Trong thế giới ngày nay, khách hàng quản lý lượng dữ liệu khổng lồ trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), hồ dữ liệu, yêu cầu các đường ống dữ liệu phức tạp để liên tục hiểu các thay đổi trong bố cục dữ liệu và cung cấp chúng cho các hệ thống sử dụng. Keo AWS trình thu thập thông tin cung cấp một cách đơn giản để lập danh mục dữ liệu trong Danh mục dữ liệu AWS Glue giúp loại bỏ công việc nặng nhọc khi quản lý lược đồ và phân loại dữ liệu. Trình thu thập thông tin AWS Glue trích xuất lược đồ dữ liệu và phân vùng từ Amazon S3 để tự động điền vào Danh mục dữ liệu, giữ cho siêu dữ liệu luôn cập nhật.
Nhưng với dữ liệu tăng theo cấp số nhân theo thời gian, số lượng phân vùng trong một bảng nhất định có thể tăng lên đáng kể. Bởi vì các dịch vụ phân tích như amazon Athena truy vấn một bảng chứa hàng triệu phân vùng, thời gian cần thiết để truy xuất phân vùng sẽ tăng lên và có thể khiến thời gian chạy truy vấn tăng lên.
Hôm nay, hỗ trợ trình thu thập thông tin AWS Glue đã được mở rộng để tự động thêm chỉ mục phân vùng cho các bảng mới được phát hiện nhằm tối ưu hóa quá trình xử lý truy vấn trên tập dữ liệu được phân vùng. Bây giờ, khi trình thu thập thông tin tạo một bảng Danh mục dữ liệu mới trong quá trình chạy trình thu thập thông tin, nó cũng tạo một chỉ mục phân vùng theo mặc định, với hoán vị lớn nhất trong tất cả các cột phân vùng kiểu số và chuỗi làm khóa. Sau đó, Danh mục dữ liệu sẽ tạo một chỉ mục có thể tìm kiếm dựa trên các khóa này, giúp giảm thời gian cần thiết để truy xuất và lọc siêu dữ liệu phân vùng trên các bảng có hàng triệu phân vùng. Việc tạo các chỉ mục phân vùng có lợi cho khối lượng công việc phân tích chạy trên Athena, Amazon EMR, Quang phổ dịch chuyển đỏ Amazonvà Keo AWS.
Trong bài đăng này, chúng tôi mô tả cách tạo chỉ mục phân vùng bằng trình thu thập thông tin AWS Glue và so sánh mức cải thiện hiệu suất truy vấn khi truy cập dữ liệu được thu thập thông tin có và không có chỉ mục phân vùng từ Athena.
Tổng quan về giải pháp
Chúng tôi sử dụng một Hình thành đám mây AWS mẫu để tạo tài nguyên giải pháp của chúng tôi. Trong các bước sau, chúng tôi trình bày cách định cấu hình trình thu thập dữ liệu AWS Glue để tạo chỉ mục phân vùng bằng bảng điều khiển AWS Glue hoặc bảng điều khiển AWS Glue. Giao diện dòng lệnh AWS (AWS CLI). Sau đó, chúng tôi so sánh các cải tiến về hiệu suất truy vấn bằng Athena.
Điều kiện tiên quyết
Để theo dõi bài đăng này, bạn phải có quyền truy cập vào một Quản lý truy cập và nhận dạng AWS (IAM) vai trò quản trị viên để tạo tài nguyên bằng AWS CloudFormation.
Thiết lập tài nguyên giải pháp của bạn
Mẫu CloudFormation tạo các tài nguyên sau:
- Vai trò và chính sách của IAM
- Cơ sở dữ liệu AWS Glue để giữ lược đồ
- Trình thu thập dữ liệu AWS Glue trỏ đến tập dữ liệu được phân vùng cao
- Nhóm làm việc Athena và bộ chứa để lưu trữ kết quả truy vấn
Hoàn thành các bước sau để thiết lập tài nguyên giải pháp:
- Đăng nhập vào Bảng điều khiển quản lý AWS với tư cách là quản trị viên IAM.
