Đây là một bài đăng chung do AWS và Voxel51 đồng viết. Voxel51 là công ty đứng sau FiftyOne, bộ công cụ nguồn mở để xây dựng bộ dữ liệu chất lượng cao và mô hình thị giác máy tính.
Một công ty bán lẻ đang xây dựng một ứng dụng di động để giúp khách hàng mua quần áo. Để tạo ứng dụng này, họ cần có bộ dữ liệu chất lượng cao chứa hình ảnh quần áo, được gắn nhãn với các danh mục khác nhau. Trong bài đăng này, chúng tôi trình bày cách sử dụng lại tập dữ liệu hiện có thông qua làm sạch dữ liệu, tiền xử lý và ghi nhãn trước bằng mô hình phân loại zero-shot trong Năm mươi mốtvà điều chỉnh các nhãn này bằng Sự thật về mặt đất của Amazon SageMaker.
Bạn có thể sử dụng Ground Truth và FiftyOne để tăng tốc dự án ghi nhãn dữ liệu của mình. Chúng tôi minh họa cách sử dụng liền mạch hai ứng dụng cùng nhau để tạo bộ dữ liệu được gắn nhãn chất lượng cao. Đối với trường hợp sử dụng ví dụ của chúng tôi, chúng tôi làm việc với Bộ dữ liệu Fashion200K, phát hành tại ICCV 2017.
Tổng quan về giải pháp
Ground Truth là dịch vụ ghi nhãn dữ liệu được quản lý và tự phục vụ hoàn toàn, hỗ trợ các nhà khoa học dữ liệu, kỹ sư máy học (ML) và nhà nghiên cứu xây dựng bộ dữ liệu chất lượng cao. Năm mươi mốt by voxel51 là bộ công cụ nguồn mở để quản lý, trực quan hóa và đánh giá bộ dữ liệu thị giác máy tính để bạn có thể đào tạo và phân tích các mô hình tốt hơn bằng cách tăng tốc các trường hợp sử dụng của mình.
Trong các phần sau, chúng tôi trình bày cách thực hiện như sau:
- Trực quan hóa tập dữ liệu trong FiftyOne
- Làm sạch tập dữ liệu bằng tính năng lọc và sao chép hình ảnh trong FiftyOne
- Gắn nhãn trước cho dữ liệu đã làm sạch với phân loại zero-shot trong FiftyOne
- Gắn nhãn tập dữ liệu được quản lý nhỏ hơn với Ground Truth
- Đưa các kết quả được dán nhãn từ Ground Truth vào FiftyOne và xem xét các kết quả được dán nhãn trong FiftyOne
Tổng quan về ca sử dụng
Giả sử bạn sở hữu một công ty bán lẻ và muốn xây dựng một ứng dụng dành cho thiết bị di động để đưa ra các đề xuất được cá nhân hóa nhằm giúp người dùng quyết định nên mặc gì. Người dùng tiềm năng của bạn đang tìm kiếm một ứng dụng cho họ biết những mặt hàng quần áo nào trong tủ quần áo của họ phối hợp ăn ý với nhau. Bạn nhìn thấy một cơ hội ở đây: nếu bạn có thể xác định những trang phục tốt, bạn có thể sử dụng cơ hội này để giới thiệu các mặt hàng quần áo mới bổ sung cho quần áo mà khách hàng đã sở hữu.
Bạn muốn làm mọi thứ dễ dàng nhất có thể cho người dùng cuối. Lý tưởng nhất là ai đó sử dụng ứng dụng của bạn chỉ cần chụp ảnh quần áo trong tủ quần áo của họ và các mô hình ML của bạn sẽ phát huy tác dụng kỳ diệu của chúng ở hậu trường. Bạn có thể đào tạo một mô hình có mục đích chung hoặc tinh chỉnh một mô hình theo phong cách riêng của từng người dùng với một số dạng phản hồi.
Tuy nhiên, trước tiên, bạn cần xác định loại quần áo mà người dùng đang chụp. Có phải là một chiếc áo sơ mi? Một chiếc quần? Hay cái gì khác? Rốt cuộc, bạn có thể không muốn giới thiệu một bộ trang phục có nhiều váy hoặc nhiều mũ.
Để giải quyết thách thức ban đầu này, bạn muốn tạo tập dữ liệu huấn luyện bao gồm hình ảnh của nhiều mặt hàng quần áo với nhiều mẫu và kiểu dáng khác nhau. Để tạo nguyên mẫu với ngân sách hạn chế, bạn muốn khởi động bằng tập dữ liệu hiện có.
Để minh họa và hướng dẫn bạn thực hiện quy trình trong bài đăng này, chúng tôi sử dụng tập dữ liệu Fashion200K được phát hành tại ICCV 2017. Đây là tập dữ liệu được thiết lập và trích dẫn tốt, nhưng không phù hợp trực tiếp cho trường hợp sử dụng của bạn.
Mặc dù các mặt hàng quần áo được dán nhãn theo danh mục (và danh mục phụ) và chứa nhiều thẻ hữu ích được trích xuất từ mô tả sản phẩm ban đầu, dữ liệu không được gắn nhãn một cách có hệ thống với thông tin về mẫu hoặc kiểu dáng. Mục tiêu của bạn là biến tập dữ liệu hiện có này thành tập dữ liệu đào tạo mạnh mẽ cho các mô hình phân loại quần áo của bạn. Bạn cần làm sạch dữ liệu, tăng lược đồ ghi nhãn bằng các nhãn kiểu. Và bạn muốn thực hiện điều đó một cách nhanh chóng và tốn ít chi phí nhất có thể.
Tải xuống dữ liệu cục bộ
Trước tiên, hãy tải xuống tệp zip women.tar và thư mục nhãn (cùng với tất cả các thư mục con của nó) theo hướng dẫn được cung cấp trong Bộ dữ liệu Fashion200K Kho lưu trữ GitHub. Sau khi bạn đã giải nén cả hai, hãy tạo một thư mục mẹ fashion200k, và di chuyển các thư mục nhãn và phụ nữ vào đó. May mắn thay, những hình ảnh này đã được cắt thành các hộp giới hạn phát hiện đối tượng, vì vậy chúng tôi có thể tập trung vào việc phân loại, thay vì lo lắng về việc phát hiện đối tượng.
Mặc dù có biệt danh là “200K”, danh mục phụ nữ mà chúng tôi đã trích xuất chứa 338,339 hình ảnh. Để tạo bộ dữ liệu Fashion200K chính thức, các tác giả của bộ dữ liệu đã thu thập dữ liệu trực tuyến của hơn 300,000 sản phẩm và chỉ những sản phẩm có mô tả chứa hơn bốn từ mới được chọn. Đối với các mục đích của chúng tôi, khi mô tả sản phẩm không cần thiết, chúng tôi có thể sử dụng tất cả các hình ảnh được thu thập thông tin.
Hãy xem dữ liệu này được tổ chức như thế nào: trong thư mục phụ nữ, hình ảnh được sắp xếp theo loại bài viết cấp cao nhất (váy, áo, quần, áo khoác và váy) và tiểu thể loại bài viết (áo cánh, áo phông, dài tay ngọn).
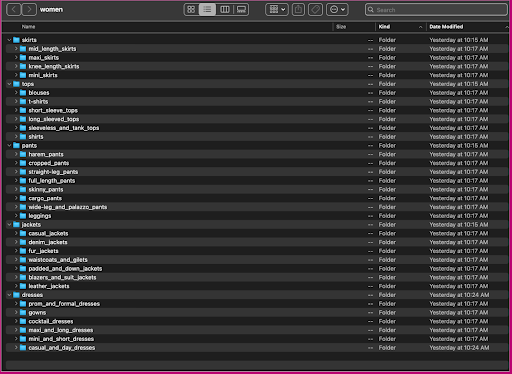
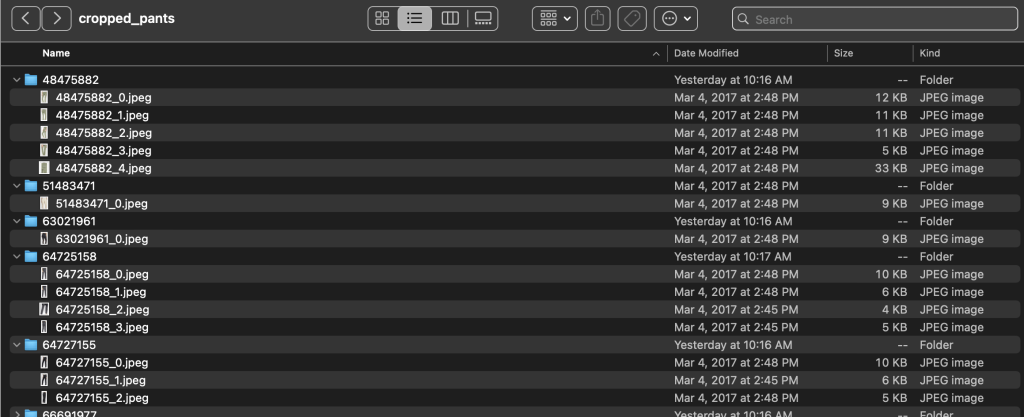
Trong các thư mục danh mục con, có một thư mục con cho mỗi danh sách sản phẩm. Mỗi trong số này chứa một số lượng hình ảnh khác nhau. Ví dụ: danh mục phụ cropped_pants chứa danh sách sản phẩm sau đây và hình ảnh liên quan.
