
Hình ảnh từ tác giả | Trình tạo hình ảnh Bing
Dolly 2.0 là một mô hình ngôn ngữ lớn (LLM) mã nguồn mở, tuân theo hướng dẫn, được tinh chỉnh trên tập dữ liệu do con người tạo ra. Nó có thể được sử dụng cho cả mục đích nghiên cứu và thương mại.
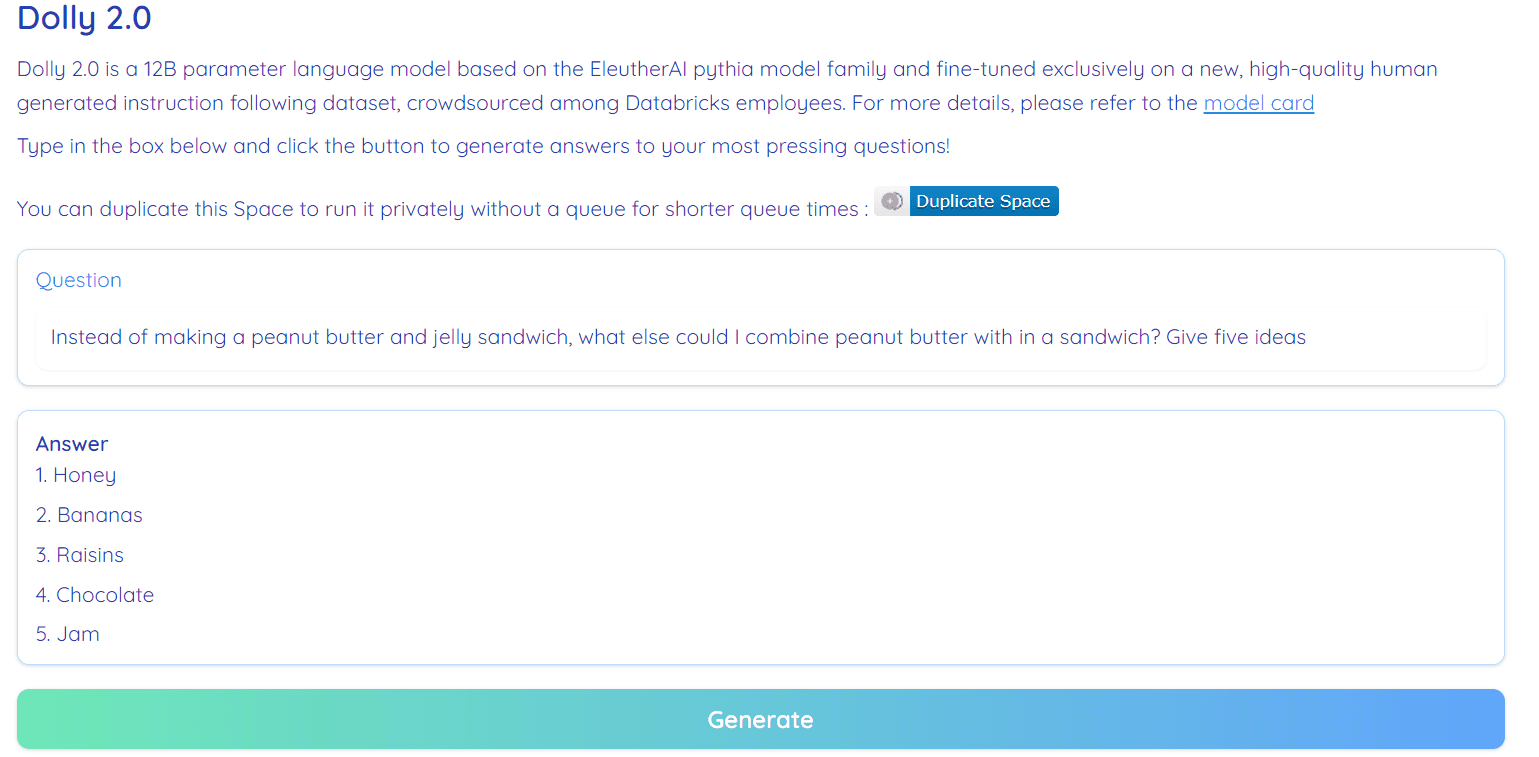
Hình ảnh từ Ôm không gian khuôn mặt của RamAnanth1
Trước đây, nhóm Databricks đã phát hành Dolly 1.0, LLM, thể hiện khả năng làm theo hướng dẫn giống như ChatGPT và chi phí đào tạo chưa đến 30 USD. Nó đang sử dụng tập dữ liệu của nhóm Stanford Alpaca, theo giấy phép hạn chế (Chỉ nghiên cứu).