- Chọn Khởi chạy Stack để triển khai mẫu CloudFormation:

- Trong Tên cơ sở dữ liệu, giữ nguyên giá trị mặc định
blog_partition_index_crawlerdb.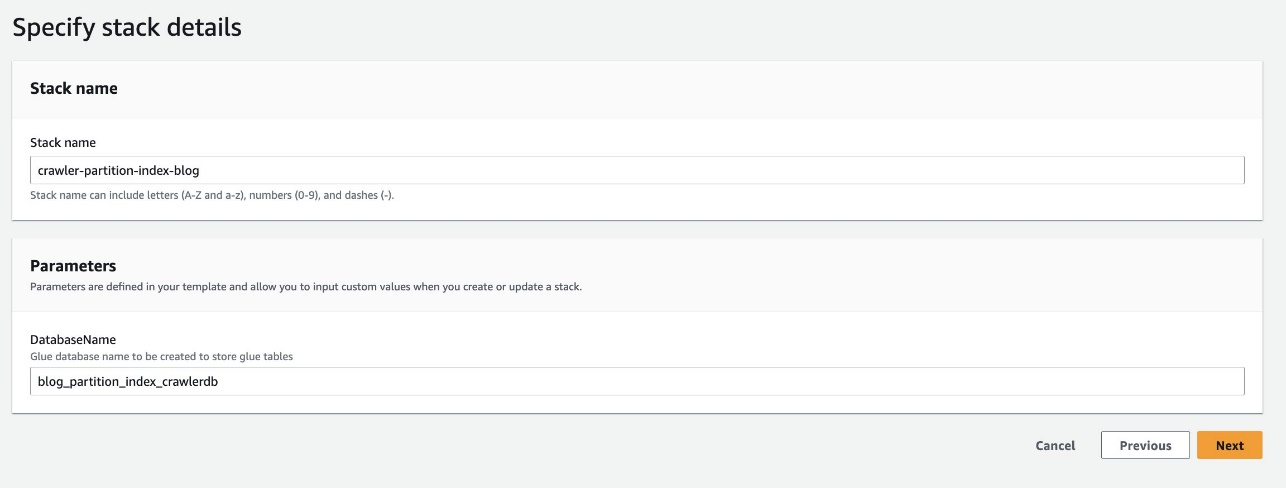
- Chọn Sau.
- Xem lại chi tiết trên trang cuối cùng và chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM.
- Chọn Tạo ngăn xếp.
- Khi ngăn xếp hoàn tất, trên bảng điều khiển AWS CloudFormation, hãy điều hướng đến Kết quả đầu ra tab của ngăn xếp.
- Ghi lại các giá trị của
DatabaseNamevàGlueCrawlerName.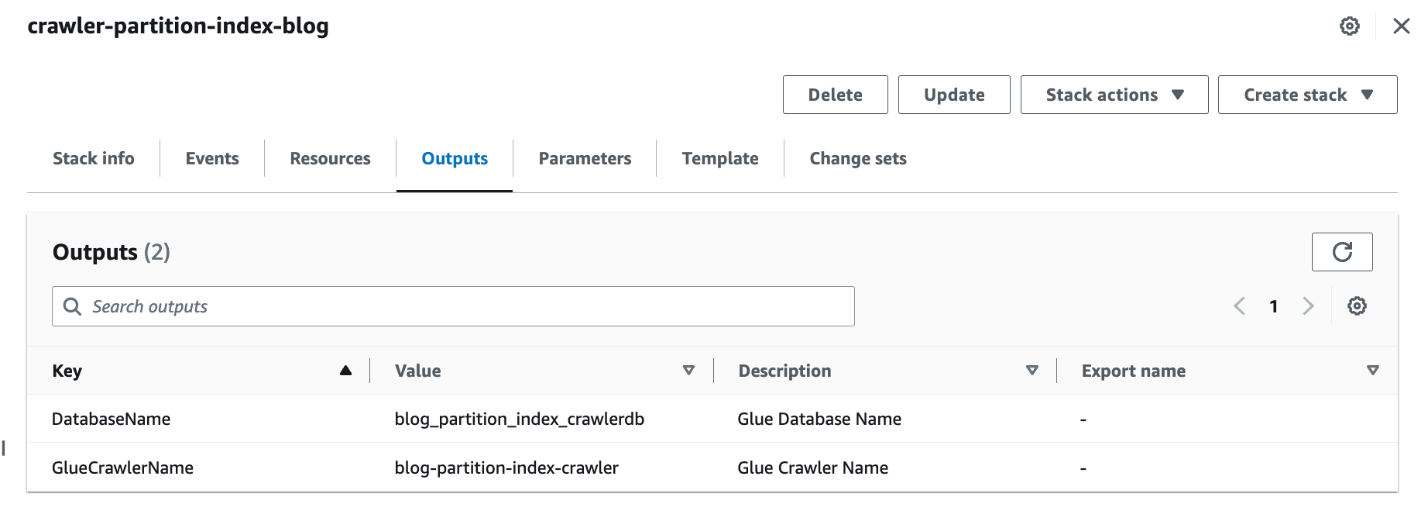
Một số tài nguyên mà ngăn xếp này triển khai phát sinh chi phí khi sử dụng.