Thư mục nhãn chứa một tệp văn bản cho từng loại bài viết cấp cao nhất, cho cả phân tách đào tạo và kiểm tra. Trong mỗi tệp văn bản này có một dòng riêng cho từng hình ảnh, chỉ định đường dẫn tệp tương đối, điểm số và các thẻ từ mô tả sản phẩm.
Bởi vì chúng tôi đang tái sử dụng tập dữ liệu, chúng tôi kết hợp tất cả các hình ảnh đào tạo và thử nghiệm. Chúng tôi sử dụng những thứ này để tạo tập dữ liệu dành riêng cho ứng dụng chất lượng cao. Sau khi chúng tôi hoàn thành quá trình này, chúng tôi có thể chia ngẫu nhiên tập dữ liệu kết quả thành các phần tách thử nghiệm và đào tạo mới.
Tiêm, xem và quản lý tập dữ liệu trong FiftyOne
Nếu bạn chưa làm như vậy, hãy cài đặt mã nguồn mở FiftyOne bằng cách sử dụng pip:
Cách tốt nhất là làm như vậy trong một môi trường ảo (venv hoặc conda) mới. Sau đó nhập các mô-đun có liên quan. Nhập thư viện cơ sở, XNUMX, FiftyOne Brain, có các phương thức ML tích hợp, FiftyOne Zoo, từ đó chúng tôi sẽ tải một mô hình sẽ tạo nhãn zero-shot cho chúng tôi và ViewField, cho phép chúng tôi lọc hiệu quả dữ liệu trong bộ dữ liệu của chúng tôi:
Bạn cũng muốn nhập mô-đun glob và os Python, mô-đun này sẽ giúp chúng tôi làm việc với các đường dẫn và khớp mẫu trên nội dung thư mục:
Bây giờ, chúng tôi đã sẵn sàng tải tập dữ liệu vào FiftyOne. Đầu tiên, chúng tôi tạo một tập dữ liệu có tên là fashion200k và làm cho nó bền vững, cho phép chúng tôi lưu kết quả của các hoạt động tính toán chuyên sâu, vì vậy chúng tôi chỉ cần tính toán các đại lượng nói trên một lần.
Giờ đây, chúng tôi có thể lặp qua tất cả các thư mục danh mục phụ, thêm tất cả hình ảnh vào các thư mục sản phẩm. Chúng tôi thêm nhãn phân loại FiftyOne vào từng mẫu có tên trường article_type, được phổ biến bởi danh mục bài viết cấp cao nhất của hình ảnh. Chúng tôi cũng thêm cả thông tin danh mục và danh mục phụ dưới dạng thẻ:
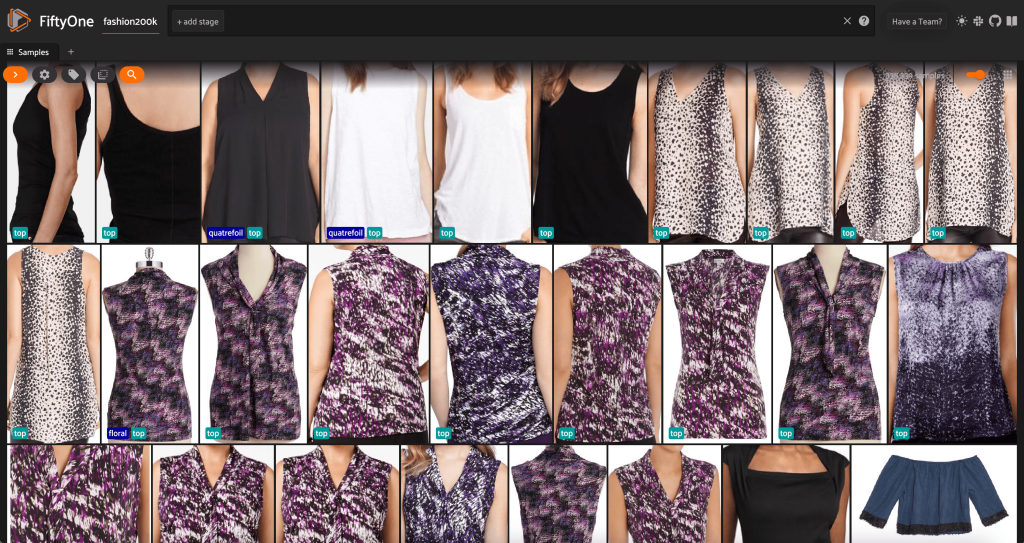
Tại thời điểm này, chúng ta có thể trực quan hóa tập dữ liệu của mình trong ứng dụng FiftyOne bằng cách khởi chạy một phiên:
Chúng tôi cũng có thể in ra một bản tóm tắt của tập dữ liệu bằng Python bằng cách chạy print(dataset):
Chúng tôi cũng có thể thêm các thẻ từ labels thư mục vào các mẫu trong tập dữ liệu của chúng tôi:
Nhìn vào dữ liệu, một vài điều trở nên rõ ràng:
- Một số hình ảnh khá hạt, với độ phân giải thấp. Điều này có thể là do những hình ảnh này được tạo bằng cách cắt các hình ảnh ban đầu trong các hộp giới hạn phát hiện đối tượng.
- Một số quần áo được mặc bởi một người, và một số được chụp bởi chính họ. Những chi tiết này được đóng gói bởi
viewpointbất động sản. - Rất nhiều hình ảnh của cùng một sản phẩm rất giống nhau, vì vậy, ít nhất là ban đầu, việc bao gồm nhiều hơn một hình ảnh cho mỗi sản phẩm có thể không mang lại nhiều khả năng dự đoán. Phần lớn, hình ảnh đầu tiên của mỗi sản phẩm (kết thúc bằng
_0.jpeg) là sạch nhất.
Ban đầu, chúng tôi có thể muốn đào tạo mô hình phân loại kiểu quần áo của mình trên một tập hợp con được kiểm soát của những hình ảnh này. Để đạt được mục tiêu này, chúng tôi sử dụng hình ảnh có độ phân giải cao về các sản phẩm của mình và giới hạn chế độ xem của chúng tôi ở một mẫu đại diện cho mỗi sản phẩm.
Đầu tiên, chúng tôi lọc ra những hình ảnh có độ phân giải thấp. chúng tôi sử dụng compute_metadata() phương pháp tính toán và lưu trữ chiều rộng và chiều cao của hình ảnh, tính bằng pixel, cho mỗi hình ảnh trong bộ dữ liệu. Sau đó chúng tôi sử dụng FiftyOne ViewField để lọc ra các hình ảnh dựa trên các giá trị chiều rộng và chiều cao tối thiểu được phép. Xem đoạn mã sau:
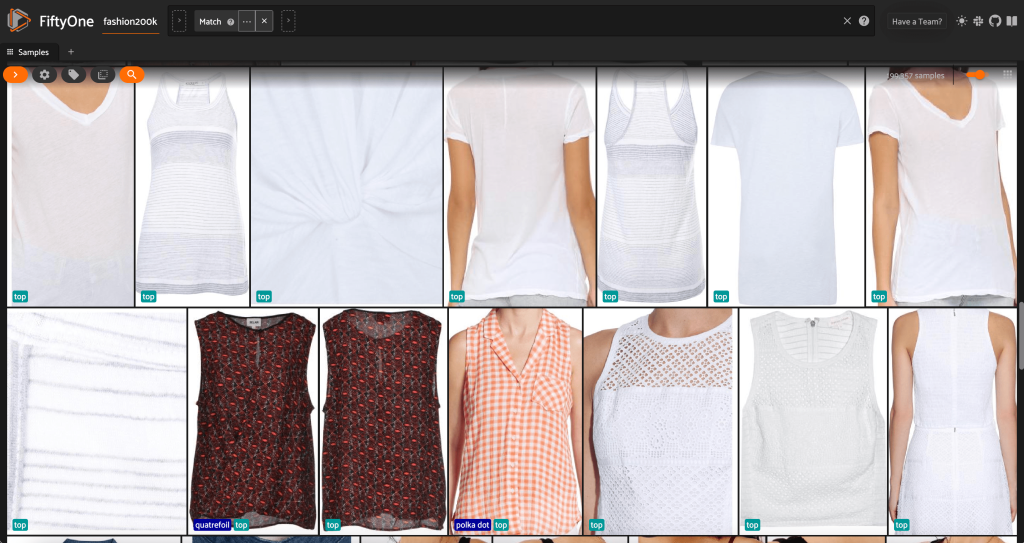
Tập hợp con có độ phân giải cao này chỉ có dưới 200,000 mẫu.
