freezing
- từ
- Full
- Hơn nữa
- thế hệ
- thế hệ
- Trí tuệ nhân tạo
- được
- Cho
- Go
- đi
- GPU
- cấp
- phần cứng
- he
- Nghe
- giúp đỡ
- giúp
- tại đây
- Cao
- hiệu suất cao
- đi bộ đường dài
- của mình
- chủ nhà
- tổ chức
- lưu trữ
- House
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- ID
- if
- hình ảnh
- thực hiện
- thực hiện
- in
- bao gồm
- bao gồm
- Bao gồm
- tăng
- độc lập
- ngành công nghiệp
- thông tin
- đổi mới
- đầu vào
- đầu vào
- ví dụ
- trường hợp
- hướng dẫn
- bảo hiểm
- ngành bảo hiểm
- tích hợp
- Tích hợp
- trong
- giới thiệu
- IT
- sự lặp lại
- ITS
- Java
- cuộc hành trình
- jpg
- json
- Giữ
- Key
- bộ dụng cụ
- Bộ công cụ (SDK)
- Ngôn ngữ
- lớn
- lớn hơn
- mới nhất
- phát động
- lớp
- lớp
- học tập
- Chiều dài
- Cấp
- thư viện
- Thư viện
- vòng đời
- Lượt thích
- Lượt thích
- Dòng
- Danh sách
- Loài đà mã ở nam mỹ
- tải
- tải
- địa điểm thư viện nào
- còn
- yêu
- thấp hơn
- máy
- học máy
- Chủ yếu
- duy trì
- làm cho
- quản lý
- nhiều
- tối đa hóa
- Bộ nhớ
- đi
- phương pháp
- phương pháp
- Might
- ML
- kiểu mẫu
- mô hình
- Modules
- Màn Hình
- chi tiết
- hầu hết
- nhiều
- nhiều
- tên
- nas
- Cần
- mạng
- lưu lượng mạng
- mạng lưới
- Mới
- Không
- giải thưởng Nobel
- Không áp dụng
- ghi
- con số
- of
- on
- ONE
- có thể
- mở
- mã nguồn mở
- Hoạt động
- tối ưu hóa
- Tối ưu hóa
- tối ưu hóa
- Tùy chọn
- Các lựa chọn
- or
- Nền tảng khác
- nếu không thì
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- Kết quả
- Ngoài trời
- đề cương
- đầu ra
- bên ngoài
- kết thúc
- riêng
- gói
- Giấy
- Song song
- tham số
- thông số
- một phần
- các bộ phận
- vượt qua
- đam mê
- con đường
- hiệu suất
- thực hiện
- kế hoạch
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- xin vui lòng
- Phổ biến
- Bài đăng
- bài viết
- quyền lực
- -
- thực hành
- Độ chính xác
- dự đoán
- Dự đoán
- dự đoán
- Predictor
- điều kiện tiên quyết
- riêng
- giải thưởng
- xác suất
- Vấn đề
- quá trình
- sản xuất
- Sản lượng
- hứa
- tài sản
- cho
- công khai
- công bố
- Python
- ngọn đuốc
- phạm vi
- khác nhau,
- hơn
- Đọc
- Người đọc
- Reading
- nhận
- gần đây
- giới thiệu
- giảm
- xem
- đề cập
- kho
- yêu cầu
- yêu cầu
- cần phải
- đòi hỏi
- nghiên cứu
- Thông tin
- phản ứng
- phản ứng
- ngay
- chạy
- chạy
- hy sinh
- nhà làm hiền triết
- Lưu
- Quy mô
- mở rộng quy mô
- phạm vi
- sdk
- liền mạch
- Thứ hai
- Thế hệ thứ hai
- Phần
- an ninh
- xem
- gửi
- cao cấp
- Trình tự
- phục vụ
- dịch vụ
- DỊCH VỤ
- phục vụ
- định
- thiết lập
- thiết lập
- một số
- ngắn
- giới thiệu
- cho thấy
- thể hiện
- Chương trình
- kể từ khi
- duy nhất
- Kích thước máy
- nhỏ
- đoạn
- So
- Phần mềm
- phát triển phần mềm
- bộ phát triển phần mềm
- giải pháp
- Giải pháp
- đôi khi
- nguồn
- nguồn
- chuyên gia
- riêng
- quy định
- Tiêu chuẩn
- bắt đầu
- thống kê
- ở lại
- Bước
- Các bước
- lưu trữ
- phòng thu
- Thành công
- như vậy
- hỗ trợ
- Hỗ trợ
- Hỗ trợ
- nhiệm vụ
- Giảng dạy
- kỹ thuật
- kỹ thuật
- tensorflow
- thử nghiệm
- văn bản
- tạo văn bản
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Kia là
- điều này
- Thông qua
- Tim
- thời gian
- đến
- mã thông báo
- Tokens
- quá
- hàng đầu
- chủ đề
- ngọn đuốc
- giao thông
- Train
- đào tạo
- Hội thảo
- biến áp
- Nghìn tỷ
- đúng
- thử
- hai
- kiểu
- Cập nhật
- tải lên
- URI
- URL
- sử dụng
- đã sử dụng
- người sử dang
- Kinh nghiệm người dùng
- sử dụng
- thường
- HIỆU LỰC
- xác nhận
- phiên bản
- thông qua
- ảo
- đi bộ
- hương
- muốn
- là
- we
- web
- các dịch vụ web
- trọng lượng
- TỐT
- Điều gì
- Là gì
- cái nào
- trong khi
- sẽ
- với
- ở trong
- không có
- Công việc
- công nhân
- Luồng công việc
- viết
- viết
- bạn
- trên màn hình
- zephyrnet