Chỉnh sửa và chạy trình thu thập thông tin AWS Glue
Để định cấu hình và chạy trình thu thập dữ liệu AWS Glue, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
- Định vị
crawler blog-partition-index-crawlerVà chọn Chỉnh sửa.
- Trong tạp chí Đặt đầu ra và lập lịch phần, dưới Tùy chọn cấp cao, lựa chọn Tạo chỉ mục phân vùng tự động.
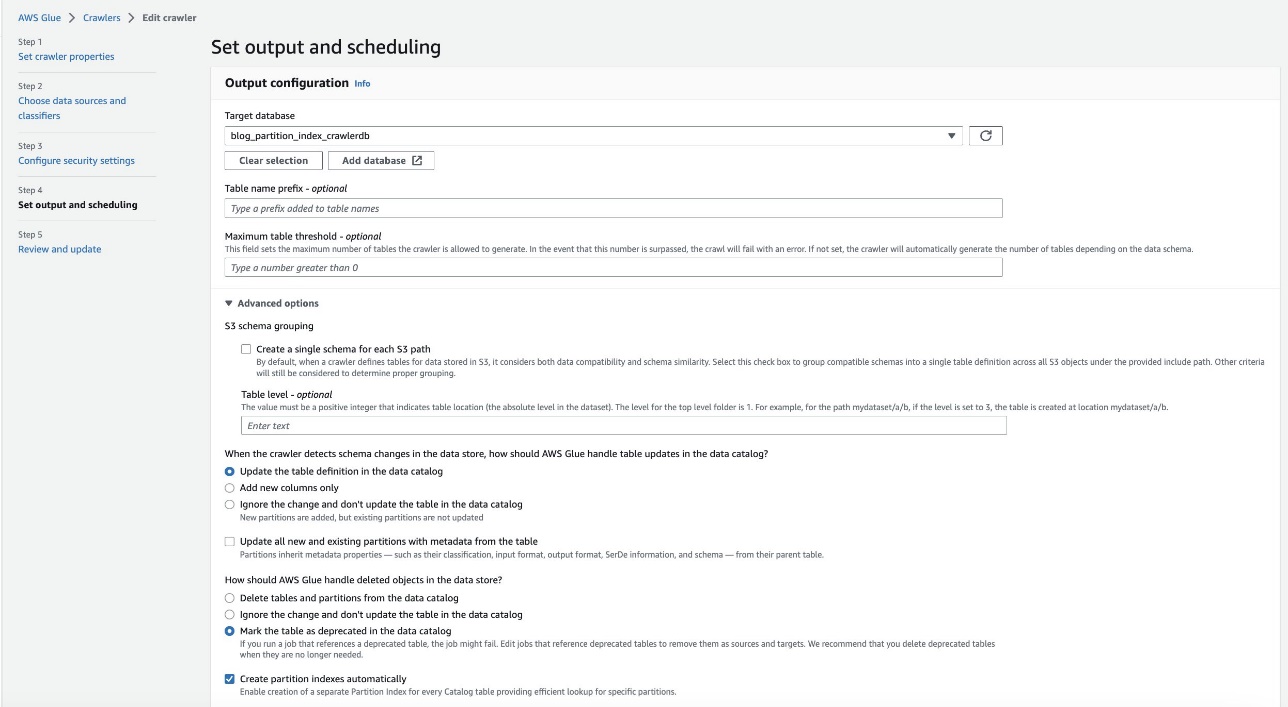
- Xem lại và cập nhật cài đặt trình thu thập thông tin.