Từ chế độ xem này, chúng tôi có thể tạo chế độ xem mới trong tập dữ liệu của mình chỉ chứa một mẫu đại diện (tối đa) cho mỗi sản phẩm. chúng tôi sử dụng ViewField một lần nữa, khớp mẫu cho các đường dẫn tệp kết thúc bằng _0.jpeg:
Hãy xem thứ tự các hình ảnh được xáo trộn ngẫu nhiên trong tập hợp con này:
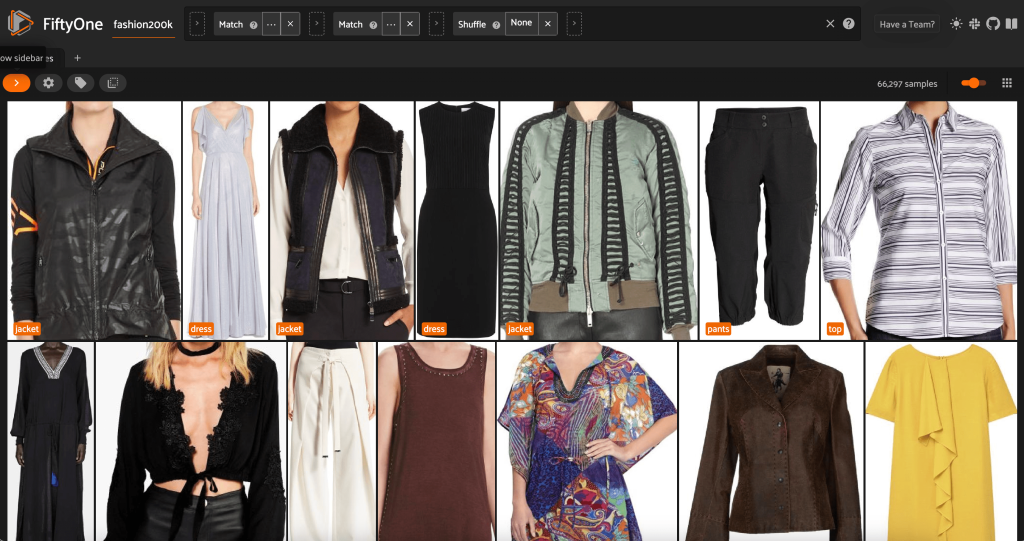
Loại bỏ các hình ảnh dư thừa trong tập dữ liệu
Chế độ xem này chứa 66,297 hình ảnh hoặc chỉ hơn 19% tập dữ liệu gốc. Tuy nhiên, khi nhìn vào khung cảnh, chúng tôi thấy rằng có nhiều sản phẩm rất giống nhau. Việc giữ tất cả các bản sao này có thể sẽ chỉ tăng thêm chi phí cho việc ghi nhãn và đào tạo mô hình của chúng tôi mà không cải thiện đáng kể hiệu suất. Thay vào đó, hãy loại bỏ các bản sao gần nhất để tạo một tập dữ liệu nhỏ hơn mà vẫn có cùng một cú đấm.
Bởi vì những hình ảnh này không phải là bản sao chính xác nên chúng tôi không thể kiểm tra sự bằng nhau về pixel. May mắn thay, chúng tôi có thể sử dụng FiftyOne Brain để giúp chúng tôi làm sạch tập dữ liệu của mình. Cụ thể, chúng ta sẽ tính toán một phép nhúng cho mỗi hình ảnh—một vectơ chiều thấp hơn đại diện cho hình ảnh—và sau đó tìm kiếm các hình ảnh có các vectơ nhúng gần nhau. Các vectơ càng gần, hình ảnh càng giống nhau.
Chúng tôi sử dụng mô hình CLIP để tạo vectơ nhúng 512 chiều cho mỗi hình ảnh và lưu trữ các phần nhúng này trong trường nhúng trên các mẫu trong tập dữ liệu của chúng tôi:
Sau đó, chúng tôi tính toán mức độ gần gũi giữa các lần nhúng, sử dụng cosine tương tựvà khẳng định rằng bất kỳ hai vectơ nào có độ tương tự lớn hơn một số ngưỡng có khả năng gần trùng lặp. Điểm tương tự cosine nằm trong phạm vi [0, 1] và nhìn vào dữ liệu, điểm ngưỡng thresh=0.5 dường như là đúng. Một lần nữa, điều này không cần phải hoàn hảo. Một số hình ảnh gần như trùng lặp không có khả năng làm hỏng khả năng dự đoán của chúng tôi và việc loại bỏ một vài hình ảnh không trùng lặp không ảnh hưởng đáng kể đến hiệu suất của mô hình.
Chúng tôi có thể xem các mục trùng lặp có mục đích để xác minh rằng chúng thực sự dư thừa:
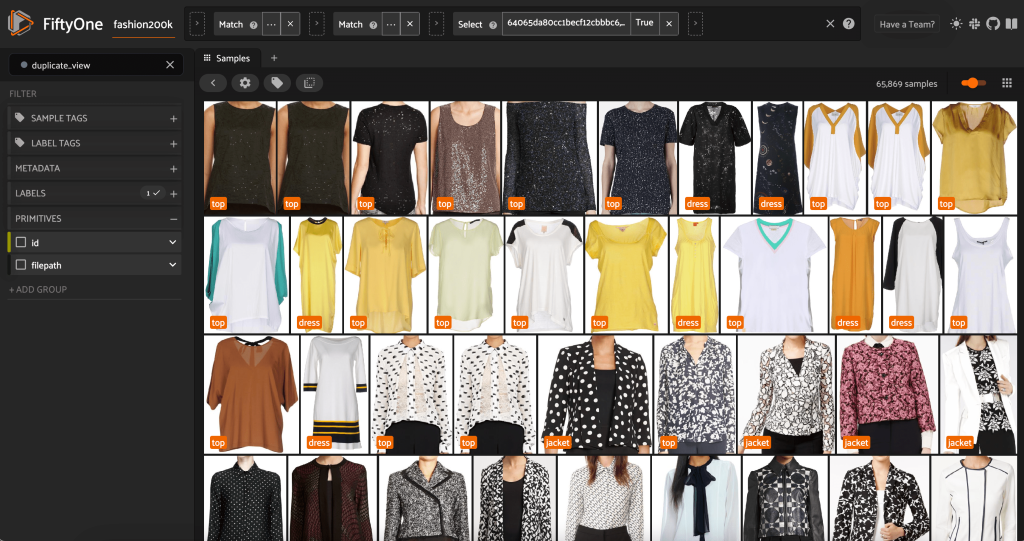
Khi chúng tôi hài lòng với kết quả và tin rằng những hình ảnh này thực sự gần giống nhau, chúng tôi có thể chọn một mẫu từ mỗi bộ mẫu tương tự để giữ lại và bỏ qua những mẫu khác:
Bây giờ chế độ xem này có 3,729 hình ảnh. Bằng cách làm sạch dữ liệu và xác định một tập hợp con chất lượng cao của tập dữ liệu Fashion200K, FiftyOne cho phép chúng tôi hạn chế tiêu điểm của mình từ hơn 300,000 hình ảnh xuống chỉ còn dưới 4,000, tương đương với mức giảm 98%. Chỉ riêng việc sử dụng các nhúng để loại bỏ các hình ảnh gần như trùng lặp đã làm giảm hơn 90% tổng số hình ảnh đang được xem xét của chúng tôi mà hầu như không ảnh hưởng đến bất kỳ mô hình nào được đào tạo trên dữ liệu này.
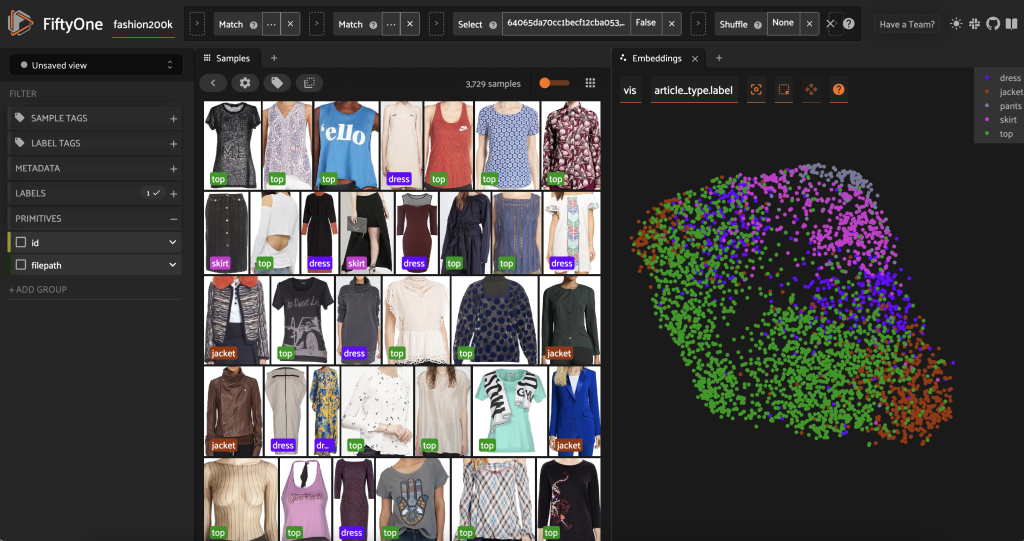
Trước khi gắn nhãn trước tập hợp con này, chúng tôi có thể hiểu rõ hơn về dữ liệu bằng cách trực quan hóa các phần nhúng mà chúng tôi đã tính toán. Chúng ta có thể sử dụng tính năng tích hợp sẵn của FiftyOne Brain compute_visualization(), sử dụng kỹ thuật xấp xỉ đa tạp thống nhất (UMAP) để chiếu các vectơ nhúng 512 chiều vào không gian hai chiều để chúng ta có thể hình dung chúng:
Chúng tôi mở một cái mới bảng nhúng trong ứng dụng FiftyOne và tô màu theo loại bài viết, và chúng ta có thể thấy rằng các phần nhúng này đại khái mã hóa một khái niệm về loại bài viết (trong số những thứ khác!).