Dolly 2.0 đã giải quyết vấn đề này bằng cách tinh chỉnh mô hình ngôn ngữ tham số 12B (Pythia) trên hướng dẫn chất lượng cao do con người tạo ra trong tập dữ liệu sau, được gắn nhãn bởi nhân viên của Datbricks. Cả mô hình và tập dữ liệu đều có sẵn cho mục đích thương mại.
Dolly 1.0 được đào tạo trên bộ dữ liệu Stanford Alpaca, được tạo bằng API OpenAI. Tập dữ liệu chứa đầu ra từ ChatGPT và ngăn không cho bất kỳ ai sử dụng nó để cạnh tranh với OpenAI. Nói tóm lại, bạn không thể xây dựng một ứng dụng ngôn ngữ hoặc chatbot thương mại dựa trên tập dữ liệu này.
Hầu hết các mẫu mới nhất ra mắt trong vài tuần qua đều gặp phải vấn đề tương tự, những mẫu như Alpaca, Koala, GPT4Tất cảvà Vicuna. Để giải quyết vấn đề này, chúng tôi cần tạo các bộ dữ liệu mới chất lượng cao có thể được sử dụng cho mục đích thương mại và đó là những gì nhóm Databricks đã thực hiện với bộ dữ liệu databricks-dolly-15k.
Bộ dữ liệu mới chứa 15,000 cặp lời nhắc/phản hồi chất lượng cao do con người gắn nhãn có thể được sử dụng để thiết kế hướng dẫn điều chỉnh các mô hình ngôn ngữ lớn. Các databricks-dolly-15k tập dữ liệu đi kèm với Creative Commons Ghi công-Chia sẻ tương tự 3.0 Giấy phép chưa chuyển đổi, cho phép mọi người sử dụng, sửa đổi và tạo ứng dụng thương mại trên đó.
Họ đã tạo tập dữ liệu databricks-dolly-15k như thế nào?
Nghiên cứu OpenAI giấy tuyên bố rằng mô hình InstructGPT ban đầu đã được đào tạo dựa trên 13,000 lời nhắc và phản hồi. Bằng cách sử dụng thông tin này, nhóm Databricks đã bắt đầu nghiên cứu nó và hóa ra việc tạo ra 13 nghìn câu hỏi và câu trả lời là một nhiệm vụ khó khăn. Họ không thể sử dụng dữ liệu tổng hợp hoặc dữ liệu tạo AI và họ phải tạo ra câu trả lời gốc cho mọi câu hỏi. Đây là nơi họ quyết định sử dụng 5,000 nhân viên của Databricks để tạo ra dữ liệu do con người tạo ra.
Databricks đã tổ chức một cuộc thi, trong đó 20 người gắn nhãn hàng đầu sẽ nhận được một giải thưởng lớn. Trong cuộc thi này, 5,000 nhân viên Databricks rất quan tâm đến LLM đã tham gia
Dolly-v2-12b không phải là mẫu hiện đại. Nó hoạt động kém hơn dolly-v1-6b trong một số tiêu chuẩn đánh giá. Có thể là do thành phần và kích thước của các bộ dữ liệu tinh chỉnh cơ bản. Dòng mô hình Dolly đang được phát triển tích cực, vì vậy bạn có thể thấy phiên bản cập nhật với hiệu suất tốt hơn trong tương lai.
Nói tóm lại, mô hình dolly-v2-12b đã hoạt động tốt hơn EleutherAI/gpt-neox-20b và EleutherAI/pythia-6.9b.

Hình ảnh từ Dolly miễn phí
Dolly 2.0 là nguồn mở 100%. Nó đi kèm với mã đào tạo, tập dữ liệu, trọng số mô hình và đường dẫn suy luận. Tất cả các thành phần đều phù hợp cho mục đích thương mại. Bạn có thể thử mẫu trên Ôm Mặt Không Gian Dolly V2 của RamAnanth1.