Ngoài ra, bạn có thể định cấu hình trình thu thập thông tin của mình bằng AWS CLI (cung cấp Khu vực và vai trò IAM của bạn):
- Bây giờ hãy chạy trình thu thập thông tin và xác minh rằng quá trình chạy trình thu thập thông tin đã hoàn tất.
Đây là tập dữ liệu được phân vùng cao và sẽ mất khoảng 90 phút để hoàn thành.
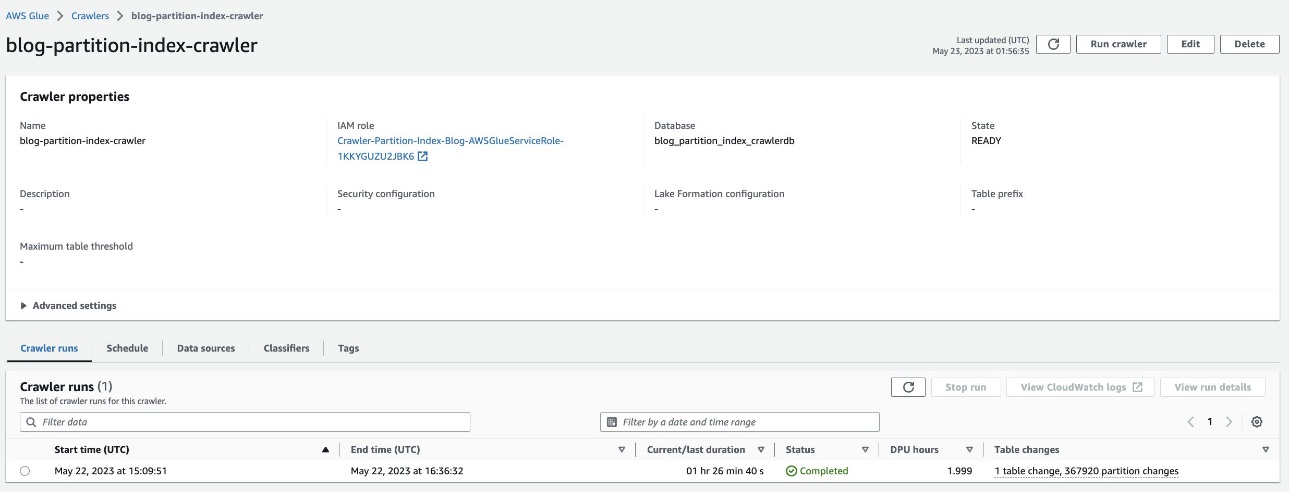
Xác minh bảng được phân vùng
Trong cơ sở dữ liệu AWS Glue blog_partition_index_crawlerdb, xác minh rằng bảng highly_partitioned_table được tạo ra.
Theo mặc định, trình thu thập thông tin xác định một chỉ mục dựa trên hoán vị lớn nhất của các cột phân vùng của các loại cột hợp lệ theo cùng thứ tự của các cột phân vùng, là số hoặc chuỗi. Đối với bảng được tạo bởi trình thu thập thông tin (highly_partitioned_table), chúng tôi có các cột phân vùng year (chuỗi), month (chuỗi), day (chuỗi) và hour (dây).
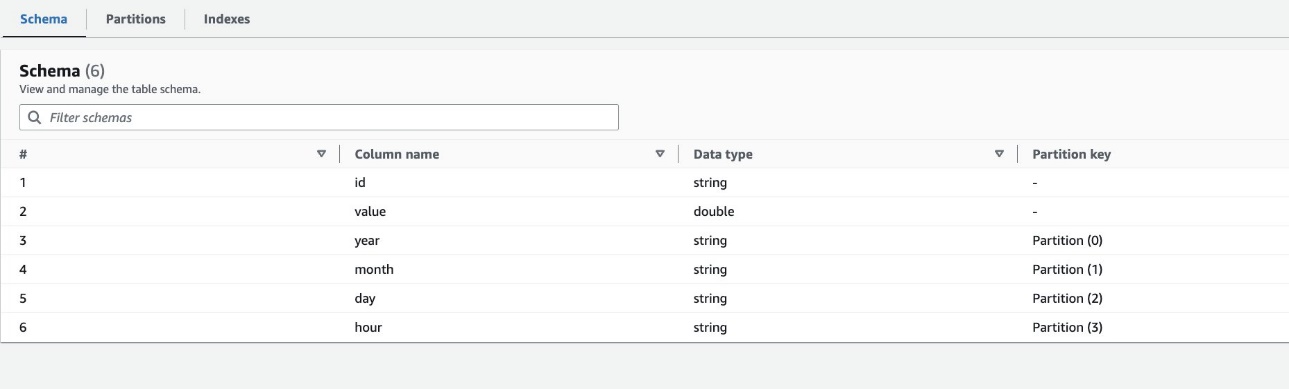
Dựa trên định nghĩa này, trình thu thập thông tin đã tạo một chỉ mục trên hoán vị của năm, tháng, ngày và giờ. Trình thu thập thông tin đã tạo các chỉ mục có tiền tố là crawler_ trên bất kỳ chỉ mục phân vùng nào được tạo theo mặc định.