Bây giờ chúng tôi đã sẵn sàng để dán nhãn trước cho dữ liệu này.
Khi kiểm tra những hình ảnh có độ phân giải cao, rất độc đáo này, chúng tôi có thể tạo một danh sách phong cách ban đầu hợp lý để sử dụng làm các lớp trong phân loại ảnh không chụp trước khi dán nhãn của chúng tôi. Mục tiêu của chúng tôi khi dán nhãn trước cho những hình ảnh này không nhất thiết phải gắn nhãn chính xác cho từng hình ảnh. Thay vào đó, mục tiêu của chúng tôi là cung cấp một điểm khởi đầu tốt cho người chú thích là con người để chúng tôi có thể giảm thời gian và chi phí dán nhãn.
Sau đó, chúng tôi có thể khởi tạo mô hình phân loại zero-shot cho ứng dụng này. Chúng tôi sử dụng mô hình CLIP, đây là mô hình có mục đích chung được đào tạo về cả hình ảnh và ngôn ngữ tự nhiên. Chúng tôi khởi tạo một mô hình CLIP với lời nhắc văn bản “Quần áo theo phong cách”, sao cho một hình ảnh được cung cấp, mô hình sẽ xuất ra lớp mà “Quần áo theo phong cách [lớp]” là phù hợp nhất. CLIP không được đào tạo về dữ liệu bán lẻ hoặc thời trang cụ thể, vì vậy điều này sẽ không hoàn hảo, nhưng nó có thể giúp bạn tiết kiệm chi phí ghi nhãn và chú thích.
Sau đó, chúng tôi áp dụng mô hình này cho tập hợp con đã giảm của mình và lưu trữ kết quả trong một article_style cánh đồng:
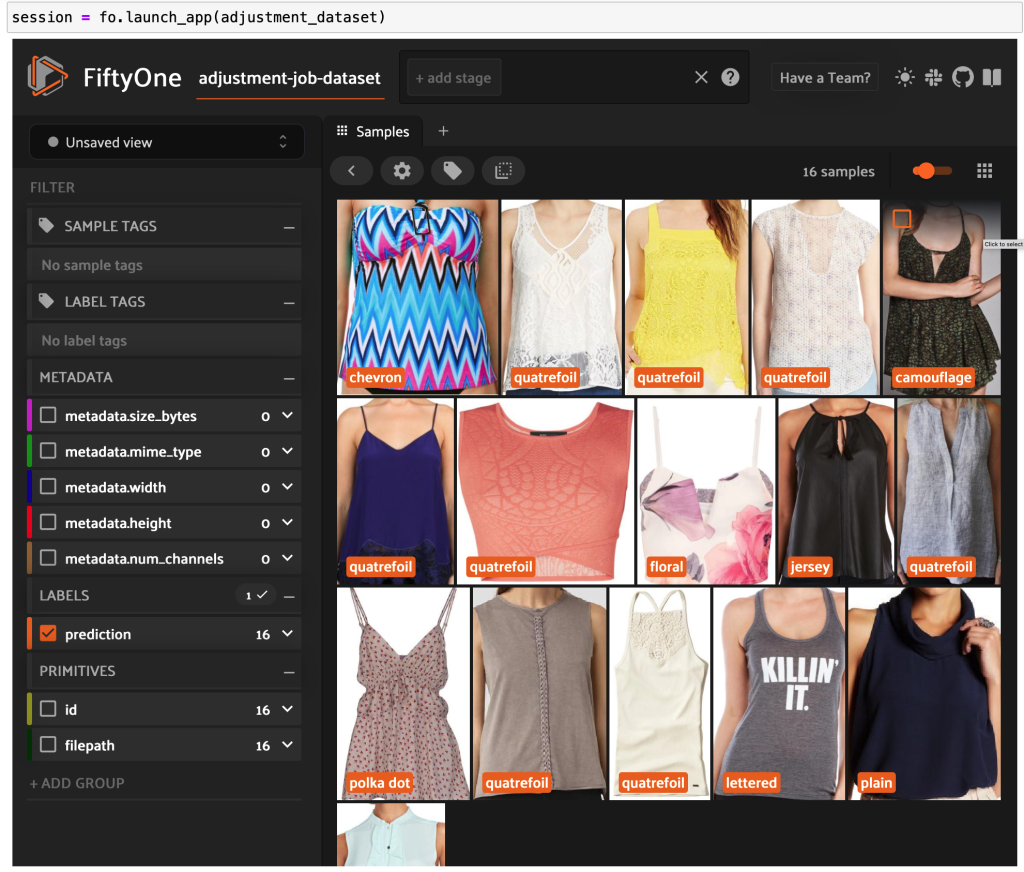
Khởi chạy Ứng dụng FiftyOne một lần nữa, chúng ta có thể trực quan hóa hình ảnh bằng các nhãn kiểu được dự đoán này. Chúng tôi sắp xếp theo độ tin cậy của dự đoán để chúng tôi xem các dự đoán theo phong cách tự tin nhất trước tiên:
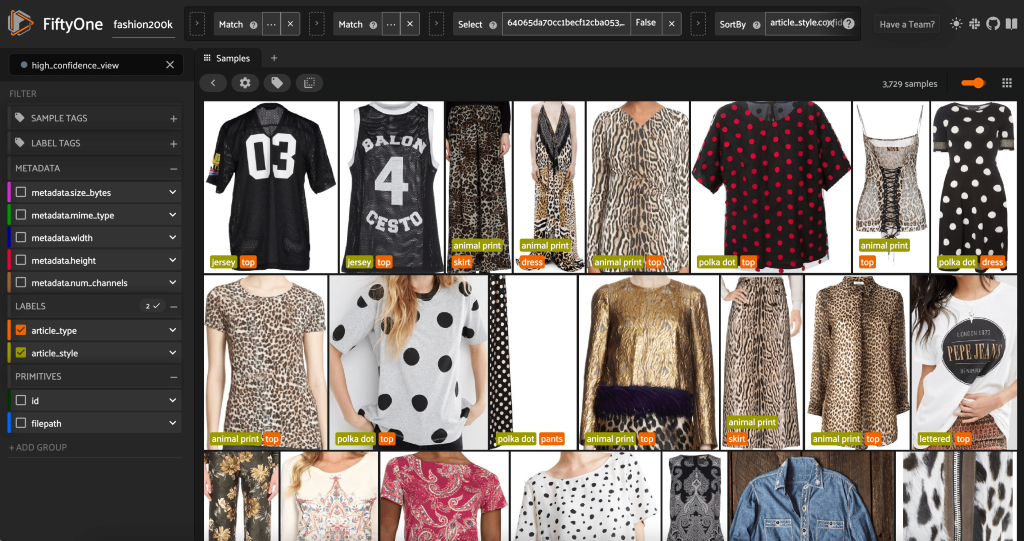
Chúng ta có thể thấy rằng các dự đoán có độ tin cậy cao nhất dường như dành cho kiểu “áo”, “hình in động vật”, “chấm bi” và “chữ cái”. Điều này có ý nghĩa, bởi vì những phong cách này tương đối khác biệt. Phần lớn, có vẻ như các nhãn kiểu được dự đoán là chính xác.