Hình ảnh từ Ôm mặt
Tài nguyên:
Bản trình diễn Dolly 2.0: Dolly V2 của RamAnanth1
Abid Ali Awan (@ 1abidaliawan) là một nhà khoa học dữ liệu chuyên nghiệp được chứng nhận, người yêu thích việc xây dựng các mô hình học máy. Hiện tại, anh đang tập trung sáng tạo nội dung và viết blog kỹ thuật về công nghệ máy học và khoa học dữ liệu. Abid có bằng Thạc sĩ về Quản lý Công nghệ và bằng cử nhân về Kỹ thuật Viễn thông. Tầm nhìn của ông là xây dựng một sản phẩm AI bằng cách sử dụng mạng nơ-ron đồ thị cho những sinh viên đang chống chọi với bệnh tâm thần.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- : có
- :là
- :không phải
- $ LÊN
- 000
- 1
- 20
- a
- có khả năng
- hoạt động
- AI
- Tất cả
- cho phép
- thay thế
- an
- và
- câu trả lời
- bất kỳ ai
- api
- Các Ứng Dụng
- LÀ
- xung quanh
- tác giả
- có sẵn
- giải thưởng
- dựa
- BE
- Điểm chuẩn
- Berkeley
- Hơn
- lớn
- Bing
- blog
- cả hai
- xây dựng
- Xây dựng
- by
- CAN
- không thể
- CHỨNG NHẬN
- chatbot
- ChatGPT
- mã
- thương gia
- Dân chúng
- cạnh tranh
- các thành phần
- chứa
- nội dung
- tạo nội dung
- cuộc thi
- Chi phí
- tạo
- tạo ra
- tạo
- Hiện nay
- dữ liệu
- khoa học dữ liệu
- nhà khoa học dữ liệu
- Bảng dữ liệu
- bộ dữ liệu
- quyết định
- Bằng cấp
- Demo
- Thiết kế
- Phát triển
- ĐÃ LÀM
- khó khăn
- Dolly
- Công nhân
- nhân viên
- Kỹ Sư
- đánh giá
- Mỗi
- triển lãm
- Đối mặt
- gia đình
- vài
- tập trung
- tiếp theo
- Trong
- từ
- tương lai
- tạo ra
- tạo ra
- thế hệ
- được
- đồ thị
- Mạng Neural Đồ thị
- Có
- he
- chất lượng cao
- giữ
- HTML
- HTTPS
- bệnh
- hình ảnh
- in
- thông tin
- quan tâm
- vấn đề
- các vấn đề
- IT
- jpg
- Xe đẩy
- Ngôn ngữ
- lớn
- Họ
- mới nhất
- học tập
- Giấy phép
- Lượt thích
- máy
- học máy
- quản lý
- chủ
- tâm thần
- Bệnh tâm thần
- Might
- kiểu mẫu
- mô hình
- sửa đổi
- Cần
- mạng
- Thần kinh
- mạng lưới thần kinh
- Mới
- of
- on
- có thể
- mở
- mã nguồn mở
- OpenAI
- or
- nguyên
- đầu ra
- cặp
- tham số
- tham gia
- hiệu suất
- đường ống dẫn
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- Sản phẩm
- chuyên nghiệp
- mục đích
- câu hỏi
- Câu hỏi
- phát hành
- nghiên cứu
- quyết định
- hạn chế
- s
- tương tự
- Khoa học
- Nhà khoa học
- định
- ngắn
- Kích thước máy
- So
- một số
- nguồn
- Không gian
- không gian
- stanford
- bắt đầu
- nhà nước-of-the-art
- Bang
- Đấu tranh
- Sinh viên
- phù hợp
- sợi tổng hợp
- dữ liệu tổng hợp
- Nhiệm vụ
- nhóm
- Kỹ thuật
- Công nghệ
- Công nghệ
- viễn thông
- hơn
- việc này
- Sản phẩm
- Tương lai
- họ
- điều này
- đến
- hàng đầu
- Train
- đào tạo
- Hội thảo
- Dưới
- cơ bản
- cập nhật
- sử dụng
- đã sử dụng
- sử dụng
- phiên bản
- tầm nhìn
- là
- we
- tuần
- là
- Điều gì
- cái nào
- CHÚNG TÔI LÀ
- với
- Công việc
- sẽ
- viết
- bạn
- zephyrnet