Xác minh tương tự bằng cách điều hướng đến bảng highly_partitioned_table trên bảng điều khiển AWS Glue và chọn Chỉ số tab.
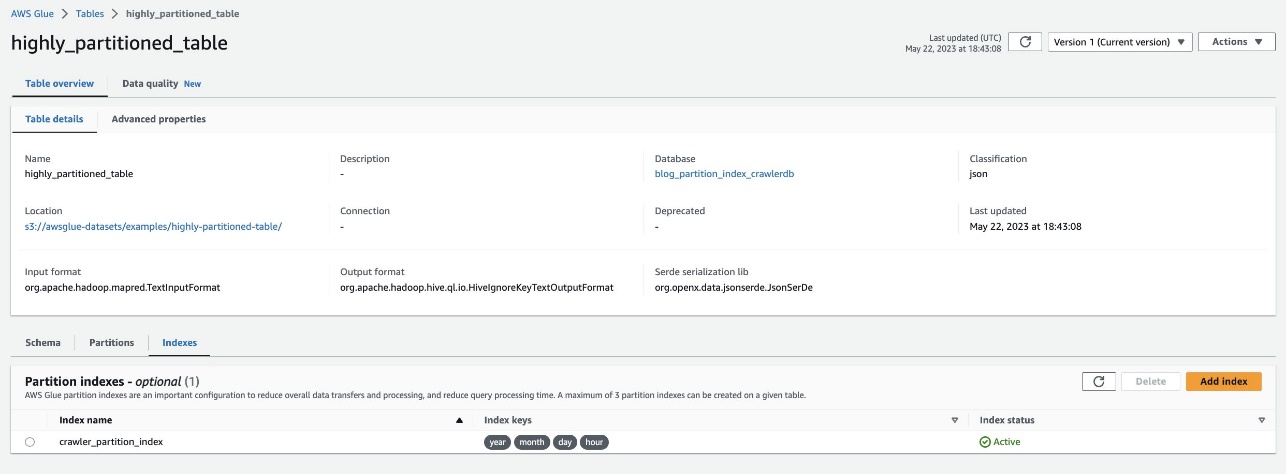
Trình thu thập thông tin có thể thu thập dữ liệu nguồn dữ liệu S3 và điền thành công các chỉ mục phân vùng cho bảng.
So sánh các cải tiến hiệu suất truy vấn bằng Athena
Đầu tiên, chúng tôi truy vấn bảng trong Athena mà không sử dụng chỉ mục phân vùng. Để xác minh các bảng bằng Athena, hãy hoàn thành các bước sau:
- Trên bảng điều khiển Athena, chọn
crawler-primary-workgroupvới tư cách là nhóm làm việc Athena và chọn Công nhận.