Chúng ta cũng có thể xem xét các dự đoán kiểu có độ tin cậy thấp nhất:
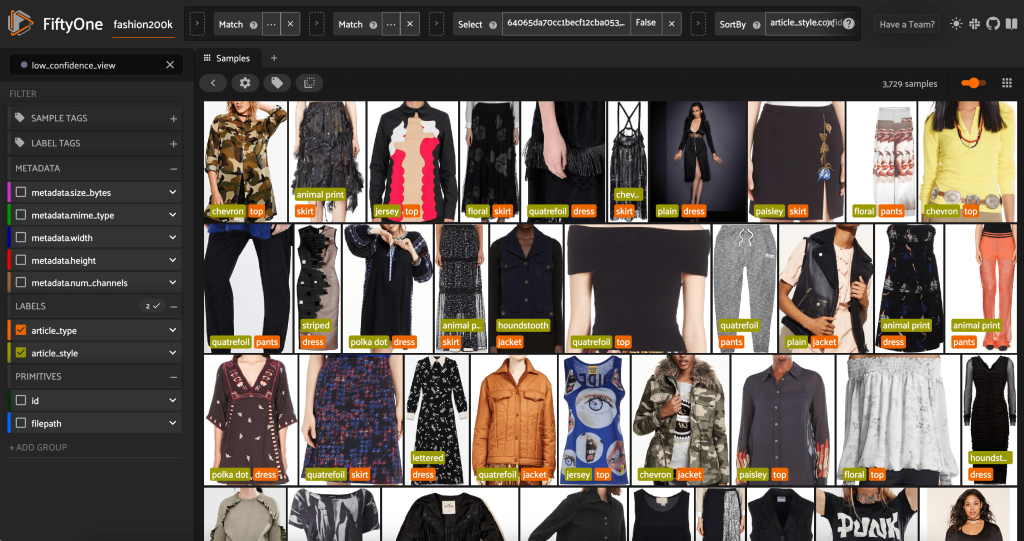
Đối với một số hình ảnh này, danh mục phong cách phù hợp nằm trong danh sách được cung cấp và mặt hàng quần áo được dán nhãn không chính xác. Ví dụ: hình ảnh đầu tiên trong lưới phải rõ ràng là “ngụy trang” chứ không phải “chevron”. Tuy nhiên, trong các trường hợp khác, các sản phẩm không phù hợp gọn gàng với các danh mục kiểu dáng. Ví dụ: chiếc váy trong hình ảnh thứ hai ở hàng thứ hai không chính xác là "sọc", nhưng với các tùy chọn ghi nhãn giống nhau, người chú thích là con người cũng có thể bị mâu thuẫn. Khi chúng tôi xây dựng tập dữ liệu của mình, chúng tôi cần quyết định xem có nên xóa các trường hợp cạnh như thế này, thêm danh mục kiểu mới hay tăng cường tập dữ liệu hay không.
Xuất tập dữ liệu cuối cùng từ FiftyOne
Xuất tập dữ liệu cuối cùng với mã sau:
Chúng tôi có thể xuất một tập dữ liệu nhỏ hơn, ví dụ: 16 hình ảnh, vào thư mục 200kFashionDatasetExportResult-16Images. Chúng tôi tạo một công việc điều chỉnh Ground Truth bằng cách sử dụng nó:
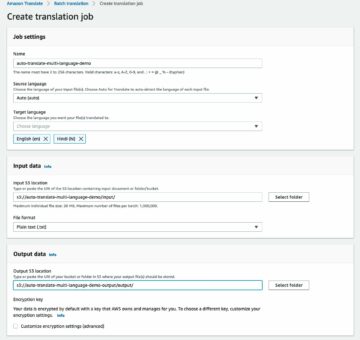
Tải tập dữ liệu đã sửa đổi lên, chuyển đổi định dạng nhãn thành Ground Truth, tải lên Amazon S3 và tạo tệp kê khai cho tác vụ điều chỉnh
Chúng tôi có thể chuyển đổi các nhãn trong tập dữ liệu để phù hợp với lược đồ bảng kê khai đầu ra của công việc hộp giới hạn Ground Truth và tải hình ảnh lên một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) để khởi chạy một Công việc điều chỉnh Ground Truth:
Tải tệp kê khai lên Amazon S3 bằng mã sau:
Tạo nhãn theo kiểu đã sửa với Ground Truth
Để chú thích dữ liệu của bạn bằng các nhãn kiểu bằng Ground Truth, hãy hoàn thành các bước cần thiết để bắt đầu công việc ghi nhãn hộp giới hạn bằng cách thực hiện theo quy trình được nêu trong Bắt đầu với sự thật cơ bản hướng dẫn với tập dữ liệu trong cùng một nhóm S3.
- Trên bảng điều khiển SageMaker, hãy tạo công việc ghi nhãn Ground Truth.
- Đặt Vị trí tập dữ liệu đầu vào là bảng kê khai mà chúng ta đã tạo trong các bước trước.
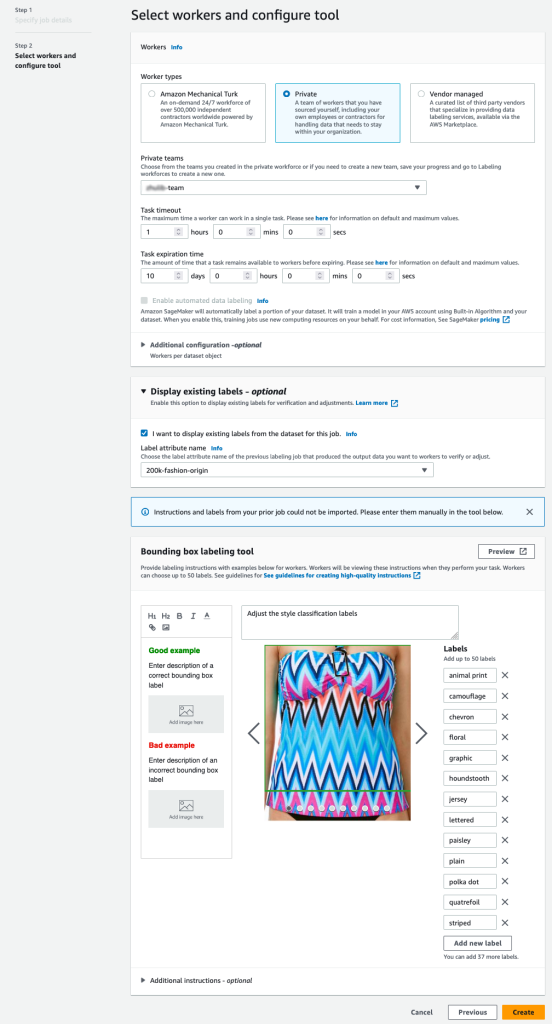
- Chỉ định đường dẫn S3 cho Vị trí tập dữ liệu đầu ra.
- Trong Vai trò IAM, chọn Nhập vai trò IAM tùy chỉnh RNA, sau đó nhập vai ARN.
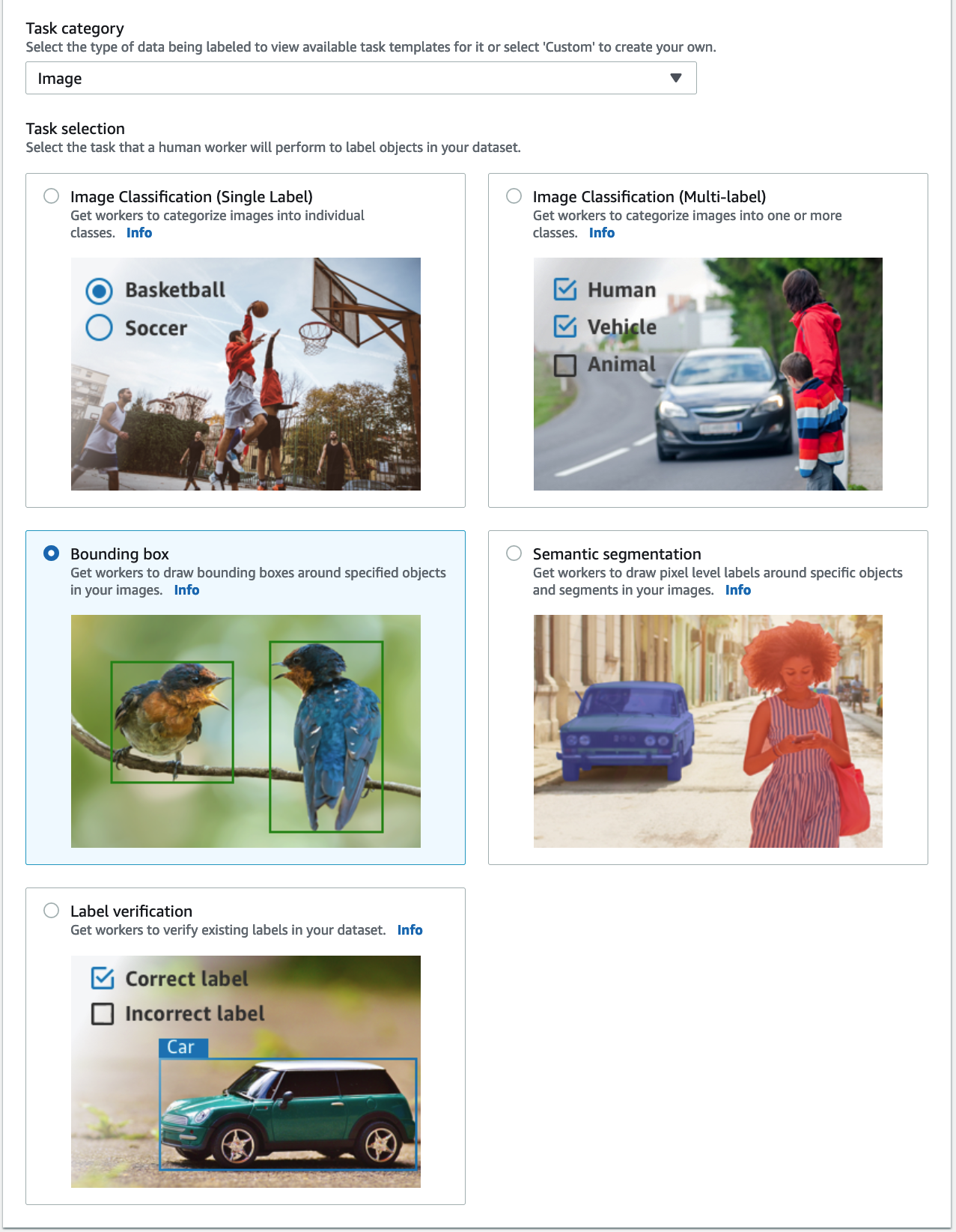
- Trong Nhiệm vụ, chọn Hình ảnh và chọn Hộp giới hạn.