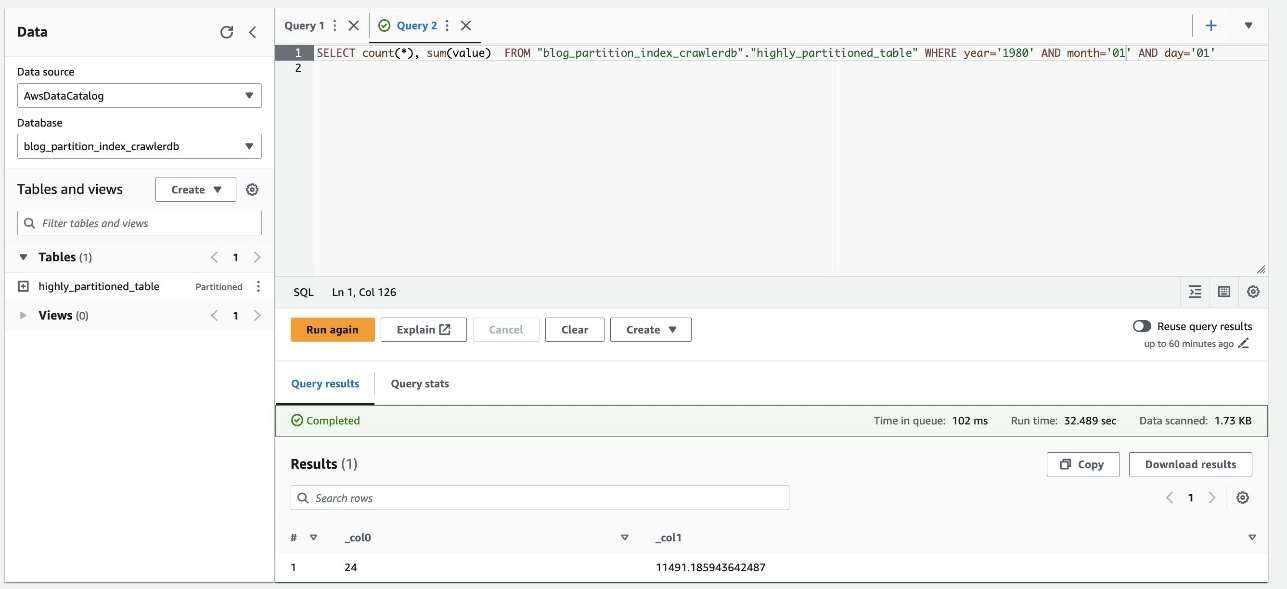
- Chạy truy vấn sau:
Ảnh chụp màn hình sau đây cho thấy truy vấn mất khoảng 32 giây mà không bật tính năng lọc bằng chỉ mục phân vùng.
- Bây giờ chúng tôi kích hoạt chỉ mục phân vùng trên truy vấn Athena:
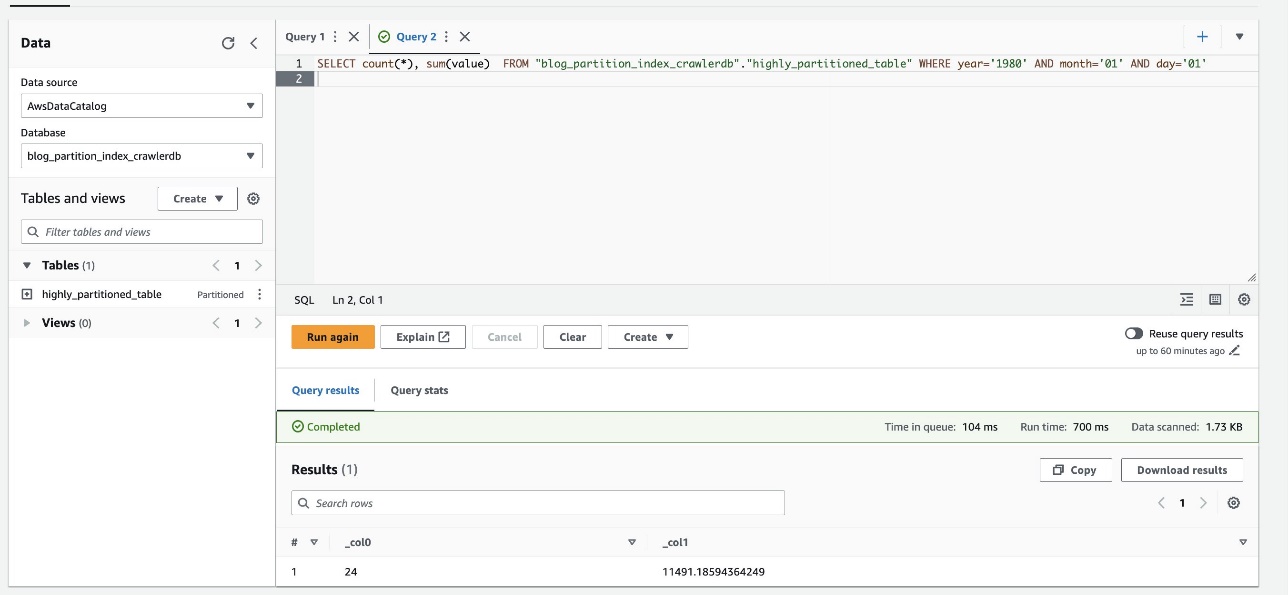
- Chạy lại truy vấn sau và lưu ý thời gian chạy:
Ảnh chụp màn hình sau đây cho thấy truy vấn chỉ mất 700 mili giây, nhanh hơn nhiều với tính năng lọc được bật bằng chỉ mục phân vùng.