- Chọn Sau.
- Trong tạp chí Người lao động chọn loại lực lượng lao động bạn muốn sử dụng.
Bạn có thể chọn một lực lượng lao động thông qua Amazon Mechanical Turk, nhà cung cấp bên thứ ba hoặc lực lượng lao động tư nhân của riêng bạn. Để biết thêm chi tiết về các tùy chọn lực lượng lao động của bạn, hãy xem Tạo và quản lý lực lượng lao động. - Mở rộng Tùy chọn hiển thị nhãn hiện có và chọn Tôi muốn hiển thị các nhãn hiện có từ tập dữ liệu cho công việc này.
- Trong thuộc tính nhãn tên, hãy chọn tên từ bảng kê khai tương ứng với các nhãn mà bạn muốn hiển thị để điều chỉnh.
Bạn sẽ chỉ thấy tên thuộc tính nhãn cho các nhãn phù hợp với loại tác vụ mà bạn đã chọn trong các bước trước đó. - Nhập thủ công các nhãn cho Công cụ ghi nhãn hộp ranh giới.
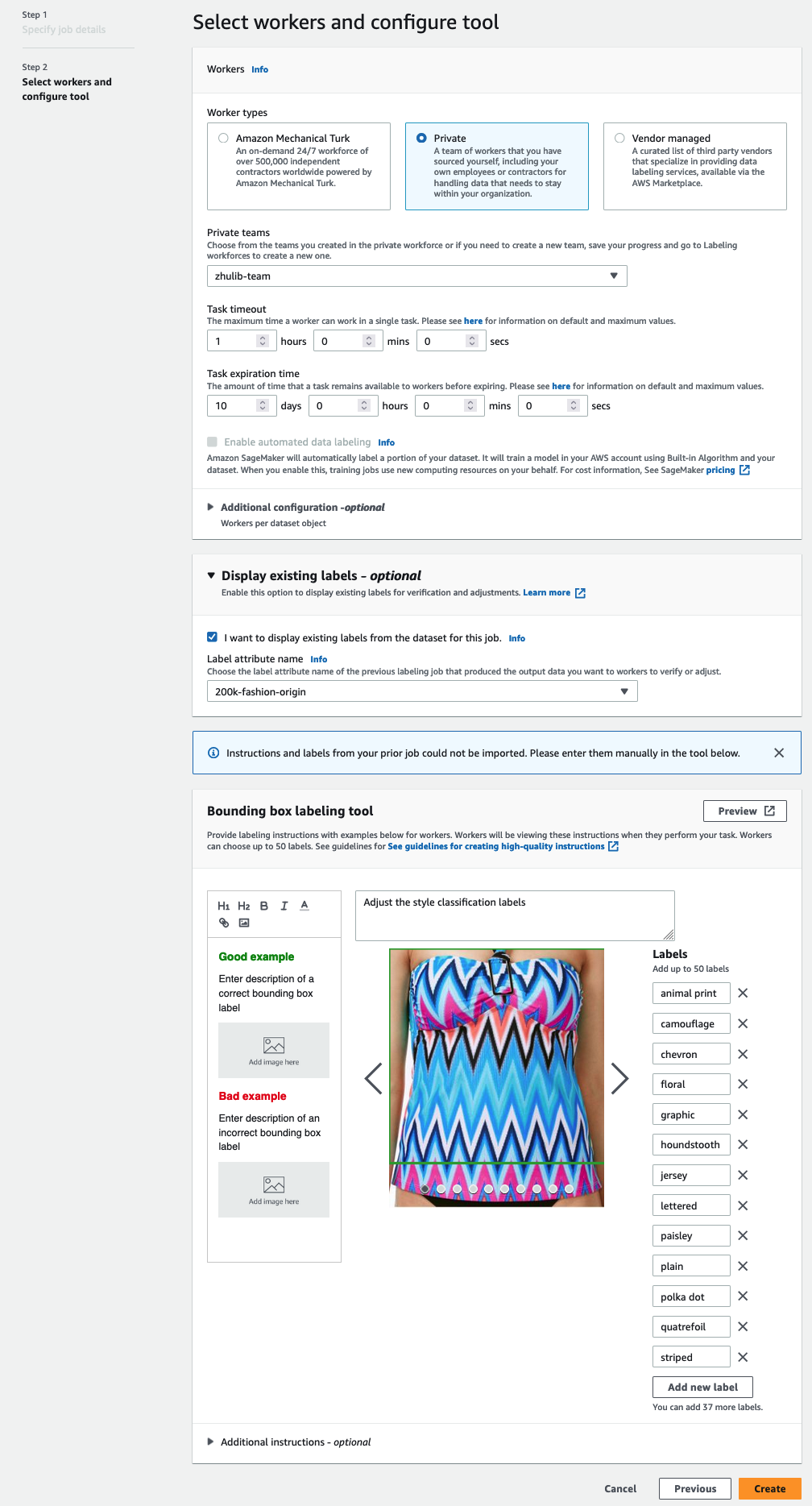 Các nhãn phải chứa các nhãn giống như được sử dụng trong tập dữ liệu công khai. Bạn có thể thêm nhãn mới. Ảnh chụp màn hình sau đây cho thấy cách bạn có thể chọn nhân viên và định cấu hình công cụ cho công việc dán nhãn của mình.
Các nhãn phải chứa các nhãn giống như được sử dụng trong tập dữ liệu công khai. Bạn có thể thêm nhãn mới. Ảnh chụp màn hình sau đây cho thấy cách bạn có thể chọn nhân viên và định cấu hình công cụ cho công việc dán nhãn của mình.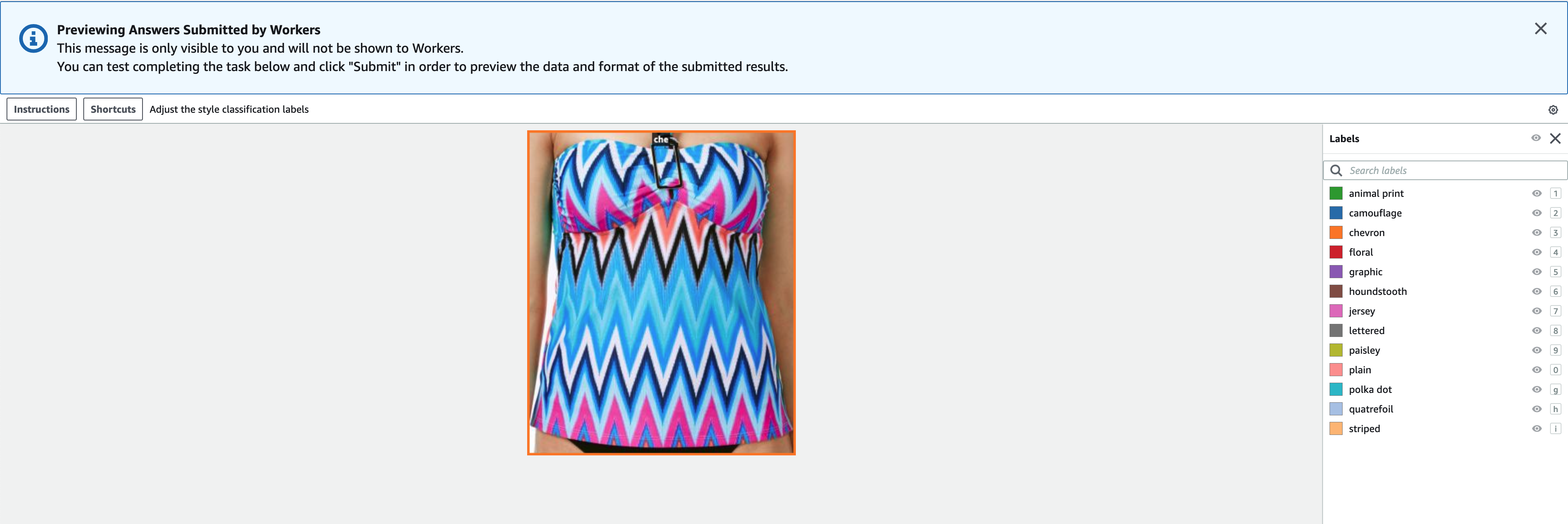
- Chọn Xem trước để xem trước hình ảnh và chú thích ban đầu.