Làm sạch
Để tránh các khoản phí không mong muốn đối với tài khoản AWS của mình, bạn có thể xóa tài nguyên AWS:
- Đăng nhập vào bảng điều khiển CloudFormation với tư cách là quản trị viên IAM được sử dụng để tạo ngăn xếp CloudFormation.
- Xóa ngăn xếp CloudFormation mà bạn đã tạo.
Kết luận
Trong bài đăng này, chúng tôi đã giải thích cách định cấu hình trình thu thập dữ liệu AWS để tạo chỉ mục phân vùng và so sánh hiệu suất truy vấn khi truy cập dữ liệu bằng chỉ mục từ Athena.
Nếu không có chỉ mục phân vùng nào trên bảng, AWS Glue sẽ tải tất cả các phân vùng của bảng, sau đó lọc các phân vùng đã tải, dẫn đến việc truy xuất siêu dữ liệu không hiệu quả. Các dịch vụ phân tích như Redshift Spectrum, Amazon EMR và AWS Glue ETL Spark DataFrames hiện có thể sử dụng các chỉ mục để tìm nạp phân vùng, dẫn đến hiệu suất truy vấn đáng kể.
Để biết thêm thông tin về chỉ mục phân vùng và hiệu suất truy vấn trên các công cụ phân tích khác nhau, hãy tham khảo Cải thiện hiệu suất truy vấn Amazon Athena bằng cách sử dụng chỉ mục phân vùng AWS Glue Data Catalog và Cải thiện hiệu suất truy vấn bằng cách sử dụng chỉ mục phân vùng AWS Glue.
Đặc biệt cảm ơn tất cả những người đã đóng góp cho việc ra mắt tính năng trình thu thập thông tin này: Yuhang Chen, Kyle Duong và Mita Gavade.
Giới thiệu về tác giả
 Srividya Parthasarathy là Kiến trúc sư dữ liệu lớn cấp cao trong nhóm AWS Lake Formation. Cô thích xây dựng các giải pháp lưới dữ liệu và chia sẻ chúng với cộng đồng.
Srividya Parthasarathy là Kiến trúc sư dữ liệu lớn cấp cao trong nhóm AWS Lake Formation. Cô thích xây dựng các giải pháp lưới dữ liệu và chia sẻ chúng với cộng đồng.
 Sandeep Adwankar là Giám đốc Sản phẩm Kỹ thuật Cấp cao tại AWS. Có trụ sở tại Khu vực Vịnh California, ông làm việc với khách hàng trên toàn cầu để chuyển các yêu cầu kinh doanh và kỹ thuật thành các sản phẩm cho phép khách hàng cải thiện cách họ quản lý, bảo mật và truy cập dữ liệu.
Sandeep Adwankar là Giám đốc Sản phẩm Kỹ thuật Cấp cao tại AWS. Có trụ sở tại Khu vực Vịnh California, ông làm việc với khách hàng trên toàn cầu để chuyển các yêu cầu kinh doanh và kỹ thuật thành các sản phẩm cho phép khách hàng cải thiện cách họ quản lý, bảo mật và truy cập dữ liệu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- EVM tài chính. Giao diện hợp nhất cho tài chính phi tập trung. Truy cập Tại đây.
- Tập đoàn truyền thông lượng tử. Khuếch đại IR/PR. Truy cập Tại đây.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : có
- :là
- :Ở đâu
- $ LÊN
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Có khả năng
- truy cập
- truy cập
- Tài khoản
- công nhận
- ngang qua
- thêm vào
- quản trị viên
- một lần nữa
- Tất cả
- dọc theo
- Ngoài ra
- đàn bà gan dạ
- amazon Athena
- Amazon EMR
- Amazon Web Services
- số lượng
- an
- Phân tích
- phân tích
- và
- bất kì
- khoảng
- LÀ
- KHU VỰC
- xung quanh
- AS
- At
- tự động
- có sẵn
- tránh
- AWS
- Hình thành đám mây AWS
- Keo AWS
- Sự hình thành hồ AWS
- dựa
- vịnh
- bởi vì
- được
- Lợi ích
- lớn
- Dữ Liệu Lớn.
- Xây dựng
- kinh doanh
- by
- california
- CAN
- Danh mục hàng
- Nguyên nhân
- Những thay đổi
- tải
- chen
- Chọn
- lựa chọn
- phân loại
- Cột
- Cột
- đến
- cộng đồng
- so sánh
- so
- hoàn thành
- An ủi
- liên tục
- đóng góp
- Chi phí
- thu thập thông tin
- tạo
- tạo ra
- tạo ra
- Tạo
- tạo
- Current
- khách hàng
- dữ liệu
- truy cập dữ liệu
- Hồ dữ liệu
- Cơ sở dữ liệu
- ngày
- Mặc định
- chứng minh
- triển khai
- triển khai
- mô tả
- chi tiết
- xác định
- phát hiện
- xuống
- suốt trong
- hiệu quả
- hay
- cho phép
- kích hoạt
- Động cơ
- Ether (ETH)
- mọi người
- mở rộng
- Giải thích
- theo hàm mũ
- trích xuất
- trích xuất dữ liệu
- nhanh hơn
- Đặc tính
- lọc
- lọc
- bộ lọc
- cuối cùng
- theo
- tiếp theo
- Trong
- hình thành
- từ
- tạo
- được
- toàn cầu
- Phát triển
- Phát triển
- Có
- he
- nặng
- nâng nặng
- cao
- tổ chức
- giờ
- Độ đáng tin của
- Hướng dẫn
- HTML
- http
- HTTPS
- IAM
- Bản sắc
- nâng cao
- cải thiện
- cải tiến
- in
- Tăng lên
- Tăng
- chỉ số
- chỉ số
- không hiệu quả
- thông tin
- trong
- IT
- jpg
- Giữ
- giữ
- phím
- hồ
- lớn nhất
- phóng
- Bố trí
- nâng
- Lượt thích
- Dòng
- tải
- làm cho
- quản lý
- quản lý
- giám đốc
- mắt lưới
- Siêu dữ liệu
- Might
- hàng triệu
- phút
- tháng
- chi tiết
- nhiều
- phải
- Điều hướng
- điều hướng
- THÔNG TIN
- cần thiết
- Mới
- mới
- Không
- tại
- con số
- of
- on
- có thể
- Tối ưu hóa
- or
- gọi món
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- đầu ra
- kết thúc
- trang
- cửa sổ
- con đường
- hiệu suất
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Bài đăng
- trình bày
- xử lý
- Sản phẩm
- giám đốc sản xuất
- Sản phẩm
- cho
- giảm
- khu
- cần phải
- Yêu cầu
- đòi hỏi
- Thông tin
- kết quả
- Kết quả
- Vai trò
- vai trò
- chạy
- chạy
- tương tự
- giây
- Phần
- an toàn
- cao cấp
- DỊCH VỤ
- định
- thiết lập
- chia sẻ
- chị ấy
- Chương trình
- có ý nghĩa
- đáng kể
- Đơn giản
- giải pháp
- Giải pháp
- nguồn
- Spark
- quang phổ
- ngăn xếp
- Các bước
- là gắn
- hàng
- đơn giản
- Chuỗi
- Thành công
- hỗ trợ
- hệ thống
- bàn
- Hãy
- nhóm
- Kỹ thuật
- mẫu
- cảm ơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- Kia là
- họ
- điều này
- thời gian
- đến
- hôm nay
- mất
- dịch
- đúng
- kiểu
- loại
- Dưới
- hiểu
- không mong muốn
- Cập nhật
- sử dụng
- đã sử dụng
- sử dụng
- sử dụng
- giá trị
- Các giá trị
- khác nhau
- Lớn
- xác minh
- phiên bản
- là
- Đường..
- we
- web
- các dịch vụ web
- khi nào
- cái nào
- CHÚNG TÔI LÀ
- sẽ
- với
- không có
- Nhóm làm việc
- công trinh
- thế giới
- khoai mỡ
- năm
- bạn
- trên màn hình
- zephyrnet