Bây giờ chúng tôi đã tạo một công việc ghi nhãn trong Ground Truth. Sau khi công việc của chúng tôi hoàn thành, chúng tôi có thể tải dữ liệu được gắn nhãn mới được tạo vào FiftyOne. Ground Truth tạo dữ liệu đầu ra trong bảng kê khai đầu ra Ground Truth. Để biết thêm chi tiết về tệp kê khai đầu ra, hãy xem Kết quả công việc hộp giới hạn. Đoạn mã sau hiển thị một ví dụ về định dạng tệp kê khai đầu ra này:
Xem lại các kết quả được dán nhãn từ Ground Truth trong FiftyOne
Sau khi công việc hoàn tất, hãy tải xuống tệp kê khai đầu ra của công việc dán nhãn từ Amazon S3.
Đọc tệp kê khai đầu ra:
Tạo tập dữ liệu FiftyOne và chuyển đổi các dòng kê khai thành mẫu trong tập dữ liệu:
Giờ đây, bạn có thể xem dữ liệu được gắn nhãn chất lượng cao từ Ground Truth trong FiftyOne.
Kết luận
Trong bài đăng này, chúng tôi đã chỉ ra cách xây dựng bộ dữ liệu chất lượng cao bằng cách kết hợp sức mạnh của Năm mươi mốt by voxel51, một bộ công cụ mã nguồn mở cho phép bạn quản lý, theo dõi, trực quan hóa và sắp xếp tập dữ liệu của mình và Ground Truth, một dịch vụ ghi nhãn dữ liệu cho phép bạn gắn nhãn hiệu quả và chính xác các tập dữ liệu cần thiết cho các hệ thống ML đào tạo bằng cách cung cấp quyền truy cập vào nhiều bộ dữ liệu được xây dựng -in các mẫu nhiệm vụ và truy cập vào lực lượng lao động đa dạng thông qua Mechanical Turk, nhà cung cấp bên thứ ba hoặc lực lượng lao động tư nhân của riêng bạn.
Chúng tôi khuyến khích bạn dùng thử chức năng mới này bằng cách cài đặt phiên bản FiftyOne và sử dụng bảng điều khiển Ground Truth để bắt đầu. Để tìm hiểu thêm về Ground Truth, hãy tham khảo Dữ liệu nhãn, Câu hỏi thường gặp về ghi nhãn dữ liệu của Amazon SageMaker, và Blog Học máy AWS.
Kết nối với Cộng đồng Machine Learning & AI nếu bạn có bất kỳ câu hỏi hoặc phản hồi!
Tham gia cộng đồng FiftyOne!
Tham gia cùng hàng ngàn kỹ sư và nhà khoa học dữ liệu đã sử dụng FiftyOne để giải quyết một số vấn đề khó khăn nhất trong thị giác máy tính hiện nay!
Về các tác giả
Shalendra Chhabra hiện là Trưởng bộ phận quản lý sản phẩm cho Dịch vụ Human-in-the-Loop (HIL) của Amazon SageMaker. Trước đây, Shalendra đã ươm tạo và lãnh đạo Trí tuệ ngôn ngữ và hội thoại cho các cuộc họp nhóm của Microsoft, là EIR tại Công cụ tăng tốc khởi nghiệp Amazon Alexa Techstars, Phó chủ tịch sản phẩm và tiếp thị tại Thảo luận.io, Trưởng bộ phận Sản phẩm và Tiếp thị tại Clipboard (do Salesforce mua lại) và Giám đốc Sản phẩm chính tại Swype (do Nuance mua lại). Tổng cộng, Shalendra đã giúp xây dựng, vận chuyển và tiếp thị các sản phẩm đã chạm đến cuộc sống của hơn một tỷ người.
Jacob Marks là Kỹ sư máy học và Nhà phát triển truyền bá tại Voxel51, nơi anh ấy giúp mang lại sự minh bạch và rõ ràng cho dữ liệu của thế giới. Trước khi gia nhập Voxel51, Jacob đã thành lập một công ty khởi nghiệp để giúp các nhạc sĩ mới nổi kết nối và chia sẻ nội dung sáng tạo với người hâm mộ. Trước đó, anh làm việc tại Google X, Samsung Research và Wolfram Research. Ở kiếp trước, Jacob là một nhà vật lý lý thuyết, hoàn thành bằng tiến sĩ tại Stanford, nơi ông nghiên cứu các pha lượng tử của vật chất. Khi rảnh rỗi, Jacob thích leo núi, chạy và đọc tiểu thuyết khoa học viễn tưởng.
Jason Corso là người đồng sáng lập và Giám đốc điều hành của Voxel51, nơi ông chỉ đạo chiến lược giúp mang lại sự minh bạch và rõ ràng cho dữ liệu của thế giới thông qua phần mềm linh hoạt hiện đại. Ông cũng là Giáo sư về Người máy, Kỹ thuật Điện và Khoa học Máy tính tại Đại học Michigan, nơi ông tập trung vào các vấn đề cấp bách tại giao điểm của thị giác máy tính, ngôn ngữ tự nhiên và nền tảng vật lý. Khi rảnh rỗi, Jason thích dành thời gian cho gia đình, đọc sách, hòa mình vào thiên nhiên, chơi trò chơi trên bàn cờ và tất cả các loại hoạt động sáng tạo.
Brian Moore là người đồng sáng lập và CTO của Voxel51, nơi ông lãnh đạo tầm nhìn và chiến lược kỹ thuật. Ông có bằng Tiến sĩ về Kỹ thuật Điện của Đại học Michigan, nơi nghiên cứu của ông tập trung vào các thuật toán hiệu quả cho các vấn đề máy học quy mô lớn, đặc biệt chú trọng đến các ứng dụng thị giác máy tính. Khi rảnh rỗi, anh ấy thích chơi cầu lông, chơi gôn, đi bộ đường dài và chơi với Yorkshire Terrier song sinh của mình.
Chu Lăng Bạch là Kỹ sư phát triển phần mềm tại Amazon Web Services. Cô làm việc về phát triển các hệ thống phân tán quy mô lớn để giải quyết các vấn đề về học máy.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : có
- :là
- :không phải
- :Ở đâu
- $ LÊN
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Giới thiệu
- đẩy nhanh tiến độ
- tăng tốc
- gia tốc
- truy cập
- chính xác
- chính xác
- mua lại
- hoạt động
- thêm vào
- thêm
- địa chỉ
- Điều chỉnh
- Điều chỉnh
- Sau
- một lần nữa
- AI
- Alexa
- thuật toán
- Tất cả
- cho phép
- cô đơn
- Đã
- Ngoài ra
- đàn bà gan dạ
- amazon alexa
- Amazon SageMaker
- Sự thật về mặt đất của Amazon SageMaker
- Amazon Web Services
- trong số
- an
- phân tích
- và
- động vật
- bất kì
- ứng dụng
- Các Ứng Dụng
- các ứng dụng
- Đăng Nhập
- thích hợp
- LÀ
- bố trí
- bài viết
- bài viết
- AS
- liên kết
- At
- tác giả
- xa
- AWS
- cơ sở
- dựa
- BE
- bởi vì
- trở nên
- được
- trước
- sau
- đằng sau hậu trường
- được
- Tin
- BEST
- Hơn
- giữa
- Tỷ
- bảng
- Board Games
- XƯƠNG
- bootstrap
- cả hai
- Hộp
- hộp
- Brain
- Nghỉ giải lao
- mang lại
- Mang lại
- ngân sách
- xây dựng
- Xây dựng
- được xây dựng trong
- nhưng
- mua
- by
- CAN
- Chụp
- trường hợp
- trường hợp
- đố
- Phân loại
- giám đốc điều hành
- thách thức
- thách thức
- kiểm tra
- Chọn
- rõ ràng
- tốt nghiệp lớp XNUMX
- các lớp học
- phân loại
- Làm sạch
- trong sáng
- Rõ ràng
- khách hàng
- Leo núi
- Đóng
- gần gũi hơn
- quần áo
- Quần áo
- Đồng sáng lập
- mã
- kết hợp
- kết hợp
- công ty
- Bổ sung
- hoàn thành
- hoàn thành
- Tính
- máy tính
- Khoa học Máy tính
- Tầm nhìn máy tính
- Ứng dụng Thị giác Máy tính
- sự tự tin
- tự tin
- Kết nối
- xem xét
- Bao gồm
- An ủi
- chứa
- nội dung
- nội dung
- kiểm soát
- đàm thoại
- chuyển đổi
- bản sao
- Trung tâm
- sửa chữa
- tương ứng
- Phí Tổn
- Chi phí
- tạo
- tạo ra
- Sáng tạo
- Credentials
- CTO
- lưu trữ
- sắp xếp
- Hiện nay
- khách hàng
- khách hàng
- khách hàng
- Cắt
- tiên tiến
- dữ liệu
- bộ dữ liệu
- quyết định
- chứng minh
- Bông chéo
- chiều sâu
- Mô tả
- chi tiết
- Phát hiện
- Nhà phát triển
- phát triển
- Phát triển
- khác nhau
- trực tiếp
- thư mục
- Giao diện
- khác biệt
- phân phối
- hệ thống phân phối
- khác nhau
- do
- Không
- Dog
- làm
- thực hiện
- dont
- DOT
- xuống
- tải về
- bản sao
- e
- mỗi
- dễ dàng
- Cạnh
- hiệu lực
- hiệu quả
- hiệu quả
- kỹ thuật điện
- nhúng
- mới nổi
- nhấn mạnh
- sử dụng
- trao quyền
- đóng gói
- khuyến khích
- cuối
- ky sư
- Kỹ Sư
- Kỹ sư
- đăng ký hạng mục thi
- Môi trường
- bình đẳng
- thiết yếu
- thành lập
- Ether (ETH)
- đánh giá
- Thuyết phúc âm
- chính xác
- ví dụ
- hiện tại
- xuất khẩu
- khá
- gia đình
- người hâm mộ
- thông tin phản hồi
- vài
- Tiểu thuyết
- lĩnh vực
- Lĩnh vực
- Tập tin
- Các tập tin
- lọc
- lọc
- cuối cùng
- Tên
- phù hợp với
- linh hoạt
- Tập trung
- tập trung
- tập trung
- tiếp theo
- Trong
- hình thức
- định dạng
- May mắn thay
- Thành lập
- 4
- Miễn phí
- từ
- đầy đủ
- chức năng
- Trò chơi
- mục đích chung
- tạo ra
- tạo ra
- được
- GitHub
- Cho
- được
- mục tiêu
- golf
- tốt
- lớn hơn
- lưới
- Mặt đất
- Nhóm
- hướng dẫn
- vui mừng
- Có
- he
- cái đầu
- cao
- giúp đỡ
- đã giúp
- hữu ích
- giúp
- tại đây
- chất lượng cao
- độ phân giải cao
- cao nhất
- cao
- đi bộ đường dài
- của mình
- giữ
- Độ đáng tin của
- Hướng dẫn
- Tuy nhiên
- HTML
- http
- HTTPS
- Nhân loại
- i
- IAM
- ID
- xác định
- xác định
- id
- if
- hình ảnh
- hình ảnh
- Va chạm
- nhập khẩu
- cải thiện
- in
- Mặt khác
- Bao gồm
- không chính xác
- ủ
- thông tin
- ban đầu
- ban đầu
- cài đặt, dựng lên
- Cài đặt
- ví dụ
- thay vì
- hướng dẫn
- Sự thông minh
- ngã tư
- trong
- IT
- ITS
- áo nịt len
- Việc làm
- tham gia
- chung
- json
- chỉ
- Giữ
- giữ
- nhãn
- ghi nhãn
- Nhãn
- Ngôn ngữ
- quy mô lớn
- phóng
- ra mắt
- dẫn
- Dẫn
- LEARN
- học tập
- ít nhất
- Led
- trái
- cho phép
- Thư viện
- Cuộc sống
- Lượt thích
- Có khả năng
- LIMIT
- Hạn chế
- Dòng
- dòng
- Danh sách
- niêm yết
- Các bảng liệt kê
- ít
- cuộc sống
- tải
- Xem
- tìm kiếm
- Rất nhiều
- Thấp
- máy
- học máy
- thực hiện
- ma thuật
- làm cho
- LÀM CHO
- quản lý
- quản lý
- quản lý
- giám đốc
- nhiều
- bản đồ
- thị trường
- Marketing
- Trận đấu
- phù hợp
- vật chất
- chất
- Có thể..
- cơ khí
- Phương tiện truyền thông
- các cuộc họp
- Siêu dữ liệu
- Siêu dữ liệu
- phương pháp
- phương pháp
- Michigan
- microsoft
- đội microsoft
- Might
- tối thiểu
- ML
- di động
- ứng dụng di động
- kiểu mẫu
- mô hình
- Modules
- chi tiết
- hầu hết
- di chuyển
- nhiều
- nhiều
- nhạc sĩ
- phải
- tên
- Được đặt theo tên
- tên
- Tự nhiên
- Ngôn ngữ tự nhiên
- Thiên nhiên
- Gần
- nhất thiết
- cần thiết
- Cần
- nhu cầu
- Mới
- đáng chú ý
- Khái niệm
- tại
- bóng
- con số
- vật
- Phát hiện đối tượng
- đối tượng
- of
- chính thức
- on
- hàng loạt
- ONE
- Trực tuyến
- có thể
- mở
- mã nguồn mở
- Hoạt động
- Cơ hội
- Các lựa chọn
- or
- Tổ chức
- nguyên
- OS
- Nền tảng khác
- Khác
- vfoXNUMXfipXNUMXhfpiXNUMXufhpiXNUMXuf
- ra
- nêu
- đầu ra
- kết thúc
- riêng
- sở hữu
- Gói
- ghép đôi
- một phần
- riêng
- qua
- con đường
- Họa tiết
- mô hình
- hoàn hảo
- hiệu suất
- người
- Cá nhân
- Các giai đoạn của vật chất
- vật lý
- chọn
- Những bức ảnh
- kẻ sọc
- Trơn
- Nền tảng
- plato
- Thông tin dữ liệu Plato
- PlatoDữ liệu
- chơi
- Điểm
- đông dân cư
- có thể
- Bài đăng
- quyền lực
- thực hành
- dự đoán
- dự đoán
- Dự đoán
- Xem trước
- trước
- trước đây
- In
- Trước khi
- riêng
- có lẽ
- vấn đề
- quá trình
- Sản phẩm
- quản lý sản phẩm
- giám đốc sản xuất
- Sản phẩm
- Giáo sư
- dự án
- tài sản
- tương lai
- nguyên mẫu
- cho
- cung cấp
- cung cấp
- công khai
- cú đấm
- mục đích
- Python
- Quantum
- Câu hỏi
- Mau
- phạm vi
- hơn
- Reading
- sẵn sàng
- giới thiệu
- khuyến nghị
- giảm
- Giảm
- giảm
- tương đối
- phát hành
- có liên quan
- tẩy
- đại diện
- đại diện
- cần phải
- nghiên cứu
- nhà nghiên cứu
- Độ phân giải
- hạn chế
- kết quả
- kết quả
- Kết quả
- bán lẻ
- trở lại
- xem xét
- Thoát khỏi
- robotics
- mạnh mẽ
- Vai trò
- khoảng
- HÀNG
- làm hỏng
- chạy
- nhà làm hiền triết
- Nói
- lực lượng bán hàng
- tương tự
- Samsung
- Lưu
- cảnh
- Khoa học
- Khoa học giả tưởng
- các nhà khoa học
- Điểm số
- liền mạch
- Thứ hai
- Phần
- phần
- xem
- hình như
- dường như
- chọn
- ý nghĩa
- riêng biệt
- dịch vụ
- DỊCH VỤ
- Phiên
- định
- Chia sẻ
- chị ấy
- nên
- hiển thị
- Chương trình
- SIM
- tương tự
- Đơn giản
- nhỏ hơn
- So
- Phần mềm
- phát triển phần mềm
- động SOLVE
- một số
- Một người nào đó
- một cái gì đó
- Không gian
- tiêu
- Chi
- chia
- Tách
- stanford
- Bắt đầu
- bắt đầu
- Bắt đầu
- khởi động
- máy gia tốc khởi động
- nhà nước-of-the-art
- Các bước
- Vẫn còn
- là gắn
- hàng
- Chiến lược
- phong cách
- phong cách
- TÓM TẮT
- Hỗ trợ
- hệ thống
- Hãy
- Nhiệm vụ
- đội
- Kỹ thuật
- TechStars
- nói
- mẫu
- thử nghiệm
- hơn
- việc này
- Sản phẩm
- cung cấp their dịch
- Them
- sau đó
- lý thuyết
- Đó
- Kia là
- họ
- điều
- nghĩ
- của bên thứ ba
- điều này
- hàng ngàn
- ngưỡng
- Thông qua
- Ném
- thời gian
- đến
- bên nhau
- công cụ
- bộ công cụ
- hàng đầu
- cấp cao nhất
- tops
- Tổng số:
- xúc động
- theo dõi
- Train
- đào tạo
- Hội thảo
- Chuyển đổi
- Minh bạch
- đúng
- Sự thật
- XOAY
- hai
- kiểu
- loại
- Dưới
- hiểu
- độc đáo
- trường đại học
- Đại học Michigan
- Cập nhật
- us
- sử dụng
- ca sử dụng
- đã sử dụng
- người sử dang
- Người sử dụng
- sử dụng
- Các giá trị
- nhiều
- khác nhau
- nhà cung cấp
- xác minh
- rất
- thông qua
- Xem
- ảo
- tầm nhìn
- muốn
- là
- we
- web
- các dịch vụ web
- TỐT
- là
- Điều gì
- khi nào
- liệu
- cái nào
- Wikipedia
- sẽ
- với
- ở trong
- không có
- Dành cho Nữ
- từ
- Công việc
- làm việc
- công nhân
- Lực lượng lao động
- công trinh
- thế giới
- lo
- sẽ
- viết
- X
- bạn
- trên màn hình
- zephyrnet
- Zip
- VƯỜN BÁCH THÚ